Springboot扩展点之BeanPostProcessor
前言
Springboot(Spring)的扩展点其实有很多,但是都有一个共同点,都是围绕着Bean和BeanFactory(容器)展开的,其实这也很好理解,Spring的核心是控制反转、依赖注入、面向切面编程,再抛开所有的枝枝节节,你发现了什么?Spring提供了一个容器,来管理Bean,整个生态好像是都围绕这个展开。研究源码意义,一方面是在于技术本身,另一方面也在于理解接受其中的思想。
没有目的的乱走总是会迷路,有了目标就不一样了,所以这篇文章是围绕以下几个问题展开的,这也是我想和大家分享的内容:(如果你和我的疑问一样,关注,收藏+点赞,不迷路哦)
1、BeanPostProcessor接口的功能特性是什么样的?
2、BeanPostProcessor接口怎么实现扩展?
3、BeanPostProcessor接口的实现类的工作原理是什么?
4、BeanPostProcessor接口的应用场景有哪些?
功能特性
1、BeanPostProcessor是Bean级别的扩展接口,在Spring管理的Bean实例化完成后,预留了两种扩展点;
2、这两处扩展的实现方式就是实现BeanPostProcessor接口,并将实现类注册到Spring容器中;
3、两种扩展点分别是BeanPostProcessor接口的postProcessBeforeInitialization方法和postProcessAfterInitialization方法;
4、postProcessBeforeInitialization方法的执行时机是在Spring管理的Bean实例化、属性注入完成后,InitializingBean#afterPropertiesSet方法以及自定义的初始化方法之前;
5、postProcessAfterInitialization方法的执行时机是在InitializingBean#afterPropertiesSet方法以及自定义的初始化方法之前之后;
6、BeanPostProcessor接口的实现类的postProcessBeforeInitialization方法和postProcessAfterInitialization方法,在在Spring管理的每个bean初始化后都会执行到;
实现方式
1、定义一个实体类Dog,并实现InitializingBean接口,并且实现afterPropertiesSet()。其中afterPropertiesSet()和init()是为了演示BeanPostProcessor接口的实现类的postProcessBeforeInitialization方法和postProcessAfterInitialization方法的执行时机;
@Getter
@Setter
@Slf4j
public class Dog implements InitializingBean {private String name = "旺财";private String color = "黑色";public Dog() {log.info("---dog的无参构造方法被执行");}@Overridepublic void afterPropertiesSet() throws Exception {log.info("---afterPropertiesSet被执行");}public void init() {log.info("---initMethod被执行");}
}把Dog类注册到Spring容器中,并设置了Bean实例化后的初始化方法;
@Configuration
public class SpringConfig {@Bean(initMethod = "init")public Dog dog(){Dog dog = new Dog();return dog;}
}2、定义MyBeanPostProcessor,并且实现BeanPostProcessor接口;(这里类的命名和方法内逻辑仅是为了演示需要,实际开发中需要以实际逻辑来替换掉演示内容)
@Component
@Slf4j
public class MyBeanPostProcessor implements BeanPostProcessor {@Overridepublic Object postProcessBeforeInitialization(Object bean, String beanName) throws BeansException {if (beanName.equals("dog")) {log.info("postProcessBeforeInitialization---" + beanName);//如果特定的bean实例化完成后,还未执行InitializingBean.afterPropertiesSet()方法之前,有一些其他操作,可以在这里实现}return bean;}@Overridepublic Object postProcessAfterInitialization(Object bean, String beanName) throws BeansException {if (beanName.equals("dog")) {log.info("postProcessAfterInitialization---" + beanName);//如果特定的bean实例化完成,InitializingBean.afterPropertiesSet()方法执行后,有一些其他操作,可以在这里实现}return bean;}
}3、编写单元测试,来验证结果;
@SpringBootTest
@Slf4j
public class FanfuApplicationTests {@Testpublic void test3(){AnnotationConfigApplicationContext context = new AnnotationConfigApplicationContext("com.fanfu");Dog dog = ((Dog) context.getBean("dog"));log.info(dog.getName());}
}
结论:从单元测试的执行结果来看,验证了Spring的扩展点BeanPostProcessor的执行时机,即postProcessBeforeInitialization方法的执行时机是在Spring管理的Bean实例化、属性注入完成后,InitializingBean#afterPropertiesSet方法以及自定义的初始化方法之前;postProcessAfterInitialization方法的执行时机是在InitializingBean#afterPropertiesSet方法以及自定义的初始化方法之前之后;
以上演示了BeanPostProcessor作为Springboot的扩展点之一的实现方式和执行时机,下面从示例入手,来了解一下其基本的工作原理,正所谓知其然还要知其所以然嘛。
工作原理
BeanPostProcessor的工作原理的关键其实就是两点,第一,BeanPostProcessor的实现类是什么时候被注册的?第二,BeanPostProcessor的实现类的postProcessBeforeInitialization方法和postProcessAfterInitialization方法是如何被执行的?
注册时机
1、BeanPostProcessor中的两个扩展方法中,postProcessBeforeInitialization方法是先被执行的,即Bean实例化和属性注入完成之后,通过实现方式示例代码的Debug,找到了BeanPostProcessor接口的实现类到Spring容器中的入口,即org.springframework.context.support.AbstractApplicationContext#refresh--->registerBeanPostProcessors
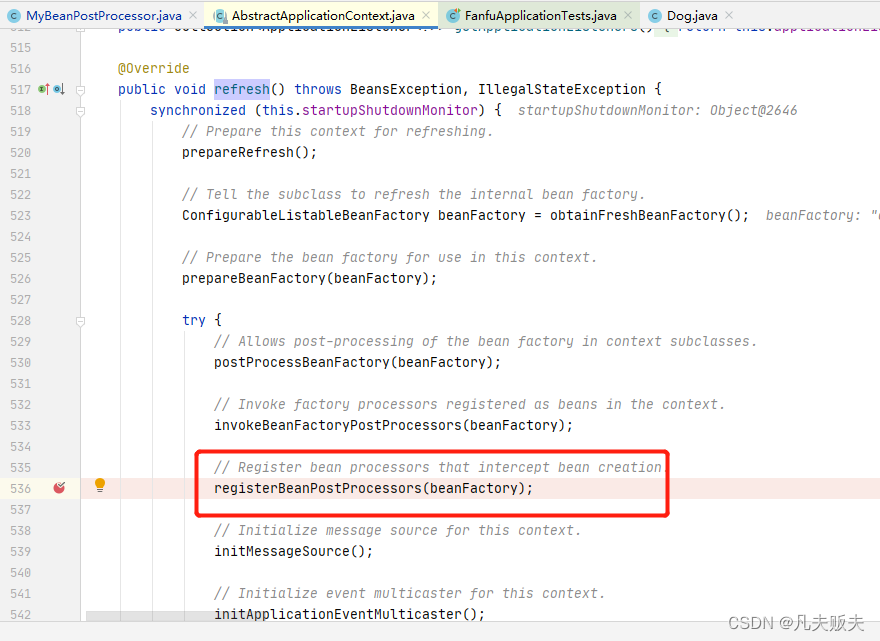
2、进入到AbstractApplicationContext#registerBeanPostProcessors方法内,会发现这段代码很干净,即依赖于PostProcessorRegistrationDelegate类的registerBeanPostProcessors()方法;
protected void registerBeanPostProcessors(ConfigurableListableBeanFactory beanFactory) {PostProcessorRegistrationDelegate.registerBeanPostProcessors(beanFactory, this);
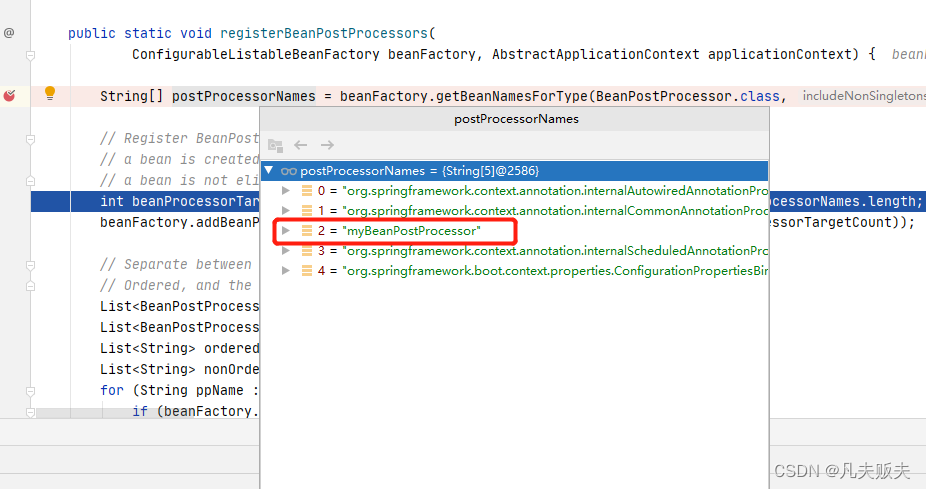
}3、进入到PostProcessorRegistrationDelegate类的registerBeanPostProcessors()方法又是另一番洞天:第一步,获取所有实现BeanPostProcessor接口的实现类的名称,实现方式示例中的MyBeanPostProcessors就在其中;
第二步,提前注册BeanPostProcessorChecker,主要用途是用于Bean创建过程中的日志信息打印记录;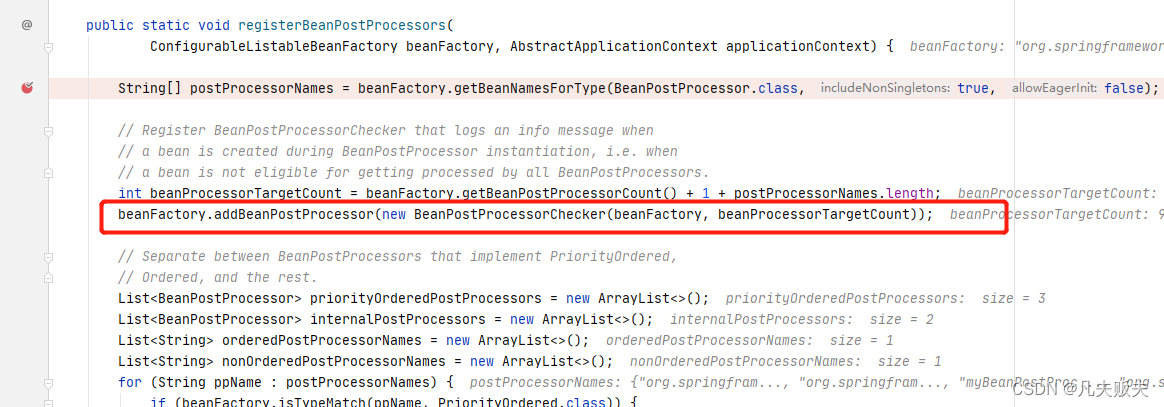
第三步,就是把所有的BeanPostProcessor接口的实现类,按照是否实现PriorityOrdered接口、是否实现Ordered接口、其他,分为三组;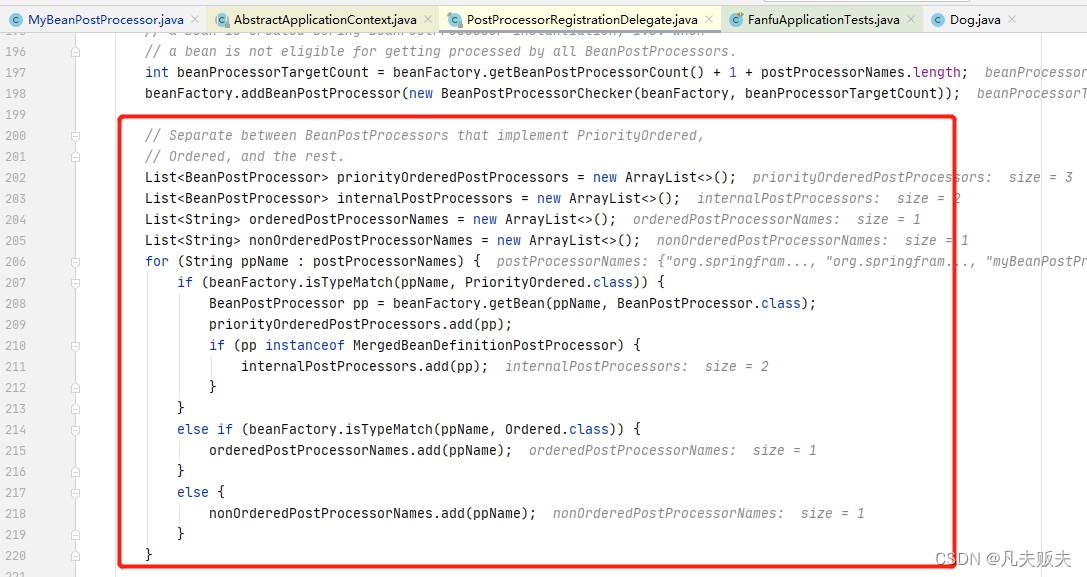
最后,下面的内容很长,不过很简单,即按第二步分成的三类,依次注册,具体的顺序是实现PriorityOrdered接口BeanPostProcessor接口的实现类、实现实现Ordered接口BeanPostProcessor接口的实现类、其他的BeanPostProcessor接口的实现类;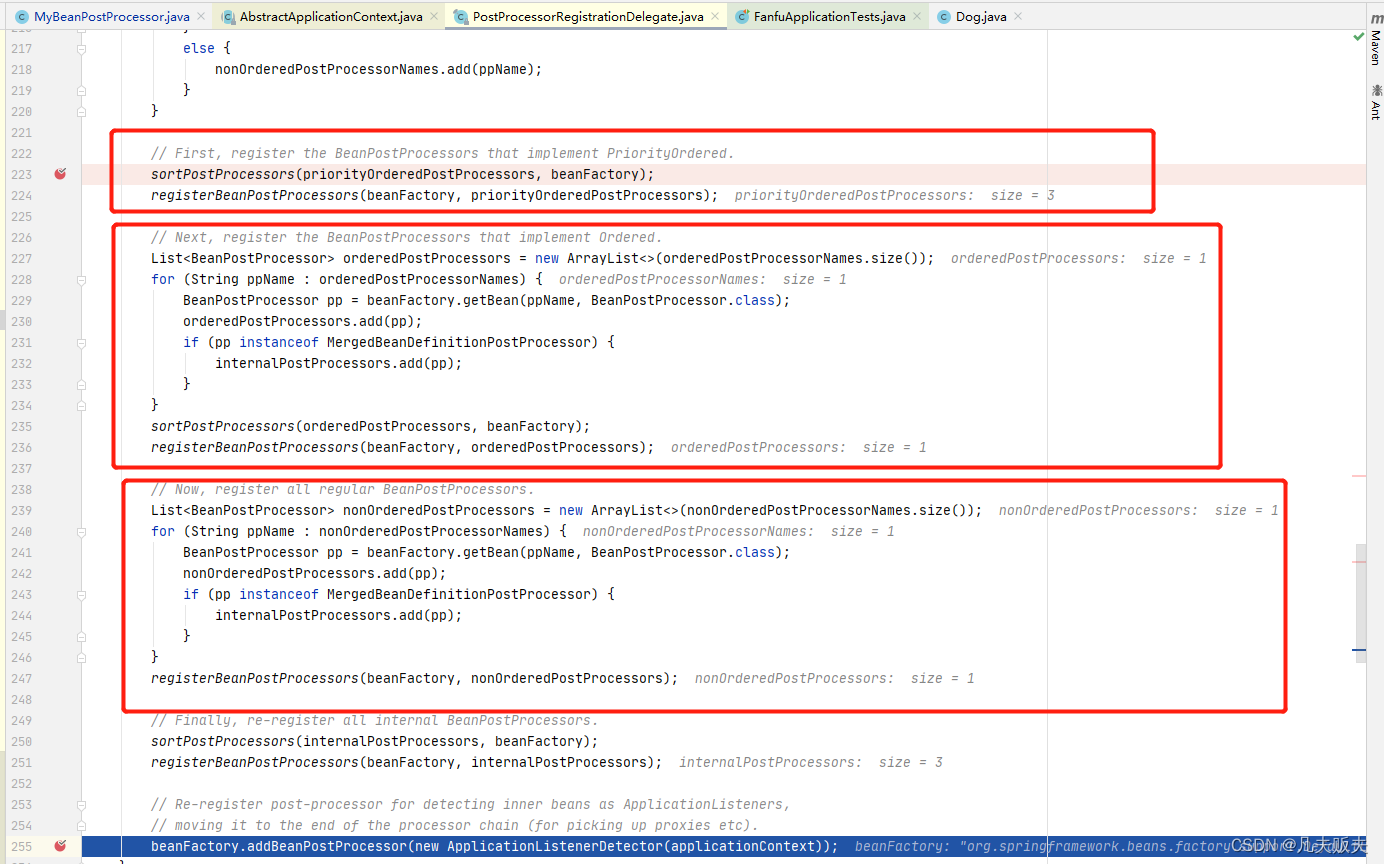
总结,BeanPostProcessor的注册时机是在Spring容器启动过程中,即BeanFactoryPostProcessor扩展点的逻辑执行完成后,紧接着就开始了BeanPostProcessor的注册,其具体的注册逻辑在PostProcessorRegistrationDelegate#registerBeanPostProcessors()。

执行时机
从实现方式的示例中验证得知,BeanPostProcessor接口的实现类的执行时机是在Spring管理的Bean实例化、属性注入完成后,那么找到Dog类的实例化入口,那么离BeanPostProcessor接口的实现类的执行时机也就不远了。
1、通过Debug调试,注册到Spring容器中的Dog类的实例化入口,即org.springframework.context.support.AbstractApplicationContext#refresh--->finishBeanFactoryInitialization();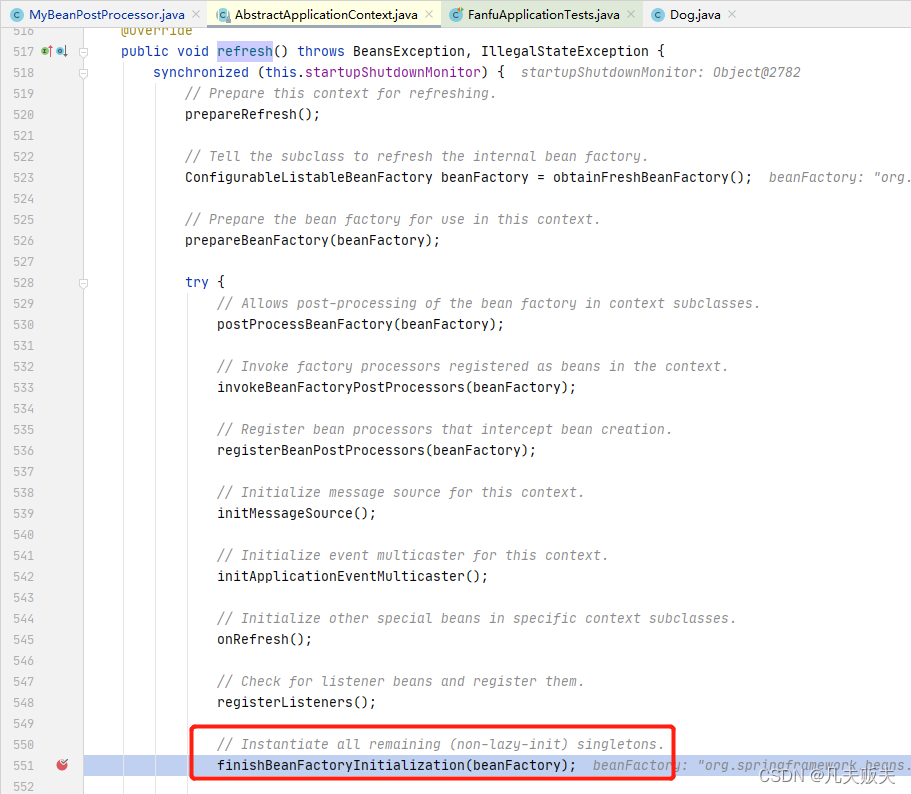
2、进入到finishBeanFactoryInitialization(),发现实现方式示例中的Dog类是在DefaultListableBeanFactory#preInstantiateSingletons--->getBean()中实例化完成的。这里大致介绍一下getBean()业务逻辑:当获取某一个bean时,先查询缓存确定是否存在,若存在,则直接返回,若不存在,则开始创建Bean,若Bean内依赖了另外一个Bean,则是上述过程的一个递归。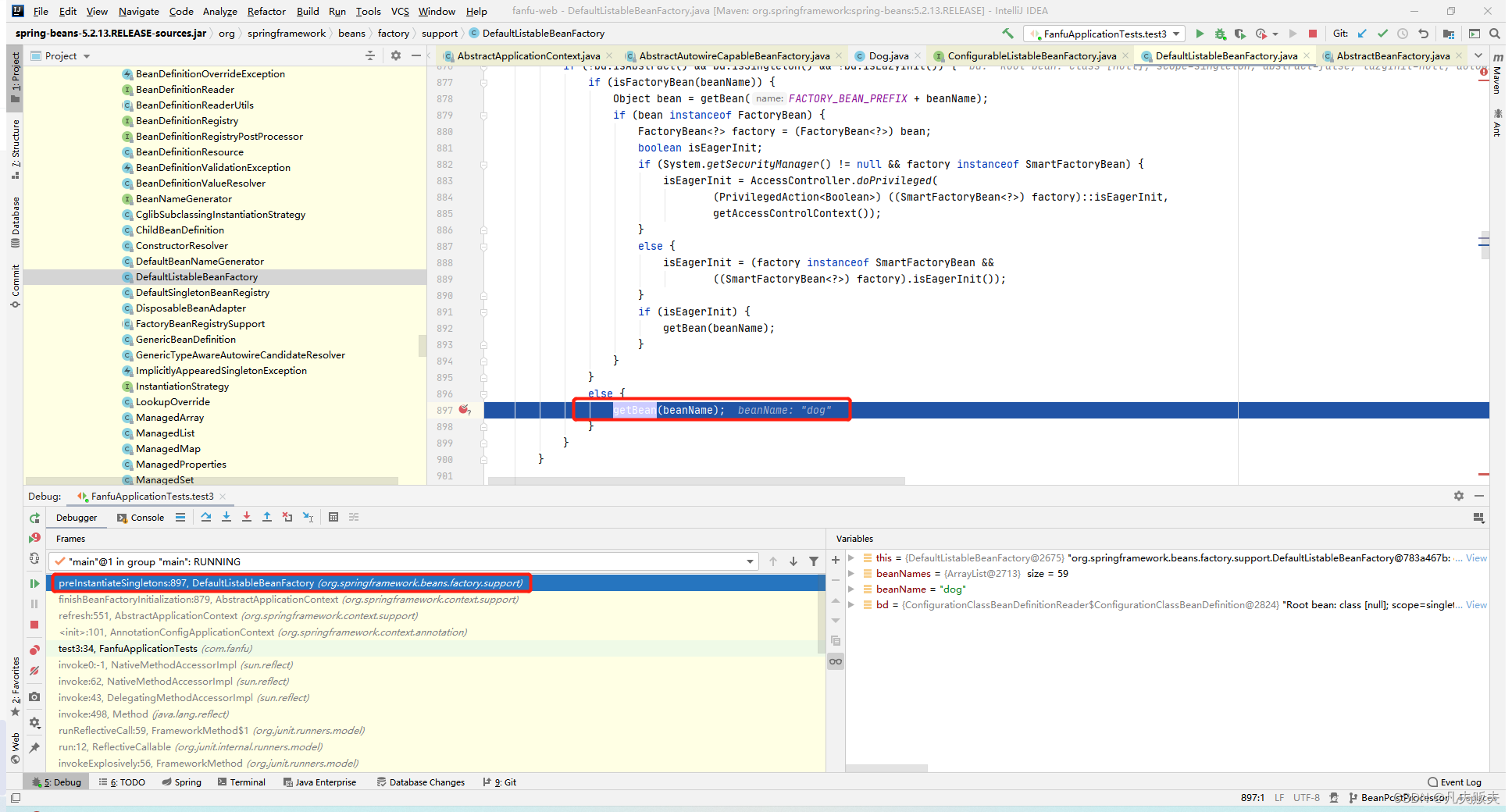
3、从getBean方法进入后,主要过程是AbstractBeanFactory#doGetBean-->AbstractBeanFactory#createBean-->AbstractAutowireCapableBeanFactory#doCreateBean-->AbstractAutowireCapableBeanFactory#createBeanInstance,至此完成了Bean的实例化和属性注入。到这要打起精神了,要找的BeanPostProcessor接口的实现类的执行时机马上就到。果然在AbstractAutowireCapableBeanFactory#doCreateBean方法中,Dog类实例化完后,又调用initializeBean()进行bean的初始化操作,而BeanPostProcessor接口的实现类的postProcessBeforeInitialization方法和postProcessAfterInitialization方法的执行时机分别是在Bean的初始化方法执行前后触发,那么这个方法大概率就是BeanPostProcessor接口的实现类的执行时机的入口了。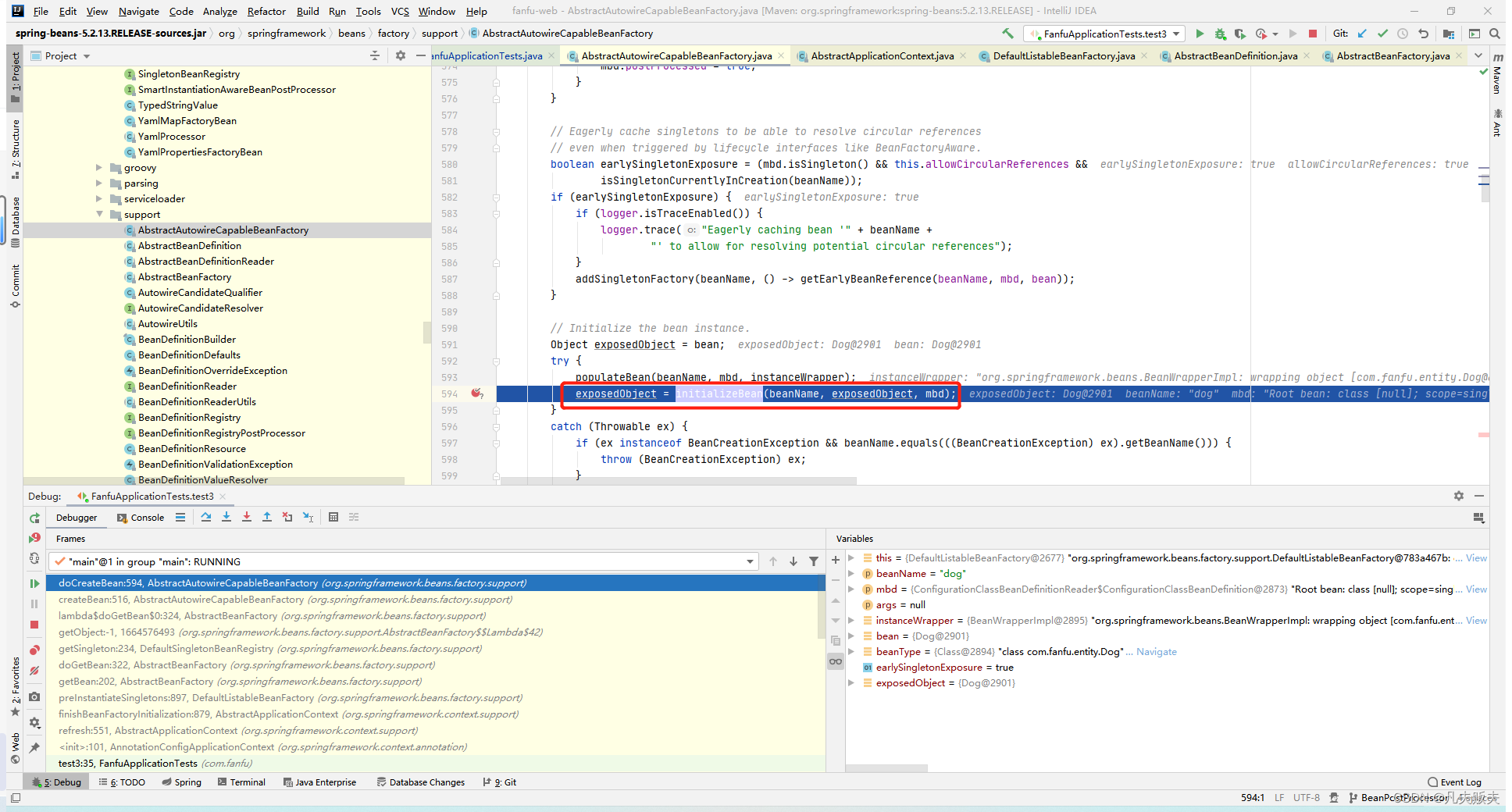
4、进入到initializeBean()一看,判断的果然没错,先执行BeanPostProcessor接口实现类的postProcessBeforeInitialization方法,接着如果bean实现了InitializingBean或者自定义了initMethod,就会在这里执行InitializingBean#afterPropertiesSet和initMethod方法,最后会执行执行BeanPostProcessor接口实现类的postProcessAfterInitialization方法;
protected Object initializeBean(String beanName, Object bean, @Nullable RootBeanDefinition mbd) {if (System.getSecurityManager() != null) {AccessController.doPrivileged((PrivilegedAction<Object>) () -> {invokeAwareMethods(beanName, bean);return null;}, getAccessControlContext());}else {invokeAwareMethods(beanName, bean);}Object wrappedBean = bean;if (mbd == null || !mbd.isSynthetic()) {//执行BeanPostProcessor接口实现类的postProcessBeforeInitialization方法wrappedBean = applyBeanPostProcessorsBeforeInitialization(wrappedBean, beanName);}try {//如果bean实现了InitializingBean或者自定义了initMethod,//会在这里执行InitializingBean#afterPropertiesSet和initMethod方法invokeInitMethods(beanName, wrappedBean, mbd);}catch (Throwable ex) {throw new BeanCreationException((mbd != null ? mbd.getResourceDescription() : null),beanName, "Invocation of init method failed", ex);}if (mbd == null || !mbd.isSynthetic()) {//执行BeanPostProcessor接口实现类的postProcessAfterInitialization方法wrappedBean = applyBeanPostProcessorsAfterInitialization(wrappedBean, beanName);}return wrappedBean;
}5、下面分别再进入到applyBeanPostProcessorsBeforeInitialization()、invokeInitMethods()、applyBeanPostProcessorsAfterInitialization(),看看具体是怎么实现的。先来看applyBeanPostProcessorsBeforeInitialization():如果仔细研究过之前的Springboot扩展点之BeanFactoryPostProcessor 、Springboot扩展点之BeanDefinitionRegistryPostProcessor 、Springboot扩展点之ApplicationContextInitializer这几篇文章,那么对这个方法的套路就再熟悉不过了:先获取到所有注册到Spring容器中BeanPostProcessor接口的实现类,然后再遍历执行触发方法,就这么朴实无华。
public Object applyBeanPostProcessorsBeforeInitialization(Object existingBean, String beanName)throws BeansException {Object result = existingBean;for (BeanPostProcessor processor : getBeanPostProcessors()) {Object current = processor.postProcessBeforeInitialization(result, beanName);if (current == null) {return result;}result = current;}return result;
}6、再来看一下,AbstractAutowireCapableBeanFactory#invokeInitMethods,逻辑也是很清晰,先判断是否实现了InitializingBean接口,如果实现了InitializingBean接口,就会触发执行afterPropertiesSet(),然后判断有没有自定义initMethod方法,如果有,则在这里开始执行;
protected void invokeInitMethods(String beanName, Object bean, @Nullable RootBeanDefinition mbd)throws Throwable {//判断是否实现了InitializingBean接口boolean isInitializingBean = (bean instanceof InitializingBean);if (isInitializingBean && (mbd == null || !mbd.isExternallyManagedInitMethod("afterPropertiesSet"))) {if (logger.isTraceEnabled()) {logger.trace("Invoking afterPropertiesSet() on bean with name '" + beanName + "'");}if (System.getSecurityManager() != null) {try {AccessController.doPrivileged((PrivilegedExceptionAction<Object>) () -> {((InitializingBean) bean).afterPropertiesSet();return null;}, getAccessControlContext());}catch (PrivilegedActionException pae) {throw pae.getException();}}else {//如果实现了InitializingBean接口,就会重写afterPropertiesSet(),这里就会触发执行((InitializingBean) bean).afterPropertiesSet();}}if (mbd != null && bean.getClass() != NullBean.class) {//判断有没有自定义initMethod方法,如果有,则在这里开始执行;String initMethodName = mbd.getInitMethodName();if (StringUtils.hasLength(initMethodName) &&!(isInitializingBean && "afterPropertiesSet".equals(initMethodName)) &&!mbd.isExternallyManagedInitMethod(initMethodName)) {invokeCustomInitMethod(beanName, bean, mbd);}}
}7、最后来看一下applyBeanPostProcessorsAfterInitialization(),前面applyBeanPostProcessorsBeforeInitialization()看懂了,这里就没有必要分析了,如出一辙,熟悉配方,熟悉的味道。
public Object applyBeanPostProcessorsAfterInitialization(Object existingBean, String beanName)throws BeansException {Object result = existingBean;for (BeanPostProcessor processor : getBeanPostProcessors()) {Object current = processor.postProcessAfterInitialization(result, beanName);if (current == null) {return result;}result = current;}return result;
}至此,Springboot扩展点BeanPostProcessor的工作原理分析完了,归根结底就是两点,第一,在Spring容器初始化的过程中,完成扩展点的注册;第二,在Spring中Bean完成实例化和属性注入后,开始触发已注册的扩展点的扩展动作。内容很长,但是逻辑简单,希望阅读到这篇文章的小伙伴能够有耐心看完,因为我在研究清楚整个过程后,我是感觉获益良多的,希望你也是。
应用场景
其实了解了BeanPostProcessor的功能特性、实现方式和工作原理,在遇到类似的业务需求的时候都可以应用这个扩展点,这里举两个我想到的应用场景:
处理自定义注解
在程序中我们可以自定义注解并标到相应的类上,当个类注册到Spring容器中,并实例化完成后,希望触发自定义注解对应的一些其他操作的时候,就可以通过BeanPostProcessor来实现。
参数校验
前面有两篇文章优雅的Springboot参数校验(一) 、优雅的Springboot参数校验(二) 和大家分享了参数校验具体实现方式,其核心原理正是用到了BeanPostProcessor扩展点,具体的实现类是org.springframework.validation.beanvalidation.BeanValidationPostProcessor
相关文章:
Springboot扩展点之BeanPostProcessor
前言 Springboot(Spring)的扩展点其实有很多,但是都有一个共同点,都是围绕着Bean和BeanFactory(容器)展开的,其实这也很好理解,Spring的核心是控制反转、依赖注入、面向切面编程&…...

Fluent Python 笔记 第 3 章 字典和集合
3.1 泛映射类型 只有可散列 的数据类型才能用作这些映射里的键 字典构造方法: >>> a dict(one1, two2, three3) >>> b {one: 1, two: 2, three: 3} >>> c dict(zip([one, two, three], [1, 2, 3])) >>> d dict([(two, 2…...
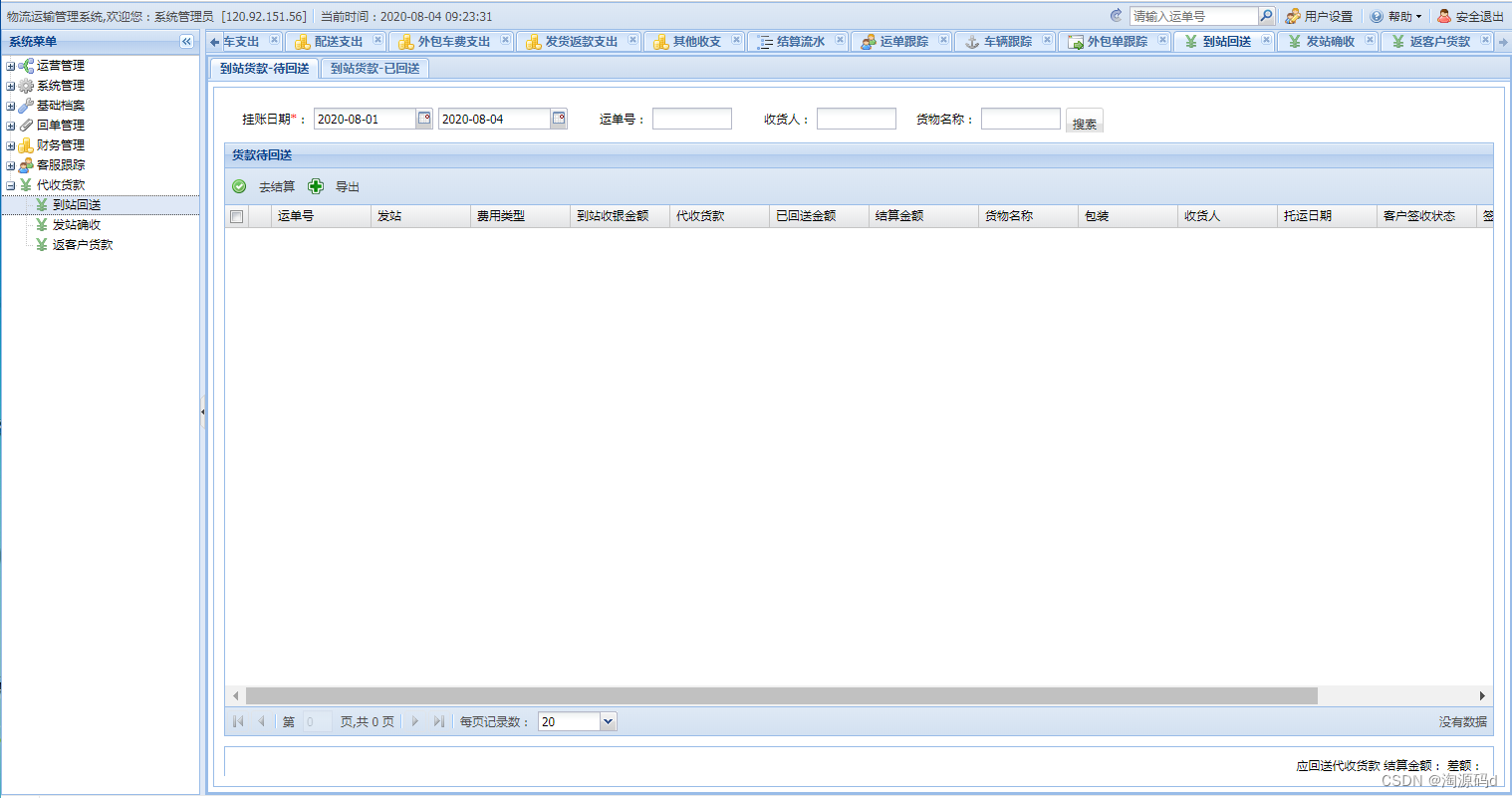
大型物流运输管理系统源码 TMS源码
大型物流运输管理系统源码 TMS是一套适用于物流公司的物流运输管理系统,涵盖物流公司内部从订单->提货->运单->配车->点到->预约->签收->回单->代收货款的全链条管理系统。 菜单功能 一、运营管理 1、订单管理:用于客户意向订…...
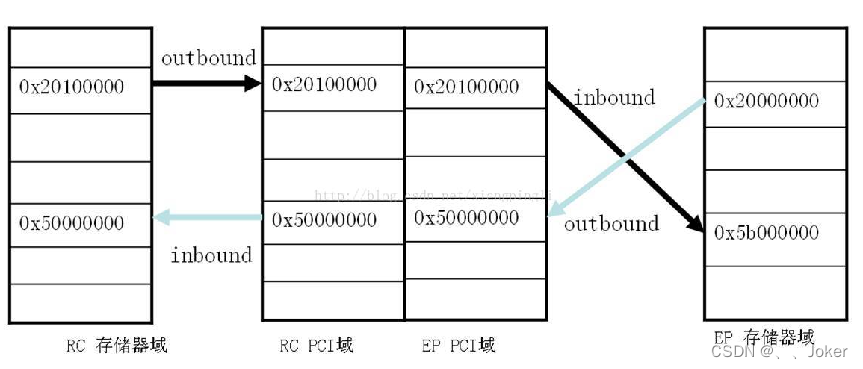
PCIE总线
PCIE总线记录描述PCI分类与速度PCIE连接拓扑与角色PCIE接口定义PCIE数据传输方式与中断在PCIE中有两种数据传输方式:PCIE中断:PCIE协议栈与工作流程PCIE地址空间分类实例分析PCIE两种访问方式描述 PCI-Express(peripheral component interconnect expre…...

Android IO 框架 Okio 的实现原理,如何检测超时?
本文已收录到 AndroidFamily,技术和职场问题,请关注公众号 [彭旭锐] 提问。 前言 大家好,我是小彭。 在上一篇文章里,我们聊到了 Square 开源的 I/O 框架 Okio 的三个优势:精简且全面的 API、基于共享的缓冲区设计以…...

简单介绍反射
1.定义Java的反射机制是在运行状态中,对于任意一个类,都知道这个类的所有属性和方法;对于任意一个对象,都能调用它的任意方法和属性,既然能拿到,我们就可以修改部分类型信息;这种动态获取信息的…...

PyTorch学习笔记:nn.MSELoss——MSE损失
PyTorch学习笔记:nn.MSELoss——MSE损失 torch.nn.MSELoss(size_average None,reduce None,reduction mean)功能:创建一个平方误差(MSE)损失函数,又称为L2损失: l(x,y)L{l1,…,lN}T,ln(xn−yn)2l(x,y)L…...
apache和nginx的TLS1.0和TLS1.1禁用处理方案
1、TLS1.0和TLS1.1是什么? TLS协议其实就是网络安全传输层协议,用于在两个通信应用程序之间提供保密性和数据完整性,TLS 1. 0 和TLS 1. 1 是分别是96 年和 06 年发布的老版协议。 2、为什么要禁用TLS1.0和TLS1.1传输协议 TLS1.0和TLS1.1协…...
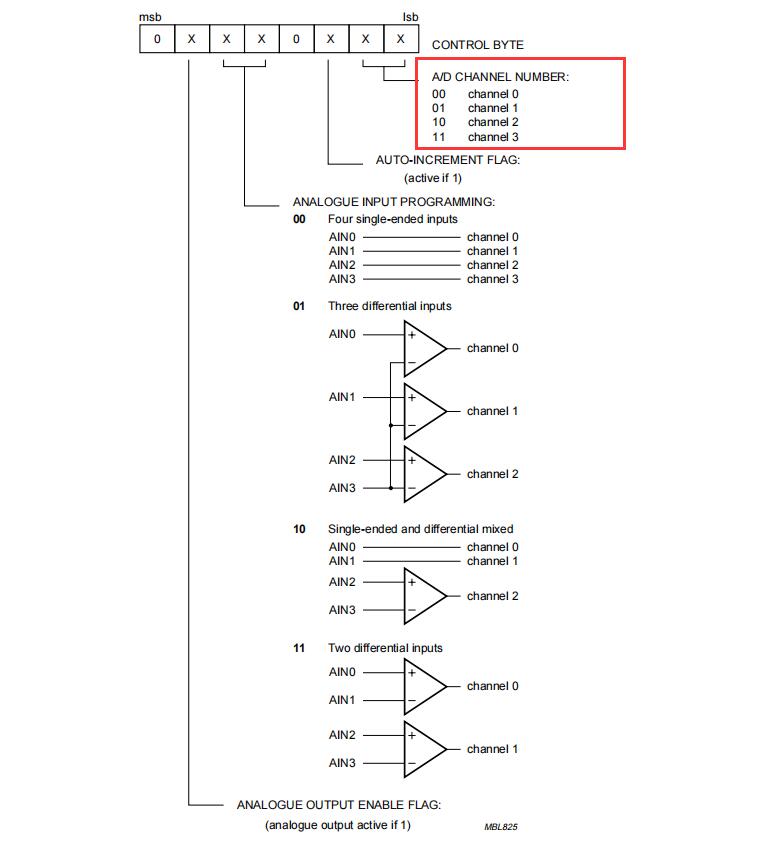
K_A12_002 基于STM32等单片机采集光敏电阻传感器参数串口与OLED0.96双显示
K_A12_002 基于STM32等单片机采集光敏电阻传感器参数串口与OLED0.96双显示一、资源说明二、基本参数参数引脚说明三、驱动说明IIC地址/采集通道选择/时序对应程序:四、部分代码说明1、接线引脚定义1.1、STC89C52RC光敏电阻传感器模块1.2、STM32F103C8T6光敏电阻传感器模块五、基…...

《机器学习》学习笔记
第 2 章 模型评估与选择 2.1 经验误差与过拟合 精度:精度1-错误率。如果在 mmm 个样本中有 aaa 个样本分类错误,则错误率 Ea/mEa/mEa/m,精度 1−a/m1-a/m1−a/m。误差:一般我们把学习器的实际预测输出与样本的真实输出之间的差…...
前端卷算法系列(一)
前端卷算法系列(一) 两数之和 给定一个整数数组 nums 和一个整数目标值 target,请你在该数组中找出 和为目标值 target 的那 两个 整数,并返回它们的数组下标。 你可以假设每种输入只会对应一个答案。但是,数组中同…...

【机器学习】聚类算法(理论)
聚类算法(理论) 目录一、概论1、聚类算法的分类2、欧氏空间的引入二、K-Means算法1、算法思路2、算法总结三、DBSCAN算法1、相关概念2、算法思路3、算法总结四、实战部分一、概论 聚类分析,即聚类(Clustering)…...
Docker-用Jenkins发版Java项目-(1)Docke安装Jenkins
文章目录前言环境背景操作流程docker安装及jenkins软件安装jenkins配置登录配置安装插件及创建账号前言 学海无涯,旅“途”漫漫,“途”中小记,如有错误,敬请指出,在此拜谢! 最近新购得了M2的MAC,…...
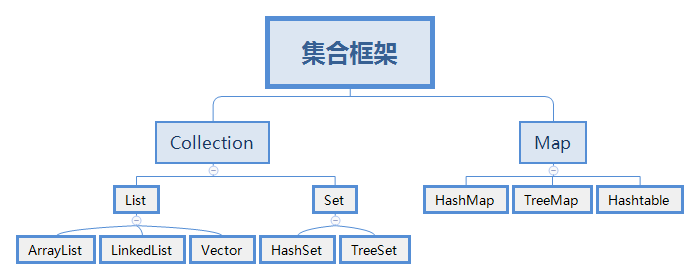
java集合框架内容整理
主要内容集合框架体系ArrayListLinkedListHashSetTreeSetLinkedHashSet内部比较器和外部比较器哈希表的原理List集合List集合的主要实现类有ArrayList和LinkedList,分别是数据结构中顺序表和链表的实现。另外还包括栈和队列的实现类:Deque和Queue。• Li…...

win10系统安装Nginx
Nginx是一款自由的、开源的、高性能的HTTP服务器和反向代理服务器,同时也提供了IMAP/POP3/SMTP服务。 Nginx可以进行反向代理、负载均衡、HTTP服务器(动静分离)、正向代理等操作。因为最近在公司使用到了Nginx 第一步:下载Nginx …...

数据库学习笔记(2)——workbench和SQL语言
1、workbench简介: 登录客户端的两种方法 在cmd中,只能通过sql语句控制数据库;workbench其实就是一种图形化数据库管理工具,在workbench中既可以通过sql语句控制数据库,也可以通过图形化界面控制数据库。通过workbenc…...

测量学期末考试之名词解释总结
仅供自己参考,且范围不全面.大地水准面与处于静止平衡状态的平均海水面重合,并延伸通过陆地的水准面高程地面点到大地水准面的铅锤距离水准面处于静止状态的水面就是水准面高差两点的水准面之间的铅锤距离垂直角在铅锤面上,瞄准目标的倾斜视线…...
TDengine时序数据库的简单使用
最近学习了TDengine数据库,因为我们公司有硬件设备,设备按照每分钟,每十分钟,每小时上传数据,存入数据库。而这些数据会经过sql查询,统计返回展示到前端。但时间积累后现在数据达到了百万级数据,…...

记录每日LeetCode 2335.装满被子需要的最短总时长 Java实现
题目描述: 现有一台饮水机,可以制备冷水、温水和热水。每秒钟,可以装满 2 杯 不同 类型的水或者 1 杯任意类型的水。 给你一个下标从 0 开始、长度为 3 的整数数组 amount ,其中 amount[0]、amount[1] 和 amount[2] 分别表示需要…...

了解线程池newFixedTheadPool
什么是线程池 操作系统 能够进行运算 调度 的最小单位。线程池是一种多线程处理形式。 为什么引入线程池的概念 解决处理短时间任务时创建和销毁线程代价较大的弊端,可以使用线程池技术。 复用 饭店只有一个服务员和饭店有10个服务员 线程池的种类 newFixedThea…...

百川2-13B-4bits量化版精度测试:OpenClaw自动化任务准确率对比
百川2-13B-4bits量化版精度测试:OpenClaw自动化任务准确率对比 1. 测试背景与实验设计 上周在部署OpenClaw自动化工作流时,我遇到了一个现实问题:本地显卡只有12GB显存,跑不动原版13B模型。于是尝试了百川2-13B的4bits量化版本&…...

客服服务时长难统计?RPA自动记时长,排班更合理
RPA在客服服务时长统计中的应用客服服务时长的准确统计是优化排班和提高效率的关键。传统手动统计方式存在误差大、效率低等问题。RPA(机器人流程自动化)技术可以自动记录客服工作时长,为排班提供数据支持。RPA自动记录客服工作时长的实现方式…...

从零到精通:Human Resource Machine 全关卡高效解法与思维跃迁指南
1. 为什么《Human Resource Machine》是程序员的最佳思维训练场 第一次打开《Human Resource Machine》时,我以为这不过是个披着编程外衣的小游戏。但当我卡在"第三年"的关卡整整一个下午后,才意识到这可能是最接近真实编程思维的训练场。这款…...

Wan2.1 VAE模型压缩实战:降低显存占用以适配更多GPU设备
Wan2.1 VAE模型压缩实战:降低显存占用以适配更多GPU设备 最近在尝试部署一些图像生成项目时,经常遇到一个头疼的问题:模型太大,显存不够用。特别是像Wan2.1 VAE这类模型,虽然生成效果出色,但动辄几个G的显…...
到底怎么落地)
别再只盯着ODD了!从特斯拉FSD和华为ADS的实战,聊聊ODC(设计运行条件)到底怎么落地
从特斯拉FSD到华为ADS:ODC实战落地的工程密码 当特斯拉车主在暴雨天启动FSD时,系统会先检查挡风玻璃上的雨滴传感器数据;而华为ADS用户试图在未系安全带状态下激活系统,仪表盘会立即弹出红色警告——这些看似简单的交互背后&…...
彩色蔓延路径规划算法Matlab代码)
【路径规划】传统A星+改进A星(star)彩色蔓延路径规划算法Matlab代码
✅作者简介:热爱科研的Matlab仿真开发者,擅长毕业设计辅导、数学建模、数据处理、建模仿真、程序设计、完整代码获取、论文复现及科研仿真。🍎 往期回顾关注个人主页:Matlab科研工作室👇 关注我领取海量matlab电子书和…...

ElasticSearch集群搭建步骤
文章目录一、前言二、使用 RPM 安装 Elasticsearch导入 Elasticsearch GPG 密钥从 RPM 存储库安装三、设置基本安全性生成证书使用TLS加密节点间通信四、为 Elasticsearch 加密 HTTP 客户端通信五、配置集群编辑 elasticsearch.yml(通用配置)关键性能参数…...

OpenClaw硬件监控:nanobot定时报告系统资源使用情况
OpenClaw硬件监控:nanobot定时报告系统资源使用情况 1. 为什么需要自动化硬件监控 去年夏天,我的开发机因为内存泄漏问题突然宕机,导致一个重要的线上演示被迫推迟。当时我就意识到,手动检查系统资源的方式既不及时也不可靠。直…...

Zotero文献管理终极指南:从混乱到高效的研究工作流
Zotero文献管理终极指南:从混乱到高效的研究工作流 【免费下载链接】zotero Zotero is a free, easy-to-use tool to help you collect, organize, annotate, cite, and share your research sources. 项目地址: https://gitcode.com/gh_mirrors/zo/zotero Z…...

别再只开会了!解锁Jitsi隐藏玩法:用Freeswitch+Jigasi打造智能电话会议IVR
解锁Jitsi企业级应用:用FreeswitchJigasi构建智能会议IVR系统 当视频会议成为企业刚需,大多数团队仍停留在基础会议功能层面。开源工具Jitsi与电信级软交换平台Freeswitch的结合,能创造出远超常规会议体验的智能交互系统。想象一下这样的场景…...