解密Kafka主题的分区策略:提升实时数据处理的关键

目录
- 一、Kafka主题的分区策略概述
- 1.1 什么是Kafka主题的分区策略?
- 1.2 为什么分区策略重要?
- 二、Kafka默认分区策略
- 2.1 Round-Robin分区策略
- 三、自定义分区策略
- 3.1 编写自定义分区器
- 3.2 最佳实践:如何选择分区策略
- 四、分区策略的性能考量
- 4.1 数据均衡
- 4.2 高吞吐量
- 4.3 顺序性
- 五、示例:使用不同分区策略
- 5.1 示例1:Round-Robin策略
- 5.2 示例2:自定义分区策略
- 六、总结
大家好,我是哪吒。
Kafka几乎是当今时代背景下数据管道的首选,无论你是做后端开发、还是大数据开发,对它可能都不陌生。开源软件Kafka的应用越来越广泛。
面对Kafka的普及和学习热潮,哪吒想分享一下自己多年的开发经验,带领读者比较轻松地掌握Kafka的相关知识。
上一节我们说到了Kafka的批处理和流处理,今天系统的说一下Kafka的分区策略,实现步步为营,逐个击破,拿下Kafka。
一、Kafka主题的分区策略概述
理解Kafka主题的分区策略对于构建高性能的消息传递系统至关重要。深入探讨Kafka分区策略的重要性以及如何在分布式消息传递中使用它。
1.1 什么是Kafka主题的分区策略?
Kafka是一个分布式消息传递系统,用于实现高吞吐量的数据流。消息传递系统的核心是主题(Topics),而这些主题可以包含多个分区(Partitions)。
分区是Kafka的基本并行处理单位,允许数据并发处理。

分区策略定义了消息在主题中如何分配到不同的分区。它决定了消息将被写入哪个分区,以及在消费时如何从不同分区读取消息。
分区策略是Kafka的关键组成部分,直接影响到Kafka集群的性能和数据的顺序性。
1.2 为什么分区策略重要?
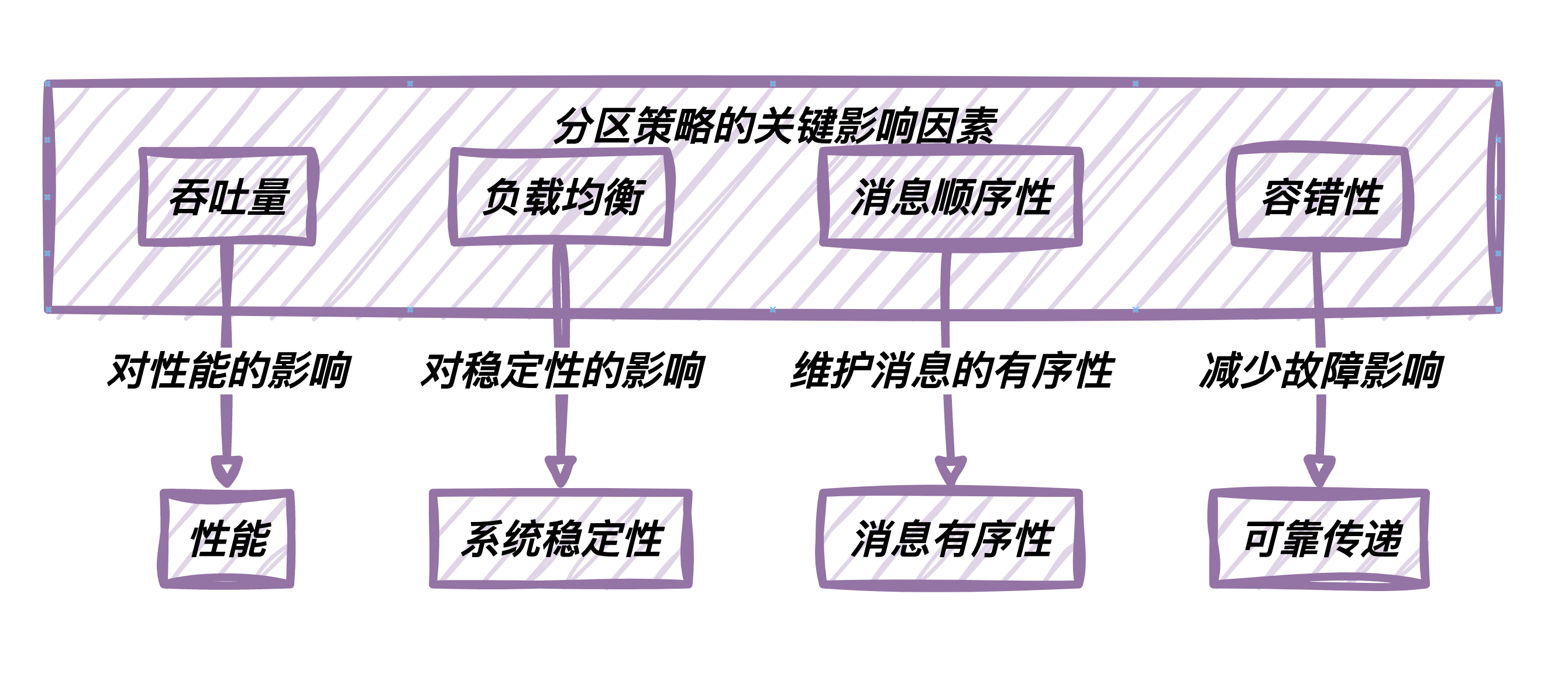
分区策略的选择对Kafka系统的性能、伸缩性和容错性产生深远影响。
以下是一些分区策略的关键影响因素:
-
吞吐量:合理的分区策略可以提高Kafka集群的吞吐量。它允许消息并行处理,提高了数据传递的效率。
-
负载均衡:分区策略有助于均衡Kafka集群中各个分区的负载。均衡的分区分布意味着没有过载的分区,从而提高了系统的稳定性。
-
顺序性:某些应用程序需要保持消息的顺序性,因此选择正确的分区策略对于维护消息的有序性至关重要。
-
容错性:合适的分区策略可以减少故障对系统的影响。在节点故障时,分区策略可以确保消息的可靠传递。
二、Kafka默认分区策略
2.1 Round-Robin分区策略
Kafka默认的分区策略是Round-Robin。这意味着当生产者将消息发送到主题时,Kafka会循环选择每个分区,以便均匀分布消息。
Round-Robin策略的工作原理如下:
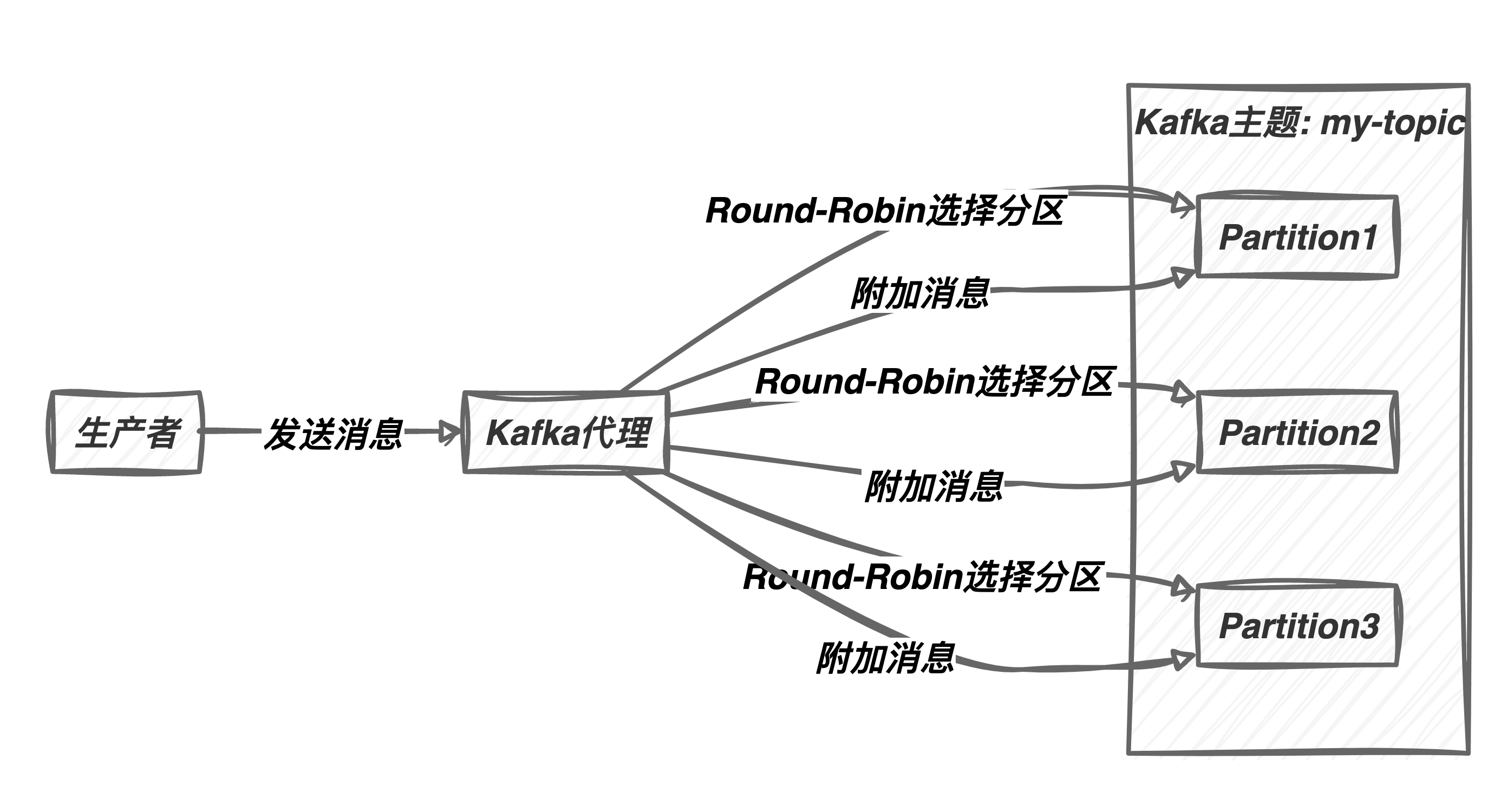
- 生产者发送消息到主题时,不指定目标分区。
- Kafka代理根据Round-Robin算法选择下一个可用分区。
- 消息被附加到选定的分区。
这个策略适用于以下情况:
- 当消息的键没有特定的含义或用途时,Round-Robin是一种简单的分区策略。
- 当你希望均匀地将消息分布到各个分区时,这是一种有效的策略。
这段代码示例展示了如何创建一个使用Round-Robin分区策略的Kafka生产者。以下是代码的详细说明:
(1)导入所需的库:
import org.apache.kafka.clients.producer.KafkaProducer;
import org.apache.kafka.clients.producer.Producer;
import org.apache.kafka.clients.producer.ProducerConfig;
import org.apache.kafka.clients.producer.ProducerRecord;
(2)设置Kafka生产者的配置属性:
Properties props = new Properties();
props.put("bootstrap.servers", "localhost:9092");
props.put("key.serializer", "org.apache.kafka.common.serialization.StringSerializer");
props.put("value.serializer", "org.apache.kafka.common.serialization.StringSerializer");
"bootstrap.servers": 这是Kafka代理的地址,生产者将与之建立连接。"key.serializer": 用于序列化消息键的序列化器。"value.serializer": 用于序列化消息值的序列化器。
(3)创建Kafka生产者:
Producer<String, String> producer = new KafkaProducer<>(props);
(4)使用生产者发送消息到主题(“my-topic”),这里演示了两个消息:
producer.send(new ProducerRecord<>("my-topic", "key1", "value1"));
producer.send(new ProducerRecord<>("my-topic", "key2", "value2"));
// ...
ProducerRecord用于指定要发送到的主题、消息的键和值。
(5)最后,不要忘记在使用生产者结束时关闭它:
producer.close();
这段代码创建了一个Kafka生产者,使用Round-Robin分区策略将消息发送到名为"my-topic"的主题。这是一个简单但常见的用例,适用于那些不需要特定分区策略的情况,只需均匀地将消息分布到各个分区。
三、自定义分区策略
3.1 编写自定义分区器

有时,Kafka默认的Round-Robin策略不能满足特定的需求。在这种情况下,你可以编写自定义的分区策略。自定义分区策略为你提供了更大的灵活性,允许你根据消息的键来选择分区。
要编写自定义分区器,你需要实现org.apache.kafka.clients.producer.Partitioner接口,并实现以下方法:
int partition(String topic, Object key, byte[] keyBytes, Object value, byte[] valueBytes, Cluster cluster): 该方法根据消息的键来选择分区,并返回分区的索引。void close(): 在分区器关闭时执行的清理操作。void configure(Map<String, ?> configs): 配置分区器。
下面是一个示例,展示了如何编写自定义分区器的Java类:
// 代码示例:自定义分区器的Java类
public class CustomPartitioner implements Partitioner {@Overridepublic int partition(String topic, Object key, byte[] keyBytes, Object value, byte[] valueBytes, Cluster cluster) {List<PartitionInfo> partitions = cluster.partitionsForTopic(topic);int numPartitions = partitions.size();// 根据消息的键来选择分区int partition = Math.abs(key.hashCode()) % numPartitions;return partition;}@Overridepublic void close() {// 关闭资源}@Overridepublic void configure(Map<String, ?> configs) {// 配置信息}
}
3.2 最佳实践:如何选择分区策略
选择适当的分区策略是关键,它直接影响到你的Kafka应用程序的性能和行为。
以下是一些建议,帮助你选择最合适的分区策略:
- 考虑消息的含义:消息的键如果具有特定的含义,例如地理位置或用户ID,可以使用自定义分区策略来确保相关消息被写入同一分区,以维护数据的局部性。
- 性能测试和评估:在选择分区策略之前,进行性能测试和评估非常重要。不同的策略可能会产生不同的性能影响。
- 负载均衡:确保分区策略能够均衡地分配负载到Kafka集群的各个节点。避免
出现过载的分区,以维持系统的稳定性。
你可以在生产者的配置中指定使用哪个分区器,如下所示:
// 代码示例:如何在生产者中指定自定义分区器
props.put("partitioner.class", "com.example.CustomPartitioner");
四、分区策略的性能考量
4.1 数据均衡
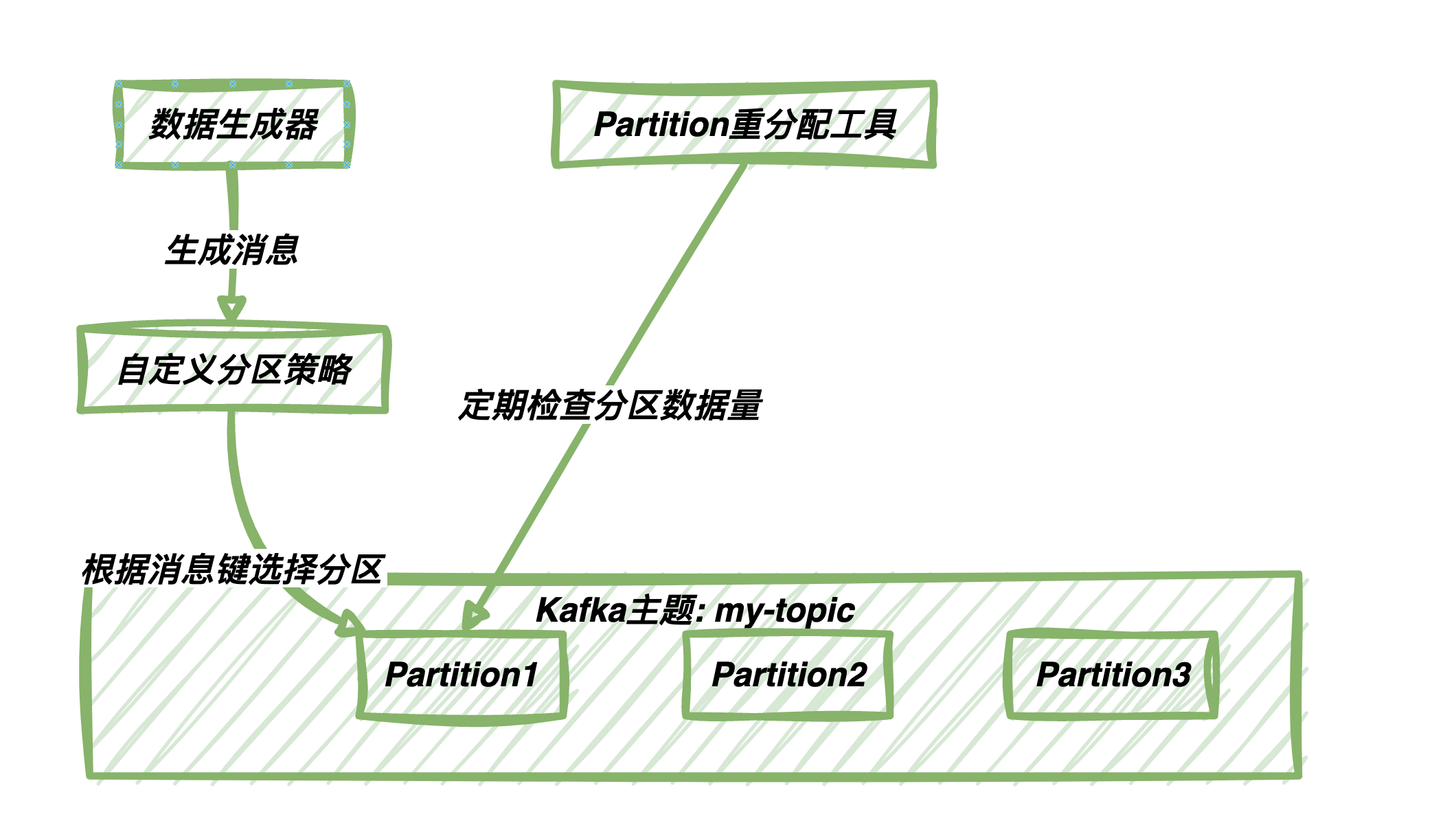
在Kafka中,数据均衡是分区策略中的一个关键因素。如果分区不平衡,可能会导致一些分区处理的数据量远大于其他分区,从而引起负载不均匀的问题。
在实际情况中,数据均衡的问题可能是由于消息的键分布不均匀而引起的。
为了解决这个问题,你可以考虑以下几种方法:
-
自定义分区策略:根据消息的键来选择分区,以确保相关消息被写入同一分区。这可以维护数据的局部性,有助于减少分区不均衡。
-
分区重分配:定期检查分区的数据量,如果发现不均衡,可以考虑重新分配分区。这可以是手动的过程,也可以借助工具来自动实现。
4.2 高吞吐量

高吞吐量是Kafka集群的一个关键性能指标。下面深入探讨分区策略对Kafka集群吞吐量的影响。同时,我们将提供性能优化的策略,包括深入分析吞吐量瓶颈和性能调整。
要实现高吞吐量,你可以考虑以下几个方面的性能优化:
- 调整生产者设置:通过调整生产者的配置参数,如
batch.size和linger.ms,可以实现更高的吞吐量。这些参数影响了消息的批量发送和等待时间,从而影响了吞吐量。
// 代码示例:如何调整生产者的批量发送设置以提高吞吐量
props.put("batch.size", 16384);
props.put("linger.ms", 1);
-
水平扩展:如果Kafka集群的吞吐量需求非常高,可以考虑通过添加更多的Kafka代理节点来进行水平扩展。这将增加集群的整体吞吐量。
-
监控和调整:定期监控Kafka集群的性能,并根据需要进行调整。使用监控工具来检测性能瓶颈,例如高负载的分区,然后采取措施来解决这些问题。
4.3 顺序性
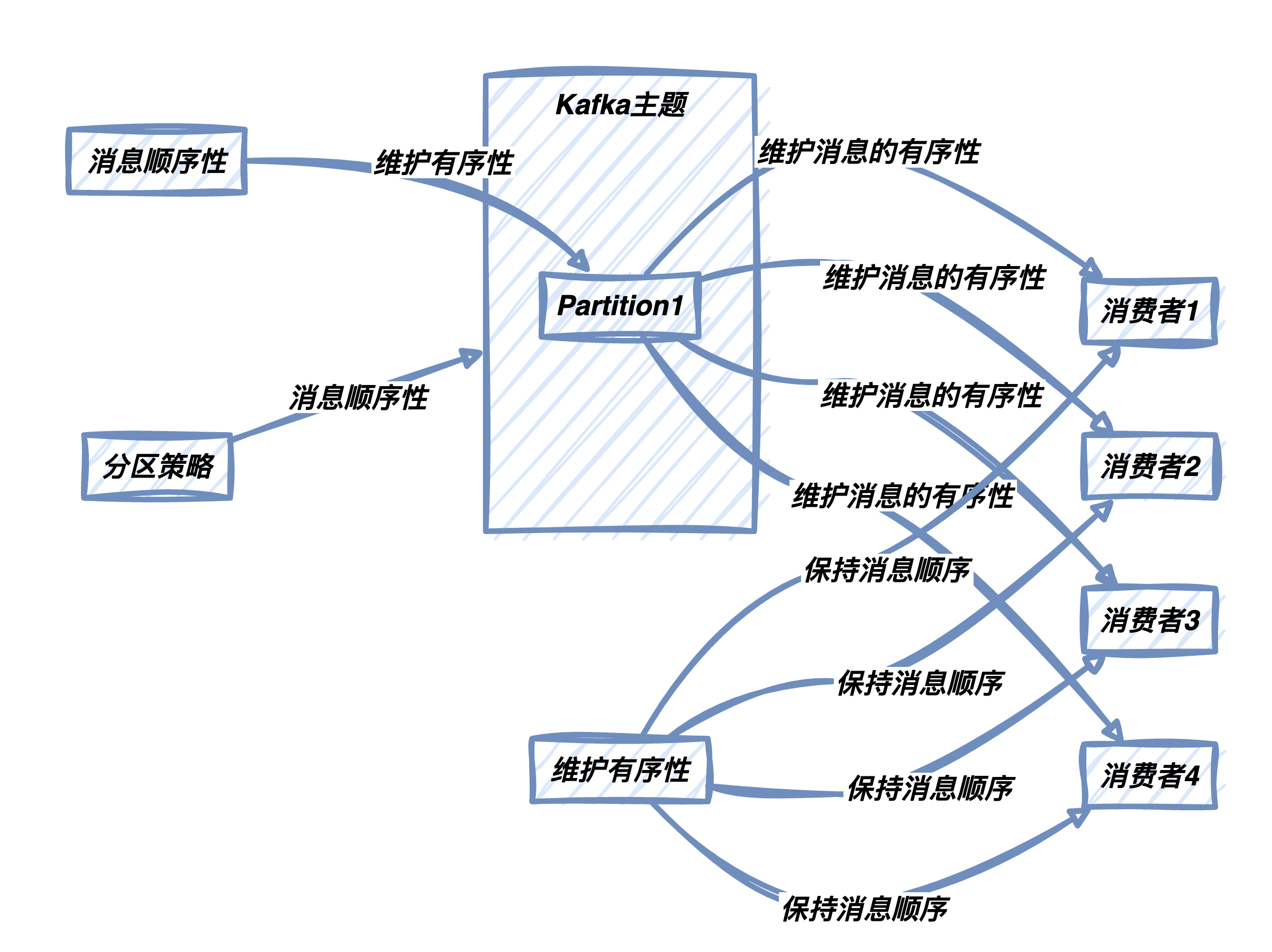
Kafka以其出色的消息顺序性而闻名。然而,分区策略可以影响消息的顺序性。下面介绍分区策略如何影响消息的顺序性,以及如何确保具有相同键的消息被写入到同一个分区,以维护消息的有序性。
保持消息的有序性对于某些应用程序至关重要。如果消息被分散写入到多个分区,它们可能会以不同的顺序被消费。要确保有序性,你可以考虑以下几种方法:
-
自定义分区策略:使用自定义分区策略,根据消息的键来选择分区。这将确保具有相同键的消息被写入到同一个分区,维护消息的有序性。
-
单一分区主题:对于需要维护强有序性的数据,可以考虑将它们写入单一分区的主题。这样,无论你使用什么分区策略,这些消息都将在同一个分区中。
-
监控消息顺序性:定期监控消息的顺序性,确保没有异常情况。使用Kafka提供的工具来检查消息的分区分布和顺序。
这些策略可以帮助你在高吞吐量的同时维护消息的顺序性,确保数据的正确性和一致性。
以上内容详细介绍了分区策略的性能考量,包括数据均衡、高吞吐量和顺序性。理解这些性能因素对于设计和优化Kafka应用程序至关重要。希望这些信息对你有所帮助。
五、示例:使用不同分区策略
在这一部分,我们将通过示例演示如何使用不同的分区策略来满足特定的需求。
我们将提供示例代码、输入数据、输出数据以及性能测试结果,以便更好地理解每种策略的应用和影响。
5.1 示例1:Round-Robin策略
背景:
假设你正在构建一个日志记录系统,需要将各种日志消息发送到Kafka以供进一步处理。在这种情况下,你可能对消息的分区不太关心,因为所有的日志消息都具有相似的重要性。这是Round-Robin策略可以派上用场的场景。
示例:
// 代码示例:创建一个使用Round-Robin策略的Kafka生产者
Properties props = new Properties();
props.put("bootstrap.servers", "localhost:9092");
props.put("key.serializer", "org.apache.kafka.common.serialization.StringSerializer");
props.put("value.serializer", "org.apache.kafka.common.serialization.StringSerializer");Producer<String, String> producer = new KafkaProducer<>(props);// 发送日志消息,分区策略为Round-Robin
producer.send(new ProducerRecord<>("logs-topic", "log-message-1"));
producer.send(new ProducerRecord<>("logs-topic", "log-message-2"));
producer.send(new ProducerRecord<>("logs-topic", "log-message-3"));producer.close();
输出:
- 日志消息1被写入分区1
- 日志消息2被写入分区2
- 日志消息3被写入分区3
性能测试:
Round-Robin策略通常表现出很好的吞吐量,因为它均匀地分配消息到不同的分区。
在这个示例中,吞吐量将取决于Kafka集群的性能和生产者的配置。
5.2 示例2:自定义分区策略
背景:
现在假设你正在构建一个电子商务平台,需要将用户生成的订单消息发送到Kafka进行处理。在这种情况下,订单消息的关键信息是订单ID,你希望具有相同订单ID的消息被写入到同一个分区,以维护订单消息的有序性。
示例:
// 代码示例:创建一个使用自定义分区策略的Kafka生产者
Properties props = new Properties();
props.put("bootstrap.servers", "localhost:9092");
props.put("key.serializer", "org.apache.kafka.common.serialization.StringSerializer");
props.put("value.serializer", "org.apache.kafka.common.serialization.StringSerializer");
props.put("partitioner.class", "com.example.OrderPartitioner");Producer<String, String> producer = new KafkaProducer<>(props);// 发送订单消息,使用自定义分区策略
producer.send(new ProducerRecord<>("orders-topic", "order-123", "order-message-1"));
producer.send(new ProducerRecord<>("orders-topic", "order-456", "order-message-2"));
producer.send(new ProducerRecord<>("orders-topic", "order-123", "order-message-3"));producer.close();
输出:
- 订单消息1被写入分区2
- 订单消息2被写入分区1
- 订单消息3被写入分区2
性能测试:
自定义分区策略通常在维护消息的有序性方面表现出色。吞吐量仍然取决于Kafka集群的性能和生产者的配置,但在这个示例中,重点是保持订单消息的顺序性。
这两个示例展示了不同分区策略的应用和性能表现。根据你的特定需求,你可以选择适当的分区策略以满足业务要求。
以上内容详细介绍了示例,包括Round-Robin策略和自定义分区策略的实际应用。示例代码和性能测试结果将有助于更好地理解这些策略的使用方式。
六、总结
在文章中,我们深入探讨了Kafka主题的分区策略,这是Kafka消息传递系统的核心组成部分。我们从基础知识入手,了解了分区策略的基本概念,为什么它重要,以及它如何影响Kafka集群的性能和数据的顺序性。
首先介绍了Kafka默认的分区策略,即Round-Robin策略,它将消息均匀分配到各个分区。
通过示例,我们展示了Round-Robin策略的应用场景和性能特点,然后,深入研究了如何编写自定义分区策略。我们提供了示例代码,演示了如何根据消息的键来选择分区,以满足特定需求。
我们还分享了一些建议,帮助你选择适当的分区策略,并进行性能测试和评估。在分区策略的性能考量中,讨论了数据均衡、高吞吐量和顺序性等关键因素。提供了性能优化的策略和示例代码,以帮助你优化分区策略的性能。
🏆哪吒多年工作总结:Java学习路线总结,搬砖工逆袭Java架构师。

相关文章:
解密Kafka主题的分区策略:提升实时数据处理的关键
目录 一、Kafka主题的分区策略概述1.1 什么是Kafka主题的分区策略?1.2 为什么分区策略重要? 二、Kafka默认分区策略2.1 Round-Robin分区策略 三、自定义分区策略3.1 编写自定义分区器3.2 最佳实践:如何选择分区策略 四、分区策略的性能考量4.…...

GPT5大剧第二季开启,Sam Altman 重掌 OpenAI CEO 大权
OpenAl 最新公告: Sam Altman 重掌 OpenAI CEO 大权,公司迎来新的初始董事会 Mira Murati 出任 CTO,Greg Brockman 再次成为总裁。来看看CEO Sam Altman和董事会主席 Bret Taylor的最新发言。 2023年11月29日 以下是 CEO Sam Altman和董事会主席 Bret Taylor 今天下…...
Selenium 连接到现有的 Google Chrome 示例
python 3.7 selenium 3.14.1 urllib3 1.26.8 Google Chrome 119.0.6045.160 (64位) chromedriver.exe 119.0.6045.105(win32) 1 Google Chrome 添加参数 "--remote-debugging-port9222" 2 测试效果(chromedriver.exe 要和 Google Chrome 版本…...

EI级 | Matlab实现TCN-BiLSTM-Multihead-Attention多头注意力机制多变量时间序列预测
EI级 | Matlab实现TCN-BiLSTM-Multihead-Attention多头注意力机制多变量时间序列预测 目录 EI级 | Matlab实现TCN-BiLSTM-Multihead-Attention多头注意力机制多变量时间序列预测预测效果基本介绍程序设计参考资料 预测效果 基本介绍 1.【EI级】Matlab实现TCN-BiLSTM-Multihead-…...
基于安卓的2048益智游戏的设计与实现
基于安卓的2048益智类游戏的设计与实现 摘要:现如今随着社会日新月异,人们越来越离不开智能手机所提供的灵活性与便携性。安卓系统是在这股手机发展迅猛的潮流中其市场占有率过半的手机平台,基于安卓系统的游戏开发有着不可估量的前景。 本论…...

解决Linux Visual Studio Code显示字体有问题/Liunx下Visual Studio Code更换字体
01、具体问题 在Linux下VsCode控制台与代码区显示异常,如下图所示: 代码显示 终端显示 02、解决方案 下载字体 [rootlocalhost mhzzj]$ cd /usr/share/fonts # 进入目录 [rootlocalhost fonts]$ sudo yum install git # 下载字体 [rootlocalhost fo…...
CityEngine2023 根据shp数据构建三维模型并导入UE5
目录 0 引言1 基本操作2 实践2.1 导入数据(.shp)2.2 构建三维模型2.3 将模型导入UE5 🙋♂️ 作者:海码007📜 专栏:CityEngine专栏💥 标题:CityEngine2023 根据shp数据构建三维模型…...

修复电脑中缺失的VCRUNTIME140.dll文件的5个有效方法
vcruntime140.dll丢失5个修复方法与vcruntime140.dll是什么以及丢失对电脑的影响 引言: 在日常使用电脑的过程中,我们可能会遇到一些错误提示,其中之一就是“vcruntime140.dll丢失”。那么,什么是vcruntime140.dll?它…...

什么是PDN的交流阻抗?
什么是PDN的交流阻抗? 在电力电子领域,PDN(Power Distribution Network)的交流阻抗是一个重要的概念,它反映了PDN在交流电源和负载之间传输电能的能力。了解PDN的交流阻抗对于优化电源设计、提高系统性能和可靠性具有重…...

FFmpeg之将视频转为16:9(横屏)或9:16(竖屏)(一)
简介: CSDN博客专家,专注Android/Linux系统,分享多mic语音方案、音视频、编解码等技术,与大家一起成长! 优质专栏:Audio工程师进阶系列【原创干货持续更新中……】🚀 优质专栏:多媒…...
Web安全漏洞分析-XSS(上)
随着互联网的迅猛发展,Web应用的普及程度也愈发广泛。然而,随之而来的是各种安全威胁的不断涌现,其中最为常见而危险的之一就是跨站脚本攻击(Cross-Site Scripting,简称XSS)。XSS攻击一直以来都是Web安全领…...
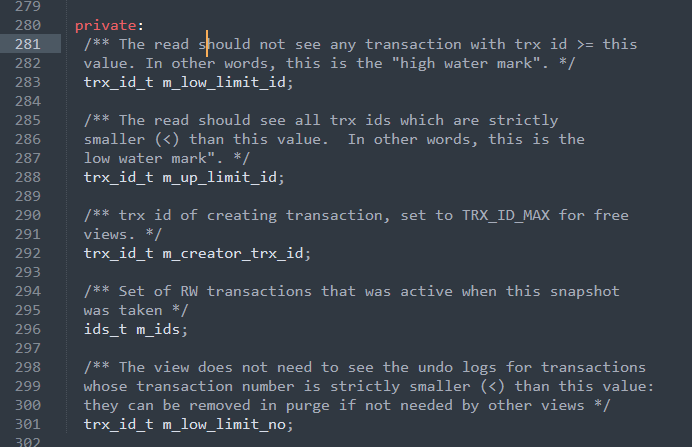
MVCC多版本并发控制相关面试题整理
多版本并发控制是一种用于支持并发事务的数据库管理系统技术,它允许多个事务同时访问数据库,而不会相互干扰或导致数据不一致。MVCC通过在数据库中维护不同版本的数据来实现这一目标,从而允许每个事务看到一致的数据库快照。 并发导致的问题…...

02-鸿蒙学习之4.0todoList练习
02-鸿蒙学习之4.0todoList练习 代码 /*** 1:组件必须使用Component装饰* 2.Entry 装饰哪个组件,哪个组件就呈现在页面上* 3.被Entry 装饰的入口组件。build()必须有且仅有一个根 ** 容器 ** 组件* 其他的自定义组件,build() 中…...

springsecurity5.7.x和springsecurity6.x配置文件对比
springsecurity5和springsecurity6如何要实现多种登录方式,自定义登录方式都是一样的操作步骤,主要有四个步骤。 一、自定义登录用户实体实现springsecurity中的UserDetails接口 二、自定义登录用户实现类实现springsecurity中的UserDetailsService接口 三、自定义登录用户au…...
brat文本标注工具——安装
目录 一、Linux系统安装 1. centOS系统 2. Ubuntu系统 3. macOS系统 4.说明 二、Google Chrome安装 1. 打开命令行,切换到管理者权限 2. 安装依赖 3. 下载Google浏览器的安装包 4. 安装Google Chrome 三、yum更新 四、Apache安装 安装Apache 启动Apac…...
麒麟操作系统网桥配置
网桥概念: Bridge 是 Linux 上用来做 TCP/IP 二层协议交换的设备,其功能可 以简单的理解为是一个二层交换机或者 Hub;多个网络设备可以连接 到同一个 Bridge,当某个设备收到数据包时,Bridge 会将数据转发 给其他设备。…...
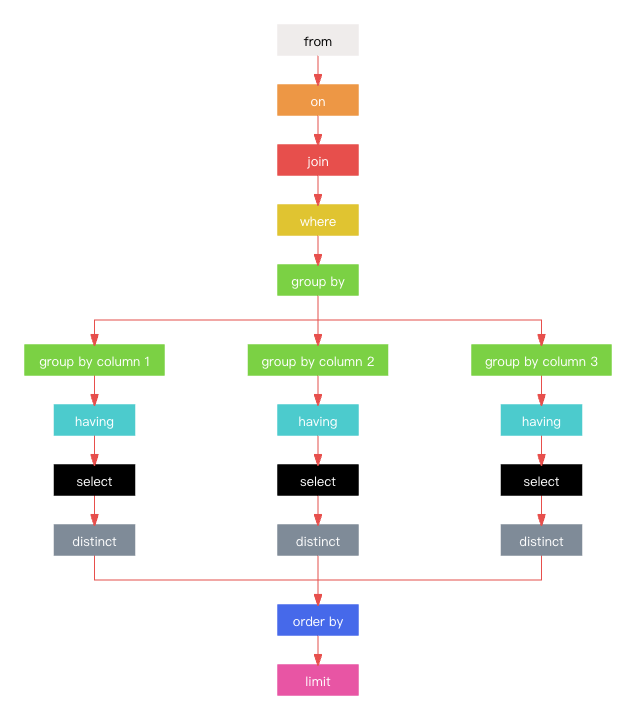
禁奥义·SQL秘籍
sql secret scripts sql 语法顺序、执行顺序、执行过程、要点解析、优化技巧。 1、语法顺序 如上图所示,为 sql 语法顺序与执行顺序对照图。其具体含义如下: 0、select: 用于从数据库中选取数据,即表示从数据库中查询到的数据的…...

浅谈用户体验测试的主要功能
用户体验(User Experience,简称UX)在现代软件和产品开发中变得愈发重要。为了确保产品能够满足用户期望,提高用户满意度,用户体验测试成为不可或缺的环节。本文将详细探讨用户体验测试的主要功能,以及它在产品开发过程中的重要性。…...

2021年6月3日 Go生态洞察:Fuzzing技术的Beta测试
🌷🍁 博主猫头虎(🐅🐾)带您 Go to New World✨🍁 🦄 博客首页——🐅🐾猫头虎的博客🎐 🐳 《面试题大全专栏》 🦕 文章图文…...

全新Self-RAG框架亮相,自适应检索增强助力超越ChatGPT与Llama2,提升事实性与引用准确性
全新Self-RAG框架亮相,自适应检索增强助力超越ChatGPT与Llama2,提升事实性与引用准确性 1. 基本思想 大型语言模型(LLMs)具有出色的能力,但由于完全依赖其内部的参数化知识,它们经常产生包含事实错误的回答,尤其在长尾知识中。 为了解决这一问题,之前的研究人员提出了…...

踩坑实录:Seatunnel同步Hive到StarRocks时,数据量翻倍和中文乱码怎么破?
Seatunnel数据同步实战:破解Hive到StarRocks的三大典型问题 在数据仓库迁移和ETL流程中,Seatunnel作为一款高效的数据同步工具,已经成为许多企业技术栈中的关键组件。但当我们将Hive数据同步到StarRocks时,往往会遇到一些令人头疼…...

从加密狗激活到平台注册:dSPACE MicroAutoBOX II 与 MATLAB 2016b 联调实战记录
从加密狗激活到平台注册:dSPACE MicroAutoBOX II 与 MATLAB 2016b 联调实战记录 在汽车电子控制单元(ECU)开发领域,dSPACE MicroAutoBOX II 作为一款实时硬件在环(HIL)测试平台,与 MATLAB/Simul…...

Linux操作系统安装图文配置教程详细版
随着嵌入式的发展,Linux的知识是必须的一部分,下面就让我们进行Linux系统的安装过程演示:一、 Linux的安装在此博客中以红旗(Red Flag)Asianux Workstation 3为例进行描述,其他版本的Linux与此相似。 1.1 安…...

AI赋能百业,从城市治理到智能家居,这些应用场景让你大开眼界!
文章深入探讨了人工智能在各个领域的创新应用,包括城市治理、医疗、金融、教育、交通出行、零售电商、制造、能源、农业、智能家居、娱乐传媒、文化旅游等。通过具体的案例和技术手段,展示了AI如何提升效率、优化决策、改善生活质量。例如,成…...

不会 CSS 也能做出惊艳 PPT!Frontend Slides这个开源 Claude Code 技能让 AI 帮你生成 12 种风格演示文稿,告别千篇一律的紫渐变
不会 CSS 也能做出惊艳 PPT!Frontend Slides这个开源 Claude Code 技能让 AI 帮你生成 12 种风格演示文稿,告别千篇一律的紫渐变 💡 每次做 PPT 都在 Powerpoint 里拖来拖去,最后做出来还是那个味儿?Frontend Slides 让…...

打造梦幻岛屿的5个秘诀:免费在线规划工具完整指南
打造梦幻岛屿的5个秘诀:免费在线规划工具完整指南 【免费下载链接】HappyIslandDesigner "Happy Island Designer (Alpha)",是一个在线工具,它允许用户设计和定制自己的岛屿。这个工具是受游戏《动物森友会》(Animal Crossing)启发…...

告别手动配IP!用STM32CubeMX快速实现LwIP DHCP客户端,连接路由器即插即用
告别手动配IP!用STM32CubeMX快速实现LwIP DHCP客户端 每次为嵌入式设备配置静态IP都像在玩一场"猜谜游戏"——子网掩码输错一位、网关地址填错,整个网络就瘫痪了。更糟的是,当设备需要部署到不同网络环境时,还得重新烧…...

树莓派Linux命令行实战指南:从基础操作到系统运维
1. 项目概述:为什么你需要一份树莓派命令手册如果你刚拿到一块树莓派,兴奋地接上电源和显示器,看着熟悉的桌面系统,感觉和一台迷你电脑没什么两样。但当你真正想用它做点“正经事”——比如让它24小时运行一个网站、自动备份文件到…...

LoRA微调、DINOv2视觉基础模型与CLIP驱动编辑实战指南
1. 项目概述:这不是一份新闻简报,而是一份AI领域从业者的“十月实战观测手记”2021年10月,AI圈没有爆炸性突破,但有一股沉潜的力量在积蓄——模型能力正从“能跑通”加速转向“敢落地”。我翻遍当月所有主流技术博客、会议预印本、…...

3分钟实现网页图片格式自由转换:Chrome扩展终极指南
3分钟实现网页图片格式自由转换:Chrome扩展终极指南 【免费下载链接】Save-Image-as-Type Save Image as Type is an chrome extension which add Save as PNG / JPG / WebP to the context menu of image. 项目地址: https://gitcode.com/gh_mirrors/sa/Save-Ima…...