禁奥义·SQL秘籍
sql secret scripts
sql 语法顺序、执行顺序、执行过程、要点解析、优化技巧。
1、语法顺序
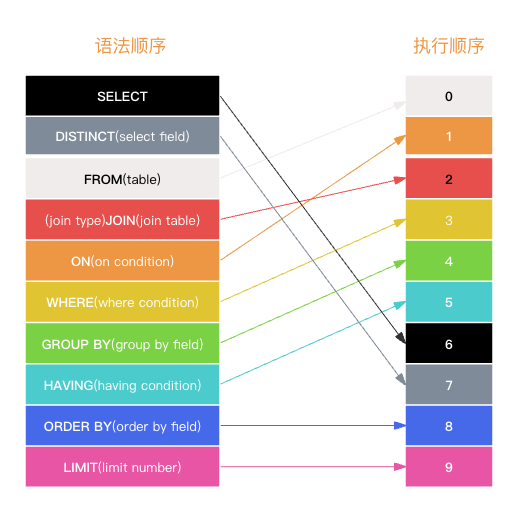
如上图所示,为 sql 语法顺序与执行顺序对照图。其具体含义如下:
- 0、select: 用于从数据库中选取数据,即表示从数据库中查询到的数据的列。其后可跟列名、函数、子查询等。
- 1、distinct: 用于对结果集进行去重,即若查询的数据中存在重复项,则可用其进行去重。其需要放在 select 后第一顺位,且其去重并不是对 select 后某个字段进行去重,而是对 select 后所有列进行去重。
- 2、from: 表示要查询的数据库表,即主表。其后跟表名、子查询等。
- 3、join: 表示要连接的表,及关联表。其后跟要连接表名、子查询等。
- 4、on: 表示主表与关联表的关联条件。
- 5、where: 表示查询条件。其后可跟普通条件、函数(普通函数)等。
- 6、group by: 表示分组,及将数据按照分组条件进行分组。其后跟要分组的列名。
- 7、having: 对分组结果进行筛选。其后跟普通条件、聚合函数等。
- 8、order by: 表示排序,及将结果集按照某种条件进行排序。其后跟要排序的列名及排序方式(升序、降序)。
- 9、limit: 表示最终结果集的大小,即查询结果集的大小将 <= limit 的值。其后跟数据集大小。
如上所述,则对于表 用户表 web_user(id, username, age, gender, address)、系统日志表 sys_log(id, user_id, operate_name, request_time, request_params),其查询 sql 可为:
# 某些数据库中 user 字符为关键字 故此 sql 中 user 别名呈关键字色
select distinct user.username, log.operate_name
from sys_log logleft join web_user useron log.user_id = user.id
where log.operate_name like '%列表%'
group by user.username, log.operate_name
having avg(log.request_time) > 100
order by user.username desc
limit 10
2、执行顺序
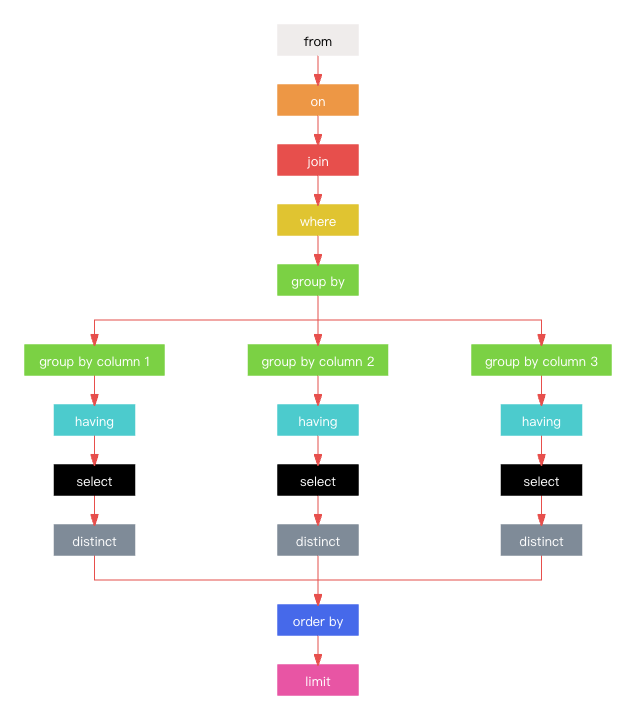
如上图所示,为 sql 实际执行顺序。在 sql 的实际执行过程中,每个步骤都会产生一个虚拟表,这个虚拟表将作为下一步的基础数据。其具体含义如下:
- 0、from: 选择要查询的基表(即主表),产生虚拟表 1。
- 1、on: 连接查询(join)时主表与关联表的关联条件。将关联条件匹配到的行记录在虚拟表 2。
- 2、join: 选择要关联的表。若为 left/right join,则将主表中关联条件为匹配到的行添加到虚拟表 2,产生虚拟表 3。若有多个关联表,则重复执行 0~2 步,直到所有关联表都处理完。
- 3、where: 使用过滤条件对虚拟表 3 进行过滤,将符合条件的行插入到虚拟表 4。
- 4、group by: 根据 group by 指定的列,对虚拟表 4 进行分组,产生虚拟表 5。
- 5、having: 根据 having 指定的过滤条件对 虚拟表 5 中的每一组记录进行过滤,将符合条件的的行插入到虚拟表 6。
- 6、select: 从虚拟表 6 中取出 select 指定的列的记录插入到虚拟表 7。
- 7、distinct: 将虚拟表 7 中重复的行删除(记录的唯一性),产生虚拟表 8。
- 8、order by: 对虚拟表 8 中的记录按照 order by 指定的列及指定的排序方式进行排序。
- 9、limit: 取出指定行数的记录,返回结果集。
3、要点解析
-
distinct: 其作用是对记录进行去重,去重时不是根据 distinct 后的某个字段去重,而是根据其后的所有字段去重,即可以理解为其后所有字段构成的唯一主键。一般而言,distinct 是 group by 子句的特殊情况,若对 distinct 结果集进行排序则可得到 group by 同样的结果。同时,distinct 会讲 null 值当作一条记录返回。
当想要根据某个或某几个字段去重,同时又要查出其它字段时,则可以结合 group by 来实现,如想根据 username 去重,同时查询出 id,则其 sql 可为:
# 此方案不适配 mysql select id, count(distinct username) from sys_log group by username; -
join: 关联查询,分为四种类型,分别是:
- inner join:内连接,即左右两个表中至少匹配到一条记录则返回。
- left join:左连接,即使右表(关联表)中没有匹配到行,也返回左表(主表)中的所有行。
- right join:右连接,即使左表(关联表)中没有匹配到行,也返回右表(主表)中的所有行。
- full join:全连接,只要有一个表中匹配到行,则返回。
join 时要注意 on 条件,on 条件作为左右两表的关联条件,直接决定了后续 where 时的数据量,所以尽可能的在 on 中筛选掉无用数据。若无 on 条件则会出现笛卡尔积现象。
-
where: where 条件中只能使用普通条件(如 and、or、in 等)和普通函数(ucase()、lcase()、mid()、substring()、len()、round()、now()、format() 等),不能使用聚合函数(avg()、max()、min()、count()、first()、last()、sum() 等)。
-
not、and、or: 逻辑运算符。
- and:若 and 前后两个条件都成立,则 and 运算符显示一条记录。
- or:若 or 前后两个条件只要一个成立,则 or 运算符显示一条记录。
- not:表示非。
逻辑运算符使用需要注意优先级,其优先级为 ( )、not、and、or。所以必要时需使用 ( ) 来确保 and 和 or 条件的先后顺序。
-
between: between 的使用需要注意上下限,而其上下限由不同数据库的实现决定。如:
- 在某些数据库中,between 选取介于两个值之间但不包括两个值的数据。
- 在某些数据库中,between 选取介于两个值之间且包括两个值的数据。
- 在某些数据库中,between 选取介于两个值之间但只包括第一个值不包括第二个值的数据。
-
group by: group by 表示分组,其规定 group by 后跟的列需和 select distinct 后跟的列保持一致,若此时还需要查出其它字段,则可以使用 rank() over (parition by) 关键字实现。
rank() over (partition by):其中 rank() 是排序函数,其会对结果集排序并产生一个序号;partition by 为分组,若无指定则所有结果集默认一个组。如想按 operate_name 分组,同时又想查出 username、operate_name 列,则 sql 可为:
# order by 是为了对 partition by 分组结果进行排序,所以 order by 列尽可能使用 id 这种差异性极强的列来排序(如唯一索引) # 只有排序后每条记录的 rankNo 值都不同,才能根据 rankNo = 1 取到唯一的一条记录 select * from (select username, operate_name, rank() over (partition by operate_name order by id) rankNo from sys_log) as temp where temp.rankNo = 1 -
having: 对分组后的结果进行筛选,其后只能跟普通条件和聚合函数(avg()、max()、min()、count()、first()、last()、sum() 等)。
-
order by: order by 表示排序,需要注意多字段排序的情况。如 order by a, b,先根据字段 a 的值排序,然后对 a 列相同的行再根据字段 b 的值排序。
-
union: union 用来合并两个或多个 select 的结果集。需注意,使用 union 时,多个 select 语句必须拥有相同数量的列,且列的数据类型需保持一致,select 列的先后顺序也要保持一致。
-
limit: limit 语句用来截取指定条数的结果集,一般用在分页中,如以下 sql:
select * from sys_log where operate_name = '列表' limit 1000000, 10其含义为查询出第 1000000 行及之后的 9 行,但在实际执行中会发现耗时较长。这是因为数据库也不知道第 1000000 行从什么地方开始,因此需要先找到第 1000000 行,然后再取出 10 条。此时则可以将上一页的最大值作为查询条件传入,则 sql 如下:
# 假设上一页最后一条数据的 create_time 值为 2023-11-30 22:25:00 select * from sys_log where operate_name = '列表' and create_time > '2023-11-30 22:25:00' limit 10此时会发现,耗时将大大减小。
相关文章:
禁奥义·SQL秘籍
sql secret scripts sql 语法顺序、执行顺序、执行过程、要点解析、优化技巧。 1、语法顺序 如上图所示,为 sql 语法顺序与执行顺序对照图。其具体含义如下: 0、select: 用于从数据库中选取数据,即表示从数据库中查询到的数据的…...

浅谈用户体验测试的主要功能
用户体验(User Experience,简称UX)在现代软件和产品开发中变得愈发重要。为了确保产品能够满足用户期望,提高用户满意度,用户体验测试成为不可或缺的环节。本文将详细探讨用户体验测试的主要功能,以及它在产品开发过程中的重要性。…...

2021年6月3日 Go生态洞察:Fuzzing技术的Beta测试
🌷🍁 博主猫头虎(🐅🐾)带您 Go to New World✨🍁 🦄 博客首页——🐅🐾猫头虎的博客🎐 🐳 《面试题大全专栏》 🦕 文章图文…...

全新Self-RAG框架亮相,自适应检索增强助力超越ChatGPT与Llama2,提升事实性与引用准确性
全新Self-RAG框架亮相,自适应检索增强助力超越ChatGPT与Llama2,提升事实性与引用准确性 1. 基本思想 大型语言模型(LLMs)具有出色的能力,但由于完全依赖其内部的参数化知识,它们经常产生包含事实错误的回答,尤其在长尾知识中。 为了解决这一问题,之前的研究人员提出了…...

句子相似度计算
文章目录 https://huggingface.co/sentence-transformers/all-MiniLM-L6-v2 这里使用预训练的 nreimers/MiniLM-L6-H384-uncased 模型,并在 1B 句对数据集上微调。 如果你使用 sentence-transformers pip install -U sentence-transformers可以这样使用模型 impor…...
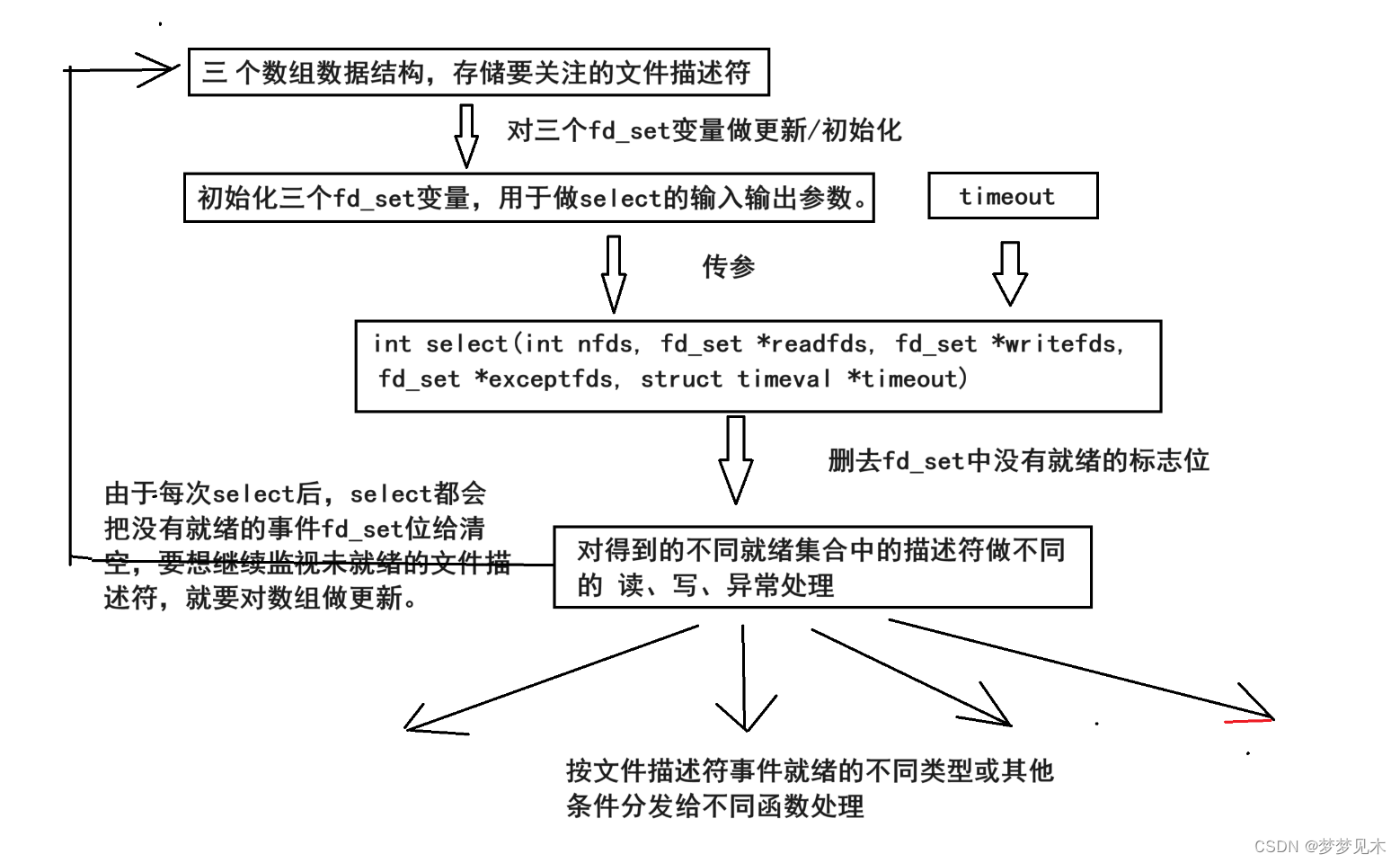
高级IO select 多路转接实现思路
文章目录 select 函数fd_set 类型timeval 结构体select 函数的基本使用流程文件描述符就绪条件以select函数为中心实现多路转接的思路select 缺陷 select 函数 int select(int nfds, fd_set *readfds, fd_set *writefds, fd_set *exceptfds, struct timeval *timeout); selec…...

C++学不会?一篇文章带你快速入门
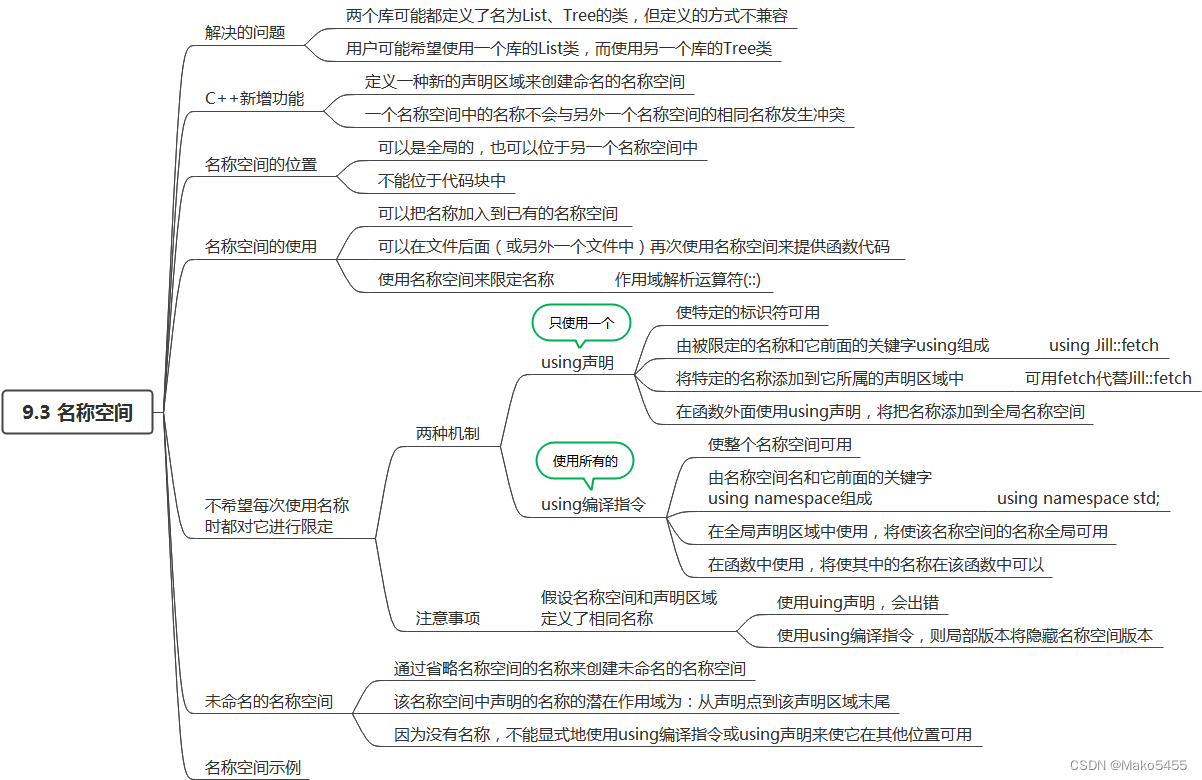
1. 命名空间 1.1 命名空间的概念 C命名空间是一种用于避免名称冲突的机制。它允许在多个文件中定义相同的函数、类或变量,而不会相互干扰。 1.2 命名空间的定义 namespace是命名空间的关键字,后面是命名空间的名字,然后后面一对 {},{}中即…...

【加密相册】 隐私协议
【加密相册】隐私协议 1.个人信息的收集和使用 我们的应用程序不会收集用户的个人信息,包括姓名、地址、电子邮件地址、电话号码等。我们不会追踪用户的位置信息或共享用户的个人信息。 2. 非个人化信息的收集和使用 我们的应用程序可能会收集一些非个人化信息&a…...

超越基础:释放 Systemd 的全部潜力【systemd 二】
🎏:你只管努力,剩下的交给时间 🏠 :小破站 超越基础:释放 Systemd 的全部潜力【systemd 二】 前言第一:系统服务高级管理高级服务配置:环境变量设置:服务单元文件的高级选…...
Flask学习二:项目拆分、请求与响应、cookie
教程 教程地址: 千锋教育Flask2框架从入门到精通,Python全栈开发必备教程 老师讲的很好,可以看一下。 项目拆分 项目结构 在项目根目录下,创建一个App目录,这是项目下的一个应用,应该类似于后端的微服…...
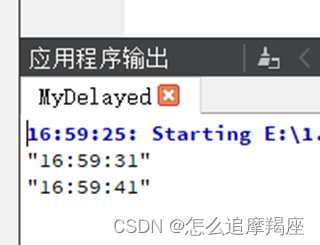
6、Qt延时的使用
一、sleep() 1、说明 QThread类中如下三个静态函数: QThread::sleep(n); //延迟n秒 QThread::msleep(n); //延迟n毫秒 QThread::usleep(n); //延迟n微妙 这种方式使用简单,但是会阻塞线程,有界面时界面会卡死,一般在非GUI线…...

《Effective C++》条款26
尽可能延后变量定义式的出现时间 string test(const string& passwd) {string s;if (s.size() < MinLenth){throw logic_error("passwd is too short");} } 这段代码的问题是:如果抛出了异常,那么定义的string对象将面临毫无意义的构造…...
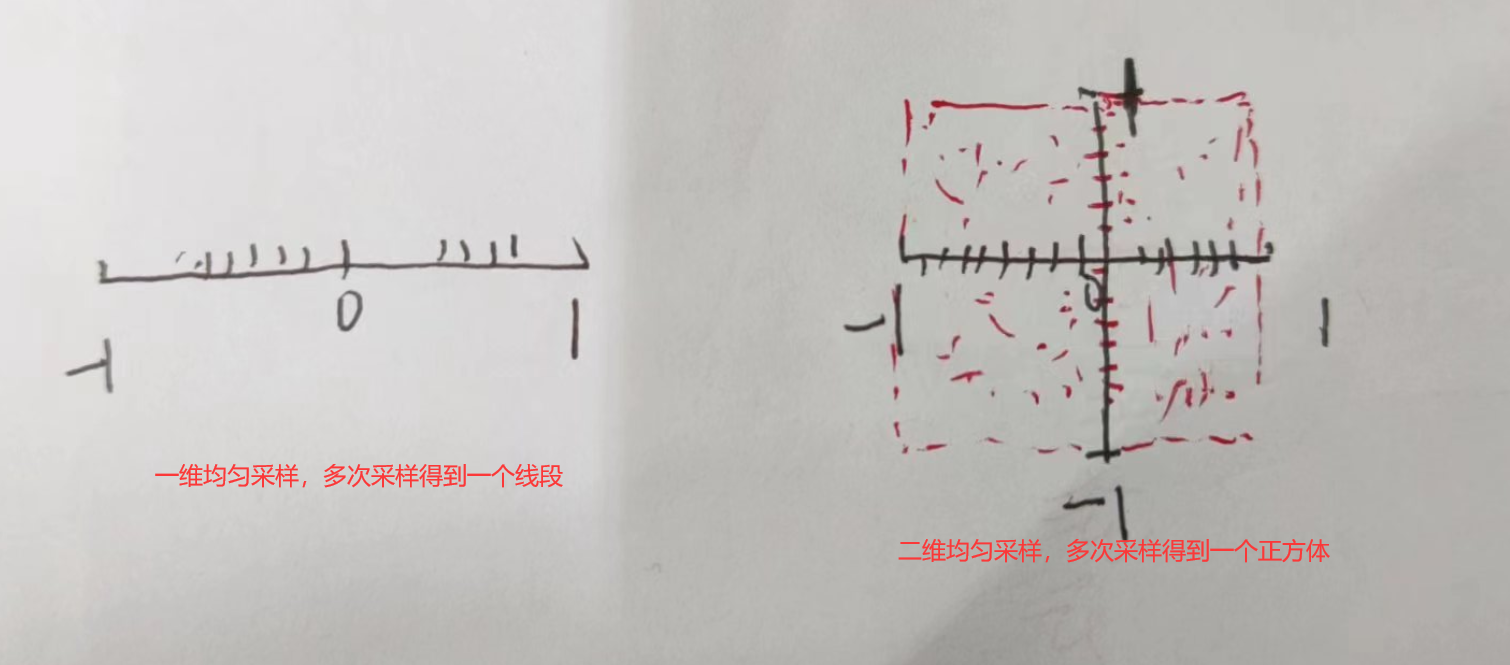
np.random.uniform() 采样得到的是一个高维立方体,而不是球体,为什么?
在代码中,采样是通过以下方式完成的: samples self.center np.random.uniform(-self.radius, self.radius, (num_samples, len(self.center))) 这里,np.random.uniform函数在每个维度独立地生成了一个介于-self.radius和self.radius之间的…...
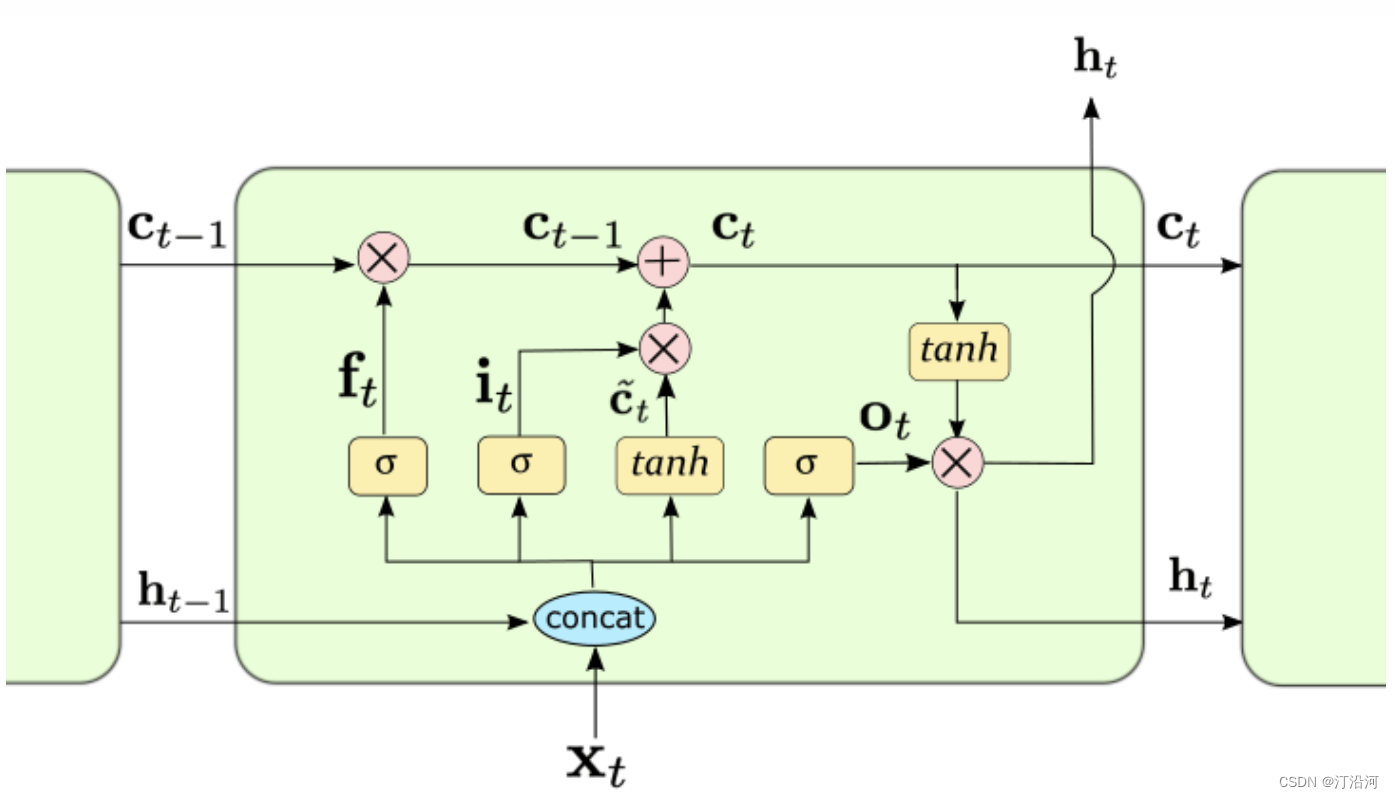
1 时间序列模型入门: LSTM
0 前言 循环神经网络(Recurrent Neural Network,RNN)是一种用于处理序列数据的神经网络。相比一般的神经网络来说,他能够处理序列变化的数据。比如某个单词的意思会因为上文提到的内容不同而有不同的含义,RNN就能够很好…...

1-Python与设计模式--单例模式
23种计模式之 前言 (5)单例模式、工厂模式、简单工厂模式、抽象工厂模式、建造者模式、原型模式、(7)代理模式、装饰器模式、适配器模式、门面模式、组合模式、享元模式、桥梁模式、(11)策略模式、责任链模式、命令模式、中介者模…...

Rust之构建命令行程序(一):接受命令行参数
开发环境 Windows 10Rust 1.73.0 VS Code 1.84.2 项目工程 这次创建了新的工程minigrep. IO工程:构建命令行程序 这一章回顾了到目前为止你所学的许多技能,并探索了一些更标准的库特性。我们将构建一个与文件和命令行输入/输出交互的命令行工具&#…...

Go 谈论了解Go语言
一、引言 Go的历史回顾 Go语言(通常被称为Go或Golang)由Robert Griesemer、Rob Pike和Ken Thompson在2007年开始设计,并于2009年正式公开发布。这三位设计者都曾在贝尔实验室工作,拥有丰富的编程语言和操作系统研究经验。Go的诞生…...
《C++PrimerPlus》第9章 内存模型和名称空间
9.1 单独编译 Visual Studio中新建头文件和源代码 通过解决方案资源管理器,如图所示: 分成三部分的程序(直角坐标转换为极坐标) 头文件coordin.h #ifndef __COORDIN_H__ // 如果没有被定义过 #define __COORDIN_H__struct pola…...
uniapp上架app store详细攻略
目录 uniapp上架app store详细攻略 前言 一、登录苹果开发者网站 二、创建好APP 前言 uniapp开发多端应用,打包ios应用后,会生成一个ipa后缀的文件。这个文件无法直接安装在iphone上,需要将这个ipa文件上架app store后,才能通…...

面试:线上问题处理
文章目录 在处理线上问题时,你的排查思路和步骤是什么线上偶发性问题如何处理和跟踪当系统出现大量错误日志时,你会如何分析和解决问题在高并发场景中,如何排查和解决线程安全问题当系统出现大规模的故障时,你的应急处理和恢复策略…...

5分钟彻底掌握Windows驱动管理:DriverStore Explorer完全指南
5分钟彻底掌握Windows驱动管理:DriverStore Explorer完全指南 【免费下载链接】DriverStoreExplorer Driver Store Explorer 项目地址: https://gitcode.com/gh_mirrors/dr/DriverStoreExplorer 你是否发现Windows系统盘空间持续减少,却找不到原因…...

85%企业将淘汰纯业务程序员!2026年前,大模型才是你的职业救命稻草!
文章指出传统技术岗面临淘汰风险,85%企业计划在2026年前淘汰纯业务型程序员。未来职场核心竞争力在于掌握大模型技术。文章强调大模型技术是技术人的时代红利,提供从入门到精通的全套视频教程,涵盖提示词工程、RAG、Agent等技术点。文章还分析…...

对比直连与通过Taotoken调用大模型API的延迟体感差异
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 对比直连与通过Taotoken调用大模型API的延迟体感差异 在集成大模型API到应用时,开发者通常会关注请求的响应速度&#…...

【收藏干货】2026 版 11 款主流 AI Agent 框架全方位对比!程序员小白入门大模型必备选型指南
本篇整合当下热度顶尖的 11 款 AI Agent 开发框架,囊括 LangChain、AutoGen、CrewAI 等主流工具,新版补充实战落地要点与行业最新应用方向。围绕各框架核心特性、优缺点、适配场景展开深度比对,依托大语言模型搭建智能自主系统,可…...

代数拓扑运算流程
文章目录0、背景一、标准计算流程:以单纯同调为例空间剖分,构建单纯复形生成各维度链群定义边界算子定义闭链群与边缘链群计算同调群并解读拓扑信息推导最终拓扑结论二、其他核心概念的典型计算逻辑0、背景 之前为了做一个东西学习TDA&…...

LeetDown深度解析:如何让iPhone 5s/6等老设备重返iOS 10.3.3黄金时代
LeetDown深度解析:如何让iPhone 5s/6等老设备重返iOS 10.3.3黄金时代 【免费下载链接】LeetDown a macOS app that downgrades A6 and A7 iDevices to OTA signed firmwares 项目地址: https://gitcode.com/gh_mirrors/le/LeetDown 还记得iPhone 5s的Touch I…...

机器学习核函数原理与实战选型指南
1. 什么是机器学习中的核函数?它到底在解决什么问题?“Types of Kernels in Machine Learning”这个标题看起来像教科书目录里的一节,但如果你真在项目里调过SVM(kernelrbf)、用过sklearn.metrics.pairwise.rbf_kernel、或者被kernel trick这…...

如何快速入门Play框架:5分钟搭建你的第一个Java Web应用
如何快速入门Play框架:5分钟搭建你的第一个Java Web应用 【免费下载链接】play1 Play framework 项目地址: https://gitcode.com/gh_mirrors/pl/play1 Play框架是一个轻量级的Java Web开发框架,它采用了MVC架构模式,提供了快速开发、热…...

taotoken token plan套餐详解如何节省大模型调用成本
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 Taotoken Token Plan 套餐详解:如何节省大模型调用成本 对于频繁使用大模型 API 的企业开发者或个人用户而言ÿ…...

如何用OneMore插件彻底改变你的OneNote笔记体验:终极效率提升指南
如何用OneMore插件彻底改变你的OneNote笔记体验:终极效率提升指南 【免费下载链接】OneMore A OneNote add-in with simple, yet powerful and useful features 项目地址: https://gitcode.com/gh_mirrors/on/OneMore 你是否曾经在OneNote中花费大量时间调整…...