1 时间序列模型入门: LSTM
0 前言
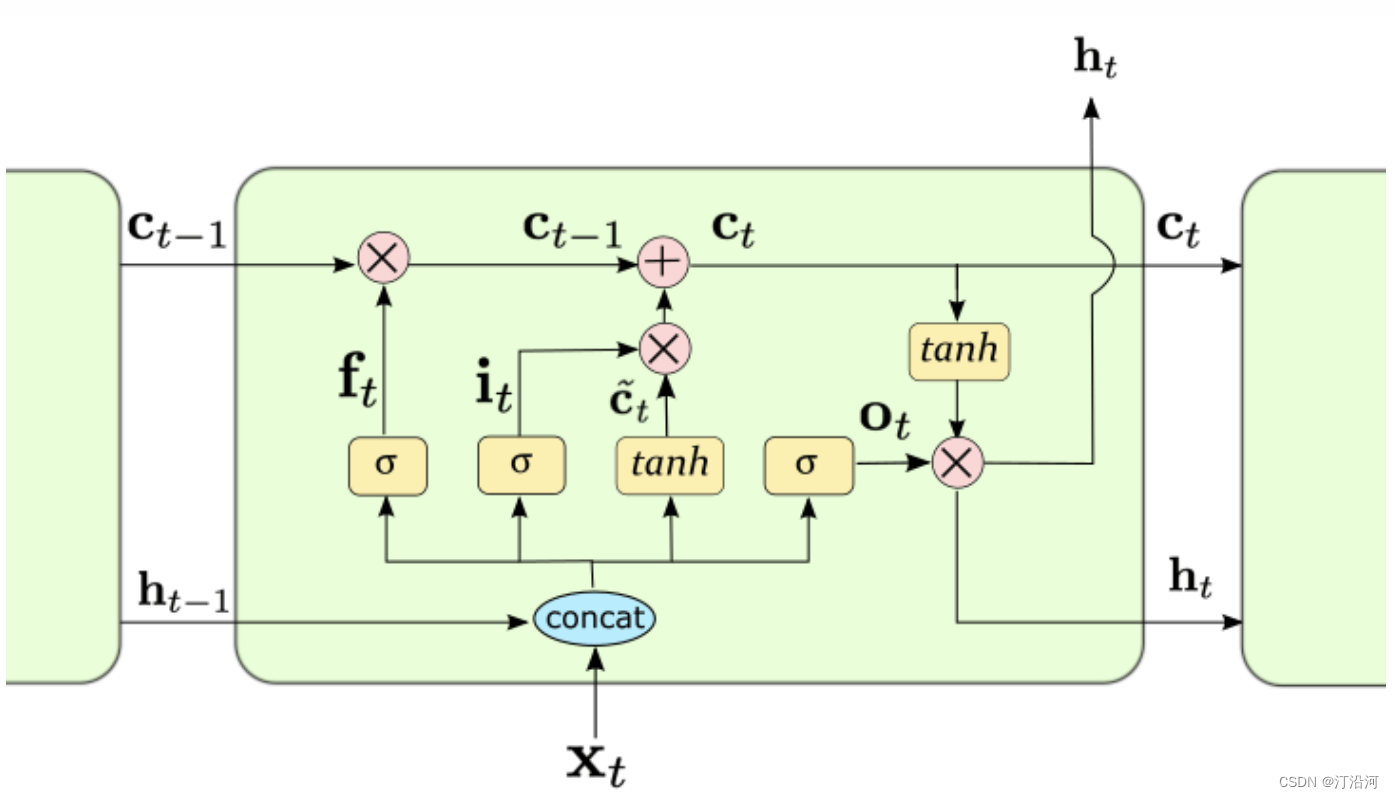
循环神经网络(Recurrent Neural Network,RNN)是一种用于处理序列数据的神经网络。相比一般的神经网络来说,他能够处理序列变化的数据。比如某个单词的意思会因为上文提到的内容不同而有不同的含义,RNN就能够很好地解决这类问题。本质是一个全连接网络,但是因为当前时刻受历史时刻的影响。
传统的RNN结构可以看做是多个重复的神经元构成的“回路”,每个神经元都接受输入信息并产生输出,然后将输出再次作为下一个神经元的输入,依次传递下去。这种结构能够在序列数据上学习短时依赖关系,但是由于梯度消失和梯度爆炸问题(梯度反向求导链式法则导致),RNN在处理长序列时难以达到很好的性能。而LSTM通过引入记忆细胞、输入门、输出门和遗忘门的概念(加号的引入),能够有效地解决长序列问题。记忆细胞负责保存重要信息,输入门决定要不要将当前输入信息写入记忆细胞,遗忘门决定要不要遗忘记忆细胞中的信息,输出门决定要不要将记忆细胞的信息作为当前的输出。这些门的控制能够有效地捕捉序列中重要的长时间依赖性,并且能够解决梯度问题。
备注:
输入门:输入的数据有多大程度进入模型;
输出门:控制当前时刻的内部状态 c有多少信息需要输出给外部状态;
遗忘门:控制上一个时刻的内部状态, ct−1需要遗忘多少信息;
nn.LSTM(input_size=embed_dim, hidden_size=hidden_size, num_layers=num_layers, batch_first=True)
embed_dim:每个输入元素的特征维度
hidden_size:隐状态的特征维度,根据工程经验可取 hidden_size = embed_dim * 2
num_layers: LSTM 的层数,一般设置为 1-4 层;
output, (hn, cn) = lstm(input)
input shape = (batch_size, times_stamp, embed_dim)
output = (batch_size, times_stamp, hidden_size)
output:表示隐藏层在各个 time step 上计算并输出的隐状态
hn 表示所有隐藏层的在最后一个 time step 隐状态,
cn 表示句子的最后一个单词的细胞状态;
1 模块介绍
数据: 2023“SEED”第四届江苏大数据开发与应用大赛--新能源赛道的数据
MARS开发者生态社区
解题思路: 总共500个充电站状, 关联地理位置,然后提取18个特征;把这18个特征作为时步不长(记得是某个比赛的思路)然后特征长度为1 (类比词向量的size).
y = LSTM(x,h0,c0)
import numpy as np
import pandas as pd
import torch
import torch.nn as nn
#import tushare as ts
from sklearn.preprocessing import StandardScaler, MinMaxScaler
from sklearn.model_selection import train_test_split
from torch.utils.data import TensorDataset
from tqdm import tqdmimport matplotlib.pyplot as plt
import tqdm
import sys
import os
import gc
import argparse
import warningswarnings.filterwarnings('ignore')# 读取数据
train_power_forecast_history = pd.read_csv('../data/data1/train/power_forecast_history.csv')
train_power = pd.read_csv('../data/data1/train/power.csv')
train_stub_info = pd.read_csv('../data/data1/train/stub_info.csv')test_power_forecast_history = pd.read_csv('../data/data1/test/power_forecast_history.csv')
test_stub_info = pd.read_csv('../data/data1/test/stub_info.csv')# 聚合数据
train_df = train_power_forecast_history.groupby(['id_encode','ds']).head(1)
del train_df['hour']test_df = test_power_forecast_history.groupby(['id_encode','ds']).head(1)
del test_df['hour']tmp_df = train_power.groupby(['id_encode','ds'])['power'].sum()
tmp_df.columns = ['id_encode','ds','power']# 合并充电量数据
train_df = train_df.merge(tmp_df, on=['id_encode','ds'], how='left')### 合并数据
train_df = train_df.merge(train_stub_info, on='id_encode', how='left')
test_df = test_df.merge(test_stub_info, on='id_encode', how='left')h3_code = pd.read_csv("../data/h3_lon_lat.csv")
train_df = train_df.merge(h3_code,on='h3')
test_df = test_df.merge(h3_code,on='h3')def kalman_filter(data, q=0.0001, r=0.01):# 后验初始值x0 = data[0] # 令第一个估计值,为当前值p0 = 1.0# 存结果的列表x = [x0]for z in data[1:]: # kalman 滤波实时计算,只要知道当前值z就能计算出估计值(后验值)x0# 先验值x1_minus = x0 # X(k|k-1) = AX(k-1|k-1) + BU(k) + W(k), A=1,BU(k) = 0p1_minus = p0 + q # P(k|k-1) = AP(k-1|k-1)A' + Q(k), A=1# 更新K和后验值k1 = p1_minus / (p1_minus + r) # Kg(k)=P(k|k-1)H'/[HP(k|k-1)H' + R], H=1x0 = x1_minus + k1 * (z - x1_minus) # X(k|k) = X(k|k-1) + Kg(k)[Z(k) - HX(k|k-1)], H=1p0 = (1 - k1) * p1_minus # P(k|k) = (1 - Kg(k)H)P(k|k-1), H=1x.append(x0) # 由输入的当前值z 得到估计值x0存入列表中,并开始循环到下一个值return x#kalman_filter()
train_df['new_label'] = 0
for i in range(500):#print(i)label = i#train_df[train_df['id_encode']==labe]['power'].valuestrain_df.loc[train_df['id_encode']==label, 'new_label'] = kalman_filter(data=train_df[train_df['id_encode']==label]['power'].values)### 数据预处理
train_df['flag'] = train_df['flag'].map({'A':0,'B':1})
test_df['flag'] = test_df['flag'].map({'A':0,'B':1})def get_time_feature(df, col):df_copy = df.copy()prefix = col + "_"df_copy['new_'+col] = df_copy[col].astype(str)col = 'new_'+coldf_copy[col] = pd.to_datetime(df_copy[col], format='%Y%m%d')#df_copy[prefix + 'year'] = df_copy[col].dt.yeardf_copy[prefix + 'month'] = df_copy[col].dt.monthdf_copy[prefix + 'day'] = df_copy[col].dt.day# df_copy[prefix + 'weekofyear'] = df_copy[col].dt.weekofyeardf_copy[prefix + 'dayofweek'] = df_copy[col].dt.dayofweek# df_copy[prefix + 'is_wknd'] = df_copy[col].dt.dayofweek // 6df_copy[prefix + 'quarter'] = df_copy[col].dt.quarter# df_copy[prefix + 'is_month_start'] = df_copy[col].dt.is_month_start.astype(int)# df_copy[prefix + 'is_month_end'] = df_copy[col].dt.is_month_end.astype(int)del df_copy[col]return df_copytrain_df = get_time_feature(train_df, 'ds')
test_df = get_time_feature(test_df, 'ds')train_df = train_df.fillna(999)
test_df = test_df.fillna(999)cols = [f for f in train_df.columns if f not in ['ds','power','h3','new_label']]# 是否进行归一化
scaler = MinMaxScaler(feature_range=(0,1))
scalar_falg = False
if scalar_falg == True:df_for_training_scaled = scaler.fit_transform(train_df[cols])df_for_testing_scaled= scaler.transform(test_df[cols])
else:df_for_training_scaled = train_df[cols]df_for_testing_scaled = test_df[cols]
#df_for_training_scaled
# scaler_label = MinMaxScaler(feature_range=(0,1))
# label_for_training_scaled = scaler_label.fit_transform(train_df['new_label']..values)
# label_for_testing_scaled= scaler_label.transform(train_df['new_label'].values)
# #df_for_training_scaledclass Config():data_path = '../data/data1/train/power.csv'timestep = 18 # 时间步长,就是利用多少时间窗口batch_size = 32 # 批次大小feature_size = 1 # 每个步长对应的特征数量,这里只使用1维,每天的风速hidden_size = 256 # 隐层大小output_size = 1 # 由于是单输出任务,最终输出层大小为1,预测未来1天风速num_layers = 2 # lstm的层数epochs = 10 # 迭代轮数best_loss = 0 # 记录损失learning_rate = 0.00003 # 学习率model_name = 'lstm' # 模型名称save_path = './{}.pth'.format(model_name) # 最优模型保存路径config = Config()
x_train, x_test, y_train, y_test = train_test_split(df_for_training_scaled.values, train_df['new_label'].values,shuffle=False, test_size=0.2)# 将数据转为tensor
x_train_tensor = torch.from_numpy(x_train.reshape(-1,config.timestep,1)).to(torch.float32)
y_train_tensor = torch.from_numpy(y_train.reshape(-1,1)).to(torch.float32)
x_test_tensor = torch.from_numpy(x_test.reshape(-1,config.timestep,1)).to(torch.float32)
y_test_tensor = torch.from_numpy(y_test.reshape(-1,1)).to(torch.float32)# 5.形成训练数据集
train_data = TensorDataset(x_train_tensor, y_train_tensor)
test_data = TensorDataset(x_test_tensor, y_test_tensor)# 6.将数据加载成迭代器
train_loader = torch.utils.data.DataLoader(train_data,config.batch_size,False)test_loader = torch.utils.data.DataLoader(test_data,config.batch_size,False)#train_df[cols]
# 7.定义LSTM网络
class LSTM(nn.Module):def __init__(self, feature_size, hidden_size, num_layers, output_size):super(LSTM, self).__init__()self.hidden_size = hidden_size # 隐层大小self.num_layers = num_layers # lstm层数# feature_size为特征维度,就是每个时间点对应的特征数量,这里为1self.lstm = nn.LSTM(feature_size, hidden_size, num_layers, batch_first=True)self.fc = nn.Linear(hidden_size, output_size)def forward(self, x, hidden=None):#print(x.shape)batch_size = x.shape[0] # 获取批次大小 batch, time_stamp , feat_size# 初始化隐层状态if hidden is None:h_0 = x.data.new(self.num_layers, batch_size, self.hidden_size).fill_(0).float()c_0 = x.data.new(self.num_layers, batch_size, self.hidden_size).fill_(0).float()else:h_0, c_0 = hidden# LSTM运算output, (h_0, c_0) = self.lstm(x, (h_0, c_0))# 全连接层output = self.fc(output) # 形状为batch_size * timestep, 1# 我们只需要返回最后一个时间片的数据即可return output[:, -1, :]
model = LSTM(config.feature_size, config.hidden_size, config.num_layers, config.output_size) # 定义LSTM网络loss_function = nn.L1Loss() # 定义损失函数
optimizer = torch.optim.AdamW(model.parameters(), lr=config.learning_rate) # 定义优化器# 8.模型训练
for epoch in range(config.epochs):model.train()running_loss = 0train_bar = tqdm(train_loader) # 形成进度条for data in train_bar:x_train, y_train = data # 解包迭代器中的X和Yoptimizer.zero_grad()y_train_pred = model(x_train)loss = loss_function(y_train_pred, y_train.reshape(-1, 1))loss.backward()optimizer.step()running_loss += loss.item()train_bar.desc = "train epoch[{}/{}] loss:{:.3f}".format(epoch + 1,config.epochs,loss)# 模型验证model.eval()test_loss = 0with torch.no_grad():test_bar = tqdm(test_loader)for data in test_bar:x_test, y_test = datay_test_pred = model(x_test)test_loss = loss_function(y_test_pred, y_test.reshape(-1, 1))if test_loss < config.best_loss:config.best_loss = test_losstorch.save(model.state_dict(), save_path)print('Finished Training')train epoch[1/10] loss:293.638: 100%|███████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 3727/3727 [01:41<00:00, 36.84it/s] 100%|█████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 932/932 [00:12<00:00, 73.96it/s] train epoch[2/10] loss:272.386: 100%|███████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 3727/3727 [01:49<00:00, 33.90it/s] 100%|█████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 932/932 [00:12<00:00, 77.56it/s] train epoch[3/10] loss:252.972: 100%|███████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 3727/3727 [01:43<00:00, 35.91it/s] 100%|█████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 932/932 [00:13<00:00, 70.65it/s] train epoch[4/10] loss:235.282: 100%|███████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 3727/3727 [01:45<00:00, 35.27it/s] 100%|█████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 932/932 [00:09<00:00, 93.71it/s] train epoch[5/10] loss:219.069: 100%|███████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 3727/3727 [01:34<00:00, 39.57it/s] 100%|████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 932/932 [00:08<00:00, 103.92it/s] train epoch[6/10] loss:203.969: 100%|███████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 3727/3727 [01:30<00:00, 41.22it/s] 100%|█████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 932/932 [00:09<00:00, 95.62it/s] train epoch[7/10] loss:189.877: 100%|███████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 3727/3727 [01:35<00:00, 39.19it/s] 100%|█████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 932/932 [00:12<00:00, 77.61it/s] train epoch[8/10] loss:176.701: 100%|███████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 3727/3727 [01:52<00:00, 33.12it/s] 100%|█████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 932/932 [00:11<00:00, 81.34it/s] train epoch[9/10] loss:164.382: 100%|███████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 3727/3727 [01:41<00:00, 36.64it/s] 100%|████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 932/932 [00:08<00:00, 112.27it/s] train epoch[10/10] loss:152.841: 100%|██████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 3727/3727 [01:25<00:00, 43.40it/s] 100%|█████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 932/932 [00:09<00:00, 94.54it/s]
相关文章:
1 时间序列模型入门: LSTM
0 前言 循环神经网络(Recurrent Neural Network,RNN)是一种用于处理序列数据的神经网络。相比一般的神经网络来说,他能够处理序列变化的数据。比如某个单词的意思会因为上文提到的内容不同而有不同的含义,RNN就能够很好…...

1-Python与设计模式--单例模式
23种计模式之 前言 (5)单例模式、工厂模式、简单工厂模式、抽象工厂模式、建造者模式、原型模式、(7)代理模式、装饰器模式、适配器模式、门面模式、组合模式、享元模式、桥梁模式、(11)策略模式、责任链模式、命令模式、中介者模…...

Rust之构建命令行程序(一):接受命令行参数
开发环境 Windows 10Rust 1.73.0 VS Code 1.84.2 项目工程 这次创建了新的工程minigrep. IO工程:构建命令行程序 这一章回顾了到目前为止你所学的许多技能,并探索了一些更标准的库特性。我们将构建一个与文件和命令行输入/输出交互的命令行工具&#…...

Go 谈论了解Go语言
一、引言 Go的历史回顾 Go语言(通常被称为Go或Golang)由Robert Griesemer、Rob Pike和Ken Thompson在2007年开始设计,并于2009年正式公开发布。这三位设计者都曾在贝尔实验室工作,拥有丰富的编程语言和操作系统研究经验。Go的诞生…...
《C++PrimerPlus》第9章 内存模型和名称空间
9.1 单独编译 Visual Studio中新建头文件和源代码 通过解决方案资源管理器,如图所示: 分成三部分的程序(直角坐标转换为极坐标) 头文件coordin.h #ifndef __COORDIN_H__ // 如果没有被定义过 #define __COORDIN_H__struct pola…...
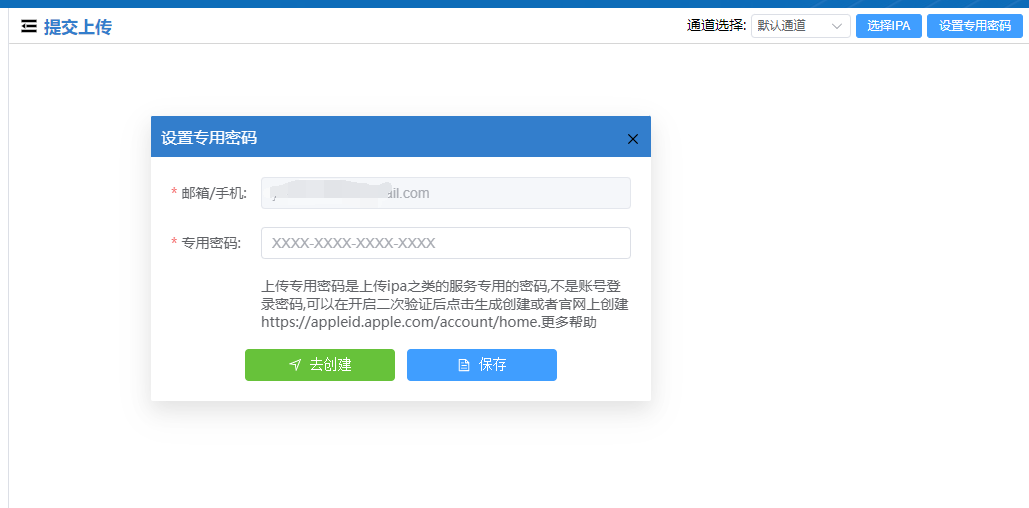
uniapp上架app store详细攻略
目录 uniapp上架app store详细攻略 前言 一、登录苹果开发者网站 二、创建好APP 前言 uniapp开发多端应用,打包ios应用后,会生成一个ipa后缀的文件。这个文件无法直接安装在iphone上,需要将这个ipa文件上架app store后,才能通…...

面试:线上问题处理
文章目录 在处理线上问题时,你的排查思路和步骤是什么线上偶发性问题如何处理和跟踪当系统出现大量错误日志时,你会如何分析和解决问题在高并发场景中,如何排查和解决线程安全问题当系统出现大规模的故障时,你的应急处理和恢复策略…...

Vue3中快速Diff算法
在Vue3中,快速Diff算法主要用于优化虚拟DOM的更新过程,减少不必要的DOM操作,提高性能。以下是对Vue3源码中快速Diff算法的解读: 首先,我们需要引入Vue3的相关包: import { reactive, toRefs, watch } fro…...

ROS2+STM32小车红外对射光电计数器模块资料
数据:一个周长内有20个孔洞或者20个分隔。外径:6.8cm 图片不是实物图,是示意图 因为没有串口,所以不可能会发送出数字的,就是通过电压变化次数来计算距离或者其他数据 有遮挡时,输出高电平,无遮…...
Android设计模式--桥接模式
闻正言,行正道,左右前后皆正人 一,定义 将抽象部分与实现部分分离,使它们都可以独立地进行变化 二,使用场景 从模式的定义中,我们大致可以了解到,这里的桥接的作用其实就是连接抽象部分与实现…...
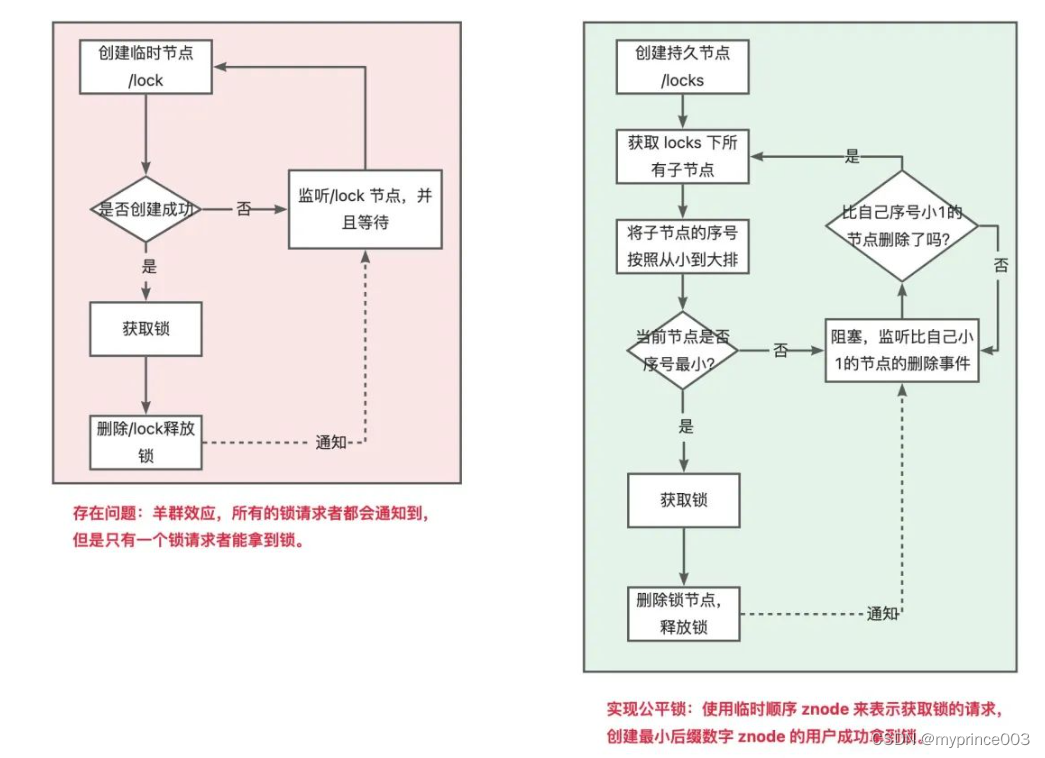
1、分布式锁实现原理与最佳实践(一)
在单体的应用开发场景中涉及并发同步时,大家往往采用Synchronized(同步)或同一个JVM内Lock机制来解决多线程间的同步问题。而在分布式集群工作的开发场景中,就需要一种更加高级的锁机制来处理跨机器的进程之间的数据同步问题&…...

Autosar通信实战系列03-NM模块要点及其配置介绍
本文框架 前言1. NM模块要点介绍1.1 NM基本功能介绍1.2 NM协同功能介绍2. NM配置2.1 NmGlobalConfig配置2.2 NmChannelConfigs配置前言 在本系列笔者将结合工作中对通信实战部分的应用经验进一步介绍常用,包括但不限于通信各模块的开发教程,代码逻辑分析,调测试方法及典型问…...

Golang模块管理功能
文章目录 1. Golang 包管理1.1 GOPATH 包管理1.2 Go vendor 包管理1.3 Go modules包管理2. Go Modules 应用实践2.1 Go modules关键信息2.1.1 go mod 命令行2.1.2 配置代理服务2.2 创建项目2.3 获取依赖包2.4 运行项目1. Golang 包管理 1.1 GOPATH 包管理 第一阶段: Golang初…...
从零构建属于自己的GPT系列1:文本数据预处理、文本数据tokenizer、逐行代码解读
🚩🚩🚩Hugging Face 实战系列 总目录 有任何问题欢迎在下面留言 本篇文章的代码运行界面均在PyCharm中进行 本篇文章配套的代码资源已经上传 从零构建属于自己的GPT系列1:文本数据预处理 从零构建属于自己的GPT系列2:语…...

scipy 笔记:scipy.spatial.distance
1 pdist 计算n维空间中观测点之间的成对距离。 scipy.spatial.distance.pdist(X, metriceuclidean, *, outNone, **kwargs) 1.1 主要参数 X一个m行n列的数组,表示n维空间中的m个原始观测点metric使用的距离度量out输出数组。如果非空,压缩的距离矩阵…...

java video audio encoder
引言 在现代互联网的时代,视频和音频已经成为人们生活中不可或缺的一部分。而在计算机科学中,视频和音频编码器则是将原始的视频和音频数据转换为可压缩格式的关键技术。在本文中,我们将探讨基于Java的视频和音频编码器的使用。 什么是视频…...

TypeScript 中声明类型的方法
1、使用:运算符来为变量和函数参数指定类型。例如: let num: number 5; function add(a: number, b: number): number {return a b; }2、使用 type 关键字来声明自定义类型别名。例如: type Point {x: number;y: number; };3、使用 interface 关键字…...
显示器校准软件BetterDisplay Pro mac中文版介绍
BetterDisplay Pro mac是一款显示器校准软件,可以帮助用户调整显示器的颜色和亮度,以获得更加真实、清晰和舒适的视觉体验。 BetterDisplay Pro mac软件特点 - 显示器校准:可以根据不同的需求和环境条件调整显示器的颜色、亮度和对比度等参数…...

Element UI 走马灯 实现鼠标滚动切换页面
鼠标滚动切换页面 elementui Carousel 走马灯鼠标滚轮事件实现 一、在轮播图外的盒子外添加鼠标滚轮事件,触发GoWheel函数。 wheel"goWheel"二、通过判断deltaY的数值来触发相应事件 它检查滚轮事件的deltaY属性是否大于0 event.deltaY当鼠标滚轮向下…...

在Docker上部署Springboot项目
在Docker上部署Springboot项目 ###1.安装docker 2.安装mysql 拉 Mysql 镜像 docker pull mysql:5.7.31运行 Mysql 5.7.31 第一次运行需要设置密码 docker run -d --name myMysql -p 9506:3306 -v /data/mysql:/var/lib/mysql -e MYSQL_ROOT_PASSWORD1234 mysql:5.7.31不是…...

Meta裁了8000人,员工拖着行李箱抢可乐
昨天凌晨4点,Meta很多员工的邮箱同时响了。是裁员邮件。这一次,Meta裁掉了全球约10%的员工,规模大约8000人。分手大礼包:16周基础薪资 每满1年工龄额外2周薪资 18个月全家医保。真正让硅谷炸锅的,反而是裁员前几天&a…...

【收藏 2026 版】程序员零基础转 AI 应用赛道!不用深耕算法训练,靠现有编程功底轻松转行
当下 AI 技术全面普及,传统开发岗位竞争日趋激烈,不少程序员都想顺势切入人工智能领域。很多人觉得入行 AI 就得钻研复杂算法、上手大模型训练,门槛高到难以触碰。实则 2026 年 AI 应用开发门槛大幅降低,拥有基础编程能力…...

DeepSeek技术搜索RAG Pipeline重构实录:从模糊匹配到精准意图识别的6次AB测试数据全公开
更多请点击: https://kaifayun.com 第一章:DeepSeek技术搜索RAG Pipeline重构实录:从模糊匹配到精准意图识别的6次AB测试数据全公开 在DeepSeek内部技术文档搜索系统升级中,我们对原有RAG Pipeline进行了深度重构,核心…...

Unity低耦合可复用交互系统设计与实现
1. 为什么“交互系统”在Unity项目里总变成一锅粥?你有没有遇到过这样的场景:美术同事改了个按钮位置,UI脚本里硬编码的transform.Find("Button")就报空引用;策划临时加个新交互逻辑,程序员得翻遍PlayerCont…...

加拿大AI治理实战:风险分级、监管沙盒与可信AI工程化落地
1. 项目概述:这不是一场技术秀,而是一场制度设计的实战演练“Canada’s AI Ambitions: Navigating the Future of AI Governance”——这个标题里没有一行代码,不提一个模型参数,却直指当前全球AI发展最棘手、最易被忽视的底层命题…...

HS2-HF Patch终极指南:一键解锁完整汉化与去码体验
HS2-HF Patch终极指南:一键解锁完整汉化与去码体验 【免费下载链接】HS2-HF_Patch Automatically translate, uncensor and update HoneySelect2! 项目地址: https://gitcode.com/gh_mirrors/hs/HS2-HF_Patch 还在为《Honey Select 2》的语言障碍和功能限制而…...

2026降AI率工具红黑榜:AI智能降重工具怎么选?用数据说话!
红榜优先选千笔AI、ThouPen、豆包,适配国内高校AI率检测规范;黑榜避开低质免费降AI工具、无正规检测对接、改写痕迹生硬的工具,优先按需求匹配三维模型(降AI效果-学术合规性-使用成本)。 一、红榜:10 款高分…...
漏洞原理与漏洞复现(基于vulhub))
log4j2(CVE-2021-44228)漏洞原理与漏洞复现(基于vulhub)
声明:部分内容来源于网络,如若侵权请联系删除 什么是log4j2? Log for Java,Apache的开源日志记录组件,是一个Java的日志记录工具。在log4j框架的基础上进行了改进,并引入了丰富的特性,可以控制日志信息输送…...

别让‘单电源供电’坑了你:运放参考电压旁路电容的选型与避坑全攻略
别让‘单电源供电’坑了你:运放参考电压旁路电容的选型与避坑全攻略 在单电源供电的运算放大器电路中,参考电压的稳定性往往决定了整个系统的性能。许多工程师习惯性地在Vcc/2分压点添加旁路电容,却不知这个看似合理的操作可能引发灾难性振荡…...
)
别再死记公式了!用Multisim仿真带你直观理解星三角变换(Y-Δ)
用Multisim仿真破解星三角变换:从公式恐惧到电路直觉 记得第一次在实验室里面对三相电路板时,那些密密麻麻的接线和闪烁的指示灯让我完全摸不着头脑。教授在黑板上写满Y-Δ变换公式时,我的笔记本上只留下了一堆问号——直到我发现仿真软件这…...