从零构建属于自己的GPT系列1:文本数据预处理、文本数据tokenizer、逐行代码解读
🚩🚩🚩Hugging Face 实战系列 总目录
有任何问题欢迎在下面留言
本篇文章的代码运行界面均在PyCharm中进行
本篇文章配套的代码资源已经上传
从零构建属于自己的GPT系列1:文本数据预处理
从零构建属于自己的GPT系列2:语言模型训练
0 任务基本流程
- 拿到txt文本数据,本文以15本金庸小说为例
- CpmTokenizer预训练模型将所有文本处理成.pkl的token文件
- 配置训练参数
- token数据转化为索引
- 导入GPT2LMHeadModel预训练中文模型,训练文本数据
- 训练结束得到个人文本数据特征的新模型
- 搭载简易网页界面,部署本地模型
- text-to-text专属GPT搭建完成
- 获取新数据,模型更加个性化
- 优化模型,一次性读取更长文本,生成更长的结果
1 训练数据
在本任务的训练数据中,我选择了金庸的15本小说,全部都是txt文件
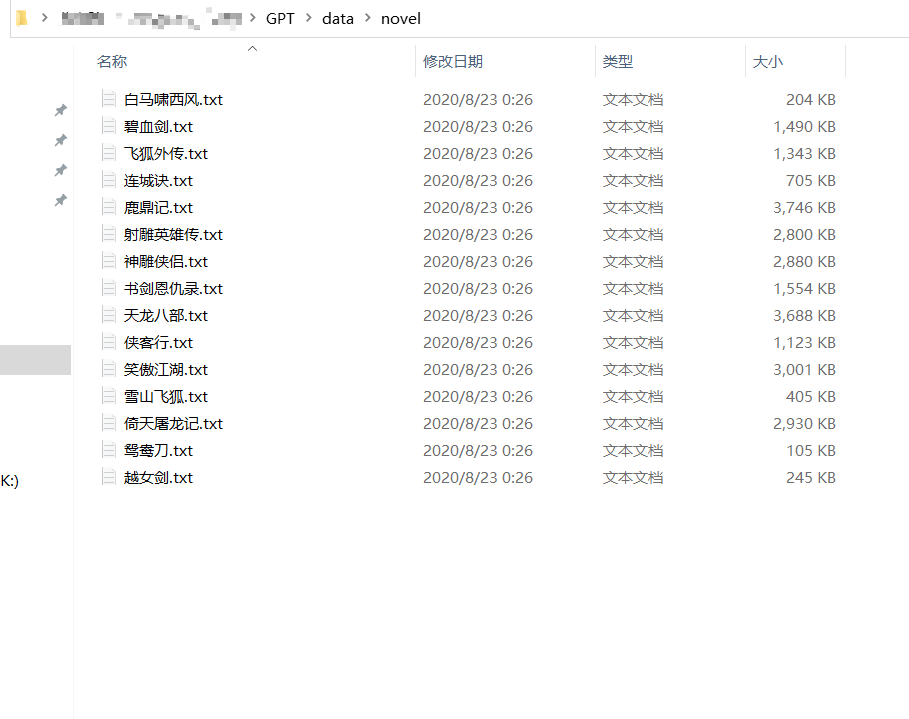
数据打开后的样子
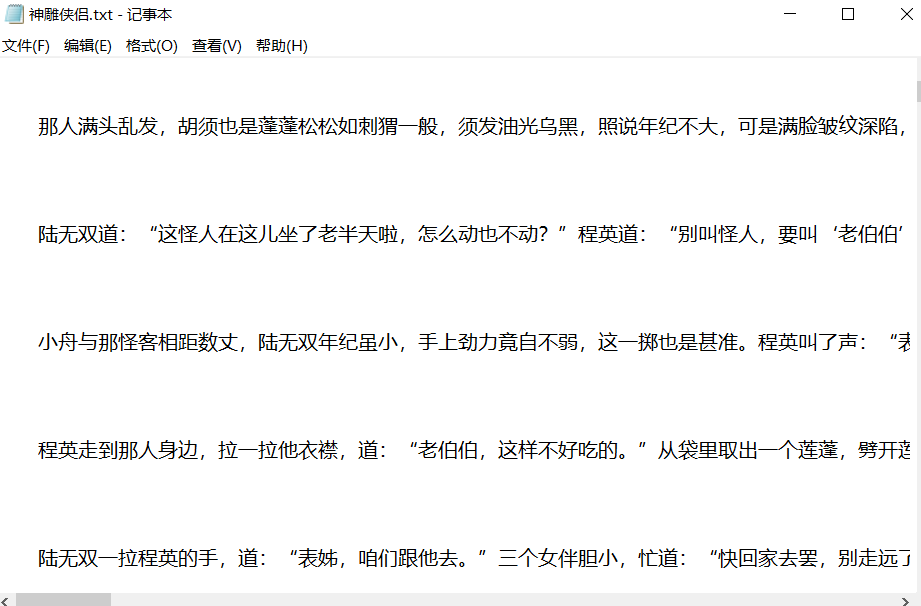
数据预处理需要做的事情就是使用huggingface的transformers包的tokenizer模块,将文本转化为token
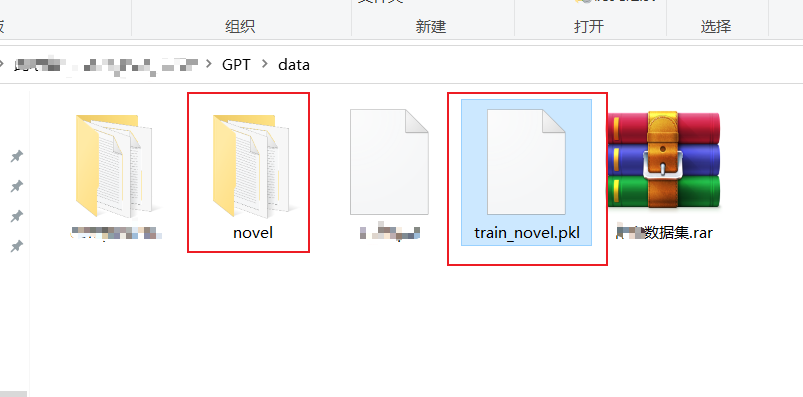
最后生成的文件就是train_novel.pkl文件,就不用在训练的时候读txt文件了
数据预处理:preprocess.py
2 设置参数
import argparse
from utils import set_logger
from transformers import CpmTokenizer
import os
import pickle
from tqdm import tqdm
parser = argparse.ArgumentParser()
parser.add_argument('--vocab_file', default='vocab/chinese_vocab.model', type=str, required=False,help='词表路径')
parser.add_argument('--log_path', default='log/preprocess.log', type=str, required=False, help='日志存放位置')
parser.add_argument('--data_path', default='data/novel', type=str, required=False, help='数据集存放位置')
parser.add_argument('--save_path', default='data/train.pkl', type=str, required=False,help='对训练数据集进行tokenize之后的数据存放位置')
parser.add_argument('--win_size', default=200, type=int, required=False,help='滑动窗口的大小,相当于每条数据的最大长度')
parser.add_argument('--step', default=200, type=int, required=False, help='滑动窗口的滑动步幅')
args = parser.parse_args()
- 参数包
- 本项目utils.py中初始化参数函数
- chinese pre-trained model Tokenizer包
- 系统包
- pickle包,用于将 python 对象序列化(serialization)为字节流,或者将字节流反序列化为 Python 对象
- 进度条包
- 创建一个用于解析命令行参数的 ArgumentParser 对象
- 处理中文文本的变成token的预训练模型的模型文件存放位置
- 运行日志文件存放位置
- 数据集存放位置
- 对训练数据集进行tokenize之后的数据存放位置
- 滑动窗口的大小,相当于每条数据的最大长度
- 滑动窗口的滑动步幅
3 初始化日志对象
logger = set_logger(args.log_path)
def set_logger(log_path):logger = logging.getLogger(__name__)logger.setLevel(logging.INFO)formatter = logging.Formatter('%(asctime)s - %(levelname)s - %(message)s')file_handler = logging.FileHandler(filename=log_path)file_handler.setFormatter(formatter)file_handler.setLevel(logging.INFO)logger.addHandler(file_handler)console = logging.StreamHandler()console.setLevel(logging.DEBUG)console.setFormatter(formatter)logger.addHandler(console)return logger
- 选择日志路径,调用日志函数
- 创建 logger 对象
- 设置日志级别为’logging.INFO’
- 创建格式化器 formatter
- 创建文件处理器file_handler并指定了日志文件的路径为log_path
- 设置处理器的日志级别为 logging.INFO
- 添加文件处理器 file_handler 到创建的 logger 对象中
- 创建控制台处理器 console,用 logging.StreamHandler() 创建一个将日志输出到控制台的处理器
- 设置其日志级别为 logging.DEBUG
- 将格式化器 formatter 应用到这个控制台处理器上
- 控制台处理器 console 添加到 logger 对象中
- 返回了这个配置好的 logger 对象
4 初始化
logger = set_logger(args.log_path)
tokenizer = CpmTokenizer(vocab_file="vocab/chinese_vocab.model") # pip install jieba
eod_id = tokenizer.convert_tokens_to_ids("<eod>") # 文档结束符
sep_id = tokenizer.sep_token_id
train_list = []
logger.info("start tokenizing data")
- 初始化日志
- 创建CPMTokenizer 对象,用于分词和处理中文文本
- tokenizer 将特殊标记 转换为其对应的 ID
- 获取分词器中分隔符的 ID
- 最后处理的数据
- 打印
5 处理数据
for file in tqdm(os.listdir(args.data_path)):file = os.path.join(args.data_path, file)with open(file, "r", encoding="utf8") as reader:lines = reader.readlines()for i in range(len(lines)):if lines[i].isspace() != True and lines[i] != '\n':token_ids = tokenizer.encode(lines[i].strip(), add_special_tokens=False) + [eod_id]if i % 1000 == 0:print('cur_step', i, lines[i].strip())else:continuewin_size = args.win_sizestep = args.stepstart_index = 0end_index = win_sizedata = token_ids[start_index:end_index]train_list.append(data)start_index += stepend_index += stepwhile end_index + 50 < len(token_ids): # 剩下的数据长度,大于或等于50,才加入训练数据集data = token_ids[start_index:end_index]train_list.append(data)start_index += stepend_index += step# 序列化训练数据
with open(args.save_path, "wb") as f:pickle.dump(train_list, f)
os.listdir(args.data_path):得到该路径下所有文件的文件名字符串并返回一个字符串数组,for file in tqdm的for循环会打印读取进度的进度条- 获得当前文件的完整路径
- 按照
file路径、utf-8编码格式、只读模式打开文件 - 按行来读取文件,line在这里是一个list,list每个数据都对于文件的一行数据
- 按照行数遍历读取文件数据
- 判断当前行是否为空行,或者这行只有换行
- 使用tokenizer进行encode,加入结束索引
- 每1000行进行一次打印操作
- 每1000行进行一次打印操作
- 空行不处理
- 空行不处理
- 滑动窗口长度
- 滑动次数
- 第一个文件的第i行的第一条数据的开始索引
- 第一个文件的第i行的第一条数据的结束索引
- 第一个文件的第i行的第一条数据
- 添加第一条数据到总数据中
- while循环取数据,最后一条数据不足50时就不要了,逐个取数据直到换行,注意这里一行数据可能是一段哦,不一定有逗号或者句号就会换行
- 第一个文件的第i行的第k条数据
- 添加第k条数据到总数据中
- 按照滑动次数更新开始索引
- 按照滑动次数更新结束索引
- 最后所有的数据都保存在了train_list中
- 保存为pickle文件
从零构建属于自己的GPT系列1:文本数据预处理
从零构建属于自己的GPT系列2:语言模型训练
相关文章:
从零构建属于自己的GPT系列1:文本数据预处理、文本数据tokenizer、逐行代码解读
🚩🚩🚩Hugging Face 实战系列 总目录 有任何问题欢迎在下面留言 本篇文章的代码运行界面均在PyCharm中进行 本篇文章配套的代码资源已经上传 从零构建属于自己的GPT系列1:文本数据预处理 从零构建属于自己的GPT系列2:语…...

scipy 笔记:scipy.spatial.distance
1 pdist 计算n维空间中观测点之间的成对距离。 scipy.spatial.distance.pdist(X, metriceuclidean, *, outNone, **kwargs) 1.1 主要参数 X一个m行n列的数组,表示n维空间中的m个原始观测点metric使用的距离度量out输出数组。如果非空,压缩的距离矩阵…...

java video audio encoder
引言 在现代互联网的时代,视频和音频已经成为人们生活中不可或缺的一部分。而在计算机科学中,视频和音频编码器则是将原始的视频和音频数据转换为可压缩格式的关键技术。在本文中,我们将探讨基于Java的视频和音频编码器的使用。 什么是视频…...

TypeScript 中声明类型的方法
1、使用:运算符来为变量和函数参数指定类型。例如: let num: number 5; function add(a: number, b: number): number {return a b; }2、使用 type 关键字来声明自定义类型别名。例如: type Point {x: number;y: number; };3、使用 interface 关键字…...
显示器校准软件BetterDisplay Pro mac中文版介绍
BetterDisplay Pro mac是一款显示器校准软件,可以帮助用户调整显示器的颜色和亮度,以获得更加真实、清晰和舒适的视觉体验。 BetterDisplay Pro mac软件特点 - 显示器校准:可以根据不同的需求和环境条件调整显示器的颜色、亮度和对比度等参数…...

Element UI 走马灯 实现鼠标滚动切换页面
鼠标滚动切换页面 elementui Carousel 走马灯鼠标滚轮事件实现 一、在轮播图外的盒子外添加鼠标滚轮事件,触发GoWheel函数。 wheel"goWheel"二、通过判断deltaY的数值来触发相应事件 它检查滚轮事件的deltaY属性是否大于0 event.deltaY当鼠标滚轮向下…...

在Docker上部署Springboot项目
在Docker上部署Springboot项目 ###1.安装docker 2.安装mysql 拉 Mysql 镜像 docker pull mysql:5.7.31运行 Mysql 5.7.31 第一次运行需要设置密码 docker run -d --name myMysql -p 9506:3306 -v /data/mysql:/var/lib/mysql -e MYSQL_ROOT_PASSWORD1234 mysql:5.7.31不是…...

2024中国眼博会,全国眼康与眼镜品牌加盟展会,北京眼健康展
立足北京,面向全球,2024第六届CEYEE中国眼博会,将以大规模的展览面积在4月与您相会; ——春天是万物复苏的季节,更是企业开拓市场,抓住春季发展机遇的重要时节;第六届CEYEE中国眼博会将在2024年…...

C++学习 --谓词
目录 1, 什么是谓词 1-1, 一元谓词 1-2, 二元谓词 1, 什么是谓词 返回bool类型的仿函数, 叫着谓词, 分为一元谓词和二元谓词 1-1, 一元谓词 operator()接收一个参数,叫着一元谓…...

Arkts深入了解运用 LazyForEach【鸿蒙专栏-17】
文章目录 深入了解 LazyForEach:数据懒加载LazyForEach概述接口描述IDataSource接口DataChangeListener接口使用限制和注意事项键值生成规则和组件创建规则首次渲染键值相同时错误渲染键值生成规则和组件创建规则首次渲染键值相同时错误渲染键值生成规则和组件创建规则首次渲染…...

如何让你的 Jmeter+Ant 测试报告更具吸引力?
引言 想象一下,你辛苦搭建了一个复杂的网站,投入了大量的时间和精力进行开发和测试。当你终于完成了测试并准备生成测试报告时,你可能会发现这个过程相当乏味,而对于其他人来说,它可能也不那么吸引人。 但是…...

游戏APP接入哪些广告类型
当谈到游戏应用程序(APP)接入广告时,选择适合用户体验和盈利的广告类型至关重要。游戏开发者通常考虑以下几种广告类型: admaoyan猫眼聚合 横幅广告: 这些广告以横幅形式显示在游戏界面的顶部或底部。它们不会打断游戏…...

Echarts地图registerMap使用的GeoJson数据获取
https://datav.aliyun.com/portal/school/atlas/area_selector 可以选择省,市,区。 也可以直接在地图上点击对应区域。 我的应用场景 我这里用到这个还是一个特别老的大屏项目,用的jq写的。显示中国地图边界区域 我们在上面的这个地区选择…...

【JavaEE】Java中的多线程 (Thread类)
作者主页:paper jie_博客 本文作者:大家好,我是paper jie,感谢你阅读本文,欢迎一建三连哦。 本文录入于《JavaEE》专栏,本专栏是针对于大学生,编程小白精心打造的。笔者用重金(时间和精力)打造&…...

python中具名元组的使用
collections.namedtuple是一个工厂函数,它可以用来构建一个带字段名的元组和一个有名字的类。 from collections import namedtuple City namedtuple(City2, name country population coordinates) tokyo City(Tokyo, JP, 36.933, (35.689722, 139.691667)) pr…...

【开题报告】基于SpringBoot的婚纱店试妆预约平台的设计与实现
1.选题背景 婚礼是人生中的重要时刻,而试妆是婚礼准备过程中不可或缺的一环。传统的婚纱店试妆预约方式通常需要亲自到店或通过电话预约,这样的方式可能存在一些问题。首先,用户需要花费时间和精力到店进行预约,对于忙碌的现代人…...

Qt 布局讲解及举例
Qt布局是一个用于管理窗口部件位置和大小的机制,它使得开发人员能够轻松地创建可伸缩、可调整大小的界面。在Qt中,布局管理器是一种用于自动调整窗口部件大小的机制,它可以根据窗口大小的变化自动调整部件的位置和大小。 Qt布局管理器通过使…...

【微服务】java 规则引擎使用详解
目录 一、什么是规则引擎 1.1 规则引擎概述 1.2 规则引擎执行过程 二、为什么要使用规则引擎 2.1 使用规则引擎的好处 2.1.1 易于维护和更新 2.1.2 增强应用程序的准确性和效率 2.1.3 加快应用程序的开发和部署 2.1.4 支持可视化和可管理性 2.2 规则引擎使用场景 三、…...
HCIA-Datacom跟官方路线学习
通过两次更换策略。最后找到最终的学习方案,华为ICT官网有对这个路线的学习,hcia基础有这个学习路线,hcip也有目录路线。所以,最后制定学习路线,是根据这个认证的路线进行学习了: 官网课程:课程…...
MySQL三大日志详细总结(redo log undo log binlog)
MySQL日志 包括事务日志(redolog undolog)慢查询日志,通用查询日志,二进制日志(binlog) 最为重要的就是binlog(归档日志)事务日志redolog(重做日志)undolog…...

Agent大战,赢家暗自在哪下功夫?
(一)日子都不好过OpenAI和Anthropic在release note节奏上,证明了一件事:他们有实力两周抬一次模型能力线。其威力,足以消灭掉一批创业公司。这事不展开,共识。在这一波里,别说小公司,…...

解析美国RTP导热工程塑料在电子散热领域的性能表现与行业应用
美国RTP导热工程塑料通过填充陶瓷、金属等导热介质提升材料热导率,同时保持优异机械性能与绝缘特性,完美适配电子散热场景。行业数据显示其热导率可达1-20 W/(mK),远超普通塑料0.2W/(mK)水平,成为解决电子设备过热问题的优选方案。…...

Triton+KServe构建高可用ML模型服务的七道关卡
1. 项目概述:这不是一次“部署”,而是一场从实验室到产线的系统性迁移“From Notebook to Production: Running ML in the Real World (Part 4)”——这个标题里藏着太多被轻描淡写却重若千钧的词。“Notebook”不是指纸质本子,而是Jupyter里…...

如何快速配置TQVaultAE:泰坦之旅玩家的终极装备管理与存档扩展指南
如何快速配置TQVaultAE:泰坦之旅玩家的终极装备管理与存档扩展指南 【免费下载链接】TQVaultAE Extra bank space for Titan Quest Anniversary Edition 项目地址: https://gitcode.com/gh_mirrors/tq/TQVaultAE TQVaultAE是《泰坦之旅周年版》玩家的开源装备…...

基于改进粒子群算法的混合储能系统容量优化附Matlab代码
✅作者简介:热爱科研的Matlab仿真开发者,擅长毕业设计辅导、数学建模、数据处理、程序设计科研仿真。🍎完整代码获取 定制创新 论文复现点击:Matlab科研工作室👇 关注我领取海量matlab电子书和数学建模资料 dz…...

85%企业将淘汰纯业务程序员!2026年前,大模型才是你的职业救命稻草!
文章指出传统技术岗面临淘汰风险,85%企业计划在2026年前淘汰纯业务型程序员。未来职场核心竞争力在于掌握大模型技术。文章强调大模型技术是技术人的时代红利,提供从入门到精通的全套视频教程,涵盖提示词工程、RAG、Agent等技术点。文章还分析…...

AI大模型学习顺序_七步掌握大模型精髓:从入门到精通的进阶秘籍!
本文以“七层关系”为框架,系统地阐述了学习大模型的最佳路径。从基础概念入手,逐步深入到模型架构、训练技巧、应用场景等核心内容,旨在帮助读者构建完整的知识体系,最终实现从入门到精通的全面提升。按“七层关系”学大模型&…...

3大远程管理痛点解决方案:MobaXterm中文版实现一站式终端效率革命
3大远程管理痛点解决方案:MobaXterm中文版实现一站式终端效率革命 【免费下载链接】Mobaxterm-Chinese Mobaxterm simplified Chinese version. Mobaxterm 的简体中文版. 项目地址: https://gitcode.com/gh_mirrors/mo/Mobaxterm-Chinese 远程服务器管理面临…...

3步搞定TikTok音乐提取:DouK-Downloader终极免费工具使用指南
3步搞定TikTok音乐提取:DouK-Downloader终极免费工具使用指南 【免费下载链接】TikTokDownloader TikTok 发布/喜欢/合辑/直播/视频/图集/音乐;抖音发布/喜欢/收藏/收藏夹/视频/图集/实况/直播/音乐/合集/评论/账号/搜索/热榜数据采集工具/下载工具 项…...
)
2026年亲测AI论文写作软件指南(高效定稿版)
为解决学术写作中效率与合规两大核心痛点,本文精选8款高适配性 AI 论文写作工具(按综合优先级排序),围绕中文学术规范适配、真实参考文献生成、格式标准化、高性价比四大核心维度进行测评,同时配套分场景精准选型方案与…...