C++学不会?一篇文章带你快速入门
1. 命名空间
1.1 命名空间的概念
C++命名空间是一种用于避免名称冲突的机制。它允许在多个文件中定义相同的函数、类或变量,而不会相互干扰。
1.2 命名空间的定义
namespace是命名空间的关键字,后面是命名空间的名字,然后后面一对 {},{}中即为命名空间的成员
//正常的命名空间介绍
namespace zs
{int num = 0;
}//命名空间可以嵌套
namespace zs
{int num = 0;namespace ls{int num = 10;}
}//同一个工程中允许存在多个相同名称的命名空间,编译器最后会合成同一个命名空间中
namespace A
{int a = 10;
}
namespace A
{int b = 20;
}
注意事项:一个命名空间就定义了一个新的作用域,命名空间中所有的内容都局限于该命名空间中
1.3 命名空间的使用方式
1. 加命名空间名称及作用限定符
namespace N
{int a = 0;int b = 1;
}
int main()
{printf("%d\n", N::a);return 0;
}
2. 使用using将命名空间中某个成员引入
namespace N
{int a = 0;int b = 1;
}
using N::b;
int main()
{printf("%d\n", N::a);printf("%d\n", b);return 0;
}
3. 使用using namespace 命名空间名称引入
namespace N
{int a = 0;int b = 1;
}
using namespace N;
int main()
{printf("%d\n", a);printf("%d\n", b);return 0;
}
2.作用域
2.1 作用域的使用
1. 局部域:在函数内部定义的变量,只能在该函数内部访问
#include<iostream>
using namespace std;
int main()
{int a = 1;cout << a << endl;return 0;
}
2. 全局域:在整个程序范围内定义的变量,可以在程序的任意位置访问
#include<iostream>
using namespace std;
int a = 10;
int main()
{cout << a << endl;return 0;
}
3. 命名空间域:在命名空间内定义的变量,只能在该命名空间内访问
include<iostream>
using namespace std;
namespace zs
{int a = 11;
}
int main()
{cout << zs::a << endl;return 0;
}
4. 类域:在类内部定义的成员变量,只能在该类的成员函数中访问
#include <iostream>class MyClass {
public:int myVar; // 类域变量MyClass() {myVar = 0; // 构造函数,初始化类域变量}void setMyVar(int value) {myVar = value; // 设置类域变量的值}int getMyVar() {return myVar; // 获取类域变量的值}
};int main() {MyClass obj; // 创建对象obj.setMyVar(10); // 设置类域变量的值std::cout << "类域变量的值为:" << obj.getMyVar() << std::endl; // 输出类域变量的值return 0;
}
2.2 作用域的工作原理
不同作用域的变量名可以相同,但是它们是不同的变量。当在更内层的作用域中使用同名变量时,会屏蔽外层作用域中的同名变量。
3. C++输入和输出
-
使用
cout标准输出对象和cin标准输入对象时,必须包含<iostream>头文件以及按命名空间使用方法使用std -
<<是流插入运算符,>>是流提取运算符 -
C++输入和输出可以自动识别类型
#include <iostream>
using namespace std;
int main()
{int a;cin >> a;cout << a << endl;return 0;
}
4. 缺省参数
4.1 缺省参数的概念
缺省参数是在声明或定义函数时,给函数的参数指定一个默认值。在调用该函数的时候,如果没有为该参数指定实参,那么就会使用这个默认值。如果提供了指定的实参,那么就会使用指定的实参。
#include <iostream>
using namespace std;
void Func(int a = 0)
{cout << a << endl;
}
int main()
{Func(); //没有传递参数时,使用参数的默认值Func(1); //传参时,使用指定的实参return 0;
}
4.2 缺省参数的分类
1. 全缺省参数
#include <iostream>
using namespace std;
void Func(int a = 1, int b = 2, int c = 3)
{cout << "a=" << a << endl;cout << "b=" << b << endl;cout << "c=" << c << endl;
}
int main()
{Func();
}
2. 半缺省参数
#include <iostream>
using namespace std;
void Func(int a , int b = 2, int c = 3)
{cout << "a=" << a << endl;cout << "b=" << b << endl;cout << "c=" << c << endl;
}
int main()
{Func(10);
}
注意事项:
- 半缺省的参数必须从右往左依次来给出,不能间隔着给
- 缺省参数不能在函数声明和定义中同时出现
- 缺省值必须是常量或者全局变量
- C语言不支持缺省参数
5. 函数重载
函数重载是C++编程语言中的一个重要概念,它允许在同一作用域内定义多个同名函数,但这些同名函数的参数列表必须有所不同。这意味着,虽然这些函数在名称上相同,但通过参数的类型、参数个数或类型顺序的不同,每个函数都有其独特的功能或含义。
5.1 参数类型不同
#include <iostream>
using namespace std;
int Max(int a, int b)
{cout << "int Max(int a, int b)" << endl;return a > b ? a : b;
}
double Max(double a, double b)
{cout << "double Max(double a, double b)" << endl;return a > b ? a : b;
}
int main()
{cout<<Max(1, 2)<<endl;cout<<Max(10.2, 2.2)<<endl;
}
5.2 参数个数不同
#include <iostream>
using namespace std;
void f(int a, int b)
{cout << "void f(int a, int b)" << endl;
}
void f(int a)
{cout << "void f(int a)" << endl;
}
int main()
{f(1, 1);f(2);
}
5.3 参数类型顺序不同
#include <iostream>
using namespace std;
void f(int, char b)
{cout << "f(int, char b)" << endl;
}
void f(char b, int a)
{cout << "f(char b, int a)" << endl;
}
int main()
{f(10, 'a');f('b', 20);
}
6. 引用
6.1 引用的概念
引用是给已经存在的变量取一个别名,编译器不会为引用变量开辟内存空间,它和它引用的变量共用同一块内存空间
6.2 引用的使用
类型& 引用变量名(对象名)=引用实体;
#include <iostream>
using namespace std;
int main()
{int a = 10;int& aa = a;printf("%p\n", &a);printf("%p\n", &aa);
}
注意:引用类型必须和引用实体是同种类型
6.3 引用的特性
- 引用在定义的时候必须先初始化
- 一个变量可以有多个引用
- 引用一旦引用一个实体,再不能引用其他实体
#include <iostream>
using namespace std;
int main()
{int a = 10;int& aa = a;int& aaa = a;printf("%p\n", &a);printf("%p\n", &aa);printf("%p\n", &aaa);
}
6.4 引用的使用场景
1. 做参数
#include <iostream>
using namespace std;
void Swap(int& left, int right)
{int temp = left;left = right;right = temp;
}
int main()
{int a = 10, b = 20;cout << "a:" << a <<" " << "b:" << b << endl;Swap(a, b);cout << "a:" << a <<" " << "b:" << b << endl;
}
2. 做返回值
如果函数返回时,出了函数作用域,如果返回对象还在(还没有还给操作系统),则可以使用引用返回,如果已经还给系统了,则必须使用传值返回
//因为static类型可以被整个程序访问,出了函数还在,所以可以使用引用返回
#include <iostream>
using namespace std;
int& Count()
{static int n = 0;n++;return n;
}
int main()
{int& ret = Count();cout << "ret:" << ret << endl;
}
//因为c是临时变量,Add函数运行结束后,该函数对应的栈空间就被回收了,即c变量就没有意义了
//在main中ret引用Add函数返回值,实际应用的就是一块已经被释放的空间
#include <iostream>
using namespace std;
int& Add(int a, int b)
{int c = a + b;return c;
}
int main()
{int& ret = Add(1, 2);cout << "Add(1,2) is:" << ret << endl;return 0;
}
注意事项:
函数运行时,系统需要给该函数开辟独立的栈空间,用来保存该函数的形参、局部变量以及一些寄存器信息等
函数运行结束后,该函数对应的栈空间就被系统回收了
空间被回收指该块栈空间暂时不能使用,但是内存还在
6.5 传值和传引用的区别
以值作为参数或者返回值类型,在传递和返回期间,函数不会直接传递实参或者将变量本身直接返回,而是传递实参或者返回变量的一份临时拷贝,因此用值返回作为参数或者返回值类型,效率非常低,尤其是当参数或者返回值类型非常大的时候,效率会更低
1. 做参数时
#include <iostream>
#include<time.h>
using namespace std;
struct A
{int a[10000];
};
void TestFunc1(A a){}
void TestFunc2(A& a){}
void TestRefAndValue()
{A a;//以值作为函数参数size_t begin1 = clock();for (size_t i = 0; i < 10000; i++)TestFunc1(a);size_t end1 = clock();//以引用作为函数参数size_t begin2 = clock();for (size_t i = 0; i < 10000; i++)TestFunc2(a);size_t end2 = clock();//分别计算两个函数运行结束后的时间cout << "TestFunc1(A)-time:" << end1 - begin1 << endl;cout << "TestFunc2(B)-time:" << end2 - begin2 << endl;
}
int main()
{TestRefAndValue();
}
2. 做返回值时
#include <iostream>
#include<time.h>
using namespace std;
struct A { int a[10000]; };
A a;
// 值返回
A TestFunc1() { return a; }
// 引用返回
A& TestFunc2() { return a; }
void TestReturnByRefOrValue()
{// 以值作为函数的返回值类型size_t begin1 = clock();for (size_t i = 0; i < 100000; ++i)TestFunc1();size_t end1 = clock();// 以引用作为函数的返回值类型size_t begin2 = clock();for (size_t i = 0; i < 100000; ++i)TestFunc2();size_t end2 = clock();// 计算两个函数运算完成之后的时间cout << "TestFunc1 time:" << end1 - begin1 << endl;cout << "TestFunc2 time:" << end2 - begin2 << endl;
}
int main()
{TestReturnByRefOrValue();return 0;
}
6.6 引用和指针的区别
在语法概念上,引用就是一个别名,没有独立空间,和其引用实体公用同一块空间
#include<iostream>
using namespace std;
int main()
{int a = 10;int& ra = a;cout << "&a=" << &a << endl; //&a=009CF84Ccout << "&ra=" << &ra << endl; //&ra=009CF84Creturn 0;
}
在底层实现上实际是有空间的,因为引用是按照指针方法实现的
6.7 引用和指针的不同的点:
- 引用概念上定义一个变量的别名,指针存储一个变量地址
- 引用在定义时必须初始化,指针没有要求
- 引用在初始化时引用一个实体后,就不能再引用其他实体,而指针可以在任何时候指向一个同类型实体
- 没有NULL引用,但有NULL指针
- 在sizeof中含义不同:引用结果为引用类型的大小,但指针始终是地址空间所占字节个数(32位平台下占4个字节)
- 引用自加即引用的实体增加1,指针自加即指针向后偏移一个类型的大小
- 有多级指针,但是没有多级引用
- 访问实体方式不同,指针需要显式解引用,引用编译器自己处理
- 引用比指针使用起来相对安全
7. 内联函数
7.1 内联函数的概念
以inline修饰的函数叫做内联函数,编译时C++编译器会在调用内联函数的地方展开,没有调用建立栈帧的开销,内联函数提升程序运行的效率
7.2 内联函数的特性
- inline是一种以空间换时间的做法,如果编译器将函数当成内联函数处理,在编译阶段,会用函数体替换函数调用
- inline对于编译器而言只是一个建议,不同编译器关于inline实现机制可能不同,一般建议:将函数规模较小(即函数不是很长,具体没有准确的说法,取决于编译器内部实现)、不是递归、频繁调用的函数采用inline修饰,否则编译器会忽略inline特性。
- inline不建议声明和定义分离,分离会导致链接错误。因为inline被展开,就没有函数地址了,链接就会找不到。
8. auto关键字(C++11)
8.1 auto的作用
C++中的auto关键字的出现是为了简化变量声明和类型推导的过程。
8.2 auto的使用规则
- auto与指针和引用结合起来使用:用auto声明指针类型时,用auto和auto*没有任何区别,但是用auto声明引用类型时必须加&
#include<iostream>
using namespace std;
int main()
{int x = 10;auto a = &x;auto* b = &x;auto& c = x;cout << typeid(a).name() << endl; //int *cout << typeid(b).name() << endl; //int *cout << typeid(c).name() << endl; //int
}
- 在同一行定义多个变量:当在同一行声明多个变量时,这些变量必须是相同的类型,否则编译器将会报错,因为编译器实际只对第一个类型进行推导,然后用推导出来的类型定义其他变量
#include<iostream>
using namespace std;
int main()
{auto a = 1, b = 2;auto c = 3, d = 2.0; //该行代码会编译失败,因为c和d的初始化表达式类型不同
}
- auto不能作为函数的参数
// 此处代码编译失败,auto不能作为形参类型,因为编译器无法对a的实际类型进行推导
void TestAuto(auto a)
{}
- auto不能直接用来声明数组
void TestAuto()
{
int a[] = {1,2,3};
auto b[] = {4,5,6};
}
- 为了避免与C++98中的auto发生混淆,C++11只保留了auto作为类型指示符的用法
- auto在实际中最常见的优势用法就是跟C++11提供的新式for循环,还有lambda表达式等进行配合使用
9. 基于范围的for循环(C++11)
9.1 范围for的语法
C++98遍历方式
#include<iostream>
using namespace std;
int main()
{int array[] = { 1,2,3,4,5 };for (int i = 0; i < sizeof(array) / sizeof(array[0]); i++)array[i] *= 2;for (int* p = array; p < array + sizeof(array) / sizeof(array[0]); ++p)cout << *p << endl;
}
C++11遍历方式(for循环后的括号由冒号“:”分为两部分:第一部分是范围内用于迭代的变量,第二部分是表达被迭代的范围)
#include<iostream>
using namespace std;
int main()
{int array[] = { 1,2,3,4,5 };for (auto& e : array)e *= 2;for (auto e : array)cout << e << " ";
}
**注意事项:**与普通循环类似,可以用continue来结束本次循环,也可以用break来跳出整个循环
9.2 范围for的使用条件
- for循环迭代的范围必须是确定的
对于数组而言,就是数组中第一个元素和最后一个元素的范围;对于类而言,应该提供begin和end的方法,begin和end就是for循环的迭代的范围
注意:以下代码就有问题,因为for的范围不确定
- 迭代的对象要实现++和==的操作
10. 指针空值nullptr(C++11)
- 在使用
nullptr表示指针空值时,不需要包含头文件,因为nullptr是C++11作为新关键字引入的 - 在C++11中,
sizeof(nullptr)与sizeof((void*)0)所占的字节数相同 - 为了提高代码的健壮性,在后续表示指针空值时建议最好使用
nullptr
相关文章:

C++学不会?一篇文章带你快速入门
1. 命名空间 1.1 命名空间的概念 C命名空间是一种用于避免名称冲突的机制。它允许在多个文件中定义相同的函数、类或变量,而不会相互干扰。 1.2 命名空间的定义 namespace是命名空间的关键字,后面是命名空间的名字,然后后面一对 {},{}中即…...

【加密相册】 隐私协议
【加密相册】隐私协议 1.个人信息的收集和使用 我们的应用程序不会收集用户的个人信息,包括姓名、地址、电子邮件地址、电话号码等。我们不会追踪用户的位置信息或共享用户的个人信息。 2. 非个人化信息的收集和使用 我们的应用程序可能会收集一些非个人化信息&a…...

超越基础:释放 Systemd 的全部潜力【systemd 二】
🎏:你只管努力,剩下的交给时间 🏠 :小破站 超越基础:释放 Systemd 的全部潜力【systemd 二】 前言第一:系统服务高级管理高级服务配置:环境变量设置:服务单元文件的高级选…...
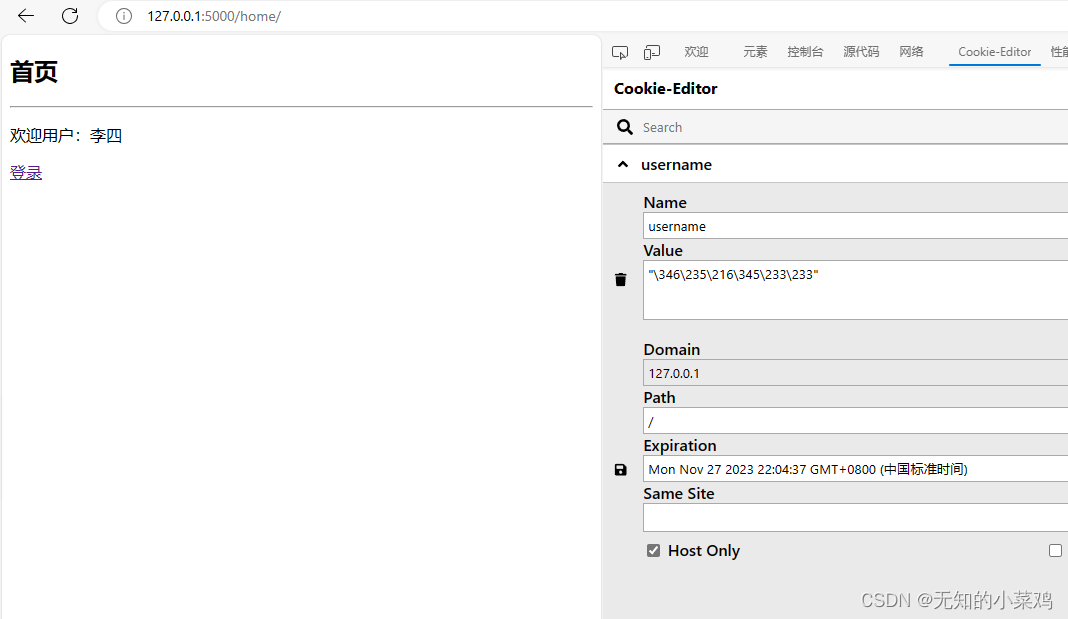
Flask学习二:项目拆分、请求与响应、cookie
教程 教程地址: 千锋教育Flask2框架从入门到精通,Python全栈开发必备教程 老师讲的很好,可以看一下。 项目拆分 项目结构 在项目根目录下,创建一个App目录,这是项目下的一个应用,应该类似于后端的微服…...
6、Qt延时的使用
一、sleep() 1、说明 QThread类中如下三个静态函数: QThread::sleep(n); //延迟n秒 QThread::msleep(n); //延迟n毫秒 QThread::usleep(n); //延迟n微妙 这种方式使用简单,但是会阻塞线程,有界面时界面会卡死,一般在非GUI线…...

《Effective C++》条款26
尽可能延后变量定义式的出现时间 string test(const string& passwd) {string s;if (s.size() < MinLenth){throw logic_error("passwd is too short");} } 这段代码的问题是:如果抛出了异常,那么定义的string对象将面临毫无意义的构造…...
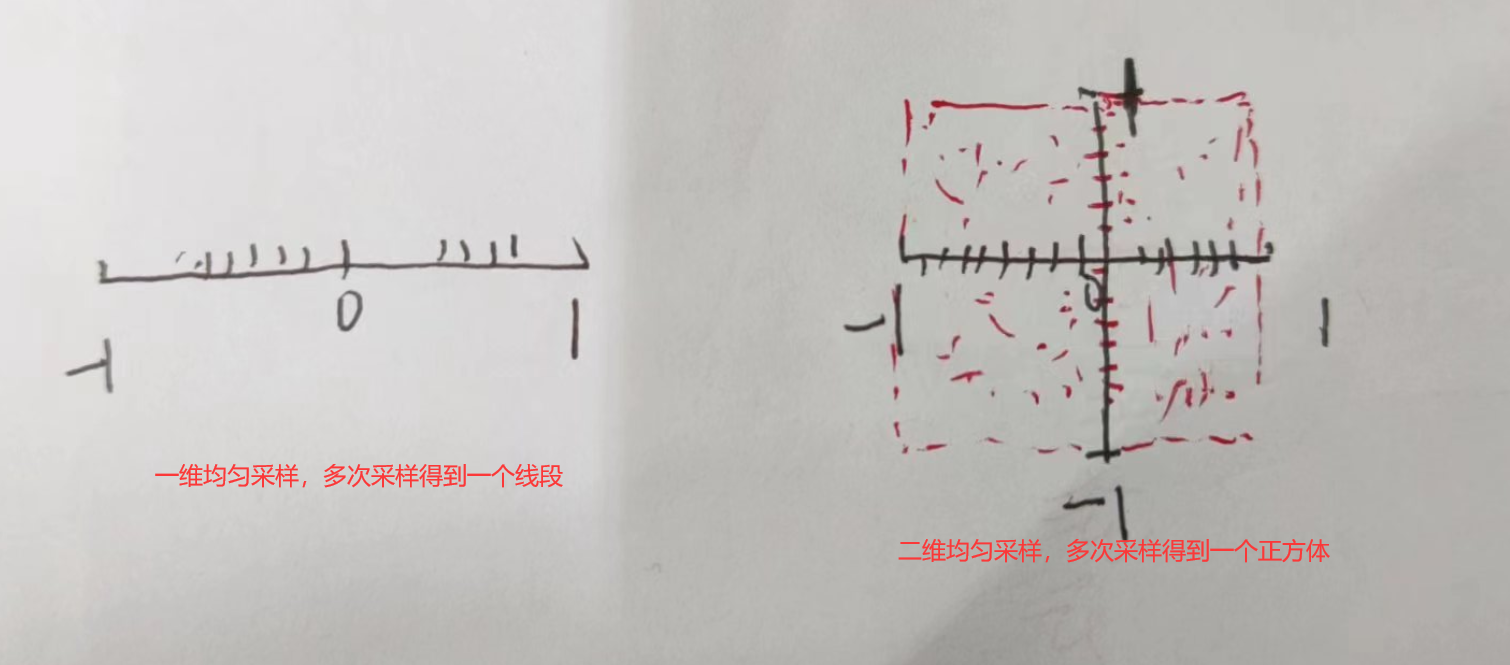
np.random.uniform() 采样得到的是一个高维立方体,而不是球体,为什么?
在代码中,采样是通过以下方式完成的: samples self.center np.random.uniform(-self.radius, self.radius, (num_samples, len(self.center))) 这里,np.random.uniform函数在每个维度独立地生成了一个介于-self.radius和self.radius之间的…...
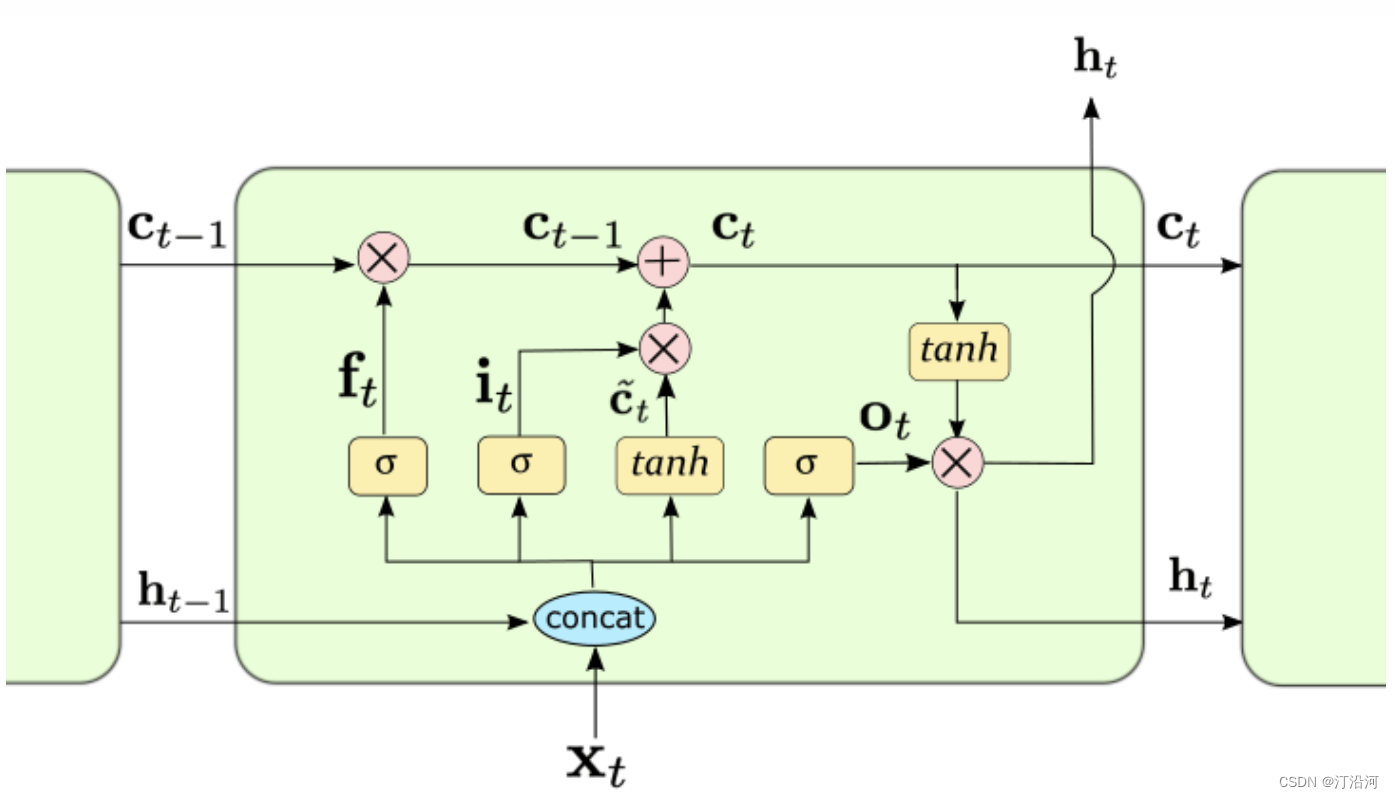
1 时间序列模型入门: LSTM
0 前言 循环神经网络(Recurrent Neural Network,RNN)是一种用于处理序列数据的神经网络。相比一般的神经网络来说,他能够处理序列变化的数据。比如某个单词的意思会因为上文提到的内容不同而有不同的含义,RNN就能够很好…...

1-Python与设计模式--单例模式
23种计模式之 前言 (5)单例模式、工厂模式、简单工厂模式、抽象工厂模式、建造者模式、原型模式、(7)代理模式、装饰器模式、适配器模式、门面模式、组合模式、享元模式、桥梁模式、(11)策略模式、责任链模式、命令模式、中介者模…...

Rust之构建命令行程序(一):接受命令行参数
开发环境 Windows 10Rust 1.73.0 VS Code 1.84.2 项目工程 这次创建了新的工程minigrep. IO工程:构建命令行程序 这一章回顾了到目前为止你所学的许多技能,并探索了一些更标准的库特性。我们将构建一个与文件和命令行输入/输出交互的命令行工具&#…...

Go 谈论了解Go语言
一、引言 Go的历史回顾 Go语言(通常被称为Go或Golang)由Robert Griesemer、Rob Pike和Ken Thompson在2007年开始设计,并于2009年正式公开发布。这三位设计者都曾在贝尔实验室工作,拥有丰富的编程语言和操作系统研究经验。Go的诞生…...
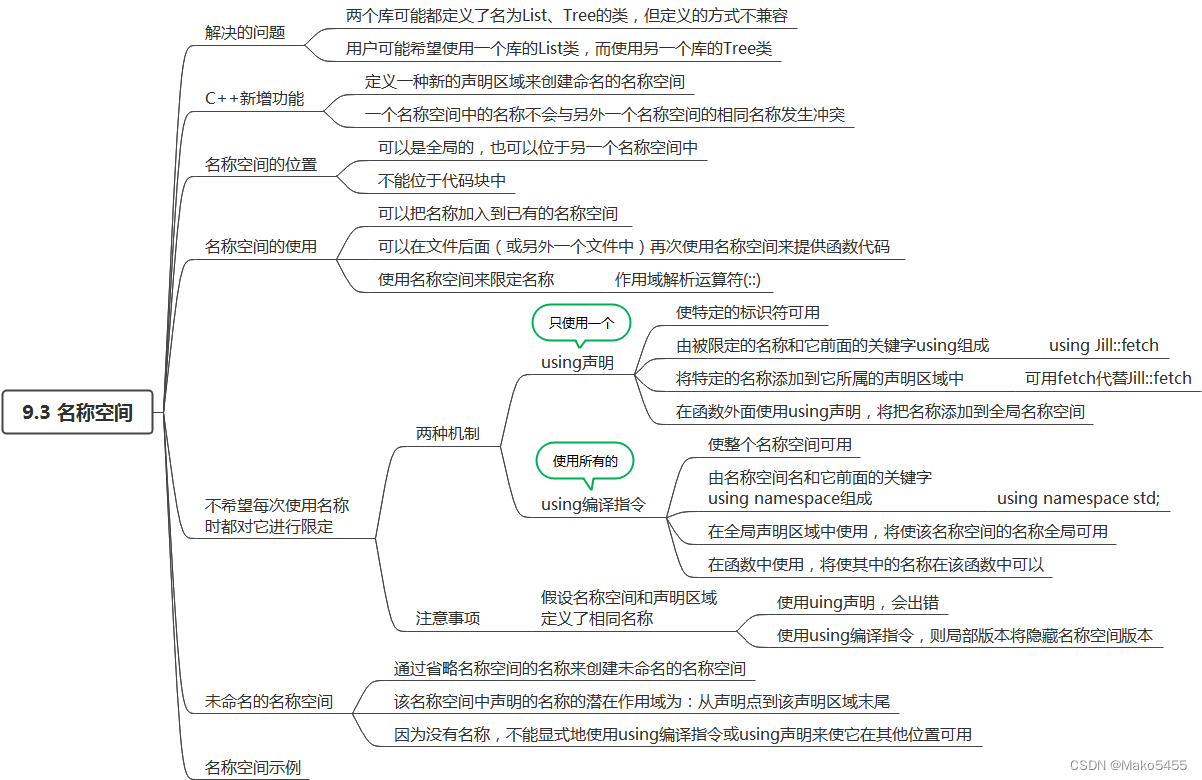
《C++PrimerPlus》第9章 内存模型和名称空间
9.1 单独编译 Visual Studio中新建头文件和源代码 通过解决方案资源管理器,如图所示: 分成三部分的程序(直角坐标转换为极坐标) 头文件coordin.h #ifndef __COORDIN_H__ // 如果没有被定义过 #define __COORDIN_H__struct pola…...
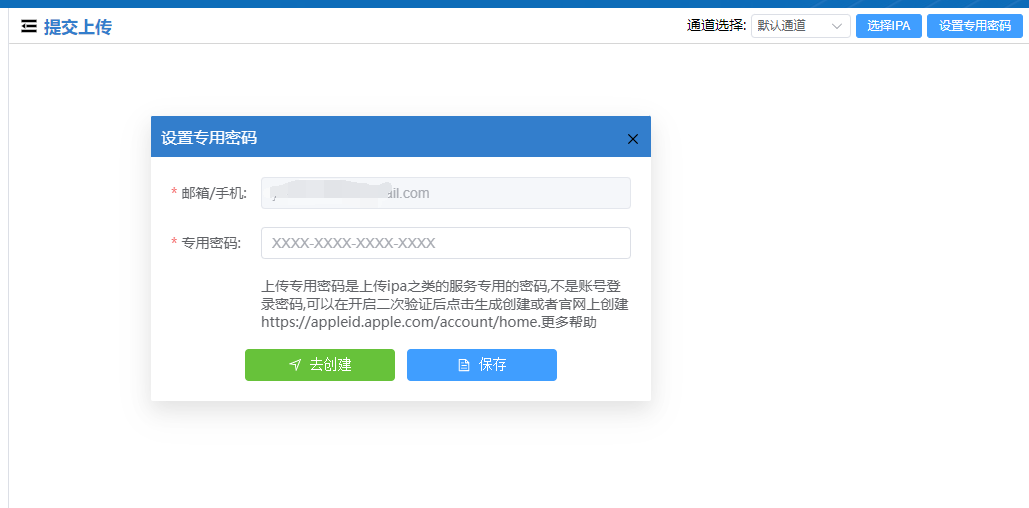
uniapp上架app store详细攻略
目录 uniapp上架app store详细攻略 前言 一、登录苹果开发者网站 二、创建好APP 前言 uniapp开发多端应用,打包ios应用后,会生成一个ipa后缀的文件。这个文件无法直接安装在iphone上,需要将这个ipa文件上架app store后,才能通…...

面试:线上问题处理
文章目录 在处理线上问题时,你的排查思路和步骤是什么线上偶发性问题如何处理和跟踪当系统出现大量错误日志时,你会如何分析和解决问题在高并发场景中,如何排查和解决线程安全问题当系统出现大规模的故障时,你的应急处理和恢复策略…...

Vue3中快速Diff算法
在Vue3中,快速Diff算法主要用于优化虚拟DOM的更新过程,减少不必要的DOM操作,提高性能。以下是对Vue3源码中快速Diff算法的解读: 首先,我们需要引入Vue3的相关包: import { reactive, toRefs, watch } fro…...

ROS2+STM32小车红外对射光电计数器模块资料
数据:一个周长内有20个孔洞或者20个分隔。外径:6.8cm 图片不是实物图,是示意图 因为没有串口,所以不可能会发送出数字的,就是通过电压变化次数来计算距离或者其他数据 有遮挡时,输出高电平,无遮…...
Android设计模式--桥接模式
闻正言,行正道,左右前后皆正人 一,定义 将抽象部分与实现部分分离,使它们都可以独立地进行变化 二,使用场景 从模式的定义中,我们大致可以了解到,这里的桥接的作用其实就是连接抽象部分与实现…...
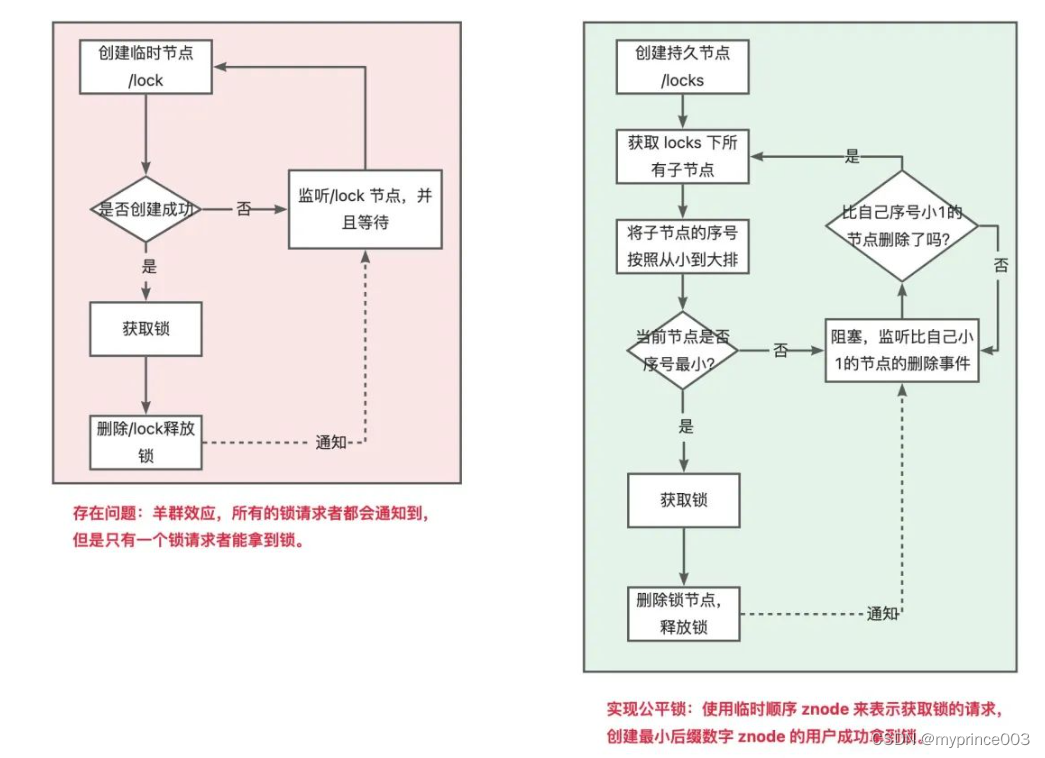
1、分布式锁实现原理与最佳实践(一)
在单体的应用开发场景中涉及并发同步时,大家往往采用Synchronized(同步)或同一个JVM内Lock机制来解决多线程间的同步问题。而在分布式集群工作的开发场景中,就需要一种更加高级的锁机制来处理跨机器的进程之间的数据同步问题&…...

Autosar通信实战系列03-NM模块要点及其配置介绍
本文框架 前言1. NM模块要点介绍1.1 NM基本功能介绍1.2 NM协同功能介绍2. NM配置2.1 NmGlobalConfig配置2.2 NmChannelConfigs配置前言 在本系列笔者将结合工作中对通信实战部分的应用经验进一步介绍常用,包括但不限于通信各模块的开发教程,代码逻辑分析,调测试方法及典型问…...

Golang模块管理功能
文章目录 1. Golang 包管理1.1 GOPATH 包管理1.2 Go vendor 包管理1.3 Go modules包管理2. Go Modules 应用实践2.1 Go modules关键信息2.1.1 go mod 命令行2.1.2 配置代理服务2.2 创建项目2.3 获取依赖包2.4 运行项目1. Golang 包管理 1.1 GOPATH 包管理 第一阶段: Golang初…...

【无人机通信】无线通信网络中无人机UAV定位与带宽分配的优化算法在确保地面用户服务质量QoS约束的同时,最大化网络吞吐量附matlab代码
✅作者简介:热爱科研的Matlab仿真开发者,擅长毕业设计辅导、数学建模、数据处理、程序设计科研仿真。🍎完整代码获取 定制创新 论文复现点击:Matlab科研工作室👇 关注我领取海量matlab电子书和数学建模资料 dz…...

井下无信号密闭空间:UWB基站断联失效,无感定位纯视觉独立解算
井下无信号密闭空间:UWB基站断联失效,无感定位纯视觉独立解算矿山井下巷道、采掘工作面、密闭峒室等区域,属于典型无外源通信、信号隔绝的密闭作业空间。数字孪生与视频孪生技术逐步下沉矿山安全生产领域,镜像视界浙江科技有限公司…...

3步掌握UI-TARS智能助手:从零开始实现桌面任务自动化
3步掌握UI-TARS智能助手:从零开始实现桌面任务自动化 【免费下载链接】UI-TARS-desktop The Open-Source Multimodal AI Agent Stack: Connecting Cutting-Edge AI Models and Agent Infra 项目地址: https://gitcode.com/GitHub_Trending/ui/UI-TARS-desktop …...

PyMICAPS:基于Python的气象数据可视化解决方案,提升Micaps数据处理效率300%
PyMICAPS:基于Python的气象数据可视化解决方案,提升Micaps数据处理效率300% 【免费下载链接】PyMICAPS 气象数据可视化,用matplotlib和basemap绘制micaps数据 项目地址: https://gitcode.com/gh_mirrors/py/PyMICAPS PyMICAPS是一个专…...

Chrome画中画扩展终极指南:一键实现多任务视频播放
Chrome画中画扩展终极指南:一键实现多任务视频播放 【免费下载链接】picture-in-picture-chrome-extension 项目地址: https://gitcode.com/gh_mirrors/pi/picture-in-picture-chrome-extension Chrome画中画扩展是一款基于原生Picture-in-Picture API开发的…...

7个实用技巧让你快速掌握Sabaki围棋软件:从零基础到高手复盘
7个实用技巧让你快速掌握Sabaki围棋软件:从零基础到高手复盘 【免费下载链接】Sabaki An elegant Go board and SGF editor for a more civilized age. 项目地址: https://gitcode.com/gh_mirrors/sa/Sabaki Sabaki是一款优雅的围棋棋盘和SGF编辑器ÿ…...

Android Framework 1
Android Framework 1环境准备Ubuntu 环境配置下载安卓源码编译源码Android Studio 环境编译环境准备 VMware WorkStation Pro 17.6.4 Ubuntu 20.04 安卓源码官方地址 Ubuntu 环境配置 1.安装必须的软件包 sudo apt-get install git-core gnupg flex bison build-essential …...

一多操作系统的生命体架构与当前主流开发语言的区别
这套架构与当前主流开发语言的区别,本质上就是**“造物主”与“工匠”**的区别。 目前的编程语言(无论是 C、Java 还是 Python)都是在教计算机**“怎么做”(How),而一多 OS 的生物学构架是在告诉系统“要什…...

为什么92%的OTA试水AI Agent后6个月内放弃?——头部旅行社CTO亲述3大技术断层
更多请点击: https://kaifayun.com 第一章:为什么92%的OTA试水AI Agent后6个月内放弃?——头部旅行社CTO亲述3大技术断层 在2023–2024年OTA行业AI落地调研中,某第三方机构追踪了137家上线AI Agent原型系统的在线旅游企业&#…...

戴森球计划工厂蓝图宝典:5000+免费设计助你轻松建设星际工厂
戴森球计划工厂蓝图宝典:5000免费设计助你轻松建设星际工厂 【免费下载链接】FactoryBluePrints 游戏戴森球计划的**工厂**蓝图仓库 项目地址: https://gitcode.com/GitHub_Trending/fa/FactoryBluePrints 还在为戴森球计划中复杂的工厂布局头疼吗࿱…...