LLVM学习笔记(63)
4.4.3.3.2.3. 向量操作数类型的处理
下面开始处理向量类型。在默认情形下这些操作都会拆分为更小的操作或者调用库。
X86TargetLowering::X86TargetLowering(续)
667 // Some FP actions are always expanded for vector types.
668 for (auto VT : { MVT::v4f32, MVT::v8f32, MVT::v16f32,
669 MVT::v2f64, MVT::v4f64, MVT::v8f64 }) {
670 setOperationAction(ISD::FSIN, VT, Expand);
671 setOperationAction(ISD::FSINCOS, VT, Expand);
672 setOperationAction(ISD::FCOS, VT, Expand);
673 setOperationAction(ISD::FREM, VT, Expand);
674 setOperationAction(ISD::FCOPYSIGN, VT, Expand);
675 setOperationAction(ISD::FPOW, VT, Expand);
676 setOperationAction(ISD::FLOG, VT, Expand);
677 setOperationAction(ISD::FLOG2, VT, Expand);
678 setOperationAction(ISD::FLOG10, VT, Expand);
679 setOperationAction(ISD::FEXP, VT, Expand);
680 setOperationAction(ISD::FEXP2, VT, Expand);
681 }
682
683 // First set operation action for all vector types to either promote
684 // (for widening) or expand (for scalarization). Then we will selectively
685 // turn on ones that can be effectively codegen'd.
686 for (MVT VT : MVT::vector_valuetypes()) {
687 setOperationAction(ISD::SDIV, VT, Expand);
688 setOperationAction(ISD::UDIV, VT, Expand);
689 setOperationAction(ISD::SREM, VT, Expand);
690 setOperationAction(ISD::UREM, VT, Expand);
691 setOperationAction(ISD::EXTRACT_VECTOR_ELT, VT,Expand);
692 setOperationAction(ISD::INSERT_VECTOR_ELT, VT, Expand);
693 setOperationAction(ISD::EXTRACT_SUBVECTOR, VT,Expand);
694 setOperationAction(ISD::INSERT_SUBVECTOR, VT,Expand);
695 setOperationAction(ISD::FMA, VT, Expand);
696 setOperationAction(ISD::FFLOOR, VT, Expand);
697 setOperationAction(ISD::FCEIL, VT, Expand);
698 setOperationAction(ISD::FTRUNC, VT, Expand);
699 setOperationAction(ISD::FRINT, VT, Expand);
700 setOperationAction(ISD::FNEARBYINT, VT, Expand);
701 setOperationAction(ISD::SMUL_LOHI, VT, Expand);
702 setOperationAction(ISD::MULHS, VT, Expand);
703 setOperationAction(ISD::UMUL_LOHI, VT, Expand);
704 setOperationAction(ISD::MULHU, VT, Expand);
705 setOperationAction(ISD::SDIVREM, VT, Expand);
706 setOperationAction(ISD::UDIVREM, VT, Expand);
707 setOperationAction(ISD::CTPOP, VT, Expand);
708 setOperationAction(ISD::CTTZ, VT, Expand);
709 setOperationAction(ISD::CTLZ, VT, Expand);
710 setOperationAction(ISD::ROTL, VT, Expand);
711 setOperationAction(ISD::ROTR, VT, Expand);
712 setOperationAction(ISD::BSWAP, VT, Expand);
713 setOperationAction(ISD::SETCC, VT, Expand);
714 setOperationAction(ISD::FP_TO_UINT, VT, Expand);
715 setOperationAction(ISD::FP_TO_SINT, VT, Expand);
716 setOperationAction(ISD::UINT_TO_FP, VT, Expand);
717 setOperationAction(ISD::SINT_TO_FP, VT, Expand);
718 setOperationAction(ISD::SIGN_EXTEND_INREG, VT,Expand);
719 setOperationAction(ISD::TRUNCATE, VT, Expand);
720 setOperationAction(ISD::SIGN_EXTEND, VT, Expand);
721 setOperationAction(ISD::ZERO_EXTEND, VT, Expand);
722 setOperationAction(ISD::ANY_EXTEND, VT, Expand);
723 setOperationAction(ISD::SELECT_CC, VT, Expand);
724 for (MVT InnerVT : MVT::vector_valuetypes()) {
725 setTruncStoreAction(InnerVT, VT, Expand);
726
727 setLoadExtAction(ISD::SEXTLOAD, InnerVT, VT, Expand);
728 setLoadExtAction(ISD::ZEXTLOAD, InnerVT, VT, Expand);
729
730 // N.b. ISD::EXTLOAD legality is basically ignored except for i1-like
731 // types, we have to deal with them whether we ask for Expansion or not.
732 // Setting Expand causes its own optimisation problems though, so leave
733 // them legal.
734 if (VT.getVectorElementType() == MVT::i1)
735 setLoadExtAction(ISD::EXTLOAD, InnerVT, VT, Expand);
736
737 // EXTLOAD for MVT::f16 vectors is not legal because f16 vectors are
738 // split/scalarized right now.
739 if (VT.getVectorElementType() == MVT::f16)
740 setLoadExtAction(ISD::EXTLOAD, InnerVT, VT, Expand);
741 }
742 }
4.4.3.3.2.3.1. MMX、SSE1、SSE2与SSE41
接下来则是根据目标机器是否支持MMX,SSE1,SSE2,SSE41指令集,添加可用的寄存器类别,以及设置各种action的行为。注意,在使用软件模拟浮点时,这些类别的寄存器都不可用,相关具有操作数的指令也是非法的。
X86TargetLowering::X86TargetLowering(续)
744 // FIXME: In order to prevent SSE instructions being expanded to MMX ones
745 // with -msoft-float, disable use of MMX as well.
746 if (!Subtarget->useSoftFloat() && Subtarget->hasMMX()) {
747 addRegisterClass(MVT::x86mmx, &X86::VR64RegClass);
748 // No operations on x86mmx supported, everything uses intrinsics.
749 }
750
751 if (!Subtarget->useSoftFloat() && Subtarget->hasSSE1()) {
752 addRegisterClass(MVT::v4f32, Subtarget.hasVLX() ? &X86::VR128XRegClass
753 : &X86::VR128RegClass);
754
755 setOperationAction(ISD::FNEG, MVT::v4f32, Custom);
756 setOperationAction(ISD::FABS, MVT::v4f32, Custom);
757 setOperationAction(ISD::FCOPYSIGN, MVT::v4f32, Custom);
758 setOperationAction(ISD::BUILD_VECTOR, MVT::v4f32, Custom);
759 setOperationAction(ISD::VECTOR_SHUFFLE, MVT::v4f32, Custom);
760 setOperationAction(ISD::VSELECT, MVT::v4f32, Custom);
761 setOperationAction(ISD::EXTRACT_VECTOR_ELT, MVT::v4f32, Custom);
762 setOperationAction(ISD::SELECT, MVT::v4f32, Custom);
763 setOperationAction(ISD::UINT_TO_FP, MVT::v4i32, Custom);
764 }
765
766 if (!Subtarget->useSoftFloat() && Subtarget->hasSSE2()) {
767 addRegisterClass(MVT::v2f64, Subtarget.hasVLX() ? &X86::VR128XRegClass
768 : &X86::VR128RegClass);
769
770 // FIXME: Unfortunately, -soft-float and -no-implicit-float mean XMM
771 // registers cannot be used even for integer operations.
772 addRegisterClass(MVT::v16i8, Subtarget.hasVLX() ? &X86::VR128XRegClass
773 : &X86::VR128RegClass);
774 addRegisterClass(MVT::v8i16, Subtarget.hasVLX() ? &X86::VR128XRegClass
775 : &X86::VR128RegClass);
776 addRegisterClass(MVT::v4i32, Subtarget.hasVLX() ? &X86::VR128XRegClass
777 : &X86::VR128RegClass);
778 addRegisterClass(MVT::v2i64, Subtarget.hasVLX() ? &X86::VR128XRegClass
779 : &X86::VR128RegClass);
780
781 setOperationAction(ISD::MUL, MVT::v16i8, Custom);
782 setOperationAction(ISD::MUL, MVT::v4i32, Custom);
783 setOperationAction(ISD::MUL, MVT::v2i64, Custom);
784 setOperationAction(ISD::UMUL_LOHI, MVT::v4i32, Custom);
785 setOperationAction(ISD::SMUL_LOHI, MVT::v4i32, Custom);
786 setOperationAction(ISD::MULHU, MVT::v16i8, Custom);
787 setOperationAction(ISD::MULHS, MVT::v16i8, Custom);
788 setOperationAction(ISD::MULHU, MVT::v8i16, Legal);
789 setOperationAction(ISD::MULHS, MVT::v8i16, Legal);
790 setOperationAction(ISD::MUL, MVT::v8i16, Legal);
791 setOperationAction(ISD::FNEG, MVT::v2f64, Custom);
792 setOperationAction(ISD::FABS, MVT::v2f64, Custom);
793 setOperationAction(ISD::FCOPYSIGN, MVT::v2f64, Custom);
794
795 for (auto VT : { MVT::v16i8, MVT::v8i16, MVT::v4i32, MVT::v2i64 }) {
796 setOperationAction(ISD::SMAX, VT, VT == MVT::v8i16 ? Legal : Custom);
797 setOperationAction(ISD::SMIN, VT, VT == MVT::v8i16 ? Legal : Custom);
798 setOperationAction(ISD::UMAX, VT, VT == MVT::v16i8 ? Legal : Custom);
799 setOperationAction(ISD::UMIN, VT, VT == MVT::v16i8 ? Legal : Custom);
800 }
801
802 setOperationAction(ISD::INSERT_VECTOR_ELT, MVT::v8i16, Custom);
803 setOperationAction(ISD::INSERT_VECTOR_ELT, MVT::v4i32, Custom);
804 setOperationAction(ISD::INSERT_VECTOR_ELT, MVT::v4f32, Custom);
805
806 // Provide custom widening for v2f32 setcc. This is really for VLX when
807 // setcc result type returns v2i1/v4i1 vector for v2f32/v4f32 leading to
808 // type legalization changing the result type to v4i1 during widening.
809 // It works fine for SSE2 and is probably faster so no need to qualify with
810 // VLX support.
811 setOperationAction(ISD::SETCC, MVT::v2i32, Custom);
812
813 for (auto VT : { MVT::v16i8, MVT::v8i16, MVT::v4i32, MVT::v2i64 }) {
814 setOperationAction(ISD::SETCC, VT, Custom);
815 setOperationAction(ISD::CTPOP, VT, Custom);
816 setOperationAction(ISD::CTTZ, VT, Custom);
817
818 // The condition codes aren't legal in SSE/AVX and under AVX512 we use
819 // setcc all the way to isel and prefer SETGT in some isel patterns.
820 setCondCodeAction(ISD::SETLT, VT, Custom);
821 setCondCodeAction(ISD::SETLE, VT, Custom);
822 }
823
824 for (auto VT : { MVT::v16i8, MVT::v8i16, MVT::v4i32 }) {
825 setOperationAction(ISD::SCALAR_TO_VECTOR, VT, Custom);
826 setOperationAction(ISD::BUILD_VECTOR, VT, Custom);
827 setOperationAction(ISD::VECTOR_SHUFFLE, VT, Custom);
828 setOperationAction(ISD::VSELECT, VT, Custom);
829 setOperationAction(ISD::EXTRACT_VECTOR_ELT, VT, Custom);
830 }
831
832 // We support custom legalizing of sext and anyext loads for specific
833 // memory vector types which we can load as a scalar (or sequence of
834 // scalars) and extend in-register to a legal 128-bit vector type. For sext
835 // loads these must work with a single scalar load.
836 for (MVT VT : MVT::integer_vector_valuetypes()) {
837 setLoadExtAction(ISD::SEXTLOAD, VT, MVT::v4i8, Custom);
838 setLoadExtAction(ISD::SEXTLOAD, VT, MVT::v4i16, Custom);
839 setLoadExtAction(ISD::SEXTLOAD, VT, MVT::v8i8, Custom);
840 setLoadExtAction(ISD::EXTLOAD, VT, MVT::v2i8, Custom);
841 setLoadExtAction(ISD::EXTLOAD, VT, MVT::v2i16, Custom);
842 setLoadExtAction(ISD::EXTLOAD, VT, MVT::v2i32, Custom);
843 setLoadExtAction(ISD::EXTLOAD, VT, MVT::v4i8, Custom);
844 setLoadExtAction(ISD::EXTLOAD, VT, MVT::v4i16, Custom);
845 setLoadExtAction(ISD::EXTLOAD, VT, MVT::v8i8, Custom);
846 }
847
848 for (auto VT : { MVT::v2f64, MVT::v2i64 }) {
849 setOperationAction(ISD::BUILD_VECTOR, VT, Custom);
850 setOperationAction(ISD::VECTOR_SHUFFLE, VT, Custom);
851 setOperationAction(ISD::VSELECT, VT, Custom);
852
853 if (VT == MVT::v2i64 && !Subtarget.is64Bit())
854 continue;
855
856 setOperationAction(ISD::INSERT_VECTOR_ELT, VT, Custom);
857 setOperationAction(ISD::EXTRACT_VECTOR_ELT, VT, Custom);
858 }
859
860 // Promote v16i8, v8i16, v4i32 load, select, and, or, xor to v2i64.
861 for (auto VT : { MVT::v16i8, MVT::v8i16, MVT::v4i32 }) {
862 setOperationPromotedToType(ISD::AND, VT, MVT::v2i64);
863 setOperationPromotedToType(ISD::OR, VT, MVT::v2i64);
864 setOperationPromotedToType(ISD::XOR, VT, MVT::v2i64);
865 setOperationPromotedToType(ISD::LOAD, VT, MVT::v2i64);
866 setOperationPromotedToType(ISD::SELECT, VT, MVT::v2i64);
867 }
868
869 // Custom lower v2i64 and v2f64 selects.
870 setOperationAction(ISD::SELECT, MVT::v2f64, Custom);
871 setOperationAction(ISD::SELECT, MVT::v2i64, Custom);
872
873 setOperationAction(ISD::FP_TO_SINT, MVT::v4i32, Legal);
874 setOperationAction(ISD::FP_TO_SINT, MVT::v2i32, Custom);
875
876 setOperationAction(ISD::SINT_TO_FP, MVT::v4i32, Legal );
877 setOperationAction(ISD::SINT_TO_FP, MVT::v2i32, Custom);
878
879 setOperationAction(ISD::UINT_TO_FP, MVT::v2i32, Custom);
880
881 // Fast v2f32 UINT_TO_FP( v2i32 ) custom conversion.
882 setOperationAction(ISD::UINT_TO_FP, MVT::v2f32, Custom);
883
884 setOperationAction(ISD::FP_EXTEND, MVT::v2f32, Custom);
885 setOperationAction(ISD::FP_ROUND, MVT::v2f32, Custom);
886
887 for (MVT VT : MVT::fp_vector_valuetypes())
888 setLoadExtAction(ISD::EXTLOAD, VT, MVT::v2f32, Legal);
889
890 setOperationAction(ISD::BITCAST, MVT::v2i32, Custom);
891 setOperationAction(ISD::BITCAST, MVT::v4i16, Custom);
892 setOperationAction(ISD::BITCAST, MVT::v8i8, Custom);
893 if (!Subtarget.hasAVX512())
894 setOperationAction(ISD::BITCAST, MVT::v16i1, Custom);
895
896 setOperationAction(ISD::SIGN_EXTEND_VECTOR_INREG, MVT::v2i64, Custom);
897 setOperationAction(ISD::SIGN_EXTEND_VECTOR_INREG, MVT::v4i32, Custom);
898 setOperationAction(ISD::SIGN_EXTEND_VECTOR_INREG, MVT::v8i16, Custom);
899
900 // In the customized shift lowering, the legal v4i32/v2i64 cases
901 // in AVX2 will be recognized.
902 for (auto VT : { MVT::v16i8, MVT::v8i16, MVT::v4i32, MVT::v2i64 }) {
903 setOperationAction(ISD::SRL, VT, Custom);
904 setOperationAction(ISD::SHL, VT, Custom);
905 setOperationAction(ISD::SRA, VT, Custom);
906 }
907
908 setOperationAction(ISD::ROTL, MVT::v4i32, Custom);
909 setOperationAction(ISD::ROTL, MVT::v8i16, Custom);
910 setOperationAction(ISD::ROTL, MVT::v16i8, Custom);
911 }
912
913 if (!Subtarget.useSoftFloat() && Subtarget.hasSSSE3()) {
914 setOperationAction(ISD::ABS, MVT::v16i8, Legal);
915 setOperationAction(ISD::ABS, MVT::v8i16, Legal);
916 setOperationAction(ISD::ABS, MVT::v4i32, Legal);
917 setOperationAction(ISD::BITREVERSE, MVT::v16i8, Custom);
918 setOperationAction(ISD::CTLZ, MVT::v16i8, Custom);
919 setOperationAction(ISD::CTLZ, MVT::v8i16, Custom);
920 setOperationAction(ISD::CTLZ, MVT::v4i32, Custom);
921 setOperationAction(ISD::CTLZ, MVT::v2i64, Custom);
922 }
923
924 if (!Subtarget->useSoftFloat() && Subtarget->hasSSE41()) {
925 for (MVT RoundedTy : {MVT::f32, MVT::f64, MVT::v4f32, MVT::v2f64}) {
926 setOperationAction(ISD::FFLOOR, RoundedTy, Legal);
927 setOperationAction(ISD::FCEIL, RoundedTy, Legal);
928 setOperationAction(ISD::FTRUNC, RoundedTy, Legal);
929 setOperationAction(ISD::FRINT, RoundedTy, Legal);
930 setOperationAction(ISD::FNEARBYINT, RoundedTy, Legal);
931 }
932
933 setOperationAction(ISD::SMAX, MVT::v16i8, Legal);
934 setOperationAction(ISD::SMAX, MVT::v4i32, Legal);
935 setOperationAction(ISD::UMAX, MVT::v8i16, Legal);
936 setOperationAction(ISD::UMAX, MVT::v4i32, Legal);
937 setOperationAction(ISD::SMIN, MVT::v16i8, Legal);
938 setOperationAction(ISD::SMIN, MVT::v4i32, Legal);
939 setOperationAction(ISD::UMIN, MVT::v8i16, Legal);
940 setOperationAction(ISD::UMIN, MVT::v4i32, Legal);
941
942 // FIXME: Do we need to handle scalar-to-vector here?
943 setOperationAction(ISD::MUL, MVT::v4i32, Legal);
944
945 // We directly match byte blends in the backend as they match the VSELECT
946 // condition form.
947 setOperationAction(ISD::VSELECT, MVT::v16i8, Legal);
948
949 // SSE41 brings specific instructions for doing vector sign extend even in
950 // cases where we don't have SRA.
951 for (auto VT : { MVT::v8i16, MVT::v4i32, MVT::v2i64 }) {
952 setOperationAction(ISD::SIGN_EXTEND_VECTOR_INREG, VT, Legal);
953 setOperationAction(ISD::ZERO_EXTEND_VECTOR_INREG, VT, Legal);
954 }
955
956 for (MVT VT : MVT::integer_vector_valuetypes()) {
957 setLoadExtAction(ISD::SEXTLOAD, VT, MVT::v2i8, Custom);
958 setLoadExtAction(ISD::SEXTLOAD, VT, MVT::v2i16, Custom);
959 setLoadExtAction(ISD::SEXTLOAD, VT, MVT::v2i32, Custom);
960 }
961
962 // SSE41 also has vector sign/zero extending loads, PMOV[SZ]X
963 for (auto LoadExtOp : { ISD::SEXTLOAD, ISD::ZEXTLOAD }) {
964 setLoadExtAction(LoadExtOp, MVT::v8i16, MVT::v8i8, Legal);
965 setLoadExtAction(LoadExtOp, MVT::v4i32, MVT::v4i8, Legal);
966 setLoadExtAction(LoadExtOp, MVT::v2i32, MVT::v2i8, Legal);
967 setLoadExtAction(LoadExtOp, MVT::v2i64, MVT::v2i8, Legal);
968 setLoadExtAction(LoadExtOp, MVT::v4i32, MVT::v4i16, Legal);
969 setLoadExtAction(LoadExtOp, MVT::v2i64, MVT::v2i16, Legal);
970 setLoadExtAction(LoadExtOp, MVT::v2i64, MVT::v2i32, Legal);
971 }
972
973 // i8 vectors are custom because the source register and source
974 // source memory operand types are not the same width.
975 setOperationAction(ISD::INSERT_VECTOR_ELT, MVT::v16i8, Custom);
976 }
977
978 if (!Subtarget.useSoftFloat() && Subtarget.hasXOP()) {
979 for (auto VT : { MVT::v16i8, MVT::v8i16, MVT::v4i32, MVT::v2i64,
980 MVT::v32i8, MVT::v16i16, MVT::v8i32, MVT::v4i64 })
981 setOperationAction(ISD::ROTL, VT, Custom);
982
983 // XOP can efficiently perform BITREVERSE with VPPERM.
984 for (auto VT : { MVT::i8, MVT::i16, MVT::i32, MVT::i64 })
985 setOperationAction(ISD::BITREVERSE, VT, Custom);
986
987 for (auto VT : { MVT::v16i8, MVT::v8i16, MVT::v4i32, MVT::v2i64,
988 MVT::v32i8, MVT::v16i16, MVT::v8i32, MVT::v4i64 })
989 setOperationAction(ISD::BITREVERSE, VT, Custom);
990 }
4.4.3.3.2.3.2. AVX与AVX2
下面993行的hasInt256()返回true表示目标机器支持AVX2以上的指令集。995行的hasVLX()返回true表示支持AVX512向量长度扩展指令集1(扩展大多数AVX-512指令运行在XMM/128位及YMM/ 256位寄存器上)。1028行的hasAVX512()则对支持AVX512F以上指令集的目标机器返回true。
X86TargetLowering::X86TargetLowering(续)
992 if (!Subtarget.useSoftFloat() && Subtarget.hasAVX()) {
993 bool HasInt256 = Subtarget.hasInt256();
994
995 addRegisterClass(MVT::v32i8, Subtarget.hasVLX() ? &X86::VR256XRegClass
996 : &X86::VR256RegClass);
997 addRegisterClass(MVT::v16i16, Subtarget.hasVLX() ? &X86::VR256XRegClass
998 : &X86::VR256RegClass);
999 addRegisterClass(MVT::v8i32, Subtarget.hasVLX() ? &X86::VR256XRegClass
1000 : &X86::VR256RegClass);
1001 addRegisterClass(MVT::v8f32, Subtarget.hasVLX() ? &X86::VR256XRegClass
1002 : &X86::VR256RegClass);
1003 addRegisterClass(MVT::v4i64, Subtarget.hasVLX() ? &X86::VR256XRegClass
1004 : &X86::VR256RegClass);
1005 addRegisterClass(MVT::v4f64, Subtarget.hasVLX() ? &X86::VR256XRegClass
1006 : &X86::VR256RegClass);
1007
1008 for (auto VT : { MVT::v8f32, MVT::v4f64 }) {
1009 setOperationAction(ISD::FFLOOR, VT, Legal);
1010 setOperationAction(ISD::FCEIL, VT, Legal);
1011 setOperationAction(ISD::FTRUNC, VT, Legal);
1012 setOperationAction(ISD::FRINT, VT, Legal);
1013 setOperationAction(ISD::FNEARBYINT, VT, Legal);
1014 setOperationAction(ISD::FNEG, VT, Custom);
1015 setOperationAction(ISD::FABS, VT, Custom);
1016 setOperationAction(ISD::FCOPYSIGN, VT, Custom);
1017 }
1018
1019 // (fp_to_int:v8i16 (v8f32 ..)) requires the result type to be promoted
1020 // even though v8i16 is a legal type.
1021 setOperationAction(ISD::FP_TO_SINT, MVT::v8i16, Promote);
1022 setOperationAction(ISD::FP_TO_UINT, MVT::v8i16, Promote);
1023 setOperationAction(ISD::FP_TO_SINT, MVT::v8i32, Legal);
1024
1025 setOperationAction(ISD::SINT_TO_FP, MVT::v8i32, Legal);
1026 setOperationAction(ISD::FP_ROUND, MVT::v4f32, Legal);
1027
1028 if (!Subtarget.hasAVX512())
1029 setOperationAction(ISD::BITCAST, MVT::v32i1, Custom);
1030
1031 for (MVT VT : MVT::fp_vector_valuetypes())
1032 setLoadExtAction(ISD::EXTLOAD, VT, MVT::v4f32, Legal);
1033
1034 // In the customized shift lowering, the legal v8i32/v4i64 cases
1035 // in AVX2 will be recognized.
1036 for (auto VT : { MVT::v32i8, MVT::v16i16, MVT::v8i32, MVT::v4i64 }) {
1037 setOperationAction(ISD::SRL, VT, Custom);
1038 setOperationAction(ISD::SHL, VT, Custom);
1039 setOperationAction(ISD::SRA, VT, Custom);
1040 }
1041
1042 setOperationAction(ISD::ROTL, MVT::v8i32, Custom);
1043 setOperationAction(ISD::ROTL, MVT::v16i16, Custom);
1044 setOperationAction(ISD::ROTL, MVT::v32i8, Custom);
1045
1046 setOperationAction(ISD::SELECT, MVT::v4f64, Custom);
1047 setOperationAction(ISD::SELECT, MVT::v4i64, Custom);
1048 setOperationAction(ISD::SELECT, MVT::v8f32, Custom);
1049
1050 for (auto VT : { MVT::v16i16, MVT::v8i32, MVT::v4i64 }) {
1051 setOperationAction(ISD::SIGN_EXTEND, VT, Custom);
1052 setOperationAction(ISD::ZERO_EXTEND, VT, Custom);
1053 setOperationAction(ISD::ANY_EXTEND, VT, Custom);
1054 }
1055
1056 setOperationAction(ISD::TRUNCATE, MVT::v16i8, Custom);
1057 setOperationAction(ISD::TRUNCATE, MVT::v8i16, Custom);
1058 setOperationAction(ISD::TRUNCATE, MVT::v4i32, Custom);
1059 setOperationAction(ISD::BITREVERSE, MVT::v32i8, Custom);
1060
1061 for (auto VT : { MVT::v32i8, MVT::v16i16, MVT::v8i32, MVT::v4i64 }) {
1062 setOperationAction(ISD::SETCC, VT, Custom);
1063 setOperationAction(ISD::CTPOP, VT, Custom);
1064 setOperationAction(ISD::CTTZ, VT, Custom);
1065 setOperationAction(ISD::CTLZ, VT, Custom);
1066
1067 // The condition codes aren't legal in SSE/AVX and under AVX512 we use
1068 // setcc all the way to isel and prefer SETGT in some isel patterns.
1069 setCondCodeAction(ISD::SETLT, VT, Custom);
1070 setCondCodeAction(ISD::SETLE, VT, Custom);
1071 }
1072
1073 if (Subtarget.hasAnyFMA()) {
1074 for (auto VT : { MVT::f32, MVT::f64, MVT::v4f32, MVT::v8f32,
1075 MVT::v2f64, MVT::v4f64 })
1076 setOperationAction(ISD::FMA, VT, Legal);
1077 }
1078
1079 for (auto VT : { MVT::v32i8, MVT::v16i16, MVT::v8i32, MVT::v4i64 }) {
1080 setOperationAction(ISD::ADD, VT, HasInt256 ? Legal : Custom);
1081 setOperationAction(ISD::SUB, VT, HasInt256 ? Legal : Custom);
1082 }
1083
1084 setOperationAction(ISD::MUL, MVT::v4i64, Custom);
1085 setOperationAction(ISD::MUL, MVT::v8i32, HasInt256 ? Legal : Custom);
1086 setOperationAction(ISD::MUL, MVT::v16i16, HasInt256 ? Legal : Custom);
1087 setOperationAction(ISD::MUL, MVT::v32i8, Custom);
1088
1089 setOperationAction(ISD::UMUL_LOHI, MVT::v8i32, Custom);
1090 setOperationAction(ISD::SMUL_LOHI, MVT::v8i32, Custom);
1091
1092 setOperationAction(ISD::MULHU, MVT::v16i16, HasInt256 ? Legal : Custom);
1093 setOperationAction(ISD::MULHS, MVT::v16i16, HasInt256 ? Legal : Custom);
1094 setOperationAction(ISD::MULHU, MVT::v32i8, Custom);
1095 setOperationAction(ISD::MULHS, MVT::v32i8, Custom);
1096
1097 setOperationAction(ISD::SMAX, MVT::v4i64, Custom);
1098 setOperationAction(ISD::UMAX, MVT::v4i64, Custom);
1099 setOperationAction(ISD::SMIN, MVT::v4i64, Custom);
1100 setOperationAction(ISD::UMIN, MVT::v4i64, Custom);
1101
1102 for (auto VT : { MVT::v32i8, MVT::v16i16, MVT::v8i32 }) {
1103 setOperationAction(ISD::ABS, VT, HasInt256 ? Legal : Custom);
1104 setOperationAction(ISD::SMAX, VT, HasInt256 ? Legal : Custom);
1105 setOperationAction(ISD::UMAX, VT, HasInt256 ? Legal : Custom);
1106 setOperationAction(ISD::SMIN, VT, HasInt256 ? Legal : Custom);
1107 setOperationAction(ISD::UMIN, VT, HasInt256 ? Legal : Custom);
1108 }
1109
1110 if (HasInt256) {
1111 setOperationAction(ISD::SIGN_EXTEND_VECTOR_INREG, MVT::v4i64, Custom);
1112 setOperationAction(ISD::SIGN_EXTEND_VECTOR_INREG, MVT::v8i32, Custom);
1113 setOperationAction(ISD::SIGN_EXTEND_VECTOR_INREG, MVT::v16i16, Custom);
1114
1115 // The custom lowering for UINT_TO_FP for v8i32 becomes interesting
1116 // when we have a 256bit-wide blend with immediate.
1117 setOperationAction(ISD::UINT_TO_FP, MVT::v8i32, Custom);
1118
1119 // AVX2 also has wider vector sign/zero extending loads, VPMOV[SZ]X
1120 for (auto LoadExtOp : { ISD::SEXTLOAD, ISD::ZEXTLOAD }) {
1121 setLoadExtAction(LoadExtOp, MVT::v16i16, MVT::v16i8, Legal);
1122 setLoadExtAction(LoadExtOp, MVT::v8i32, MVT::v8i8, Legal);
1123 setLoadExtAction(LoadExtOp, MVT::v4i64, MVT::v4i8, Legal);
1124 setLoadExtAction(LoadExtOp, MVT::v8i32, MVT::v8i16, Legal);
1125 setLoadExtAction(LoadExtOp, MVT::v4i64, MVT::v4i16, Legal);
1126 setLoadExtAction(LoadExtOp, MVT::v4i64, MVT::v4i32, Legal);
1127 }
1128 }
1129
1130 for (auto VT : { MVT::v4i32, MVT::v8i32, MVT::v2i64, MVT::v4i64,
1131 MVT::v4f32, MVT::v8f32, MVT::v2f64, MVT::v4f64 }) {
1132 setOperationAction(ISD::MLOAD, VT, Legal);
1133 setOperationAction(ISD::MSTORE, VT, Legal);
1134 }
1135
1136 // Extract subvector is special because the value type
1137 // (result) is 128-bit but the source is 256-bit wide.
1138 for (auto VT : { MVT::v16i8, MVT::v8i16, MVT::v4i32, MVT::v2i64,
1139 MVT::v4f32, MVT::v2f64 }) {
1140 setOperationAction(ISD::EXTRACT_SUBVECTOR, VT, Legal);
1141 }
1142
1143 // Custom lower several nodes for 256-bit types.
1144 for (MVT VT : { MVT::v32i8, MVT::v16i16, MVT::v8i32, MVT::v4i64,
1145 MVT::v8f32, MVT::v4f64 }) {
1146 setOperationAction(ISD::BUILD_VECTOR, VT, Custom);
1147 setOperationAction(ISD::VECTOR_SHUFFLE, VT, Custom);
1148 setOperationAction(ISD::VSELECT, VT, Custom);
1149 setOperationAction(ISD::INSERT_VECTOR_ELT, VT, Custom);
1150 setOperationAction(ISD::EXTRACT_VECTOR_ELT, VT, Custom);
1151 setOperationAction(ISD::SCALAR_TO_VECTOR, VT, Custom);
1152 setOperationAction(ISD::INSERT_SUBVECTOR, VT, Legal);
1153 setOperationAction(ISD::CONCAT_VECTORS, VT, Custom);
1154 }
1155
1156 if (HasInt256)
1157 setOperationAction(ISD::VSELECT, MVT::v32i8, Legal);
1158
1159 // Promote v32i8, v16i16, v8i32 select, and, or, xor to v4i64.
1160 for (auto VT : { MVT::v32i8, MVT::v16i16, MVT::v8i32 }) {
1161 setOperationPromotedToType(ISD::AND, VT, MVT::v4i64);
1162 setOperationPromotedToType(ISD::OR, VT, MVT::v4i64);
1163 setOperationPromotedToType(ISD::XOR, VT, MVT::v4i64);
1164 setOperationPromotedToType(ISD::LOAD, VT, MVT::v4i64);
1165 setOperationPromotedToType(ISD::SELECT, VT, MVT::v4i64);
1166 }
1167
1168 if (HasInt256) {
1169 // Custom legalize 2x32 to get a little better code.
1170 setOperationAction(ISD::MGATHER, MVT::v2f32, Custom);
1171 setOperationAction(ISD::MGATHER, MVT::v2i32, Custom);
1172
1173 for (auto VT : { MVT::v4i32, MVT::v8i32, MVT::v2i64, MVT::v4i64,
1174 MVT::v4f32, MVT::v8f32, MVT::v2f64, MVT::v4f64 })
1175 setOperationAction(ISD::MGATHER, VT, Custom);
1176 }
1177 }
4.4.3.3.2.3.3. AVX-512
到1266行,从1039行开始的if块结束,它设置了支持AVX以上指令集目标机器相关指令的行为。接下来,对支持更高级AVX512指令集目标机器进行进一步的设置。
下面的hasAVX512()用于检测目标机器是否支持最基本的AVX-512指令集;
hasBWI()返回true表示目标机器激活了AVX512的BWI(字节与字版本指令);
hasDQI()则是检测是否支持AVX-512DQ指令集;
useAVX512Regs()则表示支持AVX-512DQ,但不支持AVX-512VLX,且首选向量宽度大于256;
hasCDI()则表示支持AVX-512CD(Conflict Detection,冲突检测);
hasVPOPCNTDQ()表示支持AVX-512的VPOPCNT系列指令。
X86TargetLowering::X86TargetLowering(续)
1179 // This block controls legalization of the mask vector sizes that are
1180 // available with AVX512. 512-bit vectors are in a separate block controlled
1181 // by useAVX512Regs.
1182 if (!Subtarget.useSoftFloat() && Subtarget.hasAVX512()) {
1183 addRegisterClass(MVT::v1i1, &X86::VK1RegClass);
1184 addRegisterClass(MVT::v2i1, &X86::VK2RegClass);
1185 addRegisterClass(MVT::v4i1, &X86::VK4RegClass);
1186 addRegisterClass(MVT::v8i1, &X86::VK8RegClass);
1187 addRegisterClass(MVT::v16i1, &X86::VK16RegClass);
1188
1189 setOperationAction(ISD::SELECT, MVT::v1i1, Custom);
1190 setOperationAction(ISD::EXTRACT_VECTOR_ELT, MVT::v1i1, Custom);
1191 setOperationAction(ISD::BUILD_VECTOR, MVT::v1i1, Custom);
1192
1193 setOperationPromotedToType(ISD::FP_TO_SINT, MVT::v8i1, MVT::v8i32);
1194 setOperationPromotedToType(ISD::FP_TO_UINT, MVT::v8i1, MVT::v8i32);
1195 setOperationPromotedToType(ISD::FP_TO_SINT, MVT::v4i1, MVT::v4i32);
1196 setOperationPromotedToType(ISD::FP_TO_UINT, MVT::v4i1, MVT::v4i32);
1197 setOperationAction(ISD::FP_TO_SINT, MVT::v2i1, Custom);
1198 setOperationAction(ISD::FP_TO_UINT, MVT::v2i1, Custom);
1199
1200 // There is no byte sized k-register load or store without AVX512DQ.
1201 if (!Subtarget.hasDQI()) {
1202 setOperationAction(ISD::LOAD, MVT::v1i1, Custom);
1203 setOperationAction(ISD::LOAD, MVT::v2i1, Custom);
1204 setOperationAction(ISD::LOAD, MVT::v4i1, Custom);
1205 setOperationAction(ISD::LOAD, MVT::v8i1, Custom);
1206
1207 setOperationAction(ISD::STORE, MVT::v1i1, Custom);
1208 setOperationAction(ISD::STORE, MVT::v2i1, Custom);
1209 setOperationAction(ISD::STORE, MVT::v4i1, Custom);
1210 setOperationAction(ISD::STORE, MVT::v8i1, Custom);
1211 }
1212
1213 // Extends of v16i1/v8i1/v4i1/v2i1 to 128-bit vectors.
1214 for (auto VT : { MVT::v16i8, MVT::v8i16, MVT::v4i32, MVT::v2i64 }) {
1215 setOperationAction(ISD::SIGN_EXTEND, VT, Custom);
1216 setOperationAction(ISD::ZERO_EXTEND, VT, Custom);
1217 setOperationAction(ISD::ANY_EXTEND, VT, Custom);
1218 }
1219
1220 for (auto VT : { MVT::v2i1, MVT::v4i1, MVT::v8i1, MVT::v16i1 }) {
1221 setOperationAction(ISD::ADD, VT, Custom);
1222 setOperationAction(ISD::SUB, VT, Custom);
1223 setOperationAction(ISD::MUL, VT, Custom);
1224 setOperationAction(ISD::SETCC, VT, Custom);
1225 setOperationAction(ISD::SELECT, VT, Custom);
1226 setOperationAction(ISD::TRUNCATE, VT, Custom);
1227
1228 setOperationAction(ISD::BUILD_VECTOR, VT, Custom);
1229 setOperationAction(ISD::EXTRACT_VECTOR_ELT, VT, Custom);
1230 setOperationAction(ISD::INSERT_VECTOR_ELT, VT, Custom);
1231 setOperationAction(ISD::VECTOR_SHUFFLE, VT, Custom);
1232 setOperationAction(ISD::VSELECT, VT, Expand);
1233 }
1234
1235 setOperationAction(ISD::CONCAT_VECTORS, MVT::v16i1, Custom);
1236 setOperationAction(ISD::CONCAT_VECTORS, MVT::v8i1, Custom);
1237 setOperationAction(ISD::CONCAT_VECTORS, MVT::v4i1, Custom);
1238 setOperationAction(ISD::INSERT_SUBVECTOR, MVT::v2i1, Custom);
1239 setOperationAction(ISD::INSERT_SUBVECTOR, MVT::v4i1, Custom);
1240 setOperationAction(ISD::INSERT_SUBVECTOR, MVT::v8i1, Custom);
1241 setOperationAction(ISD::INSERT_SUBVECTOR, MVT::v16i1, Custom);
1242 for (auto VT : { MVT::v1i1, MVT::v2i1, MVT::v4i1, MVT::v8i1 })
1243 setOperationAction(ISD::EXTRACT_SUBVECTOR, VT, Custom);
1244 }
1245
1246 // This block controls legalization for 512-bit operations with 32/64 bit
1247 // elements. 512-bits can be disabled based on prefer-vector-width and
1248 // required-vector-width function attributes.
1249 if (!Subtarget.useSoftFloat() && Subtarget.useAVX512Regs()) {
1250 addRegisterClass(MVT::v16i32, &X86::VR512RegClass);
1251 addRegisterClass(MVT::v16f32, &X86::VR512RegClass);
1252 addRegisterClass(MVT::v8i64, &X86::VR512RegClass);
1253 addRegisterClass(MVT::v8f64, &X86::VR512RegClass);
1254
1255 for (MVT VT : MVT::fp_vector_valuetypes())
1256 setLoadExtAction(ISD::EXTLOAD, VT, MVT::v8f32, Legal);
1257
1258 for (auto ExtType : {ISD::ZEXTLOAD, ISD::SEXTLOAD}) {
1259 setLoadExtAction(ExtType, MVT::v16i32, MVT::v16i8, Legal);
1260 setLoadExtAction(ExtType, MVT::v16i32, MVT::v16i16, Legal);
1261 setLoadExtAction(ExtType, MVT::v8i64, MVT::v8i8, Legal);
1262 setLoadExtAction(ExtType, MVT::v8i64, MVT::v8i16, Legal);
1263 setLoadExtAction(ExtType, MVT::v8i64, MVT::v8i32, Legal);
1264 }
1265
1266 for (MVT VT : { MVT::v16f32, MVT::v8f64 }) {
1267 setOperationAction(ISD::FNEG, VT, Custom);
1268 setOperationAction(ISD::FABS, VT, Custom);
1269 setOperationAction(ISD::FMA, VT, Legal);
1270 setOperationAction(ISD::FCOPYSIGN, VT, Custom);
1271 }
1272
1273 setOperationAction(ISD::FP_TO_SINT, MVT::v16i32, Legal);
1274 setOperationPromotedToType(ISD::FP_TO_SINT, MVT::v16i16, MVT::v16i32);
1275 setOperationPromotedToType(ISD::FP_TO_SINT, MVT::v16i8, MVT::v16i32);
1276 setOperationPromotedToType(ISD::FP_TO_SINT, MVT::v16i1, MVT::v16i32);
1277 setOperationAction(ISD::FP_TO_UINT, MVT::v16i32, Legal);
1278 setOperationPromotedToType(ISD::FP_TO_UINT, MVT::v16i1, MVT::v16i32);
1279 setOperationPromotedToType(ISD::FP_TO_UINT, MVT::v16i8, MVT::v16i32);
1280 setOperationPromotedToType(ISD::FP_TO_UINT, MVT::v16i16, MVT::v16i32);
1281 setOperationAction(ISD::SINT_TO_FP, MVT::v16i32, Legal);
1282 setOperationAction(ISD::UINT_TO_FP, MVT::v16i32, Legal);
1283
1284 setTruncStoreAction(MVT::v8i64, MVT::v8i8, Legal);
1285 setTruncStoreAction(MVT::v8i64, MVT::v8i16, Legal);
1286 setTruncStoreAction(MVT::v8i64, MVT::v8i32, Legal);
1287 setTruncStoreAction(MVT::v16i32, MVT::v16i8, Legal);
1288 setTruncStoreAction(MVT::v16i32, MVT::v16i16, Legal);
1289
1290 if (!Subtarget.hasVLX()) {
1291 // With 512-bit vectors and no VLX, we prefer to widen MLOAD/MSTORE
1292 // to 512-bit rather than use the AVX2 instructions so that we can use
1293 // k-masks.
1294 for (auto VT : {MVT::v4i32, MVT::v8i32, MVT::v2i64, MVT::v4i64,
1295 MVT::v4f32, MVT::v8f32, MVT::v2f64, MVT::v4f64}) {
1296 setOperationAction(ISD::MLOAD, VT, Custom);
1297 setOperationAction(ISD::MSTORE, VT, Custom);
1298 }
1299 }
1300
1301 setOperationAction(ISD::TRUNCATE, MVT::v8i32, Custom);
1302 setOperationAction(ISD::TRUNCATE, MVT::v16i16, Custom);
1303 setOperationAction(ISD::ZERO_EXTEND, MVT::v16i32, Custom);
1304 setOperationAction(ISD::ZERO_EXTEND, MVT::v8i64, Custom);
1305 setOperationAction(ISD::ANY_EXTEND, MVT::v16i32, Custom);
1306 setOperationAction(ISD::ANY_EXTEND, MVT::v8i64, Custom);
1307 setOperationAction(ISD::SIGN_EXTEND, MVT::v16i32, Custom);
1308 setOperationAction(ISD::SIGN_EXTEND, MVT::v8i64, Custom);
1309
1310 for (auto VT : { MVT::v16f32, MVT::v8f64 }) {
1311 setOperationAction(ISD::FFLOOR, VT, Legal);
1312 setOperationAction(ISD::FCEIL, VT, Legal);
1313 setOperationAction(ISD::FTRUNC, VT, Legal);
1314 setOperationAction(ISD::FRINT, VT, Legal);
1315 setOperationAction(ISD::FNEARBYINT, VT, Legal);
1316 }
1317
1318 setOperationAction(ISD::SIGN_EXTEND_VECTOR_INREG, MVT::v8i64, Custom);
1319 setOperationAction(ISD::SIGN_EXTEND_VECTOR_INREG, MVT::v16i32, Custom);
1320
1321 // Without BWI we need to use custom lowering to handle MVT::v64i8 input.
1322 setOperationAction(ISD::SIGN_EXTEND_VECTOR_INREG, MVT::v64i8, Custom);
1323 setOperationAction(ISD::ZERO_EXTEND_VECTOR_INREG, MVT::v64i8, Custom);
1324
1325 setOperationAction(ISD::CONCAT_VECTORS, MVT::v8f64, Custom);
1326 setOperationAction(ISD::CONCAT_VECTORS, MVT::v8i64, Custom);
1327 setOperationAction(ISD::CONCAT_VECTORS, MVT::v16f32, Custom);
1328 setOperationAction(ISD::CONCAT_VECTORS, MVT::v16i32, Custom);
1329
1330 setOperationAction(ISD::MUL, MVT::v8i64, Custom);
1331 setOperationAction(ISD::MUL, MVT::v16i32, Legal);
1332
1333 setOperationAction(ISD::UMUL_LOHI, MVT::v16i32, Custom);
1334 setOperationAction(ISD::SMUL_LOHI, MVT::v16i32, Custom);
1335
1336 setOperationAction(ISD::SELECT, MVT::v8f64, Custom);
1337 setOperationAction(ISD::SELECT, MVT::v8i64, Custom);
1338 setOperationAction(ISD::SELECT, MVT::v16f32, Custom);
1339
1340 for (auto VT : { MVT::v16i32, MVT::v8i64 }) {
1341 setOperationAction(ISD::SMAX, VT, Legal);
1342 setOperationAction(ISD::UMAX, VT, Legal);
1343 setOperationAction(ISD::SMIN, VT, Legal);
1344 setOperationAction(ISD::UMIN, VT, Legal);
1345 setOperationAction(ISD::ABS, VT, Legal);
1346 setOperationAction(ISD::SRL, VT, Custom);
1347 setOperationAction(ISD::SHL, VT, Custom);
1348 setOperationAction(ISD::SRA, VT, Custom);
1349 setOperationAction(ISD::CTPOP, VT, Custom);
1350 setOperationAction(ISD::CTTZ, VT, Custom);
1351 setOperationAction(ISD::ROTL, VT, Custom);
1352 setOperationAction(ISD::ROTR, VT, Custom);
1353 setOperationAction(ISD::SETCC, VT, Custom);
1354
1355 // The condition codes aren't legal in SSE/AVX and under AVX512 we use
1356 // setcc all the way to isel and prefer SETGT in some isel patterns.
1357 setCondCodeAction(ISD::SETLT, VT, Custom);
1358 setCondCodeAction(ISD::SETLE, VT, Custom);
1359 }
1360
1361 // Need to promote to 64-bit even though we have 32-bit masked instructions
1362 // because the IR optimizers rearrange bitcasts around logic ops leaving
1363 // too many variations to handle if we don't promote them.
1364 setOperationPromotedToType(ISD::AND, MVT::v16i32, MVT::v8i64);
1365 setOperationPromotedToType(ISD::OR, MVT::v16i32, MVT::v8i64);
1366 setOperationPromotedToType(ISD::XOR, MVT::v16i32, MVT::v8i64);
1367
1368 if (Subtarget->hasCDI()) {
1369 setOperationAction(ISD::SINT_TO_FP, MVT::v8i64, Legal);
1370 setOperationAction(ISD::UINT_TO_FP, MVT::v8i64, Legal);
1371 setOperationAction(ISD::FP_TO_SINT, MVT::v8i64, Legal);
1372 setOperationAction(ISD::FP_TO_UINT, MVT::v8i64, Legal);
1373
1374 setOperationAction(ISD::MUL, MVT::v8i64, Legal);
1375 }
1376
1377 if (Subtarget->hasDQI()) {
1378 // NonVLX sub-targets extend 128/256 vectors to use the 512 version.
1379 for (auto VT : { MVT::v16i32, MVT::v8i64} ) {
1380 setOperationAction(ISD::CTLZ, VT, Legal);
1381 setOperationAction(ISD::CTTZ_ZERO_UNDEF, VT, Custom);
1382 }
1383 }
1384
1385 if (Subtarget.hasVPOPCNTDQ()) {
1386 for (auto VT : { MVT::v16i32, MVT::v8i64 })
1387 setOperationAction(ISD::CTPOP, VT, Legal);
1388 }
1389
1390 // Extract subvector is special because the value type
1391 // (result) is 256/128-bit but the source is 512-bit wide.
1392 // 128-bit was made Legal under AVX1.
1393 for (auto VT : { MVT::v32i8, MVT::v16i16, MVT::v8i32, MVT::v4i64,
1394 MVT::v8f32, MVT::v4f64 })
1395 setOperationAction(ISD::EXTRACT_SUBVECTOR, VT, Legal);
1396
1397 for (auto VT : { MVT::v16i32, MVT::v8i64, MVT::v16f32, MVT::v8f64 }) {
1398 setOperationAction(ISD::VECTOR_SHUFFLE, VT, Custom);
1399 setOperationAction(ISD::INSERT_VECTOR_ELT, VT, Custom);
1400 setOperationAction(ISD::BUILD_VECTOR, VT, Custom);
1401 setOperationAction(ISD::VSELECT, VT, Custom);
1402 setOperationAction(ISD::EXTRACT_VECTOR_ELT, VT, Custom);
1403 setOperationAction(ISD::SCALAR_TO_VECTOR, VT, Custom);
1404 setOperationAction(ISD::INSERT_SUBVECTOR, VT, Legal);
1405 setOperationAction(ISD::MLOAD, VT, Legal);
1406 setOperationAction(ISD::MSTORE, VT, Legal);
1407 setOperationAction(ISD::MGATHER, VT, Custom);
1408 setOperationAction(ISD::MSCATTER, VT, Custom);
1409 }
1410 for (auto VT : { MVT::v64i8, MVT::v32i16, MVT::v16i32 }) {
1411 setOperationPromotedToType(ISD::LOAD, VT, MVT::v8i64);
1412 setOperationPromotedToType(ISD::SELECT, VT, MVT::v8i64);
1413 }
1414
1415 // Need to custom split v32i16/v64i8 bitcasts.
1416 if (!Subtarget.hasBWI()) {
1417 setOperationAction(ISD::BITCAST, MVT::v32i16, Custom);
1418 setOperationAction(ISD::BITCAST, MVT::v64i8, Custom);
1419 }
1420 } // has AVX-512
1421
1422 // This block controls legalization for operations that don't have
1423 // pre-AVX512 equivalents. Without VLX we use 512-bit operations for
1424 // narrower widths.
1425 if (!Subtarget.useSoftFloat() && Subtarget.hasAVX512()) {
1426 // These operations are handled on non-VLX by artificially widening in
1427 // isel patterns.
1428 // TODO: Custom widen in lowering on non-VLX and drop the isel patterns?
1429
1430 setOperationAction(ISD::FP_TO_UINT, MVT::v8i32, Legal);
1431 setOperationAction(ISD::FP_TO_UINT, MVT::v4i32, Legal);
1432 setOperationAction(ISD::FP_TO_UINT, MVT::v2i32, Custom);
1433 setOperationAction(ISD::UINT_TO_FP, MVT::v8i32, Legal);
1434 setOperationAction(ISD::UINT_TO_FP, MVT::v4i32, Legal);
1435
1436 for (auto VT : { MVT::v2i64, MVT::v4i64 }) {
1437 setOperationAction(ISD::SMAX, VT, Legal);
1438 setOperationAction(ISD::UMAX, VT, Legal);
1439 setOperationAction(ISD::SMIN, VT, Legal);
1440 setOperationAction(ISD::UMIN, VT, Legal);
1441 setOperationAction(ISD::ABS, VT, Legal);
1442 }
1443
1444 for (auto VT : { MVT::v4i32, MVT::v8i32, MVT::v2i64, MVT::v4i64 }) {
1445 setOperationAction(ISD::ROTL, VT, Custom);
1446 setOperationAction(ISD::ROTR, VT, Custom);
1447 }
1448
1449 // Custom legalize 2x32 to get a little better code.
1450 setOperationAction(ISD::MSCATTER, MVT::v2f32, Custom);
1451 setOperationAction(ISD::MSCATTER, MVT::v2i32, Custom);
1452
1453 for (auto VT : { MVT::v4i32, MVT::v8i32, MVT::v2i64, MVT::v4i64,
1454 MVT::v4f32, MVT::v8f32, MVT::v2f64, MVT::v4f64 })
1455 setOperationAction(ISD::MSCATTER, VT, Custom);
1456
1457 if (Subtarget.hasDQI()) {
1458 for (auto VT : { MVT::v2i64, MVT::v4i64 }) {
1459 setOperationAction(ISD::SINT_TO_FP, VT, Legal);
1460 setOperationAction(ISD::UINT_TO_FP, VT, Legal);
1461 setOperationAction(ISD::FP_TO_SINT, VT, Legal);
1462 setOperationAction(ISD::FP_TO_UINT, VT, Legal);
1463
1464 setOperationAction(ISD::MUL, VT, Legal);
1465 }
1466 }
1467
1468 if (Subtarget.hasCDI()) {
1469 for (auto VT : { MVT::v4i32, MVT::v8i32, MVT::v2i64, MVT::v4i64 }) {
1470 setOperationAction(ISD::CTLZ, VT, Legal);
1471 setOperationAction(ISD::CTTZ_ZERO_UNDEF, VT, Custom);
1472 }
1473 } // Subtarget.hasCDI()
1474
1475 if (Subtarget.hasVPOPCNTDQ()) {
1476 for (auto VT : { MVT::v4i32, MVT::v8i32, MVT::v2i64, MVT::v4i64 })
1477 setOperationAction(ISD::CTPOP, VT, Legal);
1478 }
1479 }
1480
1481 // This block control legalization of v32i1/v64i1 which are available with
1482 // AVX512BW. 512-bit v32i16 and v64i8 vector legalization is controlled with
1483 // useBWIRegs.
1484 if (!Subtarget->useSoftFloat() && Subtarget->hasBWI()) {
1485 addRegisterClass(MVT::v32i1, &X86::VK32RegClass);
1486 addRegisterClass(MVT::v64i1, &X86::VK64RegClass);
1487
1488 for (auto VT : { MVT::v32i1, MVT::v64i1 }) {
1489 setOperationAction(ISD::ADD, VT, Custom);
1490 setOperationAction(ISD::SUB, VT, Custom);
1491 setOperationAction(ISD::MUL, VT, Custom);
1492 setOperationAction(ISD::VSELECT, VT, Expand);
1493
1494 setOperationAction(ISD::TRUNCATE, VT, Custom);
1495 setOperationAction(ISD::SETCC, VT, Custom);
1496 setOperationAction(ISD::EXTRACT_VECTOR_ELT, VT, Custom);
1497 setOperationAction(ISD::INSERT_VECTOR_ELT, VT, Custom);
1498 setOperationAction(ISD::SELECT, VT, Custom);
1499 setOperationAction(ISD::BUILD_VECTOR, VT, Custom);
1500 setOperationAction(ISD::VECTOR_SHUFFLE, VT, Custom);
1501 }
1502
1503 setOperationAction(ISD::CONCAT_VECTORS, MVT::v32i1, Custom);
1504 setOperationAction(ISD::CONCAT_VECTORS, MVT::v64i1, Custom);
1505 setOperationAction(ISD::INSERT_SUBVECTOR, MVT::v32i1, Custom);
1506 setOperationAction(ISD::INSERT_SUBVECTOR, MVT::v64i1, Custom);
1507 for (auto VT : { MVT::v16i1, MVT::v32i1 })
1508 setOperationAction(ISD::EXTRACT_SUBVECTOR, VT, Custom);
1509
1510 // Extends from v32i1 masks to 256-bit vectors.
1511 setOperationAction(ISD::SIGN_EXTEND, MVT::v32i8, Custom);
1512 setOperationAction(ISD::ZERO_EXTEND, MVT::v32i8, Custom);
1513 setOperationAction(ISD::ANY_EXTEND, MVT::v32i8, Custom);
1514 }
1515
1516 // This block controls legalization for v32i16 and v64i8. 512-bits can be
1517 // disabled based on prefer-vector-width and required-vector-width function
1518 // attributes.
1519 if (!Subtarget.useSoftFloat() && Subtarget.useBWIRegs()) {
1520 addRegisterClass(MVT::v32i16, &X86::VR512RegClass);
1521 addRegisterClass(MVT::v64i8, &X86::VR512RegClass);
1522
1523 // Extends from v64i1 masks to 512-bit vectors.
1524 setOperationAction(ISD::SIGN_EXTEND, MVT::v64i8, Custom);
1525 setOperationAction(ISD::ZERO_EXTEND, MVT::v64i8, Custom);
1526 setOperationAction(ISD::ANY_EXTEND, MVT::v64i8, Custom);
1527
1528 setOperationAction(ISD::MUL, MVT::v32i16, Legal);
1529 setOperationAction(ISD::MUL, MVT::v64i8, Custom);
1530 setOperationAction(ISD::MULHS, MVT::v32i16, Legal);
1531 setOperationAction(ISD::MULHU, MVT::v32i16, Legal);
1532 setOperationAction(ISD::MULHS, MVT::v64i8, Custom);
1533 setOperationAction(ISD::MULHU, MVT::v64i8, Custom);
1534 setOperationAction(ISD::CONCAT_VECTORS, MVT::v32i16, Custom);
1535 setOperationAction(ISD::CONCAT_VECTORS, MVT::v64i8, Custom);
1536 setOperationAction(ISD::INSERT_SUBVECTOR, MVT::v32i16, Legal);
1537 setOperationAction(ISD::INSERT_SUBVECTOR, MVT::v64i8, Legal);
1538 setOperationAction(ISD::EXTRACT_VECTOR_ELT, MVT::v32i16, Custom);
1539 setOperationAction(ISD::EXTRACT_VECTOR_ELT, MVT::v64i8, Custom);
1540 setOperationAction(ISD::SCALAR_TO_VECTOR, MVT::v32i16, Custom);
1541 setOperationAction(ISD::SCALAR_TO_VECTOR, MVT::v64i8, Custom);
1542 setOperationAction(ISD::SIGN_EXTEND, MVT::v32i16, Custom);
1543 setOperationAction(ISD::ZERO_EXTEND, MVT::v32i16, Custom);
1544 setOperationAction(ISD::ANY_EXTEND, MVT::v32i16, Custom);
1545 setOperationAction(ISD::VECTOR_SHUFFLE, MVT::v32i16, Custom);
1546 setOperationAction(ISD::VECTOR_SHUFFLE, MVT::v64i8, Custom);
1547 setOperationAction(ISD::INSERT_VECTOR_ELT, MVT::v32i16, Custom);
1548 setOperationAction(ISD::INSERT_VECTOR_ELT, MVT::v64i8, Custom);
1549 setOperationAction(ISD::TRUNCATE, MVT::v32i8, Custom);
1550 setOperationAction(ISD::BITREVERSE, MVT::v64i8, Custom);
1551
1552 setOperationAction(ISD::SIGN_EXTEND_VECTOR_INREG, MVT::v32i16, Custom);
1553
1554 setTruncStoreAction(MVT::v32i16, MVT::v32i8, Legal);
1555
1556 for (auto VT : { MVT::v64i8, MVT::v32i16 }) {
1557 setOperationAction(ISD::BUILD_VECTOR, VT, Custom);
1558 setOperationAction(ISD::VSELECT, VT, Custom);
1559 setOperationAction(ISD::ABS, VT, Legal);
1560 setOperationAction(ISD::SRL, VT, Custom);
1561 setOperationAction(ISD::SHL, VT, Custom);
1562 setOperationAction(ISD::SRA, VT, Custom);
1563 setOperationAction(ISD::MLOAD, VT, Legal);
1564 setOperationAction(ISD::MSTORE, VT, Legal);
1565 setOperationAction(ISD::CTPOP, VT, Custom);
1566 setOperationAction(ISD::CTTZ, VT, Custom);
1567 setOperationAction(ISD::CTLZ, VT, Custom);
1568 setOperationAction(ISD::SMAX, VT, Legal);
1569 setOperationAction(ISD::UMAX, VT, Legal);
1570 setOperationAction(ISD::SMIN, VT, Legal);
1571 setOperationAction(ISD::UMIN, VT, Legal);
1572 setOperationAction(ISD::SETCC, VT, Custom);
1573
1574 setOperationPromotedToType(ISD::AND, VT, MVT::v8i64);
1575 setOperationPromotedToType(ISD::OR, VT, MVT::v8i64);
1576 setOperationPromotedToType(ISD::XOR, VT, MVT::v8i64);
1577 }
1578
1579 for (auto ExtType : {ISD::ZEXTLOAD, ISD::SEXTLOAD}) {
1580 setLoadExtAction(ExtType, MVT::v32i16, MVT::v32i8, Legal);
1581 }
1582
1583 if (Subtarget.hasBITALG()) {
1584 for (auto VT : { MVT::v64i8, MVT::v32i16 })
1585 setOperationAction(ISD::CTPOP, VT, Legal);
1586 }
1587 }
1588
1589 if (!Subtarget.useSoftFloat() && Subtarget.hasBWI()) {
1590 for (auto VT : { MVT::v32i8, MVT::v16i8, MVT::v16i16, MVT::v8i16 }) {
1591 setOperationAction(ISD::MLOAD, VT, Subtarget.hasVLX() ? Legal : Custom);
1592 setOperationAction(ISD::MSTORE, VT, Subtarget.hasVLX() ? Legal : Custom);
1593 }
1594
1595 // These operations are handled on non-VLX by artificially widening in
1596 // isel patterns.
1597 // TODO: Custom widen in lowering on non-VLX and drop the isel patterns?
1598
1599 if (Subtarget.hasBITALG()) {
1600 for (auto VT : { MVT::v16i8, MVT::v32i8, MVT::v8i16, MVT::v16i16 })
1601 setOperationAction(ISD::CTPOP, VT, Legal);
1602 }
1603 }
上面1583/1599行的hasBITALG()返回true表示支持AVX-512字节/字比特操作的VPOPCNTDQ指令扩展。
接下来则是通过setTargetDAGCombine()设置通过TargetDAGCombineArray容器记录的期望回调PerformDAGCombine()的LLVM IR操作(这与X86TargetLowering::PerformDAGCombine()对应)。
X86TargetLowering::X86TargetLowering(续)
1703 // We have target-specific dag combine patterns for the following nodes:
1704 setTargetDAGCombine(ISD::VECTOR_SHUFFLE);
1705 setTargetDAGCombine(ISD::SCALAR_TO_VECTOR);
1706 setTargetDAGCombine(ISD::EXTRACT_VECTOR_ELT);
1707 setTargetDAGCombine(ISD::INSERT_SUBVECTOR);
1706 setTargetDAGCombine(ISD::EXTRACT_SUBVECTOR);
1709 setTargetDAGCombine(ISD::BITCAST);
1710 setTargetDAGCombine(ISD::VSELECT);
1711 setTargetDAGCombine(ISD::SELECT);
1712 setTargetDAGCombine(ISD::SHL);
1713 setTargetDAGCombine(ISD::SRA);
1714 setTargetDAGCombine(ISD::SRL);
1715 setTargetDAGCombine(ISD::OR);
1716 setTargetDAGCombine(ISD::AND);
1717 setTargetDAGCombine(ISD::ADD);
1718 setTargetDAGCombine(ISD::FADD);
1719 setTargetDAGCombine(ISD::FSUB);
1720 setTargetDAGCombine(ISD::FNEG);
1721 setTargetDAGCombine(ISD::FMA);
1722 setTargetDAGCombine(ISD::FMINNUM);
1723 setTargetDAGCombine(ISD::FMAXNUM);
1724 setTargetDAGCombine(ISD::SUB);
1725 setTargetDAGCombine(ISD::LOAD);
1726 setTargetDAGCombine(ISD::MLOAD);
1727 setTargetDAGCombine(ISD::STORE);
1728 setTargetDAGCombine(ISD::MSTORE);
1729 setTargetDAGCombine(ISD::TRUNCATE);
1730 setTargetDAGCombine(ISD::ZERO_EXTEND);
1731 setTargetDAGCombine(ISD::ANY_EXTEND);
1732 setTargetDAGCombine(ISD::SIGN_EXTEND);
1733 setTargetDAGCombine(ISD::SIGN_EXTEND_INREG);
1734 setTargetDAGCombine(ISD::SIGN_EXTEND_VECTOR_INREG);
1735 setTargetDAGCombine(ISD::ZERO_EXTEND_VECTOR_INREG);
1736 setTargetDAGCombine(ISD::SINT_TO_FP);
1737 setTargetDAGCombine(ISD::UINT_TO_FP);
1738 setTargetDAGCombine(ISD::SETCC);
1739 setTargetDAGCombine(ISD::MUL);
1740 setTargetDAGCombine(ISD::XOR);
1741 setTargetDAGCombine(ISD::MSCATTER);
1742 setTargetDAGCombine(ISD::MGATHER);
1743
1744 computeRegisterProperties(Subtarget->getRegisterInfo());
1745
1746 MaxStoresPerMemset = 16; // For @llvm.memset -> sequence of stores
1747 MaxStoresPerMemsetOptSize = 8;
1748 MaxStoresPerMemcpy = 8; // For @llvm.memcpy -> sequence of stores
1749 MaxStoresPerMemcpyOptSize = 4;
1750 MaxStoresPerMemmove = 8; // For @llvm.memmove -> sequence of stores
1751 MaxStoresPerMemmoveOptSize = 4;
1752
1753 // TODO: These control memcmp expansion in CGP and could be raised higher, but
1754 // that needs to benchmarked and balanced with the potential use of vector
1755 // load/store types (PR33329, PR33914).
1756 MaxLoadsPerMemcmp = 2;
1757 MaxLoadsPerMemcmpOptSize = 2;
1758
1759 // Set loop alignment to 2^ExperimentalPrefLoopAlignment bytes (default: 2^4).
1760 setPrefLoopAlignment(ExperimentalPrefLoopAlignment);
1761
1762 // An out-of-order CPU can speculatively execute past a predictable branch,
1763 // but a conditional move could be stalled by an expensive earlier operation.
1764 PredictableSelectIsExpensive = Subtarget.getSchedModel().isOutOfOrder();
1765 EnableExtLdPromotion = true;
1766 setPrefFunctionAlignment(4); // 2^4 bytes.
1767
1768 verifyIntrinsicTables();
1769 }
最后是改写诸如MaxStoresPerMemset这样的设置。其中ExperimentalPrefLoopAlignment可由选项-x86-experimental-pref-loop-alignment设置,缺省值为16。它设置循环对齐大小。另外,如果目标机器支持乱序执行,把PredictableSelectIsExpensive设为true,因为乱序CPU可以试探执行一个预测分支后的代码,但条件移动(所谓的select)会被前面的操作阻止。
相关文章:
)
LLVM学习笔记(63)
4.4.3.3.2.3. 向量操作数类型的处理 下面开始处理向量类型。在默认情形下这些操作都会拆分为更小的操作或者调用库。 X86TargetLowering::X86TargetLowering(续) 667 // Some FP actions are always expanded for vector types. 668 for…...

【python+requests】接口自动化测试
这两天一直在找直接用python做接口自动化的方法,在网上也搜了一些博客参考,今天自己动手试了一下。 一、整体结构 上图是项目的目录结构,下面主要介绍下每个目录的作用。 Common:公共方法:主要放置公共的操作的类,比如数据库sql…...
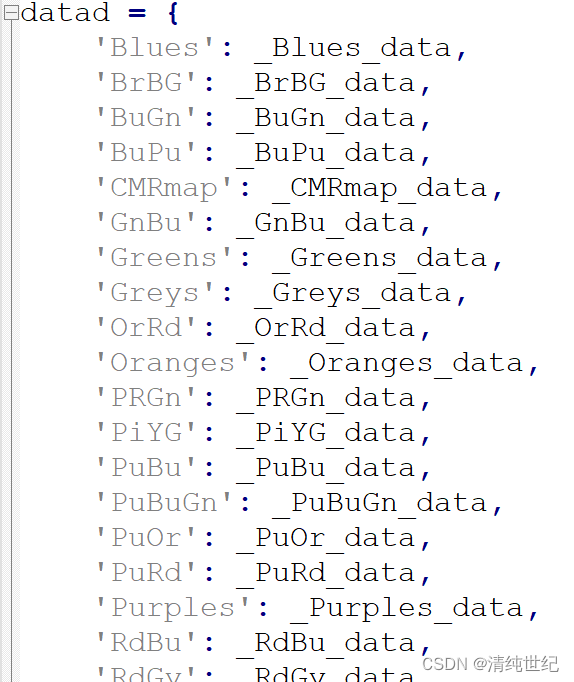
plt创建指定色系
1、创建不连续色系 import matplotlib.pyplot as plt from matplotlib.colors import ListedColormap# 定义颜色的RGB值 colors [(0.2, 0.4, 0.6), # 蓝色(0.8, 0.1, 0.3), # 红色(0.5, 0.7, 0.2),(0.3,0.5,0.8)] # 绿色# 创建色系 cmap ListedColormap(colors)# 绘制…...
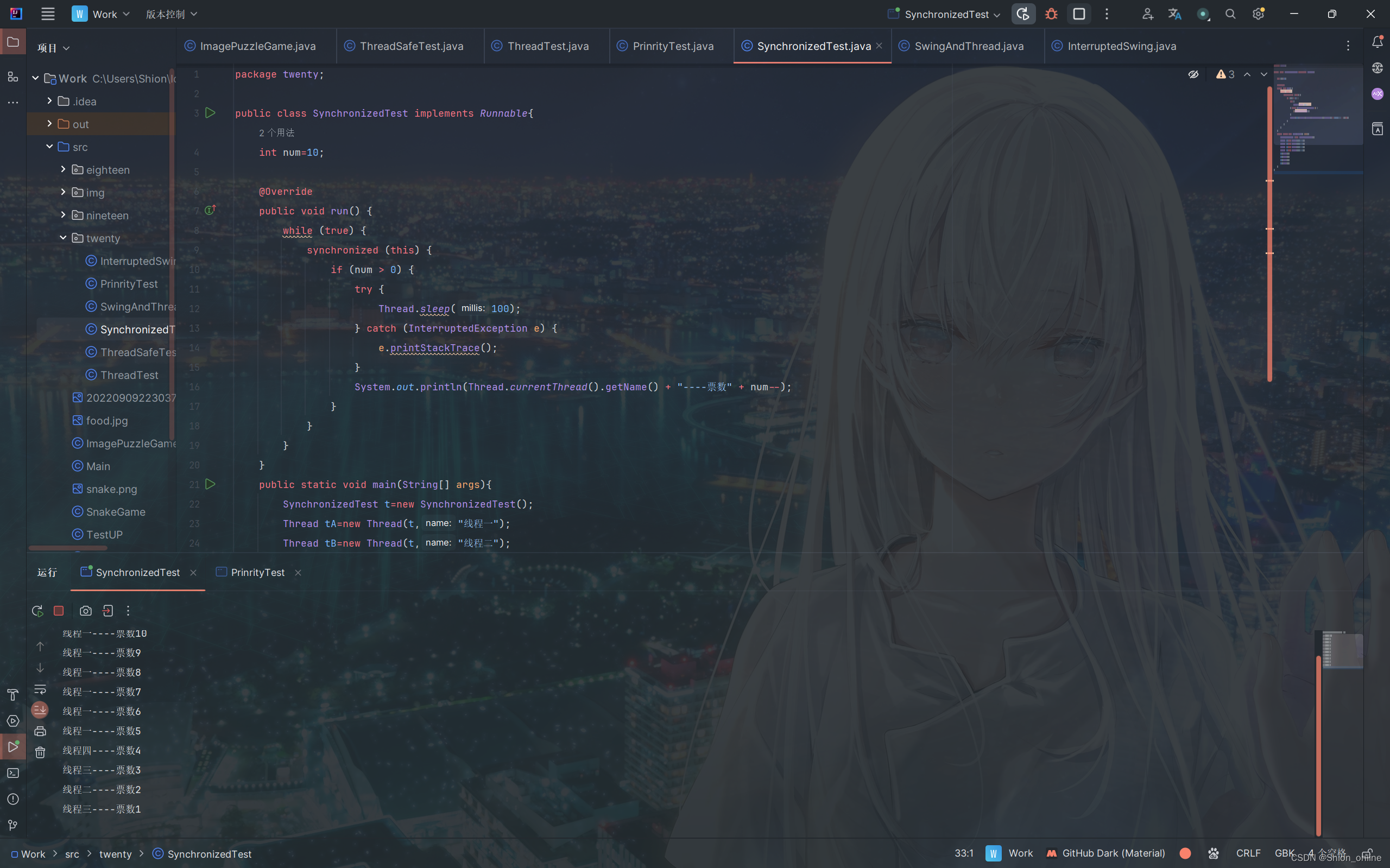
Java多线程-第20章
Java多线程-第20章 1.创建线程 Java是一种支持多线程编程的编程语言。多线程是指在同一程序中同时执行多个独立任务的能力。在Java中,线程是一种轻量级的子进程,它是程序中的最小执行单元。Java的多线程编程可以通过两种方式实现:继承Threa…...

寿险公司通过开源治理保障数字创新,安全打通高质量服务新通道
某寿险公司致力于为消费者提供人性化的产品和服务,在中国保险市场中始终保持前列。该寿险公司以挖掘和满足客户需求为出发点,从产品开发、渠道销售、运营流程和售后服务等各环节,借助数字化工具,不断地努力探索并提升服务品质。 精…...

SpringBoot中的部分注解
1.SpringBoot/spring SpringBootApplication: 包含Configuration、EnableAutoConfiguration、ComponentScan通常用在主类上; Repository: 用于标注数据访问组件,即DAO组件; Service: 用于标注业务层组件; RestController: 用…...

蓝桥杯-02-蓝桥杯C/C++组考点与14届真题
文章目录 蓝桥杯C/C组考点与14届真题参考资源C/C组考点1. 组别2. 竞赛赛程3. 竞赛形式4. 参赛选手机器环境5. 试题形式5.1. 结果填空题5.2. 编程大题 6. 试题考查范围7. 答案提交8. 评分9. 样题样题 1:矩形切割(结果填空题)样题 2:…...

计算机杂谈系列精讲100篇-【计算机应用】关于TensorFlow和PyTorch的一些看法
目录 前言 知识储备 PyTorch使用高频代码 导入包和版本查询...

Uni-App知识点
文章目录 一、事件总线二、什么是事件总线三、触发事件1、监听事件2、只监听一次3、移除监听4、触发事件注意事项5、代码示例6、注意事项 一、事件总线 除了父子组件传参之外,兄弟组件之间共享信息也是我们经常会遇到的。如果遇到这类问题,我们现在可以…...

Postman如何使用(四):接口测试
一.接口 1.程序内部接口:方法与方法之间,模块与模块之间的交互,程序内部抛出的接口,比如bbs系统,有登录模块,发帖模块等等,那你要发帖就必须先登录,那么这两个模块就得有交互&#…...
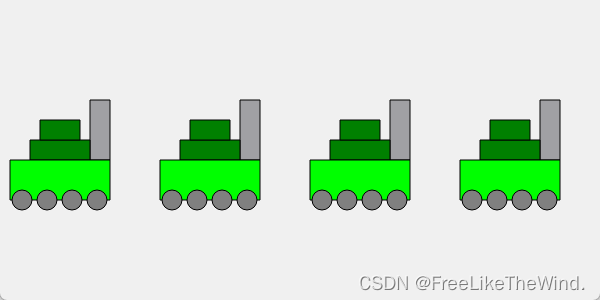
【Qt绘图】之绘制坦克
使用绘图事件,绘制坦克。 效果 效果很逼真,想象力,有没有。 示例 代码像诗一样优雅,有没有。 包含头文件 #include <QApplication> #include <QWidget> #include <QPainter>绘制坦克类 class TankWidge…...
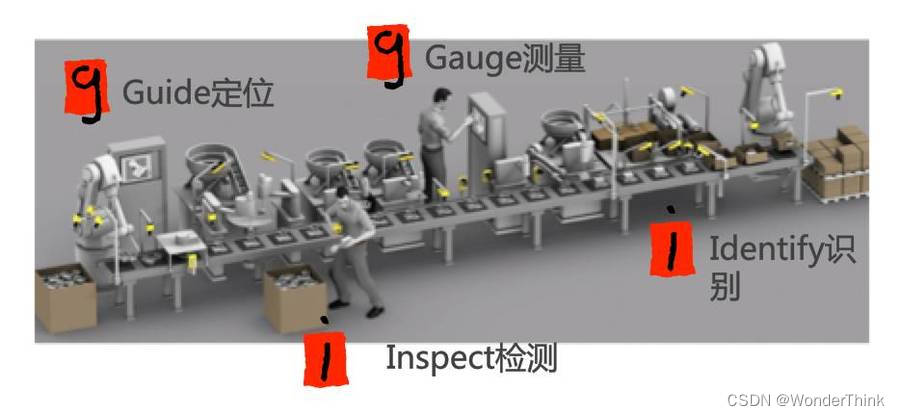
【机器视觉技术栈】- 机器视觉基础
1.1 为什么采用机器视觉 人眼与机器视觉对比 人眼机器视觉精确性差,64灰度级,不能分辨小于100微米的目标强,256灰度级,可检测微米级目标速度慢,无法看清间隔小于40毫秒的运动目标快,快门时间可达10微秒适…...

Arkts开发UIAbility组件生命周期启动模式开发详解【鸿蒙专栏-19】
文章目录 HarmonyOS UIAbility组件详解UIAbility组件概述声明配置UIAbility组件生命周期Create状态WindowStageCreate和WindowStageDestroy状态Foreground和Background状态Destroy状态UIAbility组件启动模式Singleton启动模式Standard启动模式Specified启动模式HarmonyOS UIAbi…...
力扣295. 数据流的中位数(java,堆解法)
Problem: 295. 数据流的中位数 文章目录 题目描述思路解题方法复杂度Code 题目描述 思路 由于该题目的数据是动态的我们可以维护两个堆来解决该问题 1.维护一个大顶堆,一个小顶堆 2.每个堆中元素个数接近n/2;如果n是偶数,两个堆中的数据个数…...

open3d-点云及其操作
open3d提供了一个专门用于点云的数据结构 PointCloud。 class PointCloud(Geometry3D):color # 颜色normals # 法向量points # 点云def __init__(self, *args, **kwargs):"""__init__(*args, **kwargs)Overloaded function.1. __init__(self: open3d.cpu.py…...

无人机助力电力设备螺母缺销智能检测识别,python基于YOLOv7开发构建电力设备螺母缺销高分辨率图像小目标检测系统
传统作业场景下电力设备的运维和维护都是人工来完成的,随着现代技术科技手段的不断发展,基于无人机航拍飞行的自动智能化电力设备问题检测成为了一种可行的手段,本文的核心内容就是基于YOLOv7来开发构建电力设备螺母缺销检测识别系统…...
如何使用Python的Open3D开源库进行三维数据处理
简介 在本文中,我提供了一个关于如何使用Python的Open3D库(一个用于3D数据处理的开源库)来探索、处理和可视化3D模型的快速演练。 使用Open3D可视化的3D模型(链接https://sketchfab.com/3d-models/tesla-model-s-plaid-9de8855fa…...

HarmonyOS应用开发者基础认证试题
判断题 1.Ability是系统调度应用的最小单元,是能够完成一个独立功能的组件。一个应用可以包含一个或多个Ability。(true) 2.Tabs组件仅可包含子组件TabsContent,每一个页签对应一个内容视图即TabContet组件。(true) 3.使用http模块发起网络请求时&#…...
和光学防抖(OIS))
Android Camera2开启电子防抖(EIS)和光学防抖(OIS)
刚好当前项目有录像功能,使用了第三方框架是基于Camera2引擎开发,当使用 Camera2 API 开发相机应用时,启用和关闭 EIS(电子防抖)是一个重要的功能。EIS 可以帮助减少相机拍摄时的抖动,从而提高图像和视频的…...

劲爆:Sam Altman 回归CEO专访确认Q*的存在
每周跟踪AI热点新闻动向和震撼发展 想要探索生成式人工智能的前沿进展吗?订阅我们的简报,深入解析最新的技术突破、实际应用案例和未来的趋势。与全球数同行一同,从行业内部的深度分析和实用指南中受益。不要错过这个机会,成为AI领…...

在多模型间切换使用时对响应速度与一致性的感受
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 在多模型间切换使用时对响应速度与一致性的感受 作为一名需要频繁调用大模型API的开发者,我的日常工作离不开与各类模型…...

构建企业内部知识问答Agent时如何借助Taotoken降低模型依赖风险
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 构建企业内部知识问答Agent时如何借助Taotoken降低模型依赖风险 应用场景类,企业在开发基于大模型的内部分析Agent时&a…...

暗黑破坏神2终极角色编辑器:打造完美角色的完整指南
暗黑破坏神2终极角色编辑器:打造完美角色的完整指南 【免费下载链接】diablo_edit Diablo II Character editor. 项目地址: https://gitcode.com/gh_mirrors/di/diablo_edit 想要在暗黑破坏神2中体验完美的角色构建吗?厌倦了重复刷装备的枯燥过程…...

Apache Camel 企业级集成框架技术深度解析
Apache Camel 企业级集成框架技术深度解析 【免费下载链接】camelinaction2 :camel: This project hosts the source code for the examples of the Camel in Action 2nd ed book :closed_book: written by Claus Ibsen and Jonathan Anstey. 项目地址: https://gitcode.com/…...

Mac NTFS读写终极指南:Free NTFS for Mac完整解决方案
Mac NTFS读写终极指南:Free NTFS for Mac完整解决方案 【免费下载链接】Free-NTFS-for-Mac Nigate: An open-source NTFS utility for Mac. It supports all Mac models (Intel and Apple Silicon), providing full read-write access, mounting, and management fo…...

Postman接口测试实战:48小时掌握状态码、JSON与断言
1. 这不是又一篇“点点点就完事”的接口测试入门“接口测试小白入门”——光是看到这七个字,我手边的咖啡杯就晃了三下。过去三年,我带过27个刚转行进测试岗的新人,其中21个在入职第一周就卡在“Postman怎么发请求”这一步;还有4个…...

皮线、裸纤总是分不清?试试这个算法一键校准技巧
不知道你有没有经历过这种工地上的"崩溃瞬间":大热天蹲在居民楼昏暗的楼道里,蚊子在耳边嗡嗡叫,你手里正拉着一根刚从住户门缝里拽出来的皮线光缆,准备跟分纤箱引出来的单模裸纤做熔接。结果放进机器,合上盖…...
)
逆向思维拆解:我是如何通过AST“翻译”极验4混淆代码的逻辑的(含控制流平坦化详解)
逆向工程实战:用AST解析技术破解JavaScript混淆的艺术 当面对一团被精心混淆过的JavaScript代码时,就像侦探面对加密的线索——每个字符都可能是关键,每个变量名都可能是陷阱。本文将带你走进AST(抽象语法树)的世界&am…...

Worldquant研究顾问速通
几天时间速通拿了金牌,中间停了一两周,然后仔细研究了下,学了相关知识,搭建自己ai驱动的工作流后每天大约10分钟设置好任务,可探索到10来个可以提交的alpha,目前产出比大约在1/100,simulate100个…...

别只盯着DMA!用Vivado AXI DataMover实现PL-PS高速数据搬运的完整流程与状态机设计
基于AXI DataMover的PL-PS高速数据通路设计与实战解析 在异构计算架构中,高效的数据搬运机制往往是系统性能的瓶颈所在。当我们在Zynq或Versal平台上构建数据采集或处理系统时,传统DMA方案虽然简单易用,但在复杂场景下往往显得力不从心——无…...