ELK分布式日志管理平台部署
目录
一、ELK概述
1、ELK概念:
2、其他数据收集工具:
3、ELK工作流程图:
4、ELK 的工作原理:
5、日志系统的特征:
二、实验部署:
1、ELK Elasticsearch 集群部署
2、安装 Elasticsearch-head 插件
3、ELK Logstash 部署
3.1、将messages日志添加到elasticsearch集群
4、ELK Kiabana 部署
4.1、将 Apache 服务器的日志(访问的、错误的)添加到 Elasticsearch 并通过 Kibana 显示
4.2、nginx日志添加到elasticsearch集群,并用kiabana分析
三、es 性能调优参数
一、ELK概述
1、ELK概念:
ELK是一套完整的日志集中处理方案,由三个开源的软件的简称组成
E:ElasticSearch 简称ES,是一个开源的,分布式的存储检索引擎(索引型的非关系数据库)。作用就是存储日志。由java代码开发,基于Lucene结构开发的一套全文检索引擎。拥有一个web接口。用户可以通过浏览器的形式和ES组件进行通信。
作用:存储,允许全文搜索结构化搜索(索引点),索引和搜索容量可以支持大容量的日志数据。也可以搜索其他不同类型的文档
K:kiabana 图形化界面。可以更好的分析存储在ES上的日志数据。提供了一个图形化的界面,来浏览ES上的日志数据。汇总、分析、搜索
L:Logstash 数据收集引擎,支持动态的(实时的)从各种服务应用收集日志资源,还可以对收集到的日志数据进行过滤、分析,还可以丰富收集到的日志数据,统一格式等等操作。然后把数据同步到ES存储引擎上。RUBY语言编写,运行在java虚拟机上的一个强大的数据处理工具。数据传输,格式化处理,格式化输出。主要作用就是处理日志
2、其他数据收集工具:
fliebeat:轻量级的开源的,日志收集工具。收集的速度较快,但是没有数据分析和过滤的能力,一般是结合logstash一块使用
kafka、RabbitMQ:中间消息队列
3、ELK工作流程图:
1、在所有需要搜集日志的服务器上部署logstash,由logstash收集日志,将日志格式化并输出到elasticsearch集群中
2、elasticsearch对格式化后的日志进行索引和存储
3、kiabana从elasticsearch集群中查询数据生成图表,并进行前端数据的展示

4、ELK 的工作原理:
1、在所有需要收集日志的服务器上部署Logstash;或者先将日志进行集中化管理在日志服务器上,在日志服务器上部署 Logstash。
2、Logstash 收集日志,将日志格式化并输出到 Elasticsearch 群集中。
3、Elasticsearch 对格式化后的数据进行索引和存储。
4、Kibana 从 ES 群集中查询数据生成图表,并进行前端数据的展示。
总结:logstash作为日志搜集器,从数据源采集数据,并对数据进行过滤,格式化处理,
然后交由Elasticsearch存储,kibana对日志进行可视化处理。
5、日志系统的特征:
- 收集,可以收集基本上市面上常用的软件日志
- 传输,收集完的日志,需要发送到ES上
- 存储,ES存储负责存储数据
- UI:图形化界面(kiabana)
总结:ELK的作用,当我们管理一个打大集群时,需要分析和定位的日志就会很多,每一台服务器分别取分析,将会耗时耗力。所以我们应运而生了一个集中的统一的日志管理系统和分析系统。极大的提高了定位问题的效率
二、实验部署:
架构:三台主机(三台机器最低配置 2核4G)
两台ES:
ES1:20.0.0.21
ES2:20.0.0.22
logstash和kiabana部署在一台机器上:20.0.0.23(最好给4核8G)
1、ELK Elasticsearch 集群部署
(在Node1、Node2节点上操作)
1.环境准备
#设置Java环境
java -version #如果没有安装,yum -y install java
openjdk version "1.8.0_131"
OpenJDK Runtime Environment (build 1.8.0_131-b12)
OpenJDK 64-Bit Server VM (build 25.131-b12, mixed mode)

2.部署 Elasticsearch 软件
(1)安装elasticsearch—rpm包
#上传elasticsearch-6.7.2.rpm到/opt目录下
cd /opt
rpm -ivh elasticsearch-6.7.2.rpm
(2)修改elasticsearch主配置文件
cp /etc/elasticsearch/elasticsearch.yml /etc/elasticsearch/elasticsearch.yml.bak
vim /etc/elasticsearch/elasticsearch.yml
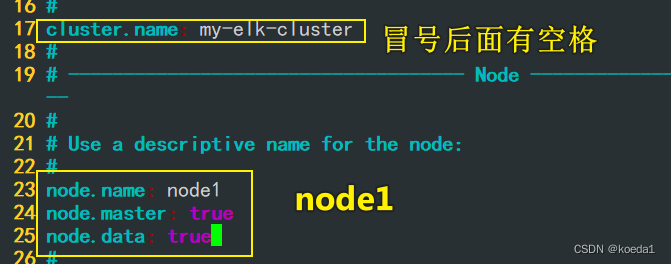
--17--取消注释,指定集群名字
cluster.name: my-elk-cluster
--23--取消注释,指定节点名字:Node1节点为node1,Node2节点为node2
node.name: node1
node.master: true #是否master节点,false为否
node.data: true #是否数据节点,false为否

--33--取消注释,指定数据存放路径
path.data: /var/lib/elasticsearch
--37--取消注释,指定日志存放路径
path.logs: /var/log/elasticsearch

--43--取消注释,
bootstrap.memory_lock: true
--55--取消注释,设置监听地址,0.0.0.0代表所有地址
network.host: 0.0.0.0
--59--取消注释,ES 服务的默认监听端口为9200
http.port: 9200 #指定es集群提供外部访问的接口
transport.tcp.port: 9300 #指定es集群内部通信接口

--68--取消注释,集群发现通过单播实现,指定要发现的节点
discovery.zen.ping.unicast.hosts: ["192.168.233.12:9300", "192.168.233.13:9300"]

grep -v "^#" /etc/elasticsearch/elasticsearch.yml

启动elasticsearch是否成功开启
systemctl start elasticsearch.service
systemctl enable elasticsearch.service
netstat -antp | grep 9200

若没有启动 看日志
tail -f /var/log/elasticsearch/my-elk-cluster.log
查看节点信息
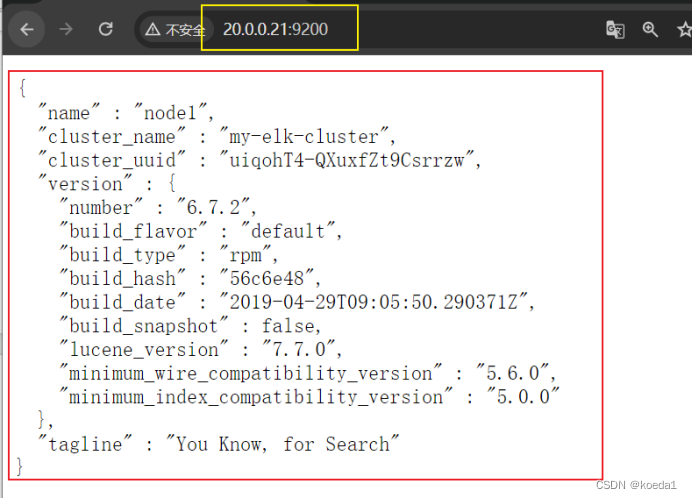
浏览器访问
http://20.0.0.21:9200
http://20.0.0.22:9200
查看节点 Node1、Node2 的信息。
浏览器访问
http://20.0.0.21:9200/_cluster/health?pretty
http://20.0.0.22:9200/_cluster/health?pretty
查看群集的健康情况,可以看到 status 值为 green(绿色), 表示节点健康运行。

浏览器访问 http://20.0.0.21:9200/_cluster/state?pretty 检查群集状态信息。
#使用上述方式查看群集的状态对用户并不友好,可以通过安装 Elasticsearch-head 插件,可以更方便地管理群集。
2、安装 Elasticsearch-head 插件
Elasticsearch 在 5.0 版本后,Elasticsearch-head 插件需要作为独立服务进行安装,
需要使用npm工具(NodeJS的包管理工具)安装。
安装 Elasticsearch-head 需要提前安装好依赖软件 node 和 phantomjs。
node:是一个基于 Chrome V8 引擎的 JavaScript 运行环境。
phantomjs:是一个基于 webkit 的JavaScriptAPI,可以理解为一个隐形的浏览器,
任何基于 webkit 浏览器做的事情,它都可以做到。
(1)编译安装 node
#上传软件包 node-v8.2.1.tar.gz 到/opt
yum install gcc gcc-c++ make -y
cd /opt
tar zxvf node-v8.2.1.tar.gz
cd node-v8.2.1/
./configure
make && make install
(2)安装 phantomjs
#上传软件包 phantomjs-2.1.1-linux-x86_64.tar.bz2 到
cd /opt
tar jxvf phantomjs-2.1.1-linux-x86_64.tar.bz2
cd /opt/phantomjs-2.1.1-linux-x86_64/bin
cp phantomjs /usr/local/bin
(3)安装 Elasticsearch-head 数据可视化工具
#上传软件包 elasticsearch-head-master.zip 到/opt
cd /opt
unzip elasticsearch-head-master.zip
cd elasticsearch-head-master/
npm install //安装依赖包
#速度慢,可以指定为淘宝镜像,再npm install安装
npm config set registry http://registry.npm.taobao.org/
(4)修改 Elasticsearch 主配置文件
vim /etc/elasticsearch/elasticsearch.yml
......
--末尾添加以下内容--
http.cors.enabled: true #开启跨域访问支持,默认为 false
http.cors.allow-origin: "*" #指定跨域访问允许的域名地址为所有

systemctl restart elasticsearch

(5)启动 elasticsearch-head 服务
#必须在解压后的 elasticsearch-head 目录下启动服务,进程会读取该目录下的 gruntfile.js 文件,否则可能启动失败。
cd /opt/elasticsearch-head-master
npm run start &
#elasticsearch-head 监听的端口是 9100
netstat -natp |grep 9100

(6)通过 Elasticsearch-head 查看 Elasticsearch 信息
通过浏览器访问 http://20.0.0.21:9100/ 地址并连接群集。如果看到群集健康值为 green 绿色,代表群集很健康。
9100是可视化工具的访问端口
9200是ES数据库的访问端口

(7)插入索引
#通过命令插入一个测试索引,索引为 index-demo,类型为 test。
curl -X PUT 'localhost:9200/index-demo/test/1?pretty&pretty' -H 'content-Type: application/json' -d '{"user":"zhangsan","mesg":"hello world"}'


删除:
curl -X DELETE 'localhost:9200/index-demo/test/1?pretty&pretty' -H 'content-Type: application/json' -d '{"user":"zhangsan","mesg":"hello world"}'
浏览器访问 http://192.168.233.12:9100/ 查看索引信息,可以看见索引默认被分片5个,并且有一个副本。

点击“数据浏览”,会发现在node1上创建的索引为 index-demo,类型为 test 的相关信息。
Elasticsearch 的可视化工具中,以索引分区(Shard)为单位,
可能采用不同的标识颜色来表示它们的状态。黑色的边框通常表示主分片(Primary Shard)。
在 Elasticsearch 中,索引被分成多个分区,这些分区称为分片。
每个索引可能包含一个或多个主分片以及它们的副本。主分片是数据的主要存储,
副本用于提高冗余和可用性。
3、ELK Logstash 部署
(在非ES节点上操作)
Logstash 一般部署在需要监控其日志的服务器。在本案例中,Logstash 部署在 Apache 服务器上,
用于收集 Apache 服务器的日志信息并发送到 Elasticsearch。
1.更改主机名
hostnamectl set-hostname apache
2.安装Apahce服务(httpd)
yum -y install httpd
systemctl start httpd
3.安装Java环境
yum -y install java
java -version
4.安装logstash
#上传软件包 logstash-6.7.2.rpm 到/opt目录下
cd /opt
rpm -ivh logstash-6.7.2.rpm
systemctl start logstash.service
systemctl enable logstash.service
ln -s /usr/share/logstash/bin/logstash /usr/local/bin/
#可以指定logstash的工作目录,默认为:/etc/logstash/conf.d
path.config: /opt/log
测试 Logstash
Logstash 命令常用选项:
-f:通过这个选项可以指定 Logstash 的配置文件,根据配置文件配置 Logstash 的输入和输出流。
-e:从命令行中获取,输入、输出后面跟着字符串,
该字符串可以被当作 Logstash 的配置(如果是空,则默认使用 stdin 作为输入,stdout 作为输出)。
-t:测试配置文件是否正确,然后退出。
定义输入和输出流:
logstash -e 'input { stdin{} } output { stdout{} }'
所有的键盘命令行输出,转化为标准输出(rubydebug的模式,6.0之后logstash的默认输出模式就是rubydebug格式的标准输出)
#使用 rubydebug 输出详细格式显示,codec 为一种编解码器
logstash -e 'input { stdin{} } output { stdout{ codec=>rubydebug } }'

#使用 Logstash 将信息写入 Elasticsearch 中
logstash -e 'input { stdin{} } output { elasticsearch { hosts=>["20.0.0.21:9200","20.0.0.22:9200"] } }' --path.data /opt/test1
--path.data /opt/test1
区分不同的数据存放目录,指定好会自动创建
6.0之后logstash自带的输出格式rubydebug,自动的把输出格式定义为统一格式的标准输出

定义 logstash配置文件
Logstash 配置文件基本由三部分组成:input、output 以及 filter(可选,根据需要选择使用)。
input:
表示从数据源采集数据,常见的数据源如Kafka、日志文件等
file beats kafka redis stdin
filter:
表示数据处理层,包括对数据进行格式化处理、数据类型转换、数据过滤等,支持正则表达式
grok 对若干个大文本字段进行再分割成一些小字段 (?<字段名>正则表达式) 字段名: 正则表达式匹配到的内容
date 对数据中的时间格式进行统一和格式化
mutate 对一些无用的字段进行剔除,或增加字段
mutiline 对多行数据进行统一编排,多行合并或拆分
output:
表示将Logstash收集的数据经由过滤器处理之后输出到Elasticsearch。
elasticsearch stdout
#格式如下:
input {...}
filter {...}
output {...}
在每个部分中,也可以指定多个访问方式。
例如,若要指定两个日志来源文件,则格式如下:
input {
file { path =>"/var/log/messages" type =>"syslog"}
file { path =>"/var/log/httpd/access.log" type =>"apache"}
}
可以指定logstash的工作目录,默认为:/etc/logstash/conf.d
path.config: /opt/log
运行配置
logstash -f /opt/log/system.conf --path.data /opt/test1 &
logstash -f:指定配置文件
/opt/log/system.conf:配置文件路径
--path.data /opt/test1 &:指定数据工作目录/opt/test1
3.1、将messages日志添加到elasticsearch集群
修改 Logstash 配置文件,让其收集系统日志/var/log/messages,并将其输出到 elasticsearch 中。
chmod +r /var/log/messages #让 Logstash 可以读取日志
cd /etc/logstash/conf.d/
vim system.conf

logstash -f system.conf --path.data /opt/test1 &
浏览器访问 http://20.0.0.21:9100/ 查看索引信息

4、ELK Kiabana 部署
(logstash节点上部署)
1.安装 Kiabana
#上传软件包 kibana-6.7.2-x86_64.rpm 到/opt目录
cd /opt
rpm -ivh kibana-6.7.2-x86_64.rpm
2.设置 Kibana 的主配置文件
vim /etc/kibana/kibana.yml
--2--取消注释,Kiabana 服务的默认监听端口为5601
server.port: 5601
--7--取消注释,设置 Kiabana 的监听地址,0.0.0.0代表所有地址
server.host: "0.0.0.0"

--28--取消注释,配置es服务器的ip,如果是集群则配置该集群中master节点的ip
elasticsearch.url: ["http://192.168.80.12:9200","http://192.168.80.13:9200"]

--37--取消注释,设置在 elasticsearch 中添加.kibana索引
kibana.index: ".kibana"

--96--取消注释,配置kibana的日志文件路径(需手动创建),不然默认是messages里记录日志
logging.dest: /var/log/kibana.log

--113--修改为中文模式
i18n.locale: "zh-CN"

3.创建日志文件,启动 Kibana 服务
touch /var/log/kibana.log
chown kibana:kibana /var/log/kibana.log
systemctl start kibana.service
systemctl enable kibana.service
netstat -natp | grep 5601

4.验证 Kibana
浏览器访问 http://20.0.0.23:5601

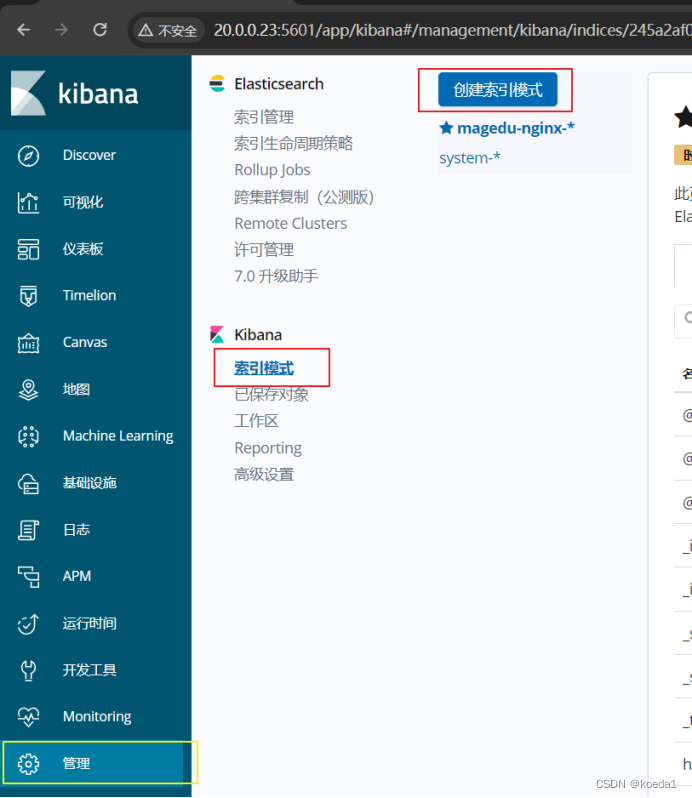
第一次登录需要添加一个 Elasticsearch 索引:
Management -> Index Pattern -> Create index pattern
Index pattern 输入:system-* #在索引名中输入之前配置的 Output 前缀“system”
Next step -> Time Filter field name 选择 @timestamp -> Create index pattern
单击 “Discover” 按钮可查看图表信息及日志信息。
数据展示可以分类显示,在“Available Fields”中的“host”,然后单击 “add”按钮,可以看到按照“host”筛选后的结果
4.1、将 Apache 服务器的日志(访问的、错误的)添加到 Elasticsearch 并通过 Kibana 显示
vim /etc/logstash/conf.d/apache_log.conf
input {
file{
path => "/etc/httpd/logs/access_log"
type => "access"
start_position => "beginning"
}
file{
path => "/etc/httpd/logs/error_log"
type => "error"
start_position => "beginning"
}
}
output {
if [type] == "access" {
elasticsearch {
hosts => ["20.0.0.21:9200","20.0.0.22:9200"]
index => "apache_access-%{+YYYY.MM.dd}"
}
}
if [type] == "error" {
elasticsearch {
hosts => ["20.0.0.21:9200","20.0.0.22:9200"]
index => "apache_error-%{+YYYY.MM.dd}"
}
}
}
cd /etc/logstash/conf.d/
/usr/share/logstash/bin/logstash -f apache_log.conf
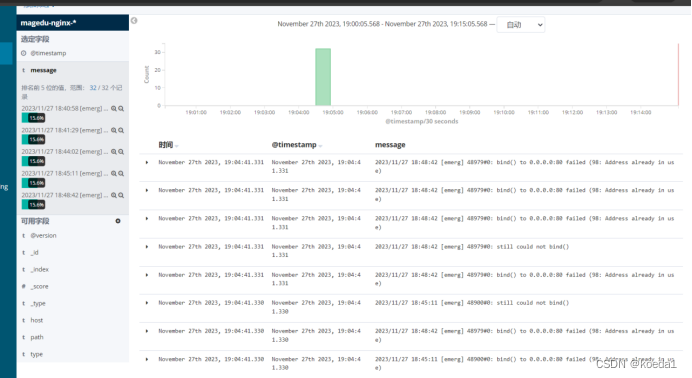
浏览器访问 http://20.0.0.23:9100 查看索引是否创建
浏览器访问 http://20.0.0.23:5601 登录 Kibana
单击“Index Pattern -> Create Index Pattern”按钮添加索引, 在索引名中输入之前配置的 Output 前缀 apache_access-*,并单击“Create”按钮。在用相同的方法添加 apache_error-*索引。
选择“Discover”选项卡,在中间下拉列表中选择刚添加的 apache_access-* 、apache_error-* 索引, 可以查看相应的图表及日志信息。

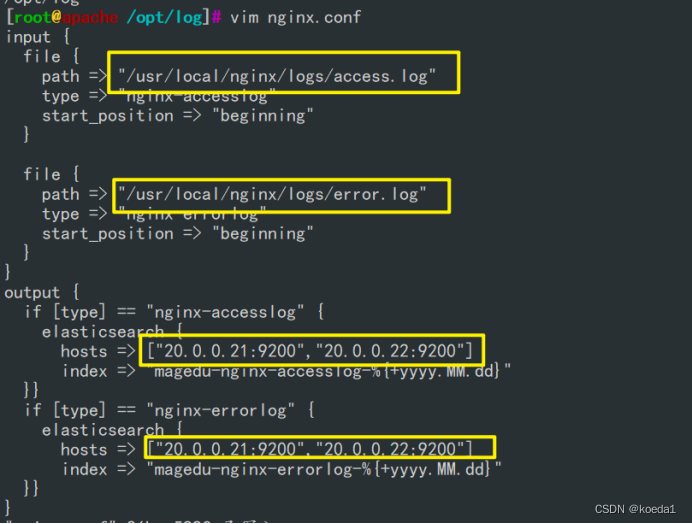
4.2、nginx日志添加到elasticsearch集群,并用kiabana分析
1.修改nginx的配置文件,以json格式存放到/var/log/nginx/access.log文件中
log_format access_json '{"@timestamp":"$time_iso8601",'
'"host":"$server_addr",'
'"clientip":"$remote_addr",'
'"size":$body_bytes_sent,'
'"responsetime":$request_time,'
'"upstreamtime":"$upstream_response_time",'
'"upstreamhost":"$upstream_addr",'
'"http_host":"$host",'
'"uri":"$uri",'
'"domain":"$host",'
'"xff":"$http_x_forwarded_for",'
'"referer":"$http_referer",'
'"tcp_xff":"$proxy_protocol_addr",'
'"http_user_agent":"$http_user_agent",'
'"status":"$status"}';
access_log /usr/local/nginx/logs/access.log access_json;
- 编写logstash.conf脚本,过滤nginx的access,error日志
重启logstash服务

登录elasticsearch,查看nginx-accesslog nginx-errorlog索引,能正常查看到

登录kibana,创建nginx-accesslog和nginx-errorlog数据视图,正常查看日志
三、性能调优参数
1、ES性能调优
#优化最大内存大小和最大文件描述符的数量
vim /etc/security/limits.conf
......
* soft nofile 65536
* hard nofile 65536
* soft nproc 32000
* hard nproc 32000
* soft memlock unlimited
* hard memlock unlimited
vim /etc/systemd/system.conf
DefaultLimitNOFILE=65536
DefaultLimitNPROC=32000
DefaultLimitMEMLOCK=infinity
DefaultLimitNOFILE=65536:
这是指定一个用户会话(session)的默认最大文件描述符数量的限制。
文件描述符是一个用于标识打开文件或其他 I/O 资源的整数。在这里,设置为 65536,
表示一个用户会话可以拥有的最大文件描述符数为 65536。
DefaultLimitNPROC=32000:
这是指定一个用户会话的默认最大进程数量的限制。进程是正在运行的程序的实例。
这里设置为 32000,表示一个用户会话可以拥有的最大进程数为 32000。
DefaultLimitMEMLOCK=infinity:
这是指定一个用户会话的默认锁定内存的限制。锁定内存是指将内存保留在物理内存中,
防止被交换到磁盘。"infinity" 表示没有内存锁定的限制,用户会话可以锁定任意数量的内存。
需重启生效
#优化elasticsearch用户拥有的内存权限
由于ES构建基于lucene, 而lucene设计强大之处在于lucene能够很好的利用操作系统内存来缓存索引数据,
以提供快速的查询性能。lucene的索引文件segements是存储在单文件中的,并且不可变,对于OS来说,
能够很友好地将索引文件保持在cache中,以便快速访问;因此,我们很有必要将一半的物理内存留给lucene ;
另一半的物理内存留给ES(JVM heap )。所以, 在ES内存设置方面,可以遵循以下原则:
1.当机器内存小于64G时,遵循通用的原则,50%给ES,50%留给操作系统,供lucene使用
2.当机器内存大于64G时,遵循原则:建议分配给ES分配 4~32G 的内存即可,其它内存留给操作系统,供lucene使用
vim /etc/sysctl.conf
#一个进程可以拥有的最大内存映射区域数,参考数据(分配 2g/262144,4g/4194304,8g/8388608)
vm.max_map_count=262144
vm.max_map_count 参数用于限制一个进程可以拥有的最大内存映射区域数。
内存映射是一种将文件或其他设备映射到进程地址空间的方法,
允许进程直接读取或写入文件,而无需进行常规的文件 I/O 操作。
Elasticsearch 和 Lucene 等搜索引擎: 这些引擎使用内存映射来加速索引和搜索操作。
大量的映射区域可以用于存储索引和缓存,提高搜索性能。
数据库系统: 一些数据库系统使用内存映射来管理数据文件,以加速读写操作。
科学计算和大数据处理: 在某些科学计算和大数据处理应用中,内存映射可以用于高效地处理大型数据集。
sysctl -p
sysctl -a | grep vm.max_map_count
总结:
ELK:
es:存储数据,索引型的数据库
logstash:收集日志,然后按照标准化格式发送给ES(rubydebug的格式)
k:可视化工具更人性化的显示用户信息,方便用户检索查询
2、logstash性能调优
logstash启动是在jvm虚拟机上启动的,启动一次至少占500M内存
pipeline.workers: 2
logstash的工作线程,默认值就是cpu数,4核给2, 8核 给4 给一半即可
pipeline.batch.size 125
一次性能够批量处理检索事件的大小默认125。性能好可以给 200
pipline.batch.delay: 50
查询更新的延迟。50毫秒,可以自行调整。生产中15 、10。看机器性能
四、filebeat+ELK
filebeat日志收集工具和logstash相同
1、概述
1.1、优点:
filebeat是一个轻量级的日志收集工具,所使用的系统资源比logstash部署和启动时使用的资源要小的多
filebeat可以运行在非java环境。他可以代替logstash在非Java环境上收集日志
filebeat收集的数据可以发往多个主机。远程收集
1.2、缺点:
filebeat无法实现数据的过滤,一般是结合logstash的数据过滤功能一块使用
1.3、工作流程图:

2、实验
架构:
ES节点两个:
node1:20.0.0.21
node2:20.0.0.22
日志节点(logstash、kibana、filebeat):20.0.0.23
1.安装 Filebeat
#上传软件包 filebeat-6.7.2-linux-x86_64.tar.gz 到/opt目录
tar zxvf filebeat-6.7.2-linux-x86_64.tar.gz
mv filebeat-6.7.2-linux-x86_64/ /usr/local/filebeat
#时间同步
yum install ntpdate -y
ntpdate ntp.aliyun.com
2.设置 filebeat 的主配置文件
cd /usr/local/filebeat
vim filebeat.yml
filebeat.inputs:

- type: log
enabled: true
paths:
- /usr/local/nginx/logs/access.log
- /usr/local/nginx/logs/error.log
tags: ["nginx_23"]
fields:
service_name: 20.0.0.23_nginx
log_type: nginx
from: 20.0.0.23
Elasticsearch output模块全部注释掉
因为filebeat只能收集日志,不能过滤日志,所以需要先发给logstash过滤处理日志,再由logstash发送给elasticsearch。这里不直接发送给elasticsearch
Logstash output

配置logsatsh

input {
beats { port => "5044" }
}
output {
if "nginx_23" in [tags] {
elasticsearch {
hosts => ["20.0.0.21:9200","20.0.0.22:9200"]
index =>"%{[fields][service_name]}-%{+YYYY.MM.dd}"
}
}
stdout {
codec => rubydebug
}
}
启动 filebeat:
nohup ./filebeat -e -c filebeat.yml > filebeat.out &
-e:输出到标准输出,禁用syslog/文件输出
-c:指定配置文件
nohup:在系统后台不挂断地运行命令,退出终端不会影响程序的运行

给所要操作的日志访问权限
chmod 777 access.log error.log

启动logstash配置:
logstash -f nginx_23.conf --path.data /opt/test1 &



filebeat 远程收集日志
工作过程:
filebeat和logstash不部署在同一节点上
filebeat先在节点上收集日志,在远程发送给logstash。
在节点上安装filebeat
配置filebeat文件:
Filebeat inputs

Elasticsearch output(全部注释掉)
Logstash output
output.logstash:
# The Logstash hosts
hosts: ["20.0.0.23:5045"] #指定 logstash 的 IP 和端口

配置logstash(去logstash节点)

启动 filebeat(filebeat节点)
cd /usr/local/filebeat
nohup ./filebeat -e -c filebeat.yml > filebeat.out &

去logstash节点启动
logstash -f nhm.conf --path.data /opt/test2 &

logstash可以使用任意端口,只要没被占用都可以使用,推荐1024之后开始
相关文章:
ELK分布式日志管理平台部署
目录 一、ELK概述 1、ELK概念: 2、其他数据收集工具: 3、ELK工作流程图: 4、ELK 的工作原理: 5、日志系统的特征: 二、实验部署: 1、ELK Elasticsearch 集群部署 2、安装 Elasticsearch-head 插件 …...
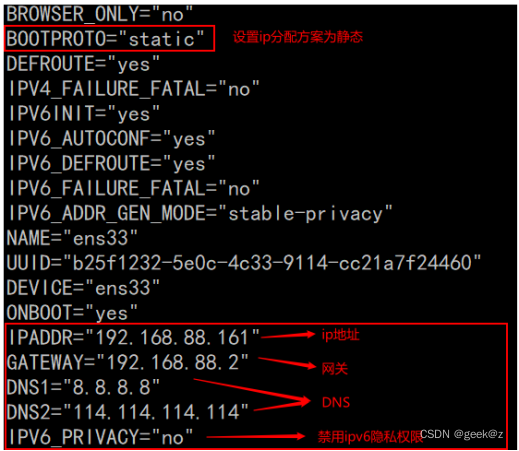
四、虚拟机网络配置
目录 1、VMware网卡配置模式 1.1 桥接模式 1.2 NAT模式 1.3 仅主机模式 2、编辑虚拟机的网络编辑器 3、编辑Window的虚拟网卡 4、修改IP地址为静态 4.1 查看网卡名字 4.2 编辑修改网卡IP地址的配置文件 4.3 重启网络: 4.…...
四、Lua循环
文章目录 一、while(循环条件)二、for(一)数值for(二)泛型for(三)repeat util 既然同为编程语言,那么控制逻辑里的循环就不能缺少,它可以帮助我们实现有规律的重复操作,而…...
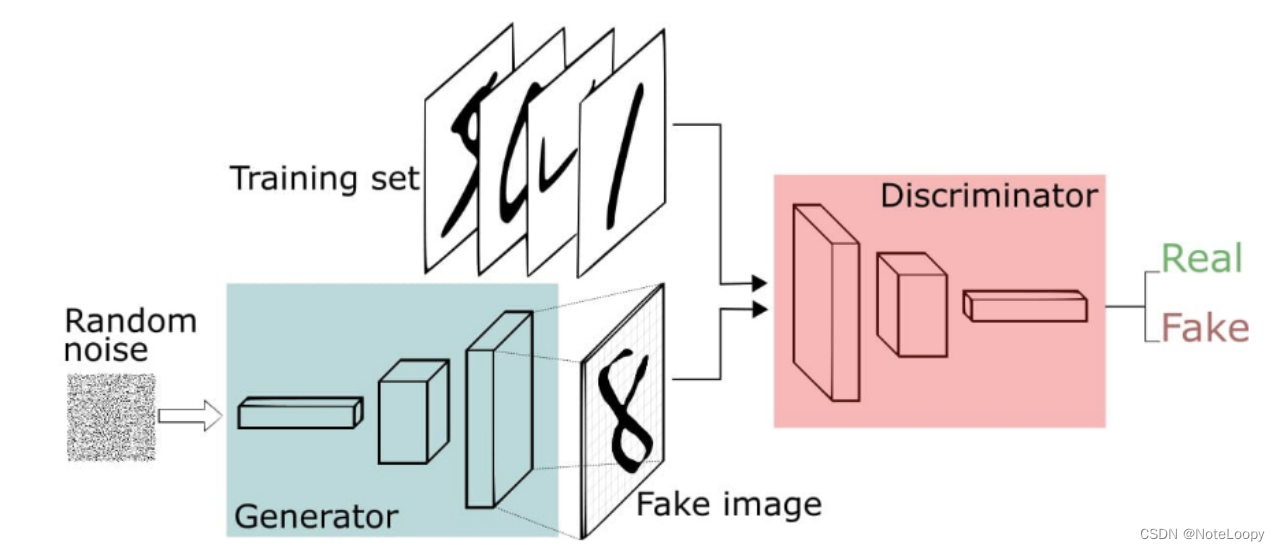
生成对抗网络(GAN)手写数字生成
文章目录 一、前言二、前期工作1. 设置GPU(如果使用的是CPU可以忽略这步) 二、什么是生成对抗网络1. 简单介绍2. 应用领域 三、网络结构四、构建生成器五、构建鉴别器六、训练模型1. 保存样例图片2. 训练模型 七、生成动图 一、前言 我的环境࿱…...

LeetCode Hot100 31.下一个排列
题目: 整数数组的一个 排列 就是将其所有成员以序列或线性顺序排列。 例如,arr [1,2,3] ,以下这些都可以视作 arr 的排列:[1,2,3]、[1,3,2]、[3,1,2]、[2,3,1] 。 整数数组的 下一个排列 是指其整数的下一个字典序更大的排列…...

Redis主从与哨兵架构详解
目录 主从架构 主从环境搭建 主从复制流程 1. 全量复制 2. 部分复制 主从风暴 哨兵架构 概念 哨兵环境搭建 主从架构 主从环境搭建 1. 复制一份redis.conf文件, 修改下面几行配置 port 6380 pidfile /var/run/redis_6380.pid logfile "6380.log" dir /usr/…...
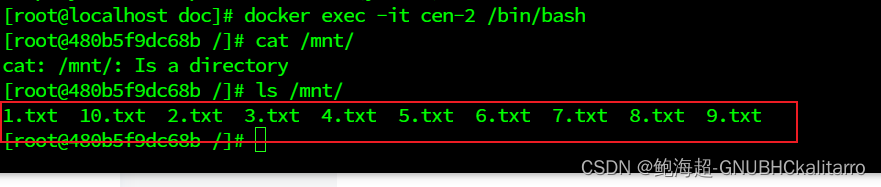
Linux:docker的数据管理(6)
数据管理操作*方便查看容器内产生的数据 *多容器间实现数据共享 两种管理方式数据卷 数据卷容器 1.数据卷 数据卷是一个供容器使用的特殊目录,位于容器中,可将宿主机的目录挂载到数据卷上,对数据卷的修改操作立刻可见,并且更新数…...

深入理解Zookeeper系列-1.初识Zoookeeper
👏作者简介:大家好,我是爱吃芝士的土豆倪,24届校招生Java选手,很高兴认识大家📕系列专栏:Spring源码、JUC源码、Kafka原理、分布式技术原理🔥如果感觉博主的文章还不错的话ÿ…...

芯片技术探索:了解构芯片的设计与制造之旅
芯片技术探索:了解构芯片的设计与制造之旅 一、引言 随着现代科技的飞速发展,芯片作为信息技术的核心,已经渗透到我们生活的方方面面。从智能手机、电视、汽车到医疗设备和工业控制系统,芯片在各个领域都发挥着至关重要的作用。然而,对于大多数人来说,芯片仍然是一个神秘…...
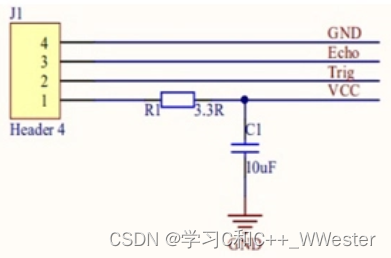
STM32 超声波模块(HC-SR04)
HC-SR04介绍 典型工作电压:5v (如果你的超声波模块没有工作,可以看一下是不是电压不够)超小静态工作电流:<2mA 感应角度:<15 (超声波模块,是一个范围式的探…...
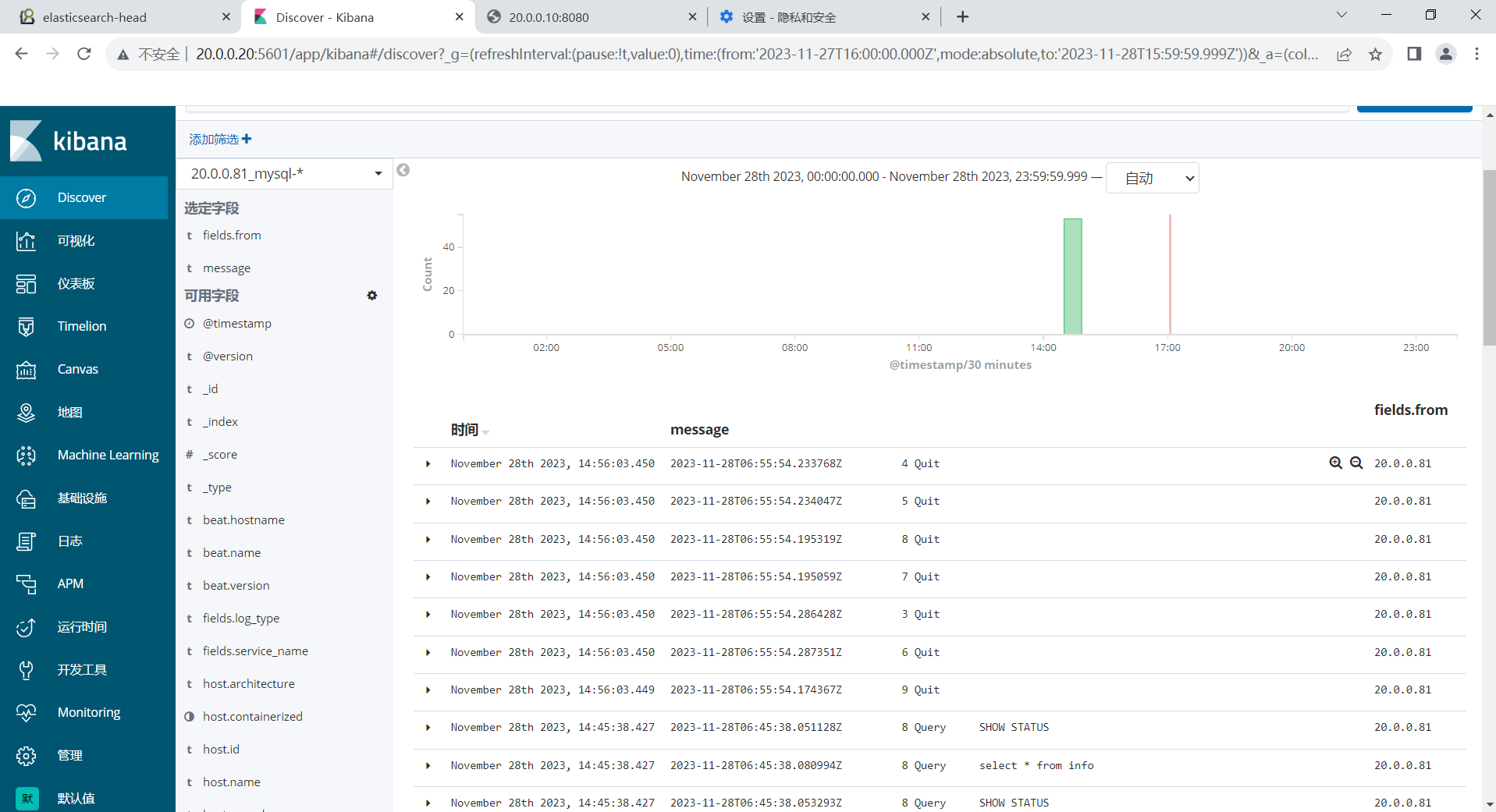
ELK+Filebeat
Filebeat概述 1.Filebeat简介 Filebeat是一款轻量级的日志收集工具,可以在非JAVA环境下运行。 因此,Filebeat常被用在非JAVAf的服务器上用于替代Logstash,收集日志信息。实际上,Filebeat几乎可以起到与Logstash相同的作用&…...

MySql之锁表、锁行解决方案
查询正在使用的表,没有跑业务,一般情况下是锁表了 show open tables where in_use > 0 ;查看进程,可以看到Command类型(Sleep为阻塞线程) show processlist;kill事务,kill 进程Id kill 8193583;其他 …...
2023年第十六届山东省职业院校技能大赛中职组“网络安全”赛项竞赛正式试题
第十六届山东省职业院校技能大赛中职组 “网络安全”赛项竞赛试题 目录 一、竞赛时间 二、竞赛阶段 三、竞赛任务书内容 (一)拓扑图 (二)A模块基础设施设置/安全加固(200分) (三…...
文件上传,分片上传,删除,下载)
JAVA 整合 AWS S3(Amazon Simple Storage Service)文件上传,分片上传,删除,下载
依赖 因为aws需要发送请求上传、下载等api,所以需要加上httpclient相关的依赖 <dependency><groupId>com.amazonaws</groupId><artifactId>aws-java-sdk-s3</artifactId><version>1.11.628</version> </dependency&…...
记录:Unity脚本的编写9.0
目录 射线一些准备工作编写代码 突然发现好像没有写过关于射线的内容,我就说怎么总感觉好像少了什么东西(心虚 那就在这里写一下关于射线的内容吧,将在这里实现射线检测鼠标点击的功能 射线 射线是一种在Unity中检测碰撞器或触发器的方法&am…...

共享单车停放(简单的struct结构运用)
本来不想写这题的,但是想想最近沉迷玩雨世界,班长又问我这题,就草草写了一下 代码如下: #include<stdio.h> #include<math.h> struct parking{int distance;int remain;int speed;int time;int jud; }parking[50]; …...

【Java8系列07】Java8日期处理
💝💝💝欢迎来到我的博客,很高兴能够在这里和您见面!希望您在这里可以感受到一份轻松愉快的氛围,不仅可以获得有趣的内容和知识,也可以畅所欲言、分享您的想法和见解。 推荐:kwan 的首页,持续学…...

为什么做CSGO搬砖的不直接去炒股呢?
首先,CS2并非只有一个交易平台,阿阳个人觉得像IGXE等交易平台一样是交易,况且我记得很早的时候我就开始用IGXE了,我记得最早的时候还是机器人发货,后来因为V社对于很多开箱网站的管控,所以让这种发货的方式…...

12月01日,每日信息差//阿里国际发布3款AI设计生态工具//美团买菜升级为“小象超市”//外国人永居证换新、6国游客免签来华
_灵感 🎖 阿里国际发布3款AI设计生态工具 🎄 AITO问界系列11月交付新车18827辆 🌍 美团买菜升级为“小象超市” 🌋 全球首个金融风控大模型国际标准出炉,由腾讯牵头制定 🎁 支付宝:支持外国人…...

ChatGPT探索:提示工程详解—程序员效率提升必备技能【文末送书】
文章目录 一.人工智能-ChatGPT1.1 ChatGPT简介1.2 ChatGPT探索:提示工程详解1.2 提示工程的优势 二.提示工程探索2.1 提示工程实例:2.2 英语学习助手2.3 Active-Prompt思维链(CoT)方法2.4 提示工程总结 三.文末推荐与福利3.1《Cha…...
式API的实现原理)
CargoBay源码解析:深入理解块(block)式API的实现原理
CargoBay源码解析:深入理解块(block)式API的实现原理 【免费下载链接】CargoBay The Essential StoreKit Companion 项目地址: https://gitcode.com/gh_mirrors/ca/CargoBay CargoBay是一个功能强大的iOS StoreKit辅助库,它为Apple的应用内购买框…...

stm32F103C8T6标准库定时器应用流水灯1——相关的寄存器
目录1.SysTick介绍2.芯片架构2.1 M3系统架构图3.SysTick使用4.readme5.定时器中断配置5.1 core_cm3.h文件5.1.1 函数头注释部分5.1.2 函数名5.1.3 判断重装值是否超过 24 位5.1.4 设置重装载寄存器5.1.5 设置中断优先级5.1.6 清空当前计数器5.1.7 配置 CTRL 寄存器(…...

AArch64 TRCCNTCTLR寄存器详解与调试技巧
1. AArch64 TRCCNTCTLR寄存器概述在AArch64架构中,TRCCNTCTLR(Trace Counter Control Register)是嵌入式跟踪扩展(FEAT_ETE)功能的重要组成部分。作为系统调试和性能分析的核心组件,它负责控制跟踪计数器的…...

AV1编码背景及现状
AV1(AOMedia Video 1)是一种开放的、免版税的视频编码标准,由开放媒体联盟开发。该标准的最初设计目的是用于互联网上的视频传输,同时提供一个对所有用户开放且无须支付版税的视频压缩解决方案。作为 VP9的下一代视频编码标准&…...

Delft3D建模、水动力模拟方法及地表水环境影响评价:岸线绘制与导入、非结构化计算网格生成、水下地形数据处理等前处理操作;水动力与污染物对流扩散模拟的参数设置、边界条件设定及模型率定验证
查看原文>>>https://mp.weixin.qq.com/s/_CiPDK_oXaAGxVfu2qk6ew 前言 本文以地表水数值模拟软件Delft3D 4.03.00操作为主要内容,强调地表水水动力建模、基础资料的获取、边界条件设定、模型率定和验证、数据分析和处理等关键环节。通过对案例模型的实操…...

向日葵远程控制16.5发布,“免密远控”功能登场便捷又安全
人在公司,急需处理家里电脑上的重要文件,却完全想不起访问密码或者系统的帐号密码;出差在外,想远程操作办公室电脑,却不得不打电话让同事帮忙看一眼密码设置甚至干脆让同事点个接受......密码虽然是一种非常主流的安全…...

LERF技术解析:基于NeRF与CLIP的3D场景语言查询与语义分割
1. 项目概述:当NeRF遇见自然语言最近在三维重建和生成领域,一个名为LERF(Language Embedded Radiance Fields)的技术组合引起了不小的关注。简单来说,它做了一件听起来很科幻的事:你给一段文字描述…...
)
构图不是靠感觉!用Fitts定律+格式塔原理验证的Midjourney 6大构图公式(附Python自动构图评分脚本)
更多请点击: https://kaifayun.com 第一章:构图不是靠感觉!用Fitts定律格式塔原理验证的Midjourney 6大构图公式(附Python自动构图评分脚本) 构图绝非主观直觉,而是可量化、可验证的视觉认知工程。我们基于…...

QiMeng-TensorOp:自动生成高性能张量运算代码的框架
1. 项目概述QiMeng-TensorOp是一个革命性的张量算子自动生成框架,它能够基于硬件原语自动生成高性能的张量运算代码。在现代深度学习和大型语言模型(LLMs)中,张量运算如矩阵乘法(GEMM)和卷积(Conv)占据了90%以上的计算量。传统的手动优化方法需要数月时间…...

Aimmy终极模型选择指南:5个秘诀帮你为不同游戏找到最佳ONNX模型
Aimmy终极模型选择指南:5个秘诀帮你为不同游戏找到最佳ONNX模型 【免费下载链接】Aimmy Universal Second Eye for Gamers with Impairments (Universal AI Aim Aligner (AI Aimbot) - ONNX/YOLOv8 - C#) 项目地址: https://gitcode.com/gh_mirrors/ai/Aimmy …...