【2024秋招】2023-10-17 金山云文档服务端二面
1 实习
1.1 讲解一下curd启动器
1.2 数据同步的过程是怎么实现的,同步过程中的数据一致性怎么保证的
答:同步过程中会记录断点,表示每一批同步成功时的位置,如果对端出现问题,则下一次同步会继续从这个断点后开始同步。
1.3 当对端出现故障时,线程会抛异常然后被捕获并且记录,那么这个库的同步不就相当于终止了吗,而且这个异常线程也会消失,你怎么让他同步完整的表(重要)
答:一般对于同步过程中出现异常的,我们都会进行记录,并且记录异常原因,稍后会通过人工会根据捕获的异常修复漏洞,然后点击按钮进行一次基于库或者表级别的同步,这个过程也是基于上次的断点同步的
1.4 线程怎么感知到已经同步完一张表了呢
答:通过比较源端表和目的端表的记录行数,就可以确定最终是否同步完成
1.5 你是需要从公司的数据库拉一批数据到内存中,然后再同步到对端的数据库,你是怎么知道这一批执行成功的呢,有什么通知机制吗?
答:我使用的是jdbc原生接口,每一次拉取到一批数据的时候,就会执行一次executeBatch方法,然后会在进行commit操作,这个接口本身有返回值,如果能继续同步下一批,就说明同步成功,如果失败会抛异常,也会被捕获
2 mysql
2.1 设计mysql表结构的时候,需要考虑到哪些点
答:
(1)必要的时候可以打破三范式
(2)按需建立多种索引
(3)分区表,分库分表
(4)对于分布式环境,尽量做到一个服务对应一个独立的库,做一个流量的隔离
gpt4的答案:
设计数据库表时需要考虑的因素相当多,这些因素会影响数据的组织、检索、更新、维护以及整体的性能和扩展性。以下是一些在设计表时应考虑的主要因素:
-
数据完整性:
- 确保数据准确性和一致性,可以使用约束(例如主键、外键、唯一性约束、检查约束)。
-
数据规范化:
- 考虑将数据分解到多个表中以减少数据冗余,同时确保数据完整性和一致性。
- 通常会遵循规范化的不同级别(如第一范式、第二范式等)。
-
数据类型选择:
- 根据数据的性质选择合适的数据类型,如整型、浮点型、字符串、日期等。
- 选择适当大小的数据类型,既不过大也不过小,以优化存储和性能。
-
索引设计:
- 考虑哪些列经常用于查询,并为这些列创建索引以提高查询性能。
- 同时要注意不要过度索引,因为索引会增加数据插入和更新的开销。
-
扩展性:
- 设计时要考虑未来可能的数据增长和变化,这样在未来的某个时刻才能容易地对表进行修改或扩展。
-
性能:
- 考虑查询的性能,尽可能避免全表扫描。
- 考虑存储和访问模式,比如,某些表可能需要分区。
-
安全性:
- 考虑哪些用户或角色可以访问或修改表中的数据。
- 为敏感数据实施加密。
-
外键和关系:
- 定义表与表之间的关系,确保引用完整性。
-
默认值和约束:
- 为某些列设置默认值,确保数据的一致性。
- 使用约束确保数据的有效性。
-
存档和历史数据:
- 考虑是否需要存储历史数据,以及如何存储(例如,使用历史表或软删除)。
- 物理存储:
- 考虑数据文件的存放位置,是否需要使用特定的存储设备或配置。
- 备份和恢复策略:
- 设计表时,考虑到后期的备份和恢复策略。
- 访问模式:
- 考虑数据的访问模式,是读密集还是写密集,或者是混合型。这将影响索引和存储的设计。
- 冗余和反规范化:
- 在某些情况下,为了性能考虑,可能需要有意识地引入冗余或反规范化。
当设计表时,建议首先深入了解业务需求,以确保数据模型能够满足业务的长期和短期需求。
2.2 覆盖索引
2.3 场景题:在上亿条记录的表中使用limit做分页查询时会碰到什么问题,怎么解决(重点)
答:刚开始我说即使上亿条记录,mysql的B+树最多5层也能搞定吧,其实这个磁盘IO应该能扛得住吧,但是面试官说他们公司的极限是3次磁盘IO
2.3.1 在拥有上亿条记录的表中使用 LIMIT 进行分页查询时,可能会遇到以下问题:
-
性能问题:
- 当使用
LIMIT m,n这种方式进行分页查询时,数据库实际上可能会扫描超过m+n行,然后丢弃前m行,仅返回接下来的n行。当m很大时,这会导致性能问题。
- 当使用
-
不稳定的结果:
- 如果表中的数据在分页查询之间发生变化(例如,新数据的插入、旧数据的删除等),那么使用
LIMIT进行的分页查询可能会返回重复的、遗漏的或乱序的结果。
- 如果表中的数据在分页查询之间发生变化(例如,新数据的插入、旧数据的删除等),那么使用
-
内存使用过多:
- 对于大表,使用
LIMIT进行深度分页可能会消耗大量的内存,因为数据库需要缓存大量的行来处理这样的查询。
- 对于大表,使用
2.3.2 如何解决这些问题?
-
使用索引覆盖分页:
- 为查询字段和排序字段创建合适的索引。通过确保查询是"覆盖索引"查询,可以大大提高查询速度。
-
避免深度分页:
- 尝试使用其他方法,如提供日期范围或其他过滤条件,来限制结果集,从而避免深入到大数据集的尾部。
-
使用seek方法(游标,重点):
- 与其使用
LIMIT m,n,不如记录上一页的最后一个记录的ID或其他标识,然后查询“大于此ID”的下一页记录。这种方法被称为游标或seek方法。
- 与其使用
-
使用物化视图:
- 对于经常进行的复杂查询,可以创建物化视图,其中数据已经预先排序和/或过滤。这样,分页查询只需在物化视图上进行,避免了大量的数据处理。
-
考虑分表或分区(我提到的方案):
- 如果表的大小是一个持续的问题,考虑将表分成多个更小的表或使用数据库的分区功能。
-
缓存结果:
- 对于经常访问的查询结果,可以考虑使用缓存技术,如Redis或Memcached,来缓存结果。这可以减少对数据库的访问频率。
-
考虑不同的数据库设计:
- 对于真正的大数据应用,可能需要考虑非关系型数据库、列式存储或其他大数据技术。
通过考虑上述方法并根据具体的应用和需求选择合适的方法,可以有效地解决在大数据集上使用 LIMIT 进行分页查询的问题。
2.3.3 对于大表,使用 LIMIT 进行深度分页可能会消耗大量的内存,因为数据库需要缓存大量的行来处理这样的查询。举个例子
深度分页的例子: 假设你有一个包含1亿条记录的大表。你想从这张表中获取第9999901到第10000000条的记录。当你执行以下查询时:
sqlCopy codeSELECT * FROM your_big_table ORDER BY some_column LIMIT 9999900, 100;实际上,MySQL会扫描前9999900条记录,丢弃它们,然后返回接下来的100条记录。这意味着数据库实际上要处理近1000万行记录,只为了返回100行结果,这自然会消耗大量的时间和内存。
2.3.4 与其使用 `LIMIT m,n`,不如记录上一页的最后一个记录的ID或其他标识,然后查询“大于此ID”的下一页记录。这种方法被称为游标或seek方法。 给个java的demo,使用游标时,sql语句怎么写呢?
当我们使用游标或seek方法进行分页时,我们不再使用传统的 OFFSET 和 LIMIT。取而代之的是,我们根据上一页的最后一个记录的标识(通常是一个递增的ID)来查询下一页的数据。
以下是一个简单的Java示例,使用JDBC和MySQL数据库:
1. 设定数据库连接参数:
String url = "jdbc:mysql://localhost:3306/your_database";
String user = "username";
String password = "password";
2. 执行分页查询:
import java.sql.Connection;
import java.sql.DriverManager;
import java.sql.PreparedStatement;
import java.sql.ResultSet;public class SeekPaginationDemo {public static void main(String[] args) {String url = "jdbc:mysql://localhost:3306/your_database";String user = "username";String password = "password";int pageSize = 10; // 每页的记录数int lastId = 0; // 上一页的最后一个记录的IDtry (Connection connection = DriverManager.getConnection(url, user, password)) {String sql = "SELECT * FROM your_table WHERE id > ? ORDER BY id ASC LIMIT ?";try (PreparedStatement preparedStatement = connection.prepareStatement(sql)) {preparedStatement.setInt(1, lastId);preparedStatement.setInt(2, pageSize);try (ResultSet resultSet = preparedStatement.executeQuery()) {while (resultSet.next()) {int id = resultSet.getInt("id");String name = resultSet.getString("name");// ... 其他列 ...System.out.println("ID: " + id + ", Name: " + name);// 更新lastId为当前记录的IDlastId = id;}}}} catch (Exception e) {e.printStackTrace();}}
}
这个示例展示了如何基于上一页的最后一个记录的ID来获取下一页的数据。当你需要获取下一页面时,只需再次运行上述代码,并使用更新后的 lastId。
2.3.5 游标是一种可滚动的结果集,可以在不返回所有数据的情况下进行分页查询。使用游标分页可以避免对整个表进行扫描,从而提高查询效率。MySQL支持使用游标进行分页查询,但需要注意内存消耗和网络传输的问题。 使用游标分页可以避免对整个表进行扫描,为什么?
使用游标分页(又称为"seek method"或基于keyset的分页)时,你是基于上一页的某个值(通常是主键或唯一键)来查询下一页的数据,而不是基于固定的偏移量。由于数据库可以利用索引(例如,B树)来快速定位到指定的起始值,所以不需要逻辑地扫描那些之前的记录。
举一个简单的例子:
假设你有一个ID为1到1000的表。你想要获取从第501条到第510条的数据。
-
使用传统的
LIMIT和OFFSET方式:SELECT * FROM table LIMIT 500, 10。在这种情况下,数据库虽然只返回了10条记录,但在逻辑上它仍然要处理前500条记录,尽管这些记录最终并没有被返回。 -
使用游标方式:如果你知道上一页的最后一个ID是500,你可以这样查询:
SELECT * FROM table WHERE id > 500 ORDER BY id LIMIT 10。这时,数据库可以利用ID的索引直接跳到ID为500的位置并开始查询,避免了处理那些之前的记录。
因此,当你使用游标分页时,可以更高效地从索引中查找和检索数据,而不必扫描那些之前的、不必要的记录。这对于大型数据集尤为有用,因为使用传统的LIMIT和OFFSET可能会导致随着页码增大而逐渐变慢。
2.3.6 使用游标方式:如果你知道上一页的最后一个ID是500,你可以这样查询:SELECT * FROM table WHERE id > 500 ORDER BY id LIMIT 10。这时,数据库可以利用ID的索引直接跳到ID为500的位置并开始查询,避免了处理那些之前的记录。 1 这样的话是不是说,可以先利用id的主键索引,以logn的复杂度查找出目标记录,然后再在目标记录中按照limit10进行筛选,如果是单纯的使用limit字段,就不会走索引,会从第一条记录开始扫描到第500条,对吗
是的,你的理解是正确的。
-
当你使用条件
WHERE id > 500并且id列有索引(通常作为主键或唯一键),数据库会利用这个索引在B-Tree结构中以O(logn)的复杂度快速定位到ID为500的记录位置。 -
一旦找到起始位置,数据库可以从那里开始检索并按照
ORDER BY和LIMIT进行排序和限制记录数。这个过程相对较快,因为它避免了逻辑上扫描那些不相关的记录。 -
对于传统的
LIMIT和OFFSET方法,如果没有其他的WHERE条件,那么数据库实际上要逻辑地扫描到指定的偏移位置。例如,LIMIT 500, 10实际上需要数据库逻辑地处理前500条记录,然后返回接下来的10条。这在大数据集上会导致性能问题,因为随着页数的增加,需要扫描的记录数也在增加。
因此,使用基于游标或keyset的分页方法通常在大数据集上更加高效。
2.3.7 SELECT * FROM table order by id LIMIT 500, 10 这种也是会扫描前500吗?
是的,当你使用SELECT * FROM table ORDER BY id LIMIT 500, 10这样的查询,它首先会根据ORDER BY条件对数据进行排序(如果使用了索引,如主键索引,那么排序操作会更快),然后跳过前500条记录,最后返回接下来的10条记录。
在这种情况下,虽然排序操作可能很快(尤其是当排序字段有索引时),但跳过前500条记录是需要时间的,特别是当这个数字(在这里是500)变得很大时,这种分页方式的性能开销会增加。这就是为什么当数据集非常大时,使用OFFSET方式的分页可能会导致性能问题,而基于游标或keyset的分页方法在这种场景下会更优越。
2.3.8 SQL游标(Cursor in SQL)和 游标方式分页(Keyset or Cursor-based Pagination)的区别
在你提供的知乎链接中描述的游标与我之前提到的"游标"概念存在明显的区别。下面,我将为你详细解释这两者之间的主要区别:
-
SQL游标(Cursor in SQL):
- 它是在关系型数据库中用于遍历和处理查询结果集的一个高级结构。
- 游标在存储过程和函数中被广泛使用,允许程序逐行处理查询结果。
- 游标可以在内部存储逻辑中实现复杂的逻辑和操作,比如更新某些行、逐行检查数据等。
- 它通常与事务、锁定等数据库功能一起使用。
- 游标的使用是相对资源密集型的,并可能对性能产生影响。
- 例如,在上面的知乎链接中描述的是SQL游标。
-
游标方式分页(Keyset or Cursor-based Pagination):
- 这是一个分页策略,不是数据库的内置功能。
- 它使用查询中的某个值(通常是上一页的最后一个值,如ID)来获取下一页的数据,从而避免了使用OFFSET。
- 这种分页方式的优势是,对于大数据集,它比使用OFFSET更加高效。
- 这不涉及逐行处理数据或在内存中保存整个结果集,只是一个获取数据的策略。
- 例如,之前我提到的“使用上一个结果集的最后一个ID来获取下一个结果集”就是基于这种游标方式的分页策略。
总之,两者的主要区别是:SQL游标是数据库中的一个高级结构,用于逐行处理查询结果;而游标方式分页是一个高效的数据检索策略,特别是在大数据集上。
2.4 评估一张表的存储空间,一般是怎么计算的,包括内存和磁盘,假设金山的用户量为2亿,每一个人半年产生一次订单,然后需要多少个这样的数据库去存储呢?
答:
我的计算过程:
2.4.1 计算字段数
以订单表为例,首先得包含这么几个字段,以下是大概15个字段,
order_id:订单的唯一标识符。通常是一个自增的整数或者一个UUID。customer_id:与下订单的客户关联的唯一标识符。order_date:订单创建的日期和时间。shipping_address:送货地址。billing_address:账单地址。total_amount:订单的总金额。tax_amount:应付的税额。shipping_cost:运输费用。order_status:订单的状态,例如'待处理'、'已发货'、'已完成'、'已取消'等。payment_method:支付方式,如'信用卡'、'PayPal'、'货到付款'等。payment_status:支付状态,如'未支付'、'已支付'、'部分支付'等。shipping_method:送货方式,如'标准'、'快递'、'自提'等。expected_delivery_date:预期的送货日期。actual_delivery_date:实际的送货日期。notes:关于订单的任何其他说明或注释。created_at 和 updated_at:记录创建和最后更新的时间戳。
2.4.2 计算一条记录占用的空间
为了估算订单表的一条记录大概会占用多少字节,我们需要考虑每个字段的数据类型和所占的字节。以下是一个简化的估算,基于您前面提到的订单表字段:
- order_id: 假设为INT,占用4字节。
- customer_id: 假设为INT,占用4字节。
- order_date: 假设为DATETIME,占用8字节。
- shipping_address: 假设为VARCHAR(255),占用的实际字节数取决于实际内容,但最大为255字节。
- billing_address: 同上,最大255字节。
- total_amount: 假设为DECIMAL(10,2),占用14字节。
- tax_amount: 假设为DECIMAL(10,2),占用14字节。
- shipping_cost: 假设为DECIMAL(10,2),占用14字节。
- order_status: 假设为VARCHAR(50),最大50字节。
- payment_method: 假设为VARCHAR(50),最大50字节。
- payment_status: 假设为VARCHAR(50),最大50字节。
- shipping_method: 假设为VARCHAR(50),最大50字节。
- expected_delivery_date: 假设为DATE,占用3字节。
- actual_delivery_date: 假设为DATE,占用3字节。
- notes: 假设为TEXT,实际占用的字节取决于内容,但假设平均长度为100字节。
- created_at: 假设为DATETIME,占用8字节。
- updated_at: 假设为DATETIME,占用8字节。
假设每个VARCHAR字段平均使用其长度的一半,那么总的字节数为:
只考虑字段:4 + 4 + 8 + 127.5 + 127.5 + 14 + 14 + 14 + 25 + 25 + 25 + 25 + 3 + 3 + 100 + 8 + 8 = 624字节
考虑到荣誉以及索引、锁记录等的开销:624+
这个估算是基于上述字段的数据类型和假设,实际的值可能会有所不同。除了字段的存储,还需要考虑其他的开销,如记录的元数据、索引、行的开销等。所以,真实环境中,一条记录可能会占用稍微多一点的空间。
2.4.3 除了字段的存储,还需要考虑其他的开销,如记录的元数据、索引、行的开销等,大概也估算一下
除了字段本身的存储空间,一条数据库记录的实际存储空间通常会受到以下几个方面的影响:
-
行开销:每行数据都会有一些额外的字节作为开销,这与特定的数据库系统有关。例如,在MySQL的InnoDB存储引擎中,每行有一些固定的开销。
-
记录的元数据:这可能包括版本信息、时间戳、事务ID等,用于MVCC (多版本并发控制) 和其他数据库内部操作。
-
NULL值的标识:数据库需要某种方法来标识某个字段是否为NULL。这通常是通过每行的额外字节来实现的。
-
索引:如果表中的某个字段被索引,那么索引本身也会消耗存储空间。索引的大小取决于索引的类型、被索引字段的大小、数据的独特性等。每种索引(如B-tree,哈希,R-tree等)都有自己的空间要求。
-
填充因子:某些数据库存储引擎可能不会完全填满每个数据库页。填充因子定义了数据库页中应该留给数据的空间百分比。
为了估算以上因素的空间需求,我们可以考虑以下简化的计算:
- 行开销:以MySQL的InnoDB为例,每行大约有5字节的开销。
- 记录的元数据:在InnoDB中,这部分的开销可能为5-7字节。
- NULL值的标识:假设每个字段使用1位(即1/8字节)来标识
是否为NULL,那么对于上述的17个字段,这将是2.125字节。
4. 索引:索引的大小非常依赖于数据和所使用的索引类型。作为一个简化的估计,假设我们为order_id和customer_id创建了两个B-tree索引。B-tree索引的大小主要取决于键的大小、树的深度和填充因子。假设每个索引条目占用20字节(键的大小+指针),对于100,000条记录的表,索引大小约为2MB。如果我们按记录计算,那么每条记录为这两个索引贡献了约20字节。
- 填充因子:假设填充因子为90%,这意味着实际上每页只有90%的空间用于数据存储。但这不直接增加每条记录的大小,而是影响整个表的存储效率。
将上述所有因素加起来:
- 字段存储:624字节(前面的计算)
- 行开销:5字节
- 元数据:6字节(取平均值)
- NULL标识:2.125字节
- 索引:20字节(平均)
合计:657.125字节
这只是一个大致估算,实际存储需求可能会有所不同,取决于数据、数据库管理系统的具体实现、索引的具体结构和其他因素。
2.4.4 总量计算:一年产生的订单数 * 一条记录占用的空间大小
金山两亿用户,一年产生的订单量可以达到4亿,那么需要的总的磁盘空间为
4 * 10^9 *650B*1.2 = 4*780* 10^9 =3120G=3.12T
gpt4给的评估方法:
评估一张表的存储空间不是一个绝对精确的计算,因为还涉及到很多因素,如数据库管理系统的内部实现、行溢出、索引的空间等。但以下是一个基本的方法来估算一张表的存储需求:
-
评估单行的大小:
- 列出每个字段的数据类型。
- 为每个数据类型分配其最大存储大小(例如,INT在MySQL中通常是4字节,VARCHAR(100)是100字节加上长度字段,等等)。
- 将每个字段的大小相加,得到单行的预估大小。
-
加入行的开销:
- 每个数据库系统都可能在每行数据中加入一些额外的信息,如行ID、事务ID、行锁信息等。你需要考虑这些开销。例如,在MySQL的InnoDB存储引擎中,每行大约有13字节的开销。
-
考虑填充因子和溢出:
- 不是所有的字段都会被完全填充,尤其是变长字段。因此,实际的数据大小可能小于最大值。
- 有时,一行中的数据可能不会完全适应一个页面,并可能产生溢出。这也需要考虑。
-
计算总的表大小:
- 估算表中预期的行数。
- 将单行的预估大小乘以预期的行数。
-
索引的大小:
- 为每个索引评估其大小。这涉及到考虑索引的类型(例如,B-tree,hash等)和索引的列。
- 将所有索引的大小相加。
-
其他因素:
- 如果有BLOB或TEXT字段,它们可能会被存储在单独的地方,并有其自己的开销。
- 考虑到碎片化。随着数据的插入、删除和更新,可能会产生未使用的空间。
-
合计:
- 将表的大小和所有索引的大小相加,得到总的存储需求。
这只是一个基本的估算方法。如果你需要更精确的估算,可能需要考虑使用特定于数据库的工具或命令。例如,在MySQL中,你可以使用SHOW TABLE STATUS命令来查看表的实际大小。
2.4.5 磁盘使用数量
2.5 秒杀系统中订单的唯一性怎么解决
秒杀场景中订单的唯一性是非常重要的,为了避免同一商品被重复秒杀,通常采用以下策略来确保唯一性:
-
利用数据库的唯一约束:
- 对于订单表中,可以设置商品ID和用户ID的组合为唯一约束。这样,如果一个用户尝试多次购买同一商品,数据库会因违反唯一性约束而拒绝第二次及之后的插入操作。
-
使用Redis的原子操作:
- 在秒杀开始前,将商品库存预先加载到Redis中。当用户尝试购买时,使用Redis的
DECRBY命令来原子性地减少库存。只有当库存大于0时,操作才会成功,否则秒杀失败。
- 在秒杀开始前,将商品库存预先加载到Redis中。当用户尝试购买时,使用Redis的
-
消息队列:
- 用户的秒杀请求首先进入消息队列,这样可以缓解直接冲击数据库的压力。消费者从队列中取出消息并处理,确保每个商品只被处理一次。
-
令牌桶算法:
- 使用令牌桶算法来限制系统的请求速率,只有获取到令牌的请求才能进入下一步处理。
-
前端限制:
- 在前端实现防重复提交机制,例如禁用按钮,或使用一次性token来防止重复提交。
2.6 设计一个高并发的分布式id生成器(场景设计题)
设计一个高并发的分布式ID生成器需要确保ID的唯一性、连续性(可选)和高效性。以下是几种常用的方法:
-
Twitter的Snowflake算法:
- Snowflake是Twitter开源的分布式ID生成算法,它可以生成一个64位的ID。由时间戳、机器id、数据中心id、序列号组成。这保证了ID的全局唯一性和趋势递增。
-
UUID:
- UUID可以确保全局唯一性,但它的长度较长(32个字符),并且是无序的。
-
Redis的
INCR命令:- 使用Redis的
INCR命令来生成连续的ID。如果需要跨多个实例生成ID,可以为每个实例分配一个范围,如:实例1生成1-1000,实例2生成1001-2000等。
- 使用Redis的
-
数据库自增ID + 双buffer:
- 使用数据库的自增ID功能,结合双buffer技巧。当一个buffer用完时,另一个buffer预先加载下一个范围的ID。
-
Segment模式:
- 预先在数据库中分配一个ID段,例如1-1000。应用在使用这个范围的ID时不需要访问数据库,当这个范围的ID用完时,再从数据库中申请下一个范围。
-
结合多种策略:
- 在某些场景下,可以结合多种策略来生成ID。例如,使用Snowflake算法生成的ID作为主ID,结合数据库的自增ID作为子ID。
总之,选择哪种ID生成策略取决于具体的应用场景和需求,如是否需要ID连续、是否需要全局唯一、生成的ID长度等。
3 消息队列
3.1 为什么使用kafka而不是rabbitMQ呢
答:
(1)性能瓶颈
(2)kafka高效的数据结构
(3)推-拉模型能够使用发送和多种消费速率
(4)日志持久化,能够进行消息重放
4 redis
4.1 redis做分布式锁怎么实现的
答:
4.2 redission分布式锁具体是怎么实现的
5 rpc框架
5.1 你实现rpc的思路是怎么样的,怎么做任务拆减(其实就是在问rpc框架的组成部分)
实现一个RPC框架通常是一个复杂的工作,需要考虑网络通信、序列化/反序列化、服务发现、负载均衡等多个方面。以下是一个基本的实现思路和任务拆解方法:
-
定义RPC协议:
- 确定一个协议来规定请求和响应的格式。
- 例如:头部信息(包括版本、消息类型、消息长度等) + 消息体。
-
网络通信:
- 基于TCP/IP实现基本的网络通信功能。
- 使用NIO或者框架如Netty来实现高效的通信。
-
序列化/反序列化:
- 选择或实现一个序列化协议,如JSON、Protobuf、Thrift等。
- 实现请求和响应的序列化和反序列化。
-
服务注册与发现:
- 使用Zookeeper、Consul或其他服务注册中心来实现服务的注册与发现。
- 客户端通过注册中心发现服务端的地址。
-
负载均衡:
- 实现多种负载均衡策略,如轮询、随机、权重等。
- 客户端在有多个服务端地址时,使用负载均衡策略选择一个。
-
超时与重试机制:
- 添加调用超时设置。
- 添加重试机制,当调用失败时可选择重试。
-
异常处理:
- 定义和处理各种异常,如网络异常、序列化异常、业务异常等。
任务拆解:
- 设计并实现RPC协议。
- 实现基于Netty的网络通信模块。
- 实现序列化/反序列化模块。
- 实现服务注册与发现模块。
- 实现负载均衡模块。
- 添加超时和重试机制。
- 定义和处理异常。
5.2 假设我要现在写了一个服务,要对接你的这个rpc框架,得注意些什么呢
当你要将你的服务接入到一个RPC框架时,通常需要注意以下几点:
-
服务定义:
- 根据RPC框架的要求定义服务接口。例如,如果框架使用gRPC,那你需要用ProtoBuf定义服务接口。
-
依赖引入:
- 引入RPC框架的相关依赖库或模块。
-
服务注册:
- 在启动服务时,需要将服务注册到指定的服务注册中心。
-
网络配置:
- 确保服务的网络端口、IP和其他配置与RPC框架相匹配。
-
异常处理:
- 确保你的服务可以处理RPC调用中可能出现的异常,并给出适当的响应。
-
序列化注意事项:
- 如果RPC框架使用了特定的序列化方式(如ProtoBuf、Thrift等),你需要确保服务的输入/输出数据结构与之匹配。
-
版本管理:
- 如果RPC框架支持版本管理,确保正确地设置和管理你的服务版本。
-
监控与日志:
- 接入RPC框架的服务应提供适当的监控和日志,以便于追踪和调试。
-
测试:
- 在接入RPC框架之后,进行充分的测试,确保服务的功能和性能满足预期。
最后,建议详细阅读RPC框架的官方文档和最佳实践,以确保服务的稳定性和高效性。
5.3 你推荐用哪一种序列化协议
单一语言系统内使用kryo,最快,跨语言系统,比如硬件系统和java系统交互,使用protocol buffer
5.4 讲讲protobuff的向前和向后兼容性
调用方收到了新的数据结构版本时,会忽略新增的字段,实现向前兼容
当调用方收到了旧版本数据结构的响应时,新增的字段会使用默认值填充,从而不会报错
6 反问
6.1 讲讲你们部门的业务
答:我们不涉及到具体的客户端文档格式,我们部门主要的业务是云文档的上传,下载和共享编写,最复杂的是文档的规模,现在已经到达2000亿级别,刚刚跟你聊到的数据库的高可用,分库分表等技术都涉及到数据规模庞大的优化问题
6.2 您这个部门的人数
答:围绕云文档的人数大概有100号人,在线预览,缩略图,文件系统之类的
6.3 是用go吗
答:百分之95的人都是用go
6.4 表现如何
答:还可以,后面还有一个hr的面试
6.5 base有限制吗
答:一般是先去武汉做一个集中几个月的培训,然后会按照意愿分配
相关文章:

【2024秋招】2023-10-17 金山云文档服务端二面
1 实习 1.1 讲解一下curd启动器 1.2 数据同步的过程是怎么实现的,同步过程中的数据一致性怎么保证的 答:同步过程中会记录断点,表示每一批同步成功时的位置,如果对端出现问题,则下一次同步会继续从这个断点后开始同…...
一种excel多线程并发写sheet的方案
一、背景 有一次项目的需求要求导出excel,并且将不同的数据分别写到不同的sheet中。 二、 方案概述 首先一开始使用easyexcel去导出excel,结果发现导出时间需要3秒左右。于是想着能不能缩短excel导出时间,于是第一次尝试使用异步线程去查询数…...
深入了解接口测试:揭秘网络分层和数据处理!
网络分层和数据 上一小节中介绍了接口测试中一些必要重要的定义,这一节我们来讨论一下在学习接口测试过程中我们要关注的最重要的东西:网络分层和数据。 首先,我们来尝试理解一下,为什么网络是要分层的呢? 我们可以…...

Java并发编程
进程和线程 进程即程序的一次执行过程,各个进程之间是独立的。线程是更小的单位,一次进程中,可能会有多个线程,可能会相互影响,各个线程有自己的程序计数器,虚拟机栈和本地方法栈,同时共同使用…...

vue+echarts实现依赖关系无向网络拓扑结图节点折叠展开策略
目录 引言 一、设计 1. 树状图(不方便呈现节点之间的关系,次要考虑) 2. 力引导依赖关系图 二、力引导关系图 三、如何实现节点的Open Or Fold 1. 设计逻辑 节点展开细节 节点收缩细节 代码实现 四、结果呈现 五、完整代码 引言 我…...

Unity3d 灯光阴影开启,法线贴图出现BUG
URP项目打开灯光的阴影后,法线贴图出现BUG 解决方案:按照下图所示调整材质的选项即可...
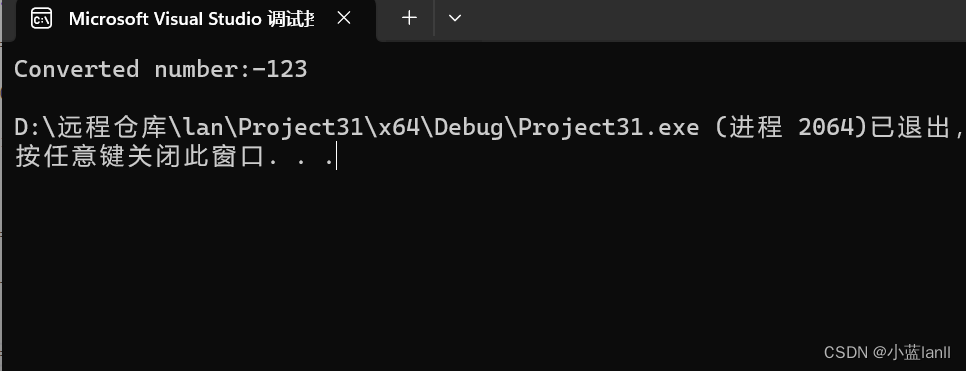
c语言:模拟实现atoi函数
atoi函数的功能和用法: 主要功能:将字符串转换为整数。例如,将字符类型的“123”转换为整数123. #include <stdio.h> #include <stdlib.h>int main() {char str[] "123";int num atoi(str);printf("Converted …...
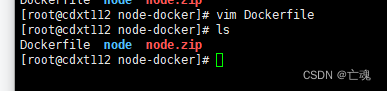
Docker 使用心得
创建一个docker 镜像,相关运行代码,放在docker镜像文件同级, pm2 不能与 docker一起使用() # node 服务docker FROM node:10.16.3LABEL author"sj"RUN mkdir -p /var/nodeCOPY ./node /var/nodeWORKDIR /va…...
Nacos 架构原理
基本架构及概念 服务 (Service) 服务是指一个或一组软件功能(例如特定信息的检索或一组操作的执行),其目的是不同的客户端可以为不同的目的重用(例如通过跨进程的网络调用)。Nacos 支持主流的服务生态,…...

尝试修改vim光标的思路
尝试修改vim光标,失败 想让vim的光标在不同模式下显示不同样式 尝试了很多方法,但是没有作用 " Set cursor shape and color if &term ~ "xterm"" INSERT modelet &t_SI "\<Esc>[6 q" . "\<Esc&…...
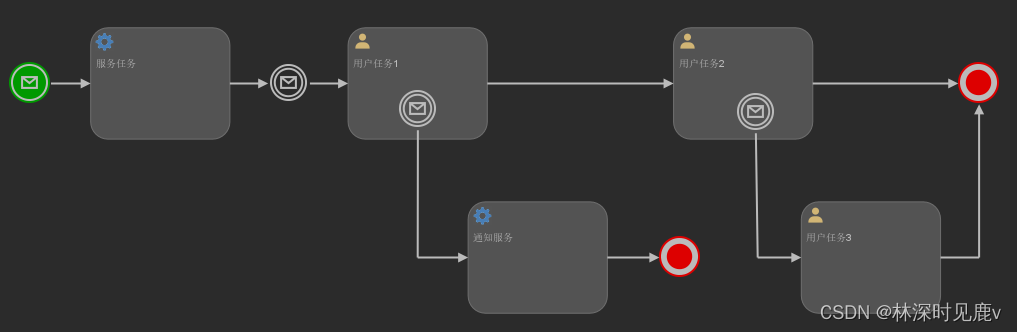
SpringBoot整合Activiti7——消息事件(十)
文章目录 消息事件开始事件中间事件边界事件代码实现xml文件测试流程流程执行步骤 消息事件 消息事件只有一个接收者,消息具有名字与载荷。 信息会储存在 act_ru_event_subscr 表中。 <!-- 定义消息 --> <message id"msgId1" name"msgName…...

高翔:《自动驾驶与机器人中的SLAM技术 》-Slam_in_autonomous_driving 编译过程中遇到的问题
使用的环境是ubuntu20.04 问题1.安装g2o没有问题,不过在编译整个项目工程时候报错: ”openmp_mutex.h: 30:10: fatal error: g2o/config.h: No such file or directory“: 解决办法: 只需要将/thirdparty/g2o/build/g2o下的config.h放到/…...

org.springframework.security.crypto.bcrypt.BCryptPasswordEncoder 实现密码加密 验证 代码示例
BCryptPasswordEncoder 是 Spring Security 提供的用于加密和验证密码的实现类。它使用强大的 BCrypt 散列函数来存储密码的散列值,提供了一种安全的密码存储方法。以下是一个简单的示例代码,演示如何使用 BCryptPasswordEncoder 进行密码加密和验证&…...
《微信小程序开发从入门到实战》学习三十八
4.2 云开发JSON数据库 4.2.9 条件查询与查询指令 在查询数据时,有时需要对查找的数据添加一些限定条件,只获取满足给定条件的数据,这样的查询称为条件查询。 可以在集合引用上使用where方法指定查询条件,再用get方法࿰…...
云服务器哪家便宜?亚马逊AWS等免费云服务器推荐
在这数字化的时代,云计算技术越来越广泛应用于各种场景,尤其是云服务器,作为一种全新的服务器架构正在逐渐取代传统的物理服务器,“云服务器哪家便宜”等用户相关问题也受到越来越多的关注。自从亚马逊最早推出了首个云计算服务—…...

Linux删除了大文件为什么磁盘空间没有释放?
某天,收到监控系统的告警信息,说磁盘空间占用过高,登上服务器,使用 df -h 一看,发现磁盘占用率已经 96%了: 通过查看 /usr/local/nginx/conf/vhost/xxx.conf 找到 access_log 和 error_log 的路径&#x…...

编写bat脚本执行msyql建库sql
使用cmd命令执行(windows下) 【MySQL的bin目录】\mysql –u用户名 –p密码 –D数据库<【sql脚本文件路径全名】,示例: D:\mysql\bin\mysql –uroot –p123456 -Dtest<d:\test\ss.sql 注意: A、如果在sql脚本文件中使用了use 数据库&…...
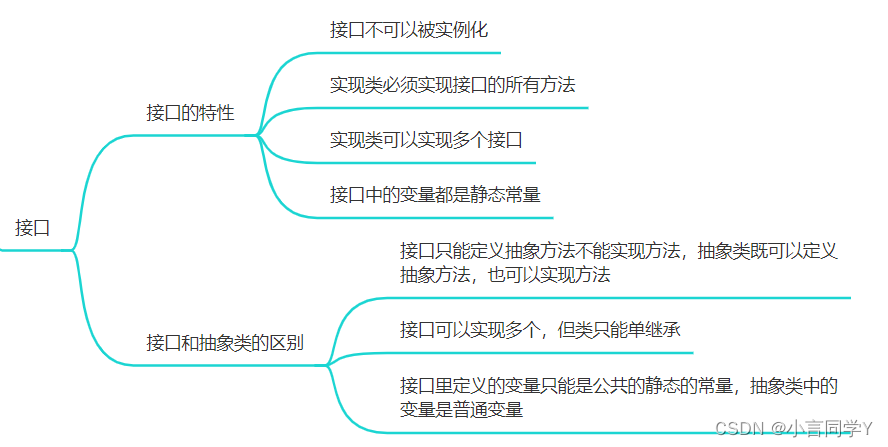
【JavaSE学习专栏】第04篇 Java面向对象
文章目录 1 面向过程&面向对象2 类和对象2.1 对象的特征2.2 java类及类的成员2.3 类的语法格式 3 创建与初始化对象3.1 类的成员之一:属性3.2 类的成员之二:方法3.3 类的成员之三:构造器(构造方法)3.3.1 无参构造方…...

sCrypt 在英国伦敦 Exeter 大学讲学
6月5日,sCrypt CEO晓晖和他的两位同事在英国伦敦Exeter大学举行了一场精彩的讲座。刘晓晖向听众们详细介绍了sCrypt智能合约开平台,并演示了如何使用sCrypt来开发基于比特币的智能合约。他用生动形象的语言,深入浅出地解释了这个领域复杂而又…...
人工智能基础创新的第二增长曲线
编者按:2023年是微软亚洲研究院建院25周年。借此机会,我们特别策划了“智启未来”系列文章,邀请到微软亚洲研究院不同研究领域的领军人物,以署名文章的形式分享他们对人工智能、计算机及其交叉学科领域的观点洞察及前沿展望。希望…...

IBM与Arm合作推进双架构主机系统开发
IBM和Arm宣布合作开发能够运行IBM和Arm双重工作负载的硬件,使Arm软件能够在IBM主机上运行。两家公司计划在三个方面展开合作:构建虚拟化工具,让Arm软件能够在IBM平台上运行;确保Arm应用程序符合受监管行业必须遵循的安全和数据驻留…...
、**运行**(正在CPU执行)、**阻塞**(等待某事件如I/O完成,主动放弃CPU))
三态模型:**就绪**(已获除CPU外所有资源,等待调度)、**运行**(正在CPU执行)、**阻塞**(等待某事件如I/O完成,主动放弃CPU)
🔹 进程与线程 进程是资源分配的基本单位,拥有独立地址空间;线程是CPU调度的基本单位,同一进程内线程共享代码段、数据段和打开文件等资源,但有独立栈和寄存器上下文。线程切换开销远小于进程切换(无需TLB刷…...

Go语言的项目结构:从单体到微服务
Go语言的项目结构:从单体到微服务 项目结构的重要性 在软件开发中,项目结构是影响代码质量和可维护性的关键因素。一个良好的项目结构可以: 提高代码的可读性和可维护性促进团队协作和代码共享便于测试和部署支持代码的重用和扩展降低项目…...
)
告别SDK迷宫:手把手教你用CCS12.1.0为TMS320F280039搭建纯净工程骨架(附文件屏蔽指南)
告别SDK迷宫:手把手教你用CCS12.1.0为TMS320F280039搭建纯净工程骨架(附文件屏蔽指南) 第一次打开C2000Ware MotorControl SDK时,那种被数百个文件夹和文件淹没的感觉,相信很多开发者都深有体会。面对如此庞大的资源库…...

霸王餐外卖接口对接中的签名校验、加密传输 Java 后端实现细节
霸王餐外卖接口对接中的签名校验、加密传输 Java 后端实现细节 在霸王餐(免费试吃)及外卖CPS分销系统的开发中,数据的安全性是核心命脉。由于涉及用户的隐私信息(如手机号、OpenId)以及核心的佣金计算逻辑,…...
完全指南:从入门到流片前的最后一道防线】)
【芯片后仿(Post-Silicon Simulation)完全指南:从入门到流片前的最后一道防线】
一、什么是后仿?为什么要做后仿?后仿,全称Post Netlist Simulation(Post-Sim)或Gate Level Simulation(GLS),是指在RTL代码综合成门级网表后,通过反标SDF(Sta…...

drm_gpusvm 与 drm_pagemap 执行顺序分析
概述 在 SVM(Shared Virtual Memory)实现中,drm_gpusvm 和 drm_pagemap 分属两个不同的抽象层,协同完成 GPU 对进程虚拟地址空间的共享访问。两者的执行顺序并非固定的"先底层后上层",而是根据操作场景有不同…...

不再依赖翻译专员:跨马翻译让运营人员也能独立完成高质量多语言出图
一、一个让中型跨境团队头疼的问题 我们团队从最初的单人作战发展到现在的十五人规模,花了大概三年时间。团队架构从最早的"运营一肩挑",逐步细分为运营组、产品组、设计组、客服组和市场组。分工越来越明确,但问题也随之而来——翻…...

天梯赛L2-006 树的遍历
L2-006 树的遍历 给定一棵二叉树的后序遍历和中序遍历,请你输出其层序遍历的序列。这里假设键值都是互不相等的正整数。 输入格式: 输入第一行给出一个正整数N(≤30),是二叉树中结点的个数。第二行给出其后序遍历序…...

物联网设备搜索终极指南:Shodan与Censys实战应用
物联网设备搜索终极指南:Shodan与Censys实战应用 在当今万物互联的时代,物联网设备搜索已经成为网络安全领域的关键技能。通过Shodan和Censys这两大专业工具,你可以轻松发现连接到互联网的各种设备,从智能摄像头到工业控制系统&a…...