(三)Pytorch快速搭建卷积神经网络模型实现手写数字识别(代码+详细注解)
提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档
文章目录
- 前言
- Q1:卷积网络和传统网络的区别
- Q2:卷积神经网络的架构
- Q3:卷积神经网络中的参数共享,也是比传统网络的优势所在
- 4、 具体的实现代码+网络搭建
前言
深度学习pytorch系列第三篇啦,之前更了FC,NN,这篇是卷积神经网络(cNN)模型实现手写数字识别,依然是重在理解哈,具体的理解内容我都以注释的形式放在了代码中,我就直接放代码了,因为我把一些知识点和理解的东西用注释的形式写了
首先是关于卷积神经网络的一些点
Q1:卷积网络和传统网络的区别
传统网络只适合结构化数据,不适合图像数据,由于图像数据的数据量大(表现为像素点多),传统网络需要使用的参数量太大
Q2:卷积神经网络的架构
卷积神经网络包括:输入层,卷积层,池化层,全连接层
重点介绍卷积层!!
卷积就是针对每个区域去计算特征。可以这样做的原因是:图片是有像素点构成的,针对每个像素点进行处理,需要的参数量过于庞大,并且相邻的像素点之间是存在联系的
特征图的个数与卷积核的个数一致。每个卷积核通过对输入特征图进行卷积操作,生成一个输出特征图。因此,卷积核的个数决定了输出的特征图的个数。
使用不同的卷积核学习同一个位置,可以得到不同的特征图,从而使特征多样化
卷积核的大小一般使用3*3
卷积核的大小规格一般是固定的,卷积核的数量理论上是越多越好
卷积层涉及的参数有:滑动窗口步长,卷积核尺寸,边缘填充,卷积核个数
卷积结果计算公式:长:h2=(h1-Fh+2p)/s +1 宽:w2=(w1-Fw+2p)/s +1
其中:w1,h1表示输入的宽度,长度;w2和h2表示输出特征图的宽度、长度,F表示卷积核的长和宽,s表示滑动窗口的补偿,p表示边界填充
经过卷积操作后,特征图的长和宽也可以保持不变
池化层的作用就是筛选好的特征,pool是只筛选位置的,channel是全部使用的
池化也称为下采样,(一次只能下采样原来的一半,不能直接224-16)
卷积神经网络由多个block组成,重点就在于怎么设计这个block的组成
关于卷积神经网络的层数,带权重参数的就算是一层,6个conn+1个fc,就可以说是7层网络结构
Q3:卷积神经网络中的参数共享,也是比传统网络的优势所在
同一个卷积核在各个位置上的参数都是一致的
权重参数的个数与输入数据的大小无关
4、 具体的实现代码+网络搭建
# 读取数据
import torch
import torch.nn as nn
import torch.optim as optim
import torch.nn.functional as F
from torchvision import datasets,transforms
# transforms 进行预处理,比如进行tensor转换
import matplotlib.pyplot as plt
import numpy as np
#全连接:batch*28*28,全连接各个像素点之间无关
# cnn:batch*1*28*28 ,多了一个参数channel,卷积会综合考虑一个窗口之间的关系,因此各个像素点并不是独立的,卷积网络更适合处理图像数据
# 定义超参数
input_size = 28 #图像的总尺寸28*28
num_classes = 10 #标签的种类数
num_epochs = 3 #训练的总循环周期
batch_size = 64 #一个撮(批次)的大小,64张图片
# 训练集
train_dataset = datasets.MNIST(root='./data',train=True,transform=transforms.ToTensor(),download=True)
# 测试集
test_dataset = datasets.MNIST(root='./data',train=False,transform=transforms.ToTensor())# 构建batch数据
train_loader = torch.utils.data.DataLoader(dataset=train_dataset,batch_size=batch_size,shuffle=True)
test_loader = torch.utils.data.DataLoader(dataset=test_dataset,batch_size=batch_size,shuffle=True)
# 卷积网络模块构建
# 一般卷积层,relu层,池化层可以写成一个套餐
# 注意卷积最后结果还是一个特征图,需要把图转换成向量才能做分类或者回归任务
# 定义一个网络
class CNN(nn.Module):def __init__(self):# 构造函数# 卷积网络一般是组合进行的:conv pool relu可以当一个组合super(CNN, self).__init__()self.conv1 = nn.Sequential( # 输入大小 (1, 28, 28)nn.Conv2d( # 2d卷积做任务in_channels=1, # 灰度图out_channels=16, # 要得到几多少个特征图,就是卷积核的个数,相当于有16个卷积核kernel_size=5, # 卷积核大小 5*5的stride=1, # 步长padding=2, # 如果希望卷积后大小跟原来一样,需要设置padding=(kernel_size-1)/2 if stride=1,一般是这么希望的# 如果不能整除pytorch采用向下取整), # 输出的特征图为 (16, 28, 28)nn.ReLU(), # relu层nn.MaxPool2d(kernel_size=2), # 进行池化操作(2x2 区域), 输出结果为: (16, 14, 14),一般是pooling后是之前的一半)self.conv2 = nn.Sequential( # 下一个套餐的输入 (16, 14, 14)nn.Conv2d(16, 32, 5, 1, 2), # 输出 (32, 14, 14)nn.ReLU(), # relu层nn.Conv2d(32, 32, 5, 1, 2),nn.ReLU(),nn.MaxPool2d(2), # 输出 (32, 7, 7))self.conv3 = nn.Sequential( # 下一个套餐的输入 (32, 7, 7)nn.Conv2d(32, 64, 5, 1, 2), # 输出 (64, 7, 7)nn.ReLU(), # 输出 (64, 7, 7))# 只有pool的时候才会筛选特征self.out = nn.Linear(64 * 7 * 7, 10) # 全连接层得到的结果,最后的任务是10分类任务,进行一个wx+b的操作去做分类def forward(self, x):x = self.conv1(x)x = self.conv2(x)x = self.conv3(x)x = x.view(x.size(0), -1) # flatten操作,结果为:(batch_size, 32 * 7 * 7),和reshape操作一样# reshape操作:总的大小是不变的,提供一个维度后,后边的维度自动计算# 比如当前的x:64*7*7,x.size:64,也就是要从三维转成两维,总的大小不变,就变为64*49这样,-1可以简单的看成一个占位符号# 变换维度,开始是64*7*7,转成batchsize*特征个数,比如64*49output = self.out(x)return output
# 定义准确率
def accuracy(predictions, labels):pred = torch.max(predictions.data, 1)[1] # 最大值是多少,最大值的索引,只要索引就可以rights = pred.eq(labels.data.view_as(pred)).sum()return rights, len(labels)
# 训练网络模型
# 实例化
net = CNN()
# 损失函数
criterion = nn.CrossEntropyLoss()
# 优化器,学习率是0.001
optimizer = optim.Adam(net.parameters(), lr=0.001) # 定义优化器,普通的随机梯度下降算法
# 开始训练循环
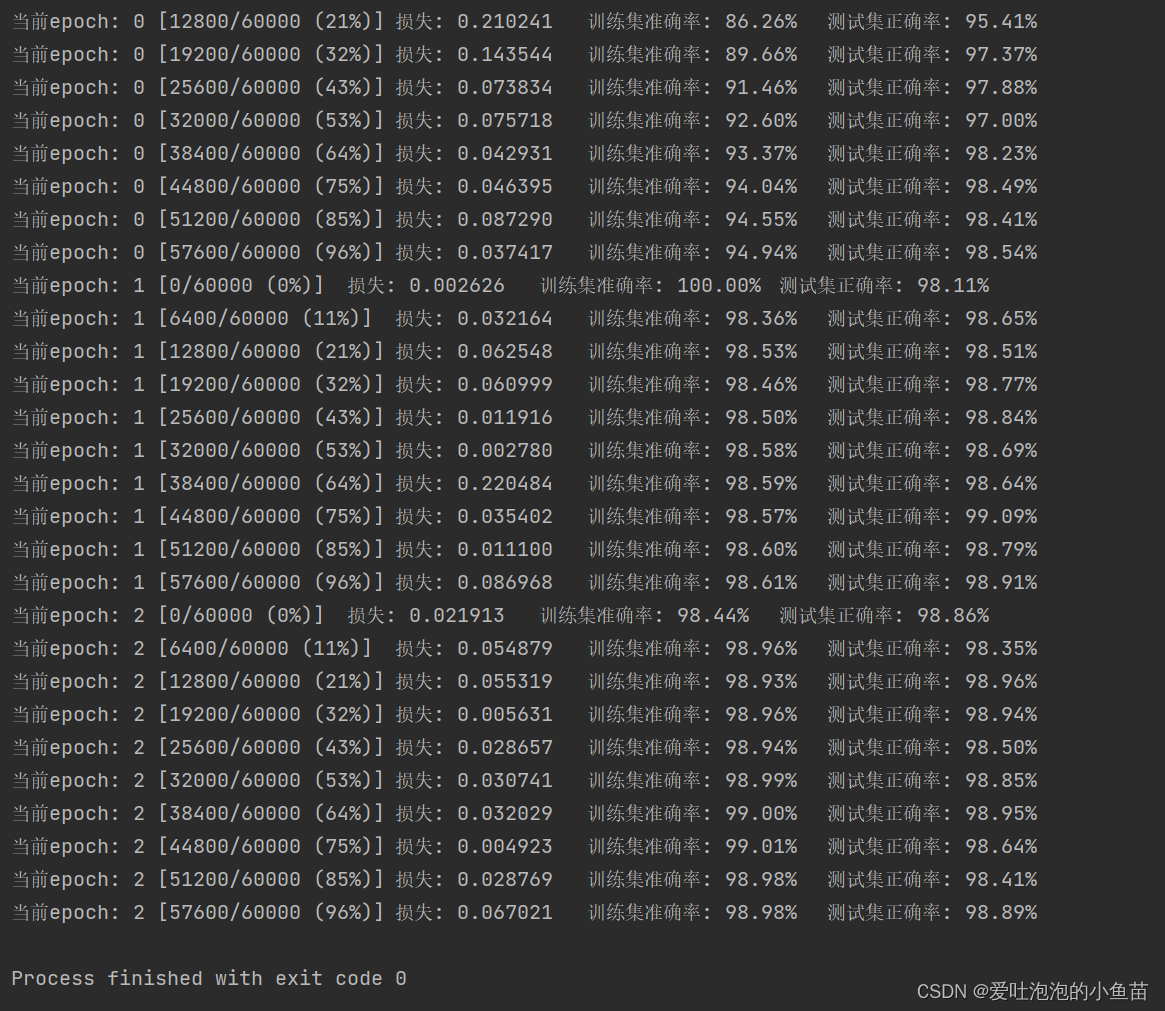
for epoch in range(num_epochs):# 当前epoch的结果保存下来train_rights = []for batch_idx, (data, target) in enumerate(train_loader): # 针对容器中的每一个批进行循环net.train()output = net(data)loss = criterion(output, target)optimizer.zero_grad()loss.backward()optimizer.step()right = accuracy(output, target)train_rights.append(right)# 每一个batch都进行训练,每一百个batch进行一次评估if batch_idx % 100 == 0:net.eval()val_rights = []for (data, target) in test_loader:output = net(data)right = accuracy(output, target)val_rights.append(right)# 准确率计算train_r = (sum([tup[0] for tup in train_rights]), sum([tup[1] for tup in train_rights]))val_r = (sum([tup[0] for tup in val_rights]), sum([tup[1] for tup in val_rights]))print('当前epoch: {} [{}/{} ({:.0f}%)]\t损失: {:.6f}\t训练集准确率: {:.2f}%\t测试集正确率: {:.2f}%'.format(epoch, batch_idx * batch_size, len(train_loader.dataset),100. * batch_idx / len(train_loader),loss.data,100. * train_r[0].numpy() / train_r[1],100. * val_r[0].numpy() / val_r[1]))
实现结果
相关文章:
(三)Pytorch快速搭建卷积神经网络模型实现手写数字识别(代码+详细注解)
提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档 文章目录 前言Q1:卷积网络和传统网络的区别Q2:卷积神经网络的架构Q3:卷积神经网络中的参数共享,也是比传统网络的优势所在4、 具体的实现代码网络搭建…...
【代码】多种调度模式下的光储电站经济性最优 储能容量配置分析matlab/yalmip
程序名称:多种调度模式下的光储电站经济性最优储能容量配置分析 实现平台:matlab-yalmip-cplex/gurobi 代码简介:代码主要做的是一个光储电站经济最优储能容量配置的问题,对光储电站中储能的容量进行优化,以实现经济…...

深度学习今年来经典模型优缺点总结,包括卷积、循环卷积、Transformer、LSTM、GANs等
文章目录 1、卷积神经网络(Convolutional Neural Networks,CNN)1.1 优点1.2 缺点1.3 应用场景1.4 网络图 2、循环神经网络(Recurrent Neural Networks,RNNs)2.1 优点2.2 缺点2.3 应用场景2.4 网络图 3、长短…...

ChatGPT成为“帮凶”:生成虚假数据集支持未知科学假设
ChatGPT 自发布以来,就成为了大家的好帮手,学生党和打工人更是每天都离不开。 然而这次好帮手 ChatGPT 却帮过头了,莫名奇妙的成为了“帮凶”,一位研究人员利用 ChatGPT 创建了虚假的数据集,用来支持未知的科学假设。…...

c#利用Forms.Timer定时检测Tcp连接状态
目的:本地创建客户端连接服务器端,如果连接正常显示连接正常如果连接异常显示连接异常。 using System; using System.Collections.Generic; using System.ComponentModel; using System.Data; using System.Drawing; using System.Linq; using System.T…...

空间注意力:改变我们理解图像的方式
空间注意力:改变我们理解图像的方式 欢迎来到深度学习和计算机视觉的新时代,在这里,空间注意力机制正改变着我们理解和处理图像的方式。本文将深入探讨空间注意力的概念,它如何工作,以及为什么它在现代图像处理技术中…...
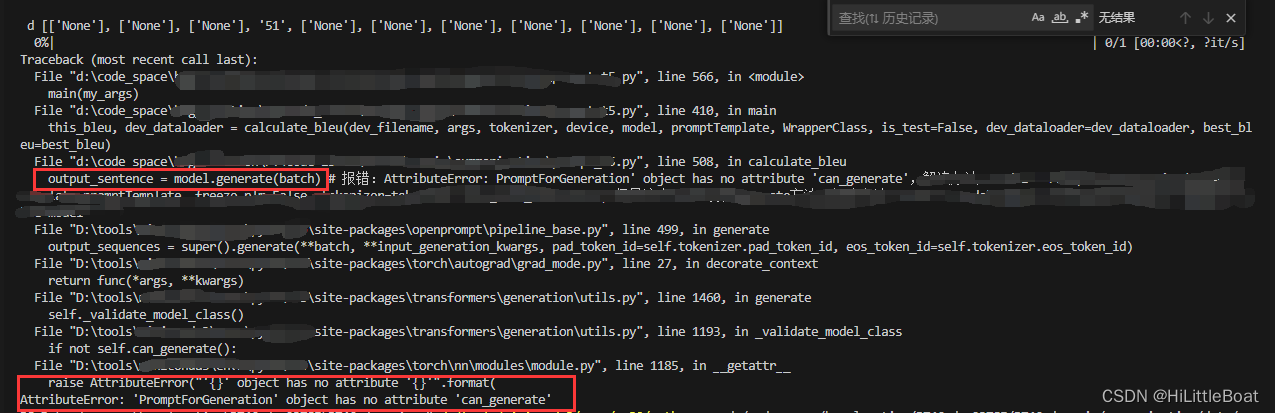
【模型报错记录】‘PromptForGeneration‘ object has no attribute ‘can_generate‘
通过这个连接中的方法解决: “PromptForGeneration”对象没有属性“can_generate” 期刊 #277 thunlp/OpenPrompt GitHub的 问题描述:在使用model.generate() 的时候报错:PromptForGeneration object has no attribute can_generate 解决方法…...

mysql学习记录
关系型数据库:不是把所有的数据全部存储在一起,而是分类存储在一起。 常见的数据库 关系型:oracle大型收费,mysql小型免费。 sql语言(操作数据库) structured query language 结构化查询语言 1.DDL 数据定义语言 创建数…...

Hdoop学习笔记(HDP)-Part.11 安装Kerberos
目录 Part.01 关于HDP Part.02 核心组件原理 Part.03 资源规划 Part.04 基础环境配置 Part.05 Yum源配置 Part.06 安装OracleJDK Part.07 安装MySQL Part.08 部署Ambari集群 Part.09 安装OpenLDAP Part.10 创建集群 Part.11 安装Kerberos Part.12 安装HDFS Part.13 安装Ranger …...
浅谈UML的概念和模型之UML九种图
1、用例图(use case diagrams) 【概念】描述用户需求,从用户的角度描述系统的功能 【描述方式】椭圆表示某个用例;人形符号表示角色 【目的】帮组开发团队以一种可视化的方式理解系统的功能需求 【用例图】 2、静态图 类图&…...
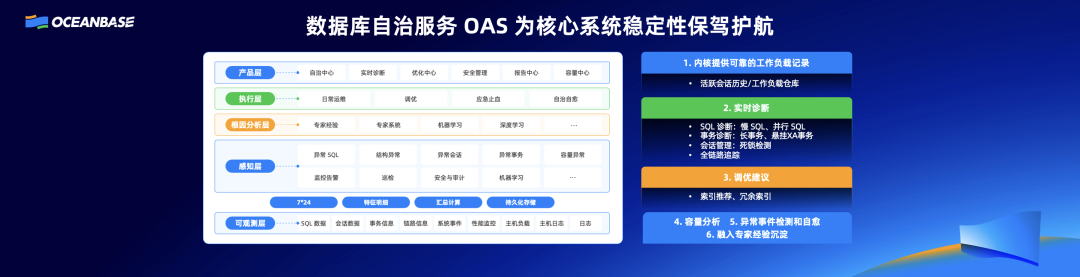
杨志丰:OceanBase助力企业应对数据库转型深水区挑战
11 月 16 日,OceanBase 在北京顺利举办 2023 年度发布会,正式宣布:将持续践行“一体化”产品战略,为关键业务负载打造一体化数据库。OceanBase 产品总经理杨志丰发表了《助力企业应对数据库转型深水区挑战》主题演讲。 以下为演讲…...
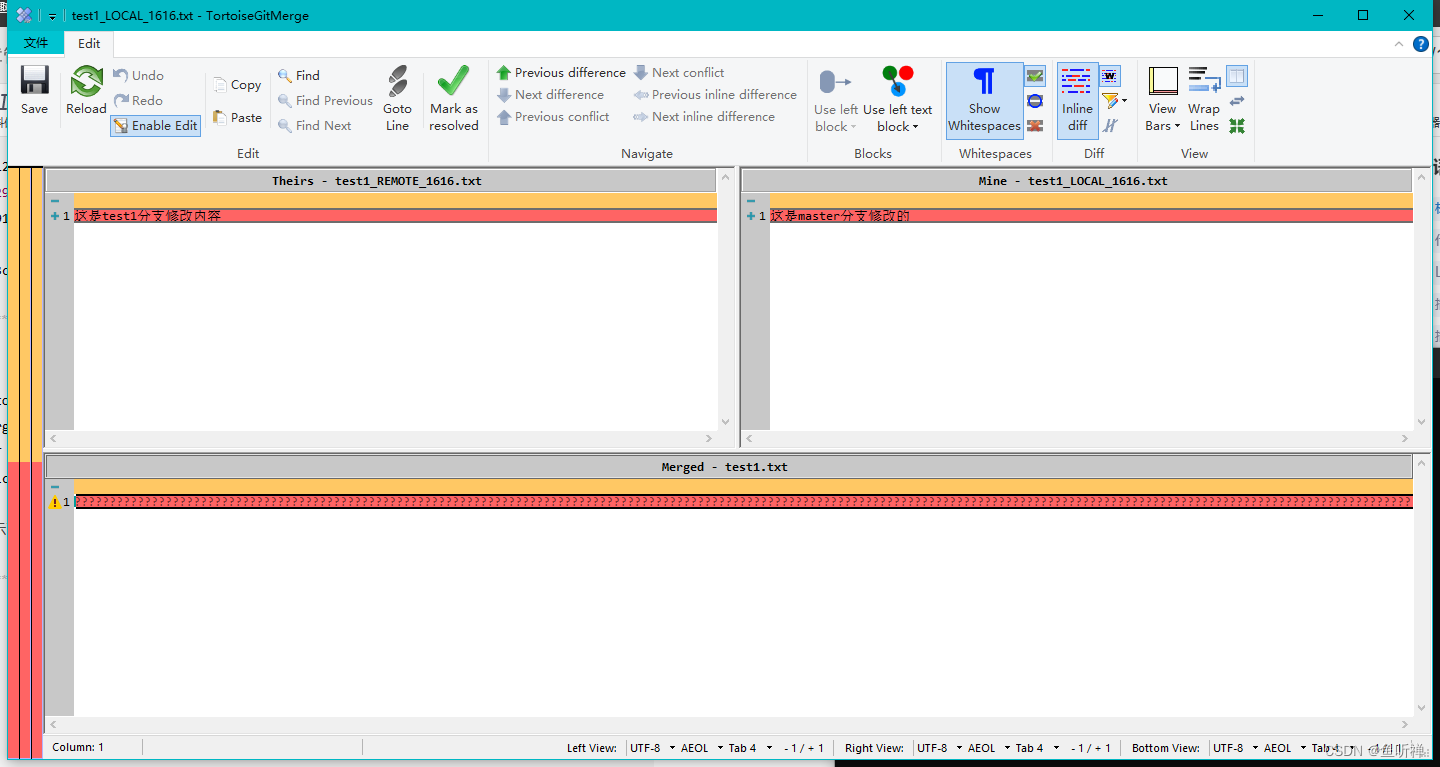
版本控制系统Git学习笔记-Git分支操作
文章目录 概述一、Git分支简介1.1 基本概念1.2 创建分支1.3 分支切换1.4 删除分支 二、新建和合并分支2.1 工作流程示意图2.2 新建分支2.3 合并分支2.4 分支示例2.4.1 当前除了主分支,再次创建了两个分支2.4.2 先合并test1分支2.4.3 合并testbranch分支 2.5 解决合并…...
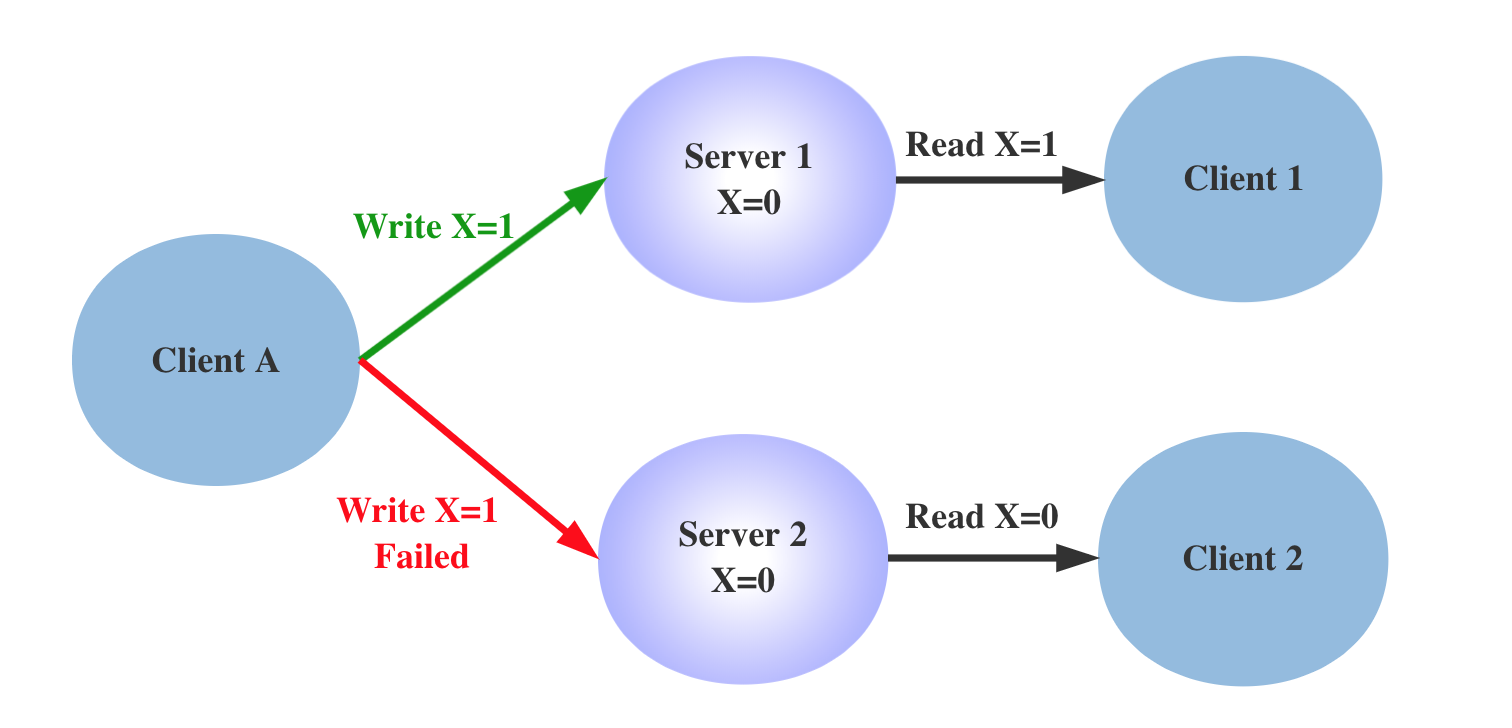
分布式系统中最基础的 CAP 理论及其应用
对于开发或设计分布式系统的架构师、工程师来说,CAP 是必须要掌握的基础理论,CAP 理论可以帮助架构师对系统设计中目标进行取舍,合理地规划系统拆分的维度。下面我们先讲讲分布式系统的特点。 分布式系统的特点 随着移动互联网的快速发展&a…...

计算机视觉(OpenCV+TensorFlow)
计算机视觉(OpenCVTensorFlow) 文章目录 计算机视觉(OpenCVTensorFlow)前言3.图像金字塔3.1 高斯金字塔3.2 拉普拉斯金字塔 4.图像轮廓图像边缘和图像轮廓的区别检测图像绘制边缘 5.轮廓近似外接矩形外接圆 6. 模板匹配6.1 什么是…...

shell语法
概论 shell是我们通过命令行与操作系统沟通的语言 shell脚本可以直接在命令行中执行,也可以将一套逻辑组织成一个文件,方便复用。 DA Terminal中的命令行可以看成是一个“shell脚本在逐行执行”。 1.脚本示例 新建一个test.sh文件,内容如…...

JAXB的XmlAttribute注解
JAXB的XmlAttribute注解,将一个JavaBean属性映射到一个XML属性。 例如,下面的Java代码,将属性currency映射到了XML的属性currency: package com.thb;import jakarta.xml.bind.annotation.XmlAttribute; import jakarta.xml.bind…...
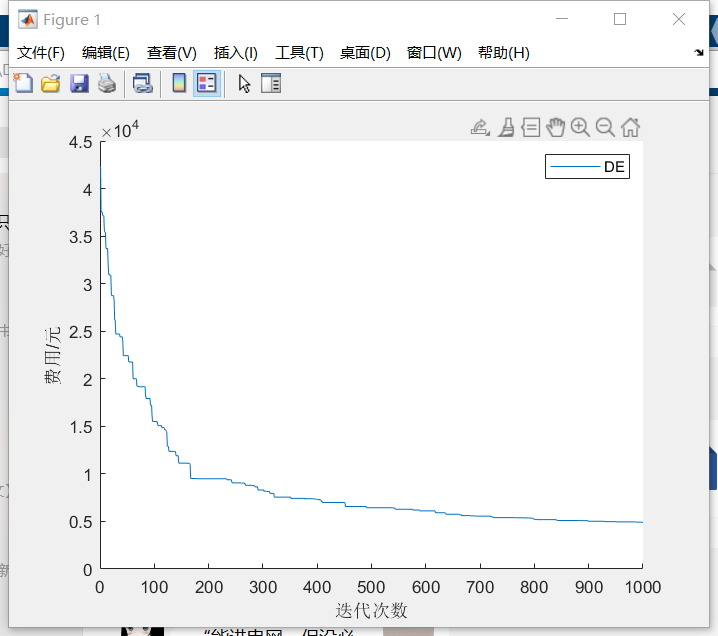
【代码】基于改进差分进化算法的微电网调度研究matlab
程序名称:基于改进差分进化算法的微电网调度研究 实现平台:matlab 代码简介:了进一步提升差分进化算法的优化性能,结合粒子群(PSO)算法的进化机制,提出一种混合多重随机变异粒子差分进化算法(DE-PSO)。所提算法不仅使用粒子群差分变异策略和…...
计算机基础知识63
Django的条件查询:查询函数 exclude exclude:返回不满足条件的数据 res Author.objects.exclude(pk1) print(res) # <QuerySet [<Author: Author object (2)>, <Author: Author object (3)>]> order_by 1、按照 id 升序排序 res …...

springboot虚拟请求——测试
springboot虚拟请求 表现层测试 web环境模拟测试 虚拟请求状态匹配——执行状态的匹配 Testvoid testStatus(Autowired MockMvc mvc) throws Exception { // //http://localhost:8080/books// 创建一个虚拟请求,当前访问的是booksMockHttpServletRequestBui…...

计算机视觉各个方向概述
计算机视觉发展很长时间了,由传统的计算机视觉到现在如火如荼的计算机视觉多模态,有很多的方向,每一个方向都是一个研究门类,有些已经比较成熟,有些还处于一个开始的阶段,相对于文本语言的处理,…...

清明节海报设计指南:4个要点打造高级感视觉呈现
每到清明临近,总有人为海报设计发愁。想做一张既体面又有格调的清明节海报,打开设计软件却不知从何下手,勉强拼凑出来的效果又总觉得差点意思。要么太过花哨显得不够庄重,要么过于简陋显得敷衍。其实高级感并不难,关键…...

温度场与锂枝晶生长的相场电势场及浓度场耦合仿真研究
comsol 锂枝晶仿真——耦合温度场 在相场,电势场和浓度场的基础上耦合了温度场,可以看不同温度对锂枝晶的影响指尖的金属晶体在电解液中野蛮生长,就像寒冬玻璃上的冰花。当我们盯着显微镜观察锂枝晶时,常忽略了一个重要变量——温…...

嵌入式软件开发中的柔性数组机制
在嵌入式系统开发中,内存资源始终是最核心的约束之一。无论是微控制器还是低功耗控制终端,程序设计都必须在有限的存储空间中实现功能、效率与可靠性的平衡。因此,开发者不仅需要关注算法逻辑,还必须重视数据结构对内存的占用方式。 在这种背景下,柔性数组成为嵌入式软件…...

基于VLFM的中文指令视觉语言导航系统设计与实现
基于VLFM的中文指令视觉语言导航系统设计与实现 一、引言 1.1 项目背景 视觉语言导航(Vision Language Navigation,VLN)是具身智能领域的核心任务之一,其目标是让智能体根据自然语言指令在三维环境中自主导航,完成路径规划与空间定位任务[reference:0]。近年来,随着大…...

星闪实战指南:10分钟掌握WS63 SDK任务调度与调试技巧
1. 星闪WS63 SDK任务调度基础 第一次接触星闪WS63 SDK的任务调度功能时,我完全被各种API搞晕了。经过几个项目的实战,才发现这套任务管理系统设计得非常巧妙。简单来说,它就像个智能管家,能帮你把各种工作安排得井井有条。 任务调…...

软考高项-第六章-项目管理概论
项目和项目集重点在于正确的做事,项目组合在于做正确的事组织过程资产:过程资产,治理文件,数据资产,知识资产,安保和安全事业环境因素:市场条件,社会和文化影响因素,监管…...

2026届学术党必备的六大降重复率工具推荐榜单
Ai论文网站排名(开题报告、文献综述、降aigc率、降重综合对比) TOP1. 千笔AI TOP2. aipasspaper TOP3. 清北论文 TOP4. 豆包 TOP5. kimi TOP6. deepseek 基于自然语言处理技术的智能应用是AI写作工具,它能辅助用户完成文本生成、语法纠…...

美元、日元、欧元怎么选?外汇新手该从哪个货币对开始?
最近有不少刚接触外汇交易的朋友问我同一个问题:美元、日元、欧元这些主流货币到底该怎么选?作为一个过来人,我想说的是——选对起步品种,比你想象中重要得多。 很多新手一上来就想着“赚快钱”,直接冲进波动剧烈的交叉…...

016、CI/CD流水线:用GitHub Actions把部署从玄学变成肌肉记忆
016、CI/CD流水线:用GitHub Actions把部署从玄学变成肌肉记忆 上周深夜,线上服务突然告警。紧急回滚时发现,测试环境通过的镜像在生产环境死活起不来。查了三个小时,最后发现是某位同事在Dockerfile里写死了测试数据库的IP。这种“…...

终极ComfyUI视频处理指南:5分钟搞定VHS_VideoCombine节点修复
终极ComfyUI视频处理指南:5分钟搞定VHS_VideoCombine节点修复 【免费下载链接】ComfyUI-VideoHelperSuite Nodes related to video workflows 项目地址: https://gitcode.com/gh_mirrors/co/ComfyUI-VideoHelperSuite 在AI绘画和视频生成领域,Com…...