【中文编码】利用bert-base-chinese中的Tokenizer实现中文编码嵌入
最近接触文本处理,查询了一些资料,记录一下中文文本编码的处理方法吧。
先下载模型和词表:bert-base-chinese镜像下载
如下图示,下载好的以下文件均存放在 bert-base-chinese 文件夹下
1. 词编码嵌入简介
按我通俗的理解,就是文本要进入模型,得编码成数字的形式,那么,怎么给定数字的形式呢,不能随便给一个数字吧,此时就需要一个词表,该表中有很多很多的字,每个字都有在该表中唯一的位置,每个字编码时,采用其在词表中的位置。
下载文件中的 vocab.txt 就是已经设定好的词表,打开看看:
2. 词编码嵌入实现
利用transformers库中的BertTokenizer实现分词编码,实例化一个tokenizer,载入预先下载好的词表,调用encode函数进行编码,encode函数有5个常用参数:
①text: 需要编码的文本;
②add_special_tokens: 是否添加特殊token,即CLS分类token和SEP分隔token;
③max_length: 文本的最大长度,根据需要处理的最长文本长度设置;
④pad_to_max_length: 是否填充到最大长度,以0补位;
⑤return_tensors: 返回的tensor类型,有4种为 [‘pt’, ‘tf’, ‘np’, ‘jax’] 分别代表 pytorch tensor、tensorflow tensor、int32数组形式和 jax tensor;
from transformers import BertTokenizerbert_name = './bert-base-chinese'
tokenizer = BertTokenizer.from_pretrained(bert_name)
text = '一念月落,一念身错,一念关山难涉过。棋逢过客,执子者不问因果。'
input_ids = tokenizer.encode(text,add_special_tokens=True,max_length=128,pad_to_max_length=True,return_tensors='pt')
print('text:\n', text)
print('text字符数:', len(text))
print('input_ids:\n', input_ids)
print('input_ids大小:', input_ids.size())
输出为:
text:一念月落,一念身错,一念关山难涉过。棋逢过客,执子者不问因果。
text字符数: 31
input_ids:tensor([[ 101, 671, 2573, 3299, 5862, 8024, 671, 2573, 6716, 7231, 8024, 671,2573, 1068, 2255, 7410, 3868, 6814, 511, 3470, 6864, 6814, 2145, 8024,2809, 2094, 5442, 679, 7309, 1728, 3362, 511, 102, 0, 0, 0,0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,0, 0, 0, 0, 0, 0, 0, 0]])
input_ids大小: torch.Size([1, 128])
查看一下tokenizer的信息:
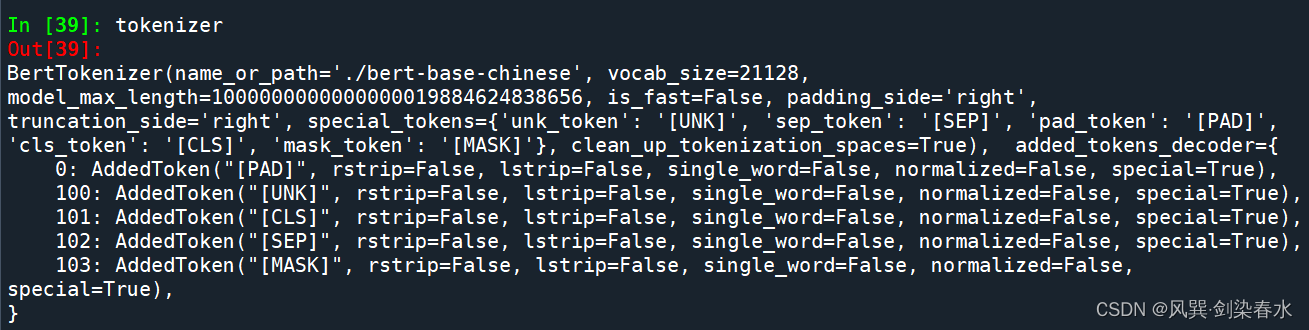
可以看到整个词表的大小为21128个字,共有5种特殊token标记:
[PAD]: 填充标记,编码为0;
[UNK]: 未知字符标记,即该字不在所定义的词表中,编码为100;
[CLS]: 分类标记,蕴含整个文本的含义,编码为101;
[SEP]: 分隔字符标记,用于断开两句话,编码为102;
[MASK]: 掩码标记,该字被遮挡,编码为103;
测试一下这些特殊token:
from transformers import BertTokenizerbert_name = './bert-base-chinese'
tokenizer = BertTokenizer.from_pretrained(bert_name)
text = '[CLS]一念月落,一念身错,[SEP]一念关山难涉过。[MASK]逢过客,执子者不问因果。[PAD][PAD][PAD],檒檒'
input_ids = tokenizer.encode(text,add_special_tokens=False,max_length=128,pad_to_max_length=False,return_tensors='pt')
print('text:\n', text)
print('text字符数:', len(text))
print('input_ids:\n', input_ids)
print('input_ids大小:', input_ids.size())
输出为:
text:[CLS]一念月落,一念身错,[SEP]一念关山难涉过。[MASK]逢过客,执子者不问因果。[PAD][PAD][PAD],檒檒
text字符数: 64
input_ids:tensor([[ 101, 671, 2573, 3299, 5862, 8024, 671, 2573, 6716, 7231, 8024, 102,671, 2573, 1068, 2255, 7410, 3868, 6814, 511, 103, 6864, 6814, 2145,8024, 2809, 2094, 5442, 679, 7309, 1728, 3362, 511, 0, 0, 0,117, 100, 100]])
input_ids大小: torch.Size([1, 39])
也可以利用tokenize函数直接实现分词,并采用convert_tokens_to_ids函数和convert_ids_to_tokens函数实现词与编码的相互转换:
from transformers import BertTokenizerbert_name = './bert-base-chinese'
tokenizer = BertTokenizer.from_pretrained(bert_name)
text = '一念月落,一念身错,一念关山难涉过。棋逢过客,执子者不问因果。'
tokens = tokenizer.tokenize(text)
input_ids = tokenizer.convert_tokens_to_ids(tokens)
tokenxx = tokenizer.convert_ids_to_tokens(input_ids)print('中文分词:\n', tokens)
print('分词-->编码:\n', input_ids)
print('编码-->分词:\n', tokenxx)
输出为:
中文分词:['一', '念', '月', '落', ',', '一', '念', '身', '错', ',', '一', '念', '关', '山', '难', '涉', '过', '。', '棋', '逢', '过', '客', ',', '执', '子', '者', '不', '问', '因', '果', '。']
分词-->编码:[671, 2573, 3299, 5862, 8024, 671, 2573, 6716, 7231, 8024, 671, 2573, 1068, 2255, 7410, 3868, 6814, 511, 3470, 6864, 6814, 2145, 8024, 2809, 2094, 5442, 679, 7309, 1728, 3362, 511]
编码-->分词:['一', '念', '月', '落', ',', '一', '念', '身', '错', ',', '一', '念', '关', '山', '难', '涉', '过', '。', '棋', '逢', '过', '客', ',', '执', '子', '者', '不', '问', '因', '果', '。']
除了BertTokenizer,还有AutoTokenizer也是常用的分词类,使用方法与BertTokenizer类似,可以参考这篇文章了解不同的Tokenizer。
相关文章:
【中文编码】利用bert-base-chinese中的Tokenizer实现中文编码嵌入
最近接触文本处理,查询了一些资料,记录一下中文文本编码的处理方法吧。 先下载模型和词表:bert-base-chinese镜像下载 如下图示,下载好的以下文件均存放在 bert-base-chinese 文件夹下 1. 词编码嵌入简介 按我通俗的…...
一文解决msxml3.dll文件缺失问题,快速修复msxml3.dll
在了解问题之前,我们必须首先清楚msxml3.dll到底是什么。DLL(Dynamic Link Libraries)文件是Windows操作系统使用的一个重要组成部分,用于存储执行特定操作或任务的代码和数据。msxml3.dll为Windows系统提供处理XML文档的功能。如…...

《React 知识点》第一篇 大括号使用{}
简介 大括号 " {} "可以用于包裹JavaScript的表达式或语句。以便在jsx中动态生成内容。 插入变量与表达式 function expressionTest() {const name "变量测试";return (<p><div>{name}</div><div>表达式 210 {2 100}</div…...
: 位移提交)
kafka入门(二): 位移提交
位移提交: Kafka的每条消息都有唯一的 offset, 用来表示消息在分区中对应的位置。有的也称之为 “偏移量”。 消费者每次在 poll() 拉取消息,它要返回的是还没有消费过的消息集, 因此,需要记录上一次消费时的消费位…...

PG时间计算
PG数据库,时间计算使用场景总结 日期之差 --**获取秒差** SELECT round(date_part(epoch, TIMESTAMP 2019-05-05 12:11:20 - TIMESTAMP 2019-05-05 10:10:10)); --**获取分钟差** SELECT round(date_part(epoch, TIMESTAMP 2019-05-05 12:11:20 - TIMESTAMP 20…...
基于51单片机的交通灯_可调时间_夜间+紧急模式
51单片机交通灯 1 讲解视频:2 功能要求3 仿真图:4 原理图PCB5 实物图6 程序设计:7 设计报告8 资料清单(提供资料清单所有文件):设计资料下载链接: 51单片机简易交通灯_可调时间_夜间紧急 仿真代…...

网络通信原理,进制转化总结
来源,做个笔记,讲的还蛮清楚通信原理-2.5 数据封装与传输05_哔哩哔哩_bilibili ip地址范围...

西南科技大学(数据结构A)期末自测练习三
一、填空题(每空1分,共10分) 1、为解决计算机主机与打印机之间速度不匹配的问题,通常设置一个打印数据缓冲区。主机将要输出的数据依次写入缓冲区,打印机则依次从缓冲区中取出数据,则该换缓冲区的逻辑结构…...
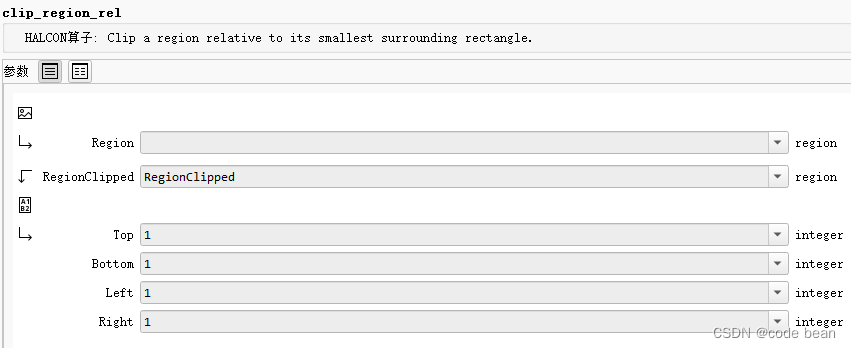
【halcon】裁剪
前言 目前我遇到的裁剪相关的函数都是以clip打头的函数。一共4个: clip_end_points_contours_xldclip_contours_xldclip_regionclip_region_rel 前面两个是对轮廓的裁剪。 后面是对区域的裁剪。 裁剪轮廓的两端 clip_end_points_contours_xld 用于实现裁剪XLD…...
vue+less+style-resources-loader 配置全局颜色变量
全局统一样式后,可配置vue.config.js实现全局颜色变量,方便在编写时使用统一风格的色彩 一、新建global.less 二、下载安装style-resources-loader npm i style-resources-loader --save-dev三、在vue.config.js中进行配置 module.exports {pluginOpt…...
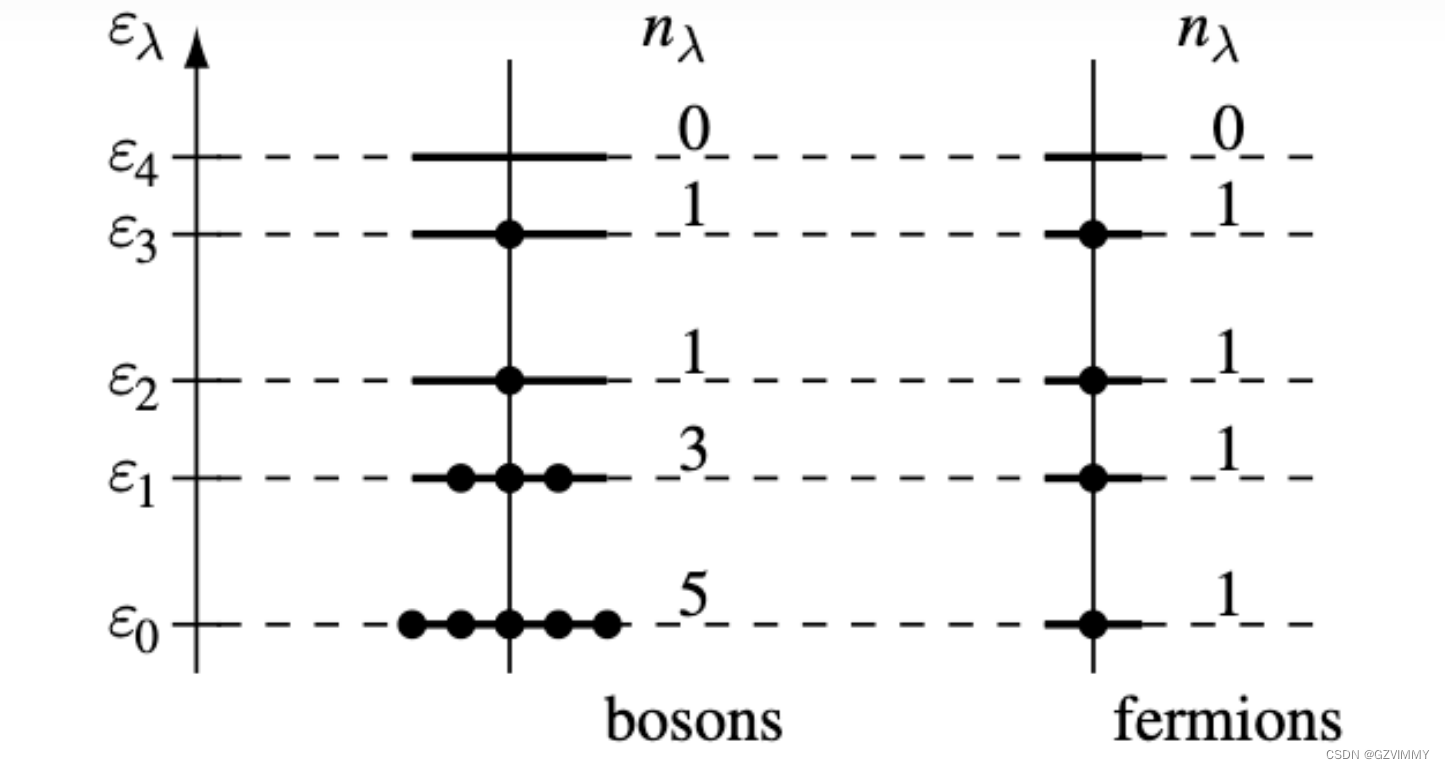
第二次量子化
专栏目录: 高质量文章导航-持续更新中 前置复盘: 玻色子和费米子: 首先,我们希望把描述单粒子态的量子力学推广到全同多粒子体系。我们的做法是从单粒子态的希尔伯特空间(Hilbert Space)出发,构造全同多粒子态的态空间——福克空间(Fock Space),它实际上就是无穷个…...
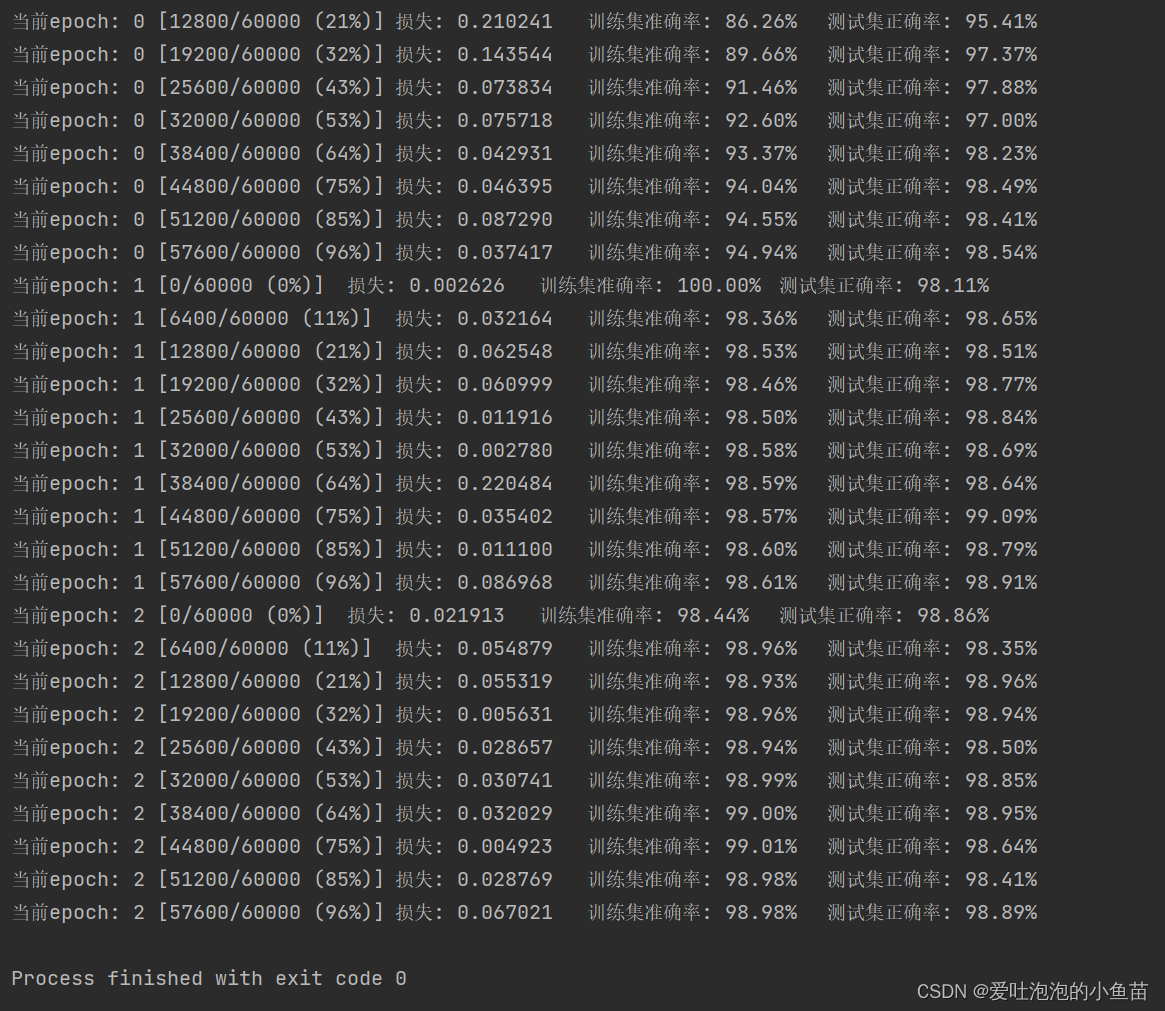
(三)Pytorch快速搭建卷积神经网络模型实现手写数字识别(代码+详细注解)
提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档 文章目录 前言Q1:卷积网络和传统网络的区别Q2:卷积神经网络的架构Q3:卷积神经网络中的参数共享,也是比传统网络的优势所在4、 具体的实现代码网络搭建…...
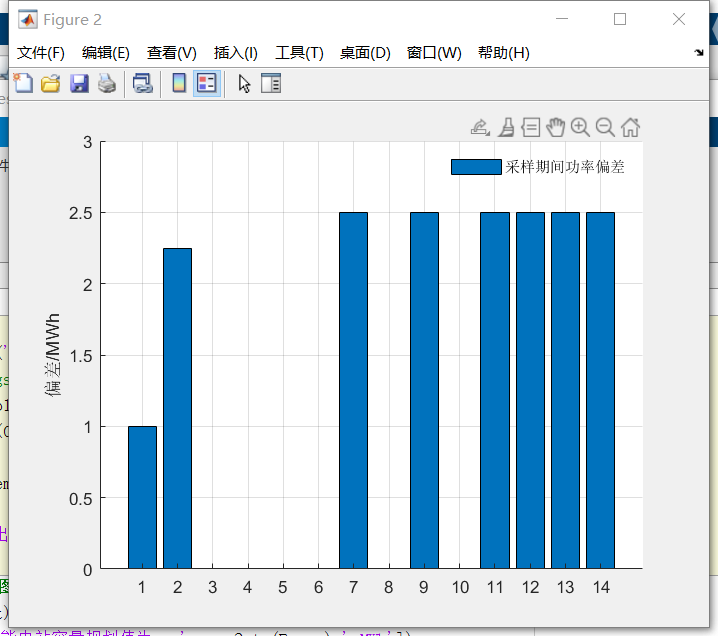
【代码】多种调度模式下的光储电站经济性最优 储能容量配置分析matlab/yalmip
程序名称:多种调度模式下的光储电站经济性最优储能容量配置分析 实现平台:matlab-yalmip-cplex/gurobi 代码简介:代码主要做的是一个光储电站经济最优储能容量配置的问题,对光储电站中储能的容量进行优化,以实现经济…...

深度学习今年来经典模型优缺点总结,包括卷积、循环卷积、Transformer、LSTM、GANs等
文章目录 1、卷积神经网络(Convolutional Neural Networks,CNN)1.1 优点1.2 缺点1.3 应用场景1.4 网络图 2、循环神经网络(Recurrent Neural Networks,RNNs)2.1 优点2.2 缺点2.3 应用场景2.4 网络图 3、长短…...

ChatGPT成为“帮凶”:生成虚假数据集支持未知科学假设
ChatGPT 自发布以来,就成为了大家的好帮手,学生党和打工人更是每天都离不开。 然而这次好帮手 ChatGPT 却帮过头了,莫名奇妙的成为了“帮凶”,一位研究人员利用 ChatGPT 创建了虚假的数据集,用来支持未知的科学假设。…...

c#利用Forms.Timer定时检测Tcp连接状态
目的:本地创建客户端连接服务器端,如果连接正常显示连接正常如果连接异常显示连接异常。 using System; using System.Collections.Generic; using System.ComponentModel; using System.Data; using System.Drawing; using System.Linq; using System.T…...

空间注意力:改变我们理解图像的方式
空间注意力:改变我们理解图像的方式 欢迎来到深度学习和计算机视觉的新时代,在这里,空间注意力机制正改变着我们理解和处理图像的方式。本文将深入探讨空间注意力的概念,它如何工作,以及为什么它在现代图像处理技术中…...
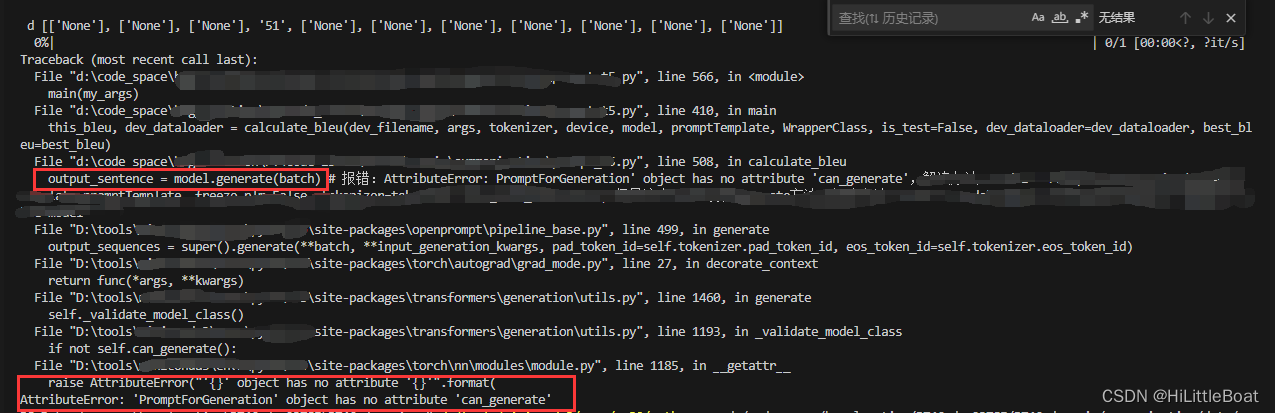
【模型报错记录】‘PromptForGeneration‘ object has no attribute ‘can_generate‘
通过这个连接中的方法解决: “PromptForGeneration”对象没有属性“can_generate” 期刊 #277 thunlp/OpenPrompt GitHub的 问题描述:在使用model.generate() 的时候报错:PromptForGeneration object has no attribute can_generate 解决方法…...

mysql学习记录
关系型数据库:不是把所有的数据全部存储在一起,而是分类存储在一起。 常见的数据库 关系型:oracle大型收费,mysql小型免费。 sql语言(操作数据库) structured query language 结构化查询语言 1.DDL 数据定义语言 创建数…...

Hdoop学习笔记(HDP)-Part.11 安装Kerberos
目录 Part.01 关于HDP Part.02 核心组件原理 Part.03 资源规划 Part.04 基础环境配置 Part.05 Yum源配置 Part.06 安装OracleJDK Part.07 安装MySQL Part.08 部署Ambari集群 Part.09 安装OpenLDAP Part.10 创建集群 Part.11 安装Kerberos Part.12 安装HDFS Part.13 安装Ranger …...

2025届毕业生推荐的十大AI辅助论文工具解析与推荐
Ai论文网站排名(开题报告、文献综述、降aigc率、降重综合对比) TOP1. 千笔AI TOP2. aipasspaper TOP3. 清北论文 TOP4. 豆包 TOP5. kimi TOP6. deepseek 在开题报告撰写进程当中,人工智能技术能够起到高效辅助功效。其一,凭…...

数仓实习实战|医疗报表电话指标缺失,完整上游排查思路
今天碰到一个问题:患者档案里明明有联系电话,但是最终报表展示的时候,这个字段就是空的。跟着师哥一步步排查下来,思路清晰了很多,也把完整的排查逻辑整理了一下,以后遇到类似问题可以直接参考一、问题场景…...

MacOS 在Trae IDE中解锁现代C++开发:从零配置到智能编码的进阶指南
1. 为什么选择Trae IDE进行现代C开发 作为一个长期使用Visual Studio和CLion的老C程序员,我第一次接触Trae IDE时就被它的AI特性惊艳到了。这不仅仅是一个代码编辑器,更像是一个懂你编程思维的智能助手。在MacOS环境下,Trae基于VSCode技术构…...

Python-for-Android终极指南:用Python代码打造原生Android应用
Python-for-Android终极指南:用Python代码打造原生Android应用 【免费下载链接】python-for-android Turn your Python application into an Android APK 项目地址: https://gitcode.com/gh_mirrors/py/python-for-android 想要用你最熟悉的Python语言开发An…...
)
收藏备用!小白程序员必看,大模型核心原理拆解(通俗易懂版)
本文专为CSDN小白程序员、AI入门者打造,用“技术拆解通俗类比”的方式,深入解析大模型的核心原理,避开专业术语壁垒。明确大模型的AI分支定位,拆解其三大底层逻辑,补充微调、提示工程的实操要点,澄清新手常…...

Python对象生命周期全链路追踪,从PyObject_MALLOC到gc_collect:一线工程师压测验证的5个致命内存误用场景
第一章:Python对象生命周期全链路追踪概览Python对象的生命周期涵盖创建、使用、引用管理直至最终销毁的全过程。理解这一链条对诊断内存泄漏、优化资源使用及编写健壮代码至关重要。对象并非仅在 __init__ 中诞生,也非仅靠 del 显式终结;其真…...

Claude Code 使用秘籍大公开!从零基础到精通,字节跳动官方手册等你拿!
本文提供了一份详尽的 Claude Code 使用手册,专为从零基础到精通的学习者设计。手册采用手把手教学方式,步骤清晰,技巧实用,无需复杂代码知识即可上手。文中特别强调了对使用 Gemini3 的伙伴的适用性,并鼓励读者点赞、…...

javaweb广告服务型互联网平台
目录同行可拿货,招校园代理 ,本人源头供货商功能模块划分广告主功能代理商功能平台管理功能技术架构要点扩展功能项目技术支持源码获取详细视频演示 :文章底部获取博主联系方式!同行可合作同行可拿货,招校园代理 ,本人源头供货商 功能模块划分 广告服务…...

QKeyMapper终极指南:如何在不重启Windows的情况下彻底改变你的按键习惯
QKeyMapper终极指南:如何在不重启Windows的情况下彻底改变你的按键习惯 【免费下载链接】QKeyMapper [按键映射工具] QKeyMapper,Qt开发Win10&Win11可用,不修改注册表、不需重新启动系统,可立即生效和停止。支持游戏手柄映射到…...

告别GitHub访问难题:Fast-GitHub让开发效率提升300%
告别GitHub访问难题:Fast-GitHub让开发效率提升300% 【免费下载链接】Fast-GitHub 国内Github下载很慢,用上了这个插件后,下载速度嗖嗖嗖的~! 项目地址: https://gitcode.com/gh_mirrors/fa/Fast-GitHub 你是否也曾经历过这…...