大小堆的实现(C语言)
目录
前言
一种完全二叉树:堆
堆的概念
堆的性质
建堆的时间复杂度
建堆的空间复杂度:
小堆的实现
必要补充
堆的初始化
堆的销毁
向上调整算法
堆的插入
向下调整算法
堆的删除
获取堆顶元素
获取堆中元素个数
堆的判空
最终代码
Heap.h文件
Heap.c文件
test.c文件
大堆的实现
思考:堆的意义是什么?
1、堆排序
2、top k问题
前言
在上一篇中,我们学习了二叉树的基本概念:C语言二叉树的基本概念(一)现在我们来学习一种完全二叉树堆,以及大小堆的实现......
一种完全二叉树:堆
堆的概念
概念:如果有一个关键码的集合K = { k0,k1,k2,…},把它的所有元素按完全二叉树的顺序存储方式存储在一个一维数组中,若分别满足以下两种情况,则称该堆为小/大堆:

根节点为最大值的堆叫做最大堆或大根堆,根节点为最小值的堆叫做最小堆或小根堆

堆的性质
- 堆是一个完全二叉树;
- 堆中每一个节点的值都必须大于等于(或小于等于)其子树中每个节点的值
建堆的时间复杂度
1、我们将一个高度为h的满二叉树转变成一个小堆,该小堆的结点总数为log(N+1)
一般来说对数的底我们将其忽略,所以这里原本是log(以2为底N+1的对数)
第一层的结点个数为2^0、第二层的结点个数为2^1......第h层的结点个数为2^(h-1)
结点总数为:2^0 + 2^1 +......+2^(h-1) = 2^h - 1
(等比数列求和公式:Sn=a1 (1-q^n)/ (1-q))
假设结点总数为N,则N与h的关系是N = 2^h - 1 == h = log(N+1)即一个高h的满二叉树的结点个数为log(N+1)
2、进行堆的调整,得到最终的时间复杂度为O(N*logN)
第一层元素向上调整0次,第二层元素向上调整1次......第h层元素向上调整h-1次
同时每一层元素中的结点个数又分别为2^0、2^1......2^(h-1)
总调整次数T为:T = 2^0×0 + 2^1×1 +......2^(h-1)×(h-1) ①
利用错位相减法列出第二个式子:2*T = 2^1×0 + 2^2×1 +......2^h×(h-1) ②
由① - ②得: T = 2 + 2^h * (h-2) ③
将h = log(以2为底N+1的对数)代入③得④:
T = (N+1)log(以2为底N+1的对数)- 2 * N ④
将④利用大O渐进表示法转换为 T(N) = O(N*log以2为底N的对数)
结论:建堆的时间复杂度为O(N*logN)
建堆的空间复杂度:
小堆的空间复杂度为O(n),其中n是小堆中元素的个数。在建堆的过程中,需要额外的空间来存储数组中的元素。
结论:建堆的空间复杂度为O(N)
小堆的实现
我们利用顺序表(顺序存储方式)实现堆
必要补充
堆的任何一个父结点的编号parent与其左孩子结点的编号leftchild满足如下关系式:

理解这里是我们后续在编写向上调整算法与向下调整算法时的基础
堆的初始化
//初始化堆
void HeapInit(HP* php)
{//检查堆的有效性assetr(php);php->a = NULL;php->capacity = 0;php->size = 0;}堆的销毁
free可以用来检查是否为空,若指针为空,则free不执行任何操作,指针不为空就释放内存空间
//堆的销毁
void HeapDestroy(HP* php)
{assert(php);//释放a指针的内存空间并将a指针置为空free(php->a);php->a = NULL;php->capacity = 0;php->size = 0;
}向上调整算法
//向上调整
void AdjustUP(HPDataType* a,int child)
{int parent = (child - 1) / 2;//当孩子等于0的时候它已经位于树顶了没有父亲了就应该结束循环while(child > 0){//if (a[child] > a[parent]),就是它if (a[child] < a[parent]){//如果儿子小于父亲就交换父子位置,同时将此时Swap(&a[child], &a[parent]);child = parent;parent = (parent - 1) / 2;}//由于是写一个小堆,所以当孩子大于等于父亲时不需要交换,直接退出循环即可else{break;}}
}
堆的插入
//堆的插入
void HeapPush(HP* php, HPDataType x)
{assert(php);//扩容if (php->size == php->capacity){size_t newCapacity = php->capacity == 0 ? 4 : php->capacity * 2;HPDataType* tmp = (HPDataType*)realloc(php->a, newCapacity * sizeof(HPDataType));if (tmp == NULL){perror("realloc error");return -1;}php->a = tmp;php->capacity = newCapacity;}php->a[php->size] = x;php->size++;//向上调整,从顺序表最后一个元素开始调整,该元素的下标为size-1AdjustUP(php->a, php->size - 1);}每插入一个新的元素都需要进行一次向上调整的判断
向下调整算法
//向下调整算法
void AdjustDown(HPDataType* a, int size, int parent)
{//根据之前的推论,左孩子的下标值为父亲下标值的两倍+1,左孩子的下标值为父亲下标值的两倍+2int child = parent * 2 + 1;//循环结束的条件是走到叶子结点while (child < size){//if (child + 1< size && a[child + 1] > a[child]),它也是//假设左孩子小,若假设失败则更新child,转换为右孩子小,同时保证child的下标不会越界if (child + 1< size && a[child + 1] < a[child]){++child;}if (a[child] < a[parent]){//如果此时满足孩子小于父亲则交换父子位置,同时令父亲的下标变为此时的儿子所在下标,儿子所在下标变为自己的儿子所在的下标(向下递归)Swap(&a[child], &a[parent]);parent = child;child = parent * 2 + 1;}//如果父亲小于等于左孩子就证明删除后形成的新堆是一个小堆,不再需要向下调整算法,循环结束else{break;}}
}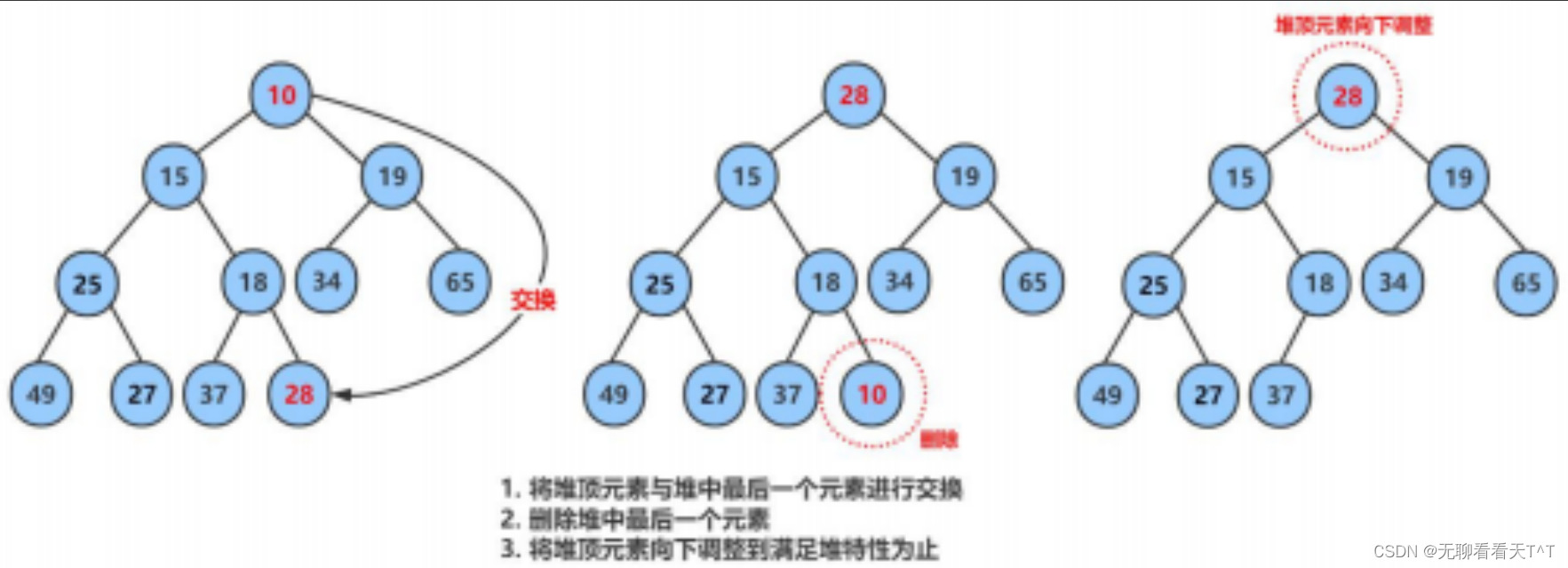
堆的删除
//堆的删除
void HeapPop(HP* php)
{assert(php);assert(php->size > 0);//这里并不采用惯用的顺序表头删的办法(向前覆盖),因为那样会引起堆的顺序被完全打乱的问题,我们在这里选择交换堆顶元素与堆尾元素然后再进行一次顺序表的尾删(直接size--即可)Swap(&php->a[0], &php->a[php->size - 1]);php->size--;//在交换完并尾删完后,可能此时的堆并不能满足小堆的要求(堆顶元素比它的两个孩子都大),所以我们必须再次对堆进行调整,经过向下调整算法将堆恢复至小堆(由于是堆顶元素开始调整所以还需传入堆顶元素对应的下标0)AdjustDown(php->a, php->size, 0);
}每删除一个元素都需要进行一次向下调整的判断
获取堆顶元素
//获取堆顶元素
HPDataType HeapTop(HP* php)
{assert(php);//获取堆顶元素则堆里应该有元素,故首先要保证size不小于等于零assert(php->size > 0);//确定堆中有元素后返回a[0]即可return php->a[0];
}
获取堆中元素个数
//获取堆中元素个数
size_t HeapSize(HP* php)
{assert(php);//判断size大于零后返回size大小即可return php->size;
}
堆的判空
//堆的判空
bool HeapEmpty(HP* php)
{assert(php);//返回对php->size == 0的判断结果return php->size == 0;
}最终代码
Heap.h文件
#include <stdio.h>
#include <assert.h>
#include <stdlib.h>
#include <stdbool.h>#pragma once
typedef int HPDataType;
typedef struct Heap
{HPDataType* a; //指向存储元素的指针int capacity; //当前顺序表容量int size; //当前顺序表的长度
}HP;//初始化堆
void HeapInit(HP* php);//销毁堆
void HeapDestroy(HP* php);//向上调整算法
void AdjustUP(HPDataType* a, int child);//堆的插入
void HeapPush(HP* php,HPDataType x);//向下调整算法
void AdjustDown(HPDataType* a, int child);//堆的删除(删除堆顶的数据)
void HeapPop(HP* php);//获取堆顶元素
HPDataType HeapTop(HP* php);//获取堆中元素个数
size_t HeapSize(HP* php);//堆的判空
bool HeapEmpty(HP* php);Heap.c文件
#include "Heap.h"//初始化堆
void HeapInit(HP* php)
{//检查堆的有效性assert(php);php->a = NULL;php->size = 0;php->capacity = 0;
}//堆的销毁
void HeapDestroy(HP* php)
{assert(php);//释放a指针的内存空间并将a指针置为空free(php->a);php->a = NULL;php->capacity = 0;php->size = 0;
}//交换父子位置
void Swap(HPDataType* p1,HPDataType* p2)
{HPDataType* tmp = *p1;*p1 = *p2;*p2 = tmp;
} //向上调整,此时传递过来的是最后一个孩子的元素下标我们用child表示
void AdjustUP(HPDataType* a,int child)
{//由于我们要调整父亲与孩子的位置所以此时也需要父亲元素的下标,而0父亲元素的下标值 = (任意一个孩子的下标值-1)/ 2 int parent = (child - 1) / 2;//当孩子等于0的时位于树顶(数组首元素的位置),树顶元素没有父亲,循环结束while(child > 0){//如果孩子还未到顶且它的下标对应的元素值小于它的父亲的下标对应的元素值,就将父子位置交换,交换玩后还要将下标对应的值“向上移动”//if (a[child] > a[parent]),就是它if (a[child] < a[parent]){Swap(&a[child], &a[parent]);child = parent;parent = (child - 1) / 2;}//由于这是一个小堆,所以当孩子大于等于父亲时不需要交换,直接退出循环即可else{break;}}
}//堆的插入
void HeapPush(HP* php, HPDataType x)
{assert(php);//扩容if (php->size == php->capacity){int newCapacity = php->capacity == 0 ? 4 : php->capacity * 2;HPDataType* tmp = (HPDataType*)realloc(php->a, newCapacity * sizeof(HPDataType));if (tmp == NULL){perror("realloc error");return -1;}php->a = tmp;php->capacity = newCapacity;}php->a[php->size] = x;php->size++;//向上调整,从顺序表最后一个元素开始调整,该元素的下标为size-1AdjustUP(php->a, php->size-1);
}//向下调整算法
void AdjustDown(HPDataType* a, int size, int parent)
{//根据之前的推论,左孩子的下标值为父亲下标值的两倍+1,左孩子的下标值为父亲下标值的两倍+2int child = parent * 2 + 1;//循环结束的条件是走到叶子结点while (child < size){//假设左孩子小,若假设失败则更新child,转换为右孩子小,同时保证child的下标不会越界//if (child + 1 < size && a[child + 1] < a[child]),它也是if (child + 1 < size && a[child + 1] < a[child]){++child;}if (a[child] < a[parent]){//如果此时满足孩子小于父亲则交换父子位置,同时令父亲的下标变为此时的儿子所在下标,儿子所在下标变为自己的儿子所在的下标(向下递归)Swap(&a[child], &a[parent]);parent = child;child = parent * 2 + 1;}//如果父亲小于等于左孩子就证明删除后形成的新堆是一个小堆,不再需要向下调整算法,循环结束else{break;}}
}//堆的删除
void HeapPop(HP* php)
{assert(php);assert(php->size > 0);//这里并不采用惯用的顺序表头删的办法(向前覆盖),因为那样会引起堆的顺序被完全打乱的问题,我们在这里选择交换堆顶元素与堆尾元素然后再进行一次顺序表的尾删(直接size--即可)Swap(&php->a[0], &php->a[php->size - 1]);php->size--;//在交换完并尾删完后,可能此时的堆并不能满足小堆的要求(堆顶元素比它的两个孩子都大),所以我们必须再次对堆进行调整,经过向下调整算法将堆恢复至小堆(由于是堆顶元素开始调整所以还需传入堆顶元素对应的下标0)AdjustDown(php->a, php->size, 0);
}//获取堆顶元素
HPDataType HeapTop(HP* php)
{assert(php);//获取堆顶元素则堆里应该有元素,故首先要保证size不小于等于零assert(php->size > 0);//确定堆中有元素后返回a[0]即可return php->a[0];
}//获取堆中元素个数
size_t HeapSize(HP* php)
{assert(php);//判断size大于零后返回size大小即可return php->size;
}//堆的判空
bool HeapEmpty(HP* php)
{assert(php);//返回对php->size == 0的判断结果return php->size == 0;
}test.c文件
#include "Heap.h"int main()
{int arr[] = { 4,6,2,1,5,8,2,9 };int sz = sizeof(arr) / sizeof(arr[0]);HP hp;HeapInit(&hp);for (int i = 0;i < sz; ++i){HeapPush(&hp,arr[i]);}//堆不为空就获取堆顶元素并删除while (!HeapEmpty(&hp)){printf("%d ",HeapTop(&hp));HeapPop(&hp);}printf("\n");return 0;
}大堆的实现
大堆的实现只需要将向上调整算法和向下调整算法中,只需要将注释掉的语句重新启用即可
思考:堆的意义是什么?
1、堆排序
堆排序即利用堆的思想来进行排序,总共分为两个步骤:建堆与利用堆删除思想进行排序
- 建堆:升序:建大堆、降序:建小堆(很重要,下一篇我们会对升序建大堆的办法进行详细介绍)
- 利用堆删除思想来进行排序:建堆和堆删除中都用到了向下调整,因此掌握了向下调整,就可以完成堆排序(重要)
当一棵树为满二叉树时,高度h与结点总数N的关系是:h = log (N + 1)
当一棵树为完全二叉树时,高度h与结点总数N最坏的关系是:h = log N + 1
所以如果有一百万个数据组成一棵二叉树,那么这棵树的高度仅为20,十亿个数据,高度仅仅为30,即如果我们要用堆排序去查找100w个数据中的其中一个大概只需要查找二十次......
补充:在使用堆排序时,并不能说它能更高效地维护数据的有序性。相反,建立和调整一个完整的二叉树结构以及频繁进行元素交换和下沉操作可能会带来一些额外开销,并且在某些情况下可能比其他简单算法慢。但是,由于其稳定而可预测性能表现,在某些特殊情况下仍然被认为是有效和实用的算法之一。
2、top k问题
问题描述:获取N个数里找最大的前K个数(N远大于K)
解决思路一:
N个数插入进大堆中,Pop K次
时间复杂度:N*logN + K*logN == O(N*logN)
但如果N为100亿(100亿个整数需要40GB左右的内存空间),而只要查找前10个数(K为10)?
解决思路二:
1、取前K个值,建立K个数的小堆
2、再读取后面的值,跟堆顶元素比较,若大于堆顶元素,交换二者位置然后重新堆化成小堆
时间复杂度:O(N*logK)
注意事项:必须要建立小堆,不能建立大堆,如果建立大堆,一旦第一大的数字在建堆时位于堆顶,后续第n大的数字就无法进堆,同时第二大的数字可能还会被挤出去,如果不信可以用[4,6,1,2,8,9,5,3]这个我随机想出来数组用以上方法取前三个最大的数字试一试
有时候你可能会很想刨根问底的知道这些办法都是怎么想出来的,其实我也不知道,这就跟你骑自行车的时候去思考这些链子为什么要这样组合在一起,为什么组合在一起就可以产生这样的效果,其实我们根本不需要思考那么多,我们只需要骑上自行车去干我们要干的事情即可,它只是一个用于解决我们问题的工具,我们说的解题思路也是一样的,这些东西都是哪些很nb的人发明出来的,如果你是一个很nb的人你也不会看到这里不是,前人栽树后人乘凉,作为一个还没有完全深入学习数据结构的菜鸟既然已经知道了有这种解决办法那么你就直接用,等你什么时候感觉自己已经很nb了再来思考为什么吧......(当然也不是说都不要思考一些必要的思考还是需要的)别钻牛角尖了🤡
模拟实现:
使用数组[7, 8, 15, 4, 20, 23, 2, 50]演示如何使用最小堆找出前3个最大的元素。
首先,我们创建一个最小堆,并将数组的前3个元素[7, 8, 15]插入堆中,初始堆的表示如下:
7/ \8 15接下来遍历数组,发现 4 < 7,因此我们不做任何操作
继续遍历数组,发现 20 > 7,因此将 7 替换为 20 并重新堆化成小堆
8/ \20 15继续遍历数组,发现 23 大于 8,因此我们将 8 替换为 23 并重新堆化成小堆
15/ \20 23继续遍历数组,发现 2 < 15,因此我们不做任何操作
继续遍历数组,发现 50 > 15,因此我们将 15 替换为 50 并重新堆化成小堆
20/ \50 23最后,数组遍历完成,得到了最终的最小堆
20/ \50 23此时,堆中的前3个最大元素为 `[20, 50, 23]`,它们就是原数组中的前3个最大元素
~over~
相关文章:
大小堆的实现(C语言)
目录 前言 一种完全二叉树:堆 堆的概念 堆的性质 建堆的时间复杂度 建堆的空间复杂度: 小堆的实现 必要补充 堆的初始化 堆的销毁 向上调整算法 堆的插入 向下调整算法 堆的删除 获取堆顶元素 获取堆中元素个数 堆的判空 最终代码 He…...
Linux系统之centos7编译安装Python 3.8
前言 CentOS (Community Enterprise Operating System) 是一种基于 Red Hat Enterprise Linux (RHEL) 进行源代码再编译并免费提供给用户的 Linux 操作系统。 CentOS 7 采用了最新的技术和软件包,并提供了强大的功能和稳定性。它适用于各种服务器和工作站应用场景&a…...

Lambda表达式与方法引用
作者简介:大家好,我是smart哥,前中兴通讯、美团架构师,现某互联网公司CTO 联系qq:184480602,加我进群,大家一起学习,一起进步,一起对抗互联网寒冬 引子 先来看一个案例 …...
)
二维数组处理(一)
输入整型二维数组a(5行5列),完成如下要求: 输出二维数组a。 将a的第2行和第4行元素对调后,形成新的二维数组a并按行输出,每个元素之间隔一个空格。(行号从0开始计算)。 用对角线(指二维数组左…...
基于JNI实现调用C++ SDK
基于JNI实现调用C SDK 背景分析解决实践 背景 上篇文章总结了几种Java项目调用C/C SDK项目方法,在逐一实践、踩坑后,最终还是敲定采用 JNI 方式进行实现。在文章开始的过程,会先大概讲讲笔者遇到的情况,因为封装方式需要根据实际…...

计算机组成原理笔记——存储器(静态RAM和动态RAM的区别,动态RAM的刷新, ROM……)
■ 随机存取存储器 ■ 1.随机存取存储器:按存储信息的原理不同分为:静态RAM和动态RAM 2.静态RAM(SRAM):用触发器工作原理存储信息,但电源掉电时,存储信息会丢失具有易失性。 3.存储器的基本单元…...

企业计算机服务器locked1勒索病毒数据恢复,locked1勒索病毒解密流程
随着计算机技术的不断发展,越来越多的企业走向数字化办公时代,计算机技术为企业的生产运营提供了有利条件,但也为企业带来了网络安全威胁。在本月,云天数据恢复中心陆续接到很多企业的求助,企业的速达办公软件遭到了lo…...
Session 与 JWT 的对决:谁是身份验证的王者? (下)
🤍 前端开发工程师(主业)、技术博主(副业)、已过CET6 🍨 阿珊和她的猫_CSDN个人主页 🕠 牛客高级专题作者、在牛客打造高质量专栏《前端面试必备》 🍚 蓝桥云课签约作者、已在蓝桥云…...
论文笔记:Confidential Assets
Confidential Assets 描述了一种称为“保密交易”的方案,该方案模糊了所有UTXO的金额,同时保持了不创建或销毁硬币的公共可验证性。进一步将此方案扩展到“保密资产”,一种单一的基于区块链的分类帐可以跟踪多种资产类型的方案。将保密交易扩…...
Docker下搭建MySQL主从复制
目录 主从复制简介 主从复制搭建 主从复制简介 主从复制,是用来建立一个和主数据库完全一样的数据库环境,称为从数据库;主数 据库一般是准实时的业务数据库。 主从复制的作用 做数据的热备。作为后备数据库,主数据库服务器故…...

VBA数据库解决方案第七讲:如何利用Recordset对象打开数据库的数据记录集
《VBA数据库解决方案》教程(版权10090845)是我推出的第二套教程,目前已经是第二版修订了。这套教程定位于中级,是学完字典后的另一个专题讲解。数据库是数据处理的利器,教程中详细介绍了利用ADO连接ACCDB和EXCEL的方法…...
内部培训平台的系统 PlayEdu搭建私有化内部培训平台
PlayEdu是由白书科技团队多年经营的线上教育系统,专为企业提供的全新企业培训方案 我们的目标是为更多的企业机构搭建私有化内部培训平台,以满足不断增长的培训需求 通过PlayEdu,企业可以有效地组织和管理培训资源,提供高质量的…...

Elasticsearch 相似度评分模型介绍
前言 Elasticsearch 是基于 Lucene 的世界范围内最流行的全文检索框架,其文档相似度算法包含 TF/IDF 和 BM25,从 ES 5.0开始 BM25 算法已经成为 ES 默认的相似度评分模块。 TF-IDF 与 BM25 的区别 TF-IDF 和 BM25 都是计算文本相似性的常用算法。TF-ID…...

视频生成的发展史及其原理解析:从Gen2、Emu Video到PixelDance、SVD、Pika 1.0
前言 考虑到文生视频开始爆发,比如11月份就是文生视频最火爆的一个月 11月3日,Runway的Gen-2发布里程碑式更新,支持4K超逼真的清晰度作品(runway是Stable Diffusion最早版本的开发商,Stability AI则开发的SD后续版本)11月16日&a…...
SQL Server 2016(基本概念和命令)
1、文件类型。 【1】主数据文件:数据库的启动信息。扩展名为".mdf"。 【2】次要(辅助)数据文件:主数据之外的数据都是次要数据文件。扩展名为".ndf"。 【3】事务日志文件:包含恢复数据库的所有事务…...

Linux C语言 30-套接字操作
Linux C语言 30-套接字操作 本节关键字:C语言 网络通信、套接字操作、TCP、UDP、服务端、客户端 相关C库函数:socket, bind, listen, accept, setsockopt, recv, send, recvfrom, sendto, close 什么是网络通信? 通信是人与人之间通过某种…...

RPC和REST对比
RPC和REST对比 参考学习 RPC 和 REST 之间有什么区别? 当我们对比RPC和REST时,其实是在对比RPC风格的API和REST风格的API,后者通常成为RESTful API。 远程过程调用(RPC)和 REST 是 API 设计中的两种架构风格。API …...

外包干了2年,技术退步明显。。。
前言 简单的说下,我大学的一个同学,毕业后我自己去了自研的公司,他去了外包,快两年了我薪资、技术各个方面都有了很大的提升,他在外包干的这两年人都要废了,技术没一点提升,学不到任何东西&…...
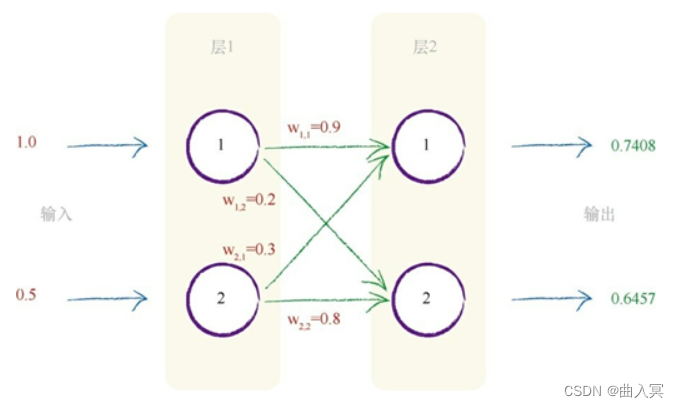
深度学习——第1章 深度学习的概念及神经网络的工作原理
1.1 序言——探索智能机器 千百年来,人类试图了解智能的机制,并将它复制到思维机器上。 人类从不满足于让机械或电子设备帮助做一些简单的任务,例如使用滑轮吊起沉重的岩石,使用计算器做算术。 人类希望计算机能够自动化执行更…...
爬虫爬取百度图片、搜狗图片
通过以下代码可以爬取两大图片网站(百度和搜狗)的图片,对于人工智能、深度学习中图片数据的搜集很有帮助! 一、爬取百度图片 该代码可以爬取任意百度图片中自定义的图片: import requests import re import time imp…...

体验Taotoken官方价折扣与Token Plan带来的成本优势
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 体验Taotoken官方价折扣与Token Plan带来的成本优势 1. 引言:从按需付费到计划性支出 对于频繁调用大模型API的开发者…...

告别Electron的臃肿:用NeutralinoJS + Vue 3,5分钟打造一个不到3MB的桌面应用
轻量化桌面应用开发实战:用NeutralinoJS与Vue 3构建3MB级工具 当现代前端开发者尝试进入桌面应用领域时,往往会遇到一个令人头疼的问题:为什么一个简单的记事本工具打包后竟超过100MB?这种困扰正是Electron等传统框架带来的"…...

异步复位同步释放:数字电路设计的核心技巧与工程实践
1. 项目概述:一个看似简单却暗藏玄机的设计技巧在数字电路设计,尤其是FPGA和ASIC开发中,复位信号的处理是确保系统从确定状态启动和稳定运行的第一道,也是最重要的一道防线。我们经常听到“异步复位,同步释放”这个设计…...

DB-GPT-Hub:基于大模型微调构建专属文本到SQL数据集的实践指南
1. 项目概述:当大模型遇见数据库,一场效率革命正在发生如果你是一名数据工程师、数据分析师,或者任何需要频繁与数据库打交道的开发者,那么你一定对这样的场景不陌生:面对一个陌生的数据库,你需要花大量时间…...

揭秘开源智能字幕系统:如何用AI实现高效的多语言内容本地化
揭秘开源智能字幕系统:如何用AI实现高效的多语言内容本地化 【免费下载链接】openlrc Transcribe and translate voice into LRC file using Whisper and LLMs (GPT, Claude, et,al). 使用whisper和LLM(GPT,Claude等)来转录、翻译你的音频为字幕文件。 …...

如何解决Reloaded-II模组加载器安装过程中的依赖循环问题
如何解决Reloaded-II模组加载器安装过程中的依赖循环问题 【免费下载链接】Reloaded-II Universal .NET Core Powered Modding Framework for any Native Game X86, X64. 项目地址: https://gitcode.com/gh_mirrors/re/Reloaded-II Reloaded-II作为一款强大的.NET Core模…...

用 IDENTITY 数据销毁对象处理个人数据销毁,SAP ILM 场景下的信息检索与合规闭环
做 SAP 系统里的个人数据治理,最怕的不是删除动作本身,而是删除之前没有把数据的来源、用途、保留规则、可检索性和审计链路讲清楚。一个系统里只要出现客户、联系人、消费者、会员、订阅人、业务伙伴、技术访问账号等身份相关对象,围绕这些对象产生的姓名、邮箱、手机号、登…...

3个步骤彻底告别电脑风扇噪音:Windows平台最精细的风扇控制解决方案
3个步骤彻底告别电脑风扇噪音:Windows平台最精细的风扇控制解决方案 【免费下载链接】FanControl.Releases This is the release repository for Fan Control, a highly customizable fan controlling software for Windows. 项目地址: https://gitcode.com/GitHu…...

避坑指南:CCPD车牌数据集预处理中,OpenCV透视变换的3个常见错误与修复方法
CCPD车牌数据集预处理实战:透视变换的3个隐蔽陷阱与工业级解决方案 当你在深夜的显示器前反复调试CCPD数据集的预处理代码,却发现透视变换后的车牌图像像被无形之手扭曲——边框错位、字符拉伸、坐标偏移。这不是算法问题,而是OpenCV实战中那…...

VN5640硬件驱动从11.1升级后必看:Network-base访问模式的完整配置流程与避坑指南
VN5640硬件驱动升级至11.1后的Network-base访问模式全流程配置与实战避坑指南 当车载以太网测试工程师将VN5xxx系列硬件驱动升级到11.1版本后,一个关键但容易被忽视的变化是Network-base访问模式的引入。这种新模式彻底改变了传统channel-base的配置逻辑࿰…...