多级缓存自用
1.什么是多级缓存
传统的缓存策略一般是请求到达Tomcat后,先查询Redis,如果未命中则查询数据库,如图:
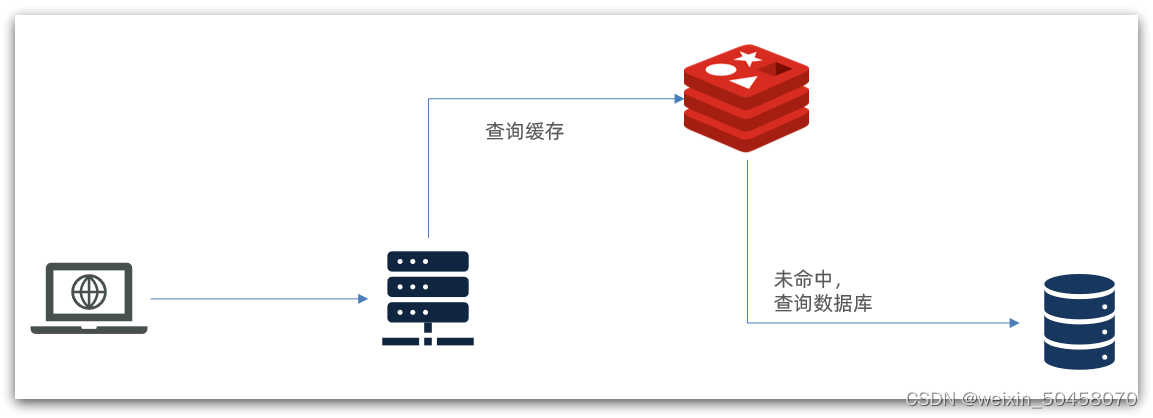
存在下面的问题:
•请求要经过Tomcat处理,Tomcat的性能成为整个系统的瓶颈
•Redis缓存失效时,会对数据库产生冲击
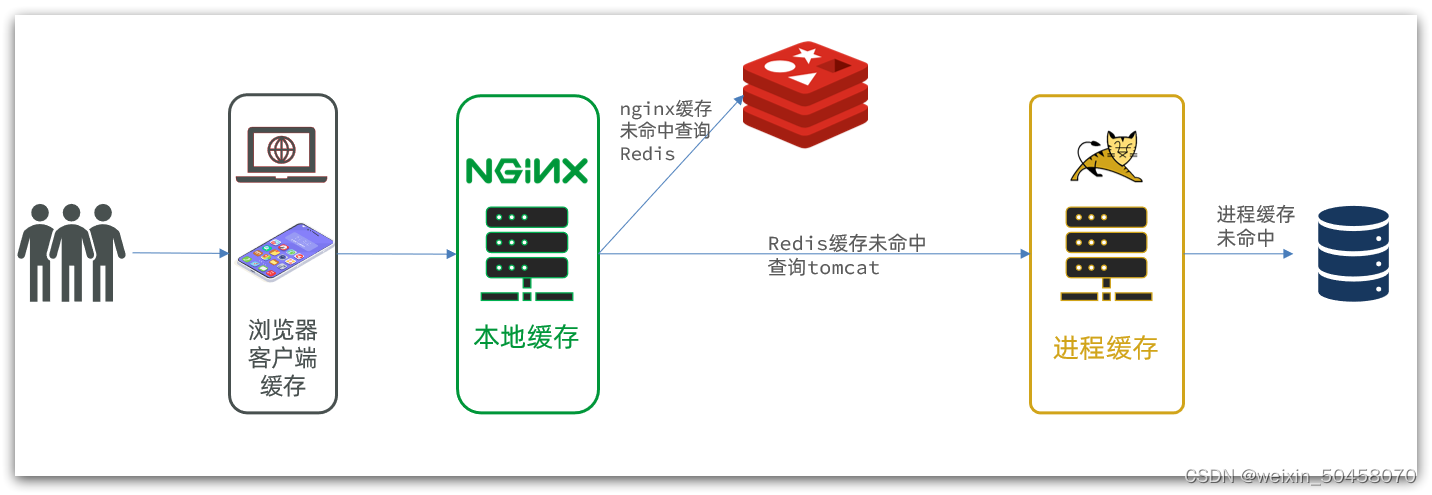
多级缓存就是充分利用请求处理的每个环节,添加缓存,减轻Tomcat压力,提升服务性能:
浏览器访问静态资源时,优先读取浏览器本地缓存
访问非静态资源(ajax查询数据)时,访问服务端
请求到达Nginx后,优先读取Nginx本地缓存
如果Nginx本地缓存未命中,则去直接查询Redis(不经过Tomcat)
如果Redis查询未命中,则查询Tomcat
请求进入Tomcat后,优先查询JVM进程缓存
如果JVM进程缓存未命中,则查询数据库
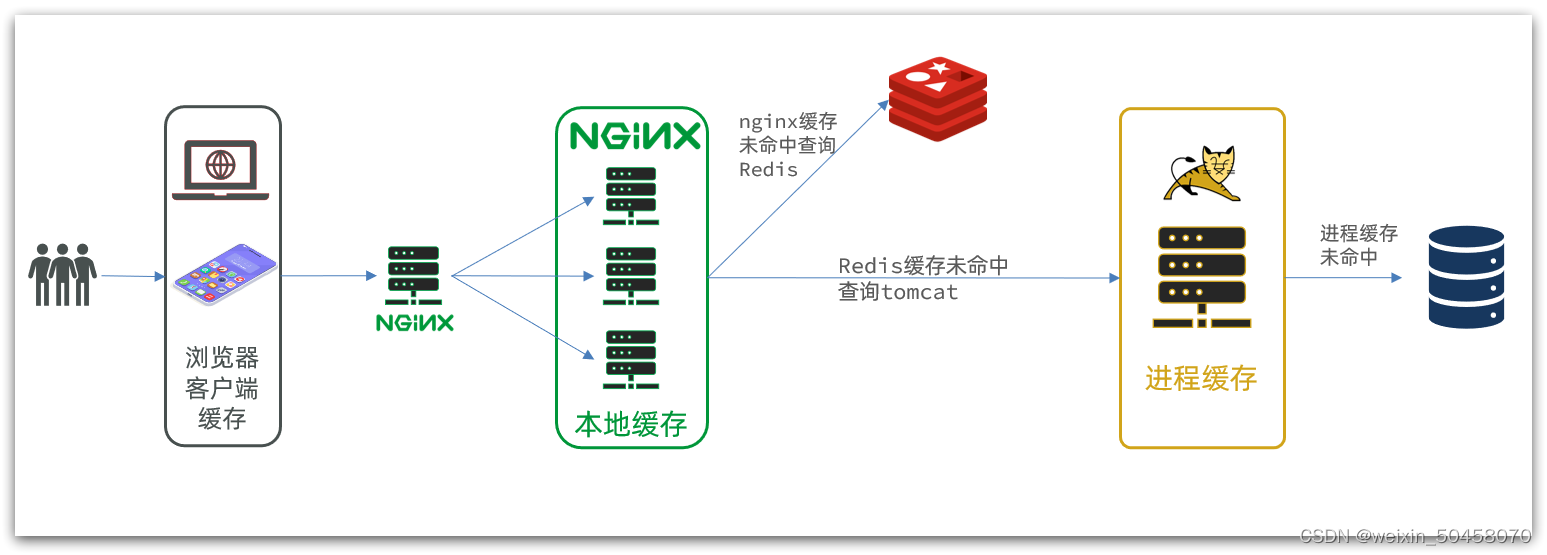
在多级缓存架构中,Nginx内部需要编写本地缓存查询、Redis查询、Tomcat查询的业务逻辑,因此这样的nginx服务不再是一个反向代理服务器,而是一个编写业务的Web服务器了。
因此这样的业务Nginx服务也需要搭建集群来提高并发,再有专门的nginx服务来做反向代理,如图:
另外,我们的Tomcat服务将来也会部署为集群模式:
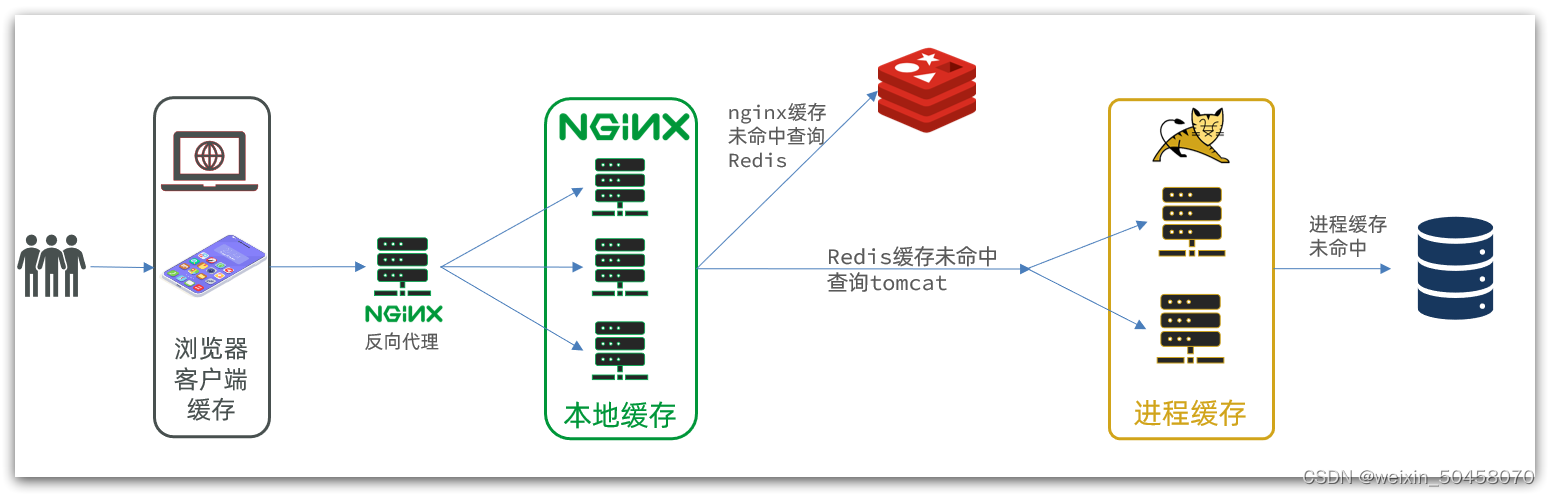
可见,多级缓存的关键有两个:
一个是在nginx中编写业务,实现nginx本地缓存、Redis、Tomcat的查询
另一个就是在Tomcat中实现JVM进程缓存
其中Nginx编程则会用到OpenResty框架结合Lua这样的语言。
2.JVM进程缓存
为了演示多级缓存的案例,我们先准备一个商品查询的业务。
2.1.初识Caffeine
缓存在日常开发中启动至关重要的作用,由于是存储在内存中,数据的读取速度是非常快的,能大量减少对数据库的访问,减少数据库的压力。我们把缓存分为两类:
分布式缓存,例如Redis:
优点:存储容量更大、可靠性更好、可以在集群间共享
缺点:访问缓存有网络开销
场景:缓存数据量较大、可靠性要求较高、需要在集群间共享
进程本地缓存,例如HashMap、GuavaCache:
优点:读取本地内存,没有网络开销,速度更快
缺点:存储容量有限、可靠性较低、无法共享
场景:性能要求较高,缓存数据量较小
我们今天会利用Caffeine框架来实现JVM进程缓存。
Caffeine是一个基于Java8开发的,提供了近乎最佳命中率的高性能的本地缓存库。目前Spring内部的缓存使用的就是Caffeine。
Caffeine的性能非常好,下图是官方给出的性能对比:
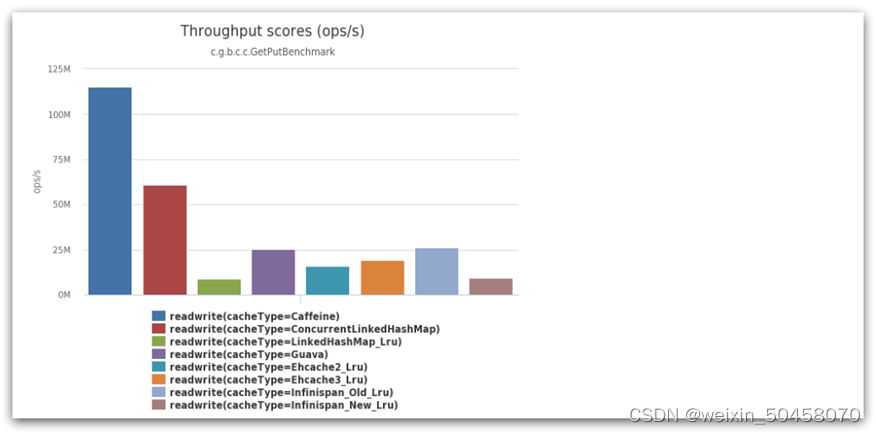
可以看到Caffeine的性能遥遥领先!
缓存使用的基本API:
@Testvoid testBasicOps() {// 构建cache对象Cache<String, String> cache = Caffeine.newBuilder().build();// 存数据cache.put("gf", "迪丽热巴");// 取数据String gf = cache.getIfPresent("gf");System.out.println("gf = " + gf);// 取数据,包含两个参数:// 参数一:缓存的key// 参数二:Lambda表达式,表达式参数就是缓存的key,方法体是查询数据库的逻辑// 优先根据key查询JVM缓存,如果未命中,则执行参数二的Lambda表达式String defaultGF = cache.get("defaultGF", key -> {// 根据key去数据库查询数据return "柳岩";});System.out.println("defaultGF = " + defaultGF);}Caffeine既然是缓存的一种,肯定需要有缓存的清除策略,不然的话内存总会有耗尽的时候。
Caffeine提供了三种缓存驱逐策略:
-
基于容量:设置缓存的数量上限
// 创建缓存对象 Cache<String, String> cache = Caffeine.newBuilder() .maximumSize(1) // 设置缓存大小上限为 1 .build(); -
基于时间:设置缓存的有效时间
// 创建缓存对象 Cache<String, String> cache = Caffeine.newBuilder() // 设置缓存有效期为 10 秒,从最后一次写入开始计时 .expireAfterWrite(Duration.ofSeconds(10)) .build(); -
基于引用:设置缓存为软引用或弱引用,利用GC来回收缓存数据。性能较差,不建议使用。
注意:在默认情况下,当一个缓存元素过期的时候,Caffeine不会自动立即将其清理和驱逐。而是在一次读或写操作后,或者在空闲时间完成对失效数据的驱逐。
2.2.实现JVM进程缓存
2.2.1.需求
利用Caffeine实现下列需求:
-
给根据id查询商品的业务添加缓存,缓存未命中时查询数据库
-
给根据id查询商品库存的业务添加缓存,缓存未命中时查询数据库
-
缓存初始大小为100
-
缓存上限为10000
2.2.2.实现
首先,我们需要定义两个Caffeine的缓存对象,分别保存商品、库存的缓存数据。
@Configuration
public class CaffeineConfig {@Beanpublic Cache<Long, Item> itemCache(){return Caffeine.newBuilder().initialCapacity(100).maximumSize(10_000).build();}@Beanpublic Cache<Long, ItemStock> stockCache(){return Caffeine.newBuilder().initialCapacity(100).maximumSize(10_000).build();}
}@RestController
@RequestMapping("item")
public class ItemController {@Autowiredprivate IItemService itemService;@Autowiredprivate IItemStockService stockService;@Autowiredprivate Cache<Long, Item> itemCache;@Autowiredprivate Cache<Long, ItemStock> stockCache; // ...其它略@GetMapping("/{id}")public Item findById(@PathVariable("id") Long id) {return itemCache.get(id, key -> itemService.query().ne("status", 3).eq("id", key).one());}@GetMapping("/stock/{id}")public ItemStock findStockById(@PathVariable("id") Long id) {return stockCache.get(id, key -> stockService.getById(key));}
}3.Lua语法入门
Nginx编程需要用到Lua语言,因此我们必须先入门Lua的基本语法。
3.1.初识Lua
Lua 是一种轻量小巧的脚本语言,用标准C语言编写并以源代码形式开放, 其设计目的是为了嵌入应用程序中,从而为应用程序提供灵活的扩展和定制功能。官网:The Programming Language Lua

Lua经常嵌入到C语言开发的程序中,例如游戏开发、游戏插件等。
Nginx本身也是C语言开发,因此也允许基于Lua做拓展。
3.1.HelloWorld
CentOS7默认已经安装了Lua语言环境,所以可以直接运行Lua代码。
1)在Linux虚拟机的任意目录下,新建一个hello.lua文件

2)添加下面的内容
print("Hello World!")
3)运行
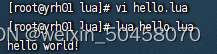
任意地方输出lua便可进入lua控制台

3.2.变量和循环
学习任何语言必然离不开变量,而变量的声明必须先知道数据的类型。
3.2.1.Lua的数据类型
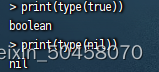
Lua中支持的常见数据类型包括:

另外,Lua提供了type()函数来判断一个变量的数据类型:
3.2.2.声明变量
Lua声明变量的时候无需指定数据类型,而是用local来声明变量为局部变量:
-- 声明字符串,可以用单引号或双引号,
local str = 'hello'
-- 字符串拼接可以使用 ..
local str2 = 'hello' .. 'world'
-- 声明数字
local num = 21
-- 声明布尔类型
local flag = true
Lua中的table类型既可以作为数组,又可以作为Java中的map来使用。数组就是特殊的table,key是数组角标而已:
-- 声明数组 ,key为角标的 table
local arr = {'java', 'python', 'lua'}
-- 声明table,类似java的map
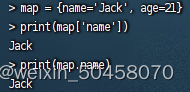
local map = {name='Jack', age=21}
Lua中的数组角标是从1开始,访问的时候与Java中类似:
-- 访问数组,lua数组的角标从1开始
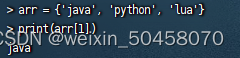
Lua中的table可以用key来访问:
-- 访问table
print(map['name'])
print(map.name)
3.2.3.循环
对于table,我们可以利用for循环来遍历。不过数组和普通table遍历略有差异。
遍历数组:
-- 声明数组 key为索引的 table 数组——ipairs
local arr = {'java', 'python', 'lua'}
-- 遍历数组
for index,value in ipairs(arr) do
print(index, value)
end
遍历普通table
-- 声明map,也就是table map-pairs
local map = {name=
相关文章:
多级缓存自用
1.什么是多级缓存 传统的缓存策略一般是请求到达Tomcat后,先查询Redis,如果未命中则查询数据库,如图: 存在下面的问题: •请求要经过Tomcat处理,Tomcat的性能成为整个系统的瓶颈 •Redis缓存失效时,会对数据库产生冲击 多级缓存就是充分利用请求处理的每个环节,添加缓…...
1.1卷积的作用
上图解释了1∗1卷积如何适用于尺寸为H∗W∗D的输入层,滤波器大小为1∗1∗D,输出通道的尺寸为H∗W∗1。如果应用n个这样的滤波器,然后组合在一起,得到的输出层大小为H∗W∗n。 1.1∗1卷积的作用 调节通道数 由于 11 卷积并不会改…...
Unity 简单打包脚本
打包脚本 这个打包脚本适用于做demo,脚本放在Editor目录下 using System; using System.Collections; using System.Collections.Generic; using System.IO; using UnityEditor; using UnityEngine;public class BuildAB {[MenuItem("Tools/递归遍历文件夹下…...
基于社区电商的Redis缓存架构-缓存数据库双写、高并发场景下优化
基于社区电商的Redis缓存架构 首先来讲一下 Feed 流的含义: Feed 流指的是当我们进入 APP 之后,APP 要做一个 Feed 行为,即主动的在 APP 内提供各种各样的内容给我们 在电商 APP 首页,不停在首页向下拉,那么每次拉的…...

Python提取PDF表格(基于AUTOSAR_SWS_CANDriver.pdf)
个人学习笔记,仅供参考。 需求:提取AUTOSAR SWS中所有的API接口信息,用于生成C代码。 此处以AUTOSAR_SWS_CANDriver.pdf为例,若需要提取多个SWS文件,遍历各个文件即可。 1.Python包 pdfplumber是一款完全用python开…...
)
UVa1583生成元(Digit Generator)
题目 如果x加上x的各个数字之和得到y,也就是说x是y的生成元。给出n(1<n<100000),求最小生成元。无解则输出0。 输入输出样例 输入 3 216 121 2005输出 198 0 1979思路 要想解决这个题目,只需要对每一个输入的值从1开始遍历找到小于…...
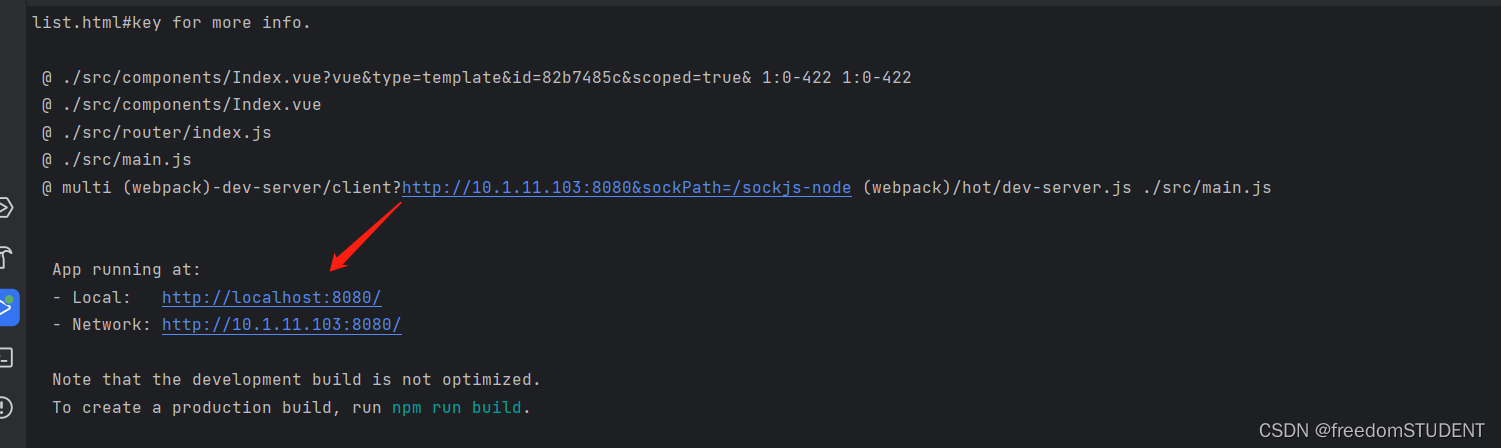
【Springboot+vue】如何运行springboot+vue项目
从github 或者 gitee 下载源码后,解压,再从idea打开项目 后端代码处理 这是我在gitee下载下来的源码 打开之后,先处理后端代码 该配置的配置,该部署的部署 比如将sql文件导入数据库 然后去配置文件更改配置 然后启动项目 确保…...

拥抱变化,良心AI工具推荐
文章目录 💥 简介🍄 工具介绍🍓 功能特点🥗 使用场景🎉 用户体验🧩 下载地址🍭 总结 💥 简介 我是一名资深程序员,但薪资缺对不起资深两个字,为了生存&#x…...
Tensorflow的日志log记录
if OUTPUT_GRAPH:tf.summary.FileWriter("logs/", sess.graph)自动创建文件夹log...
C-语言每日刷题
目录 [蓝桥杯 2015 省 A] 饮料换购 题目描述 输入格式 输出格式 输入输出样例 # [蓝桥杯 2023 省 A] 平方差 题目描述 输入格式 输出格式 输入输出样例 说明/提示 【样例说明】 [NOIP2001 普及组] 数的计算 题目描述 输入格式 输出格式 输入输出样例 说明/提示 样例 1 解释 数据…...

十五届海峡两岸电视主持新秀大会竞赛流程
海峡两岸电视主持新秀会是两岸电视媒体共同举办的一项活动,旨在为两岸年轻的电视主持人提供一个展示才华的舞台,促进两岸文化交流和青年交流。本届新秀会是第十二届海峡两岸电视艺术节的重要活动之一。本次竞赛赛制流程如下: (1&…...

安全行业招聘信息汇总
1. 阿里巴巴-淘天集团-安全部 社招岗位:Java开发 招聘层级:P5-P6 工作年限:本科毕业1-3年,硕士毕业1-2年 base地点:杭州 职位描述 负责淘天安全部风控基础标签平台0到1能力建设及产品规划和落地。负责标签应用的产品…...

【如何学习python自动化测试】—— 浏览器驱动的安装 以及 如何更新driver
之前讲到基于python的自动化测试环境,需要安装Python,再安装Selenium。具体可看【如何学习Python自动化测试】—— 自动化测试环境搭建 但是,想要使用Selenium发送指令模拟人类行为操作浏览器,就需要安装浏览器驱动。不同的浏览器需要安…...

Spring Data Redis切换底层Jedis 和 Lettuce实现
1 简介 Spring Data Redis是 Spring Data 系列的一部分,它提供了Spring应用程序对Redis的轻松配置和使用。它不仅提供了对Redis操作的高级抽象,还支持Jedis和Lettuce两种连接方式。 可通过简单的配置就能连接Redis,并且可以切换Jedis和Lett…...

wireshark自定义协议插件开发
目录 脚本代码 报文显示 脚本代码 local NAME "test" test_proto Proto("test", "test Protocol") task_id ProtoField.uint16("test.task_id", "test id", base.DEC) cn ProtoField.uint8("test.cn", &qu…...

一文读懂MongoDB的全部知识点(1),惊呆面试官。
文章目录 01、mongodb是什么?02、mongodb有哪些特点?03、你说的NoSQL数据库是什么意思?NoSQL与RDBMS直接有什么区别?为什么要使用和不使用NoSQL数据库?说一说NoSQL数据库的几个优点?04、NoSQL数据库有哪些类型?05、M…...
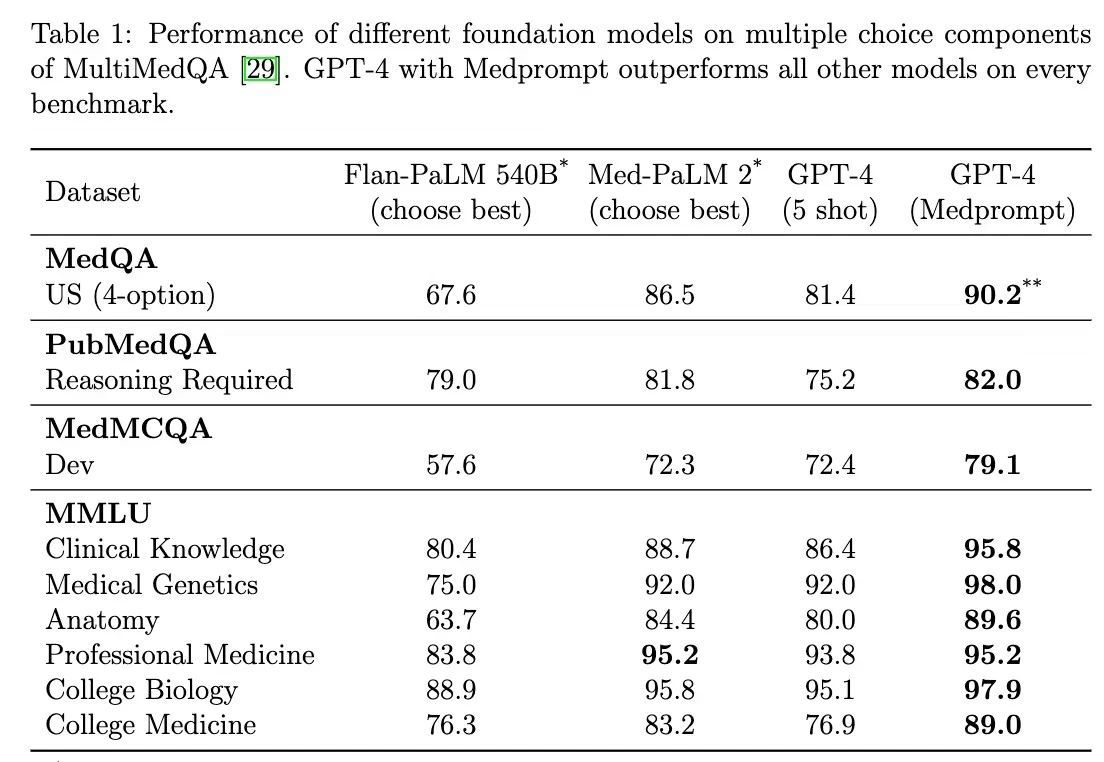
仅仅通过提示词,GPT-4可以被引导成为多个领域的特定专家
The Power of Prompting:提示的力量,仅通过提示,GPT-4可以被引导成为多个领域的特定专家。微软研究院发布了一项研究,展示了在仅使用提策略的情况下让GPT 4在医学基准测试中表现得像一个专家。研究显示,GPT-4在相同的基…...

23.Oracle11g的UNDO表空间
Oracle的UNDO表空间 一、UNDO表空间概述1、什么是UNDO表空间2、UNDO表空间的作用2.1 提供一致性读2.2 回滚事务2.3 实例恢复 3、UNDO表空间的工作机制 二、UNDO表空间的相关操作1、UNDO表空间的创建2、UNDO表空间的管理 三、Oracle 11g中UNDO表空间的新特性1、UNDO表空间自动管…...
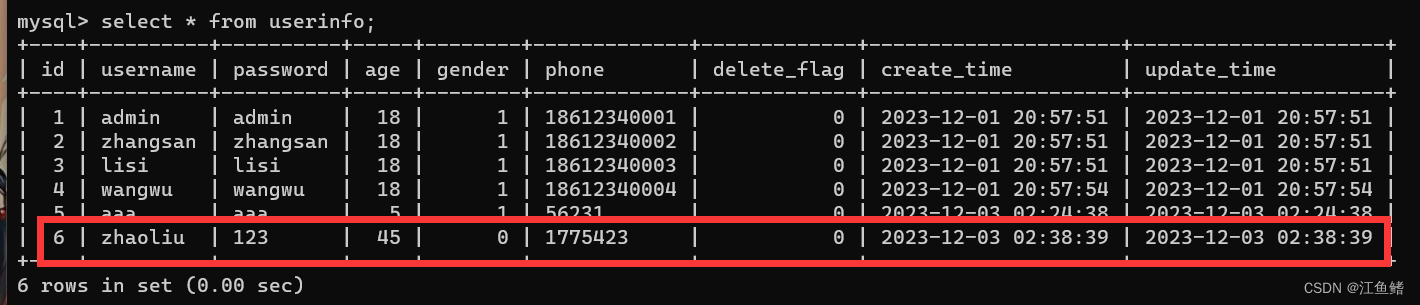
Mybatis 操作续集2(结合上文)
Mybatis 是一个持久层框架,用于简化数据库的操作,和Spring 没有任何关系,我们现在能使用它是因为 Spring Boot 把Mybatis 的依赖给引入进来了,在 pom.xml 里面 Mybatis 如何进行重命名? 看最后两行代码,这样就能重命名了 package com.example.mybatisdemo.mapper;import com…...
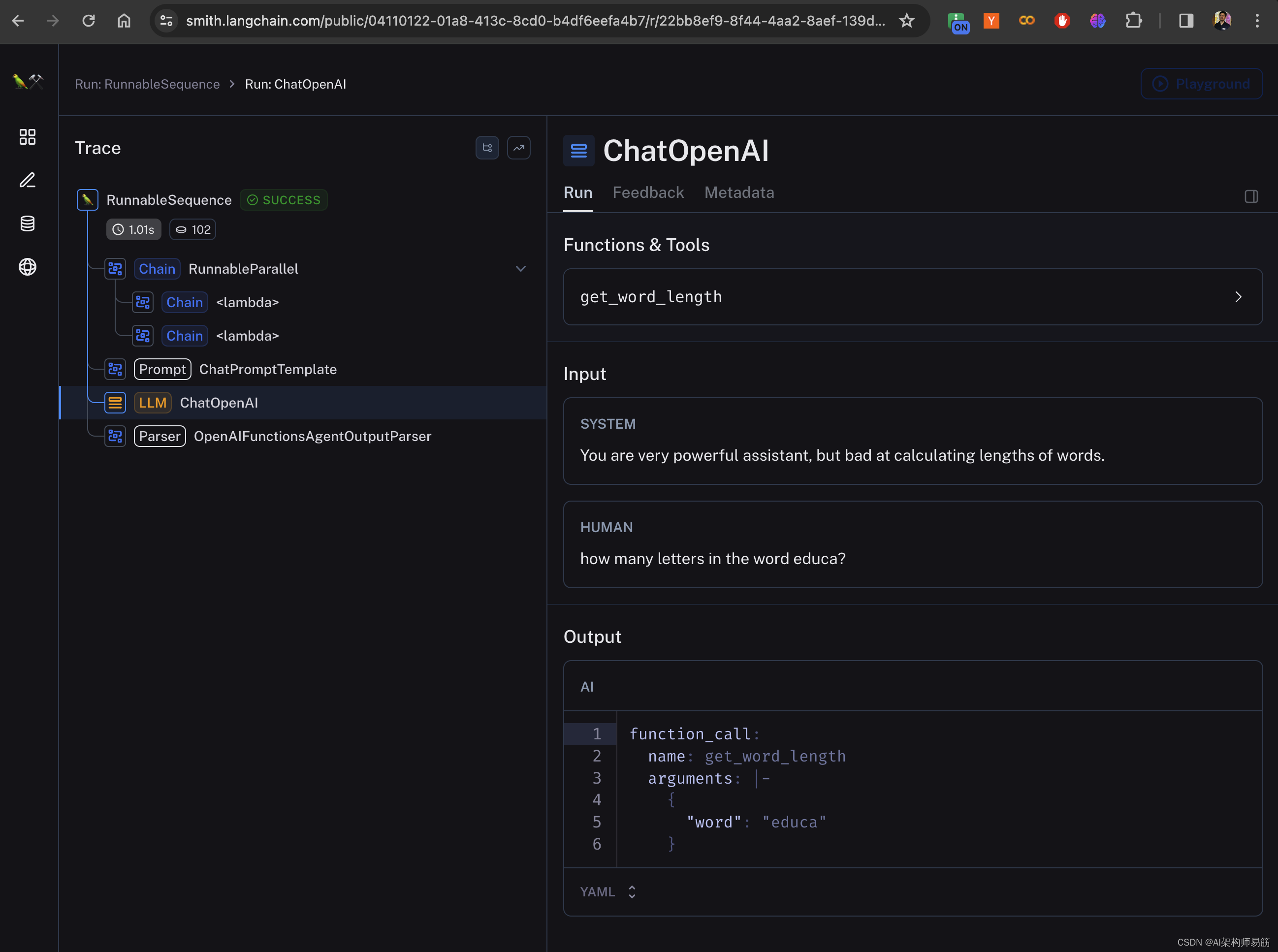
LangChain 19 Agents Reason+Action自定义agent处理OpenAI的计算缺陷
LangChain系列文章 LangChain 实现给动物取名字,LangChain 2模块化prompt template并用streamlit生成网站 实现给动物取名字LangChain 3使用Agent访问Wikipedia和llm-math计算狗的平均年龄LangChain 4用向量数据库Faiss存储,读取YouTube的视频文本搜索I…...

SQL如何提取分组中的第一条记录_使用ROW_NUMBER定位数据
ROW_NUMBER() 是最稳的分组取首行解法,需在子查询或CTE中按PARTITION BY分组、ORDER BY排序,外层筛选rn1;GROUP BY配MIN(id)易导致数据错乱,且无ORDER BY时顺序不保证;须建联合索引覆盖分组与排序字段,并注…...

基于Shell与Python的本地化GPT服务部署与架构实践
1. 项目概述:一个基于Shell与NLP的轻量级GPT服务接口最近在折腾一些自动化脚本和智能对话的集成,发现了一个挺有意思的需求:能不能在命令行里,或者通过一个简单的HTTP请求,就能调用类似GPT这样的语言模型,来…...

UEFI开发避坑指南:WaitForEvent和CreateEvent的5个实战陷阱与正确用法
UEFI开发避坑指南:WaitForEvent和CreateEvent的5个实战陷阱与正确用法 如果你正在开发UEFI驱动或应用,事件机制(Event)一定是绕不开的核心功能。但看似简单的WaitForEvent和CreateEvent,在实际编码中却暗藏玄机。本文将…...
)
内网开发环境救星:保姆级教程搞定Docker与Docker Compose离线安装(附避坑清单)
内网开发环境救星:保姆级教程搞定Docker与Docker Compose离线安装(附避坑清单) 在企业级开发环境中,内网隔离是常见的安全策略,但这也给技术栈的部署带来了挑战。想象一下,当你需要在完全离线的环境中搭建一…...
)
ESP32-C3驱动2寸ST7789屏幕?手把手教你搞定LVGL移植(附避坑代码)
ESP32-C3与ST7789屏幕的LVGL移植实战指南 在物联网设备开发中,显示交互界面往往是提升用户体验的关键一环。ESP32-C3作为乐鑫推出的高性价比RISC-V芯片,搭配ST7789驱动的2寸LCD屏幕,能够构建出性能稳定、成本可控的嵌入式显示方案。本文将带你…...

终极指南:3分钟掌握Deepin Boot Maker,轻松制作Linux启动盘
终极指南:3分钟掌握Deepin Boot Maker,轻松制作Linux启动盘 【免费下载链接】deepin-boot-maker 项目地址: https://gitcode.com/gh_mirrors/de/deepin-boot-maker 你是否曾经因为复杂的命令行操作而对Linux系统安装望而却步?或者面对…...

英雄联盟智能BP与战绩查询:你的排位赛终极助手
英雄联盟智能BP与战绩查询:你的排位赛终极助手 【免费下载链接】Seraphine 英雄联盟战绩查询工具 项目地址: https://gitcode.com/gh_mirrors/se/Seraphine 你是否曾经在排位赛BP阶段手忙脚乱,不知道该禁用哪个英雄?或者想了解队友和对…...

对抗测试框架:用字节码增强与混沌工程提升系统韧性
1. 项目概述:一个对抗测试的“剧院”最近在开源社区里,我注意到一个名字挺有意思的项目,叫nanami7777777/anti-test-theater。乍一看,这个标题有点让人摸不着头脑——“反测试剧院”?测试和剧院能扯上什么关系…...

autoloom:自动化工作流编排框架的设计原理与实践指南
1. 项目概述与核心价值最近在GitHub上看到一个挺有意思的项目,叫autoloom,作者是thresher-sh。光看名字,可能有点摸不着头脑,但如果你正在处理一些需要“编织”或“缝合”多个独立数据源、API接口、微服务或者自动化流程的任务&am…...

别再傻傻分不清了!数字IC面试必问的Latch与Flip-Flop,我用Verilog代码给你讲明白
数字IC面试突围:Latch与Flip-Flop的Verilog避坑指南 1. 从门电路到时序逻辑:存储单元的本质差异 在数字电路设计中,存储单元如同城市交通的信号灯系统。锁存器(Latch)就像持续亮着的红灯——只要信号有效(电…...