ChatGPT 问世一周年之际,开源大模型能否迎头赶上?
就在11月30日,ChatGPT 迎来了它的问世一周年,这个来自 OpenAI 的强大AI在过去一年里取得了巨大的发展,迅速吸引各个领域的用户群体。
我们首先回忆一下 OpenAI和ChatGPT这一年的大事记(表格由ChatGPT辅助生成):
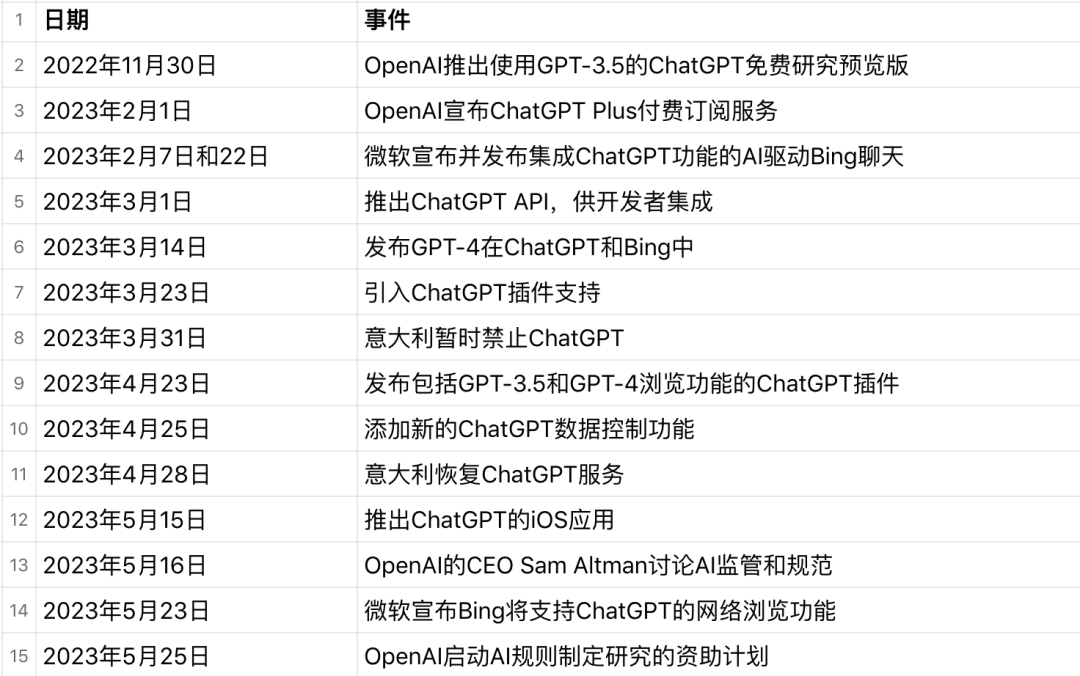
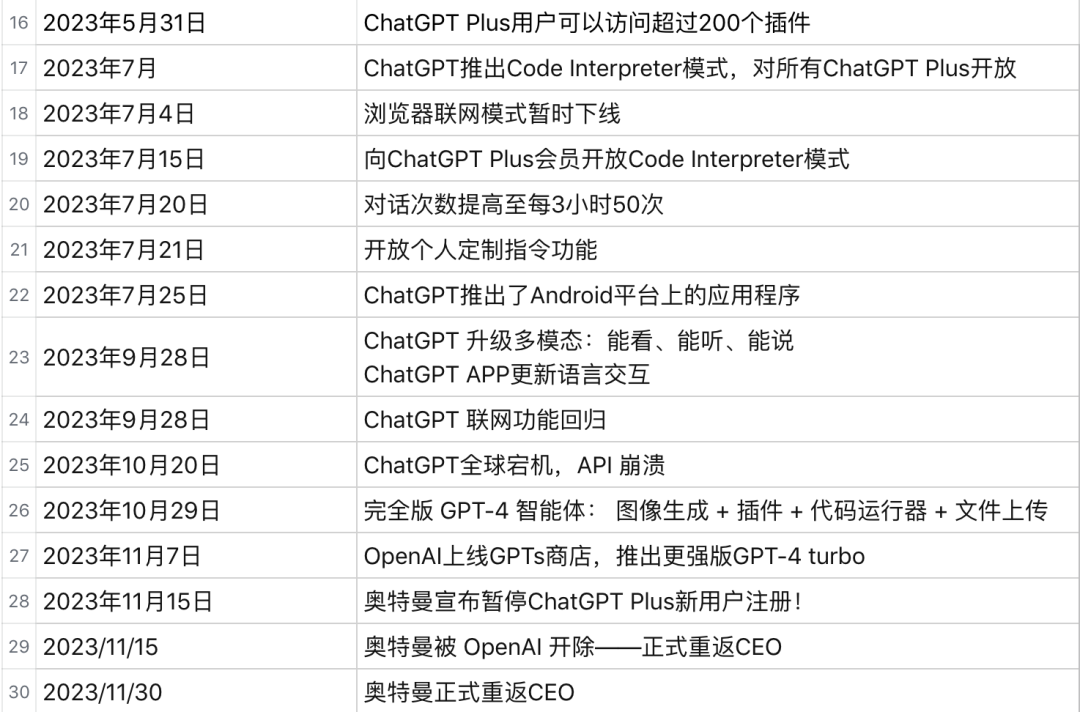
在这个具有里程碑意义的时刻,我们在回顾这一引领变革的产品的同时,也需要注意到新一代的开源大语言模型也在崛起。
这些开源大模型发展到什么程度了?
能否赶超一年前发布的 ChatGPT呢?
在这篇综述中,我们将深入介绍这些开源 LLM 的强大之处,在各个任务领域中,对比他们和 ChatGPT 的表现。相信这些模型将为自然语言处理领域未来的研究方向提供新的启示。
论文题目:
ChatGPT's One-year Anniversary: Are Open-Source Large Language Models Catching up ?
论文链接:
https://arxiv.org/abs/2311.16989
由于 ChatGPT 具有降低劳动成本、使工作流程自动化,甚至为客户带来全新体验的潜力,它在诞生仅一个月就吸引了 1 亿用户以及大量的商业投资。但它的闭源性质使得难以获取其技术细节,用户和研究者无法深入了解其确切的架构、预训练数据和微调数据。
不开源的 ChatGPT VS 开源 LLM
ChatGPT 不开源的缺点
-
缺乏透明度: 这种缺乏透明度使得难以正确评估其对社会的潜在风险(尤其涉及生成有害、有悖道德和不真实内容的情况)。
-
可复制性问题: 由于闭源,ChatGPT 的性能随时间推移可能会发生变化,妨碍了研究人员和开发者进行可复现的实验和结果验证。这种不确定性影响了对 ChatGPT长期效果和稳定性的信任。
-
服务不稳定:ChatGPT 在过去经历了多次故障,包括前段时间影响诸多忠实用户工作和学习的大宕机事件。这使得依赖 ChatGPT 的企业和开发者可能面临服务中断和不可预测的事件,对其业务产生负面影响。
-
高昂的调用费:企业调用 ChatGPT 的 API 可能会面临高昂的调用费用,这也成为使用该技术的负担。
开源 LLM 有何好处?
-
透明度与可控性: 开源 LLM 具有更高的透明度,用户和研究人员可以访问模型的源代码和详细文档,了解其内部工作原理。这种透明度有助于评估模型的安全性和可靠性。
-
社区参与与反馈: 促进了社区广泛参与,研究人员和开发者可以共同改进模型、提出建议,并报告问题。这种反馈循环有助于及时纠正潜在的问题和提升模型性能。
-
可持续发展:开源 LLM 的持续发展受益于全球社区的共同努力,使其更具鲁棒性和可持续性。这种合作能助力模型适应不断变化的需求和挑战。
-
避免依赖单一提供者:采用开源 LLM 可避免对单一提供者的过度依赖,降低了由于服务不稳定或其他问题而产生的风险。这种多样性有助于保障业务的连续性。
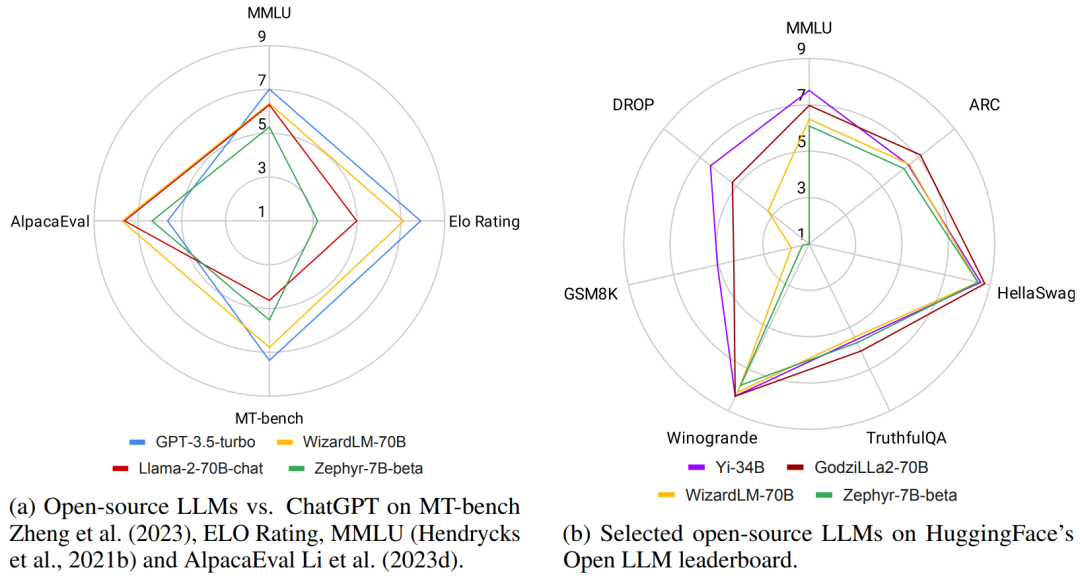
▲图1 不同开源LLM 在各种通用基准上的概述
如图 1 所示,在某些任务上,最好的开源 LLM 已经超过了 GPT-3.5-turbo。然而,随着开源 LLM 几乎每周发布一次,以及大量用于评估比较 LLM 的数据集和基准不断涌现,从中找出最佳 LLM 变得更加具有挑战性。为了帮助读者更好地了解这一领域的最新进展,本文作者对近期关于开源 LLM 的研究进行了综述,提供了在各个领域与 ChatGPT 相匹敌或超越的开源 LLM 的概述。
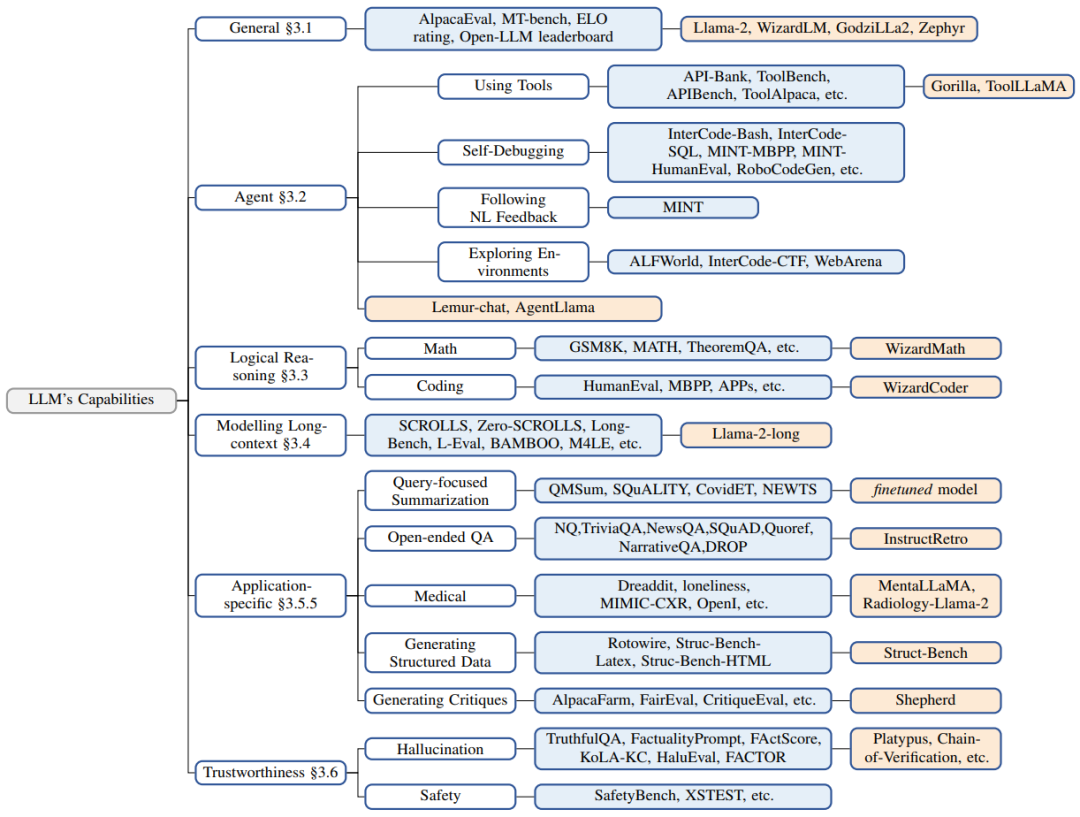
▲图2 LLM 能力和表现最佳的开源 LLM 类型。白色方框表示领域,蓝色方框表示特定数据集,橙色方框表示开源LLM
图 2 展示了在各种任务中超越或赶上 ChatGPT 的开源 LLM。
开源 LLM 与 ChatGPT 的比较
1. 通用能力上的对比
如表 1 所示,在通用任务中,Llama-2-chat-70B 相较于 GPT3.5-turbo 在一些基准上表现更好,但在其他测试中仍稍显不足。Zephir-7B 通过优化偏好逼近 70B 的 LLM。WizardLM-70B 和 GodziLLa-70B 则能够与 GPT-3.5-turbo 相媲美。整体而言,GPT-4在几个评估指标上表现都是最好的,这是目前的很多开源模型所不能比的,也是其未来所要努力的方向。
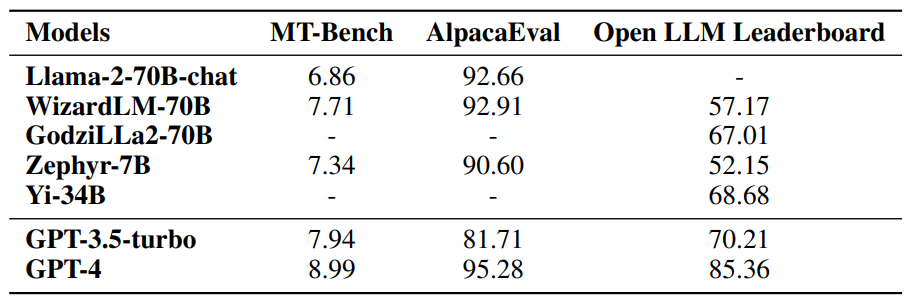
▲表1 模型在通用基准上的比较
2. 智能体能力上的对比
在基于 LLM 的智能体任务中,Lemur-70B-chat 在探索环境和任务特定预训练方面表现更好,AgentTuning 在未见过的智能体任务上有所提升,ToolLLama 更擅长掌握使用工具,Gorilla 在编写 API 调用方面优于 GPT-4。
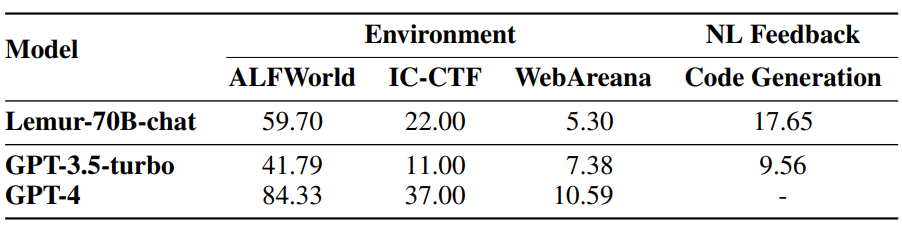
▲表2 模型在智能体基准上的性能比较
3. 逻辑推理能力上的对比
逻辑推理方面,WizardCoder 和 WizardMath 通过增强指令微调提高了推理能力,Lemur 和 Phi 通过在更高质量的数据上进行预训练表现更强大。
4. 长序列建模能力
处理长序列仍是 LLM 的关键技术瓶颈之一,因为所有模型都受到最大上下文窗口的限制,通常长度在 2k 到 8k token 之间。在长上下文建模方面,Llama-2-long 通过使用更长的 token 和更大的上下文窗口进行预训练,可以在选定的基准上取得进展。
解决长上下文任务的方法包括使用位置插值进行上下文窗口扩展,其中有对更长上下文窗口进行另一轮微调,以及需要访问检索器以查找相关信息的检索增强。Xu 等人(2023b)结合了这两种技术,将 Llama-2-70B 在 7 个长上下文任务上的平均性能提升到了 GPT-3.5-turbo-16k 之上。
5. 特定应用能力的对比
对于特定应用能力,InstructRetro 通过检索和指令微调改善了开放式问答的性能,MentaLlama-chat13B 在心理健康分析数据集中优于 GPT-3.5-turbo,RadiologyLlama2 在放射学报告分析上表现出色,Stru-Bench 在生成结构化回复方面优于 GPT-3.5-turbo,Shepherd 在生成模型反馈和批评方面达到了与 GPT-3.5-turbo相当或更好的性能。
6. 可信度方面的比较
为了确保 LLM 在现实应用中能够得到人类的信任,需要考虑的重要因素是它们的可靠性。对于幻觉和安全性的担忧可能会降低用户对 LLM 的信任。
-
在微调过程中,提高正确性和相关性方面的数据质量可以导致产生幻觉的模型减少。
-
在推理期间,现有的技术有特定的解码策略、外部知识增强和多智能体对话。
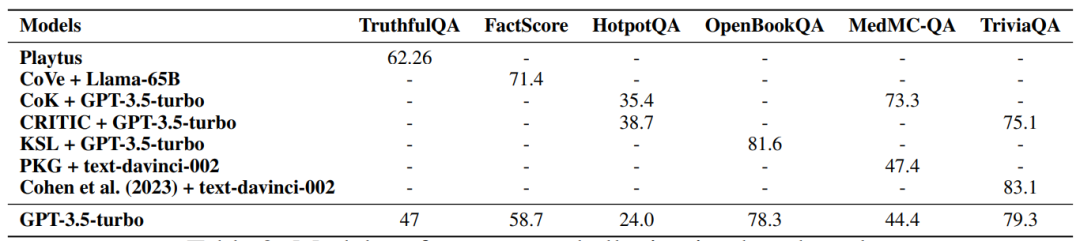
▲表3 模型在幻觉基准上的性能比较
然而,在 AI 安全领域,很多开源 LLM 与 GPT-3.5-turbo 和 GPT-4 仍然无法匹敌,因为它们以更安全、更具道德的行为而闻名,这可能是商业 LLM 相对于开源 LLM 更为重视安全性。尽管如此,随着 RLHF 过程的民主化,我们能够期待看到更多开源 LLM 改进安全性方面的性能。
LLM 的发展趋势
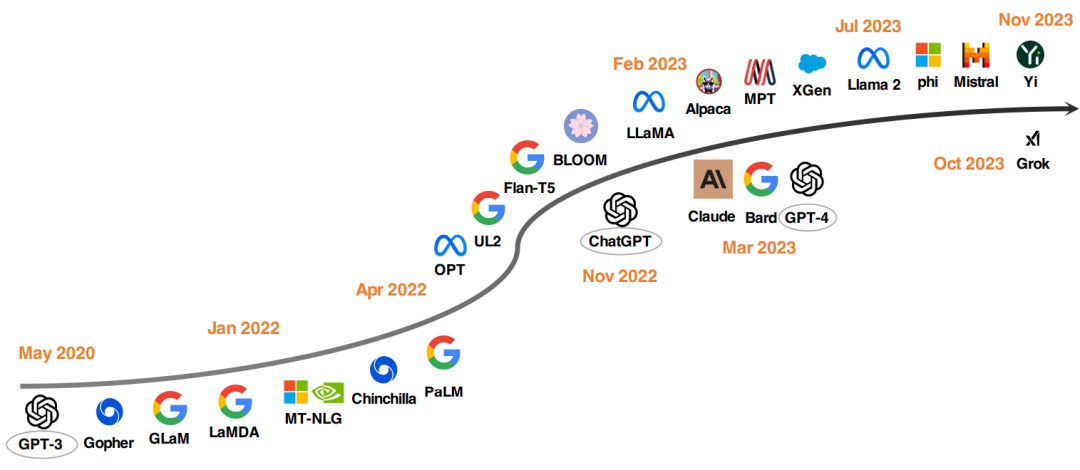
▲图3 LLM 的发展时间线,下半部分模型是闭源的,上半部分模型是开源的
自从有人证明冻结参数的 GPT-3 在 zero-shot 和 few-shot 任务上表现卓越后,研究者们就采取了多方面措施推动 LLM 的发展:
-
尝试通过增大模型参数量提升性能,但这些模型不开源,受到了应用范围的限制,从而引发了更多人对于开源 LLM 的研究兴趣。
-
致力于寻找更好的预训练策略(如 Chinchilla 和 UL2),以及在预训练以外进行指令微调的方法(如 FLAN、T0 和 Flan-T5)。
去年,OpenAI 发布的 ChatGPT 推动了 NLP 领域的研究,随后 Google 和 Anthropic 又相继推出了 Bard 和 Claude。尽管它们在很多任务上表现突出,但与 GPT-4 相比仍存在着性能上的差距。为促进开源 LLM 的发展,Meta 发布了 Llama 系列模型,以及 Alpaca、Vicuna、Lima 和 WizardLM 等模型,它们通过微调实现了不断的发展,同时还有其他工作致力于从头开始训练强大的 LLM。未来,开发更强大、高效的开源 LLM 是具有前途的研究方向。
最佳的开源 LLM 配置
作者还讨论了训练开源 LLM 的最佳实践方案:
-
数据:预训练阶段使用数万亿个来自公开可访问来源的数据 token。在道德层面排除了包含个人信息的任何数据。微调所用的数据量较小,但质量都很高,尤其是在专业领域的微调,使用优质数据能够改进性能。
-
模型架构:大多数 LLM 使用仅有解码器的 Transformer 架构,但用了不同的技术来优化效率。例如,Llama-2 引入了 Ghost attention 来改进多轮对话控制,而 Mistral 采用了滑动窗口注意力以处理更长的上下文。
-
训练:使用指令微调数据进行监督微调(SFT)的过程至关重要。高质量结果需要数万个 SFT 注释,例如 Llama-2 使用了 27540个 注释。数据的多样性和质量在这个过程中至关重要。在 RLHF 阶段,近端策略优化(PPO)通常是优选的算法,有助于使模型行为与人类偏好和指令遵循一致,从而提高 LLM 的安全性。替代 PPO 的选择是直接偏好优化(DPO)。例如,Zephyr-7B 采用了蒸馏 DPO,在各种通用基准中表现与 70B-LLM 相当,甚至在 AlpacaEval 上超越了 GPT-3.5-turbo。
待改进之处
尽管许多开源LLM 的涌现让我们看到了希望,但目前仍存在一些需要改进的方面,比如:
-
预训练期间的数据污染:模型发布时通常不公开其预训练语料库的来源,因此模型在预训练过程中可能使用了一些基准数据,而这些数据并没有在预训练任务中的数据源中被明确标记。这可能导致数据污染问题,即模型可能无意中从中获取了某些知识。由于缺少对模型预训练语料库来源的清晰了解,人们可能怀疑模型在实际应用中是否能够有效泛化到不同任务和场景。为了解决这一问题,需要检测 LLM 预训练语料库,研究基准数据与广泛使用的预训练语料库之间的重叠情况,并评估模型对基准数据的过拟合情况。未来可能的研究方向包括建立一些标准化实践,使模型在开发过程中能更透明地披露其预训练语料库的细节,并在开发层面减轻模型在整个生命周期中受到的数据污染。
-
在对齐方面的闭源开发:目前 AI 社区越来越关注利用通用偏好数据,这是一种表达人类喜好和优先选择的数据类型,结合强化学习方法进行模型的对齐,微调模型使其与人类的喜好和反馈一致。但是,获取高质量、公开可用的通用偏好数据和预训练奖励模型并不容易,只有少数开源 LLM 采用了增强 RLHF 来进行对齐。有人提议为开源社区提供支持,以解决通用偏好数据的稀缺性问题,从而促进更多的开源 LLM 采用对齐方法。但在复杂的推理、编程和安全场景中,仍然存在缺乏多样性、高质量和可扩展的偏好数据的挑战,这仍是个难题。
-
持续提升基本能力的困境:
(1)预训练期间投入大量努力来改进数据混合,以构建更平衡和稳健的基础模型。但这方面的探索成本通常较高,使得方法难以实际应用。
(2)模型要想超越像 GPT-3.5-turbo 或 GPT-4,主要依赖对这些闭源模型的知识蒸馏和额外的专家注释。尽管这种方法高效,但过度依赖知识蒸馏可能掩盖了将这些方法扩展到教师模型时的效果问题。
(3)人们都希望 LLM 能扮演智能体并提供合理的解释以支持决策,但对智能体样式的数据进行注释以使 LLM 适用于实际场景非常昂贵且耗时。
实际上,仅通过知识蒸馏或专家注释进行优化无法实现基本能力的持续改进,可能会接近一个上限。未来的研究可能需要探索无监督或自监督学习范式的新方法,以实现持续提升基本 LLM 的能力,以减轻所面临的挑战和成本。
总结
在开源 LLM 与 ChatGPT 的详细性能比较中,作者深挖了一些现象背后的原因。然而,我们应该认识到文章的关键并非仅是简单的性能数值比较,更在于作者对背后现象的深刻剖析。因为在不同的规则或标准下,这些比较都不尽全面。而在我们研究的道路上,理解“为什么”比“是什么”更为重要,所有的研究都致力于不断改进,而未来的关键更在于应该探讨“怎么办”。
尽管开源是广大研究者一致追求的目标,但要实现这一目标需要面对 LLM 训练和创新所需的高昂成本。这不仅需要大量时间和精力处理数据,还需要投入资源来处理潜在的安全或道德伦理层面的风险。
希望在相关研究层出不穷的情况下,未来的某一天,我们能够摆脱在特定领域或指标上绞尽脑汁比较性能来证明模型优越性的局面,而能够直接通过感受开源 LLM 的表现就能判断足与这些优秀的商业 LLM 相匹敌。对于这样的一天,我们翘首以盼。

相关文章:
ChatGPT 问世一周年之际,开源大模型能否迎头赶上?
就在11月30日,ChatGPT 迎来了它的问世一周年,这个来自 OpenAI 的强大AI在过去一年里取得了巨大的发展,迅速吸引各个领域的用户群体。 我们首先回忆一下 OpenAI和ChatGPT这一年的大事记(表格由ChatGPT辅助生成)&#x…...
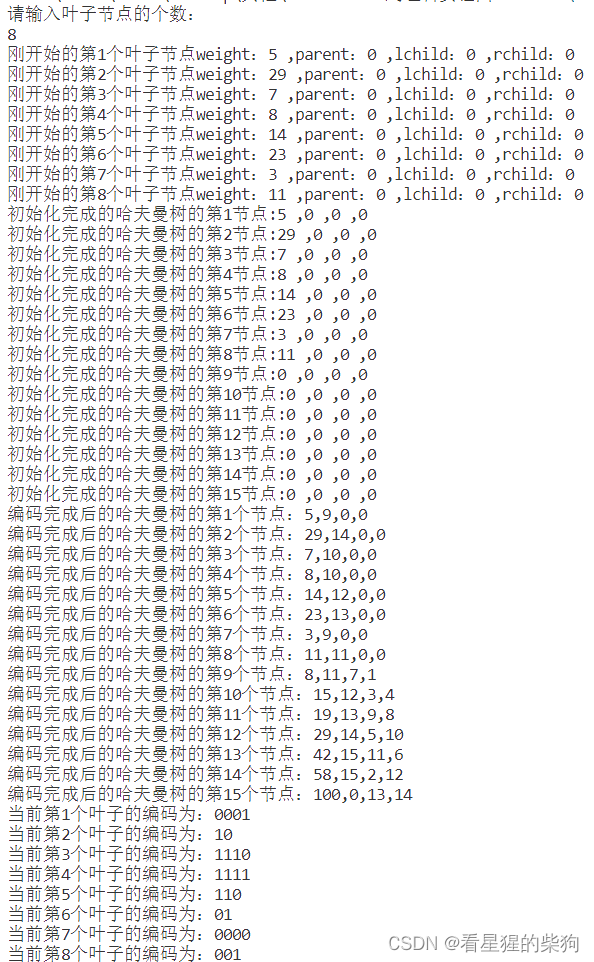
数据结构和算法-哈夫曼树以相关代码实现
文章目录 总览带权路径长度哈夫曼树的定义哈夫曼树的构造法1法2 哈夫曼编码英文字母频次总结实验内容: 哈夫曼树一、上机实验的问题和要求(需求分析):二、程序设计的基本思想,原理和算法描述:三、调试和运行…...

Kafka 的起源和背景
Apache Kafka 是一个分布式流处理平台,被广泛用于构建实时数据流应用程序和大数据处理系统。本文将深入探讨 Kafka 的起源、设计原则以及它在大数据领域中的重要作用。 大数据和实时数据处理背景 在大数据时代,处理海量数据和实时数据成为了一项关键挑…...
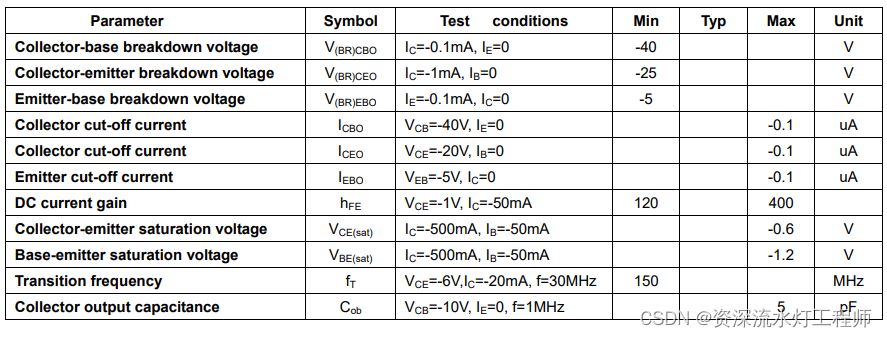
三极管在数字电路中的应用
一、认识三极管 三极管拥有3个引脚,分别对应3个级:基极(Base)、发射极(Emitter)、集电极(Collector),如下图所示;下图横向左侧的是基极,带箭头的那个引脚就是发射极,另一个就是集电…...
java后端自学错误总结
java后端自学错误总结 MessageSource国际化接口总结 MessageSource国际化接口 今天第一次使用MessageSource接口,比较意外遇到了一些坑 messageSource是spring中的转换消息接口,提供了国际化信息的能力。MessageSource用于解析 消息,并支持消息的参数化…...
CLion安装与配置教程
目录 一、下载并安装CLion1、下载1、官网:2、注意: 2、安装1、下载完成后,直接点击安装包安装,即可。2、开始安装,然后下一步3、可以在此处自定义地址,然后下一步4、根据系统版本选择,然后下一步…...

初识主力投资者
在股票市场中,真正赚钱的散户并不多。“七亏二平一赚”似乎已经成为了大家公认的一个股市定律。 为什么散户炒股赚的人少呢?原因很简单,就是因为市场上除了散户之外,还存在着一个重要的投资主体——主力。股市交易的过程ÿ…...
vue项目报错及解决npm run build:prod打包错误
vue项目报错及解决npm run build:prod打包错误 执行dev环境时加载失败了该变量,在package.json文件中 删掉 解决方法: 打包成功:...

Go连接mysql数据库
package main import ("database/sql""fmt"_ "github.com/go-sql-driver/mysql" ) //go连接数据库示例 func main() {// 数据库信息dsn : "root:roottcp(192.168.169.11:3306)/sql_test"//连接数据库 数据库类型mysql,以及数据库信息d…...

⭐ Unity 里让 Shader 动画在 Scene 面板被持续刷新
写 Unity Shader的时候,只有播放状态下的 Game 面板能看到Shader 顺畅的动态效果,不方便。 想要带有动态效果的 Shader 在 Scene 面板持续更新动画,只需要打开一个开关就能让 Scene 持续刷新动画了。 感谢大家的观看,您的点赞和关…...

面试--各种场景问题总结
1.在开发过程中,你是如何保证机票系统的正常运行的? 用户、测试、监控和日志、安全措施、数据备份、系统设计、需求分析 2.在机票系统开发过程中,你最有成就的事情,为什么? 用户体验感、高可用和稳定性、客户满意度、系…...
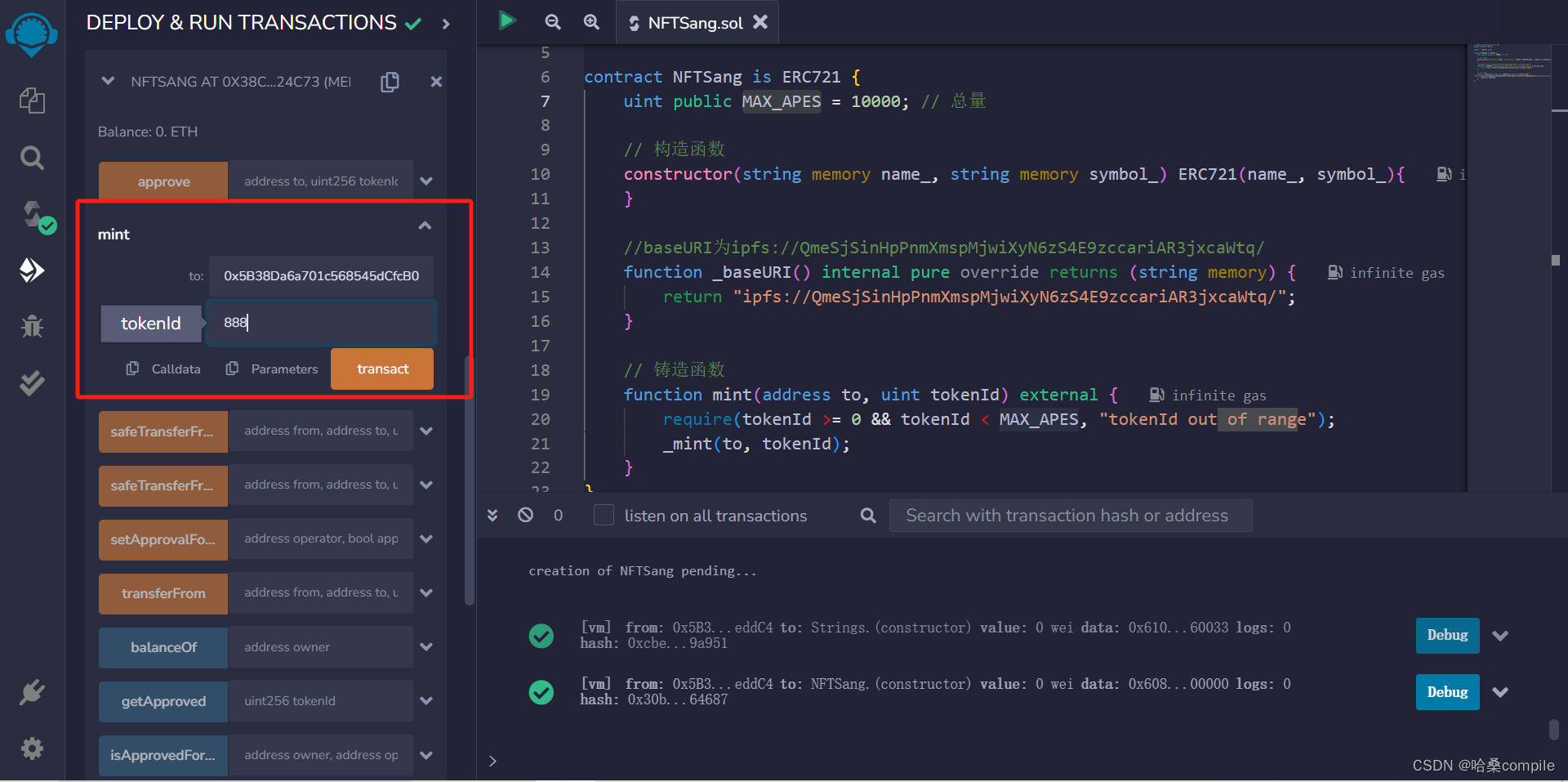
solidity实现ERC721代币标准发布NFT
文章目录 1、非同质化货币(NFT)- 维基百科2、IERC1653、IERC7214、IERC721Receiver5、IERC721Metadata6、ERC7217、ERC721 NFT 的实现8、编译部署 1、非同质化货币(NFT)- 维基百科 非同质化代币(英语:Non-F…...

Failed building wheel for opencv-python which use PEP 517
这主要是opencv-python版本更新以后wheels也更新了,但是相关安装软件没有及时适配,所以不管是使用pip直接安装还是换源其实效果都是报错,解决方法就是直接指定安装旧版opencv-python完事儿,例如: pip3 install opencv…...
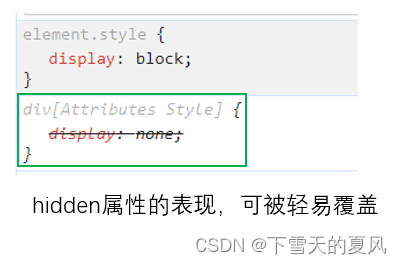
HTML5 的全局属性 hidden 和 display:none 的关系
目录 1,hidden 和 display:none 的关系2,其他隐藏元素的方式2.1,语意上的隐藏2.2,视觉上的隐藏 1,hidden 和 display:none 的关系 hidden - MDN 参考 一句话总结:hidden 是HTML5 新增的全局布尔属性&…...
CCKS2023-面向上市公司主营业务的实体链接评测-亚军方案
赛题分析 大赛地址 https://tianchi.aliyun.com/competition/entrance/532097/information 任务描述 本次任务主要针对上市公司的主营业务进行产品实体链接。需要获得主营业务中的产品实体,将该实体链接到产品数据库中的某一个标准产品实体。产品数据库将发布在竞赛…...

关于我离破500粉丝感受
嘿嘿快破500粉丝啦,加油喔,感谢支持 首先,恭喜我在CSDN上的粉丝数量即将突破500大关!这说明你在这个平台上的内容受到了很多人的关注和认可。 1. 保持高质量的内容输出:粉丝数量的增长与你在CSDN上发布的内容质量密切…...

锁表的原因及解决办法
引言 作为开发人员,我们经常会和数据库打交道。 当我们对数据库进行修改操作的时候,例如添加字段,更新记录等,没有正确评估该表在这一时刻的使用频率,直接进行修改,致使修改操作长时间无法响应࿰…...

Kettle 安装配置
文章目录 Kettle 安装配置Kettle 安装Kettle 配置连接 Hive Kettle 安装配置 Kettle 安装 在安装Kettle之前,需要确定已经安装Java运行环境。Kettle需要Java的支持才能运行,JDK的版本最好是8.x的太新的也会出现bug。Kettle的7.1版本的太旧了࿰…...
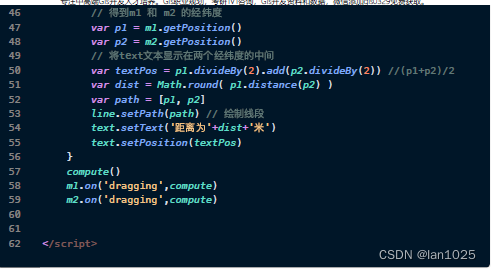
Webgis学习总结
前言: 作者跟随视频学习了webgis内容进行如下学习复习总结 参考:新中地学习笔记 WebGIS第一课:测试高德API并通过: 注册申请高德API成为开发者,创建自己的项目和key进行项目初始化,可以使用JS API官方文…...

【开源】基于Vue+SpringBoot的音乐平台
项目编号: S 055 ,文末获取源码。 \color{red}{项目编号:S055,文末获取源码。} 项目编号:S055,文末获取源码。 目录 一、摘要1.1 项目介绍1.2 项目录屏 二、功能模块三、系统展示 四、核心代码4.1 查询单首…...

Godot引擎集成Wwise音频中间件:从原理到实战的完整指南
1. 项目概述:当AAA级音频引擎遇见开源游戏引擎如果你是一位使用Godot引擎的游戏开发者,并且对游戏音频的品质有追求,那么你很可能听说过Wwise。Wwise,全称Audiokinetic Wwise,是游戏音频领域的行业标准,从《…...

sagents框架实战:从零构建具备记忆与协作能力的AI智能体
1. 项目概述:一个面向开发者的AI智能体构建框架最近在AI应用开发领域,一个名为sagents的开源项目引起了我的注意。它不是一个直接面向终端用户的聊天机器人,而是一个旨在帮助开发者快速构建、管理和编排复杂AI智能体(Agent&#x…...

DevUI布局系统完全指南:响应式设计的终极解决方案
DevUI布局系统完全指南:响应式设计的终极解决方案 【免费下载链接】ng-devui Angular UI Component Library based on DevUI Design 项目地址: https://gitcode.com/DevCloudFE/ng-devui DevUI布局系统是Angular UI组件库中的核心功能,为开发者提…...

量子退火误差缓解:经典阴影与局部虚拟纯化技术
1. 量子退火中的误差挑战与经典阴影方法量子退火(Quantum Annealing, QA)作为量子计算领域的重要算法,在优化问题求解中展现出独特优势。然而,实际硬件实现时面临的退相干问题严重制约了其计算精度。传统量子纠错方案需要大量物理…...

风冷热泵中央空调系统安装:从冷热源到末端联动的完整解析
一、什么是风冷热泵中央空调系统安装?风冷热泵中央空调系统安装,是指在办公楼、商业综合体、酒店、学校、医院、厂房办公区、实验室、园区配套建筑以及各类中小型公共建筑中,根据建筑冷热负荷、使用时段、空间功能和节能要求,对风…...

Postman+Newman自动化测试报告生成全攻略:让微信小程序接口回归测试5分钟搞定
PostmanNewman自动化测试报告生成全攻略:让微信小程序接口回归测试5分钟搞定 在追求研发效能的今天,手工重复执行接口测试已成为效率瓶颈。想象一下:每次微信小程序迭代更新,测试工程师都需要在Postman中逐个点击上百个接口用例&a…...

京东自动抢购工具完整指南:5分钟学会Python自动化购物
京东自动抢购工具完整指南:5分钟学会Python自动化购物 【免费下载链接】autobuy-jd 使用python语言的京东平台抢购脚本 项目地址: https://gitcode.com/gh_mirrors/au/autobuy-jd 还在为京东秒杀抢不到心仪商品而烦恼吗?想要在促销活动中轻松抢购…...

AI驱动的代码冻结守护者:开源项目xcf如何提升软件发布质量
1. 项目概述:当AI遇上代码冻结,一个开源协作范式的诞生最近在开源社区里,一个名为CodeFreezeAI/xcf的项目引起了我的注意。乍一看这个标题,可能会让人有些困惑:“CodeFreeze” 通常指的是软件开发流程中的“代码冻结”…...

3分钟为Windows 11 LTSC恢复微软商店的完整指南:解决精简版系统应用生态缺失问题
3分钟为Windows 11 LTSC恢复微软商店的完整指南:解决精简版系统应用生态缺失问题 【免费下载链接】LTSC-Add-MicrosoftStore Add Windows Store to Windows 11 24H2 LTSC 项目地址: https://gitcode.com/gh_mirrors/ltscad/LTSC-Add-MicrosoftStore Windows …...
)
Java后端工程师必备:系统学习大模型应用开发(收藏版)
本文深入探讨了Java后端工程师如何系统性地学习AI应用开发,从基础的CRUD操作到大模型的集成,包括RAG、Tool Calling、MCP、Agent等关键技术。文章强调了AI应用开发不仅是调用大模型接口,而是将大模型能力融入真实业务系统,实现理解…...