从零构建属于自己的GPT系列1:数据预处理(文本数据预处理、文本数据tokenizer、逐行代码解读)
🚩🚩🚩Hugging Face 实战系列 总目录
有任何问题欢迎在下面留言
本篇文章的代码运行界面均在PyCharm中进行
本篇文章配套的代码资源已经上传
从零构建属于自己的GPT系列1:文本数据预处理
从零构建属于自己的GPT系列2:语言模型训练
0 任务基本流程
- 拿到txt文本数据,本文以15本金庸小说为例
- CpmTokenizer预训练模型将所有文本处理成.pkl的token文件
- 配置训练参数
- token数据转化为索引
- 导入GPT2LMHeadModel预训练中文模型,训练文本数据
- 训练结束得到个人文本数据特征的新模型
- 搭载简易网页界面,部署本地模型
- text-to-text专属GPT搭建完成
- 获取新数据,模型更加个性化
- 优化模型,一次性读取更长文本,生成更长的结果
1 训练数据
在本任务的训练数据中,我选择了金庸的15本小说,全部都是txt文件
数据打开后的样子
数据预处理需要做的事情就是使用huggingface的transformers包的tokenizer模块,将文本转化为token
最后生成的文件就是train_novel.pkl文件,就不用在训练的时候读txt文件了
数据预处理:preprocess.py
2 设置参数
import argparse
from utils import set_logger
from transformers import CpmTokenizer
import os
import pickle
from tqdm import tqdm
parser = argparse.ArgumentParser()
parser.add_argument('--vocab_file', default='vocab/chinese_vocab.model', type=str, required=False,help='词表路径')
parser.add_argument('--log_path', default='log/preprocess.log', type=str, required=False, help='日志存放位置')
parser.add_argument('--data_path', default='data/novel', type=str, required=False, help='数据集存放位置')
parser.add_argument('--save_path', default='data/train.pkl', type=str, required=False,help='对训练数据集进行tokenize之后的数据存放位置')
parser.add_argument('--win_size', default=200, type=int, required=False,help='滑动窗口的大小,相当于每条数据的最大长度')
parser.add_argument('--step', default=200, type=int, required=False, help='滑动窗口的滑动步幅')
args = parser.parse_args()
- 参数包
- 本项目utils.py中初始化参数函数
- chinese pre-trained model Tokenizer包
- 系统包
- pickle包,用于将 python 对象序列化(serialization)为字节流,或者将字节流反序列化为 Python 对象
- 进度条包
- 创建一个用于解析命令行参数的 ArgumentParser 对象
- 处理中文文本的变成token的预训练模型的模型文件存放位置
- 运行日志文件存放位置
- 数据集存放位置
- 对训练数据集进行tokenize之后的数据存放位置
- 滑动窗口的大小,相当于每条数据的最大长度
- 滑动窗口的滑动步幅
3 初始化日志对象
logger = set_logger(args.log_path)
def set_logger(log_path):logger = logging.getLogger(__name__)logger.setLevel(logging.INFO)formatter = logging.Formatter('%(asctime)s - %(levelname)s - %(message)s')file_handler = logging.FileHandler(filename=log_path)file_handler.setFormatter(formatter)file_handler.setLevel(logging.INFO)logger.addHandler(file_handler)console = logging.StreamHandler()console.setLevel(logging.DEBUG)console.setFormatter(formatter)logger.addHandler(console)return logger
- 选择日志路径,调用日志函数
- 创建 logger 对象
- 设置日志级别为’logging.INFO’
- 创建格式化器 formatter
- 创建文件处理器file_handler并指定了日志文件的路径为log_path
- 设置处理器的日志级别为 logging.INFO
- 添加文件处理器 file_handler 到创建的 logger 对象中
- 创建控制台处理器 console,用 logging.StreamHandler() 创建一个将日志输出到控制台的处理器
- 设置其日志级别为 logging.DEBUG
- 将格式化器 formatter 应用到这个控制台处理器上
- 控制台处理器 console 添加到 logger 对象中
- 返回了这个配置好的 logger 对象
4 初始化
logger = set_logger(args.log_path)
tokenizer = CpmTokenizer(vocab_file="vocab/chinese_vocab.model") # pip install jieba
eod_id = tokenizer.convert_tokens_to_ids("<eod>") # 文档结束符
sep_id = tokenizer.sep_token_id
train_list = []
logger.info("start tokenizing data")
- 初始化日志
- 创建CPMTokenizer 对象,用于分词和处理中文文本
- tokenizer 将特殊标记 转换为其对应的 ID
- 获取分词器中分隔符的 ID
- 最后处理的数据
- 打印
5 处理数据
for file in tqdm(os.listdir(args.data_path)):file = os.path.join(args.data_path, file)with open(file, "r", encoding="utf8") as reader:lines = reader.readlines()for i in range(len(lines)):if lines[i].isspace() != True and lines[i] != '\n':token_ids = tokenizer.encode(lines[i].strip(), add_special_tokens=False) + [eod_id]if i % 1000 == 0:print('cur_step', i, lines[i].strip())else:continuewin_size = args.win_sizestep = args.stepstart_index = 0end_index = win_sizedata = token_ids[start_index:end_index]train_list.append(data)start_index += stepend_index += stepwhile end_index + 50 < len(token_ids): # 剩下的数据长度,大于或等于50,才加入训练数据集data = token_ids[start_index:end_index]train_list.append(data)start_index += stepend_index += step# 序列化训练数据
with open(args.save_path, "wb") as f:pickle.dump(train_list, f)
os.listdir(args.data_path):得到该路径下所有文件的文件名字符串并返回一个字符串数组,for file in tqdm的for循环会打印读取进度的进度条- 获得当前文件的完整路径
- 按照
file路径、utf-8编码格式、只读模式打开文件 - 按行来读取文件,line在这里是一个list,list每个数据都对于文件的一行数据
- 按照行数遍历读取文件数据
- 判断当前行是否为空行,或者这行只有换行
- 使用tokenizer进行encode,加入结束索引
- 每1000行进行一次打印操作
- 每1000行进行一次打印操作
- 空行不处理
- 空行不处理
- 滑动窗口长度
- 滑动次数
- 第一个文件的第i行的第一条数据的开始索引
- 第一个文件的第i行的第一条数据的结束索引
- 第一个文件的第i行的第一条数据
- 添加第一条数据到总数据中
- while循环取数据,最后一条数据不足50时就不要了,逐个取数据直到换行,注意这里一行数据可能是一段哦,不一定有逗号或者句号就会换行
- 第一个文件的第i行的第k条数据
- 添加第k条数据到总数据中
- 按照滑动次数更新开始索引
- 按照滑动次数更新结束索引
- 最后所有的数据都保存在了train_list中
- 保存为pickle文件
6 运行过程

结束后,生成.pkl文件,这个文件作为训练数据进行训练

从零构建属于自己的GPT系列1:文本数据预处理
从零构建属于自己的GPT系列2:语言模型训练
相关文章:
从零构建属于自己的GPT系列1:数据预处理(文本数据预处理、文本数据tokenizer、逐行代码解读)
🚩🚩🚩Hugging Face 实战系列 总目录 有任何问题欢迎在下面留言 本篇文章的代码运行界面均在PyCharm中进行 本篇文章配套的代码资源已经上传 从零构建属于自己的GPT系列1:文本数据预处理 从零构建属于自己的GPT系列2:语…...

c++中函数的引用
函数中的引用 引用可以作为函数的形参 不能返回局部变量的引用 #include<iostream> #include<stdlib.h> using namespace std; //形参是引用 void swap(int *x, int *y)//*x *y表示对x y取地址 { int tmp *x; *x *y; *y tmp; } void test01() { …...
IDA常用操作、快捷键总结以及使用技巧
先贴一张官方的图,然后我再总结一下,用的频率比较高的会做一些简单标注 快捷键 F系列【主要是调试状态的处理】 F2 添加/删除断点F4 运行到光标所在位置F5 反汇编F7 单步步入F8 单步跳过F9 持续运行直到输入/断点/结束 shift系列【主要是调出对应的页…...

Kibana使用指南
使用介绍主要特点应用场景数据可视化还有哪些类型安装步骤安装配置参数Elasticsearch配置参数注意事项 使用介绍 Kibana是一个开源的分析与可视化平台,设计出来用于和Elasticsearch一起使用的。可以用Kibana搜索、查看、交互存放在Elasticsearch索引里的数据&#…...
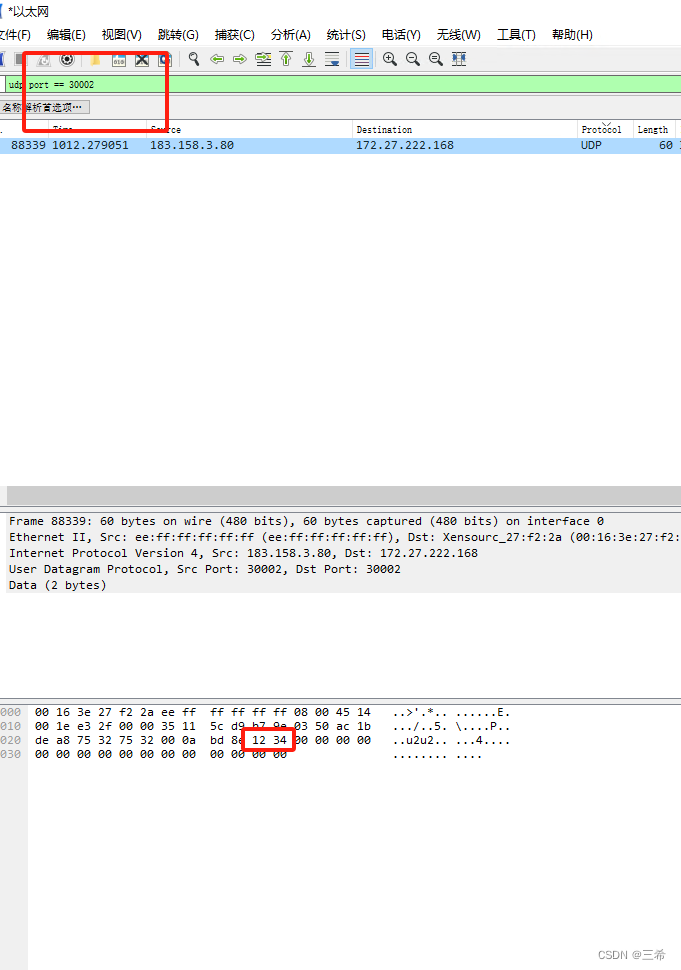
wvp如果确认音频udp端口开放成功
用到工具 在服务器上开启端口监听 选中udp server,点击创建按钮 设置服务器监听端口 在客户端连接服务器端口 选中udp客户端,点击创建 输入服务器地址 远程端口和本地端口,本地端口只要没被占用都可以使用 ,点击确认 发送数据 …...
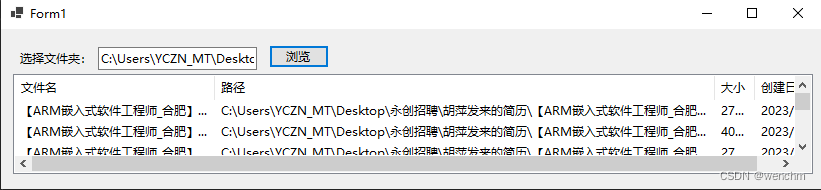
C#文件夹基本操作(判断文件夹是否存在、创建文件夹、移动文件夹、删除文件夹以及遍历文件夹中的文件)
目录 一、判断文件夹是否存在 1.Directory类的Exists()方法 2. DirectoryInfo类的Exists属性 二、创建文件夹 1. Directory类的CreateDirectory()方法 2.DirectoryInfo类的Create()方法 三、移动文件夹 1. Directory类的Move()方法 2.DirectoryInfo类的MoveT…...
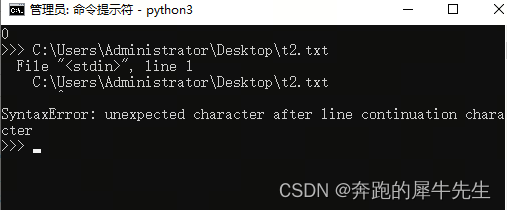
python 交互模式和命令行模式的问题
python 模式的冲突 unexpected character after line continuation character 理论上 ide里,输入 python 文件路径\文件.py 就可以执行 但是有时候却报错 unexpected character after line continuation character 出现上述错误的原因是没有退出解释器&#x…...
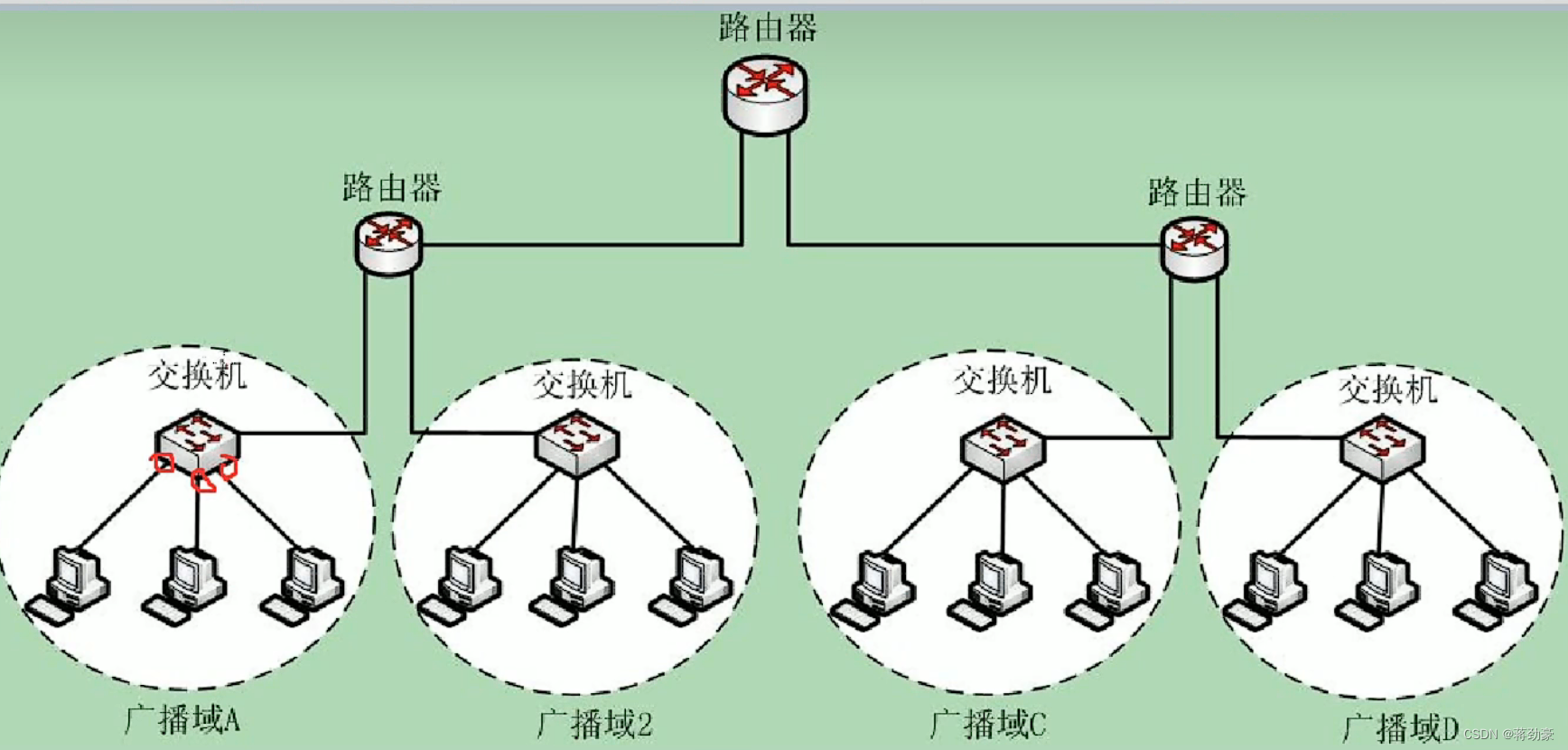
计算机网络——数据链路层
目录 一、数据链路层的基本概念 (一)数据链路层的概念 (二)帧 (三)数据链路层分为哪两个部分 (1)LLC(逻辑控制访问) (2)MAC&…...

【限时免费】20天拿下华为OD笔试之【哈希集合】2023B-明明的随机数【欧弟算法】全网注释最详细分类最全的华为OD真题题解
文章目录 题目描述与示例题目描述输入描述输出描述:示例 1输入输出说明 解题思路代码PythonJavaC时空复杂度 华为OD算法/大厂面试高频题算法练习冲刺训练 题目描述与示例 题目描述 明明生成了N 个 1 至 500 之间的随机整数。请你删去其中重复的数字,即…...
:视频帧处理并用SDL渲染播放)
播放器开发(五):视频帧处理并用SDL渲染播放
目录 学习课题:逐步构建开发播放器【QT5 FFmpeg6 SDL2】 步骤 VideoOutPut模块 1、初始化【分配缓存、读取信息】 2、开始线程工作【从队列读帧->缩放->发送渲染信号到窗口】 VideoWidget自定义Widget类 1、定义内部变量 2、如果使用SDL,需要进…...

Spring MVC数据绑定的几种方法(一)
这篇文章包含spring mvc的默认数据类型绑定和简单数据类型绑定。内容来自实验。 准备: (1)在IDEA环境中从archetye创建webapp类型的maven项目exp6。 (2)在src\main目录下创建并标注java源代码文件夹和resources资源文…...
)
CSP-坐标变换(其二)
问题描述 对于平面直角坐标系上的坐标 (x,y),小 P 定义了如下两种操作: 拉伸 k 倍:横坐标 x 变为 kx,纵坐标 y 变为 ky; 旋转 θ:将坐标 (x,y) 绕坐标原点 (0,0) 逆时针旋转 θ 弧度(0≤θ<…...

docker 安装jekins
echo Asia/Shanghai >/etc/timezone,容器中操作报错:docker容器中 Permission denied 使用该-u选项时,可以使用root用户(ID 0),而不是用默认用户登录docker容器 docker exec -u 0 -it f8a2b3d91455 /bin/bash 或者ÿ…...

ChatGPT 问世一周年之际,开源大模型能否迎头赶上?
就在11月30日,ChatGPT 迎来了它的问世一周年,这个来自 OpenAI 的强大AI在过去一年里取得了巨大的发展,迅速吸引各个领域的用户群体。 我们首先回忆一下 OpenAI和ChatGPT这一年的大事记(表格由ChatGPT辅助生成)&#x…...
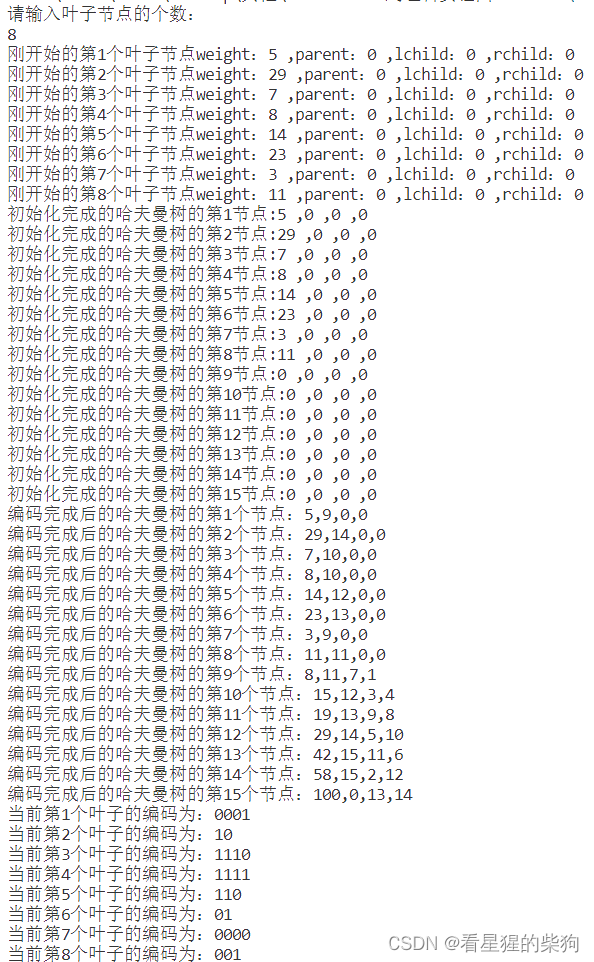
数据结构和算法-哈夫曼树以相关代码实现
文章目录 总览带权路径长度哈夫曼树的定义哈夫曼树的构造法1法2 哈夫曼编码英文字母频次总结实验内容: 哈夫曼树一、上机实验的问题和要求(需求分析):二、程序设计的基本思想,原理和算法描述:三、调试和运行…...

Kafka 的起源和背景
Apache Kafka 是一个分布式流处理平台,被广泛用于构建实时数据流应用程序和大数据处理系统。本文将深入探讨 Kafka 的起源、设计原则以及它在大数据领域中的重要作用。 大数据和实时数据处理背景 在大数据时代,处理海量数据和实时数据成为了一项关键挑…...
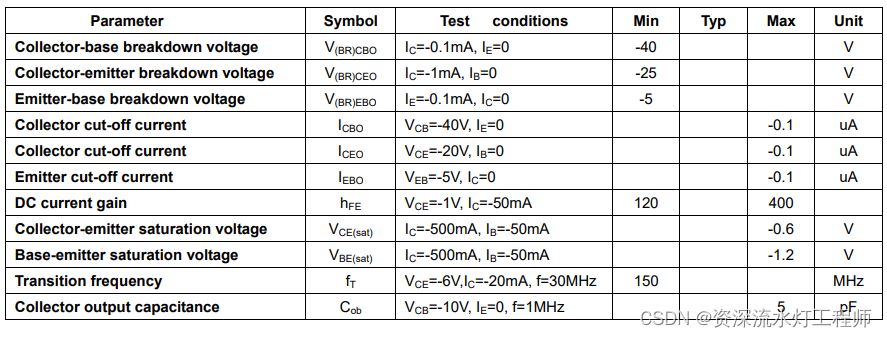
三极管在数字电路中的应用
一、认识三极管 三极管拥有3个引脚,分别对应3个级:基极(Base)、发射极(Emitter)、集电极(Collector),如下图所示;下图横向左侧的是基极,带箭头的那个引脚就是发射极,另一个就是集电…...
java后端自学错误总结
java后端自学错误总结 MessageSource国际化接口总结 MessageSource国际化接口 今天第一次使用MessageSource接口,比较意外遇到了一些坑 messageSource是spring中的转换消息接口,提供了国际化信息的能力。MessageSource用于解析 消息,并支持消息的参数化…...
CLion安装与配置教程
目录 一、下载并安装CLion1、下载1、官网:2、注意: 2、安装1、下载完成后,直接点击安装包安装,即可。2、开始安装,然后下一步3、可以在此处自定义地址,然后下一步4、根据系统版本选择,然后下一步…...

初识主力投资者
在股票市场中,真正赚钱的散户并不多。“七亏二平一赚”似乎已经成为了大家公认的一个股市定律。 为什么散户炒股赚的人少呢?原因很简单,就是因为市场上除了散户之外,还存在着一个重要的投资主体——主力。股市交易的过程ÿ…...

设备管理系统是什么?如何建立设备管理体系?
在现代企业的运转中,生产设备无疑是核心资产。无论是制造业的数控机床,还是建筑工地的重型机械,甚至是医疗机构的精密仪器,设备的稳定运行直接决定了企业的生产效率、产品质量和成本控制。然而,许多企业在设备管理上仍…...

告别重复造轮子:用快马AI一键生成openclaw项目高效串口调试工具
在机器人开发过程中,串口通信是最基础也最频繁使用的功能之一。无论是传感器数据采集、电机控制指令下发,还是与各种硬件模块的交互,都离不开串口通信的支持。然而每次新项目都要从头实现串口通信功能,不仅浪费时间,还…...

终极指南:如何用Captum快速理解PyTorch模型的决策逻辑
终极指南:如何用Captum快速理解PyTorch模型的决策逻辑 【免费下载链接】captum Model interpretability and understanding for PyTorch 项目地址: https://gitcode.com/gh_mirrors/ca/captum 在当今人工智能快速发展的时代,PyTorch已成为深度学习…...

揭秘Captum归因算法:5种NLP文本分类与情感分析的最佳实践
揭秘Captum归因算法:5种NLP文本分类与情感分析的最佳实践 【免费下载链接】captum Model interpretability and understanding for PyTorch 项目地址: https://gitcode.com/gh_mirrors/ca/captum 在当今人工智能快速发展的时代,模型可解释性已成为…...

掌握ModTheSpire:从入门到精通的开源模组加载工具实战指南
掌握ModTheSpire:从入门到精通的开源模组加载工具实战指南 【免费下载链接】ModTheSpire External mod loader for Slay The Spire 项目地址: https://gitcode.com/gh_mirrors/mo/ModTheSpire 认知铺垫:走进模组加载的技术世界 当你第一次尝试为…...

UDOP-large高性能部署:Tesseract OCR预处理与UDOP-large联合加速方案
UDOP-large高性能部署:Tesseract OCR预处理与UDOP-large联合加速方案 1. 引言:当文档理解遇上效率瓶颈 想象一下,你手头有几百份英文PDF报告需要处理。你需要从中提取标题、摘要,甚至表格里的关键数据。传统的方法是:…...
保姆级教程)
告别龟速下载!Win10/Win11下为CDO配置国内镜像源(Ubuntu 18.04 LTS)保姆级教程
告别龟速下载!Win10/Win11下为CDO配置国内镜像源(Ubuntu 18.04 LTS)保姆级教程 如果你曾在Windows系统下通过WSL安装Ubuntu并尝试下载CDO,大概率经历过每秒几KB的绝望下载速度。这不是你的网络问题——默认的国外软件源对国内用户…...

[特殊字符] GLM-4V-9B企业级方案:客户上传截图问题自动诊断
GLM-4V-9B企业级方案:客户上传截图问题自动诊断 1. 引言 想象一下这个场景:你是一家SaaS公司的技术支持工程师,每天的工作就是处理海量的客户工单。其中,有相当一部分问题描述是模糊的,比如“我的页面显示不正常”、…...

AI 模型推理 GPU 调度性能分析
AI模型推理GPU调度性能分析:解锁算力潜能的关键 随着AI技术的快速发展,深度学习模型的推理任务对计算资源的需求急剧增加。GPU因其并行计算能力成为模型推理的核心硬件,但如何高效调度GPU资源以提升性能,成为企业和研究机构关注的…...

Qwen3.5-9B Java面试宝典生成器:动态定制八股文与场景题
Qwen3.5-9B Java面试宝典生成器:动态定制八股文与场景题 1. 为什么需要智能面试助手 Java开发者求职路上,最头疼的莫过于海量面试题的整理和记忆。传统方式要么依赖网上零散的八股文合集,要么自己手动整理知识点,效率低下且难以…...