GPT4-Turbo技术原理研发现状及未来应用潜力分析报告
今天分享的是GPT4-Turb系列深度研究报告:《GPT4-Turbo技术原理研发现状及未来应用潜力分析报告》。
(报告出品方:深度行业分析研究)
报告共计:46页

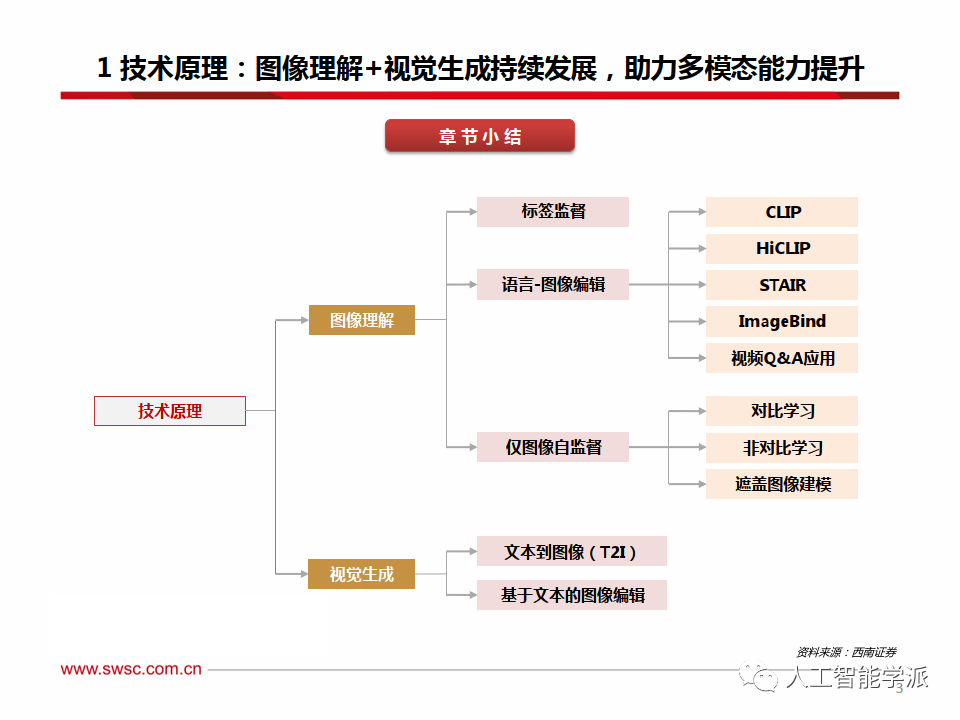
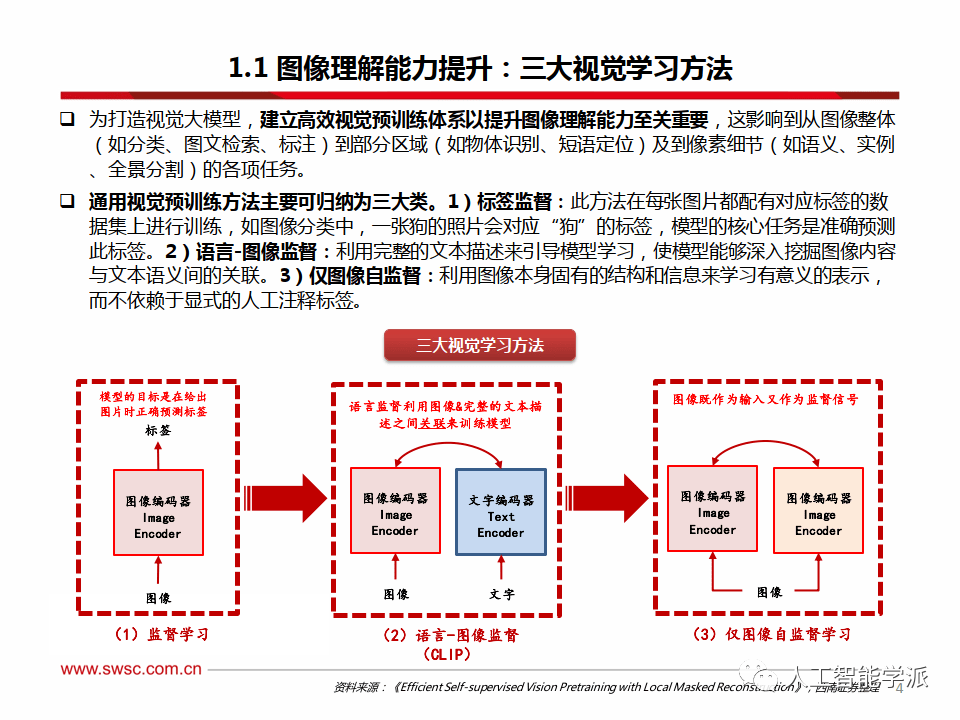
图像理解能力提升:三大视觉学习方法
为打造视觉大模型,建立高效视觉预训练体系以提升图像理解能力至关重要,这影响到从图像整体 (如分类、图文检索、标注)到部分区域(如物体识别、短语定位)及到像素细节(如语义、实例 、全景分割)的各项任务。
通用视觉预训练方法主要可归纳为三大类。
1)标签监督:此方法在每张图片都配有对应标签的数据集上进行训练,如图像分类中,一张狗的照片会对应“狗”的标签,模型的核心任务是准确预测此标签。
2)语言-图像监督:利用完整的文本描述来引导模型学习,使模型能够深入挖掘图像内容与文本语义间的关联。
3)仅图像自监督:利用图像本身固有的结构和信息来学习有意义的表示, 而不依赖于显式的人工注释标签。
图像理解能力提升:标签监督
监督式预训练已成为机器学习和计算机视 觉领域的核心技术。在这种策略中,模型首先在大规模标注数据集上进行预训练, 随后针对特定任务进行精细调整。这种方 法充分利用了如ImageNet这样的大型人工 标注数据集,为模型赋予了高度可迁移的 视觉特征。
其核心原理是将图像与预设的标签相对应 ,这些标签往往代表某一视觉物体。多年 来,这种策略在各类视觉基础架构,如 AlexNet、ResNet以及ViT的发展中都发挥 了不可或缺的作用。监督式预训练为计算 机视觉领域带来了革命性的进步,从基础 的图像分类和物体检测,到更为高级的视 觉问答和图像标注任务。受限于人工标注 的高成本,这些模型所学习到的特征会受 到预训练数据集的规模和多样性的制约。

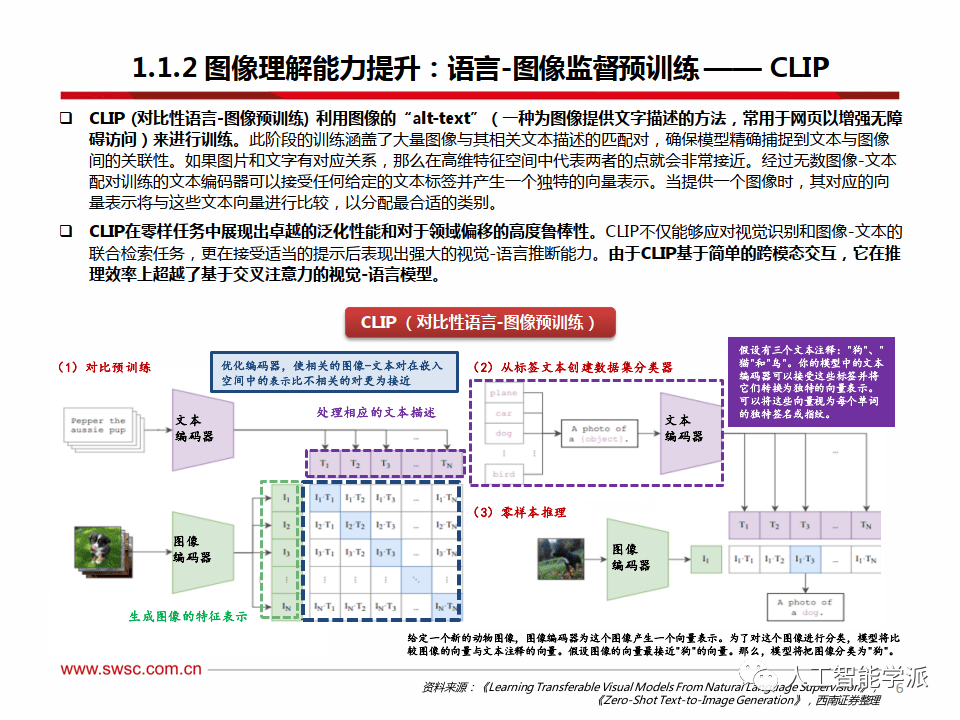
图像理解能力提升:语言-图像监督预训练—— CLIP
CLIP (对比性语言-图像预训练) 利用图像的“alt-text”(一种为图像提供文字描述的方法,常用于网页以增强无障 碍访问)来进行训练。此阶段的训练涵盖了大量图像与其相关文本描述的匹配对,确保模型精确捕捉到文本与图像间的关联性。如果图片和文字有对应关系,那么在高维特征空间中代表两者的点就会非常接近。经过无数图像-文本配对训练的文本编码器可以接受任何给定的文本标签并产生一个独特的向量表示。当提供一个图像时,其对应的向量表示将与这些文本向量进行比较,以分配最合适的类别。
CLIP在零样任务中展现出卓越的泛化性能和对于领域偏移的高度鲁棒性。CLIP不仅能够应对视觉识别和图像-文本的 联合检索任务,更在接受适当的提示后表现出强大的视觉-语言推断能力。由于CLIP基于简单的跨模态交互,它在推 理效率上超越了基于交叉注意力的视觉-语言模型。
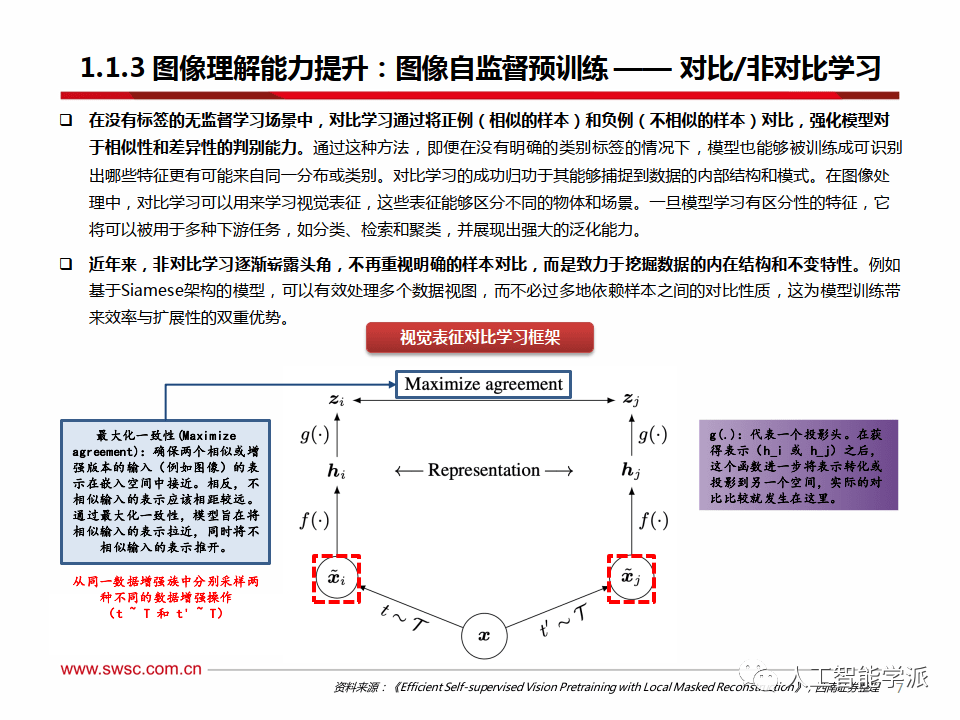
图像理解能力提升:图像自监督预训练 —— 对比/非对比学习
在没有标签的无监督学习场景中,对比学习通过将正例(相似的样本)和负例(不相似的样本)对比,强化模型对 于相似性和差异性的判别能力。通过这种方法,即便在没有明确的类别标签的情况下,模型也能够被训练成可识别 出哪些特征更有可能来自同一分布或类别。对比学习的成功归功于其能够捕捉到数据的内部结构和模式。在图像处 理中,对比学习可以用来学习视觉表征,这些表征能够区分不同的物体和场景。一旦模型学习有区分性的特征,它 将可以被用于多种下游任务,如分类、检索和聚类,并展现出强大的泛化能力。
近年来,非对比学习逐渐崭露头角,不再重视明确的样本对比,而是致力于挖掘数据的内在结构和不变特性。例如基于Siamese架构的模型,可以有效处理多个数据视图,而不必过多地依赖样本之间的对比性质,这为模型训练带 来效率与扩展性的双重优势。
视觉生成:多模态内容理解和生成的闭环
在多模态大型模型的发展过程中,视觉生成技术是整合 视觉内容与文本信息的关键手段。拥有理解和生成视觉 内容的能力使模型能够参与到更深层次和细致的任务中 ,如图像标注、视觉叙事以及复杂的设计任务。由于人 类的理解和沟通本质上是多模态的,通过整合视觉生成 功能,模型能够以更接近人类认知的方式处理和生成信 息。此外,多模态融合也为虚拟现实、增强现实以及交 互式数字平台等领域奠定基础,未来将实现更为自然、 无缝且高效的用户界面。
“人类行为对齐”旨在融合人类的认知过程和AI驱动的 视觉内容生成。传统视觉生成模型仅依赖数据,导致输 出内容往往缺乏人类的逻辑思维和行动模式。例如,在 生成‘繁忙的街道’图像时,传统模型只机械地排列车 辆、行人和商店,无法捕捉人类对‘繁忙’的深刻理解, 例如行人的匆忙步伐、车辆的密集流动和商店的热闹场 景。而通过引入人类行为对齐,模型可确保生成的视觉 内容不仅准确,更与人类的感知和期望相符合,推动模 型向更以用户为中心的方向转变,使系统在‘思考’和 ‘感知’方面更符合人类需求。在遵循人类意图合成所 需视觉内容的图像生成模型方面,主要涉及四个方向:
1)空间可控的T2I生成;
2)基于文本的图像编辑;
3) 更好地遵循文本提示;
4)在T2I生成中实现物体定制化。

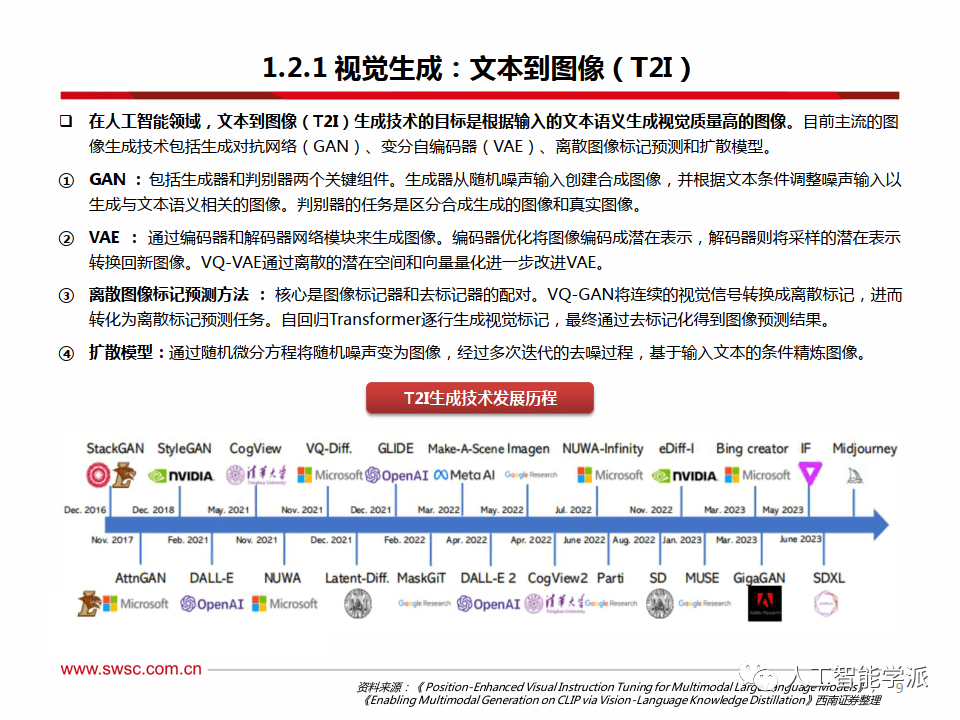
视觉生成:文本到图像(T2I)
在人工智能领域,文本到图像(T2I)生成技术的目标是根据输入的文本语义生成视觉质量高的图像。目前主流的图像生成技术包括生成对抗网络(GAN)、变分自编码器(VAE)、离散图像标记预测和扩散模型。
① GAN : 包括生成器和判别器两个关键组件。生成器从随机噪声输入创建合成图像,并根据文本条件调整噪声输入以生成与文本语义相关的图像。判别器的任务是区分合成生成的图像和真实图像。
② VAE : 通过编码器和解码器网络模块来生成图像。编码器优化将图像编码成潜在表示,解码器则将采样的潜在表示转换回新图像。VQ-VAE通过离散的潜在空间和向量量化进一步改进VAE。
③ 离散图像标记预测方法 : 核心是图像标记器和去标记器的配对。VQ-GAN将连续的视觉信号转换成离散标记,进转化为离散标记预测任务。自回归Transformer逐行生成视觉标记,最终通过去标记化得到图像预测结果。
④ 扩散模型:通过随机微分方程将随机噪声变为图像,经过多次迭代的去噪过程,基于输入文本的条件精炼图像。
视觉生成:基于文本的图像编辑
基于文本的图像编辑技术依赖于已有的图片和文本描述来合成新图像。其核心目的是维持图像的主体视觉内容,对 特定区域进行微调,如局部物体的调整或全局的风格改变,以更准确地满足用户的意图。
基于文本的编辑领域有3种主流功能。
1) 针对图像的特定区域进行修改:如物体的增减或属性更改。用户所提供的 区域蒙版与图像生成中的空间潜在变量操作结合。
2) 针对图像的特定区域进行修改2.0:用户简单描述所需区域外 观,即可作为明确的编辑指示,例如指导“将图像中的A物体替换为B物体”。
3) 专业模块融合:相较于单一T2I模 型的编辑扩展,某些编辑系统已开始融合多种专业模块,包括图像分割模型和大型语言处理模型。


GPT-4 Turbo:文本理解能力再次提升,知识储备迅速更新
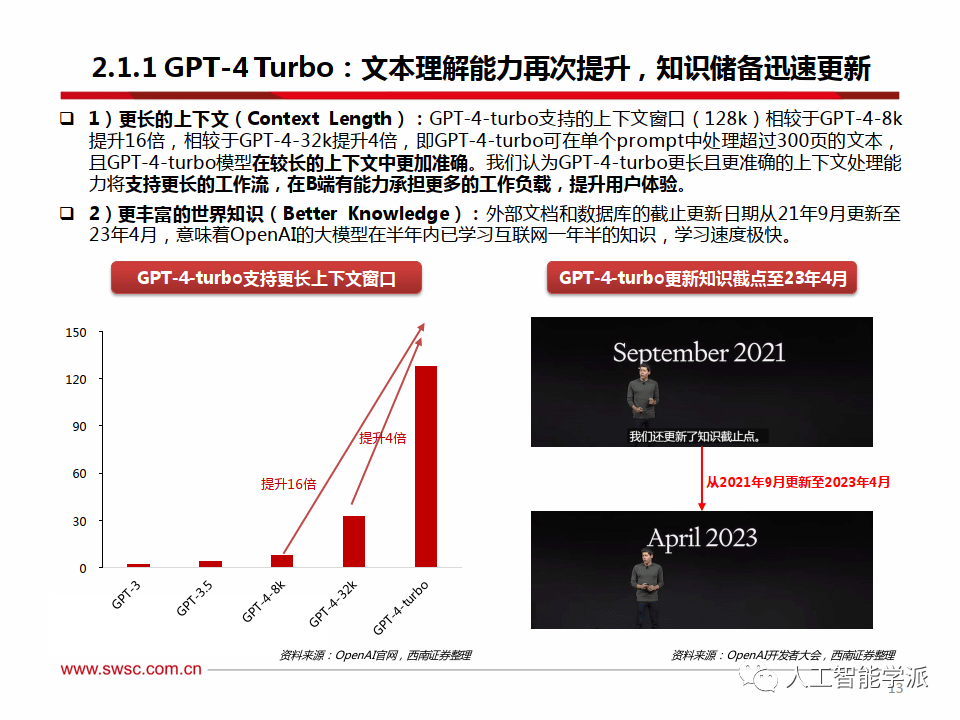
1)更长的上下文(Context Length):GPT-4-turbo支持的上下文窗口(128k)相较于GPT-4-8k 提升16倍,相较于GPT-4-32k提升4倍,即GPT-4-turbo可在单个prompt中处理超过300页的文本, 且GPT-4-turbo模型在较长的上下文中更加准确。我们认为GPT-4-turbo更长且更准确的上下文处理能 力将支持更长的工作流,在B端有能力承担更多的工作负载,提升用户体验。
2)更丰富的世界知识(Better Knowledge):外部文档和数据库的截止更新日期从21年9月更新至 23年4月,意味着OpenAI的大模型在半年内已学习互联网一年半的知识,学习速度极快。

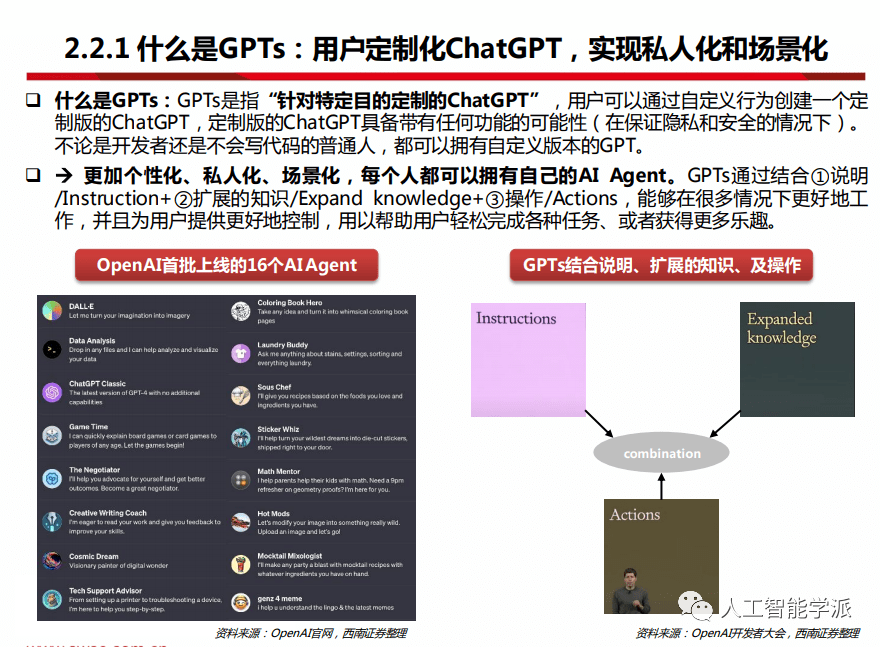
什么是GPTs:用户定制化ChatGPT,实现私人化和场景化
什么是GPTs:GPTs是指“针对特定目的定制的ChatGPT”,用户可以通过自定义行为创建一个定 制版的ChatGPT,定制版的ChatGPT具备带有任何功能的可能性(在保证隐私和安全的情况下)。 不论是开发者还是不会写代码的普通人,都可以拥有自定义版本的GPT。
更加个性化、私人化、场景化,每个人都可以拥有自己的AI Agent。GPTs通过结合①说明 /Instruction+②扩展的知识/Expand knowledge+③操作/Actions,能够在很多情况下更好地工 作,并且为用户提供更好地控制,用以帮助用户轻松完成各种任务、或者获得更多乐趣。
Assistant API:解决API开发者痛点,拓展OpenAI收入来源
针对开发者在开发API中的痛点,OpenAI推出Assistant API,致力于为开发者赋能。根据此前市 场上推出的各种API,我们可以发现API通过接入各种程序和应用,有助于帮助应用实现特定功能。 例如,Shopify的Sidekick允许用户在平台上进行操作;Discord的Clyde允许discord版主设置自定义人格;Snap my AI作为定制聊天机器人工具,可以添加至群聊中并提出建议。但以上API的构建 可能需要开发者耗费几个月的时间、并由数十名工程师搭建,而目前Assistant API的推出将使其变 得容易实现。
定价:除常规的tokens计费外,部分组件还需收取额外费用。其中,代码解释器/Code interpreter定价为单次0.003美元;检索/Retrieval定价为0.20美元/GB/助理/天。

Assistant API-函数调用
1)函数调用/Function calling:在一次API调用/call中,用户可以描述函数/functions,让模型 输出JSON对象来调用一个或多个函数。GPT-4-turbo经过训练,既可以检测何时应该调用函数 (取决于输入),也可以保证JSON输出不会有延迟。
→减轻开发者调用函数工作,助力AI赋能UI:该集成允许开发者通过自然语言就能与各种应用程序 的组件和功能进行流畅的交互,实现AI与UI的更好融合。与此同时,开发者可以将自身更多的精力放在想法的创新,无需自己分析并调用函数,将脏活累活交给助手。

相关文章:
GPT4-Turbo技术原理研发现状及未来应用潜力分析报告
今天分享的是GPT4-Turb系列深度研究报告:《GPT4-Turbo技术原理研发现状及未来应用潜力分析报告》。 (报告出品方:深度行业分析研究) 报告共计:46页 图像理解能力提升:三大视觉学习方法 为打造视觉大模…...
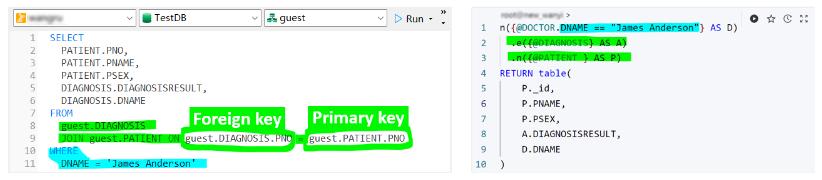
为什么 SQL 不适合图数据库
背景 “为什么你们的图形产品不支持 SQL 或类似 SQL 的查询语言?” 过去,我们的一些客户经常问这个问题,但随着时间的推移,这个问题变得越来越少。 尽管一度被忽视,但图数据库拥有无缝设计并适应其底层数据结构的查询…...
【Rust日报】2023-12-02 深度学习框架 Burn 发布 v0.11.0
深度学习框架 Burn 发布 v0.11.0 深度学习框架 Burn 发布 v0.11.0,新版本引入了自动内核融合(Kernel Fusion)功能,大大提升了访存密集型(memory-bound)操作的性能。同时宣布成立 Tracel AI (https://tracel…...

MySQL性能调优-1-实际优化案例
关于SQL优化的思路,一般都是使用执行计划看看是否用到了索引,主要可能有两大类情况: 对业务字段建立了二级联合索引,但是MySQL错误地觉得走主键聚族索引全表扫描效率更高,而没有走二级索引 走二级索引,但…...

JavaScript空值合并运算符
The Nullish Coalescing Operator(空值合并运算符)是一种 JavaScript 的新运算符,用于解决默认值设定中存在的一些问题。它的语法为 ??(两个问号),表示当左侧的操作数为 null 或 undefined 时,…...

Spring Boot 集成 spring security 01
一、导入依赖(pom.xml) <?xml version"1.0" encoding"UTF-8"?> <project xmlns"http://maven.apache.org/POM/4.0.0" xmlns:xsi"http://www.w3.org/2001/XMLSchema-instance"xsi:schemaLocation&qu…...

C 编程中使用字符串
理解字符串: C 中的字符串是使用字符数组来操作的。数组中的每个字符对应字符串的一个元素,字符串的结尾由空字符(\0)标记。这个空字符至关重要,因为它表示字符串的结尾,并允许函数确定字符串在内存中的结…...

【GD32307E-START】04 使用TinyMaix进行手写数字识别
【GD32307E-START】04 使用TinyMaix进行手写数字识别 参考博客 【GD32F427开发板试用】使用TinyMaix进行手写数字识别 https://blog.csdn.net/weixin_47569031/article/details/129009839 软硬件平台 GD32F307E-START Board开发板GCC Makefile TinyMaix简介 TinyMaix是国…...
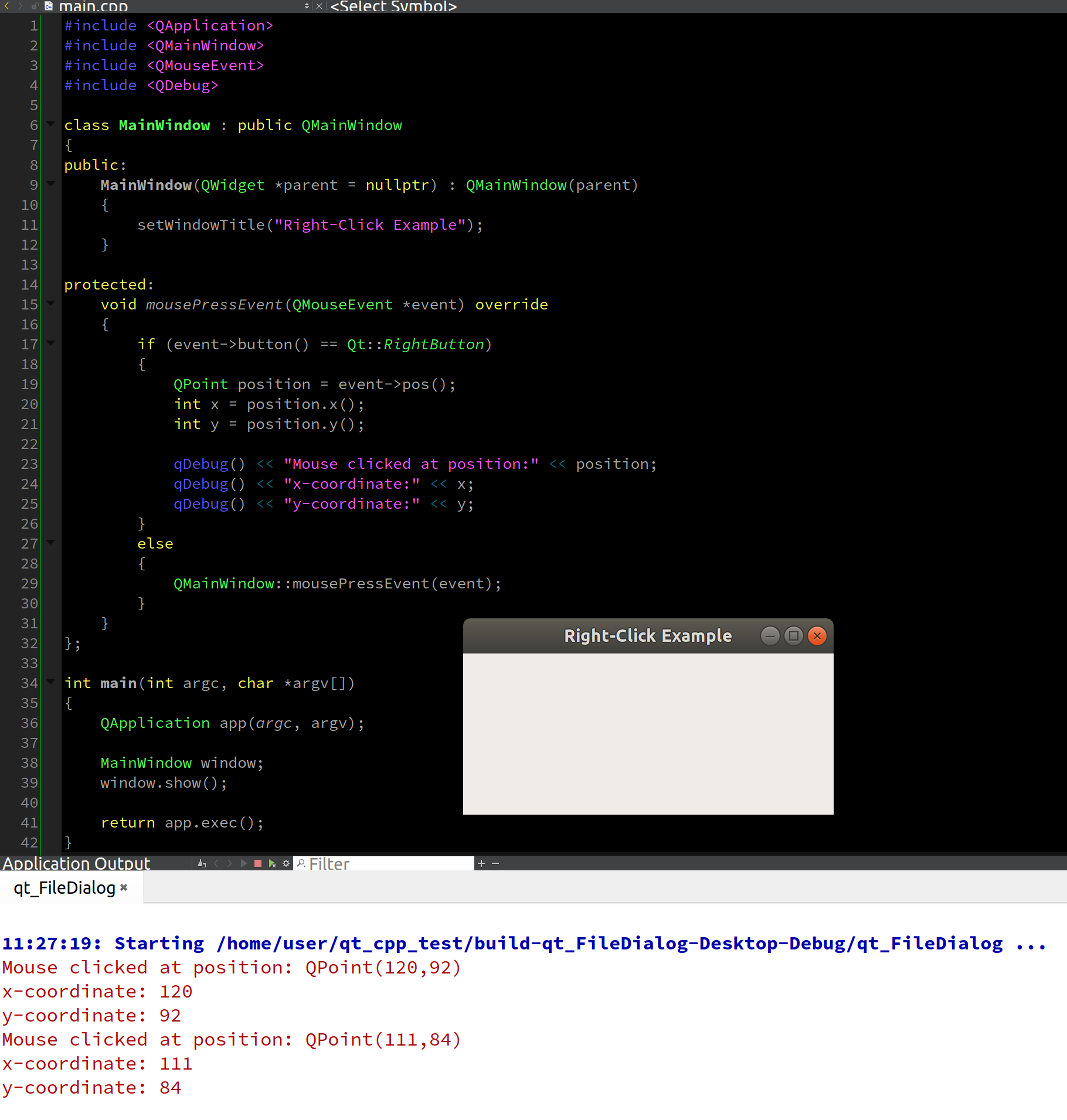
qt-C++笔记之识别点击鼠标右键、点击位置以及Qt坐标系详解
qt-C笔记之识别点击鼠标右键、点击位置以及Qt坐标系详解 code review! 文章目录 qt-C笔记之识别点击鼠标右键、点击位置以及Qt坐标系详解1.示例运行2.event->pos();详解3.event->pos()的坐标系原点4.Qt中的坐标系详解5.QMainWindow::mousePressEvent(event);详解 1.示例…...

小程序开发平台源码系统:搭建新的商业体系 附带完整的搭建教程
小程序开发平台源码系统是在移动互联网快速发展的背景下诞生的。随着微信小程序的普及,越来越多的人开始关注小程序的开发与运营。然而,对于很多初学者和小型企业来说,开发一个小程序需要专业的技术知识和大量的时间投入,这无疑是…...

css3新增的伪类有哪些?
CSS3新增的伪类有: :first-of-type,选择属于其父元素的特定类型的第一个子元素。:last-of-type,选择属于其父元素的特定类型的最后一个子元素。:only-of-type,选择属于其父元素的特定类型的唯一子元素。:only-child,选…...
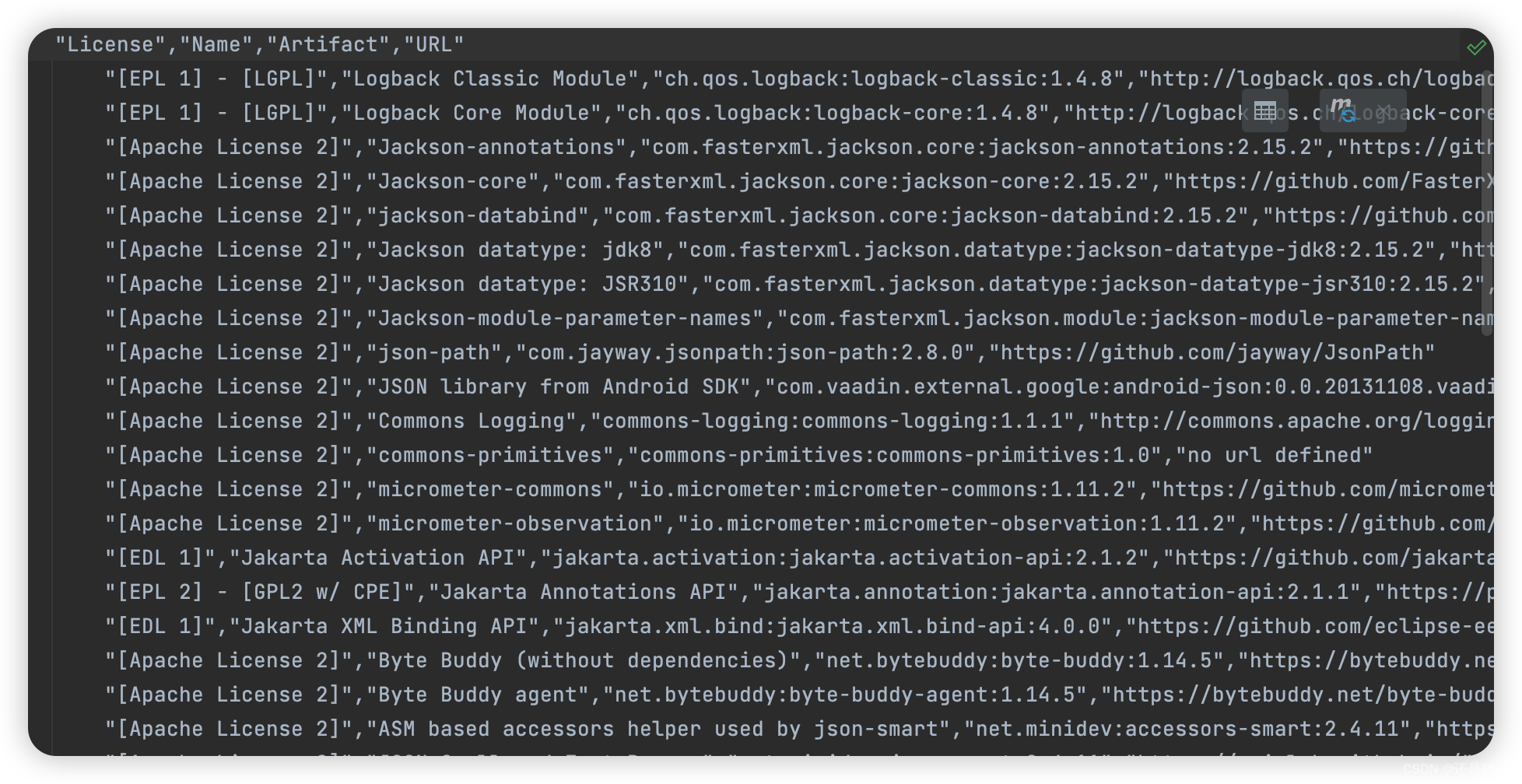
开源软件license介绍与检测
开源License介绍 通俗来讲,开源许可证就是一种允许软件使用者在一定条件内按照需要自由使用和修改软件及其源代码的的法律条款。借此条款,软件作者可以将这些权利许可给使用者,并告知使用限制。这些许可条款可以由个人、商业公司或非赢利组织…...

【LeeCode】142.环形链表II
给定一个链表的头节点 head ,返回链表开始入环的第一个节点。 如果链表无环,则返回 null。 如果链表中有某个节点,可以通过连续跟踪 next 指针再次到达,则链表中存在环。 为了表示给定链表中的环,评测系统内部使用整数…...

nodejs微信小程序+python+PHP健身房信息管理系统的设计与实现-计算机毕业设计推荐
目 录 摘 要 I ABSTRACT II 目 录 II 第1章 绪论 1 1.1背景及意义 1 1.2 国内外研究概况 1 1.3 研究的内容 1 第2章 相关技术 3 2.1 nodejs简介 4 2.2 express框架介绍 6 2.4 MySQL数据库 4 第3章 系统分析 5 3.1 需求分析 5 3.2 系统可行性分析 5 3.2.1技术可行性:…...

springboot集成springsecurity
转载自:www.javaman.cn 1、整合springsecurity 添加pom.xml <dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-security</artifactId> </dependency>2、springsecurity认证授权流程…...

脏读、不可重复读、幻读
一、脏读 A事务读取B事务尚未提交的数据,此时如果B事务发生错误并执行回滚操作,那么A事务读取到的数据就是脏数据。就好像原本的数据比较干净、纯粹,此时由于B事务更改了它,这个数据变得不再纯粹。这个时候A事务立即读取了这个脏…...
思维模型 反馈效应
本系列文章 主要是 分享 思维模型,涉及各个领域,重在提升认知。反馈促进改进。 1 反馈效应的应用 1.1 反馈效应在营销中的应用 1 “可口可乐与百事可乐之战” 在 20 世纪 80 年代,可口可乐公司是全球最大的饮料公司之一,其市场…...

【PyTorch】线性回归
文章目录 1. 模型与代码实现2. Q&A 1. 模型与代码实现 模型 y ^ w 1 x 1 . . . w d x d b w ⊤ x b . \hat{y} w_1 x_1 ... w_d x_d b \mathbf{w}^\top \mathbf{x} b. y^w1x1...wdxdbw⊤xb. 代码实现 import torch from torch import nn from to…...

硝烟弥漫的科技战场——GPT之战
没想到2023年的双11之后,还能看到如此多的科技圈大佬针对GPT提出火药味十足的讨论和极具戏剧性的表演。 历史回顾: 11月6日,OpenAI发布会:GPT-4 Turbo模型、GPT应用商店、开源Whisper-large-v3等;11月17日࿰…...

re:Invent 构建未来:云计算生成式 AI 诞生科技新局面
文章目录 前言什么是云计算云计算类型亚马逊云科技云计算最多的功能最大的客户和合作伙伴社区最安全最快的创新速度最成熟的运营专业能力 什么是生成式 AI如何使用生成式 AI后记 前言 在科技发展的滚滚浪潮中,我们见证了云计算的崛起和生成式 AI 的突破,…...

语音克隆从入门到商用变现,手把手教你在TikTok/播客/AI助手部署高保真克隆声,今天就能上线
更多请点击: https://kaifayun.com 第一章:语音克隆技术演进与ElevenLabs核心能力解析 语音克隆技术已从早期基于拼接的单元选择(Unit Selection)和统计参数合成(HMM-based TTS),跨越深度学习驱…...

企业内如何通过Taotoken实现大模型API的统一管理与审计
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 企业内如何通过Taotoken实现大模型API的统一管理与审计 对于需要将大模型能力集成到内部系统的企业而言,直接让各个团队…...

MDX-M3-Viewer深度解析:浏览器端游戏模型渲染的全新范式
MDX-M3-Viewer深度解析:浏览器端游戏模型渲染的全新范式 【免费下载链接】mdx-m3-viewer A WebGL viewer for MDX and M3 files used by the games Warcraft 3 and Starcraft 2 respectively. 项目地址: https://gitcode.com/gh_mirrors/md/mdx-m3-viewer 在…...

基于开源项目构建实时语音AI对话系统:从ASR、LLM到TTS的完整技术栈解析
1. 项目概述与核心价值 最近在折腾一个挺有意思的东西,一个叫 bigsk1/voice-chat-ai 的开源项目。简单来说,它让你能和一个AI进行实时的语音对话,就像打电话一样。你对着麦克风说话,AI不仅能听懂,还能思考࿰…...

GIT 切换分支合并分支前一定要先 fetch,一定要选择远程分支进行操作
测试 GIT 切换分支 合并分支 1、切换和合并分支时,要选择远程的分支,确保本地的代码是最新的 2、切换分支前不 fetch3、切换分支前先点 fetch4、合并分支前不 fetch5、合并分支前先 fetch...

如何在Windows上快速配置词法语法分析器:WinFlexBison完整实战指南
如何在Windows上快速配置词法语法分析器:WinFlexBison完整实战指南 【免费下载链接】winflexbison Main winflexbision repository 项目地址: https://gitcode.com/gh_mirrors/wi/winflexbison 你是否在Windows平台上开发编译器、解释器或配置文件解析器时&a…...

Windows用户的救星:APK Installer让你在电脑上轻松运行Android应用
Windows用户的救星:APK Installer让你在电脑上轻松运行Android应用 【免费下载链接】APK-Installer An Android Application Installer for Windows 项目地址: https://gitcode.com/GitHub_Trending/ap/APK-Installer 你是否曾经想在Windows电脑上体验Androi…...

组织空心化,一个被严重忽略的问题
上一篇文章我提了一个概念:管理工具空心化。干部能力起不来,你上再好的系统、再牛的流程,最后全都变成填表运动。 我相信对很多人都会有共鸣。 这说明什么?空心化不是个别现象,是多数组织的慢性病。 今天往深处再撕…...

Touchpoint:命令行工具集中管理工作上下文,提升开发效率
1. 项目概述:一个被低估的开发者效率工具如果你和我一样,日常开发工作需要在多个代码仓库、项目管理工具(如Jira、Linear)、文档平台(如Confluence、Notion)和沟通软件(如Slack)之间…...

深度解析:Performance-Fish如何通过四级缓存架构实现《环世界》400%性能优化
深度解析:Performance-Fish如何通过四级缓存架构实现《环世界》400%性能优化 【免费下载链接】Performance-Fish Performance Mod for RimWorld 项目地址: https://gitcode.com/gh_mirrors/pe/Performance-Fish Performance-Fish是《环世界》(Rim…...