从零构建属于自己的GPT系列3:模型训练2(训练函数解读、模型训练函数解读、代码逐行解读)
🚩🚩🚩Hugging Face 实战系列 总目录
有任何问题欢迎在下面留言
本篇文章的代码运行界面均在PyCharm中进行
本篇文章配套的代码资源已经上传
从零构建属于自己的GPT系列1:文本数据预处理
从零构建属于自己的GPT系列2:语言模型训练
3 数据加载函数
def load_dataset(logger, args):"""加载训练集"""logger.info("loading training dataset")train_path = args.train_pathwith open(train_path, "rb") as f:train_list = pickle.load(f)# test# train_list = train_list[:24]train_dataset = CPMDataset(train_list, args.max_len)return train_dataset
- List item
4 训练函数
def train(model, logger, train_dataset, args):train_dataloader = DataLoader(train_dataset, batch_size=args.batch_size, shuffle=True, num_workers=args.num_workers, collate_fn=collate_fn,drop_last=True)logger.info("total_steps:{}".format(len(train_dataloader)* args.epochs))t_total = len(train_dataloader) // args.gradient_accumulation_steps * args.epochsoptimizer = transformers.AdamW(model.parameters(), lr=args.lr, eps=args.eps)scheduler = transformers.get_linear_schedule_with_warmup(optimizer, num_warmup_steps=args.warmup_steps, num_training_steps=t_total)# 设置warmuplogger.info('start training')train_losses = [] # 记录每个epoch的平均loss# ========== start training ========== #for epoch in range(args.epochs):train_loss = train_epoch(model=model, train_dataloader=train_dataloader,optimizer=optimizer, scheduler=scheduler,logger=logger, epoch=epoch, args=args)train_losses.append(round(train_loss, 4))logger.info("train loss list:{}".format(train_losses))logger.info('training finished')logger.info("train_losses:{}".format(train_losses))
5 迭代训练函数
def train_epoch(model, train_dataloader, optimizer, scheduler, logger,epoch, args):model.train()device = args.deviceignore_index = args.ignore_indexepoch_start_time = datetime.now()total_loss = 0 # 记录下整个epoch的loss的总和epoch_correct_num = 0 # 每个epoch中,预测正确的word的数量epoch_total_num = 0 # 每个epoch中,预测的word的总数量for batch_idx, (input_ids, labels) in enumerate(train_dataloader):# 捕获cuda out of memory exceptiontry:input_ids = input_ids.to(device)labels = labels.to(device)outputs = model.forward(input_ids, labels=labels)logits = outputs.logitsloss = outputs.lossloss = loss.mean()# 统计该batch的预测token的正确数与总数batch_correct_num, batch_total_num = calculate_acc(logits, labels, ignore_index=ignore_index)# 统计该epoch的预测token的正确数与总数epoch_correct_num += batch_correct_numepoch_total_num += batch_total_num# 计算该batch的accuracybatch_acc = batch_correct_num / batch_total_numtotal_loss += loss.item()if args.gradient_accumulation_steps > 1:loss = loss / args.gradient_accumulation_stepsloss.backward()# 梯度裁剪torch.nn.utils.clip_grad_norm_(model.parameters(), args.max_grad_norm)# 进行一定step的梯度累计之后,更新参数if (batch_idx + 1) % args.gradient_accumulation_steps == 0:# 更新参数optimizer.step()# 更新学习率scheduler.step()# 清空梯度信息optimizer.zero_grad()if (batch_idx + 1) % args.log_step == 0:logger.info("batch {} of epoch {}, loss {}, batch_acc {}, lr {}".format(batch_idx + 1, epoch + 1, loss.item() * args.gradient_accumulation_steps, batch_acc, scheduler.get_lr()))del input_ids, outputsexcept RuntimeError as exception:if "out of memory" in str(exception):logger.info("WARNING: ran out of memory")if hasattr(torch.cuda, 'empty_cache'):torch.cuda.empty_cache()else:logger.info(str(exception))raise exception# 记录当前epoch的平均loss与accuracyepoch_mean_loss = total_loss / len(train_dataloader)epoch_mean_acc = epoch_correct_num / epoch_total_numlogger.info("epoch {}: loss {}, predict_acc {}".format(epoch + 1, epoch_mean_loss, epoch_mean_acc))# save modellogger.info('saving model for epoch {}'.format(epoch + 1))model_path = join(args.save_model_path, 'epoch{}'.format(epoch + 1))if not os.path.exists(model_path):os.mkdir(model_path)model_to_save = model.module if hasattr(model, 'module') else modelmodel_to_save.save_pretrained(model_path)logger.info('epoch {} finished'.format(epoch + 1))epoch_finish_time = datetime.now()logger.info('time for one epoch: {}'.format(epoch_finish_time - epoch_start_time))return epoch_mean_loss
从零构建属于自己的GPT系列1:文本数据预处理
从零构建属于自己的GPT系列2:语言模型训练
相关文章:
)
从零构建属于自己的GPT系列3:模型训练2(训练函数解读、模型训练函数解读、代码逐行解读)
🚩🚩🚩Hugging Face 实战系列 总目录 有任何问题欢迎在下面留言 本篇文章的代码运行界面均在PyCharm中进行 本篇文章配套的代码资源已经上传 从零构建属于自己的GPT系列1:文本数据预处理 从零构建属于自己的GPT系列2:语…...
)
Python词频统计(数据整理)
请编写程序,对一段英文文本,统计其中所有不同单词的个数,以及词频最大的前10%的单词。 输入格式: 输入给出一段非空文本,最后以符号#结尾。输入保证存在至少10个不同的单词。 输出格式: 在第一行中输出文本中所有不同单词的个数…...

基本面选股的方法
基本面选股是一种投资策略,主要关注公司的财务状况、盈利能力、行业地位等因素,以判断公司的价值并做出投资决策。以下是基本面选股的具体分析方法和重点: 财务状况分析: 利润表分析:关注公司的净利润、毛利率、营业…...
应用密码学期末复习(3)
目录 第三章 现代密码学应用案例 3.1安全电子邮件方案 3.1.1 PGP产生的背景 3.2 PGP提供了一个安全电子邮件解决方案 3.2.1 PGP加密流程 3.2.2 PGP解密流程 3.2.3 PGP整合了对称加密和公钥加密的方案 3.3 PGP数字签名和Hash函数 3.4 公钥分发与认证——去中心化模型 …...

PAD平板签约投屏-高端活动的选择
传统的现场纸质签约仪式除了缺乏仪式感之外还缺少互动性,如果要将签约的过程投放到大屏幕上更是需要额外的硬件设备成本。相比于传统的纸质签约仪式,平板现场电子签约的形式更加的新颖、更富有科技感、更具有仪式感。 平板签约投屏是应用于会议签字仪式的…...
分布式架构demo
1、外层创建pom 版本管理器 <parent><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-parent</artifactId><version>2.7.15</version><relativePath/> <!-- lookup parent from repository…...
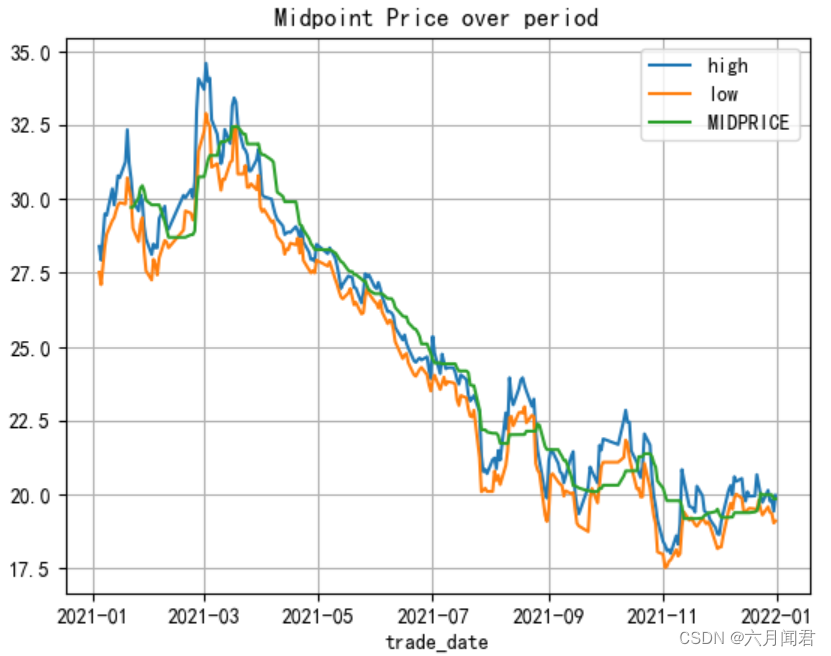
TA-Lib学习研究笔记(二)——Overlap Studies上
TA-Lib学习研究笔记(二)——Overlap Studies 1. Overlap Studies 指标 [BBANDS, DEMA, EMA, HT_TRENDLINE, KAMA, MA, MAMA, MAVP, MIDPOINT, MIDPRICE, SAR, SAREXT, SMA, T3, TEMA, TRIMA, WMA]2.数据准备 get_data函数参数(代码&#x…...

牛客java基础考点1 标识符和变量
牛客java基础考点1 标识符和变量 标识符 字母和数字: 标识符由字母、数字、下划线(_)和美元符号($)组成。其中,标识符必须以字母、下划线或美元符号开头。大小写敏感: Java 是大小写敏感的语言…...
Qt将打印信息输出到文件
将打印信息(qDebug、qInfo、qWarning、qCritial等)输出到指定文件来以实现简单的日志功能。 #include "mainwindow.h" #include <QApplication> #include <QLoggingCategory> #include <QMutex> #include <QDateTime>…...
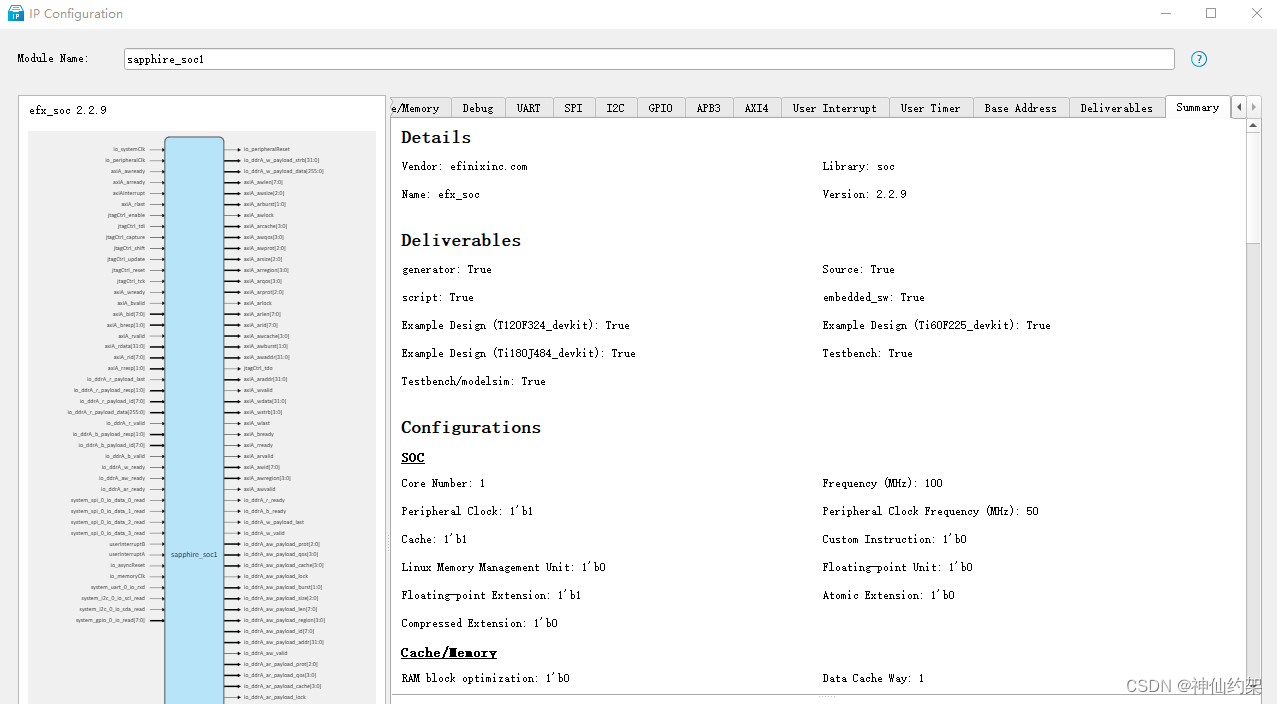
【risc-v】易灵思efinix FPGA sapphire_soc IP配置参数分享
系列文章目录 分享一些fpga内使用riscv软核的经验,共大家参考。后续内容比较多,会做成一个系列。 本系列会覆盖以下FPGA厂商 易灵思 efinix 赛灵思 xilinx 阿尔特拉 Altera 本文内容隶属于【易灵思efinix】系列。 前言 在efinix fpga中使用riscv是一…...

直播的种类及类型
随着网络技术和移动设备的普及,直播已经成为人们娱乐、学习、商业交流等众多领域的重要工具。 直播的种类主要有以下几种: 1.视频直播:这是最常见的直播形式,包括电商直播、婚庆直播、培训直播、家居直播等。 2.图文直播:这种直播形式包括PPT互动直播…...

时间序列数据压缩算法简述
本文简单介绍了时间序列压缩任务的来源,压缩算法的分类,并对常见压缩算法的优缺点进行了简介,爱码士们快来一探究竟呀! 引言 时间序列数据是在许多应用程序和领域中生成的一种基本数据类型,例如金融、医疗保健、交通和…...

智能锁-SI522TORC522方案资料
南京中科微这款SI522目前完全PinTOPin兼容的NXP:RC522、CV520 复旦微:FM17520、FM17522/FM17550 瑞盟:MS520、MS522 国民技术:NZ3801、NZ3802 SI522 是应用于13.56MHz 非接触式通信中高集成度读写卡系列芯片中的一员。是NXP 公司针对&quo…...
 -RTK简单使用)
redux(4) -RTK简单使用
简单使用 1、下载 npm i reduxjs/toolkit react-redux 2、创建 1、在redux/user.js中创建模块user。从reduxjs/toolkit中引入createSlice创建模块片段,我们需要传入name、初始数据initialState、改state的reducers等。最后需要导出reducer和action。 代码如下&a…...

开源运维监控系统-Nightingale(夜莺)应用实践(未完)
一、前言 某业务系统因OS改造,原先的Zabbix监控系统推倒后未重建,本来计划用外部企业内其他监控系统接入,后又通知需要自建才能对接,考虑之前zabbix的一些不便,本次计划采用一个类Prometheus的监控系统,镜调研后发现Nightingale兼容Prometheus,又有一些其他功能增强,又…...

深入理解GMP模型
1、GMP模型的设计思想 1)、GMP模型 GMP分别代表: G:goroutine,Go协程,是参与调度与执行的最小单位M:machine,系统级线程P:processor,包含了运行goroutine的资源&#…...

数学建模-基于集成学习的共享单车异常检测的研究
基于集成学习的共享单车异常检测的研究 整体求解过程概述(摘要) 近年来,共享单车的快速发展在方便了人们出行的同时,也对城市交通产生了一定的负面影响,其主要原因为单车资源配置的不合理。本文通过建立单车租赁数量的预测模型和异常检测模型…...

C语言-内存分配
内存分配 1. 引入 int nums[10] {0}; //对int len 10; int nums[len] {0}; //错是因为系统的内存分配原则导致的2. 概述 在程序运行时,系统为了 更好的管理进程中的内存,所以有了 内存分配机制。 分配原则: 2.1 静态分配 静态分配原…...
)
算法工程师-机器学习面试题总结(1)
目录 1-1 损失函数是什么,如何定义合理的损失函数? 1-2 回归模型和分类模型常用损失函数有哪些?各有什么优缺点 1-3 什么是结构误差和经验误差?训练模型的时候如何判断已经达到最优? 1-4 模型的“泛化”能力是指&a…...

【蓝桥杯选拔赛真题73】Scratch烟花特效 少儿编程scratch图形化编程 蓝桥杯创意编程选拔赛真题解析
目录 scratch烟花特效 一、题目要求 编程实现 二、案例分析 1、角色分析...
)
告别Vivado卡顿!用VCS2018+Verdi独立仿真Xilinx IP核的保姆级流程(附Makefile模板)
高效FPGA仿真实践:VCS与Verdi协同验证Xilinx IP核全流程指南 在FPGA开发过程中,仿真验证环节往往占据整个项目周期的60%以上时间。传统Vivado集成环境虽然提供了一站式解决方案,但随着设计规模扩大,其启动缓慢、资源占用高的问题…...

Claude Code、Cursor、GitHub Copilot、Codex 怎么选?别再按“哪个最强”来判断了
AI 编程工具越来越像“工具箱”,而不是单个聊天窗口。如果你还在问“Claude Code、Cursor、Copilot、Codex 哪个最强”,这个问题本身就有点偏。更好的判断方式是:你当前的任务发生在哪里、需要改多少文件、是否需要跑测试、结果要不要进入 PR…...

开发者专属提示词库:提升AI协作效率的实战指南
1. 项目概述:一个为开发者量身定制的提示词宝库如果你是一名开发者,无论是前端、后端、运维还是算法工程师,我相信你都或多或少地接触过像 ChatGPT 这类大型语言模型。它们能写代码、解 Bug、解释概念,甚至帮你设计架构。但很多时…...
)
用Python复现FAST天眼数学建模:从坐标变换到促动器伸缩量计算(附完整代码)
用Python复现FAST天眼数学建模:从坐标变换到促动器伸缩量计算(附完整代码) 中国天眼FAST作为全球最大单口径射电望远镜,其主动反射面调节系统堪称现代工程奇迹。当观测不同方位天体时,需要通过促动器精确控制4450块反射…...

FanControl终极指南:免费开源的风扇控制神器,轻松解决Windows散热与噪音问题
FanControl终极指南:免费开源的风扇控制神器,轻松解决Windows散热与噪音问题 【免费下载链接】FanControl.Releases This is the release repository for Fan Control, a highly customizable fan controlling software for Windows. 项目地址: https:…...

openpilot自动驾驶系统深度解析:架构剖析与实战指南
openpilot自动驾驶系统深度解析:架构剖析与实战指南 【免费下载链接】openpilot openpilot is an operating system for robotics. Currently, it upgrades the driver assistance system on 300 supported cars. 项目地址: https://gitcode.com/GitHub_Trending/…...

SyntaxUI:基于原子设计与Web组件的现代UI库开发实践
1. 项目概述:一个为开发者而生的现代UI组件库 如果你是一名前端开发者,或者正在构建一个需要用户界面的应用,那么你肯定经历过这样的场景:为了一个按钮的样式、一个表格的交互,或者一个模态框的动画,反复在…...

5分钟免费获取:开源鼠标连点器MouseClick完整使用指南
5分钟免费获取:开源鼠标连点器MouseClick完整使用指南 【免费下载链接】MouseClick 🖱️ MouseClick 🖱️ 是一款功能强大的鼠标连点器和管理工具,采用 QT Widget 开发 ,具备跨平台兼容性 。软件界面美观 ,…...

企业级后端四层架构实战:从理论到代码的清晰落地
1. 项目概述:一个四层架构的实战蓝图最近在GitHub上看到一个挺有意思的项目,叫BTawaifi/four-layer-system。光看名字,你可能会觉得这又是一个老生常谈的“四层架构”理论教程,无非是Controller、Service、Repository那套东西。但…...

mg3640s,ts8080,ts8100,g5080,g3800,g4800,ix6780,ts8180报错5B00,P07,E08,5b02,1704,1700,5b04佳能V6.200,亲测有用
下载:点这里下载 备用下载:https://pan.baidu.com/s/1WrPFvdV8sq-qI3_NgO2EvA?pwd0000 常见型号如下: G系列 G1000、G1100、G1200、G1400、G1500、G1800、G1900、G1010、G1110、G1120、G1410、G1420、G1411、G1510、G1520、G1810、G1820、…...