Python字符串模糊匹配工具:TheFuzz 库详解

更多资料获取
📚 个人网站:ipengtao.com
在处理文本数据时,常常需要进行模糊字符串匹配来找到相似的字符串。Python的 TheFuzz 库提供了强大的方法用于解决这类问题。本文将深入介绍 TheFuzz 库,探讨其基本概念、常用方法和示例代码,帮助读者更全面地了解和应用模糊字符串匹配。
TheFuzz 库简介
TheFuzz 是一个提供多种字符串比较和模糊匹配算法的 Python 库。它提供了多种算法用于计算字符串相似度,如 Levenshtein 距离、Jaccard 系数、TF-IDF 等。这些方法能够帮助我们找到字符串之间的相似度,而不仅仅是精确匹配。
基本方法介绍
a. 计算字符串相似度
from fuzzywuzzy import fuzzstring1 = "Python is great"
string2 = "Python is awesome"
similarity_ratio = fuzz.ratio(string1, string2)
print(f"相似度:{similarity_ratio}%")
b. 查找最相似的字符串
choices = ["Python is amazing", "Python is incredible", "Java is cool", "C++ is fast"]
target = "Python is astonishing"
best_match, score = fuzz.process.extractOne(target, choices)
print(f"最相似的字符串:{best_match}, 相似度:{score}")
应用场景
- 数据清洗与规范化:用于处理非精确匹配的数据,例如清理和规范化数据库中的文本字段。
数据清洗和规范化是 TheFuzz 库的一个重要应用场景。当处理大量文本数据时,往往会遇到非精确匹配的情况,这时 TheFuzz 可以发挥作用。例如,在清理和规范化数据库中的文本字段时,经常会出现不一致的数据,比如拼写错误、格式不统一或者词汇表达不同的情况。这就需要一种方法来处理这些非精确匹配的文本数据,使它们变得一致和规范。
举个例子,假设有一个数据库中存储着顾客姓名信息。由于输入错误、缩写、大小写问题或者简称等原因,同一个姓名可能以多种不同的形式出现。通过 TheFuzz 库,可以找到这些相似的姓名,并将它们规范化为统一的形式。
from fuzzywuzzy import fuzz# 示例数据:包含非精确匹配的姓名
customer_names = ["John Doe", "Jon D.", "Jane Smith", "j. smith", "J. Doe", "Alice Johnson"]# 对顾客姓名进行清洗与规范化
unique_names = set() # 存储规范化后的唯一姓名for name in customer_names:# 使用 TheFuzz 库找到最相似的姓名并规范化most_similar_name = max(unique_names, key=lambda x: fuzz.ratio(x, name), default=None)# 若找到最相似的姓名并且相似度高于阈值,则认定为同一个姓名if most_similar_name and fuzz.ratio(most_similar_name, name) > 80:unique_names.remove(most_similar_name)unique_names.add(name)else:unique_names.add(name)print(unique_names)
在上述示例中,通过比较相似度来判断姓名是否相同,并将它们规范化为唯一的形式。这有助于清理和规范化数据库中的文本字段,使得数据更加一致和易于管理。
- 搜索引擎和推荐系统:在搜索引擎中,提供模糊匹配功能;或在推荐系统中找到相似内容。
搜索引擎和推荐系统是 TheFuzz 库另一个重要的应用领域。在搜索引擎中,模糊匹配功能能够帮助用户找到即使输入存在轻微误差或不完整,但仍与搜索项高度相关的内容。而在推荐系统中,它有助于找到与用户过去喜欢的内容相似的其他内容。
举个例子,如果一个用户搜索“Python Tutorils”(拼写错误的 “Tutorials”),搜索引擎可以使用 TheFuzz 库来寻找与正确拼写最相似的结果。
from fuzzywuzzy import process# 假设这是搜索引擎的内容列表
content_list = ["Python Tutorials for Beginners","Intermediate Python Topics","Advanced Python Programming"
]# 用户输入的搜索项
user_query = "Python Tutorils"# 使用 TheFuzz 库找到与用户查询最相似的内容
best_match = process.extractOne(user_query, content_list)
print(best_match)
在推荐系统中,TheFuzz 库可以帮助找到与用户已喜欢内容相似的其他内容,提供更加个性化的推荐。
from fuzzywuzzy import process# 假设用户喜欢的内容
user_likes = "The Lord of the Rings"# 假设这是推荐系统的内容列表
content_list = ["The Lord of the Flies","The Hobbit","Game of Thrones","Harry Potter"
]# 使用 TheFuzz 库找到与用户喜欢内容相似的其他内容
similar_content = process.extract(user_likes, content_list)
print(similar_content)
上述示例展示了 TheFuzz 库在推荐系统中的应用,它可以帮助推荐系统找到与用户已喜欢内容相似的其他内容,从而提供更加个性化的推荐体验。
- 自然语言处理:用于比较文本中相似度较高的短语、句子或段落。
在自然语言处理领域,TheFuzz 库可以应用于比较文本中相似度较高的短语、句子或段落。这种比较在文本数据分析、信息提取和相似文本检测中具有重要意义。
TheFuzz 库可以帮助找到两个短语之间的相似度,甚至在它们之间存在拼写错误或格式不一致的情况下也能有效工作。
from fuzzywuzzy import fuzz# 示例短语
phrase1 = "Natural Language Processing is interesting"
phrase2 = "Naturall Langauge Process is interestng"# 比较两个短语的相似度
similarity_ratio = fuzz.ratio(phrase1, phrase2)
print(f"短语相似度:{similarity_ratio}%")
另一个常见任务是比较整个句子或段落之间的相似性。这在文本相似性比较、抄袭检测等领域有广泛的应用。
from fuzzywuzzy import fuzz# 示例句子
sentence1 = "The cat is on the mat."
sentence2 = "A cat sits on the mat."# 比较两个句子的相似度
similarity_ratio = fuzz.ratio(sentence1, sentence2)
print(f"句子相似度:{similarity_ratio}%")
TheFuzz 库提供了多种方法来比较文本之间的相似度,能够应对文本中存在的拼写错误、格式差异以及词汇表达不同的情况,帮助分析和处理自然语言文本数据。
高级功能
TheFuzz库还支持其他高级功能,例如部分字符串匹配和列表排序。
TheFuzz 库中的 partial_ratio 方法可以用于比较两个字符串的部分相似度。这在处理较长字符串时尤其有用,因为有时我们只需要比较字符串的部分内容。
from fuzzywuzzy import fuzzstring1 = "apple pie with ice cream"
string2 = "I like apple pie"
partial_similarity = fuzz.partial_ratio(string1, string2)
print(f"部分字符串相似度:{partial_similarity}%")
partial_ratio 方法将比较两个字符串的部分内容,找出它们之间的相似度。这在搜索引擎和信息提取任务中特别有用,因为不需要完全匹配,只需一部分内容相似就可以。
TheFuzz 库中的 process.extract 方法用于在列表中找到与目标字符串最相似的字符串,并按相似度降序排列返回结果。
from fuzzywuzzy import processchoices = ["apple", "ape", "apples", "mango", "banana"]
target = "app"sorted_matches = process.extract(target, choices)
print(sorted_matches)
process.extract 方法将返回一个排序后的列表,列表中的每个元素是目标字符串与列表中字符串的相似度,按相似度高低排序。
注意事项
在使用 TheFuzz 库时,需要根据具体场景选择适合的比较算法。
TheFuzz 库提供了多种比较算法,每种算法适用于不同的比较场景。比如:
fuzz.ratio用于比较整个字符串的相似度。fuzz.partial_ratio用于部分字符串的相似度比较。fuzz.token_sort_ratio用于对单词进行排序后的相似度比较。
正确选择适合场景的算法可以提高匹配的准确性。例如,在处理整个字符串时,fuzz.ratio可能更合适;而处理长文本或部分相似内容时,fuzz.partial_ratio 可能更加实用。
大数据量下的模糊匹配可能会耗费较多资源,需要考虑性能和效率问题。
在处理大量数据时,模糊匹配可能导致性能问题。因为计算字符串相似度是一项计算密集型任务,需要耗费大量的计算资源。特别是在对每个数据点进行匹配时,会造成额外的负担。
为了解决大数据量下的性能问题,可以考虑以下措施:
- 预处理数据:在进行模糊匹配之前,对数据进行预处理和清洗,以减少不必要的比较量。
- 设置相似度阈值:限制仅对高概率相似的数据进行匹配。
- 选择合适的算法和参数:根据具体情况选择合适的算法和参数以优化匹配效率。
考虑性能和效率问题对于在大数据量下使用 TheFuzz 库非常重要。正确的优化方法可以提高程序效率,减少计算资源的使用,同时获得准确的匹配结果。
总结
TheFuzz库为Python开发者提供了一种强大的工具,用于模糊字符串匹配和相似度计算。通过选择合适的算法和方法,可以在各种场景下应用模糊字符串匹配。希望这些示例和信息能够帮助您更好地了解和使用TheFuzz库。
Python学习路线

更多资料获取
📚 个人网站:ipengtao.com
如果还想要领取更多更丰富的资料,可以点击文章下方名片,回复【优质资料】,即可获取 全方位学习资料包。

点击文章下方链接卡片,回复【优质资料】,可直接领取资料大礼包。
相关文章:
Python字符串模糊匹配工具:TheFuzz 库详解
更多资料获取 📚 个人网站:ipengtao.com 在处理文本数据时,常常需要进行模糊字符串匹配来找到相似的字符串。Python的 TheFuzz 库提供了强大的方法用于解决这类问题。本文将深入介绍 TheFuzz 库,探讨其基本概念、常用方法和示例代…...

Golang中WebSocket和WSS的支持
引言 WebSocket是一种在单个TCP连接上进行全双工通信的协议,它为实时通信提供了一种简单而强大的方式。而WSS(WebSocket Secure)是一种通过加密的方式使用WebSocket的协议,可以在安全的传输层上进行通信。本文将探讨Golang中WebS…...

亚马逊云科技re:Invent大会,助力安全构建规模化生成式AI应用
2023亚马逊云科技re:Invent全球大会进入第三天,亚马逊云科技数据和人工智能副总裁Swami Sivasubramanian博士在周三的主题演讲中,为大家带来了关于亚马逊云科技生成式AI的最新能力、面向生成式AI时代的数据战略以及借助生成式AI应用提高生产效率的精彩分…...

价差后的几种方向,澳福如何操作才能盈利
在价差出现时,澳福认为会出现以下几种方向。 昂贵资产的贬值和便宜资产的平行升值。昂贵的资产贬值,而便宜的资产保持不变。昂贵资产的贬值和便宜资产的平行贬值,但昂贵资产的贬值速度更快,超过便宜资产。更贵的一对的进一步升值和…...

【Java】类和对象之超级详细的总结!!!
文章目录 前言1. 什么是面向对象?1.2面向过程和面向对象 2.类的定义和使用2.1什么是类?2.2类的定义格式2.3类的实例化2.3.1什么是实例化2.3.2类和对象的说明 3.this引用3.1为什么会有this3.2this的含义与性质3.3this的特性 4.构造方法4.1构造方法的概念4…...
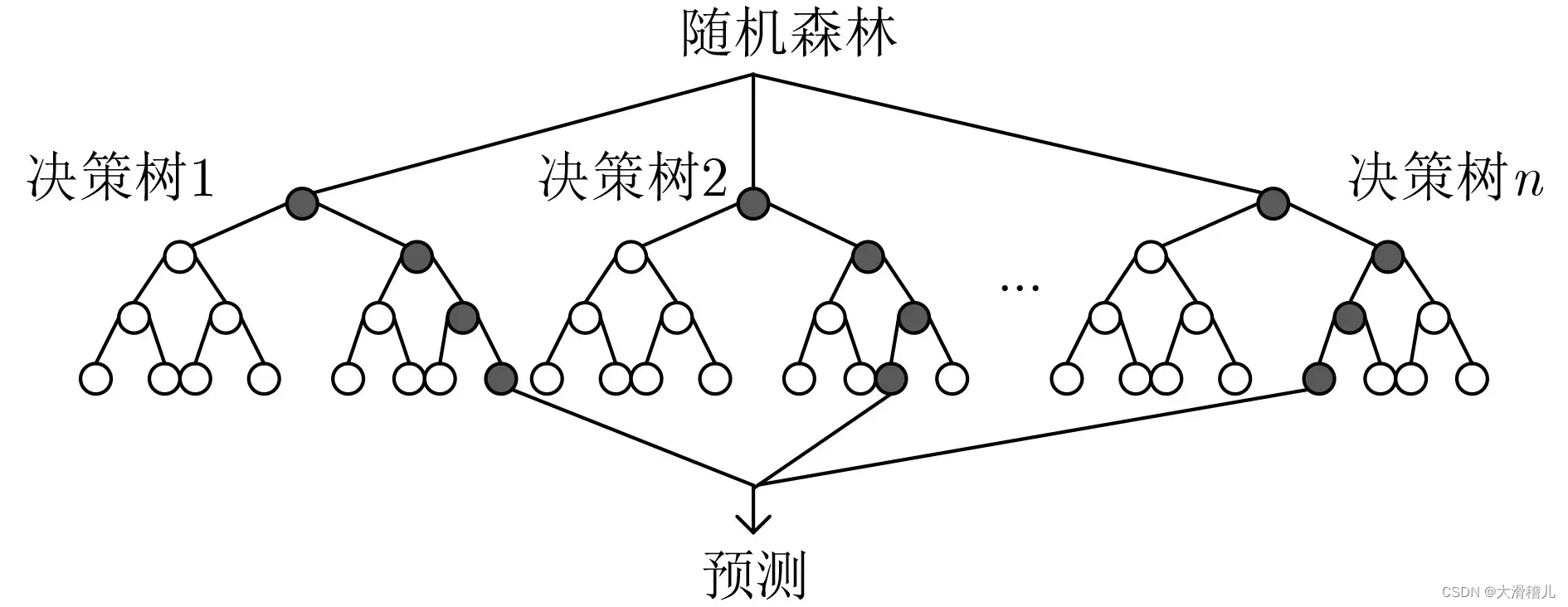
机器学习的复习笔记3-回归的细谈
一、回归的细分 机器学习中的回归问题是一种用于预测连续型输出变量的任务。回归问题的类型和特点如下: 线性回归(Linear Regression):线性回归是回归问题中最简单的一种方法。它假设自变量与因变量之间存在线性关系,…...
Git常用命令#切换分支
要在 Git 中切换分支,你可以使用 git checkout 命令。 a.创建新分支并切换到该分支 如果你想要创建一个新分支并立即切换到该分支,可以使用以下命令: git checkout -b 新分支名这会创建一个名为 新分支名 的新分支,并将你的工作目…...

【qml入门教程系列】:qml property使用介绍
作者:令狐掌门 技术交流QQ群:675120140 博客地址:https://mingshiqiang.blog.csdn.net/ 文章目录 属性的定义property基本用法属性变更事件通知属性绑定属性别名只读属性默认属性 default property访问和修改属性方式1:使用setProperty方法方式2:使用QQmlContext设置属性自定…...
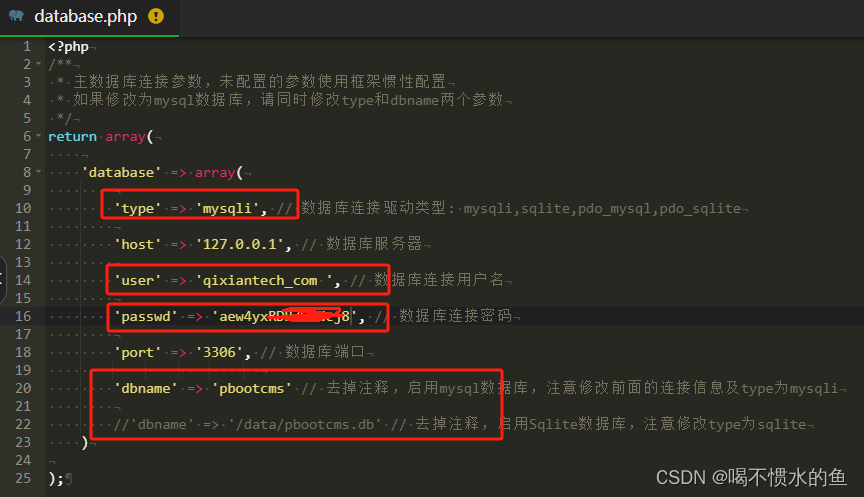
pbootcms建站
pbootcms建站 一、下载pbootcms二、安装1、进入宝塔面在网站栏,新建站点,将该址里面文件全部清再将下载的pbootcms上传至该地址。 三、修改关联数据库1、在根目录下/config打开database.php照如下修改这里我使用mysqli数据库。修改并使用自已创建的数据库…...

Spring的事务传播行为
文章目录 说一下Spring的事务传播行为 今天来和大家聊聊spring中使用的事务传播行为, 说一下Spring的事务传播行为 spring事务的传播行为说的是,当多个事务同时存在的时候,spring如何处理这些事务的行为。 ① PROPAGATION_REQUIRED…...

04_网络编程
网络编程 什么是网络编程 可以让设备中的程序与网络上其他设备中的程序进行数据交互(实现网络通信的) java.net.* 包下提供了网络编程的解决方案 通信的基本架构 CS 架构(Client 客户端 / Server 服务端)BS 架构(…...
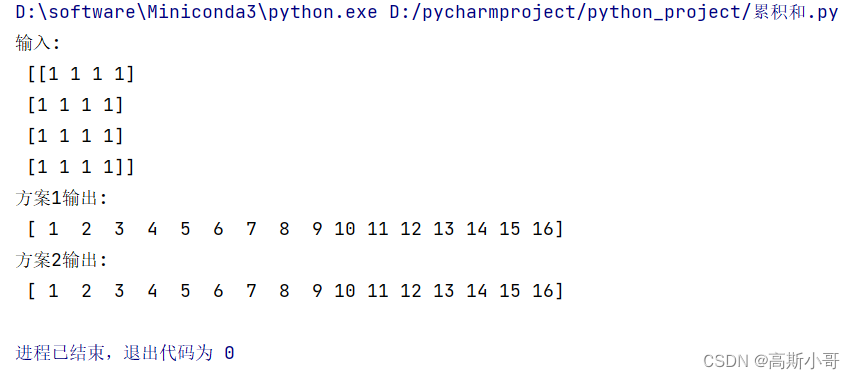
【五分钟】熟练使用numpy.cumsum()函数(干货!!!)
引言 numpy.cumsum()函数用于计算输入数组的累积和。当输入是多维数组时,numpy.cumsum()函数可以沿着指定轴计算累积和。 计算一维数组的累计和 代码如下: # 计算一维数组的累计和 tmp_array np.ones((4,), dtypenp.uint8) # [1, 1, 1, 1] print(&…...
由11月27日滴滴崩溃到近两个月国内互联网产品接二连三崩溃引发的感想
文章目录 知乎文分析微信聊天截图微信公众号 滴滴技术 发文k8s 官方文档滴滴官方微博账号 近两个月国内互联网产品“崩溃”事件2023-10-23 语雀崩溃2023-11-12 阿里云崩溃2023-11-27 滴滴崩溃2023-12-03 腾讯视频崩溃总结 我的感想 知乎文分析 最近连续加班,打车较…...
Python按要求从多个txt文本中提取指定数据
基本想法 遍历文件夹并从中找到文件名称符合我们需求的多个.txt格式文本文件,并从每一个文本文件中,找到我们需要的指定数据,最后得到所有文本文件中我们需要的数据的集合 举例 如现有名为file一个文件夹,里面含有大量的.txt格…...
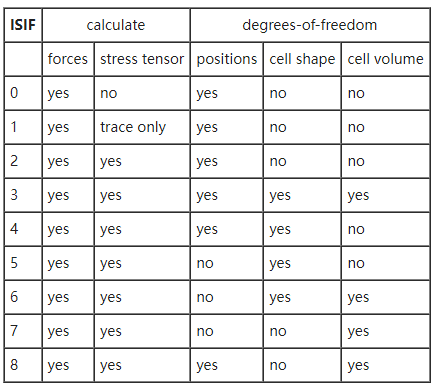
DFT新手教程:VASP中ISIF取值设置
新手初学VASP计算时首先接触到的就是结构优化的计算任务。 在结构优化中,INCAR中的关键参数包括 IBRION ,NSW,ISIF,EDIFF和EDIFFG 各个参数均可在vaspwiki查到可设置的参数以及该参数所具有的设置的含义。 https://www.vasp.at/…...

pytest自动化框架之allure测试报告的用例描述设置
allure测试报告的用例描述相关方法;如下图 allure标记用例级别severity 在做自动化测试的过程中,测试用例越来越多的时候,如果执行一轮测试发现了几个测试不通过,我们也希望能快速统计出缺陷的等级。 pytest结合allure框架可以对…...
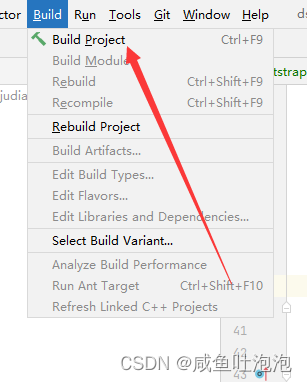
在编程中遇到的问题总结
IDEA空包粘黏问题 创建好目录以后会发现idea自动将空包合并在一起了,而且点击设置里面也没有Compact Middle Package Compact Middle Package如果不在设置的主面板上,则点击Tree Appearance,会发现Compact Middle Package在Tree Appearance里…...
)
【数据库设计和SQL基础语法】--SQL语言概述--SQL的基本结构和语法规则(二)
一、数据控制语言(DCL) 1.1 授权(GRANT) 数据控制语言(DCL)是SQL的一个子集,用于控制数据库中的数据访问和权限。GRANT语句是DCL中的一种,用于向用户或角色授予特定的数据库操作权…...

easyexcel多级表头导出各级设置样式(继承HorizontalCellStyleStrategy实现)
easyexcel多级表头导出各级设置样式(继承HorizontalCellStyleStrategy实现) package com.example.wxmessage.entity;import com.alibaba.excel.metadata.data.WriteCellData; import com.alibaba.excel.write.handler.context.CellWriteHandlerContext;…...

QMLfor python pyside6
QML QML是一种用于创建用户界面的声明性语言,它是Qt生态系统中的一部分。QML使用JavaScript语言和其独特的语法来定义用户界面组件,使得开发人员可以轻松地创建现代化、漂亮而又响应迅速的应用程序。 QML是基于QtQuick技术构建的,QtQuick是…...
深度解析与高级部署方案)
Visual C++运行库合集(vcredist)深度解析与高级部署方案
Visual C运行库合集(vcredist)深度解析与高级部署方案 【免费下载链接】vcredist AIO Repack for latest Microsoft Visual C Redistributable Runtimes 项目地址: https://gitcode.com/gh_mirrors/vc/vcredist Visual C运行库合集(vcredist)是解决Windows系统依赖问题的…...

Obsidian-Zettelkasten终极指南:20+模板构建你的第二大脑
Obsidian-Zettelkasten终极指南:20模板构建你的第二大脑 【免费下载链接】Obsidian-Templates A repository containing templates and scripts for #Obsidian to support the #Zettelkasten method for note-taking. 项目地址: https://gitcode.com/gh_mirrors/o…...

长期项目使用Taotoken按Token计费模式带来的成本优化体感
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 长期项目使用Taotoken按Token计费模式带来的成本优化体感 1. 项目背景与计费模式选择 我们团队维护着一个中等规模的AI应用项目&a…...

通过环境变量统一管理Taotoken密钥提升项目安全与便捷性
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 通过环境变量统一管理Taotoken密钥提升项目安全与便捷性 在开发基于大模型的应用时,API密钥的管理是一个基础但至关重要…...

crawdad-openclaw:构建高韧性智能爬虫的模块化框架实战
1. 项目概述:一个为数据抓取而生的开源“机械爪”如果你和我一样,在数据工程或网络爬虫领域摸爬滚打过几年,那你一定经历过这样的时刻:面对一个结构复杂、反爬机制严密的网站,你精心编写的爬虫脚本在运行了几个小时后&…...

别再到处找了!用BigMap+geojson.io,5分钟搞定ECharts镇级地图的GeoJSON数据
5分钟极速获取镇级GeoJSON数据:BigMapgeojson.io与ECharts实战指南 当我们需要在数据可视化项目中展示乡镇级地理信息时,常常会遇到数据获取的难题。主流地图平台提供的API往往止步于区县级,而公开数据源又难以满足定制化需求。本文将介绍一套…...

AI 基本面量化:从理论到可部署 MVP-1.学习目标与工具链
AI 基本面量化实战:从理论到可部署 MVP 的完整学习路径1. 核心目标与 MVP 定义1.1 学习目标定位1.1.1 掌握 AI 技术与基本面分析深度融合的方法论体系AI 基本面量化的本质并非用复杂模型替代经典金融理论,而是以经济学逻辑为锚、以数据驱动为翼ÿ…...
)
告别YAML诅咒:用LLM自动生成可验证CD流水线(附奇点大会开源Schema v2.1)
更多请点击: https://intelliparadigm.com 第一章:AI原生持续交付:2026奇点智能技术大会部署流水线优化 在2026奇点智能技术大会上,AI原生持续交付(AI-Native CI/CD)成为核心实践范式——它不再将AI模型视…...

Windows下CLion配置NDK的CMake项目,为什么你的Android.toolchain.cmake总报错?一篇讲清所有参数
Windows下CLion配置NDK的CMake项目:破解android.toolchain.cmake报错全指南 当你第一次在CLion中尝试配置NDK的CMake项目时,那个看似简单的android.toolchain.cmake文件可能成了噩梦的开始。明明按照教程一步步操作,却在编译时遭遇各种莫名其…...

通过curl命令直接测试taotoken平台api接口的详细步骤
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 通过curl命令直接测试Taotoken平台API接口的详细步骤 对于需要在无SDK环境、进行快速功能验证或排查网络问题的开发者而言…...