【数据库设计和SQL基础语法】--SQL语言概述--SQL的基本结构和语法规则(二)
一、数据控制语言(DCL)
1.1 授权(GRANT)
数据控制语言(DCL)是SQL的一个子集,用于控制数据库中的数据访问和权限。GRANT语句是DCL中的一种,用于向用户或角色授予特定的数据库操作权限。以下是GRANT语句的基本语法:
GRANT privileges
ON object
TO user_or_role [, user_or_role, ...];
其中:
privileges表示要授予的权限,如SELECT、INSERT、UPDATE、DELETE等。object表示授权的对象,可以是表、视图等数据库对象。user_or_role表示要授予权限的用户或角色。
示例:
GRANT SELECT, INSERT ON employees
TO user1, user2;
上述示例将employees表的SELECT和INSERT权限授予了user1和user2两个用户。
GRANT语句的执行通常由数据库管理员(DBA)或具有管理员权限的用户完成。权限的授予使得用户或角色能够执行特定的数据库操作,增强了数据库的安全性和灵活性。在实际应用中,授权应该根据最小权限原则,仅授予用户或角色完成其工作所需的最小权限,以降低潜在的安全风险。
1.2 撤销权限(REVOKE)
REVOKE语句是数据控制语言(DCL)中的一种,用于撤销用户或角色对数据库对象的权限。基本语法如下:
REVOKE privileges
ON object
FROM user_or_role [, user_or_role, ...];
其中:
privileges表示要撤销的权限,如SELECT、INSERT、UPDATE、DELETE等。object表示权限作用的对象,可以是表、视图等数据库对象。user_or_role表示要撤销权限的用户或角色。
示例:
REVOKE SELECT, INSERT ON employees
FROM user1, user2;
上述示例撤销了employees表上对user1和user2用户的SELECT和INSERT权限。
使用REVOKE语句可以有效地管理数据库中的权限,确保用户或角色仅具有其工作所需的最小权限。在执行REVOKE时,需要确保被撤销的权限确实已经存在,否则将产生错误。与GRANT相似,REVOKE的执行通常由数据库管理员(DBA)或具有管理员权限的用户完成。
二、事务控制语言(TCL)
2.1 提交(COMMIT)
COMMIT语句是事务控制语言(TCL)中的一种,用于将数据库事务的所有操作永久性地应用到数据库,并结束事务。在SQL中,COMMIT语句将所有之前使用BEGIN TRANSACTION开始的事务中的操作进行提交,使这些操作成为数据库的一部分。
基本语法如下:
COMMIT;
执行COMMIT后,事务所做的修改将变得永久,并对其他事务可见。这意味着对数据库的更改已成功应用,并且事务结束。
示例:
BEGIN TRANSACTION;
-- 一系列SQL操作
COMMIT;
上述示例中,BEGIN TRANSACTION标志着事务的开始,后续的一系列SQL操作将在事务中执行。最后,COMMIT语句将这些操作提交,使它们成为数据库的一部分。
值得注意的是,如果在事务执行过程中发生了错误,通常会使用ROLLBACK语句来回滚事务,撤销事务中的所有更改,而不是提交。这有助于确保在发生错误时数据库的一致性。在实际应用中,事务的使用对于确保数据库的完整性和一致性至关重要。
2.2 回滚(ROLLBACK)
ROLLBACK语句是事务控制语言(TCL)中的一种,用于撤销事务中的所有未提交的更改,并将数据库状态还原到事务开始之前的状态。如果在事务执行过程中发生错误或者需要取消事务的更改,可以使用ROLLBACK语句。
基本语法如下:
ROLLBACK;
执行ROLLBACK后,事务中的所有更改都将被撤销,数据库将恢复到事务开始之前的状态。这确保了在事务执行过程中发生错误时,数据库保持一致性和完整性。
示例:
BEGIN TRANSACTION;
-- 一系列SQL操作
-- 发生错误,需要回滚
ROLLBACK;
上述示例中,BEGIN TRANSACTION标志着事务的开始,后续的一系列SQL操作执行过程中发生错误,因此使用ROLLBACK将回滚事务,撤销所有更改。在实际应用中,ROLLBACK是确保在事务执行中发生错误时维护数据库的一致性和完整性的重要工具。
三、高级查询
3.1 聚合函数
聚合函数是SQL中的高级查询工具,用于对结果集执行计算,并返回单个值。这些函数通常用于执行诸如求和、计数、平均值等聚合操作。以下是一些常见的聚合函数:
- COUNT(): 用于计算结果集中行的数量。
SELECT COUNT(column_name) FROM table_name; - SUM(): 用于计算数值列的总和。
SELECT SUM(column_name) FROM table_name; - AVG(): 用于计算数值列的平均值。
SELECT AVG(column_name) FROM table_name; - MIN(): 用于找到数值列的最小值。
SELECT MIN(column_name) FROM table_name; - MAX(): 用于找到数值列的最大值。
SELECT MAX(column_name) FROM table_name;
这些函数可以与GROUP BY子句结合使用,以便按组执行聚合操作。例如,如果要计算每个部门的员工数量:
SELECT department, COUNT(employee_id) as employee_count
FROM employees
GROUP BY department;
上述查询将返回每个部门的员工数量。
聚合函数在数据分析和报告生成中经常被使用,它们使得可以轻松地从大量数据中提取有用的摘要信息。
3.2 分组与Having子句
在SQL中,GROUP BY子句用于将结果集按一列或多列进行分组,而HAVING子句则用于在分组的基础上对分组进行过滤。这两者通常一起使用,允许在执行聚合函数后对分组应用条件。
- GROUP BY 子句
GROUP BY子句的基本语法如下:
SELECT column1, column2, ..., aggregate_function(column)
FROM table_name
GROUP BY column1, column2, ...;
在这个语句中,column1, column2, ...是要分组的列,aggregate_function(column)是应用于每个组的聚合函数。
例如,如果要按部门分组并计算每个部门的平均工资:
SELECT department, AVG(salary) as avg_salary
FROM employees
GROUP BY department;
- HAVING 子句
HAVING子句用于在分组的基础上进行条件过滤。它类似于WHERE子句,但WHERE用于过滤行,而HAVING用于过滤分组。
基本语法如下:
SELECT column1, column2, ..., aggregate_function(column)
FROM table_name
GROUP BY column1, column2, ...
HAVING condition;
例如,如果只想选择平均工资大于50000的部门:
SELECT department, AVG(salary) as avg_salary
FROM employees
GROUP BY department
HAVING AVG(salary) > 50000;
这将返回平均工资大于50000的部门及其对应的平均工资。
HAVING子句允许在聚合函数的基础上进行进一步的筛选,对于复杂的数据分析和报告生成非常有用。
3.3 连接查询
连接查询是在多个表中检索相关数据的一种常见查询操作。SQL提供了不同类型的连接,包括内连接(INNER JOIN)、左连接(LEFT JOIN或LEFT OUTER JOIN)、右连接(RIGHT JOIN或RIGHT OUTER JOIN)和全连接(FULL JOIN或FULL OUTER JOIN)。
- 内连接(INNER JOIN)
内连接返回两个表中匹配行的交集。基本语法如下:
SELECT column1, column2, ...
FROM table1
INNER JOIN table2 ON table1.column = table2.column;
在这个语句中,table1和table2是要连接的表,column是连接的条件。
例如,如果有一个employees表和一个departments表,它们通过department_id列关联,可以使用内连接找到员工和其对应部门的信息:
SELECT employees.employee_id, employees.first_name, employees.last_name, departments.department_name
FROM employees
INNER JOIN departments ON employees.department_id = departments.department_id;
- 左连接(LEFT JOIN)
左连接返回左表中所有行,以及右表中与左表中匹配行的交集。如果右表中没有匹配的行,结果集中右表的列将包含 NULL 值。
基本语法如下:
SELECT column1, column2, ...
FROM table1
LEFT JOIN table2 ON table1.column = table2.column;
例如,要获取所有员工和其对应部门的信息,包括没有部门的员工:
SELECT employees.employee_id, employees.first_name, employees.last_name, departments.department_name
FROM employees
LEFT JOIN departments ON employees.department_id = departments.department_id;
- 右连接(RIGHT JOIN)
右连接返回右表中所有行,以及左表中与右表中匹配行的交集。如果左表中没有匹配的行,结果集中左表的列将包含 NULL 值。
基本语法如下:
SELECT column1, column2, ...
FROM table1
RIGHT JOIN table2 ON table1.column = table2.column;
右连接在某些数据库系统中可能不被支持,可以使用左连接的方式进行模拟。
- 全连接(FULL JOIN)
全连接返回两个表中所有行的并集,如果没有匹配的行,将会在结果集中填充 NULL 值。
基本语法如下:
SELECT column1, column2, ...
FROM table1
FULL JOIN table2 ON table1.column = table2.column;
全连接在某些数据库系统中可能不被支持,可以通过左连接和右连接的组合来实现。
连接查询是处理多表关联数据的重要工具,允许在一个查询中检索并组合来自不同表的信息。
3.4 子查询
子查询是指在查询中嵌套使用的查询语句。子查询通常嵌套在其他查询语句的 WHERE、FROM 或 SELECT 子句中,用于提供更复杂的条件、数据或计算。
- 单行子查询
单行子查询返回一行一列的结果,并通常用于条件判断或计算中。以下是一个示例,使用子查询查找工资最高的员工:
SELECT first_name, last_name, salary
FROM employees
WHERE salary = (SELECT MAX(salary) FROM employees);
在这个例子中,(SELECT MAX(salary) FROM employees) 是一个子查询,用于查找 employees 表中的最高工资,然后外部查询选择具有相同工资的员工记录。
- 多行子查询
多行子查询返回多行多列的结果,并通常用于条件判断或计算中。以下是一个示例,使用子查询查找部门平均工资高于公司平均工资的部门:
SELECT department_id, AVG(salary) AS department_avg_salary
FROM employees
GROUP BY department_id
HAVING AVG(salary) > (SELECT AVG(salary) FROM employees);
在这个例子中,(SELECT AVG(salary) FROM employees) 是一个子查询,用于计算整个公司的平均工资,然后外部查询选择部门平均工资高于公司平均工资的部门。
- 行子查询
行子查询返回一行多列的结果,并通常用于条件判断或计算中。以下是一个示例,使用子查询检查某个员工是否在指定的部门中:
SELECT employee_id, first_name, last_name, department_id
FROM employees
WHERE (employee_id, department_id) IN (SELECT employee_id, department_id FROM employee_department_mapping);
在这个例子中,(SELECT employee_id, department_id FROM employee_department_mapping) 是一个子查询,用于提供一个包含员工ID和部门ID的结果集,然后外部查询选择符合这些条件的员工记录。
子查询是 SQL 查询中强大且灵活的工具,可以用于处理复杂的条件和数据分析。在编写子查询时,要确保子查询返回的结果集与外部查询的条件兼容。
四、视图
4.1 视图的创建
在SQL中,视图(View)是一种虚拟的表,它基于一个或多个表的查询结果。视图不包含实际的数据,而是根据定义的查询从一个或多个表中检索数据。创建视图可以简化复杂查询、提高查询的可维护性,并对用户隐藏底层表的结构。
以下是创建视图的基本语法:
CREATE VIEW view_name AS
SELECT column1, column2, ...
FROM table1
WHERE condition;
其中,view_name 是视图的名称,column1, column2, ... 是视图的列,table1 是从中检索数据的表,condition 是一个可选的筛选条件。
例如,假设有一个名为 employees 的表:
CREATE TABLE employees (employee_id INT PRIMARY KEY,first_name VARCHAR(50),last_name VARCHAR(50),department VARCHAR(50),salary INT
);
如果要创建一个视图,显示员工ID、姓名和部门,可以使用以下语句:
CREATE VIEW employee_summary AS
SELECT employee_id, first_name, last_name, department
FROM employees;
现在,可以通过查询 employee_summary 视图来获取员工的摘要信息,就好像这个视图是一个实际的表一样:
SELECT * FROM employee_summary;
创建视图有助于简化复杂查询,提高查询的可读性,并且在视图的基础上执行的查询将自动反映底层表的变化。
Tip:视图并不存储实际的数据,而是基于查询结果生成虚拟表。在某些数据库管理系统中,视图也可以用于实现安全性控制,只允许用户访问特定列或行。
4.2 视图的使用
视图在SQL中的使用方式类似于普通的表,可以用于查询、过滤和连接数据,但视图并不存储实际的数据。以下是一些使用视图的常见情景:
-
查询数据: 视图可以像表一样用于查询数据。例如,如果有一个名为
employee_summary的视图,显示员工的摘要信息:SELECT * FROM employee_summary;这将检索并显示
employee_summary视图中的所有数据。 -
过滤数据: 视图可以包含筛选条件,以限制检索的数据。例如,如果
employee_summary视图包含了部门为 ‘IT’ 的员工信息:SELECT * FROM employee_summary WHERE department = 'IT';这将只返回部门为 ‘IT’ 的员工的信息。
-
连接数据: 视图可以与其他表或视图进行连接,实现更复杂的查询。例如,如果有一个名为
department_summary的视图,显示每个部门的摘要信息,可以通过连接employee_summary和department_summary来获取更全面的员工信息:SELECT es.*, ds.department_name FROM employee_summary es JOIN department_summary ds ON es.department = ds.department_id;这将返回每个员工的摘要信息以及其所属部门的名称。
-
简化复杂查询: 视图可以将复杂的查询逻辑封装在一个易于理解的接口中,使得查询变得更加简洁。例如,如果有一个视图
high_salary_employees显示薪水高于某个阈值的员工信息:SELECT * FROM high_salary_employees;这将返回所有薪水高于阈值的员工信息,而不需要复杂的条件。
-
提高可维护性: 视图允许将查询逻辑集中在一个地方,当底层表的结构变化时,只需修改视图而不是所有使用该查询的地方。这有助于提高查询的可维护性和代码的重用性。
Tip:虽然视图提供了便利性和灵活性,但在设计和使用时需要注意性能方面的考虑。复杂的视图可能会导致性能问题,特别是在大型数据集上。在使用视图时,建议仔细评估查询的性能,并确保适当的索引和优化策略已经应用。
4.3 视图的更新与删除
在SQL中,视图的更新和删除操作的可行性取决于视图的定义。一般来说,可以更新和删除满足以下条件的视图:
-
单表视图(包含来自单个表的数据): 如果视图是从单个表派生的简单查询,通常是可以进行更新和删除操作的。例如:
CREATE VIEW my_view AS SELECT column1, column2 FROM my_table WHERE condition;对于这样的视图,你可以使用
UPDATE和DELETE语句,就像操作普通表一样:UPDATE my_view SET column1 = value1 WHERE condition; DELETE FROM my_view WHERE condition; -
包含所有更新所需的信息: 视图的更新和删除操作需要包含所有更新所需的信息,包括在视图定义中涉及的列。如果视图的定义涉及多个表,更新和删除操作可能会受到限制。
CREATE VIEW employee_info AS SELECT employees.employee_id, employees.first_name, departments.department_name FROM employees JOIN departments ON employees.department_id = departments.department_id;在上面的例子中,
employee_info视图显示了员工的一些信息以及他们所在部门的名称。你可以更新和删除employee_info视图中的数据,前提是提供了足够的信息,包括employee_id、first_name和department_name。UPDATE employee_info SET first_name = 'NewName' WHERE employee_id = 123; DELETE FROM employee_info WHERE employee_id = 456;请注意,这些操作实际上会影响到
employees表,因为employee_info视图是基于employees表的。
五、存储过程和触发器
5.1 存储过程的定义和调用
在SQL中,存储过程是一组预编译的SQL语句,它们可以被存储在数据库中并在需要时进行调用。存储过程通常用于执行特定的任务或操作,并可以接受输入参数和返回结果。
- 存储过程的定义
以下是一个简单的存储过程定义的示例:
DELIMITER //CREATE PROCEDURE my_procedure (IN param1 INT, OUT result INT)
BEGIN-- 存储过程的SQL语句SELECT column1 INTO result FROM my_table WHERE another_column = param1;
END //DELIMITER ;
在上述示例中:
my_procedure是存储过程的名称。(IN param1 INT, OUT result INT)定义了输入参数param1和输出参数result的类型。- 存储过程体以
BEGIN开始,以END结束,其中包含了执行的SQL语句。
- 存储过程的调用
调用存储过程的方法取决于所使用的数据库管理系统。以下是一般的调用方法:
CALL my_procedure(123, @output);
在这个调用中,123 是传递给 param1 的输入参数值,@output 是用于接收输出参数值的变量。
如果存储过程执行成功,可以通过查询 @output 变量来获取输出结果:
SELECT @output;
请注意,存储过程的调用方式可能因数据库管理系统而异,上述示例适用于MySQL。在其他系统中,请查阅相应的文档以了解正确的调用语法。
存储过程的优点包括:
- 重用性: 存储过程可以在多个地方被调用,提高了代码的重用性。
- 性能优化: 存储过程可以预编译并存储在数据库中,从而提高执行效率。
- 安全性: 存储过程可以通过授权的方式限制对数据库的访问,提高安全性。
存储过程在不同的数据库系统中可能有一些差异,因此在具体使用时,请参考相应数据库的文档。
5.2 触发器的创建和触发条件
在SQL中,触发器(Trigger)是与表相关联的一段代码,当表上的特定事件发生时,触发器会自动执行。触发器通常用于实现在数据库层面的业务逻辑,例如在插入、更新或删除数据时执行某些操作。
- 触发器的创建
以下是一个通用的创建触发器的示例:
DELIMITER //CREATE TRIGGER trigger_name
AFTER INSERT ON table_name
FOR EACH ROW
BEGIN-- 触发器的SQL语句-- 可以包含任何合法的SQL语句,用于在特定事件发生时执行操作INSERT INTO log_table (event_description, event_time)VALUES ('New row inserted', NOW());
END //DELIMITER ;
在上述示例中:
trigger_name是触发器的名称。AFTER INSERT ON table_name指定触发器是在table_name表上执行插入操作之后触发的。FOR EACH ROW表示触发器会为每一行执行一次。- 触发器体以
BEGIN开始,以END结束,其中包含在触发事件发生时执行的SQL语句。
- 触发条件
触发器可以与不同的触发事件相关联,常见的触发事件包括:
- AFTER INSERT: 在插入数据后触发。
- AFTER UPDATE: 在更新数据后触发。
- AFTER DELETE: 在删除数据后触发。
- BEFORE INSERT: 在插入数据前触发。
- BEFORE UPDATE: 在更新数据前触发。
- BEFORE DELETE: 在删除数据前触发。
触发器可以根据需要选择性地使用这些触发事件,并在每个事件上执行不同的操作。
以下是一个具体的例子,创建一个在员工表插入记录后触发的触发器:
DELIMITER //CREATE TRIGGER after_employee_insert
AFTER INSERT ON employees
FOR EACH ROW
BEGIN-- 触发器的SQL语句INSERT INTO audit_log (event_description, event_time)VALUES ('New employee inserted', NOW());
END //DELIMITER ;
在上述示例中,after_employee_insert 触发器在 employees 表上执行插入操作后触发,每次插入新员工记录时,都会在 audit_log 表中插入相应的日志。这只是一个示例,实际使用时应根据具体业务需求和数据库系统的语法进行调整。
六、总结
今天学习了SQL的核心概念。深入探讨了数据控制语言、事务控制语言、高级查询、触发器、视图等高级主题,为深入理解数据库操作奠定了基础。
相关文章:
)
【数据库设计和SQL基础语法】--SQL语言概述--SQL的基本结构和语法规则(二)
一、数据控制语言(DCL) 1.1 授权(GRANT) 数据控制语言(DCL)是SQL的一个子集,用于控制数据库中的数据访问和权限。GRANT语句是DCL中的一种,用于向用户或角色授予特定的数据库操作权…...

easyexcel多级表头导出各级设置样式(继承HorizontalCellStyleStrategy实现)
easyexcel多级表头导出各级设置样式(继承HorizontalCellStyleStrategy实现) package com.example.wxmessage.entity;import com.alibaba.excel.metadata.data.WriteCellData; import com.alibaba.excel.write.handler.context.CellWriteHandlerContext;…...

QMLfor python pyside6
QML QML是一种用于创建用户界面的声明性语言,它是Qt生态系统中的一部分。QML使用JavaScript语言和其独特的语法来定义用户界面组件,使得开发人员可以轻松地创建现代化、漂亮而又响应迅速的应用程序。 QML是基于QtQuick技术构建的,QtQuick是…...
几何教学工具 Sketchpad几何画板 mac软件特色
Sketchpad几何画板 for Mac是一款适用于macOS系统的几何教学工具,用户可以在其画板上进行各种几何图形的绘制、演示,帮助教师了解学生的思路和对概念的掌握程度。此外,Sketchpad更深层次的功能则是可以用来进行几何交流、研究和讨论ÿ…...
华清远见嵌入式学习——C++——作业5
作业要求: 代码: #include <iostream>using namespace std;//沙发 类 class Sofa { private:string sitting; //是否可坐double *cost; //花费 public://无参构造函数Sofa(){}//有参构造函数Sofa(string s,double c):sitting(s),cost(new double(…...

Java中的类与类之间的关系
1、Java中类与类之间的关系 依赖(Dependency):一个类依赖于另一个类的定义。这种关系通常通过在一个类的方法中创建另一个类的实例来实现。依赖关系是类与类之间最基本的关系之一。关联(Association):关联…...
全新仿某度文库网站源码/在线文库源码/文档分享平台网站源码/仿某度文库PHP源码
源码简介: 全新仿某度文库网站源码/在线文库源码,是以phpMySQL开发的,它是仿某度文库PHP源码。有功能免费文库网站 文档分享平台 实现文档上传下载及在线预览。 仿百度文库是一个以phpMySQL进行开发的免费文库网站源码。仿某度文库实现文档…...

HTTPS的安全问题及应对方案
HTTPS是一种在网络通信中广泛使用的安全协议,通过使用SSL/TLS加密来保护数据的传输。然而,即使在使用了HTTPS的情况下,仍然存在一些潜在的安全问题。本文将深入探讨HTTPS的安全问题,并提供一些有效的应对策略,以确保数…...
-快速入门)
TensorRT-LLM保姆级教程(一)-快速入门
随着大模型的爆火,投入到生产环境的模型参数量规模也变得越来越大(从数十亿参数到千亿参数规模),从而导致大模型的推理成本急剧增加。因此,市面上也出现了很多的推理框架,用于降低模型推理延迟以及提升模型…...
-状态与信息流)
使用Redis构建简易社交网站(3)-状态与信息流
目的 本文目的:实现获取主页时间线和状态推送功能。(完整代码附在文章末尾) 相关知识 在我上一篇文章 《使用Redis构建简易社交网站(2)-处理用户关系》中提到了实现用户关注和取消关注功能。 那这篇文章将教会你掌握:1&#x…...

Python,非二进制的霍夫曼编码
一般来说,霍夫曼编码是二进制的,但是非二进制的也可以。本文中,通过修改N,可以得到任意进制的霍夫曼编码。 非二进制编码的作用:例如,设计九键输入法,希望根据拼音的概率来编码,常用…...
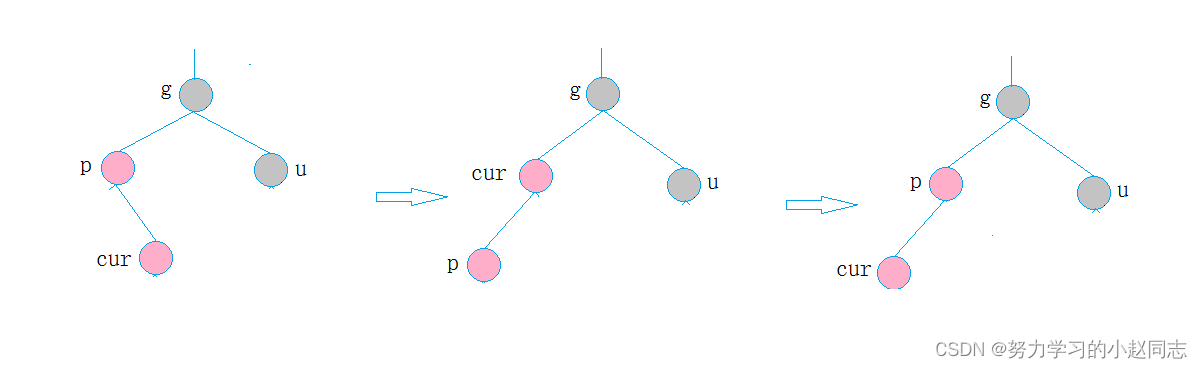
详解—[C++数据结构]—红黑树
目录 一、红黑树的概念 编辑二、红黑树的性质 三、红黑树节点的定义 四、红黑树结构 五、红黑树的插入操作 5.1. 按照二叉搜索的树规则插入新节点 5.2、检测新节点插入后,红黑树的性质是否造到破坏 情况一: cur为红,p为红,g为黑&…...

甘草书店记:6# 2023年10月31日 星期二 「梦想从来不是一夜之间实现的」
甘草书店 今天收到甘草书店第二版装修设计平面图,与理想空间越来越近。 于我而言,每一次世俗意义上所谓的成功都不如文艺作品中表现的那样让人欢腾雀跃。当你用尽120分努力,达到了冲刺满分的实力时,得个优秀的成绩也并不意外。 …...

基于Java SSM车辆租赁管理系统
现代生活方式下,人们经常需要租赁车辆,比如婚庆、自驾游等,车辆租赁公司应运而生,车辆租赁管理系统就是借助计算机对车辆租赁情况进行全面管理。系统的主要管理对象及操作有: 车辆信息:包括车辆类型、车辆名…...

侯捷C++八部曲(一,面向对象)
头文件和类的声明 inline inline修饰函数,是给编译器的一个建议,到底是否为inline由编译器来决定,inline修饰的函数在使用时是做简单的替换,这样就避免了一些函数栈空间的使用,从能提升效率。从另一种角度看ÿ…...

《数据库系统概论》学习笔记——王珊 萨师煊
第一章 绪论 一、数据库系统概述 1.数据库的4个基本概念 (1)数据 描述事物的符号记录称为数据 (2)数据库 存放数据的仓库 (3)数据库管理系统 主要功能: (1)数据定…...
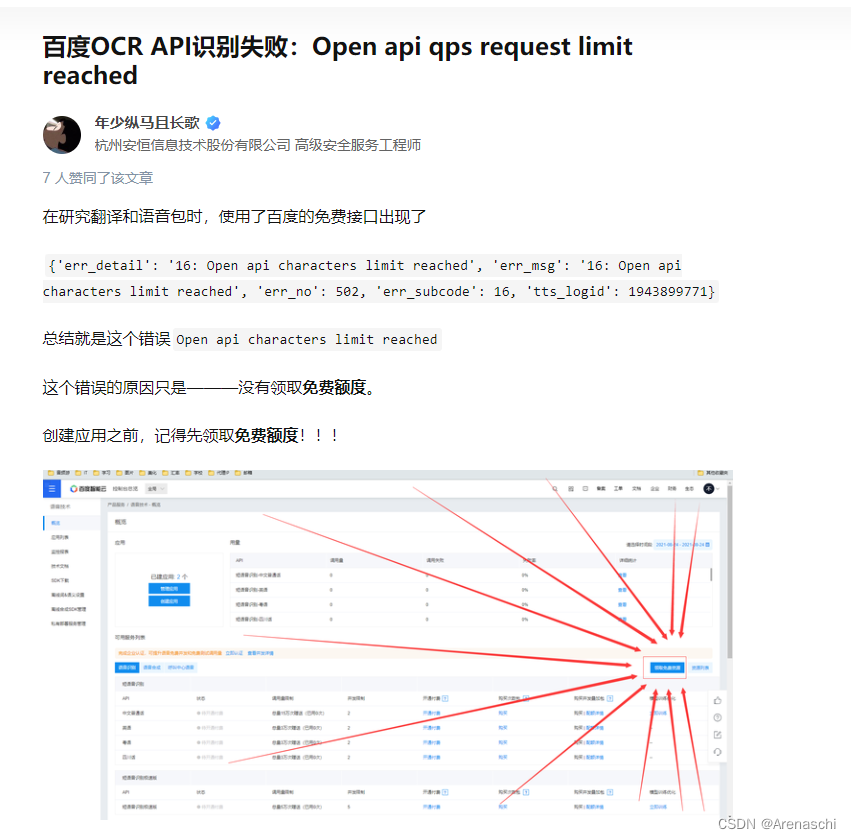
关于使用百度开发者平台处理语音朗读问题排查
错误信息:"convert_offline": false, "err_detail": "16: Open api characters limit reach 需要领取完 识别和合成都要有...

安全认证 | CISP和CISP-PTE的区别在哪里?
CISP和CISP-PTE的区别在哪里? 在国内安全信息认证体系中,虽然CISP认证与CISP-PTE认证都是中国信息安全测评中心负责颁发,均获得政府背景的认可,但二者还是有区别的。 今天就详细为大家介绍一下。 01 定义不同 ★ 注册信息安全专…...
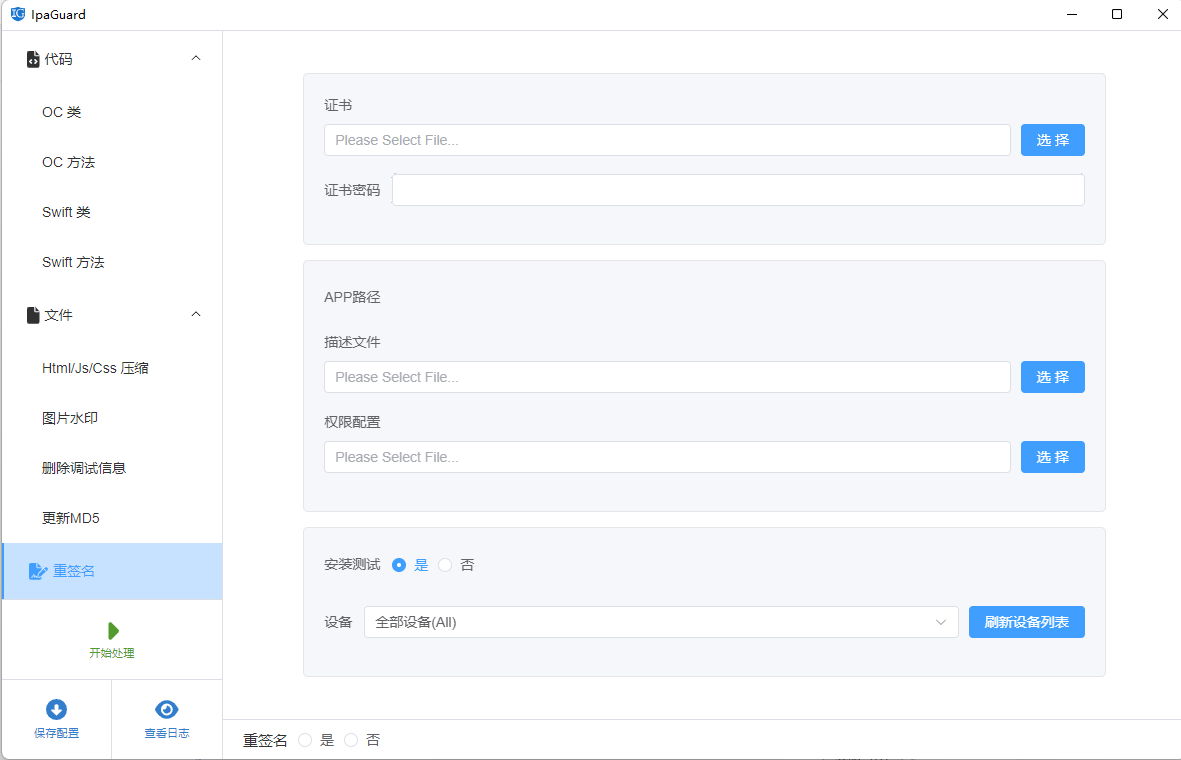
Unity3D 导出的apk进行混淆加固、保护与优化原理(防止反编译)
目录 前言: 准备资料: 正文: 1:打包一个带有签名的apk 2:对包进行反编译 3:使用ipaguard来对程序进行加固 前言: 对于辛辛苦苦完成的apk程序被人轻易的反编译了,那就得不偿…...

C语言扫雷小游戏
以下是一个简单的C语言扫雷小游戏的示例代码: #include <stdio.h>#include <stdlib.h>#include <time.h>#define BOARD_SIZE 10#define NUM_MINES 10int main() { int board[BOARD_SIZE][BOARD_SIZE]; int num_flags, num_clicks; int …...

3分钟掌握PC端聊天软件防撤回:RevokeMsgPatcher实战指南
3分钟掌握PC端聊天软件防撤回:RevokeMsgPatcher实战指南 【免费下载链接】RevokeMsgPatcher :trollface: A hex editor for WeChat/QQ/TIM - PC版微信/QQ/TIM防撤回补丁(我已经看到了,撤回也没用了) 项目地址: https://gitcode.…...

颠覆性网络拓扑可视化:基于Vue+SVG的一站式轻量级解决方案
颠覆性网络拓扑可视化:基于VueSVG的一站式轻量级解决方案 【免费下载链接】easy-topo vuesvgelement-ui 快捷画出网络拓扑图 项目地址: https://gitcode.com/gh_mirrors/ea/easy-topo 在复杂的网络架构设计和运维管理中,网络工程师和开发人员经常…...

律师拜访客户记不全?2026年4款语音转文字神器,自动整理要点不用逐字手打
做AI工具测评快三年,最近接了不少从业者的吐槽:律师出门拜访客户,不敢一直低头记怕不尊重对方,回来补要点漏了核心诉求;内容创作者剪口播视频,扒字幕改错字改到眼酸;做访谈调研的朋友࿰…...
)
Perplexity×NEJM文献交叉验证协议(NIH资助项目内部文档首次公开:含4层可信度打分矩阵与人工校验SOP)
更多请点击: https://intelliparadigm.com 第一章:PerplexityNEJM文献交叉验证协议的起源与战略意义 PerplexityNEJM文献交叉验证协议并非传统意义上的软件接口规范,而是一种面向临床研究可信度增强的元认知对齐框架。其诞生源于2023年大型语…...

【仿真实战】AnyLogic地铁站客流仿真:从零搭建带安检与限流的多层车站模型
1. 从零开始搭建地铁站仿真模型 第一次接触AnyLogic做地铁站客流仿真时,我完全被各种模块和参数搞晕了。后来在几个实际项目中摸爬滚打,终于总结出一套小白也能快速上手的方法。这次我们就来搭建一个包含安检区和限流措施的多层地铁站模型,整…...

从NASA航天电子设计看高可靠性电源与模拟电路工程实践
1. 从太空迷到电子工程师:我的技术启蒙之路我是一名不折不扣的太空迷。这个身份的烙印,始于童年时守在电视机前,目睹第一艘“水星号”载人飞船发射升空的那一天。沃尔特克朗凯特在新闻中从各个科学角度进行的详尽报道,让我整整一天…...

从零到一:在Windows Server上快速部署OpenLDAP服务与客户端连接实战
1. 为什么选择OpenLDAP? 如果你正在管理一个中小型企业的IT基础设施,用户账号管理可能会让你头疼。每次有新员工入职,都要在每台电脑上创建账号;员工离职时又要逐个删除权限。这种重复劳动不仅效率低下,还容易出错。Op…...
)
人工智能-现代方法(一)
2026.05.12 这几天开始看《人工智能-现代方法》,做一些知识记录。 1、学习的概念:归纳和演绎。(19章) 演绎靠逻辑推理,归纳靠经验总结。所以在前提正确的情况下,演绎的结论必然正确。归纳的结论则有可能出现…...

Pearcleaner:macOS终极免费应用清理工具,彻底告别数字残留
Pearcleaner:macOS终极免费应用清理工具,彻底告别数字残留 【免费下载链接】Pearcleaner A free, source-available and fair-code licensed mac app cleaner 项目地址: https://gitcode.com/gh_mirrors/pe/Pearcleaner 你是否曾经在macOS上删除应…...

TI INA333数据手册没细说的5个细节:增益电阻怎么选?温漂怎么算?你的电路可能一直没优化
INA333电路设计进阶指南:数据手册没告诉你的5个关键优化点 在精密测量电路设计中,INA333作为TI经典的仪表放大器,被广泛应用于传感器信号调理、医疗设备和工业控制等领域。虽然数据手册提供了基本参数和典型应用电路,但许多工程师…...