TensorRT-LLM保姆级教程(一)-快速入门
随着大模型的爆火,投入到生产环境的模型参数量规模也变得越来越大(从数十亿参数到千亿参数规模),从而导致大模型的推理成本急剧增加。因此,市面上也出现了很多的推理框架,用于降低模型推理延迟以及提升模型吞吐量。
本系列将针对TensorRT-LLM推理进行讲解。本文为该系列第一篇,将简要概述TensorRT-LLM的基本特性。
另外,我撰写的大模型相关的博客及配套代码均整理放置在Github:llm-action,有需要的朋友自取。
TensorRT-LLM 诞生的背景
第一、大模型参数量大,推理成本高。以10B参数规模的大模型为例,使用FP16数据类型进行部署至少需要20GB以上(模型权重+KV缓存等)。
第二、纯TensorRT使用较复杂,ONNX存在内存限制。深度学习模型通常使用各种框架(如PyTorch、TensorFlow、Keras等)进行训练和部署,而每个框架都有自己的模型表示和存储格式。因此,开发者通常使用 ONNX 解决深度学习模型在不同框架之间的互操作性问题。比如:TensorRT 就需要先将 PyTorch 模型转成 ONNX,然后再将 ONNX 转成 TensorRT。除此之外,一般还需要做数据对齐,因此需要编写 plugin,通过修改 ONNX 来适配 TensorRT plugin。另外, ONNX 使用Protobuf作为其模型文件的序列化格式。Protobuf是一种轻量级的、高效的数据交换格式,但它在序列化和反序列化大型数据时有一个默认的大小限制。在Protobuf中,默认的大小限制是2GB。这意味着单个序列化的消息不能超过2GB的大小。当你尝试加载或修改超过2GB的ONNX模型时,就会收到相关的限制提示。
第三、 纯FastTransformer使用门槛高。FastTransformer 是用 C++ 实现的;同时,它的接口和文档相对较少,用户可能需要更深入地了解其底层实现和使用方式,这对于初学者来说可能会增加学习和使用的难度。并且 FastTransformer 的生态较小,可用的资源和支持较少,这也会增加使用者在理解和应用 FastTransformer 上的困难。因此,与 Python 应用程序的部署和集成相比,它可能涉及到更多的技术细节和挑战。这可能需要用户具备更多的系统级编程知识和经验,以便将 FastTransformer 与其他系统或应用程序进行无缝集成。
综上所述,TensorRT-LLM 诞生了。
TensorRT-LLM 简介
TensorRT-LLM 为用户提供了易于使用的 Python API 来定义大语言模型 (LLM) 并构建 TensorRT 引擎,以便在 NVIDIA GPU 上高效地执行推理。 TensorRT-LLM 还包含用于创建执行这些 TensorRT 引擎的 Python 和 C++ 运行时组件。 此外,它还包括一个用于与 NVIDIA Triton 推理服务集成的后端;
同时, 使用 TensorRT-LLM 构建的模型可以使用使用张量并行和流水线并行在单 GPU 或者多机多 GPU 上执行。
TensorRT-LLM 的 Python API 的架构看起来与 PyTorch API 类似。 它为用户提供了包含 einsum、softmax、matmul 或 view 等函数的 functional 模块。 layers 模块捆绑了有用的构建块来组装 LLM; 比如: Attention 块、MLP 或整个 Transformer 层。 特定于模型的组件,例如: GPTAttention 或 BertAttention,可以在 models 模块中找到。
为了最大限度地提高性能并减少内存占用,TensorRT-LLM 允许使用不同的量化模式执行模型。 TensorRT-LLM 支持 INT4 或 INT8 权重量化(也称为仅 INT4/INT8 权重量化)以及 SmoothQuant 技术的完整实现。同时,TensorRT-LLM 优化了一系列知名模型在 NVIDIA GPU 上的性能。
支持的设备
TensorRT-LLM 在以下 GPU 上经过严格测试:
-
H100 -
L40S -
A100/ A30 -
V100 (试验阶段)
注意:如果是上面未列出 GPU,TensorRT-LLM 预计可在基于 Volta、Turing、Ampere、Hopper 和 Ada Lovelace 架构的 GPU 上工作。但是,可能存在某些限制。
关键特性
-
支持多头注意力( Multi-head Attention,MHA) -
支持多查询注意力 ( Multi-query Attention,MQA) -
支持分组查询注意力( Group-query Attention,GQA) -
支持飞行批处理(In-flight Batching) -
Paged KV Cache for the Attention -
支持 张量并行 -
支持 流水线并行 -
支持仅 INT4/INT8 权重量化 (W4A16 & W8A16) -
支持 SmoothQuant 量化 -
支持 GPTQ 量化 -
支持 AWQ 量化 -
支持 FP8 -
支持贪心搜索(Greedy-search) -
支持波束搜索(Beam-search) -
支持旋转位置编码(RoPE)
支持的模型
-
Baichuan -
Bert -
Blip2 -
BLOOM -
ChatGLM-6B -
ChatGLM2-6B -
Falcon -
GPT -
GPT-J -
GPT-Nemo -
GPT-NeoX -
LLaMA -
LLaMA-v2 -
MPT -
OPT -
SantaCoder -
StarCoder
支持的精度
TensorRT-LLM 支持各种数值精度。 但对其中一些数字精度的支持需要特定的GPU架构。
| FP32 | FP16 | BF16 | FP8 | INT8 | INT4 | |
|---|---|---|---|---|---|---|
| Volta (SM70) | Y | Y | N | N | Y | Y |
| Turing (SM75) | Y | Y | N | N | Y | Y |
| Ampere (SM80, SM86) | Y | Y | Y | N | Y | Y |
| Ada-Lovelace (SM89) | Y | Y | Y | Y | Y | Y |
| Hopper (SM90) | Y | Y | Y | Y | Y | Y |
对于目前发布的v0.5.0,并非所有模型都实现了对 FP8 和量化数据类型(INT8 或 INT4)的支持,具体如下所示。
| Model | FP32 | FP16 | BF16 | FP8 | W8A8 SQ | W8A16 | W4A16 | W4A16 AWQ | W4A16 GPTQ |
|---|---|---|---|---|---|---|---|---|---|
| Baichuan | Y | Y | Y | . | . | Y | Y | . | . |
| BERT | Y | Y | Y | . | . | . | . | . | . |
| BLOOM | Y | Y | Y | . | Y | Y | Y | . | . |
| ChatGLM | Y | Y | Y | . | . | . | . | . | . |
| ChatGLM-v2 | Y | Y | Y | . | . | . | . | . | . |
| Falcon | Y | Y | Y | . | . | . | . | . | . |
| GPT | Y | Y | Y | Y | Y | Y | Y | . | . |
| GPT-J | Y | Y | Y | Y | Y | Y | Y | Y | . |
| GPT-NeMo | Y | Y | Y | . | . | . | . | . | . |
| GPT-NeoX | Y | Y | Y | . | . | . | . | . | Y |
| LLaMA | Y | Y | Y | . | Y | Y | Y | Y | Y |
| LLaMA-v2 | Y | Y | Y | Y | Y | Y | Y | Y | Y |
| OPT | Y | Y | Y | . | . | . | . | . | . |
| SantaCoder | Y | Y | Y | . | . | . | . | . | . |
| StarCoder | Y | Y | Y | . | . | . | . | . | . |
TensorRT-LLM 的性能
注意:
下表中的数据作为参考进行提供,以帮助用户验证观察到的性能。这不是 TensorRT-LLM 提供的峰值性能。
不同模型基于 FP16 在 A100 GPUs 上的吞吐量:
| Model | Batch Size | TP (1) | Input Length | Output Length | Throughput (out tok/s) |
|---|---|---|---|---|---|
| GPT-J 6B | 64 | 1 | 128 | 128 | 3,679 |
| GPT-J 6B | 32 | 1 | 128 | 2048 | 1,558 |
| GPT-J 6B | 32 | 1 | 2048 | 128 | 526 |
| GPT-J 6B | 16 | 1 | 2048 | 2048 | 650 |
| LLaMA 7B | 64 | 1 | 128 | 128 | 3,486 |
| LLaMA 7B | 32 | 1 | 128 | 2048 | 1,459 |
| LLaMA 7B | 32 | 1 | 2048 | 128 | 529 |
| LLaMA 7B | 16 | 1 | 2048 | 2048 | 592 |
| LLaMA 70B | 64 | 4 | 128 | 128 | 1,237 |
| LLaMA 70B | 64 | 4 | 128 | 2048 | 1,181 |
| LLaMA 70B | 64 | 4 | 2048 | 128 | 272 |
| LLaMA 70B | 64 | 4 | 2048 | 2048 | 738 |
| Falcon 180B | 64 | 8 | 128 | 128 | 929 |
| Falcon 180B | 64 | 8 | 128 | 2048 | 923 |
| Falcon 180B | 64 | 8 | 2048 | 128 | 202 |
不同模型基于 FP16 在 A100 GPUs 上的首Token延迟:
针对批量大小为 1 时,第一个Token延迟的数据,代表终端用户感知在线流任务的延迟。
| Model | Batch Size | TP (1) | Input Length | 1st Token Latency (ms) |
|---|---|---|---|---|
| GPT-J 6B | 1 | 1 | 128 | 12 |
| GPT-J 6B | 1 | 1 | 2048 | 129 |
| LLaMA 7B | 1 | 1 | 128 | 16 |
| LLaMA 7B | 1 | 1 | 2048 | 133 |
| LLaMA 70B | 1 | 4 | 128 | 47 |
| LLaMA 70B | 1 | 4 | 2048 | 377 |
| Falcon 180B | 1 | 8 | 128 | 61 |
| Falcon 180B | 1 | 8 | 2048 | 509 |
结语
本文简要概述了TensorRT-LLM诞生的原因以及基本特征。码字不易,如果觉得有帮助,欢迎点赞收藏加关注。
参考文档:
-
https://github.com/NVIDIA/TensorRT-LLM/tree/v0.5.0 -
https://github.com/NVIDIA/TensorRT-LLM/blob/v0.5.0/docs/source/precision.md -
https://github.com/NVIDIA/TensorRT-LLM/blob/v0.5.0/docs/source/performance.md
相关文章:
-快速入门)
TensorRT-LLM保姆级教程(一)-快速入门
随着大模型的爆火,投入到生产环境的模型参数量规模也变得越来越大(从数十亿参数到千亿参数规模),从而导致大模型的推理成本急剧增加。因此,市面上也出现了很多的推理框架,用于降低模型推理延迟以及提升模型…...
-状态与信息流)
使用Redis构建简易社交网站(3)-状态与信息流
目的 本文目的:实现获取主页时间线和状态推送功能。(完整代码附在文章末尾) 相关知识 在我上一篇文章 《使用Redis构建简易社交网站(2)-处理用户关系》中提到了实现用户关注和取消关注功能。 那这篇文章将教会你掌握:1&#x…...

Python,非二进制的霍夫曼编码
一般来说,霍夫曼编码是二进制的,但是非二进制的也可以。本文中,通过修改N,可以得到任意进制的霍夫曼编码。 非二进制编码的作用:例如,设计九键输入法,希望根据拼音的概率来编码,常用…...
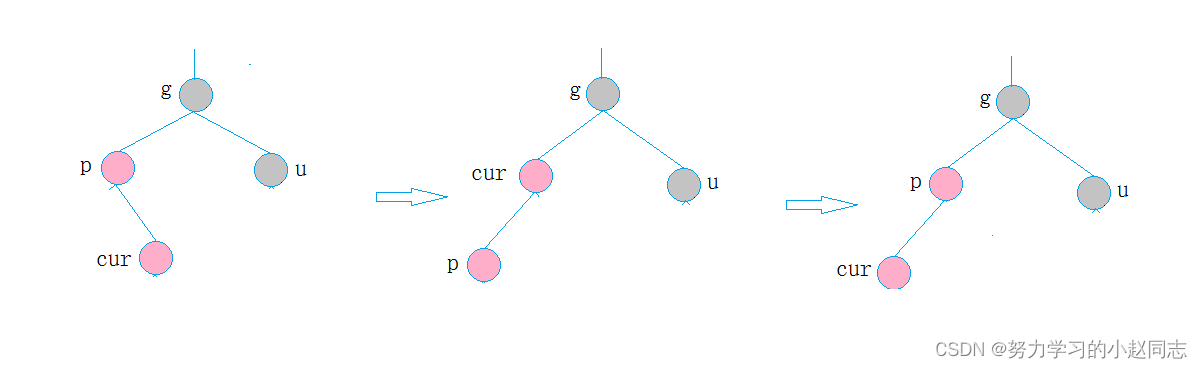
详解—[C++数据结构]—红黑树
目录 一、红黑树的概念 编辑二、红黑树的性质 三、红黑树节点的定义 四、红黑树结构 五、红黑树的插入操作 5.1. 按照二叉搜索的树规则插入新节点 5.2、检测新节点插入后,红黑树的性质是否造到破坏 情况一: cur为红,p为红,g为黑&…...

甘草书店记:6# 2023年10月31日 星期二 「梦想从来不是一夜之间实现的」
甘草书店 今天收到甘草书店第二版装修设计平面图,与理想空间越来越近。 于我而言,每一次世俗意义上所谓的成功都不如文艺作品中表现的那样让人欢腾雀跃。当你用尽120分努力,达到了冲刺满分的实力时,得个优秀的成绩也并不意外。 …...

基于Java SSM车辆租赁管理系统
现代生活方式下,人们经常需要租赁车辆,比如婚庆、自驾游等,车辆租赁公司应运而生,车辆租赁管理系统就是借助计算机对车辆租赁情况进行全面管理。系统的主要管理对象及操作有: 车辆信息:包括车辆类型、车辆名…...

侯捷C++八部曲(一,面向对象)
头文件和类的声明 inline inline修饰函数,是给编译器的一个建议,到底是否为inline由编译器来决定,inline修饰的函数在使用时是做简单的替换,这样就避免了一些函数栈空间的使用,从能提升效率。从另一种角度看ÿ…...

《数据库系统概论》学习笔记——王珊 萨师煊
第一章 绪论 一、数据库系统概述 1.数据库的4个基本概念 (1)数据 描述事物的符号记录称为数据 (2)数据库 存放数据的仓库 (3)数据库管理系统 主要功能: (1)数据定…...
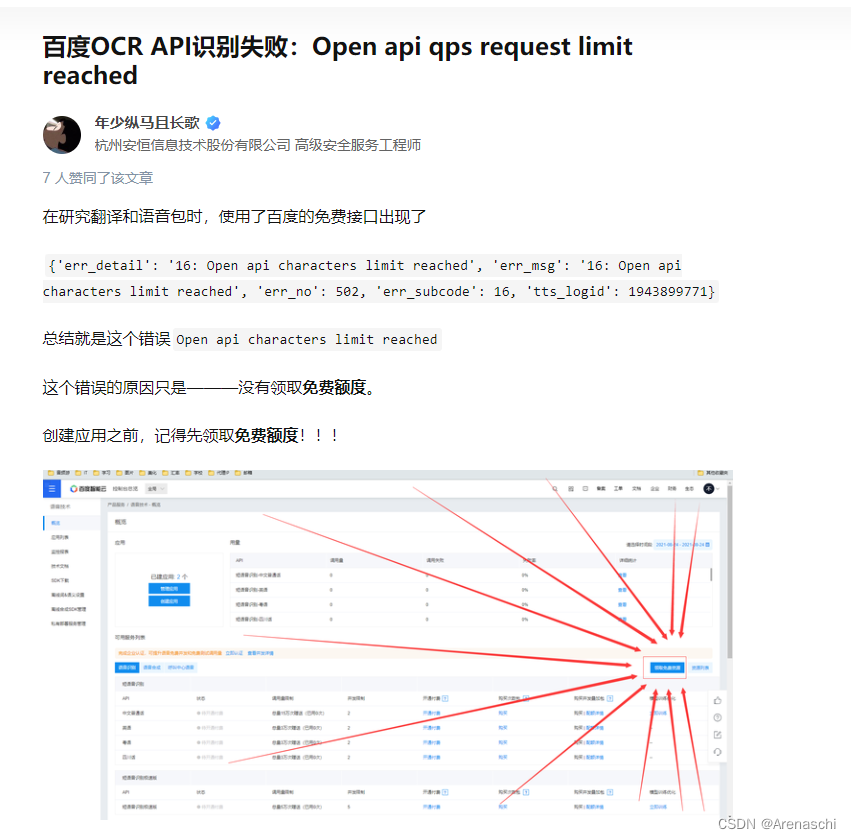
关于使用百度开发者平台处理语音朗读问题排查
错误信息:"convert_offline": false, "err_detail": "16: Open api characters limit reach 需要领取完 识别和合成都要有...

安全认证 | CISP和CISP-PTE的区别在哪里?
CISP和CISP-PTE的区别在哪里? 在国内安全信息认证体系中,虽然CISP认证与CISP-PTE认证都是中国信息安全测评中心负责颁发,均获得政府背景的认可,但二者还是有区别的。 今天就详细为大家介绍一下。 01 定义不同 ★ 注册信息安全专…...
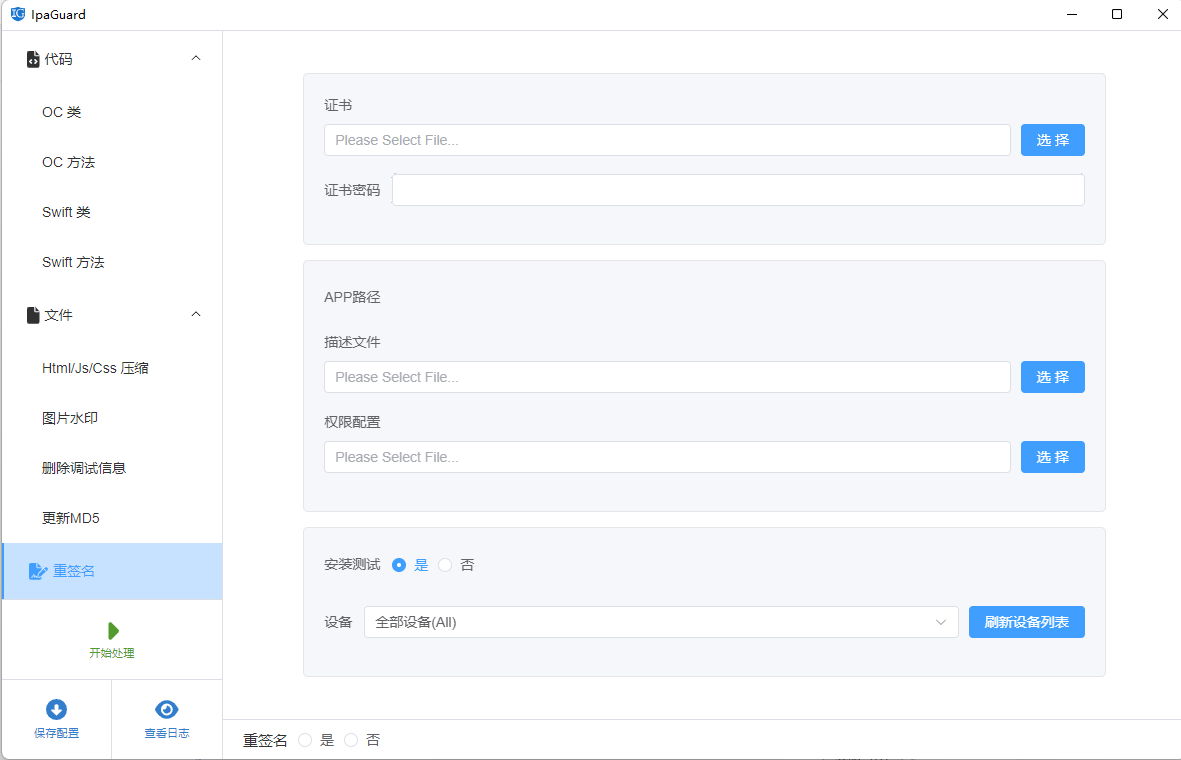
Unity3D 导出的apk进行混淆加固、保护与优化原理(防止反编译)
目录 前言: 准备资料: 正文: 1:打包一个带有签名的apk 2:对包进行反编译 3:使用ipaguard来对程序进行加固 前言: 对于辛辛苦苦完成的apk程序被人轻易的反编译了,那就得不偿…...

C语言扫雷小游戏
以下是一个简单的C语言扫雷小游戏的示例代码: #include <stdio.h>#include <stdlib.h>#include <time.h>#define BOARD_SIZE 10#define NUM_MINES 10int main() { int board[BOARD_SIZE][BOARD_SIZE]; int num_flags, num_clicks; int …...

用取样思想一探AIX上进程性能瓶颈
本篇文章也是我在解决客户问题时的一些思路,希望对读者有用。 本文与GDB也与DBX(AIX上的调试工具)无关,只是用到了前文《GDB技巧》中的思想:取样思想 客户问题: 原始问题是磁盘被占满了,通过…...
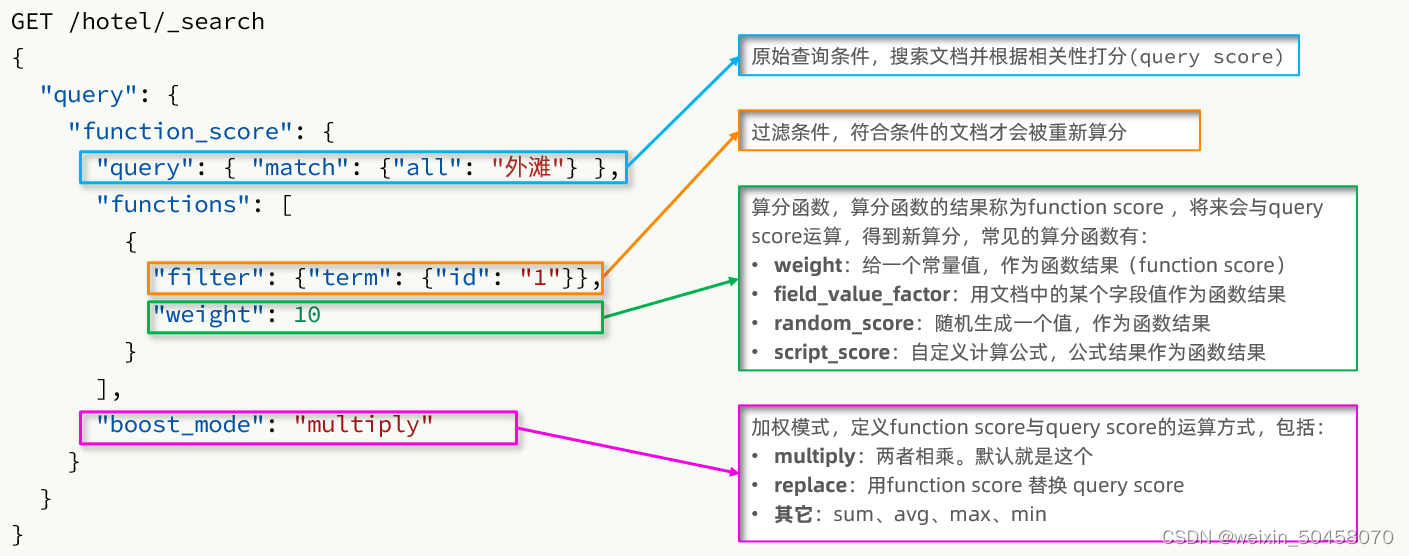
分布式搜索引擎elasticsearch(二)
1.DSL查询文档 elasticsearch的查询依然是基于JSON风格的DSL来实现的。 1.1.DSL查询分类 Elasticsearch提供了基于JSON的DSL(Domain Specific Language)来定义查询。常见的查询类型包括: 查询所有:查询出所有数据,一般测试用。例如:match_all 全文检索(full text)查…...

Tecplot绘制涡结构(Q准则)
文章目录 目的步骤1步骤2步骤3步骤4步骤5步骤6结果 目的 Tecplot绘制涡结构(Q准则判别)并用温度进行染色 Q准则计算公式 步骤1 步骤2 步骤3 步骤4 步骤5 步骤6 结果...
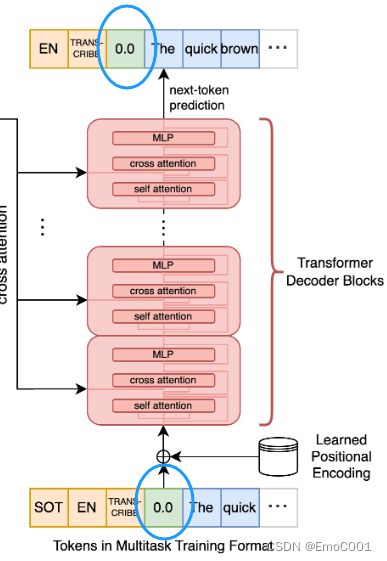
Whisper
文章目录 使后感Paper Review个人觉得有趣的Log Mel spectrogram & STFT Trainingcross-attention输入cross-attention输出positional encoding数据 Decoding为什么可以有时间戳的信息 Test code 使后感 因为运用里需要考虑到时效和准确性,类似于YOLOÿ…...

Android系统分析
Android工程师进阶第八课 AMS、WMS和PMS 一、Binder通信 【Android Framework系列】第2章 Binder机制大全_android binder-CSDN博客 Android Binder机制浅谈以及使用Binder进行跨进程通信的俩种方式(AIDL以及直接利用Binder的transact方法实现)_bind…...

五、关闭三台虚拟机的防火墙和Selinux
目录 1、关闭每台虚拟机的防火墙 2、关闭每台虚拟机的Selinux 2.1 什么是SELinux...

【从零开始学习Redis | 第六篇】爆改Setnx实现分布式锁
前言: 在Java后端业务中, 如果我们开启了均衡负载模式,也就是多台服务器处理前端的请求,就会产生一个问题:多台服务器就会有多个JVM,多个JVM就会导致服务器集群下的并发问题。我们在这里提出的解决思路是把…...

Kubernetes学习笔记-Part.05 基础环境准备
目录 Part.01 Kubernets与docker Part.02 Docker版本 Part.03 Kubernetes原理 Part.04 资源规划 Part.05 基础环境准备 Part.06 Docker安装 Part.07 Harbor搭建 Part.08 K8s环境安装 Part.09 K8s集群构建 Part.10 容器回退 第五章 基础环境准备 5.1.SSH免密登录 在master01、…...

2026年AI大模型API聚合平台技术横评:五大可靠选择与工程化选型参考
从GPT-5.5、Claude Opus 4.7到Gemini 3.1 Pro,新一代大模型迭代迅速,但在开发落地过程中,“接入复杂、成本高昂、网络波动”成为了许多开发团队面临的实际挑战。结合近期技术测试与行业观察,本文尝试从开发者工程实践的视角&#…...

知识付费浪潮下的技术学习:是捷径,还是新的信息茧房?
当“知识”成为一种商品打开手机,各类技术公众号、知识星球、极客时间专栏、慕课网实战课、B站充电视频……铺天盖地的“测试开发进阶”“性能测试大师班”“自动化测试框架实战”正以9.9元、199元、3999元的价格被明码标价。作为一名软件测试工程师,我们…...

抖音无水印下载神器:douyin-downloader完整指南,轻松保存高清视频
抖音无水印下载神器:douyin-downloader完整指南,轻松保存高清视频 【免费下载链接】douyin-downloader A practical Douyin downloader for both single-item and profile batch downloads, with progress display, retries, SQLite deduplication, and …...

Spratt Skills:基于LLM规划与代码执行的OpenClaw家庭自动化架构实践
1. 项目概述:Spratt Skills,一个为OpenClaw打造的家庭自动化基础设施套件 如果你正在使用OpenClaw,并且已经厌倦了让LLM(大语言模型)去处理那些它天生就不擅长的事情——比如定时发送消息、轮询航班状态、或者可靠地写…...

3分钟掌握完全离线的实时语音转文字:TMSpeech让你彻底告别云端依赖
3分钟掌握完全离线的实时语音转文字:TMSpeech让你彻底告别云端依赖 【免费下载链接】TMSpeech 腾讯会议摸鱼工具 项目地址: https://gitcode.com/gh_mirrors/tm/TMSpeech 在数字时代,语音转文字已成为现代办公和学习的高效助手,但你是…...

2.2 本地文件读取
本章学习目标: 知道CSV、Excel、JSON三种文件分别怎么读、会遇到什么常见问题理解每种文件格式的“坑”在哪里,以及如何向AI描述解决方案学会用“人话”告诉AI你要做什么,让AI生成代码不需要记住任何函数名或参数,只需要知道“有什…...

网站国产化改造怎么做?深度解读国产化替代路径与CMS推荐
在近年来科技领域的舆论场中,“国产化”无疑是出现频率最高的关键词之一。从芯片到操作系统,从数据库到办公软件,再到企业对外展示的门户——网站,国产化替代已从“可选项”变成了很多行业的“必答题”。但国产化仅仅是“换个牌子…...

3个步骤解决Mac Boot Camp驱动部署难题:Brigadier自动化方案详解
3个步骤解决Mac Boot Camp驱动部署难题:Brigadier自动化方案详解 【免费下载链接】brigadier Fetch and install Boot Camp ESDs with ease. 项目地址: https://gitcode.com/gh_mirrors/bri/brigadier 还在为Mac电脑安装Windows系统后的驱动问题而烦恼吗&…...

照片去背景的方法有哪些?2026年最全工具推荐与实用指南
前两天有个朋友问我,怎样能快速把证件照的底色换掉,还有电商卖家想给商品图去背景。我才意识到,现在还有很多人不知道照片去背景有这么多方便的办法。与其逐个讲解,我决定写篇文章,把我这些年试过的各种照片去背景的方…...
·面经深度解析)
前端八股文面经大全:上海威派格前端实习(2026-05-07)·面经深度解析
前言 大家好,我是木斯佳。 相信很多人都感受到了,在AI浪潮的席卷之下,前端领域的门槛在变高,纯粹的“增删改查”岗位正在肉眼可见地减少。曾经热闹非凡的面经分享,如今也沉寂了许多。但我们都知道,市场的…...