GPT实战系列-大模型训练和预测,如何加速、降低显存
GPT实战系列-大模型训练和预测,如何加速、降低显存
不做特别处理,深度学习默认参数精度为浮点32位精度(FP32)。大模型参数庞大,10-1000B级别,如果不注意优化,既耗费大量的显卡资源,也耗费大量的训练时间,AI算法中心的训练的投入都给英伟达送钱去了。有的地方32位精度没有太大必要,这就是浮点精度和量化的动力来源。
大模型的训练和预测过程中,如何加快训练速度?如何降低显存占用?
有哪些简单,快速上手的方法?
文章目录
- GPT实战系列-大模型训练和预测,如何加速、降低显存
- 混合精度
- 精度数位表示
- 转换流程
- 量化
- 量化训练
- 量化推理
混合精度
混合精度训练(mixed precision training)是一种加速深度学习训练的技术。其主要思想是在精度降低可忍受的范围内,使用较低精度的浮点数(如FP16)来表示神经网络中的权重和激活值,从而减少内存使用和计算开销,进而加速训练过程。
混合精度训练的实现可以分为以下几个步骤:
- 将FP32的权重转换为FP16格式,然后进行前向计算,得到FP32的损失(loss)。
- 使用FP16计算梯度。
- 将梯度转换为FP32格式,并将其更新到权重上。
由于FP16精度较低,表示的数值范围小,可能会导致精度损失,因此在混合精度训练中,需要使用一些技巧来保持模型的精确性。例如,可以使用梯度缩放(GradScaler)来控制梯度的大小,以避免梯度下降过快而影响模型的准确性。
精度数位表示
- FP32:单精度浮点数,使用32位二进制数表示,其中1位表示符号位,8位表示指数位,23位表示尾数位,能够表示的数值范围为 ± 3.4 × 1 0 38 ±3.4×10^{38} ±3.4×1038。
- FP16:半精度浮点数,使用16位二进制数表示,其中1位表示符号位,5位表示指数位,10位表示尾数位,能够表示的数值范围为 ± 2 15 ±2^{15} ±215。
- FP64:双精度浮点数,使用64位二进制数表示,其中1位表示符号位,11位表示指数位,52位表示尾数位,能够表示的数值范围为 ± 1.8 × 1 0 308 ±1.8×10^{308} ±1.8×10308。
- INT8:8位整数,其中1位表示符号位,能够表示的数值范围为 $ -128到127$。
- INT4:4位整数,其中1位表示符号位,能够表示的数值范围为 − 8 到 7 -8到7 −8到7。

混合精度训练的流程如下:
- 将FP32的权重转换为FP16格式,然后进行前向计算,得到FP32的损失(loss)。
- 使用FP16计算梯度。
- 将梯度转换为FP32格式,并将其更新到权重上。
在训练过程中,使用autocast将输入和输出转换为FP16格式,使用GradScaler对损失值进行缩放,以避免梯度下降过快而影响模型的准确性。
量化
量化是一种通过整型数值表示浮点的计算方式,减少数字表示的位数来减小模型存储量和计算量的方法。在深度学习中,通常使用32位浮点数来表示权重和激活值。但是,这种精度可能会导致计算和存储的开销非常高。因此,量化使用更短的整数表示权重和激活值,从而减少内存和计算开销。
量化使用整型数值,避免使用浮点处理,加速计算过程,同时也减少用于表示数字或值的比特数,降低存储的技术。将通过将权重存储在低精度数据类型中,来降低模型参数的训练、预测计算过程和模型和中间缓存的存储空间。由于量化减少了模型大小,因此它有利于在CPU或嵌入式系统等资源受限的设备上部署模型。
一种常用的方法是将模型权重从原始的16位浮点值量化为精度较低的8位整数值。

GPT,Baichuan2,ChatGLM3等大模型LLM已经展示出色的能力,但是它需要大量的CPU和内存,其中使用一种方法可以使用量化来压缩这些模型,以减少内存占用并加速计算推理,并且尽量保持模型精度性能。
在量化过程中,可以使用两种方法:动态量化和静态量化。
- 动态量化在运行时收集数据,并根据数据动态地量化模型。
- 静态量化在训练过程中对模型进行量化,并在推理时应用量化。
量化会导致模型精确度下降,因为更低的精度可能会导致舍入误差。因此,在量化期间,需要进行一些技巧来保持模型的准确程度,例如:对权重进行缩放或使用动态范围量化。
同时,在量化模型之前,需要对模型进行测试,确保精确度可以接受。另外,不是所有的模型都可以被量化,只有支持动态量化的模型才可以使用该方法进行量化。
例如:load_in_8bit=True
from transformers import AutoTokenizer, AutoModel model = AutoModel.from_pretrained("THUDM/chatglm3-6b",revision='v0.1.0',load_in_8bit=True,trust_remote_code=True,device_map="auto")
总的来说,量化是一种非常有用的方法,可以减少模型的存储和计算开销,提高模型在设备上的执行效率。
量化训练
在深度学习中,量化是一种通过减少数字表示的位数来减小模型存储量和计算量的方法。在使用混合精度训练时,可以将模型权重和梯度从FP32转换为FP16,以节省内存和加速训练。同样的思路,量化训练可以将激活值转换为更短的整数,从而减少内存和计算开销。
PyTorch中提供一些量化训练的工具和API,例如QAT(量化感知训练),使用动态范围量化等。其中,使用Adam8bit进行量化训练是一种方法。
量化推理
使用load_in_8bit方法可以实现模型的量化。该方法可以将模型权重和激活值量化为8位整数,从而减少内存和计算开销。具体实现方法如下:
import torch
from transformers import AutoModel# 加载模型
model = AutoModel.from_pretrained('bert-base-uncased',load_in_8bit=True)
需要注意的是,使用load_in_8bit方法量化模型可能会导致模型精确度下降。另外,不是所有的模型都可以被量化,只有支持动态量化的模型才可以使用该方法进行量化。
点个赞 点个赞 点个赞
觉得有用 收藏 收藏 收藏
End
GPT专栏文章:
GPT实战系列-ChatGLM2部署Ubuntu+Cuda11+显存24G实战方案
GPT实战系列-Baichuan2本地化部署实战方案
GPT实战系列-ChatGLM3本地部署CUDA11+1080Ti+显卡24G实战方案
GPT实战系列-如何用自己数据微调ChatGLM2模型训练
GPT实战系列-GPT训练的Pretraining,SFT,Reward Modeling,RLHF
GPT实战系列-P-Tuning本地化训练ChatGLM2等LLM模型,到底做了什么?(二)
GPT实战系列-P-Tuning本地化训练ChatGLM2等LLM模型,到底做了什么?(一)
GPT实战系列-ChatGLM2模型的微调训练参数解读
GPT实战系列-GPT训练的Pretraining,SFT,Reward Modeling,RLHF
决策引擎专栏:
Falcon构建轻量级的REST API服务
决策引擎-利用Drools实现简单防火墙策略
相关文章:
GPT实战系列-大模型训练和预测,如何加速、降低显存
GPT实战系列-大模型训练和预测,如何加速、降低显存 不做特别处理,深度学习默认参数精度为浮点32位精度(FP32)。大模型参数庞大,10-1000B级别,如果不注意优化,既耗费大量的显卡资源,…...

SQL Sever 基础知识 - 数据排序
SQL Sever 基础知识 - 二 、数据排序 二 、对数据进行排序第1节 ORDER BY 子句简介第2节 ORDER BY 子句示例2.1 按一列升序对结果集进行排序2.2 按一列降序对结果集进行排序2.3 按多列对结果集排序2.4 按多列对结果集不同排序2.5 按不在选择列表中的列对结果集进行排序2.6 按表…...

vscode配置使用 cpplint
标题安装clang-format和cpplint sudo apt-get install clang-format sudo pip3 install cpplint标题以下settings.json文件放置xxx/Code/User目录 settings.json {"sync.forceDownload": false,"workbench.sideBar.location": "right","…...
C++ 系列 第四篇 C++ 数据类型上篇—基本类型
系列文章 C 系列 前篇 为什么学习C 及学习计划-CSDN博客 C 系列 第一篇 开发环境搭建(WSL 方向)-CSDN博客 C 系列 第二篇 你真的了解C吗?本篇带你走进C的世界-CSDN博客 C 系列 第三篇 C程序的基本结构-CSDN博客 前言 面向对象编程(OOP)的…...
C++ 指针详解
目录 一、指针概述 指针的定义 指针的大小 指针的解引用 野指针 指针未初始化 指针越界访问 指针运算 二级指针 指针与数组 二、字符指针 三、指针数组 四、数组指针 函数指针 函数指针数组 指向函数指针数组的指针 回调函数 指针与数组 一维数组 字符数组…...

.locked、locked1勒索病毒的最新威胁:如何恢复您的数据?
导言: 网络安全问题变得愈加严峻。.locked、locked1勒索病毒是近期备受关注的一种恶意软件,给用户的数据带来了巨大威胁。本文将深入探讨.locked、locked1勒索病毒的特征,探讨如何有效恢复被其加密的数据,并提供一些建议…...
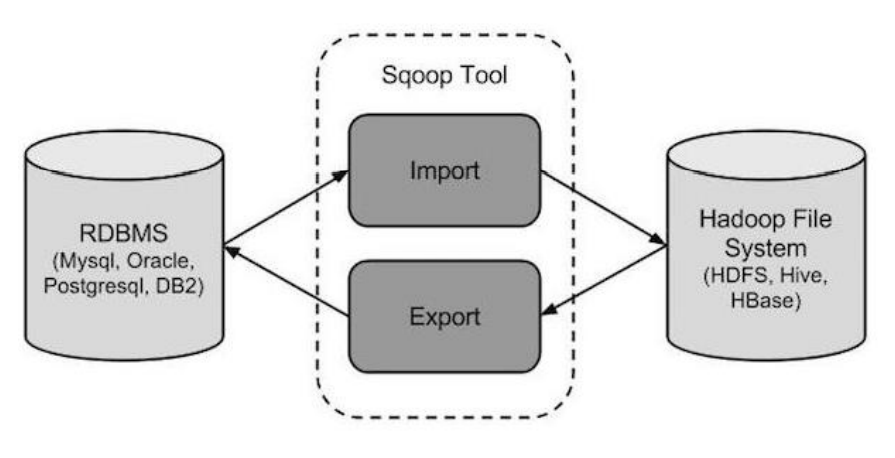
Apache Sqoop使用
1. Sqoop介绍 Apache Sqoop 是在 Hadoop 生态体系和 RDBMS 体系之间传送数据的一种工具。 Sqoop 工作机制是将导入或导出命令翻译成 mapreduce 程序来实现。在翻译出的 mapreduce 中主要是对 inputformat 和 outputformat 进行定制。 Hadoop 生态系统包括:HDFS、Hi…...

【UGUI】实现UGUI背包系统的六个主要交互功能
在这篇教程中,我们将详细介绍如何在Unity中实现一个背包系统的六个主要功能:添加物品、删除物品、查看物品信息、排序物品、搜索物品和使用物品。让我们开始吧! 一、添加物品 首先,我们需要创建一个方法来添加新的物品到背包中。…...
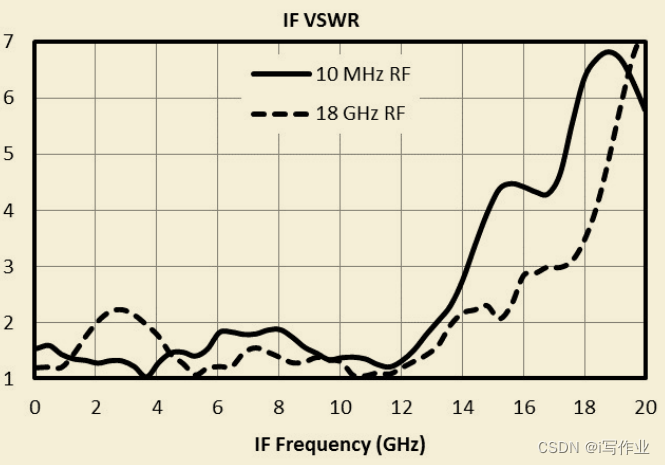
电压驻波比
电压驻波比 关于IF端口的电压驻波比 一个信号变频后,从中频端口输出,它的输出跟输入是互异的。这个电压柱波比反映了它输出的能量有多少可以真正的输送到后端连接的器件或者设备。...

Open3D 最小二乘拟合二维直线(直接求解法)
目录 一、算法原理二、代码实现三、结果展示本文由CSDN点云侠原创,原文链接。爬虫网站自重。 一、算法原理 平面直线的表达式为: y = k x + b...
)
面试题目总结(二)
1. IoC 和 AOP 的区别 控制反转(Ioc) 和面向切面编程(AOP) 是两个不同的概念,它们在软件设计中有着不同的应用和目的。 IoC 是一种基于对象组合的编程模式,通过将对象的创建、依赖关系和生命周期等管理权交给外部容器或框架来实现程序间的解耦。IoC 的…...

TrustZone概述
目录 一、概述 1.1 在开始之前 二、什么是TrustZone? 2.1 Armv8-M的TrustZone 2.2 Armv9-A Realm Management Ext...

[go 面试] Go Kit中读取原始HTTP请求体的方法
关注公众号【爱发白日梦的后端】分享技术干货、读书笔记、开源项目、实战经验、高效开发工具等,您的关注将是我的更新动力! 在Go Kit中,如果你想读取未序列化的HTTP请求体,可以使用标准的net/http包来实现。以下是一个示例,演示了如何完成这个任务: package mainimport …...

小程序如何刷新当前页面?
在小程序中,刷新当前页面通常有两种方法: 使用 wx.navigateBack 方法: wx.navigateBack({delta: 1 }) 这将返回上一页,并刷新页面。你可以通过调整 delta 参数来控制返回的页面数。例如,如果你想要返回到两页之前的页…...

ChatGPT使用路径:从新手到专家的指南
原文&精华文章&转载注明:ChatGPT与日本首相交流核废水事件-精准Prompt... hello,我是小索奇,有任何问题或者需要帮助的都可以在这里找到我或者留言哈 一、初识ChatGPT 什么是ChatGPT? ChatGPT是一种大型语言模型&…...
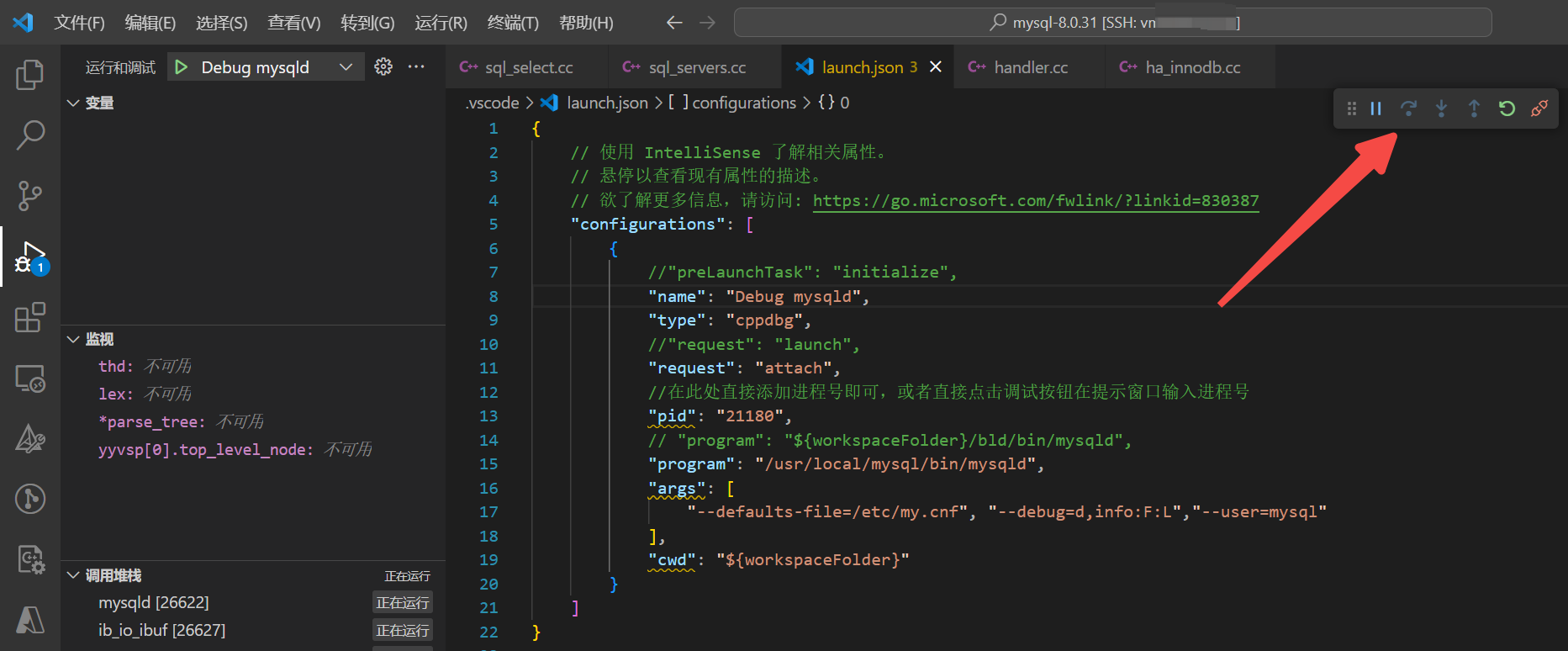
VsCode 调试 MySQL 源码
1. 启动 MySQL 2. 查看 MySQL 进程号 [root ~]# ps -ef | grep mysqld root 21479 1 0 Nov01 ? 00:00:00 /bin/sh /usr/local/mysql/bin/mysqld_safe --datadir/usr/local/mysql/data --pid-file/usr/local/mysql/data/mysqld.pid root 26622 21479 0 …...

Mysql中的正经行锁、间隙锁和临键锁
行锁、间隙锁和临键锁是数据库中的三种不同类型的锁,三者都属于行锁,第一个一般叫他正经的行锁(《Mysql是怎样运行的》一书中的说法)。 行锁(Row Lock):行锁是指对数据表中的某一行进行的锁定操…...

最强AI之风袭来,你爱了吗?
2017年,柯洁同阿尔法狗人机大战,AlphaGo以3比0大获全胜,一代英才泪洒当场...... 2019年,换脸哥视频“杨幂换朱茵”轰动全网,时至今日AI换脸仍热度只增不减; 2022年,ChatGPT一经发布便轰动全球&a…...

时间序列预测实战(二十三)进阶版LSTM多元和单元预测(课程设计毕业设计首选)
一、本文介绍 本篇文章给大家带来的是利用我个人编写的架构进行LSTM模型进行时间序列建模(专门为了时间序列领域新人编写的架构,简单且不同于市面上大家用GPT写的代码),包括结果可视化、支持单元预测、多元预测、模型拟合效果检测…...
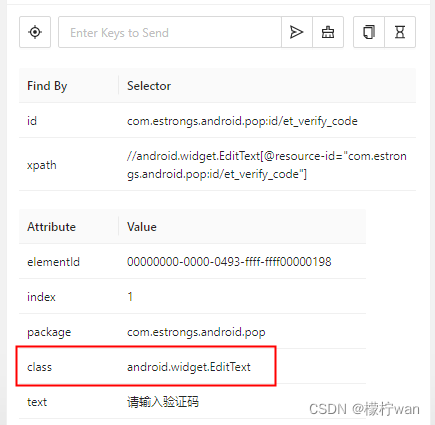
Python之Appium 2自动化测试(Android篇)
一、环境搭建及准备工作 1、Appium 2 环境搭建 请参考另一篇文章: Windows系统搭建Appium 2 和 Appium Inspector 环境 2、安装 Appium-Python-Client,版本要求3.0及以上 pip install Appium-Python-ClientVersion: 3.1.03、手机连接电脑,并在dos窗口…...

Android系统开发避坑:为什么你改了config.xml,导航栏还是不显示?
Android系统导航栏显示失效的深度排查指南 当你熬夜修改了config.xml文件,满怀期待地刷入系统,却发现导航栏依然不见踪影——这种挫败感我太熟悉了。导航栏显示问题看似简单,实则涉及Android资源覆盖机制的复杂层级。本文将带你深入AOSP的底层…...

从格式混乱到工作流重构:Cloud Document Converter如何重塑飞书文档迁移体验
从格式混乱到工作流重构:Cloud Document Converter如何重塑飞书文档迁移体验 【免费下载链接】cloud-document-converter Convert Lark Doc to Markdown 项目地址: https://gitcode.com/gh_mirrors/cl/cloud-document-converter 你是否曾花费数小时手动复制飞…...

Windows平台ADB驱动终极安装指南:3分钟搞定Android开发环境
Windows平台ADB驱动终极安装指南:3分钟搞定Android开发环境 【免费下载链接】Latest-adb-fastboot-installer-for-windows A Simple Android Driver installer tool for windows (Always installs the latest version) 项目地址: https://gitcode.com/gh_mirrors/…...

生成式AI破解基因型-表型关联:AIPheno项目实战解析
1. 项目概述:当生成式AI遇见基因表型 如果你在生物信息学或者遗传育种领域工作,最近几年一定被“基因型-表型关联”这个老大难问题折磨过。我们手里有海量的基因组测序数据(基因型),也积累了大量的生物体性状数据&…...

5大架构决策原则:ComfyUI-Manager如何平衡技术演进与系统兼容性
5大架构决策原则:ComfyUI-Manager如何平衡技术演进与系统兼容性 【免费下载链接】ComfyUI-Manager ComfyUI-Manager is an extension designed to enhance the usability of ComfyUI. It offers management functions to install, remove, disable, and enable vari…...
)
别再只点灯了!用ESP32和WebServer库做个智能家居控制面板原型(附完整代码)
用ESP32打造智能家居控制面板:从网页控制到硬件交互实战 想象一下,清晨醒来无需下床,轻点手机就能打开窗帘、调节灯光;离家时一键关闭所有电器,还能实时查看家中温湿度——这些看似未来的场景,如今用一块ES…...

【独家首发】DeepSeek-VL与R1在HumanEval上的性能断层:87.3 vs 62.1分,这15.2分差距究竟卡在哪一行代码?
更多请点击: https://intelliparadigm.com 第一章:DeepSeek-VL与R1在HumanEval上的性能断层现象 HumanEval 是评估代码生成模型逻辑正确性的黄金基准,其测试集由 164 道手写 Python 编程题构成,每题包含函数签名、文档字符串和若…...

从图文到视频:用 Python 打造公众号文章自动化转视频号的爆款流水线
摘要:本文详解一套完全基于开源工具(Python + edge-tts + ffmpeg)的自动化系统,可将任意微信公众号文章一键转换为横屏/竖屏视频,直接用于视频号分发。全程无需剪辑软件、无需出镜、无需复杂配置,5 分钟部署,1 条命令生成专业级视频。 🔥 为什么你需要这个? 在 AIGC…...

寄生电感容易被忽略,却是电路不稳定的隐形元凶
调试电路板的时候,最让人抓狂的并不是那些明面上能查到文档的参数问题。示波器一抓波形,明明电源电压已经稳定,负载也没动,可偏偏就是有那种挥之不去的毛刺,幅度不大,频率不低,排查了半天才发现…...
)
手把手教你用MOS管搭建防反接电路:从原理图到PCB布局的避坑指南(以立创EDA为例)
从零构建MOS管防反接电路:立创EDA实战全流程解析 电源反接是电子设计中最常见的"低级错误"之一,却可能造成毁灭性后果。想象一下:你花费数周完成的智能家居控制器,因为电池装反而瞬间烧毁主控芯片——这种场景在创客社区…...