Python 重要数据类型
目录
列表
序列操作
列表内置方法
列表推到式
字典
声明字典
字典基本操作
列表内置方法
字典进阶使用
字典生成式
附录
列表
在实际开发中,经常需要将一组(不只一个)数据存储起来,以便后边的代码使用。列表就是这样的一个数据结构。
列表会将所有元素都放在一对中括号[ ]里面,相邻元素之间用逗号,分隔,如下所示:
[element1, element2, element3, ..., elementn]不同于C,java等语言的数组,python的列表可以存放不同的,任意的数据类型对象。
l = [123,"yuan",True]
print(l,type(l))# 注意
a,b = [1,2]
print(a,b)序列操作
列表是 Python 序列的一种,我们可以使用索引(Index)访问列表中的某个元素(得到的是一个元素的值),也可以使用切片访问列表中的一组元素(得到的是一个新的子列表)。
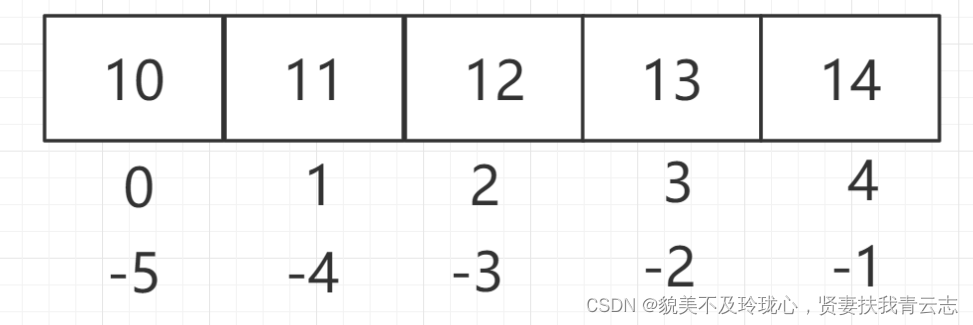
- 索引求值
l = [10,11,12,13,14]
print(l[2]) # 12
print(l[-1]) # 14- 切片操作
l = [10,11,12,13,14]
print(l[2:5])
print(l[-3:-1])
print(l[:3])
print(l[1:])
print(l[:])
print(l[2:4])
print(l[-3:-1])
print(l[-1:-3])
print(l[-1:-3:-1])
print(l[::2])1、取出的元素数量为:结束位置 - 开始位置;
2、取出元素不包含结束位置对应的索引,列表最后一个元素使用
list[len(slice)]获取;3、当缺省开始位置时,表示从连续区域开头到结束位置;
4、当缺省结束位置时,表示从开始位置到整个连续区域末尾;
5、两者同时缺省时,与列表本身等效;
6、step为正,从左向右切,为负从右向左切。
- 判断成员是否存在
in 关键字检查某元素是否为序列的成员
l = [10,11,12,13,14]
print(20 in l) # False
print(12 in l) # True- 相加
l1 = [1,2,3]
l2 = [4,5,6]
print(l1+l2) # [1, 2, 3, 4, 5, 6]- 循环列表
for name in ["张三",'李四',"王五"]:print(name)for i in range(10): # range函数: range(start,end,step)print(i)# 基于for循环从100打印到1
for i in range(100,0,-1):print(i)列表内置方法
l = [1,2,3]| 方法 | 作用 | 示例 | 结果 |
|---|---|---|---|
append() | 向列表追加元素 | l.append(4) | l:[1, 2, 3, 4] |
insert() | 向列表任意位置添加元素 | l.insert(0,100) | l:[100, 1, 2, 3] |
extend() | 向列表合并一个列表 | l.extend([4,5,6]) | l:[1, 2, 3, 4, 5, 6] |
pop() | 根据索引删除列表元素(为空删除最后一个元素) | l.pop(1) | l:[1, 3] |
remove() | 根据元素值删除列表元素 | l.remove(1) | l:[2, 3] |
clear() | 清空列表元素 | l.clear() | l:[] |
sort() | 排序(升序) | l.sort() | l:[1,2,3] |
reverse() | 翻转列表 | l.reverse() | l:[3,2,1] |
count() | 元素重复的次数 | l.count(2) | 返回值:1 |
index() | 查找元素对应索引 | l.index(2) | 返回值:1 |
# 增删改查: [].方法()# (1) ******************************** 增(append,insert,extend) ****************
l1 = [1, 2, 3]
# append方法:追加一个元素
l1.append(4)
print(l1) # [1, 2, 3, 4]
# insert(): 插入,即在任意位置添加元素
l1.insert(1, 100) # 在索引1的位置添加元素100
print(l1) # [1, 100, 2, 3, 4]
# 扩展一个列表:extend方法
l2 = [20, 21, 22, 23]
# l1.append(l2)
l1.extend(l2)
print(l1) # [1, 100, 2, 50, 3, 4,[20,21,22,23]]
# 打印列表元素个数python内置方法:
print(len(l1))# (2) ******************************** 删(pop,remove,clear) **********************l4 = [10, 20, 30, 40, 50]
# 按索引删除:pop,返回删除的元素
# ret = l4.pop(2)
# print(ret)
# print(l4) # [10, 20, 40, 50]
# 按着元素值删除
l4.remove(30)
print(l4) # [10, 20, 40, 50]
# 清空列表
l4.clear()
print(l4) # []# (3) ******************************** 修改(没有内置方法实现修改,只能基于索引赋值) ********l5 = [10, 20, 30, 40, 50]
# 将索引为1的值改为200
l5[1] = 200
print(l5) # [10, 200, 30, 40, 50]
# 将l5中的40改为400 ,step1:查询40的索引 step2:将索引为i的值改为400
i = l5.index(40) # 3
l5[i] = 400
print(l5) # [10, 20, 30, 400, 50]# (4) ******************************** 查(index,sort) *******************************l6 = [10, 50, 30, 20,40]
l6.reverse() # 只是翻转 [40, 20, 30, 50, 10]
print(l6) # []
# # 查询某个元素的索引,比如30的索引
# print(l6.index(30)) # 2
# 排序
# l6.sort(reverse=True)
# print(l6) # [50, 40, 30, 20, 10]列表推到式
列表推导式(又称列表解析式)提供了一种简明扼要的方法来创建列表。
它的结构是在一个中括号里包含一个表达式,然后是一个for语句,然后是 0 个或多个 for 或者 if 语句。那个表达式可以是任意的,意思是你可以在列表中放入任意类型的对象。返回结果将是一个新的列表,在这个以 if 和 for 语句为上下文的表达式运行完成之后产生。
列表推导式的执行顺序:各语句之间是嵌套关系,左边第二个语句是最外层,依次往右进一层,左边第一条语句是最后一层。
[x*y for x in range(1,5) if x > 2 for y in range(1,4) if y < 3]for x in range(1,5)if x > 2for y in range(1,4)if y < 3x*y字典
字典是Python提供的唯一内建的映射(Mapping Type)数据类型。
声明字典
python使用 { } 创建字典,由于字典中每个元素都包含键(key)和值(value)两部分,因此在创建字典时,键和值之间使用冒号:分隔,相邻元素之间使用逗号,分隔,所有元素放在大括号{ }中。
使用{ }创建字典的语法格式如下:
dictname = {'key':'value1', 'key2':'value2', ...}1、同一字典中的各个键必须唯一,不能重复。
2、字典是键值对是无序的,但在3.6版本后,字典默认做成有序的了,这是新的版本特征。
字典基本操作
# (1) 查键值
print(book["title"]) # 返回字符串 西游记
print(book["authors"]) # 返回列表 ['rain', 'yuan']# (2) 添加或修改键值对,注意:如果键存在,则是修改,否则是添加
book["price"] = 299 # 修改键的值
book["publish"] = "北京出版社" # 添加键值对# (3) 删除键值对 del 删除命令
print(book)
del book["publish"]
print(book)
del book
print(book)# (4) 判断键是否存在某字典中
print("price" in book)# (5) 循环
for key in book:print(key,book[key])列表内置方法
d = {"name":"yuan","age":18}| 方法 | 作用 | 示例 | 结果 |
|---|---|---|---|
get() | 查询字典某键的值, 取不到返回默认值 | d.get("name",None) | "yuan" |
setdefault() | 查询字典某键的值, 取不到给字典设置键值,同时返回设置的值 | d.setdefault("age",20) | 18 |
keys() | 查询字典中所有的键 | d.keys() | ['name','age'] |
values() | 查询字典中所有的值 | d.values() | ['yuan', 18] |
items() | 查询字典中所有的键和值 | d.items() | [('name','yuan'), ('age', 18)] |
pop() | 删除字典指定的键值对 | d.pop(‘age’) | {'name':'yuan'} |
popitem() | 删除字典最后的键值对 | d.popitem() | {'name':'yuan'} |
clear() | 清空字典 | d.clear() | {} |
update() | 更新字典 | t={"gender":"male","age":20} d.update(t) | {'name':'yuan', 'age': 20, 'gender': 'male'} |
测试代码
dic = {"name": "yuan", "age": 22, "sex": "male"}# (1)查字典的键的值print(dic["names"]) # 会报错
name = dic.get("names")
sex = dic.get("sexs", "female")
print(sex)
print(dic.keys()) # 返回值:['name', 'age', 'sex']
print(dic.values()) # 返回值:['yuan', 22, 'male']
print(dic.items()) # [('name', 'yuan'), ('age', 22), ('sex', 'male')]# setdefault取某键的值,如果能取到,则返回该键的值,如果没有改键,则会设置键值对
print(dic.setdefault("name")) # get()不会添加键值对 ,setdefault会添加
print(dic.setdefault("height", "180cm"))
print(dic)# (2)删除键值对 pop popitemsex = dic.pop("sex") # male
print(sex) # male
print(dic) # {'name': 'yuan', 'age': 22}dic.popitem() # 删除最后一个键值对
print(dic) # {'name': 'yuan'}dic.clear() # 删除键值对# (3) 添加或修改 update
add_dic = {"height": "180cm", "weight": "60kg"}
dic.update(add_dic)
print(dic) # {'name': 'yuan', 'age': 22, 'sex': 'male', 'height': '180cm', 'weight': '60kg'}update_dic = {"age": 33, "height": "180cm", "weight": "60kg"}
dic.update(update_dic)
print(dic) # {'name': 'yuan', 'age': 33, 'sex': 'male', 'height': '180cm', 'weight': '60kg'}# (4) 字典的循环dic = {"name": "yuan", "age": 22, "sex": "male"}# 遍历键值对方式1
# for key in dic: # 将每个键分别赋值给key
# print(key, dic.get(key))# 遍历键值对方式2# for i in dic.items(): # [('name', 'yuan'), ('age', 22), ('sex', 'male')]
# print(i[0],i[1])# 关于变量补充
# x = (10, 20)
# print(x, type(x)) # (10, 20) <class 'tuple'>
# x, y = (10, 20)
# print(x, y)for key, value in dic.items():print(key, value)字典进阶使用
# 案例1:列表嵌套字典data = [{"name": "rain", "age": 22},{"name": "eric", "age": 32},{"name": "alvin", "age": 24},
]# 循环data,每行按着格式『姓名:rain,年龄:22』将每个学生的信息逐行打印for stu_dic in data: # data是一个列表# print(stu_dic) #print("『姓名:%s,年龄:%s』" % (stu_dic.get("name"), stu_dic.get("age")))# 将data中第二个学生的年龄查询出来print(data[1].get("age"))# 案例2:字典嵌套字典data2 = {1001: {"name": "rain", "age": 22},1002: {"name": "eric", "age": 32},1003: {"name": "alvin", "age": 24},
}# 循环data2,每行按着格式『学号1001, 姓名:rain,年龄:22』将每个学生的信息逐行打印for stu_id, stu_dic in data2.items():# print(stu_id,stu_dic)name = stu_dic.get("name")age = stu_dic.get("age")print("『学号: %s, 姓名 %s,年龄:%s』" % (stu_id, name, age))# name = "yuan"
# age = 22
# sex = "male"
#
# print("『姓名:", name, "年龄:", age, "性别:", sex, "』")
# print("『姓名: %s 年龄: %s 性别: %s 』" % (name, age, sex))
# print("姓名:name")字典生成式
同列表生成式一样,字典生成式是用来快速生成字典的。通过直接使用一句代码来指定要生成字典的条件及内容,替换了使用多行条件或者是多行循环代码的传统方式。
格式:
{字典内容+循环条件+判断条件}stu = {"id": "1001", "name": "alvin", "age": 22, "score": 100, "weight": "50kg"}
stu = {k: v for k, v in stu.items() if k == "score" or k == "name"}
print(stu)将一个字典中的键值倒换
dic = {"1": 1001, "2": 1002, "3": 1003}
new_dic = {v: k for k, v in dic.items()}
print(new_dic)将所有的key值变为大写
print({k.upper():v for k,v in d.items()})附录
列表.py
# 列表和字典 太重要# 基本数据类型(不可变数据类型)
a = 1
b = 3.14
c = "yuan"
d = True
# 列表和字典(可变数据类型)name1 = "张三"
name2 = "李四"
name3 = "王五"names = "张三 李四 王五"
names.split(" ") # ["张三","李四","王五"]
s = "hello"
# names = ["张三", "李四", "王五", "", "", "", "", ""]
names = ["张三", "", "", "", "", "", "李四", "王五"]
ages = [18, 19, 20]
l = [1, True, "hello"]# ------------------- 列表的基本操作(序列操作)# 一:支持索引取值
print(names[1])
print(names[2])
print(names[-1])
names[0] = "张三三"# 二:切片操作
print(names[1:3]) # ["李四", "王五"]
print(names[-2:-1]) # ["李四", "王五"]
print(names[-2:]) # ["李四", "王五"]# 三、in操作print("yuan " in "hello yuan")
print("张三" in names)
print("张" in names)# 四、+
l1 = [1, 2, 3]
l2 = [4, 5, 6]
print(l1 + l2) # [1,2,3,4,5,6]
print(l1)
print(type(l1)) # <class 'list'>
print(type(l2)) # <class 'list'>
# ------------------- 列表的内置方法
# 列表的内置方法帮助我们对该列表对象的数据元素进行管理(增删改查)
l = [1, 2, 3, 4]
print(type(l)) # <class 'list'>
# <1>添加元素 append insert extend
l.append(5)
l.append([6, 7])
print(l) # [1, 2, 3, 4,5,[6, 7]]
print(len(l))
l.insert(1, 100)
print(l)
l2 = [5, 6, 7]
l.extend(l2) # [1, 2, 3, 4,5, 6, 7]
print(l) # [1, 2, 3, 4, 5, 6, 7]
# <2>删除元素
l = [100, 200, 300, 400]
l.remove(300)
print(l) # [100, 200, 400]
l.pop(1)
print(l)
l.clear()
print(l) # []
# <3>更改元素
l = [100, 200, 300, 400]
l[0] = 1
print(l)# <4>查看元素
l = [34, 56, 1, 23, 23, 100]
l.reverse()
print(l)
l.sort(reverse=True)
print(l)
print(l.count(23)) # 2
print(l.index(56))# 遍历
names = ["zhangsan", "lisi", "wangwu"]
print(names[0])
print(names[1])
print(names[2])for item in names:print(item.upper())nums = [11, 2, 3, 45, 7, 43]
s = 0
for i in nums:s += i
print(s)
字典.py
# 列表和字典 太重要names = ["张三", "李四", "王五"]
ages = [18, 19, 20]
print(ages[names.index("李四")])stus = [["张三", 19], ["李四", 20], ["李四", 21]]
print(stus[1][1])stu = ["yuan", 18]
print(stu[0])
print(stu[1])
stu = {"name": "yuan", "age": 18}
print(type(stu)) # <class 'dict'>
print(stu["name"])
print(stu["age"])# 字典的基本操作(面向增删改查)
stu = {}
stu["name"] = "yuan"
stu["age"] = 18
stu["age"] = 22
print(stu)
print(stu["age"])
# del stu
# print(stu)
del stu["age"]
print(stu)
print("name" in stu)# 字典的内置方法(面向增删改查)stu = {"name": "yuan", "age": 32, "gender": "male"}
# 查看
print(stu["name"])
print(stu.get("names", None))
print(stu.items()) # [('name', 'yuan'), ('age', 32), ('gender', 'male')]stu.popitem()
print(stu)
stu.pop("age")
print(stu)
stu.clear()
print(stu)stu.update({"age": 18, "height": "182cm", "weight": "90kg"})
print(stu)# 知识补充
x = [1, 2]
x, y = [1, 2]
print(x, y)x, y, z = [1, 2, 3]
print(x, y, z)x, y, *z = [1, 2, 3, 4, 5]
print(x, y, z)# 遍历
stu = {"name": "yuan", "age": 32, "gender": "male"}for key in stu:print(key, stu[key])for i in stu.items(): # [['name', 'yuan'], (['age', 32], ['gender', 'male']]print(i[0], i[1])# # 推荐
stu = {"name": "yuan", "age": 32, "gender": "male"}
for k, v in stu.items(): # [('name', 'yuan'), ('age', 32), (gender', 'male')]print(k, v)
相关文章:
Python 重要数据类型
目录 列表 序列操作 列表内置方法 列表推到式 字典 声明字典 字典基本操作 列表内置方法 字典进阶使用 字典生成式 附录 列表 在实际开发中,经常需要将一组(不只一个)数据存储起来,以便后边的代码使用。列表就是这样的…...

03、pytest初体验
官方实例 # content of test_sample.py def func(x):return x 1def test_ansewer():assert func(3) 5步骤解释 [100%]指的是所有测试用例的总体进度,完成后,pytest显示一个失败报告,因为func(3)没有返回5 注意:你可以使用ass…...
智能指针及强相关知识经验总结 --- 移动语义、引用计数、循环引用、move()、自定义删除器等
目录 前言 一、shared_ptr 1. 基本用法和构造方法 2. 引用计数机制 3. weak_ptr 解决循环引用 二、unique_ptr 1. 基本用法和构造方法 2. 独占性 3. 所有权转移 1)unique_ptr :: release() 2)移动语义 和 move() 三、 对比 shared_ptr 和 un…...
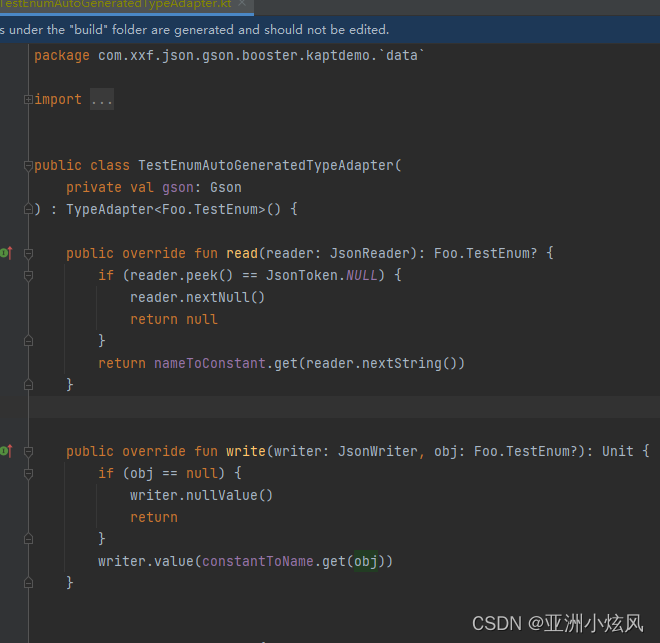
Gson 自动生成适配器插件
在json解析方面 我们常见有下面几方面困扰 1. moshi code-gen能自动生成适配器,序列化效率比gson快,但是自定义程度不如gson,能java kotlin共存 且解决了默认值的问题 2.gson api 强大自由,但是 第一次gson的反射缓存比较慢,而且生成对象都是反射,除非主动注册com.google.gson…...
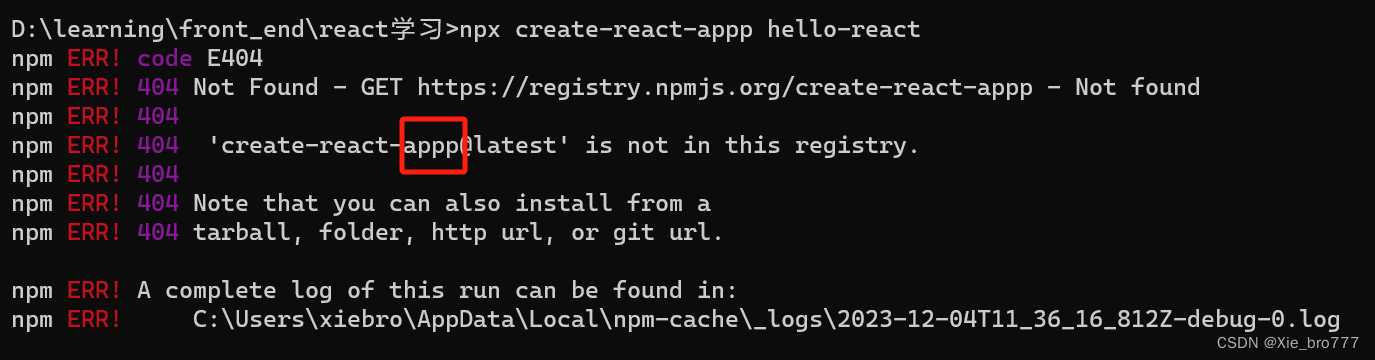
React创建项目
React创建项目 提前安装好nodejs再进行下面的操作,通过node -v验证是否安装 1.设置源地址 npm config set registry https://registry.npmmirror.com/2.确认源地址 npm config get registry返回如下 https://registry.npmmirror.com/3.输入命令 npx create-re…...
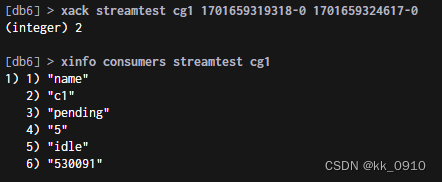
Redis5新特性-stream
Stream队列 Redis5.0 最大的新特性就是多出了一个数据结构 Stream,它是一个新的强大的 支持多播的可持久化的消息队列,作者声明 Redis Stream 地借鉴了 Kafka 的设计。 生产者 xadd 追加消息 xdel 删除消息,这里的删除仅仅是设置了标志位&am…...
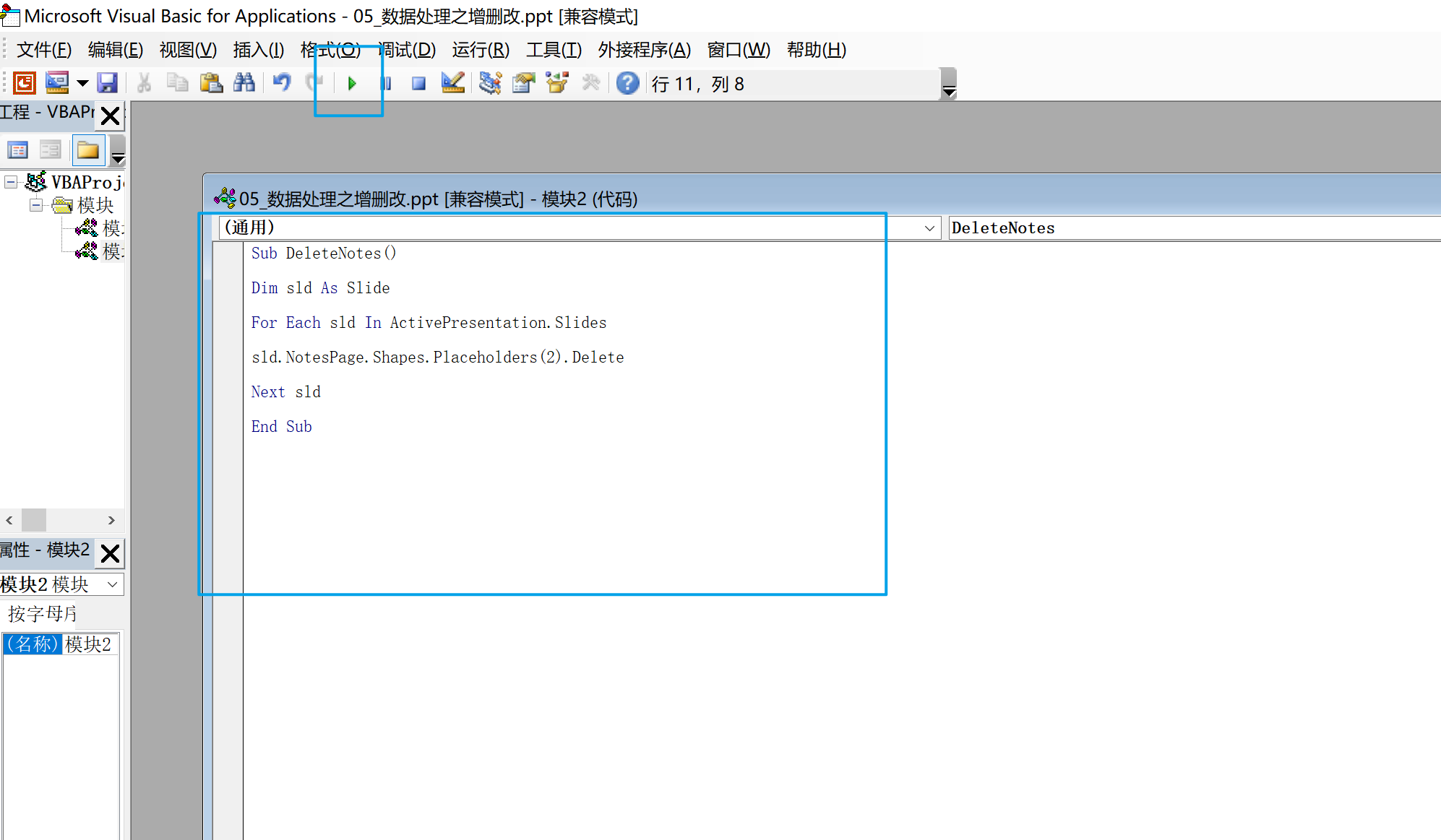
删除PPT文件的备注内容
解决方案的工作经常汇报以及经常做ppt的回报工作,但是删除备注很痛苦。 在网上或者拿历史的ppt文件修改后,需要删除ppt备注内容以及删除ppt个人文件信息的办法: 现象:很多备注信息,需要删除 解决办法一、 文件--信息-…...
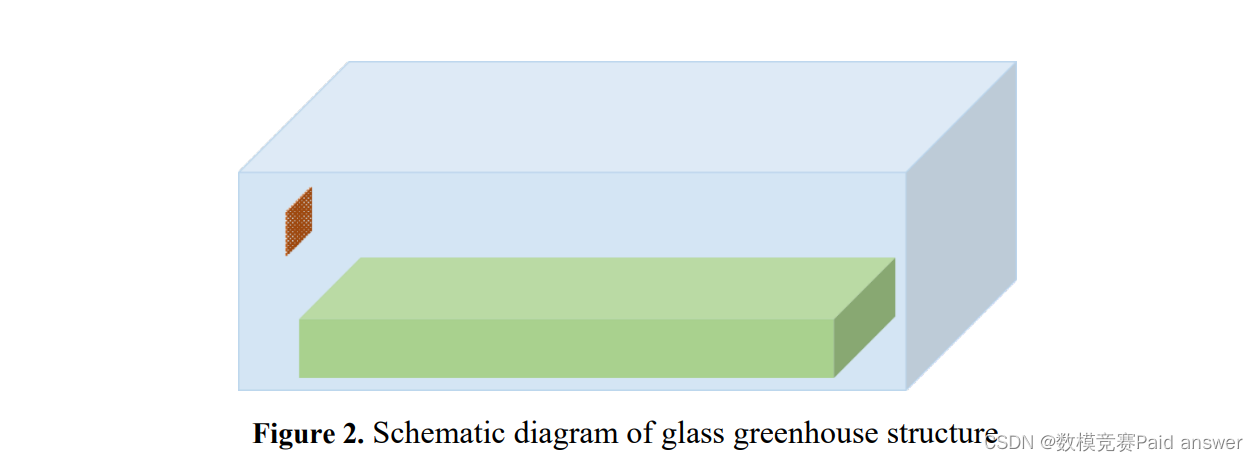
2023年亚太杯APMCM数学建模大赛B题玻璃温室小气候调控
2023年亚太杯APMCM数学建模大赛 B题 玻璃温室小气候调控 原题再现 温室作物的产量受各种气候因素的影响,包括温度、湿度和风速[1]。其中,适宜的温度和风速对植物生长至关重要[2]。为了调节玻璃温室内的温度、风速等气候因素,在温室设计中常…...

Oracle 查询语句限制只选择最前面几行,和最后面几行的实现方式。
查询最前面几行 在Oracle中,可以使用 ROWNUM 关键字来限制查询结果的行数。要选择前10条记录,可以使用以下查询语句: SELECT * FROM your_table WHERE ROWNUM < 10;实际查询时将your_table替换为要查询的表名。以上查询将返回表中的前10…...
.NET Core6.0 MVC+layui+SqlSugar 简单增删改查
HTML部分: {ViewData["Title"] "用户列表"; } <!DOCTYPE html> <html> <head><meta charset"utf-8"><title>用户列表</title><meta name"renderer" content"webkit"><meta …...
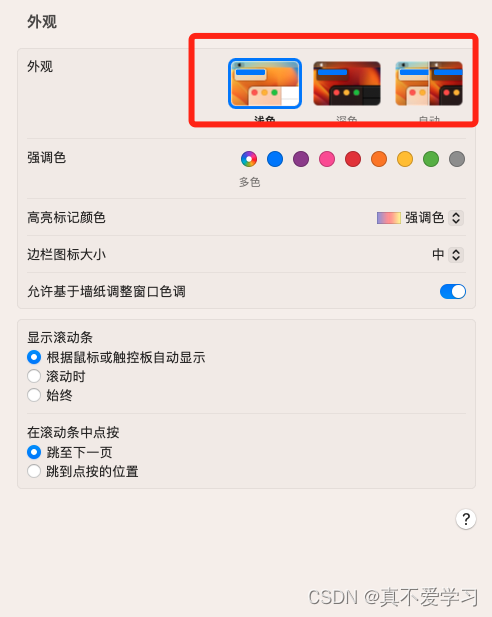
在 Mac 上使用浅色或深色外观
在 Mac 上,选取苹果菜单 >“系统设置”,然后点按边栏中的“外观” 。(你可能需要向下滚动。)选择右侧的“浅色”、“深色”或“自动”。 “浅色”表示不会发生变化的浅色外观。 “深色”表示不会发生变化的深色外观。“深色模式…...
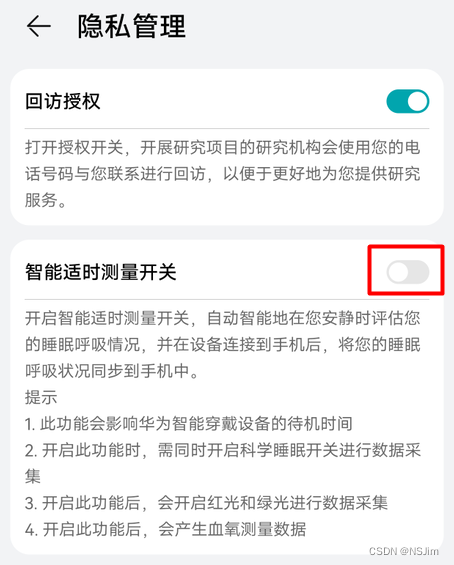
华为手环关闭智能适时测量
问题 使用华为手环并使用华为创新研究APP后,会自动打开智能适时测量开关,此开关开启后,手环会在睡眠时间自动测量血氧,增加手环功耗从而影响续航,用户可根据自身需求决定是否开启,下文介绍如何找到此开关。…...

1-Hadoop原理与技术
单选题 题目1:安装Hadoop集群时,是在哪个文件指定哪些机器作为集群的从机? 选项: A datanode B slaves C yarn-site.xml D core-site.xml 答案:B ------------------------------ 题目2:Hadoop配置文件所在目录是哪…...
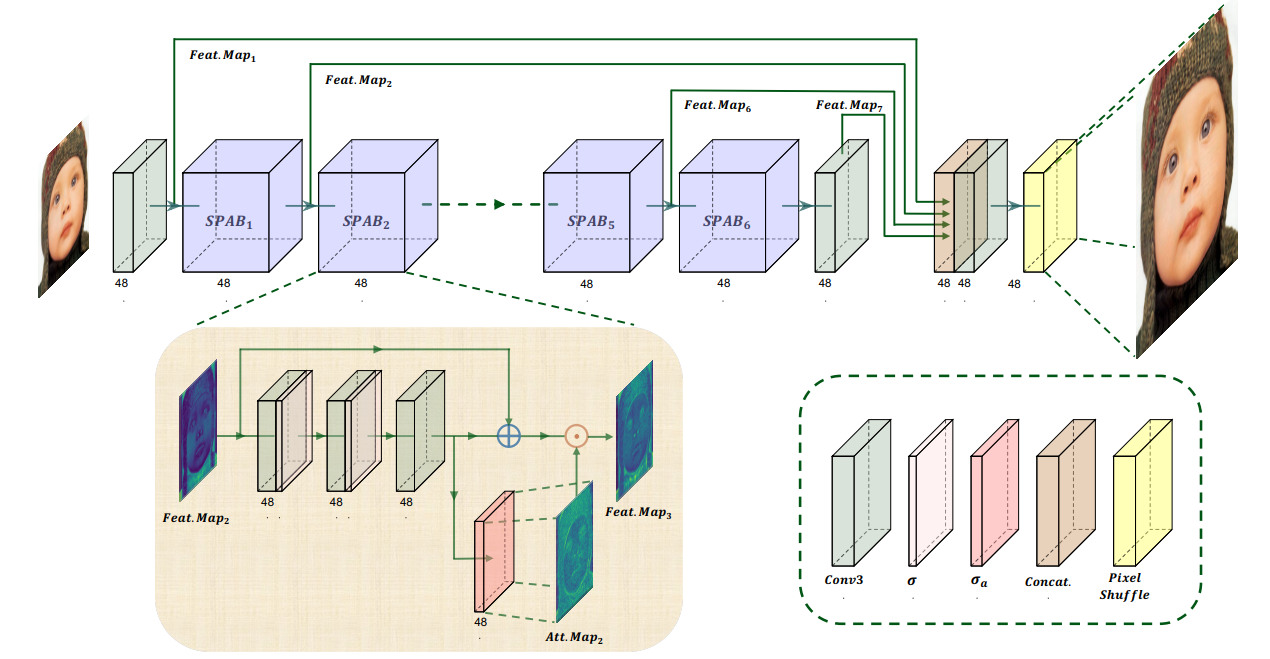
YoloV5改进策略:Swift Parameter-free Attention,无参注意力机制,超分模型的完美迁移
摘要 https://arxiv.org/pdf/2311.12770.pdf https://github.com/hongyuanyu/SPAN SPAN是一种超分网络模型。SPAN模型通过使用参数自由的注意力机制来提高SISR的性能。这种注意力机制能够增强重要信息并减少冗余,从而在图像超分辨率过程中提高图像质量。 具体来说,SPAN模…...
DAPP开发【04】测试驱动开发
测试驱动开发(Test Driven Development),是一种不同于传统软件开发流程的新型的开发方法。它要求在编写某个功能的代码之前先编写测试代码,然后只编写使测试通过的功能代码通过测试来推动整个开发的进行。这有助于编写简洁可用和高质量的代码,…...
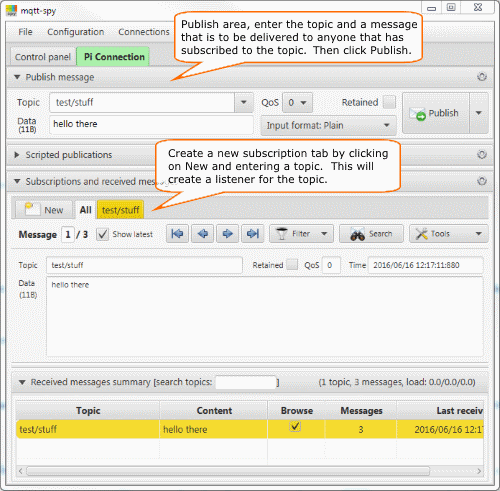
Raspberry Pi 2, 2 of n - Pi 作为 IoT 消息代理
目录 介绍 环境 先决条件 - 设置静态 IP 地址 安装 Mosquitto 启动/停止 Mosquitto 配置先决条件 - 安装 mqtt_spy 配置 Mosquitto 配置 Mosquitto - 无安全性 测试 Mosquitto 配置 - 无安全性 配置 Mosquitto - 使用密码身份验证 Mosquitto 测试 - 带密码验证 概括 介绍 在本文…...

linux服务器环境搭建(使用yum 安装mysql、jdk、redis)
一:yum的安装 1:下载yum安装包并解压 wget http://yum.baseurl.org/download/3.2/yum-3.2.28.tar.gz tar xvf yum-3.2.28.tar.gz 2.进入yum-3.2.28文件夹中进行安装,执行安装指令 cd yum-3.2.28 sudo apt install yum 3.更新版本 yum check-update yum update yum cle…...

互联网Java工程师面试题·Spring Boot篇·第二弹
目录 8、什么是 YAML? 9、如何实现 Spring Boot 应用程序的安全性? 10、如何集成 Spring Boot 和 ActiveMQ? 11、如何使用 Spring Boot 实现分页和排序? 12、什么是 Swagger?你用 Spring Boot 实现了它吗? …...

【西南交大swjtu微机与接口技术实验】D/A变换实验实验三:波形发生器
做一个存档。实验要求与电路连接见参考指导书。 1、主程序产生锯齿波 2、按下KK1输出五个周期的三角波,继续输出被中断的锯齿波 3、按下KK2输出五个周期的方波,继续输出被中断的锯齿波 程序代码 IOY0 EQU 0600H DA EQU IOT000H*2SSTACK SEGMENT STA…...
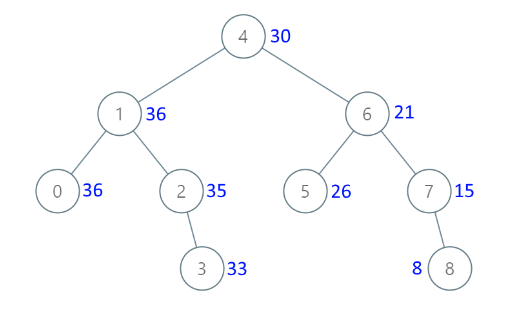
【每日一题】从二叉搜索树到更大和树
文章目录 Tag题目来源题目解读解题思路方法一:中序遍历的反序方法二:后缀数组 写在最后 Tag 【中序遍历】【二叉树】【2023-12-04】 题目来源 1038. 从二叉搜索树到更大和树 题目解读 在二叉搜索树中,将每一个节点的值替换成树中大于等于该…...

学术合规性危机预警:Perplexity生成内容如何精准适配Chicago第17版?,一文锁定98.7%高校期刊投稿要求
更多请点击: https://intelliparadigm.com 第一章:学术合规性危机预警:Perplexity生成内容如何精准适配Chicago第17版? 随着AI辅助写作工具在人文社科领域的深度渗透,Perplexity等生成式平台输出的引文、脚注与参考文…...

别再折腾Anaconda了!用PyCharm 2024.1自带工具5分钟搞定TensorFlow 2.15 + Keras 3环境
PyCharm 2024.1极简指南:5分钟无痛部署TensorFlow 2.15 Keras 3深度学习环境 深度学习环境配置曾是无数开发者的噩梦——直到PyCharm 2024.1彻底改变了游戏规则。最新版本集成的环境管理工具让TensorFlow和Keras的安装变得像点外卖一样简单,完全跳过了传…...
)
STM32L4低功耗实战:用RTC内部唤醒定时1秒,让设备续航翻倍(附CubeIDE配置)
STM32L4低功耗实战:RTC唤醒中断与CubeIDE配置全解析 在电池供电的物联网终端设计中,每微安电流都关乎产品寿命。曾有个智能农业项目,原本预计6个月的传感器续航,因未优化低功耗模式,实际仅维持了3周。这促使我们深入研…...

软件需求捕获:从Therac-25悲剧到安全关键系统开发的脊柱工程
1. 项目概述:从Therac-25悲剧到现代软件安全基石上世纪90年代中期,一系列由Therac-25放射治疗机引发的致命事故,最终催生了一场由华盛顿大学Nancy Leveson教授主导的正式调查。这场调查的结论,远不止于揪出一款医疗设备的软件缺陷…...
)
Simulink仿真避坑指南:PWM控制48V直流电机时,轻载和重载下的参数设置与波形分析(附2018a源文件)
Simulink仿真避坑指南:PWM控制48V直流电机时,轻载和重载下的参数设置与波形分析 在工程实践中,直流电机的仿真建模是验证控制算法和预测系统性能的关键环节。特别是当面对不同负载条件时,如何准确设置电机参数并解读仿真波形&…...
完整移植方案)
正点原子 RK3562 Android14 集成 GStreamer 1.24.13(CLI + V4L2 插件)完整移植方案
RK3562 Android 系统中集成 GStreamer CLI V4L2 插件的完整移植方案,重点难点在于:预编译产物整理、Android.bp 自动生成、vendor 路径安装、运行时环境变量注入,以及 Android 动态链接 namespace 限制的排查。 正点原子RK3562J开发板瑞芯微…...

三维动画课程期末复盘:从零搭建我的马卡龙童话游乐场✨
当我按下 3ds Max 的渲染按钮,看着浅蓝的摩天轮缓缓转动、粉白的旋转木马跟着节奏起舞、淡紫色热气球轻轻飘动时,我才真正意识到:为期一学期的三维动画课程,就这样在我的指尖落下了帷幕。从刚打开软件连工具栏都认不全的 “小白”…...

打造高效命令行天气查询工具:基于KMI/IRM的比利时天气CLI实践
1. 项目概述:一个为终端而生的比利时天气查询工具 如果你和我一样,是个重度命令行用户,同时又对窗外天气是晴是雨有点在意,那你肯定也烦透了为了看个天气预报还得打开浏览器、点开某个天气网站或者解锁手机。这种打断工作流的感觉…...

LibreHardwareMonitor:你的电脑健康管家,硬件监控从此无忧
LibreHardwareMonitor:你的电脑健康管家,硬件监控从此无忧 【免费下载链接】LibreHardwareMonitor Libre Hardware Monitor is free software that can monitor the temperature sensors, fan speeds, voltages, load and clock speeds of your computer…...

企业内如何安全地通过Taotoken管理各部门的AI模型使用权限
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 企业内如何安全地通过Taotoken管理各部门的AI模型使用权限 对于中大型企业而言,引入大模型能力是提升效率的关键一步&a…...