Inference with C# BERT NLP Deep Learning and ONNX Runtime
目录
效果
测试一
测试二
测试三
模型信息
项目
代码
下载
Inference with C# BERT NLP Deep Learning and ONNX Runtime
效果
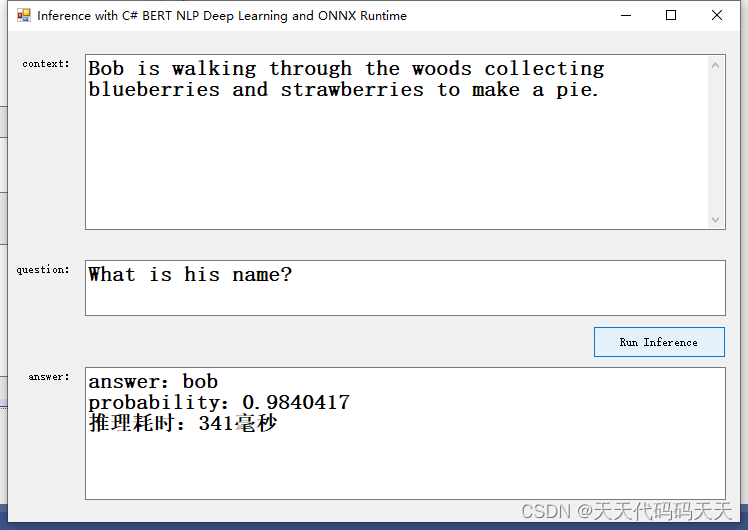
测试一
Context :Bob is walking through the woods collecting blueberries and strawberries to make a pie.
Question :What is his name?
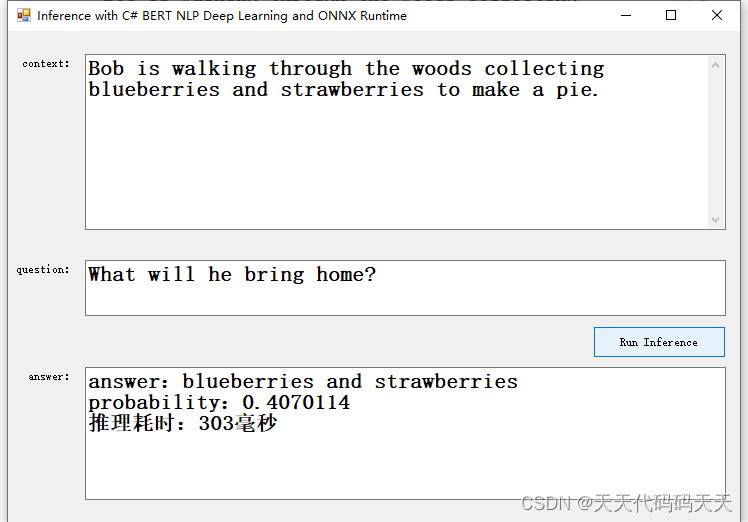
测试二
Context :Bob is walking through the woods collecting blueberries and strawberries to make a pie.
Question :What will he bring home?
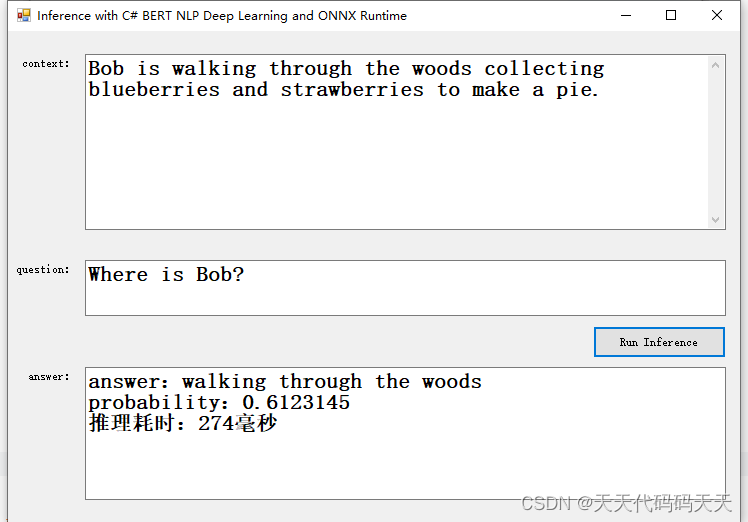
测试三
Context :Bob is walking through the woods collecting blueberries and strawberries to make a pie.
Question :Where is Bob?
模型信息
Inputs
-------------------------
name:unique_ids_raw_output___9:0
tensor:Int64[-1]
name:segment_ids:0
tensor:Int64[-1, 256]
name:input_mask:0
tensor:Int64[-1, 256]
name:input_ids:0
tensor:Int64[-1, 256]
---------------------------------------------------------------
Outputs
-------------------------
name:unstack:1
tensor:Float[-1, 256]
name:unstack:0
tensor:Float[-1, 256]
name:unique_ids:0
tensor:Int64[-1]
---------------------------------------------------------------
项目
代码
using BERTTokenizers;
using Microsoft.ML.OnnxRuntime;
using System;
using System.Collections.Generic;
using System.Data;
using System.Diagnostics;
using System.Linq;
using System.Windows.Forms;
namespace Inference_with_C__BERT_NLP_Deep_Learning_and_ONNX_Runtime
{
public struct BertInput
{
public long[] InputIds { get; set; }
public long[] InputMask { get; set; }
public long[] SegmentIds { get; set; }
public long[] UniqueIds { get; set; }
}
public partial class Form1 : Form
{
public Form1()
{
InitializeComponent();
}
RunOptions runOptions;
InferenceSession session;
BertUncasedLargeTokenizer tokenizer;
Stopwatch stopWatch = new Stopwatch();
private void Form1_Load(object sender, EventArgs e)
{
string modelPath = "bertsquad-10.onnx";
runOptions = new RunOptions();
session = new InferenceSession(modelPath);
tokenizer = new BertUncasedLargeTokenizer();
}
int MaxAnswerLength = 30;
int bestN = 20;
private void button1_Click(object sender, EventArgs e)
{
txt_answer.Text = "";
Application.DoEvents();
string question = txt_question.Text.Trim();
string context = txt_context.Text.Trim();
// Get the sentence tokens.
var tokens = tokenizer.Tokenize(question, context);
// Encode the sentence and pass in the count of the tokens in the sentence.
var encoded = tokenizer.Encode(tokens.Count(), question, context);
var padding = Enumerable
.Repeat(0L, 256 - tokens.Count)
.ToList();
var bertInput = new BertInput()
{
InputIds = encoded.Select(t => t.InputIds).Concat(padding).ToArray(),
InputMask = encoded.Select(t => t.AttentionMask).Concat(padding).ToArray(),
SegmentIds = encoded.Select(t => t.TokenTypeIds).Concat(padding).ToArray(),
UniqueIds = new long[] { 0 }
};
// Create input tensors over the input data.
var inputIdsOrtValue = OrtValue.CreateTensorValueFromMemory(bertInput.InputIds,
new long[] { 1, bertInput.InputIds.Length });
var inputMaskOrtValue = OrtValue.CreateTensorValueFromMemory(bertInput.InputMask,
new long[] { 1, bertInput.InputMask.Length });
var segmentIdsOrtValue = OrtValue.CreateTensorValueFromMemory(bertInput.SegmentIds,
new long[] { 1, bertInput.SegmentIds.Length });
var uniqueIdsOrtValue = OrtValue.CreateTensorValueFromMemory(bertInput.UniqueIds,
new long[] { bertInput.UniqueIds.Length });
var inputs = new Dictionary<string, OrtValue>
{
{ "unique_ids_raw_output___9:0", uniqueIdsOrtValue },
{ "segment_ids:0", segmentIdsOrtValue},
{ "input_mask:0", inputMaskOrtValue },
{ "input_ids:0", inputIdsOrtValue }
};
stopWatch.Restart();
// Run session and send the input data in to get inference output.
var output = session.Run(runOptions, inputs, session.OutputNames);
stopWatch.Stop();
var startLogits = output[1].GetTensorDataAsSpan<float>();
var endLogits = output[0].GetTensorDataAsSpan<float>();
var uniqueIds = output[2].GetTensorDataAsSpan<long>();
var contextStart = tokens.FindIndex(o => o.Token == "[SEP]");
var bestStartLogits = startLogits.ToArray()
.Select((logit, index) => (Logit: logit, Index: index))
.OrderByDescending(o => o.Logit)
.Take(bestN);
var bestEndLogits = endLogits.ToArray()
.Select((logit, index) => (Logit: logit, Index: index))
.OrderByDescending(o => o.Logit)
.Take(bestN);
var bestResultsWithScore = bestStartLogits
.SelectMany(startLogit =>
bestEndLogits
.Select(endLogit =>
(
StartLogit: startLogit.Index,
EndLogit: endLogit.Index,
Score: startLogit.Logit + endLogit.Logit
)
)
)
.Where(entry => !(entry.EndLogit < entry.StartLogit || entry.EndLogit - entry.StartLogit > MaxAnswerLength || entry.StartLogit == 0 && entry.EndLogit == 0 || entry.StartLogit < contextStart))
.Take(bestN);
var (item, probability) = bestResultsWithScore
.Softmax(o => o.Score)
.OrderByDescending(o => o.Probability)
.FirstOrDefault();
int startIndex = item.StartLogit;
int endIndex = item.EndLogit;
var predictedTokens = tokens
.Skip(startIndex)
.Take(endIndex + 1 - startIndex)
.Select(o => tokenizer.IdToToken((int)o.VocabularyIndex))
.ToList();
// Print the result.
string answer = "answer:" + String.Join(" ", StitchSentenceBackTogether(predictedTokens))
+ "\r\nprobability:" + probability
+ $"\r\n推理耗时:{stopWatch.ElapsedMilliseconds}毫秒";
txt_answer.Text = answer;
Console.WriteLine(answer);
}
private List<string> StitchSentenceBackTogether(List<string> tokens)
{
var currentToken = string.Empty;
tokens.Reverse();
var tokensStitched = new List<string>();
foreach (var token in tokens)
{
if (!token.StartsWith("##"))
{
currentToken = token + currentToken;
tokensStitched.Add(currentToken);
currentToken = string.Empty;
}
else
{
currentToken = token.Replace("##", "") + currentToken;
}
}
tokensStitched.Reverse();
return tokensStitched;
}
}
}
using BERTTokenizers;
using Microsoft.ML.OnnxRuntime;
using System;
using System.Collections.Generic;
using System.Data;
using System.Diagnostics;
using System.Linq;
using System.Windows.Forms;namespace Inference_with_C__BERT_NLP_Deep_Learning_and_ONNX_Runtime
{public struct BertInput{public long[] InputIds { get; set; }public long[] InputMask { get; set; }public long[] SegmentIds { get; set; }public long[] UniqueIds { get; set; }}public partial class Form1 : Form{public Form1(){InitializeComponent();}RunOptions runOptions;InferenceSession session;BertUncasedLargeTokenizer tokenizer;Stopwatch stopWatch = new Stopwatch();private void Form1_Load(object sender, EventArgs e){string modelPath = "bertsquad-10.onnx";runOptions = new RunOptions();session = new InferenceSession(modelPath);tokenizer = new BertUncasedLargeTokenizer();}int MaxAnswerLength = 30;int bestN = 20;private void button1_Click(object sender, EventArgs e){txt_answer.Text = "";Application.DoEvents();string question = txt_question.Text.Trim();string context = txt_context.Text.Trim();// Get the sentence tokens.var tokens = tokenizer.Tokenize(question, context);// Encode the sentence and pass in the count of the tokens in the sentence.var encoded = tokenizer.Encode(tokens.Count(), question, context);var padding = Enumerable.Repeat(0L, 256 - tokens.Count).ToList();var bertInput = new BertInput(){InputIds = encoded.Select(t => t.InputIds).Concat(padding).ToArray(),InputMask = encoded.Select(t => t.AttentionMask).Concat(padding).ToArray(),SegmentIds = encoded.Select(t => t.TokenTypeIds).Concat(padding).ToArray(),UniqueIds = new long[] { 0 }};// Create input tensors over the input data.var inputIdsOrtValue = OrtValue.CreateTensorValueFromMemory(bertInput.InputIds,new long[] { 1, bertInput.InputIds.Length });var inputMaskOrtValue = OrtValue.CreateTensorValueFromMemory(bertInput.InputMask,new long[] { 1, bertInput.InputMask.Length });var segmentIdsOrtValue = OrtValue.CreateTensorValueFromMemory(bertInput.SegmentIds,new long[] { 1, bertInput.SegmentIds.Length });var uniqueIdsOrtValue = OrtValue.CreateTensorValueFromMemory(bertInput.UniqueIds,new long[] { bertInput.UniqueIds.Length });var inputs = new Dictionary<string, OrtValue>{{ "unique_ids_raw_output___9:0", uniqueIdsOrtValue },{ "segment_ids:0", segmentIdsOrtValue},{ "input_mask:0", inputMaskOrtValue },{ "input_ids:0", inputIdsOrtValue }};stopWatch.Restart();// Run session and send the input data in to get inference output. var output = session.Run(runOptions, inputs, session.OutputNames);stopWatch.Stop();var startLogits = output[1].GetTensorDataAsSpan<float>();var endLogits = output[0].GetTensorDataAsSpan<float>();var uniqueIds = output[2].GetTensorDataAsSpan<long>();var contextStart = tokens.FindIndex(o => o.Token == "[SEP]");var bestStartLogits = startLogits.ToArray().Select((logit, index) => (Logit: logit, Index: index)).OrderByDescending(o => o.Logit).Take(bestN);var bestEndLogits = endLogits.ToArray().Select((logit, index) => (Logit: logit, Index: index)).OrderByDescending(o => o.Logit).Take(bestN);var bestResultsWithScore = bestStartLogits.SelectMany(startLogit =>bestEndLogits.Select(endLogit =>(StartLogit: startLogit.Index,EndLogit: endLogit.Index,Score: startLogit.Logit + endLogit.Logit))).Where(entry => !(entry.EndLogit < entry.StartLogit || entry.EndLogit - entry.StartLogit > MaxAnswerLength || entry.StartLogit == 0 && entry.EndLogit == 0 || entry.StartLogit < contextStart)).Take(bestN);var (item, probability) = bestResultsWithScore.Softmax(o => o.Score).OrderByDescending(o => o.Probability).FirstOrDefault();int startIndex = item.StartLogit;int endIndex = item.EndLogit;var predictedTokens = tokens.Skip(startIndex).Take(endIndex + 1 - startIndex).Select(o => tokenizer.IdToToken((int)o.VocabularyIndex)).ToList();// Print the result.string answer = "answer:" + String.Join(" ", StitchSentenceBackTogether(predictedTokens))+ "\r\nprobability:" + probability+ $"\r\n推理耗时:{stopWatch.ElapsedMilliseconds}毫秒";txt_answer.Text = answer;Console.WriteLine(answer);}private List<string> StitchSentenceBackTogether(List<string> tokens){var currentToken = string.Empty;tokens.Reverse();var tokensStitched = new List<string>();foreach (var token in tokens){if (!token.StartsWith("##")){currentToken = token + currentToken;tokensStitched.Add(currentToken);currentToken = string.Empty;}else{currentToken = token.Replace("##", "") + currentToken;}}tokensStitched.Reverse();return tokensStitched;}}
}
下载
源码下载
相关文章:
Inference with C# BERT NLP Deep Learning and ONNX Runtime
目录 效果 测试一 测试二 测试三 模型信息 项目 代码 下载 Inference with C# BERT NLP Deep Learning and ONNX Runtime 效果 测试一 Context :Bob is walking through the woods collecting blueberries and strawberries to make a pie. Question …...

6、原型模式(Prototype Pattern,不常用)
原型模式指通过调用原型实例的Clone方法或其他手段来创建对象。 原型模式属于创建型设计模式,它以当前对象为原型(蓝本)来创建另一个新的对象,而无须知道创建的细节。原型模式在Java中通常使用Clone技术实现,在JavaSc…...

图像万物分割——Segment Anything算法解析与模型推理
一、概述 在视觉任务中,图像分割任务是一个很广泛的领域,应用于交互式分割,边缘检测,超像素化,感兴趣目标生成,前景分割,语义分割,实例分割,泛视分割等。 交互式分割&am…...

Redis实战篇笔记(最终篇)
Redis实战篇笔记(七) 文章目录 Redis实战篇笔记(七)前言达人探店发布和查看探店笔记点赞点赞排行榜 好友关注关注和取关共同关注关注推送关注推荐的实现 总结 前言 本系列文章是Redis实战篇笔记的最后一篇,那么到这里…...

游戏配置表的导入使用
游戏配置表是游戏策划的标配,如下图: 那么程序怎么把这张配置表导入使用? 1.首先,利用命令行把Excel格式的文件转化成Json格式: json-excel\json-excel json Tables\ Data\copy Data\CharacterDefine.txt ..\Clien…...
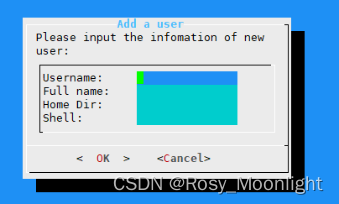
❀dialog命令运用于linux❀
目录 ❀dialog命令运用于linux❀ msgbox部件(消息框) yesno部件(yesno框) inputbox部件(输入文本框) textbox部件(文本框) menu部件(菜单框) fselect部…...

【算法】蓝桥杯2013国C 横向打印二叉树 题解
文章目录 题目链接题目描述输入格式输出格式样例自己的样例输入自己的样例输出 思路整体思路存储二叉搜索树中序遍历并存储计算目标数的行号dfs遍历并写入数组初始化和处理输入输出初始化处理输入处理输出 完整的代码如下 结束语更新初始化的修改存储二叉搜索树的修改中序遍历和…...

XunSearch 讯搜 error: storage size of ‘methods_bufferevent’ isn’t known
报错: error: storage size of ‘methods_bufferevent’ isn’t known CentOS8.0安装迅搜(XunSearch)引擎报错的解决办法 比较完整的文档 http://www.xunsearch.com/download/xs_quickstart.pdf 官方安装文档 http://www.xunsearch.com/doc/php/guide/start.in…...
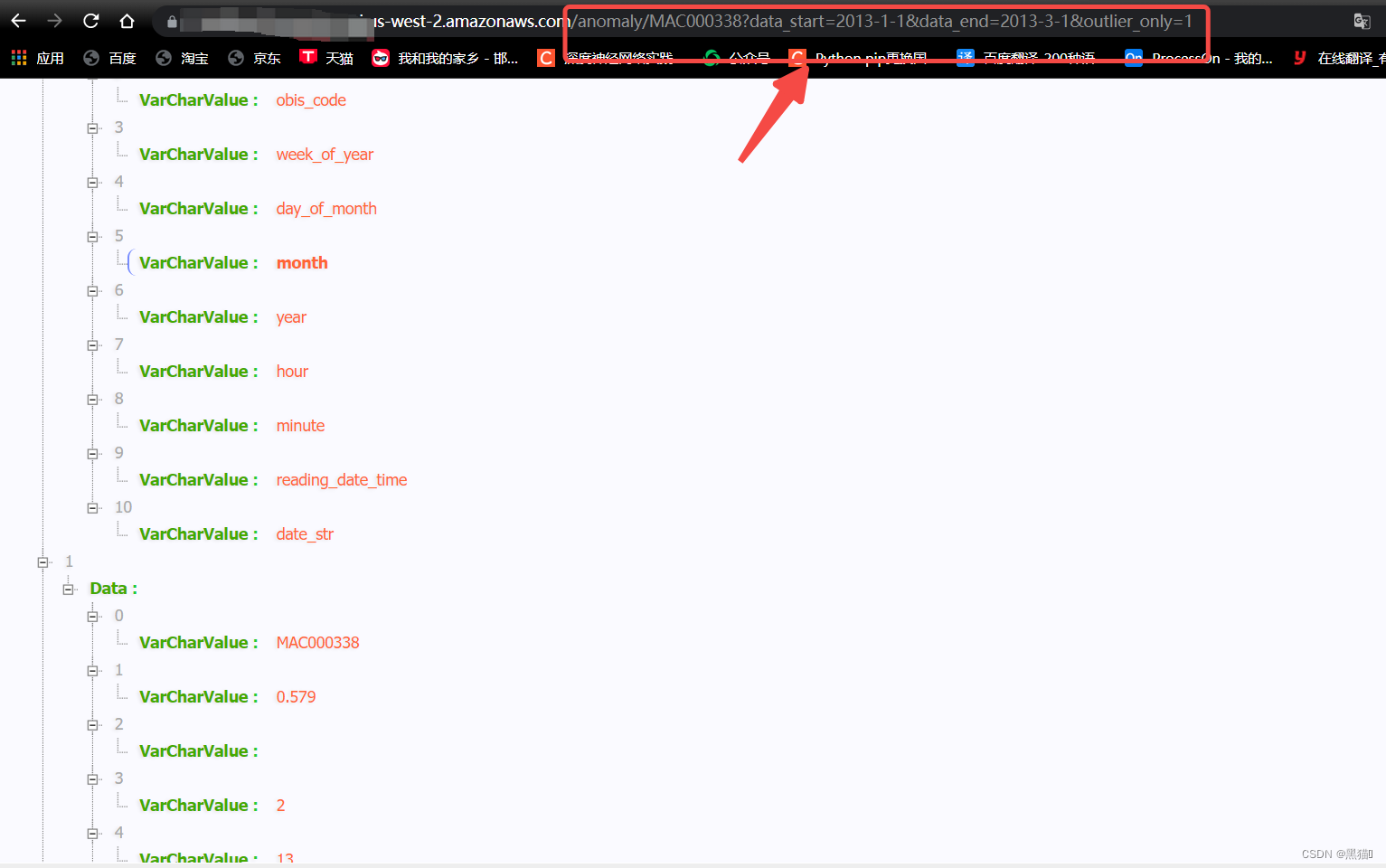
基于AWS Serverless的Glue服务进行ETL(提取、转换和加载)数据分析(三)——serverless数据分析
3 serverless数据分析 大纲 3 serverless数据分析3.1 创建Lambda3.2 创建API Gateway3.3 结果3.4 总结 3.1 创建Lambda 在Lambda中,我们将使用python3作为代码语言。 步骤图例1、入口2、创建(我们选择使用python3.7)3、IAM权限(…...

08、分析测试执行时间及获取pytest帮助
官方用例 # content of test_slow_func.py import pytest from time import sleeppytest.mark.parametrize(delay,(1.1,1.2,1.3,1.4,1.5,1.6,1.7,1.8,1.9,1.0,0.1,0.2,0,3)) def test_slow_func(delay):print("test_slow_func {}".format(delay))sleep(delay)assert…...

视频集中存储/智能分析融合云平台EasyCVR平台接入rtsp,突然断流是什么原因?
安防视频监控/视频集中存储/云存储/磁盘阵列EasyCVR平台可拓展性强、视频能力灵活、部署轻快,可支持的主流标准协议有国标GB28181、RTSP/Onvif、RTMP等,以及支持厂家私有协议与SDK接入,包括海康Ehome、海大宇等设备的SDK等。平台既具备传统安…...
)
JavaScript 复杂的<三元运算符和比较操作>的组合--案例(一)
在逆向的时候,碰上有些复杂的js代码,逻辑弄得人有点混; 因此本帖用来记录一些棘手的代码,方便自己记忆,也让大家拓展认识~ ----前言 内容: function(e, t, n) {try {1 (e "{" e[0] ? JSON.parse(e) : JSON.parse(webInstace.shell(e))).Status || 200 e.Code…...

uniapp搭建内网映射测试https域名
搭建Https域名服务器 使用github的frp搭建,使用宝塔申请免费https证书,需要先关闭宝塔nginx的反向代理,申请完域名后再开启反向代理即可。 教程 新版frp搭建教程 启动命令 服务器端 sudo systemctl start frps本地 cd D:\软件安装包\f…...

国防科技大博士招生入学考试【50+论文主观题】
目录 回答模板大意创新和学术价值启发 论文分类(根据问题/场景分类)数学问题Efficient Multiset Synchronization(高效的多集同步【简单集合/可逆计数Bloom过滤器】)大意创新和学术价值启发 An empirical study of Bayesian netwo…...
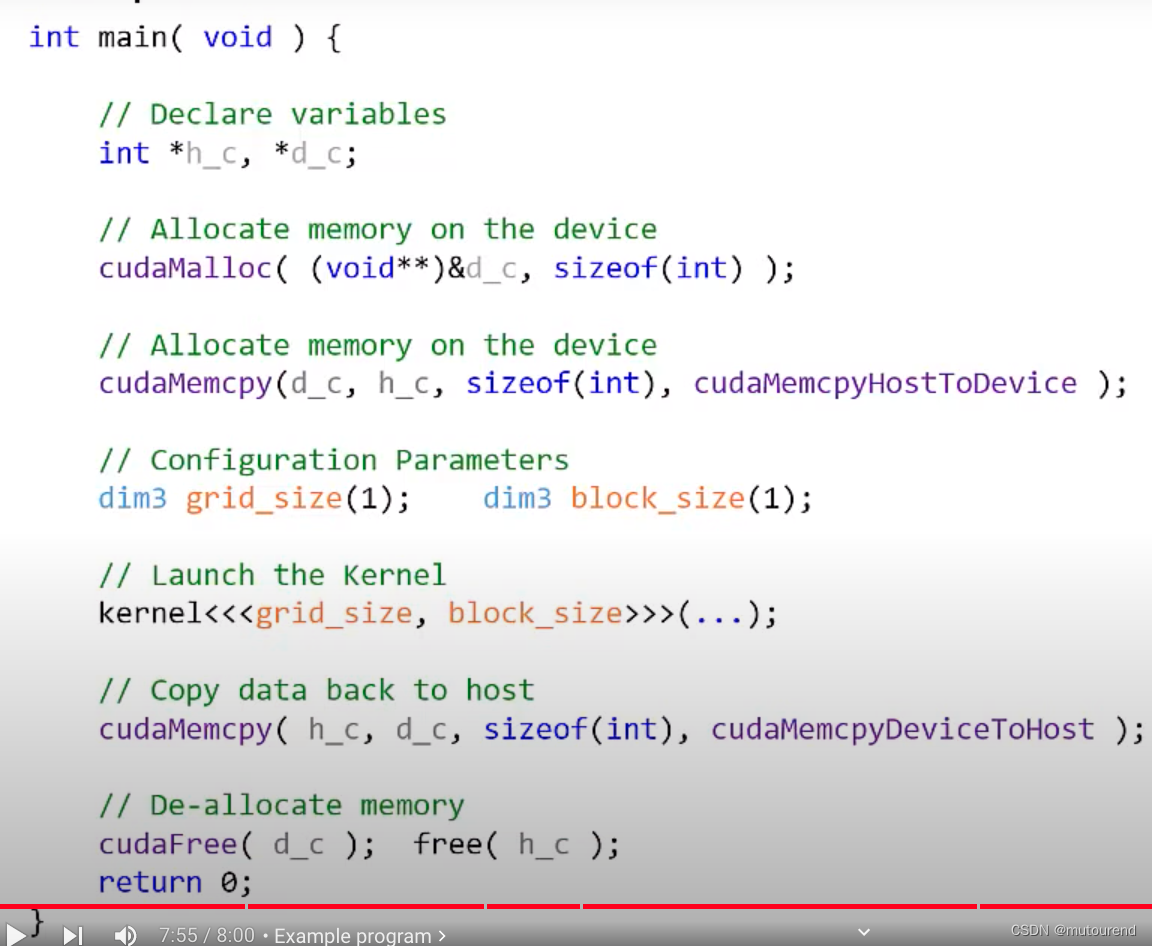
CUDA简介——编程模式
1. 引言 前序博客: CUDA简介——基本概念 CPU是用于控制的。即,host控制整个程序流程: 1)程序以Host代码main函数开始,然后顺序执行。 Host代码是顺序执行的,并执行在CPU之上。Host代码会负责Launch ke…...

Linux 软件安装
目录 一、Linux 1、Linux异常解决 1、JDK安装 1、Linux卸载JDK 2、Linux安装JDK 2、Redis安装 一、Linux 1、Linux异常解决 1、Another app is currently holding the yum lock; waiting for it to exit... 解决办法: rm -f /var/run/yum.pid1、杀死这个应用程序 ps a…...

flask之邮件发送
一、安装Flask-Mail扩展 pip install Flask-Mail二、配置Flask-Mail 格式:app.config[参数]值 三、实现方法 3.1、Mail类 常用类方法 3.2、Message类,它封装了一封电子邮件。构造函数参数如下: flask-mail.Message(subject, recipient…...
【Filament】Filament环境搭建
1 前言 Filament 是一个实时物理渲染引擎,用于 Android、iOS、Linux、macOS、Windows 和 WebGL 平台。该引擎旨在提供高效、实时的图形渲染,并被设计为在 Android 平台上尽可能小而尽可能高效。Filament 支持基于物理的渲染(PBR)&…...
外包干了2个月,技术倒退2年。。。。。
先说一下自己的情况,本科生,20年通过校招进入深圳某软件公司,干了接近4年的功能测试,今年国庆,感觉自己不能够在这样下去了,长时间呆在一个舒适的环境会让一个人堕落!而我已经在一个企业干了四年的功能测试…...

使用 python ffmpeg 批量检查 音频文件 是否损坏或不完整
自用工具,检查下载的音乐是否有损坏 或 下载不完整 使用方法,把 in_dir r’D:\158首无损珍藏版’ 改成你自己的音乐文件夹路径 如果发现文件有损坏,则会在命令行打印错误文件的路径 注意,要求 ffmpeg 命令可以直接在命令行调用…...

PCU9669 LED驱动库:Mini Board嵌入式快速验证方案
1. 项目概述utility库是为 Mini Board PCU9669 评估套件(Evaluation Kit)配套开发的底层驱动与功能封装库,专为快速验证 NXP PCU9669 高精度、多通道 LED 驱动与电流/电压监控芯片而设计。该库并非通用型 HAL 抽象层,而是面向特定…...

YOLO11 vs YOLOv8 实测对比:在自定义数据集上,精度和速度到底提升了多少?
YOLO11 vs YOLOv8 深度实测:工业场景下的精度与效率抉择 当生产线上的摄像头每秒捕获30帧图像时,算法每增加1%的误检率就意味着每小时可能多出上百次错误警报。这正是我们在某汽车零部件缺陷检测项目中面临的现实挑战——选择YOLOv8还是新发布的YOLO11&a…...

深度剖析:20206年国内AI应用上市公司谁在领跑?
随着人工智能技术加速向千行百业渗透,AI应用落地能力已成为衡量上市公司核心竞争力的关键标尺。在众多布局AI的上市企业中,新大陆数字技术股份有限公司(股票代码:000997)凭借深厚的产业积淀与前瞻的“支付AI”战略&…...

Curated Programming Resources的未来发展:AI时代编程学习资源的新趋势
Curated Programming Resources的未来发展:AI时代编程学习资源的新趋势 【免费下载链接】curated-programming-resources A curated list of resources for learning programming. 项目地址: https://gitcode.com/gh_mirrors/cu/curated-programming-resources …...

ABAQUS复合材料层合板建模与应力分析实战指南
1. ABAQUS复合材料层合板分析入门指南 第一次接触复合材料分析的朋友可能会觉得有点懵,毕竟这玩意儿跟普通金属材料差别太大了。我刚开始用ABAQUS做复合材料分析时,光是理解"铺层方向"这个概念就花了整整一周时间。不过别担心,今天…...

Umi-OCR PDF文字识别全攻略:从技术原理到实战应用
Umi-OCR PDF文字识别全攻略:从技术原理到实战应用 【免费下载链接】Umi-OCR Umi-OCR: 这是一个免费、开源、可批量处理的离线OCR软件,适用于Windows系统,支持截图OCR、批量OCR、二维码识别等功能。 项目地址: https://gitcode.com/GitHub_T…...

24小时运行:OpenClaw+GLM-4.7-Flash的网站监控方案
24小时运行:OpenClawGLM-4.7-Flash的网站监控方案 1. 为什么需要自动化网站监控 去年我负责维护的某个技术博客突然遭遇了持续3天的数据库连接泄漏,直到用户投诉才发现问题。手动刷新网页检查状态的方式,在深夜和周末存在明显的监控盲区。这…...
部署后,别忘了这3个关键监控与排错点(含track接口/VRRP状态查看))
H3C防火墙双机热备(RBM)部署后,别忘了这3个关键监控与排错点(含track接口/VRRP状态查看)
H3C防火墙双机热备(RBM)部署后的3个关键运维盲区与实战排错指南 当你在数据中心完成H3C防火墙双机热备部署时,真正的挑战才刚刚开始。很多工程师以为配置完remote-backup-group和VRRP就万事大吉,直到深夜被报警电话惊醒才发现——…...

万字拆解OpenClaw,从Gateway到多Agent,揭秘Agent系统的完整运行密码
很多技术文章拆解框架时,总爱按模块逐一罗列,最后落得个“各说各的,毫无关联”的尴尬。与其这样,不如我们回归最本质的问题:当用户真的发来一条消息时,OpenClaw内部到底在发生什么?这条消息从输…...

别再只抄代码了!手把手教你调试YOLOv5模型输出,彻底搞懂每个数字的含义
从黑盒到白盒:YOLOv5模型输出调试实战指南 在计算机视觉领域,YOLOv5无疑是最受欢迎的实时目标检测框架之一。但许多开发者在使用过程中,往往只停留在"复制粘贴后处理代码"的阶段,对模型输出的具体含义一知半解。当需要将…...