Hadoop学习笔记(HDP)-Part.18 安装Flink
目录
Part.01 关于HDP
Part.02 核心组件原理
Part.03 资源规划
Part.04 基础环境配置
Part.05 Yum源配置
Part.06 安装OracleJDK
Part.07 安装MySQL
Part.08 部署Ambari集群
Part.09 安装OpenLDAP
Part.10 创建集群
Part.11 安装Kerberos
Part.12 安装HDFS
Part.13 安装Ranger
Part.14 安装YARN+MR
Part.15 安装HIVE
Part.16 安装HBase
Part.17 安装Spark2
Part.18 安装Flink
Part.19 安装Kafka
Part.20 安装Flume
十八、安装Flink
1.配置Ambari的flink资源
(1)创建flink源
下载链接为
https://repo.huaweicloud.com/apache/flink/flink-1.9.3/flink-1.9.3-bin-scala_2.12.tgz
https://repo.maven.apache.org/maven2/org/apache/flink/flink-shaded-hadoop-2-uber/2.6.5-7.0/flink-shaded-hadoop-2-uber-2.6.5-7.0.jar
http://www.java2s.com/Code/JarDownload/javax.ws/javax.ws.rs-api-2.0.jar.zip
上传到hdp01上,并复制到/var/www/html下
mkdir /var/www/html/flink
cp /opt/flink-1.9.3-bin-scala_2.12.tgz /var/www/html/flink/
cp /opt/flink-shaded-hadoop-2-uber-2.6.5-7.0.jar /var/www/html/flink/
cp /opt/javax.ws.rs-api-2.0.jar /var/www/html/flink/
(2)下载ambari-flink-service服务
在外网服务器上
git clone https://ghproxy.com/https://gitee.com/liujingwen-git/ambari-flink-service-master.git /root/FLINK
注:github.com无法直接下载,可以使用gproxy.com进行代理加速,拼接形成加速URL;或者将github.com在本地强制解析为140.82.114.4
将FLINK文件夹上传到hdp01的/var/lib/ambari-server/resources/stacks/HDP/3.1/services/上,对应的版本可在集群的服务器中查看
hdp-select status hadoop-client | sed 's/hadoop-client - \([0-9]\.[0-9]\).*/\1/'
(3)文件说明
从github上下载的ambari-flink-service文件较多,有些可以删除以及修改

(4)修改metainfo.xml文件
文件位置:
/var/lib/ambari-server/resources/stacks/HDP/3.1/services/FLINK/metainfo.xml
修改版本
<name>FLINK</name><displayName>Flink</displayName><comment>Apache Flink is a streaming dataflow engine that provides data distribution, communication, and fault tolerance for distributed computations over data streams.</comment><version>1.9.3</version>
删除FLINK_MASTER,仅保留安装FLINK_CLIENT,在Flink on YARN模式下,master与ResourceManager合设,无需单独安装
<components><component><name>FLINK_CLIENT</name><displayName>FlinkCLIENT</displayName><category>CLIENT</category><cardinality>1+</cardinality><commandScript><script>scripts/flink_client.py</script><scriptType>PYTHON</scriptType><timeout>10000</timeout></commandScript></component></components>
(5)修改flink-ambari-config.xml文件
文件位置:
/var/lib/ambari-server/resources/stacks/HDP/3.1/services/FLINK/configuration/flink-ambari-config.xml
修改安装路径
<property><name>flink_install_dir</name><value>/usr/hdp/3.1.5.0-152/flink</value><description>Location to install Flink</description></property>
修改安装包下载地址
<property><name>flink_download_url</name><value>http://hdp01.hdp.com/flink/flink-1.9.3-bin-scala_2.12.tgz</value><description>Snapshot download location. Downloaded when setup_prebuilt is true</description></property><property><name>flink_hadoop_shaded_jar</name><value>http://hdp01.hdp.com/flink/flink-shaded-hadoop-2-uber-2.6.5-7.0.jar</value><description>Flink shaded hadoop jar download location. Downloaded when setup_prebuilt is true</description></property>
</configuration>
(6)修改flink-env.xml文件
文件位置:
/var/lib/ambari-server/resources/stacks/HDP/3.1/services/FLINK/configuration/flink-env.xml
修改JAVA环境变量
env.java.home: /usr/local/jdk1.8.0_351/jre/
(7)修改flink_client.py文件
文件位置:
/var/lib/ambari-server/resources/stacks/HDP/3.1/services/FLINK/package/scripts/flink_client.py
该文件的作用调用相关的环境变量,来实现整个安装过程
内容如下:
#!/usr/bin/env ptyhonfrom resource_management import *class FlinkClient(Script):def install(self, env):print 'Install the Flink Client'import paramsenv.set_params(params)self.configure(env)# create flink log dirDirectory(params.flink_log_dir,owner=params.flink_user,group=params.flink_group,create_parents=True,mode=0775)Execute(format("rm -rf {flink_install_dir}/log/flink"))Execute(format("ln -s {flink_log_dir} {flink_install_dir}/log/flink"))def configure(self, env):import paramsenv.set_params(params)# write out flink-conf.yamlproperties_content = InlineTemplate(params.flink_yaml_content)File(format(params.flink_install_dir + "/conf/flink-conf.yaml"), content=properties_content)def status(self, env):raise ClientComponentHasNoStatus()if __name__ == "__main__":FlinkClient().execute()
(8)修改parameter.py文件
文件位置:
/var/lib/ambari-server/resources/stacks/HDP/3.1/services/FLINK/package/scripts/params.py
该文件定义了部分环境变量
内容如下:
#!/usr/bin/env python
from resource_management import *
from resource_management.libraries.script.script import Script
import sys, os, glob
from resource_management.libraries.functions.version import format_stack_version
from resource_management.libraries.functions.default import default# server configurations
config = Script.get_config()# params from flink-ambari-config
flink_install_dir = config['configurations']['flink-ambari-config']['flink_install_dir']
flink_numcontainers = config['configurations']['flink-ambari-config']['flink_numcontainers']
flink_numberoftaskslots= config['configurations']['flink-ambari-config']['flink_numberoftaskslots']
flink_jobmanager_memory = config['configurations']['flink-ambari-config']['flink_jobmanager_memory']
flink_container_memory = config['configurations']['flink-ambari-config']['flink_container_memory']
setup_prebuilt = config['configurations']['flink-ambari-config']['setup_prebuilt']
flink_appname = config['configurations']['flink-ambari-config']['flink_appname']
flink_queue = config['configurations']['flink-ambari-config']['flink_queue']
flink_streaming = config['configurations']['flink-ambari-config']['flink_streaming']hadoop_conf_dir = config['configurations']['flink-ambari-config']['hadoop_conf_dir']
flink_download_url = config['configurations']['flink-ambari-config']['flink_download_url']
flink_hadoop_shaded_jar_url = config['configurations']['flink-ambari-config']['flink_hadoop_shaded_jar']
javax_ws_rs_api_jar = config['configurations']['flink-ambari-config']['javax_ws_rs_api_jar']conf_dir=''
bin_dir=''# params from flink-conf.yaml
flink_yaml_content = config['configurations']['flink-env']['content']
flink_user = config['configurations']['flink-env']['flink_user']
flink_group = config['configurations']['flink-env']['flink_group']
flink_log_dir = config['configurations']['flink-env']['flink_log_dir']
flink_log_file = os.path.join(flink_log_dir,'flink-setup.log')temp_file='/tmp/flink.tgz'
(9)添加用户及组
添加用户和组
groupadd flink
useradd -d /home/flink -g flink flink
(10)重启ambari服务
重启服务
ambari-server restart
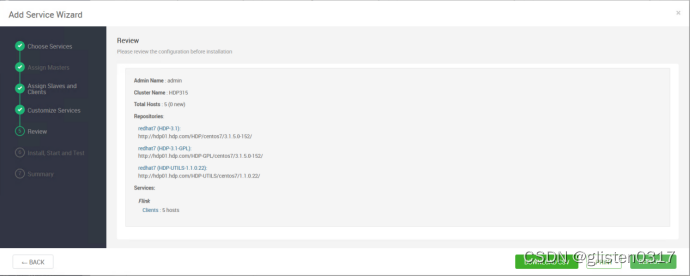
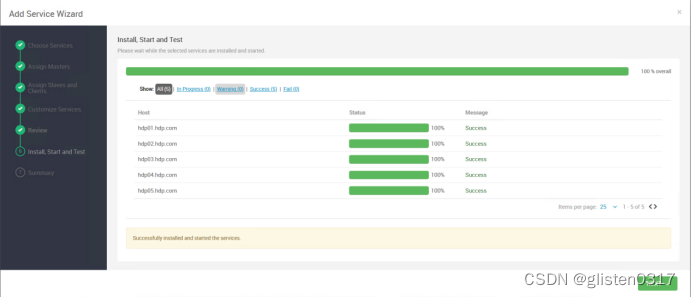
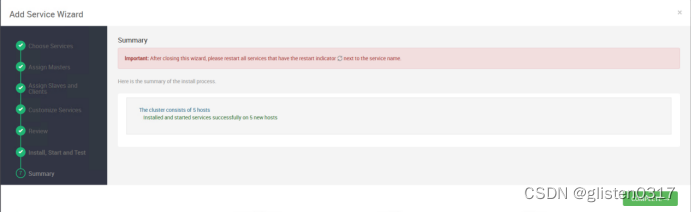
在ambari中的Stack and Versions中可以看到flink的信息
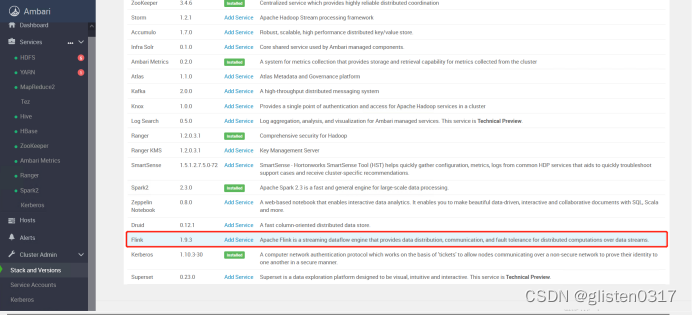
2.安装
添加flink服务
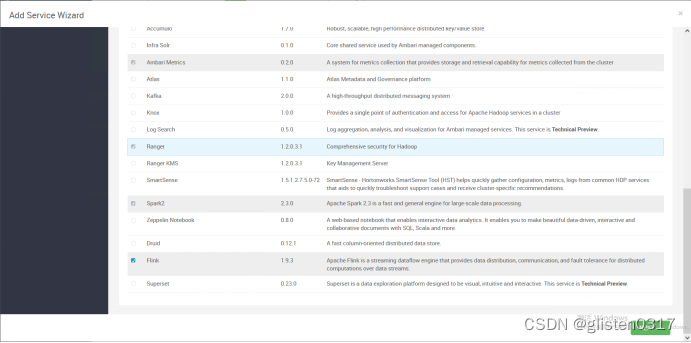

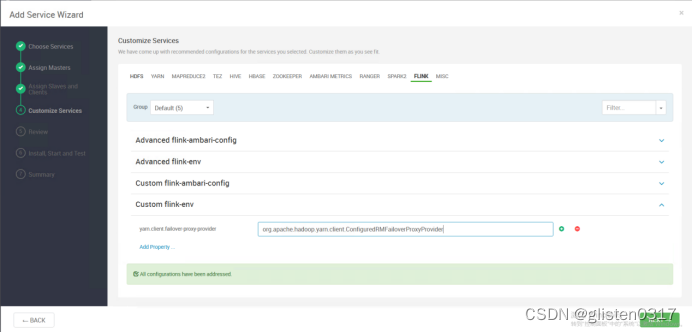
在Custom flink-env中新增
Key:yarn.client.failover-proxy-provider
Value:org.apache.hadoop.yarn.client.ConfiguredRMFailoverProxyProvider
3.实验:wordcount
实验:wordcount
从尚硅谷下载实验用的程序代码,在idea中对以socket形式接收数据流的代码进行修改,从192.168.111.1的nc处接收数据流,然后对词频统计后输出到本地文件中
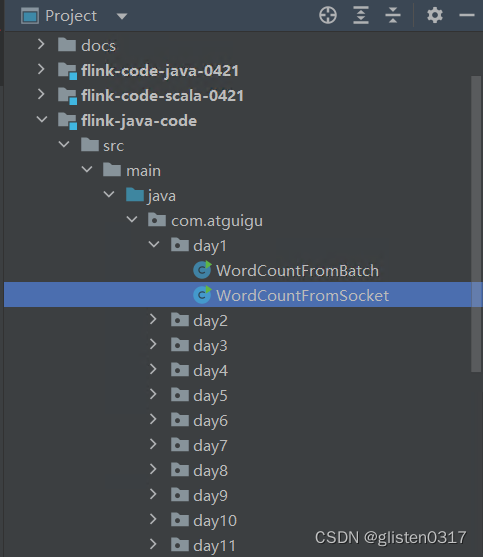
public static void main(String[] args) throws Exception {final StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();env.setParallelism(1);DataStream<String> stream = env.socketTextStream("192.168.111.1", 1234);DataStream<Tuple2<String, Integer>> resultStream = stream.flatMap(new Tokenizer()).keyBy(0).sum(1);resultStream.print();resultStream.writeAsText("/tmp/wc_result.txt");env.execute("Flink Streaming Java API Skeleton");
}
在idea中的Build->Build Artifacts中选择build生成jar包,然后上传到hdp05上,使用一个租户进行kerberos认证后,提交flink任务。
cd /usr/hdp/3.1.5.0-152/flink/bin/
./flink run -m yarn-cluster /root/flink-tutorial-master.jar -c WordCountFromSocket
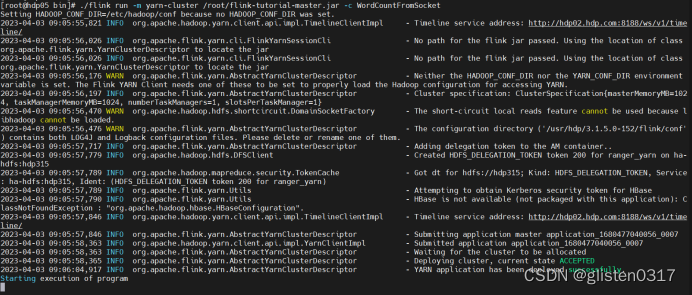
在192.168.111.1上启动nc
nc -l 1234

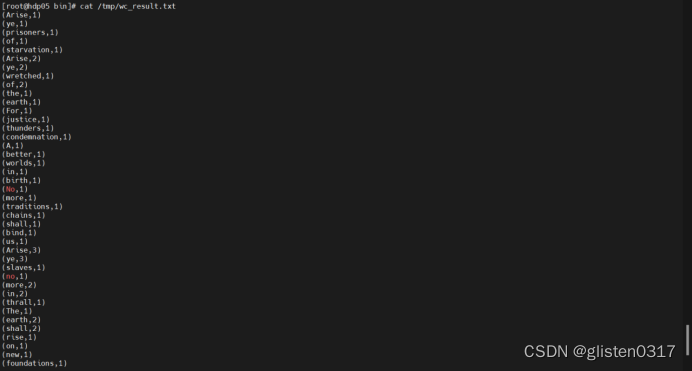
输入数据流后,中断nc进程,然后在hdp05上查看结果文件/tmp/wc_result.txt
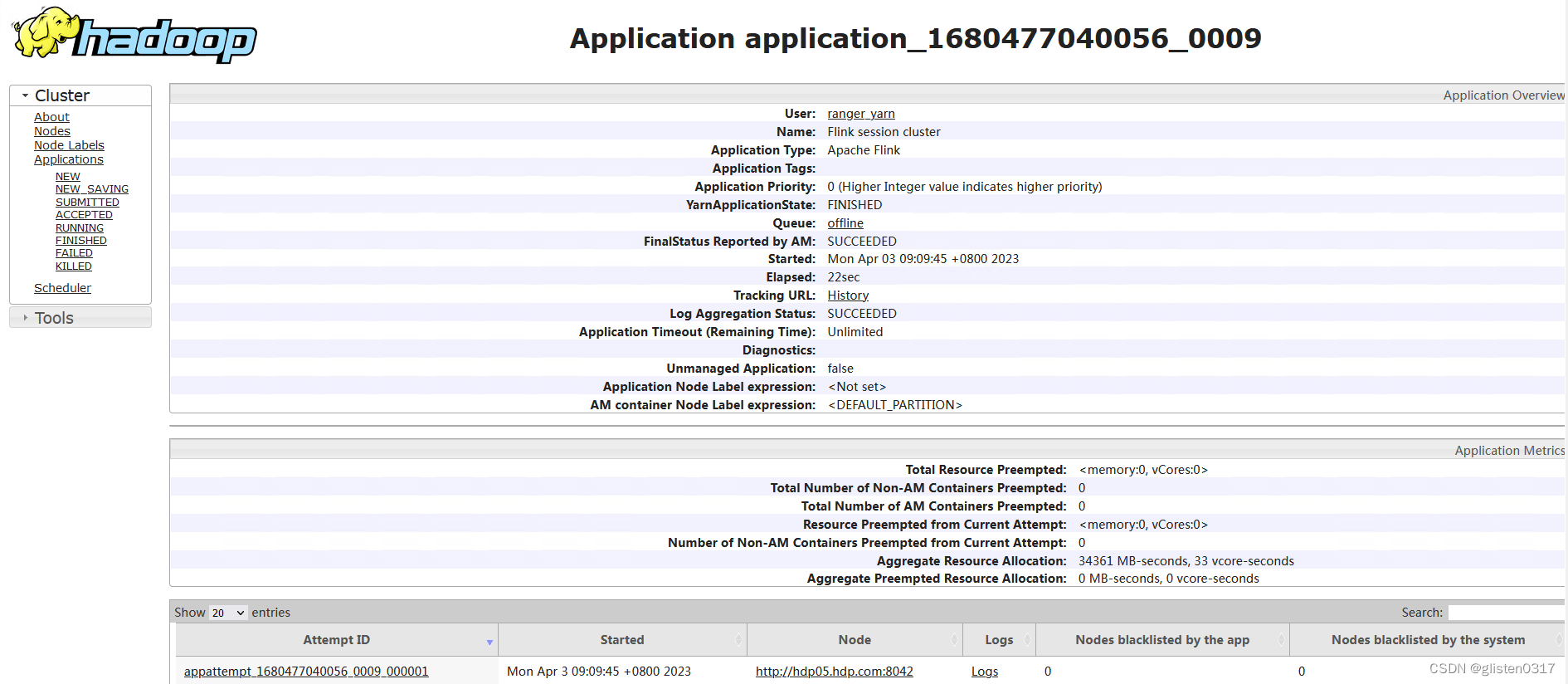
在yarn上可以查看到对应的应用信息
4.常见报错
(1)安装时报错Unable to run the custom hook script
报错信息:Error: Error: Unable to run the custom hook script [‘/usr/bin/python’, ‘/var/lib/ambari-agent/cache/stack-hooks/before-ANY/scripts/hook.py’, ‘ANY’, ‘/var/lib/ambari-agent/data/command-1360.json’, ‘/var/lib/ambari-agent/cache/stack-hooks/before-ANY’, ‘/var/lib/ambari-agent/data/structured-out-1360.json’, ‘INFO’, ‘/var/lib/ambari-agent/tmp’, ‘PROTOCOL_TLSv1_2’, ‘’]
2023-03-26 22:23:31,445 - The repository with version 3.1.5.0-152 for this command has been marked as resolved. It will be used to report the version of the component which was installed
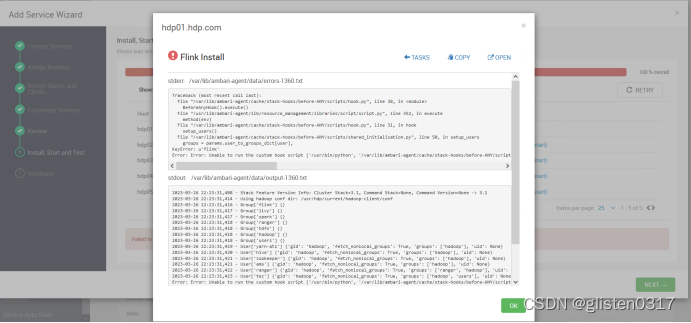
通过ambari添加自定义服务时,总是不能自动增加service账号
python configs.py -u admin -p lnyd@LNsy115 -n HDP315 -l hdp01 -t 8080 -a get -c cluster-env | grep -i ignore_groupsusers_create
python configs.py -u admin -p lnyd@LNsy115 -n HDP315 -l hdp01 -t 8080 -a set -c cluster-env -k ignore_groupsusers_create -v true

(2)安装后启动报错parent directory /usr/local/flink/conf doesn’t exist
安装后在启动时报错:resource_management.core.exceptions.Fail: Applying File[‘/usr/local/flink/conf/flink-conf.yaml’] failed, parent directory /usr/local/flink/conf doesn’t exist
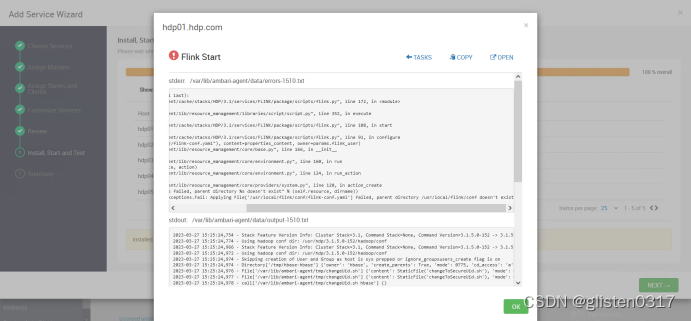
不知什么原因没解压过去,需要手动解压到该目录
tar -zxvf /opt/flink-1.9.3-bin-scala_2.12.tgz -C /root/
mv /root/flink-1.9.3/* /usr/local/flink/
(3)提交任务报错java.lang.NoClassDefFoundError
报错信息:
java.lang.NoClassDefFoundError: com/sun/jersey/core/util/FeaturesAndProperties
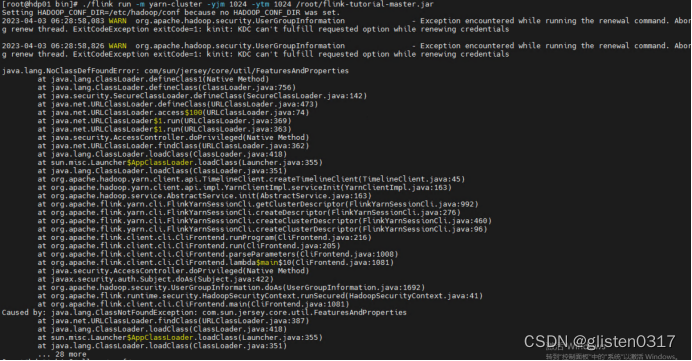
maven会自动下载相关的依赖jar包,因此需要将project下的jersey依赖jar包拷贝至flink的lib目录下

相关文章:
Hadoop学习笔记(HDP)-Part.18 安装Flink
目录 Part.01 关于HDP Part.02 核心组件原理 Part.03 资源规划 Part.04 基础环境配置 Part.05 Yum源配置 Part.06 安装OracleJDK Part.07 安装MySQL Part.08 部署Ambari集群 Part.09 安装OpenLDAP Part.10 创建集群 Part.11 安装Kerberos Part.12 安装HDFS Part.13 安装Ranger …...

LeetCode56. 合并区间
🔗:【贪心算法,合并区间有细节!LeetCode:56.合并区间-哔哩哔哩】 class Solution { public:vector<vector<int>> merge(vector<vector<int>>& intervals) {if(intervals.size()0){return intervals;…...
解决typescript报错:找不到名称xxx
现象: 原因:在同时导入默认导出和命名导出时,默认导出必须放在命名导出之前 下面的就是原始文件: 默认导出指: export default导出类型, import时无需大括号 命名导出指: 仅有export关键字…...
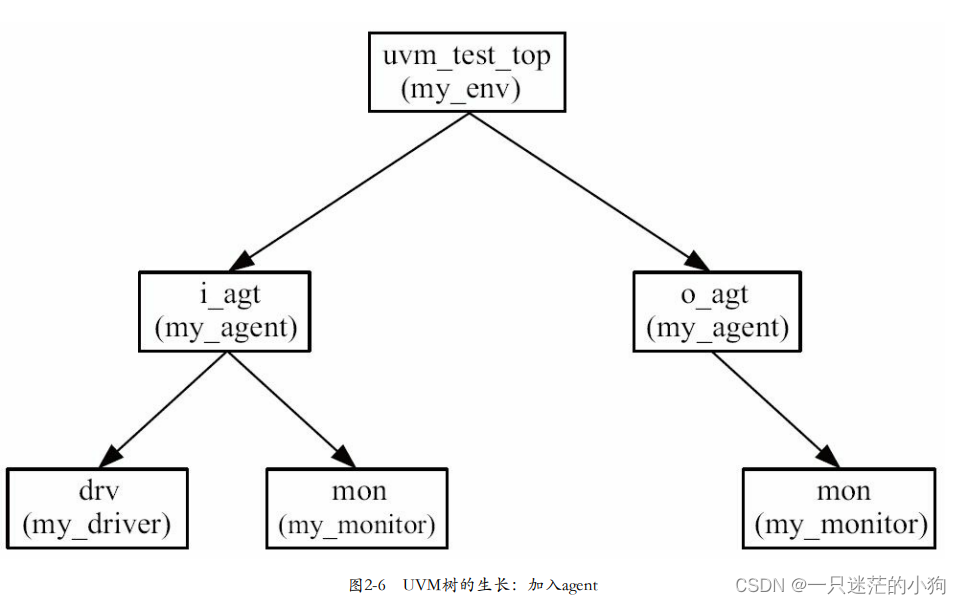
UVM中封装成agent
在验证平台中加入monitor时,看到driver和monitor之间的联系:两者之间的代码高度相似。其本质是因为二者 处理的是同一种协议,在同样一套既定的规则下做着不同的事情。由于二者的这种相似性,UVM中通常将二者封装在一起,…...
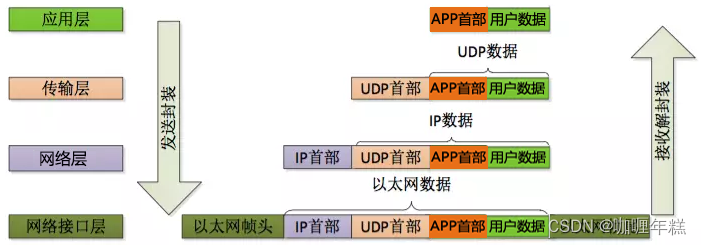
OSI七层模型与TCP/IP四层模型
一、OSI七层模型简述 OSI 模型的七层是什么?在 OSI 模型中如何进行通信?OSI 模型有哪些替代方案? TCP/IP 模型关于专有协议和模型的说明 二、七层模型详解(DNS、CDN、OSI) 状态码DNS nslookup命令 CDN whois命令 …...
QT 中 QProgressDialog 进度条窗口 备查
基础API //两个构造函数 QProgressDialog::QProgressDialog(QWidget *parent nullptr, Qt::WindowFlags f Qt::WindowFlags());QProgressDialog::QProgressDialog(const QString &labelText, const QString &cancelButtonText, int minimum, int maximum, QWidget *…...
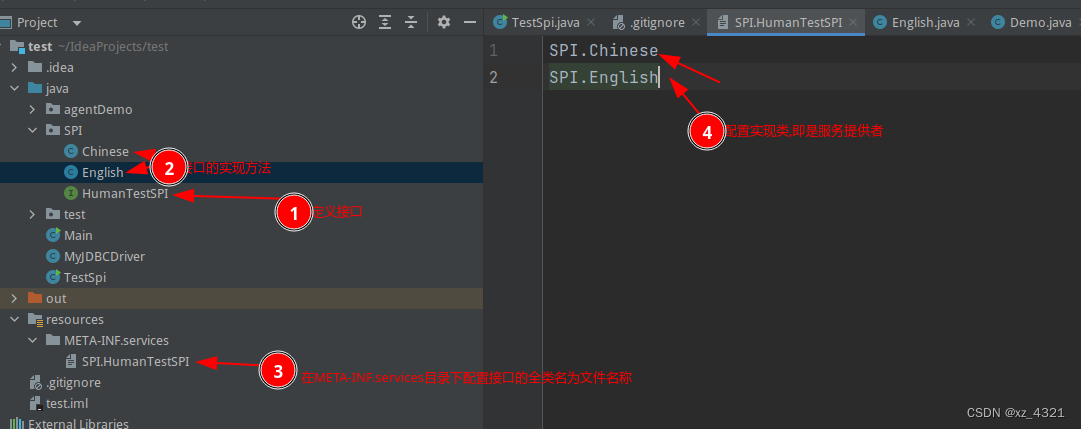
学习ShardingSphere前置知识
学习ShardingSphere前置准备知识 一. SPI SPI(Service Provider Interface)是一种Java的扩展机制,用于实现组件之间的松耦合。在SPI模型中,服务提供者(Service Provider)定义了一组接口,而服务…...
读书笔记-《数据结构与算法》-摘要3[选择排序]
选择排序 核心:不断地选择剩余元素中的最小者。 找到数组中最小元素并将其和数组第一个元素交换位置。在剩下的元素中找到最小元素并将其与数组第二个元素交换,直至整个数组排序。 性质: 比较次数(N-1)(N-2)(N-3)…21~N^2/2交换次数N运行…...
)
Arduino驱动MLX90614红外测温传感器(温湿度传感器)
目录 1、传感器特性 2、测量方法 3、硬件原理图 4、控制器和传感器连线图...

Ubuntu上传文件到SMB共享文件夹
0. 前言 公司有一些数据共享文件夹,平时可以把开发的重要文件放到上面备份。本人开发使用ubuntu系统,共享文件夹是windows的形式,想通过命令的方式,方便快捷,还可shell脚本自动化。 1. 安装挂载库 sudo apt-get upd…...

【Linux】基础IO--重定向理解Linux下一切皆文件缓冲区
文章目录 一、重定向1.什么是重定向2.dup2 系统调用3.理解输入重定向、输出重定向和追加重定向4.简易shell完整实现 二、理解linux下一切皆文件三、缓冲区1.为什么要有缓冲区2.缓冲区的刷新策略3.缓冲区的位置4.实现一个简易的C语言缓冲区5.内核缓冲区 一、重定向 1.什么是重定…...

RINEX介绍
一、RINEX是什么 Receiver Independent Exchange Format (RINEX) 是一种用于存储、交换和处理全球定位系统 (GPS) 接收机观测数据的标准化文件格式。RINEX 格式由国际电信联盟 (ITU) 和国际GPS服务 (IGS) 组织共同开发和维护。它提供了一种通用的数据格式,使得不同…...

ROS-ROS通信机制-服务通信
文章目录 一、服务通信基本知识二、自定义srv三、C实现四、Python实现 一、服务通信基本知识 服务通信也是ROS中一种极其常用的通信模式,服务通信是基于请求响应模式的,是一种应答机制。也即: 一个节点A向另一个节点B发送请求,B接收处理请求…...
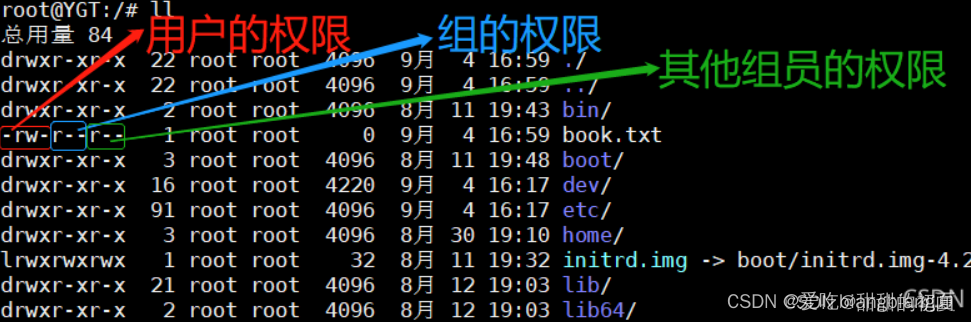
chown和chmod
chown和chmod都是在Linux和Unix系统中用于设置文件和文件夹权限的命令,但它们的功能和用途有所不同。 功能:chown主要用于修改文件或文件夹的所有者和所属组,而chmod则主要用于修改文件或文件夹的读写执行权限。用途:如果想要授权…...

【GPU】linux 安装、卸载 nvidia 显卡驱动、cuda 的官方文档、推荐方式(runfile)
文章目录 1. 显卡驱动1.1. 各版本下载地址1.2. 各版本文档地址1.3. 安装、卸载方式 2. CUDA2.1. 各版本下载地址2.2. 各版本文档地址2.3. 安装、卸载方式2.4. 多版本 CUDA 切换方式 1. 显卡驱动 1.1. 各版本下载地址 https://www.nvidia.com/Download/Find.aspx?langzh-cn 1…...
6页手写笔记总结信号与系统常考知识大题知识点
题型一 判断系统特性题型二 求系统卷积题型三 求三大变换正反变换题型四 求全响应题型五 已知微分方程求系统传递函数题型六 已知系统的传递函数求微分方程题型七 画出系统的零极点图,并判断系统的因果性和稳定性 (笔记适合快速复习,可能会有…...

Qt-QSplitter正确设置比例
简短版本: splitter->setSizes({1000, 2000}); // 这个值至少跟像素值设置的一样大,或者更大,例如x10倍详细版本: setSizes 官方介绍如下: Sets the child widgets’ respective sizes to the values given in the…...

一篇吃透大厂面试题,2024找工作一帆风顺。
🏆作者简介,普修罗双战士,一直追求不断学习和成长,在技术的道路上持续探索和实践。 🏆多年互联网行业从业经验,历任核心研发工程师,项目技术负责人。 🎉欢迎 👍点赞✍评论…...

【1day】用友 U8 Cloud系统TaskTreeQuery接口SQL注入漏洞学习
注:该文章来自作者日常学习笔记,请勿利用文章内的相关技术从事非法测试,如因此产生的一切不良后果与作者无关。 目录 一、漏洞描述 二、影响版本 三、资产测绘 四、漏洞复现...

华为快应用中自定义Slider效果
文章目录 一、前言二、实现代码三、参考链接 一、前言 在华为快应用中官方提供了<slider>控件,但是这个控件的限制比较多,比如滑块无法自定义,所以这里进行下自定义,自己修改样式。 二、实现代码 整体效果如下: 源码如下…...
Translumo终极指南:5步掌握实时屏幕翻译与OCR识别技术
Translumo终极指南:5步掌握实时屏幕翻译与OCR识别技术 【免费下载链接】Translumo Advanced real-time screen translator for games, hardcoded subtitles in videos, static text and etc. 项目地址: https://gitcode.com/gh_mirrors/tr/Translumo 你是否曾…...

桌面端酷安社区体验:Coolapk UWP 完整使用指南
桌面端酷安社区体验:Coolapk UWP 完整使用指南 【免费下载链接】Coolapk-UWP 一个基于 UWP 平台的第三方酷安客户端 项目地址: https://gitcode.com/gh_mirrors/co/Coolapk-UWP 你是否曾经希望在电脑大屏幕上舒适地浏览酷安社区,摆脱手机小屏幕的…...

从“记录系统”到“智能系统” From “System of Record” to “System of Intelligence” —— A16Z
From “System of Record” to “System of Intelligence” 从“记录系统”到“智能系统” https://www.a16z.news/p/from-system-of-record-to-system-of Here’s one way you can think about system of record stickiness: For a long time, the valuable part of social…...

东方博宜OJ入门题解:从A+B到高精度算法的实战解析
1. 东方博宜OJ平台入门指南 第一次接触在线评测系统(OJ)时,很多人都会被各种题目搞得晕头转向。东方博宜OJ作为国内知名的编程练习平台,特别适合编程新手从零开始系统学习。我刚开始刷题时也走过不少弯路,今天就和大家分享一些实战经验。 这…...

安卓位置伪装的终极指南:3步掌握应用级虚拟定位
安卓位置伪装的终极指南:3步掌握应用级虚拟定位 【免费下载链接】FakeLocation Xposed module to mock locations per app. 项目地址: https://gitcode.com/gh_mirrors/fak/FakeLocation 你是否曾因社交软件暴露真实位置而感到不安?是否需要在不同…...
)
PSIM 9.0 手把手教学:从零搭建直流电机双闭环调速模型(附完整代码与波形分析)
PSIM 9.0 手把手教学:从零搭建直流电机双闭环调速模型(附完整代码与波形分析) 在电力电子与电机控制领域,仿真技术已成为工程师和研究人员不可或缺的工具。PSIM作为一款专业的电力电子仿真软件,以其高效的仿真速度和直…...

【紧急更新】Perplexity v3.2.1已悄然移除默认引用锚点!立即启用这4种透明度兜底机制保学术安全
更多请点击: https://intelliparadigm.com 第一章:Perplexity引用透明度优化的紧急背景与影响评估 在大型语言模型推理链(Chain-of-Thought)与多跳检索增强生成(RAG)系统中,Perplexity 作为核心…...

贪吃蛇游戏开发实战:从基础架构到错误监控与性能优化
1. 项目概述:一个“会说话”的贪吃蛇游戏最近在GitHub上看到一个挺有意思的项目,叫“BugSplat-Git/snake-game”。初看标题,你可能觉得这不就是个经典的贪吃蛇游戏吗?从诺基亚时代玩到现在的玩意儿,还能有什么新花样&a…...

NotebookLM智能体插件:AI驱动的自动化知识处理与任务执行
1. 项目概述:当NotebookLM遇上智能体,知识处理的范式革命最近在AI圈子里,一个名为“notebooklm-agent-plugin”的项目引起了我的注意。乍一看,这个名字结合了Google的NotebookLM和当下火热的“智能体”(Agentÿ…...

Hotkey Detective:Windows热键冲突终极解决方案,快速定位“按键劫持“元凶
Hotkey Detective:Windows热键冲突终极解决方案,快速定位"按键劫持"元凶 【免费下载链接】hotkey-detective A small program for investigating stolen key combinations under Windows 7 and later. 项目地址: https://gitcode.com/gh_mir…...