RabbitMQ 笔记
Message durability
确保消息在server 出现问题或者recovery能恢复: declare it as durable in the producer and consumer code.
boolean durable = true;
channel.queueDeclare("hello", durable, false, false, null);
Queue 指定
//使用指定的queue,以便协同,注意各方声明时候属性要一致channel.queueDeclare(RPC_QUEUE_NAME, false, false, false, null);channel.queuePurge(RPC_QUEUE_NAME);
Fair dispatch
In order to defeat that we can use the basicQos method with the prefetchCount = 1 setting. This tells RabbitMQ not to give more than one message to a worker at a time.
exchange
rabbitmqctl list_exchanges
Listing exchanges for vhost / …
name type
amq.headers headers
amq.rabbitmq.trace topic
amq.topic topic
amq.match headers
direct
amq.direct direct
amq.fanout fanout
There are a few exchange types available: direct, topic, headers and fanout
默认exchange
default exchange, which we identify by the empty string (“”).
channel.basicPublish("", "hello", null, message.getBytes());
将queue与exchange 进行bind
channel.queueBind(queueName, EXCHANGE_NAME, "black");
The meaning of a binding key depends on the exchange type
Direct exchange
-
We were using a fanout exchange, which doesn’t give us much flexibility - it’s only capable of mindless broadcasting.
-
We will use a direct exchange instead. The routing algorithm behind a direct exchange is simple - a message goes to the queues whose binding key exactly matches the routing key of the message.
-
bind multiple queues with the same binding key. 基于全量match,即string equal
-
can’t do routing based on multiple criteria.
Topics
a message sent with a particular routing key will be delivered to all the queues that are bound with a matching binding key
基于表达式的分发
- star(*) can substitute for exactly one word.
- hash( #) can substitute for zero or more words.
When a queue is bound with “#” (hash) binding key - it will receive all the messages, regardless of the routing key - like in fanout exchange.
When special characters, “*” (star) and “#” (hash), aren’t used in bindings, the topic exchange will behave just like a direct one.
Headers Exchange
A headers exchange is designed for routing on multiple attributes that are more easily expressed as message headers than a routing key. Headers exchanges ignore the routing key attribute. Instead, the attributes used for routing are taken from the headers attribute. A message is considered matching if the value of the header equals the value specified upon binding.
It is possible to bind a queue to a headers exchange using more than one header for matching. In this case, the broker needs one more piece of information from the application developer, namely, should it consider messages with any of the headers matching, or all of them? This is what the “x-match” binding argument is for. When the “x-match” argument is set to “any”, just one matching header value is sufficient. Alternatively, setting “x-match” to “all” mandates that all the values must match.
For “any” and “all”, headers beginning with the string x- will not be used to evaluate matches. Setting “x-match” to “any-with-x” or “all-with-x” will also use headers beginning with the string x- to evaluate matches.
Headers exchanges can be looked upon as “direct exchanges on steroids”. Because they route based on header values, they can be used as direct exchanges where the routing key does not have to be a string; it could be an integer or a hash (dictionary) for example.
plugins
I have no name!@bca0cb31ba36:/$ rabbitmq-plugins listListing plugins with pattern "." ...Configured: E = explicitly enabled; e = implicitly enabled| Status: * = running on rabbit@queue-ram1|/[ ] rabbitmq_amqp1_0 3.12.10[ ] rabbitmq_auth_backend_cache 3.12.10[ ] rabbitmq_auth_backend_http 3.12.10[ ] rabbitmq_auth_backend_ldap 3.12.10[ ] rabbitmq_auth_backend_oauth2 3.12.10[ ] rabbitmq_auth_mechanism_ssl 3.12.10[ ] rabbitmq_consistent_hash_exchange 3.12.10[ ] rabbitmq_event_exchange 3.12.10[ ] rabbitmq_federation 3.12.10[ ] rabbitmq_federation_management 3.12.10[ ] rabbitmq_jms_topic_exchange 3.12.10[ ] rabbitmq_management 3.12.10[E] rabbitmq_management_agent 3.12.10
[ ] rabbitmq_mqtt 3.12.10
[ ] rabbitmq_peer_discovery_aws 3.12.10
[ ] rabbitmq_peer_discovery_common 3.12.10
[ ] rabbitmq_peer_discovery_consul 3.12.10
[ ] rabbitmq_peer_discovery_etcd 3.12.10
[ ] rabbitmq_peer_discovery_k8s 3.12.10
[E*] rabbitmq_prometheus 3.12.10
[ ] rabbitmq_random_exchange 3.12.10
[ ] rabbitmq_recent_history_exchange 3.12.10
[ ] rabbitmq_sharding 3.12.10
[ ] rabbitmq_shovel 3.12.10
[ ] rabbitmq_shovel_management 3.12.10
[ ] rabbitmq_stomp 3.12.10
[ ] rabbitmq_stream 3.12.10
[ ] rabbitmq_stream_management 3.12.10
[ ] rabbitmq_top 3.12.10
[ ] rabbitmq_tracing 3.12.10
[ ] rabbitmq_trust_store 3.12.10
[e*] rabbitmq_web_dispatch 3.12.10
[ ] rabbitmq_web_mqtt 3.12.10
[ ] rabbitmq_web_mqtt_examples 3.12.10
[ ] rabbitmq_web_stomp 3.12.10
[ ] rabbitmq_web_stomp_examples 3.12.10
参考 URL
Firehose Tracer Firehose Tracer — RabbitMQ
Plugin Development Basics — RabbitMQ
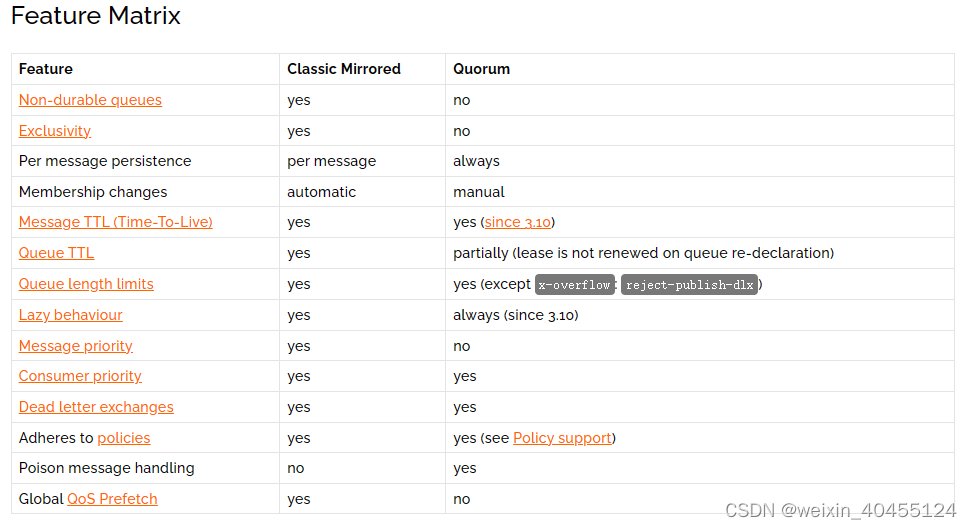
Queue Properties
Queues have properties that define how they behave. There is a set of mandatory properties and a map of optional ones:
- Name
- Durable (the queue will survive a broker restart)
- Exclusive (used by only one connection and the queue will be deleted when that connection closes)
- Auto-delete (queue that has had at least one consumer is deleted when last consumer unsubscribes)
- Arguments (optional; used by plugins and broker-specific features such as message TTL, queue length limit, etc)
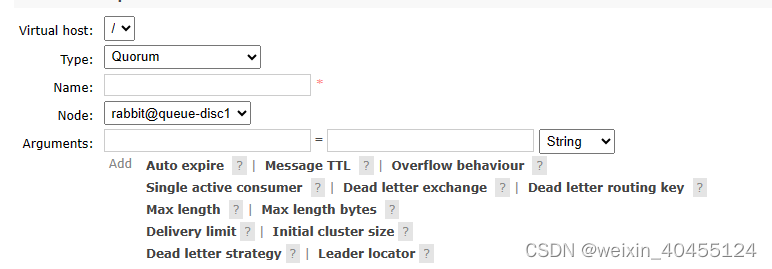
Queue type (e.g. quorum or classic) -推荐quorum,单quorum不支持messsage priority,对应append-only的log 类,推荐使用stream -Stream Plugin — RabbitMQ
Consumer priorities allow you to ensure that high priority consumers receive messages while they are active, with messages only going to lower priority consumers when the high priority consumers block.
When Not to Use Quorum Queues
In some cases quorum queues should not be used. They typically involve:
- Temporary nature of queues: transient or exclusive queues, high queue churn (declaration and deletion rates)
- Lowest possible latency: the underlying consensus algorithm has an inherently higher latency due to its data safety features
- When data safety is not a priority (e.g. applications do not use manual acknowledgements and publisher confirms are not used)
- Very long queue backlogs (streams are likely to be a better fit)
不同队列类型支持的属性


Durability
Transient queues will be deleted on node boot. They therefore will not survive a node restart, by design. Messages in transient queues will also be discarded.
Durable queues will be recovered on node boot, including messages in them published as persistent
Exclusive Queues
An exclusive queue can only be used (consumed from, purged, deleted, etc) by its declaring connection.
Replicated and Distributed Queues
Quorum queues is replicated, data safety and consistency-oriented queue type. Classic queues historically supported replication but it is deprecated and should be avoided.
Queues can also be federated across loosely coupled nodes or clusters.
Note that intra-cluster replication and federation are orthogonal features and should not be considered direct alternatives.
Streams is another replicated data structure supported by RabbitMQ, with a different set of supported operations and features.
Time-to-Live and Length Limit
Queues can have their length limited. Queues and messages can have a TTL.
RabbitMQ中的消息优先级是如何实现的?
注意 只有classic的队列支持优先级。
By default, RabbitMQ classic queues do not support priorities. When creating priority queues, a maximum priority can be chosen as you see fit. When choosing a priority value, the following factors need to be considered:
- There is some in-memory and on-disk cost per priority level per queue. There is also an additional CPU cost, especially when consuming, so you may not wish to create huge numbers of levels.
- The message priority field is defined as an unsigned byte, so in practice priorities should be between 0 and 255.
- Messages without priority property are treated as if their priority were 0. Messages with a priority which is higher than the queue’s maximum are treated as if they were published with the maximum priority.
channels
Maximum Number of Channels per Connection
On the server side, the limit is controlled using the channel_max:
# no more 100 channels can be opened on a connection at the same time
channel_max = 100
Clients can be configured to allow fewer channels per connection. With RabbitMQ Java client, ConnectionFactory#setRequestedChannelMax is the method that controls the limit:ConnectionFactory cf = new ConnectionFactory();
// Ask for up to 32 channels per connection. Will have an effect as long as the server is configured
// to use a higher limit, otherwise the server's limit will be used.
cf.setRequestedChannelMax(32);
Acknowledgements -确认
delivery tag -每个消息的唯一识别标志
When manual acknowledgements are used, any delivery (message) that was not acked is automatically requeued when the channel (or connection) on which the delivery happened is closed. This includes TCP connection loss by clients, consumer application (process) failures, and channel-level protocol exceptions (covered below).
Consumer Acknowledgement Modes and Data Safety Considerations
- basic.ack is used for positive acknowledgements
- basic.nack is used for negative acknowledgements (note: this is a RabbitMQ extension to AMQP 0-9-1)
- basic.reject is used for negative acknowledgements but has one limitation compared to basic.nack
channel.basicAck 支持批量确认
Manual acknowledgements can be batched to reduce network traffic. This is done by setting the multiple field of acknowledgement methods (see above) to true.
// AMQImpl.Queue.DeclareOk queueDeclare(String queue, boolean durable, boolean exclusive, boolean autoDelete, Map<String, Object> arguments)channel.queueDeclare(TASK_QUEUE_NAME, true, false, false, null);System.out.println(" [*] Waiting for messages. To exit press CTRL+C");
// 每次处理1 条消息channel.basicQos(1);DeliverCallback deliverCallback = (consumerTag, delivery) -> {String message = new String(delivery.getBody(), "UTF-8");System.out.println(" [x] Received '" + message + "'");try {doWork(message);} finally {System.out.println(" [x] Done");// false 待办单个channel.basicAck(delivery.getEnvelope().getDeliveryTag(), false);}};// public String basicConsume(String queue, boolean autoAck, DeliverCallback deliverCallback, CancelCallback cancelCallback) throws IOException {// 第二次参数标志是否自动ackchannel.basicConsume(TASK_QUEUE_NAME, false, deliverCallback, consumerTag -> { });
Negative Acknowledgement and Requeuing of Deliveries
This behaviour is controlled by the requeue field. When the field is set to true, the broker will requeue the delivery (or multiple deliveries, as will be explained shortly) with the specified delivery tag. Alternatively, when this field is set to false, the message will be routed to a Dead Letter Exchange if it is configured, otherwise it will be discarded.
// negatively acknowledge, the message will// be discardedchannel.basicReject(deliveryTag, false);
交给其它consumer 处理// requeue the deliverychannel.basicReject(deliveryTag, true);basic.nack 和Basic.Reject 的差异是支持批量// requeue all unacknowledged deliveries up to// this delivery tagchannel.basicNack(deliveryTag, true, true);
三者的实现代码
public void basicAck(long deliveryTag, boolean multiple) throws IOException {this.transmit(new AMQImpl.Basic.Ack(deliveryTag, multiple));this.metricsCollector.basicAck(this, deliveryTag, multiple);
}public void basicNack(long deliveryTag, boolean multiple, boolean requeue) throws IOException {this.transmit(new AMQImpl.Basic.Nack(deliveryTag, multiple, requeue));this.metricsCollector.basicNack(this, deliveryTag);
}public void basicReject(long deliveryTag, boolean requeue) throws IOException {this.transmit(new AMQImpl.Basic.Reject(deliveryTag, requeue));this.metricsCollector.basicReject(this, deliveryTag);
}
Publisher Confirms -生产者确认
-
To enable confirms, a client sends the confirm.select method. Depending on whether no-wait was set or not, the broker may respond with a confirm.select-ok. Once the confirm.select method is used on a channel, it is said to be in confirm mode.
-
通过计数来确认
-
Once a channel is in confirm mode, both the broker and the client count messages (counting starts at 1 on the first confirm.select). The broker then confirms messages as it handles them by sending a basic.ack on the same channel.
-
如要百分百确认消息落盘了,可以用confirm模式
In order to guarantee persistence, a client should use confirms. If the publisher’s channel had been in confirm mode, the publisher would not have received an ack for the lost message (since the message hadn’t been written to disk yet). -
可以在发送后同步获取( channel.waitForConfirmsOrDie(5_000);),也可以异步获取是否发送成功(channel.addConfirmListener((sequenceNumber, multiple) -> {
) 参考PublisherConfirms类
Channel Prefetch Setting (QoS)
获取数量
- A value of 0 means “no limit”, allowing any number of unacknowledged messages.
- The QoS setting can be configured for a specific channel or a specific consumer. The Consumer Prefetch guide explains the effects of this scoping.
// 每次处理1 条消息channel.basicQos(1);DeliverCallback deliverCallback = (consumerTag, delivery) -> {String message = new String(delivery.getBody(), "UTF-8");System.out.println(" [x] Received '" + message + "'");try {doWork(message);} finally {System.out.println(" [x] Done");// false 待办单个channel.basicAck(delivery.getEnvelope().getDeliveryTag(), false);}};// public String basicConsume(String queue, boolean autoAck, DeliverCallback deliverCallback, CancelCallback cancelCallback) throws IOException {// 第二次参数标志是否自动ackchannel.basicConsume(TASK_QUEUE_NAME, false, deliverCallback, consumerTag -> { });channel.consum//channel.getDefaultConsumer().handleCancel();Single Consumer
The following basic example in Java will receive a maximum of 10 unacknowledged messages at once:
Channel channel = ...;
Consumer consumer = ...;
channel.basicQos(10); // Per consumer limit
channel.basicConsume("my-queue", false, consumer);
A value of 0 is treated as infinite, allowing any number of unacknowledged messages.
Channel channel = ...;
Consumer consumer = ...;
channel.basicQos(0); // No limit for this consumer
channel.basicConsume("my-queue", false, consumer);
Independent Consumers
This example starts two consumers on the same channel, each of which will independently receive a maximum of 10 unacknowledged messages at once:
Channel channel = ...;
Consumer consumer1 = ...;
Consumer consumer2 = ...;
channel.basicQos(10); // Per consumer limit
channel.basicConsume("my-queue1", false, consumer1);
channel.basicConsume("my-queue2", false, consumer2);
Multiple Consumers Sharing the Limit
Channel channel = ...;
Consumer consumer1 = ...;
Consumer consumer2 = ...;
channel.basicQos(10, false); // Per consumer limit
channel.basicQos(15, true); // Per channel limit
channel.basicConsume("my-queue1", false, consumer1);
channel.basicConsume("my-queue2", false, consumer2);
Configurable Default Prefetch
RabbitMQ can use a default prefetch that will be applied if the consumer doesn’t specify one. The value can be configured as rabbit.default_consumer_prefetch in the advanced configuration file:
%% advanced.config file
[
{rabbit, [
{default_consumer_prefetch, {false,250}}
]
}
].
Queue Length Limit
The default behaviour for RabbitMQ when a maximum queue length or size is set and the maximum is reached is to drop or dead-letter messages from the front of the queue (i.e. the oldest messages in the queue). To modify this behaviour, use the overflow setting described below.
Queue Overflow Behaviour
Use the overflow setting to configure queue overflow behaviour. If overflow is set to reject-publish or reject-publish-dlx, the most recently published messages will be discarded. In addition, if publisher confirms are enabled, the publisher will be informed of the reject via a basic.nack message. If a message is routed to multiple queues and rejected by at least one of them, the channel will inform the publisher via basic.nack. The message will still be published to all other queues which can enqueue it. The difference between reject-publish and reject-publish-dlx is that reject-publish-dlx also dead-letters rejected messages.
What is a Lazy Queue
A “lazy queue” is a classic queue which is running in lazy mode. When the “lazy” queue mode is set, messages in classic queues are moved to disk as early as practically possible. These messages are loaded into RAM only when they are requested by consumers.
Exchange to Exchange Bindings
Java Client Example
Use the Channel#exchangeBind method. The following example binds an exchange “destination” to “source” with routing key “routingKey”.
Channel ch = conn.createChannel();
ch.exchangeBind("destination", "source", "routingKey");
---
Consumer Cancel Notification
- 用于优雅推出消费端
- if the client issues a basic.cancel on the same channel, which will cause the consumer to be cancelled and the server replies with a basic.cancel-ok.
public void basicCancel(final String consumerTag) throws IOException {
处理异常退出
channel.queueDeclare(queue, false, true, false, null);
Consumer consumer = new DefaultConsumer(channel) {@Overridepublic void handleCancel(String consumerTag) throws IOException {// consumer has been cancelled unexpectedly}
};
channel.basicConsume(queue, consumer);
boolean autoAck = false;
channel.basicConsume(queueName, autoAck, "myConsumerTag",new DefaultConsumer(channel) {@Overridepublic void handleDelivery(String consumerTag,Envelope envelope,AMQP.BasicProperties properties,byte[] body)throws IOException{String routingKey = envelope.getRoutingKey();String contentType = properties.getContentType();long deliveryTag = envelope.getDeliveryTag();// (process the message components here ...)channel.basicAck(deliveryTag, false);}});channel.basicCancel(consumerTag);
rabbitmq cluster
默认通过cookie 识别为同一cluster
In case of a node failure, clients should be able to reconnect to a different node, recover their topology and continue operation. For this reason, most client libraries accept a list of endpoints (hostnames or IP addresses) as a connection option. The list of hosts will be used during initial connection as well as connection recovery, if the client supports it. See documentation guides for individual clients to learn more.
Node Failure Handling
RabbitMQ brokers tolerate the failure of individual nodes. Nodes can be started and stopped at will, as long as they can contact a cluster member node known at the time of shutdown.
Quorum queue allows queue contents to be replicated across multiple cluster nodes with parallel replication and a predictable leader election and data safety behavior as long as a majority of replicas are online.
Non-replicated classic queues can also be used in clusters. Non-mirrored queue behaviour in case of node failure depends on queue durability.
client 端
Using Lists of Endpoints
It is possible to specify a list of endpoints to use when connecting. The first reachable endpoint will be used. In case of connection failures, using a list of endpoints makes it possible for the application to connect to a different node if the original one is down.
To use multiple of endpoint, provide a list of Addresses to ConnectionFactory#newConnection. An Address represents a hostname and port pair.
Address[] addrArr = new Address[]{ new Address(hostname1, portnumber1), new Address(hostname2, portnumber2)};
Connection conn = factory.newConnection(addrArr);
Disconnecting from RabbitMQ: To disconnect, simply close the channel and the connection:
channel.close();
conn.close();
RAM node
RAM node不落盘,可以选择RAM 对外提升性能,DISC node作为mirror和落盘保证。
相关文章:
RabbitMQ 笔记
Message durability 确保消息在server 出现问题或者recovery能恢复: declare it as durable in the producer and consumer code. boolean durable true; channel.queueDeclare("hello", durable, false, false, null);Queue 指定 //使用指定的queue&…...
DNS协议(DNS规范、DNS报文、DNS智能选路)
目录 DNS协议基本概念 DNS相关规范 DNS服务器的记录 DNS报文 DNS域名查询的两种方式 DNS工作过程 DNS智能选路 DNS协议基本概念 DNS的背景 我们知道主机通信需要依靠IP地址,但是每次通过输入对方的IP地址和对端通信不够方便,IP地址不好记忆 因此提…...

Python基础知识-变量、数据类型(整型、浮点型、字符类型、布尔类型)详解
1、基本的输出和计算表达式: prinit(12-3) printf(12*3) printf(12/3) prinit(12-3) printf(12*3) printf(12/3) 形如12-3称为表达式 这个表达式的运算结果称为 表达式的返回值 1 2 3 这样的数字,叫做 字面值常量 - * /称为 运算符或者操作符 在C和j…...
信息化,数字化,智能化是3种不同概念吗?与机械化,自动化矛盾吗?
先说结论: 1、信息化、数字化、智能化确实是3种不同的概念! 2、这3种概念与机械化、自动化并不矛盾,它们是制造业中不同发展阶段和不同层次的概念。 机械化:是指在生产过程中使用机械技术来辅助人工完成一些重复性、单一性、劳…...
C# WPF上位机开发(倒计时软件)
【 声明:版权所有,欢迎转载,请勿用于商业用途。 联系信箱:feixiaoxing 163.com】 生活当中,我们经常会遇到倒计时的场景,比如体育运动的时候、考试的时候等等。正好最近我们学习了c# wpf开发,完…...

Mysql timestamp和datetime区别
文章目录 一、存储范围和精度二、默认值和自动更新三、时区处理四、索引和性能五、存储空间和数据复制六、使用场景和注意事项七、时区转换 MySQL是一个常用的关系型数据库管理系统,其内置了多种数据类型用于存储和操作数据。其中,timestamp和datetime是…...

新手村之SQL——分组与子查询
1.GROUP BY GROUP BY 函数就是 SQL 中用来实现分组的函数,其用于结合聚合函数,能根据给定数据列的每个成员对查询结果进行分组统计,最终得到一个分组汇总表。 mysql> SELECT country, COUNT(country) AS teacher_count-> FROM teacher…...

【hacker送书第9期】算法训练营(入门篇)
第9期图书推荐 内容简介作者简介精彩书评图书目录概述参与方式 内容简介 本书以海量图解的形式,详细讲解常用的数据结构与算法,又融入大量的竞赛实例和解题技巧。通过对本书的学习,读者可掌握12种初级数据结构、15种常用STL函数、10种二叉树和…...
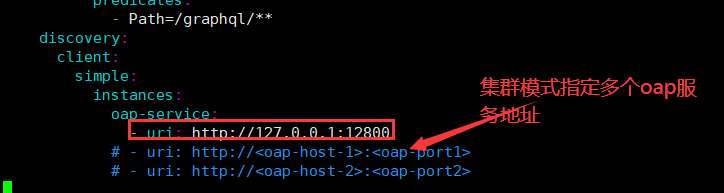
微服务链路追踪组件SkyWalking实战
概述 微服务调用存在的问题 串联调用链路,快速定位问题;理清服务之间的依赖关系;微服务接口性能分析;业务流程调用处理顺序; 全链路追踪:对请求源头到底层服务的调用链路中间的所有环节进行监控。 链路…...

ubuntu 更换国内镜像
备份 cd /etc/aptcp sources.list sources.list.bakup修改源为清华源 sed -i s/archive.ubuntu.com/mirrors.aliyun.com/g sources.list更新软件源 apt-get update其他源如下: mirrors.ustc.edu.cn 中科大 mirrors.163.com 163 mirrors.aliyun.com 阿里云...

树模型与深度模型对比
表格型数据为什么那么神奇,能让树模型在各种真实场景的表格数据中都战胜深度学习呢?作者认为有以下三种可能: 神经网络倾向于得到过于平滑的解冗余无信息的特征更容易影响神经网络 所以一定程度的特征交叉是不是必要的,因为one-ho…...

测试类运行失败:TestEngine with ID ‘junit-jupiter‘ failed to discover tests
背景:原本我的项目是可以运行的,然后我用另外一台电脑拉了下来,也是可以用的,但是很奇怪,用着用着就不能用了。报了以下错误: /Library/Java/JavaVirtualMachines/openjdk-11.jdk/Contents/Home/bin/java …...

nodejs使用node-cron实现定时任务功能
ChatGPT国内站点:海鲸AI 在Node.js中,node-cron是一个轻量级的任务调度库,它允许你根据类似于Cron的时间表来安排任务的执行。如果你想要每十分钟执行一次任务,你可以按照以下步骤来设置: 安装node-cron: 如…...

【1day】蓝凌OA 系统datajson.js接口远程命令执行漏洞学习
注:该文章来自作者日常学习笔记,请勿利用文章内的相关技术从事非法测试,如因此产生的一切不良后果与作者无关。 目录 一、漏洞概述 二、影响版本 三、资产测绘 四、漏洞复现...
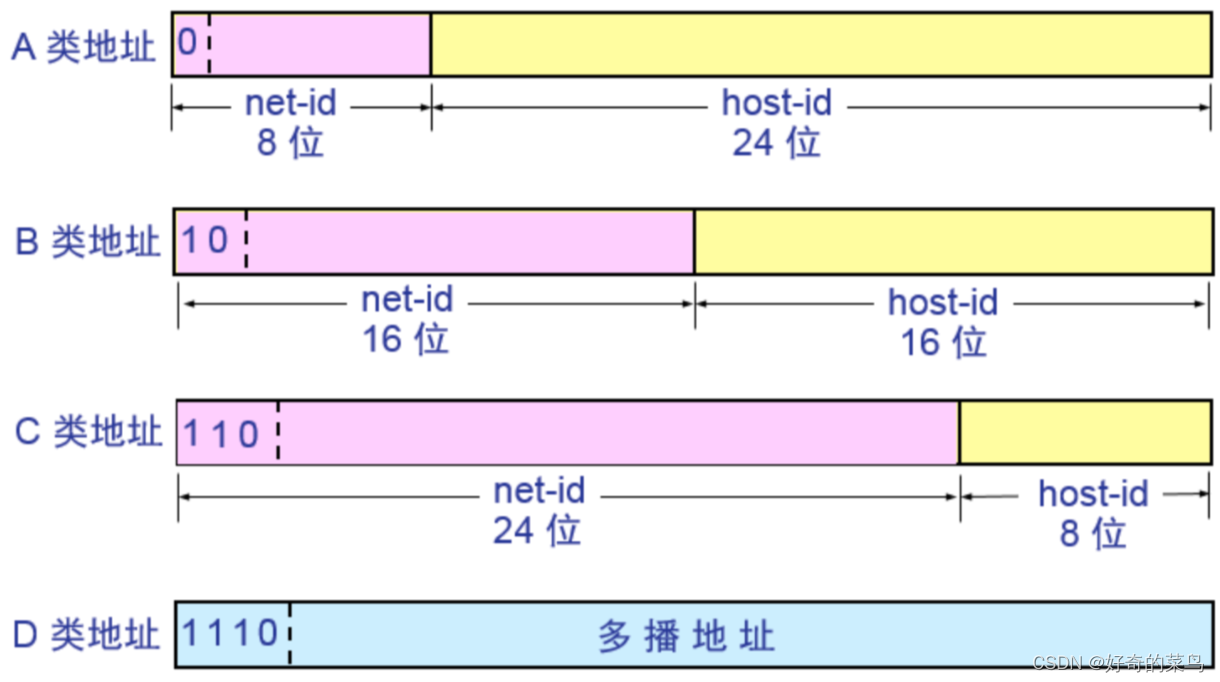
ABCDE类网络的划分及保留网段
根据IP地址的分类,IP地址被分为A、B、C、D和E五类。下面是对ABCDE类网络的划分及保留网段的详细描述: A类网络:范围从1.0.0.0到127.0.0.0,网络地址的最高位必须是“0”,可用的A类网络有127个,每个网络能容…...

营销系统规则引擎
一、系统介绍 规则引擎是一个用于执行营销规则的模块,其包括营销规则配置、规则校验等功能。规则引擎可以根据预先设定的条件和逻辑,自动化地执行特点的营销策略,帮助企业更好地吸引客户,增加销售和提高客户满意度。 规则引擎功能…...
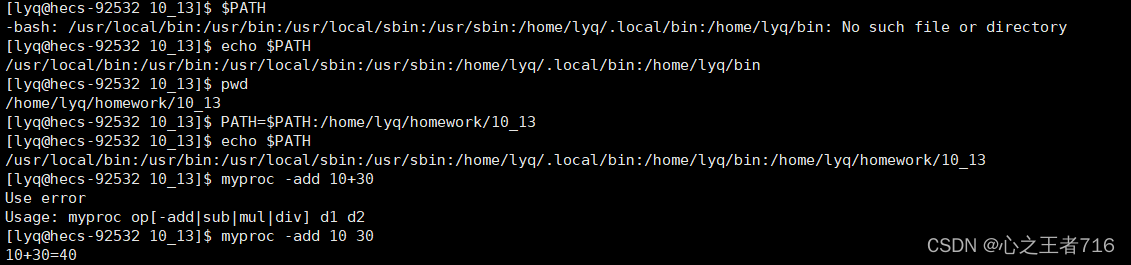
【Linux】命令行参数
文章目录 前言一、C语言main函数的参数二、环境变量总结 前言 我们在Linux命令行输入命令的时候,一般都会跟上一些参数选项,比如l命令,ls -a -l。以前我总是觉得这是理所当然的,没深究其本质究竟是什么,今天才终于知道…...

【信息安全】-个人敏感信息、个人信息、个人金融信息
文章目录 个人敏感信息个人敏感信息判定举例 个人信息个人信息判定举例 个人金融信息内容a) 账户信息指账户及账户相关信息b) 鉴别信息c) 金融交易信息d) 个人身份信息e) 财产信息f) 借贷信息g) 其他信息: 出处 个人敏感信息 个人敏感信息判定 个人敏感信息是指一旦泄露、非法…...

海外服务器和国内服务器有什么样的区别呢
海外服务器和国内服务器有什么样的区别呢,其实呢在外形方面是大同小异,除了外形还有一些其他方面还存在这一些差异。 一,地理位置的差异。 海外服务器——有可能在中国数据中心之外的任何国家地区,例如美国服务器,韩…...
电脑屏幕亮度怎么调?学会4个方法,轻松调节亮度!
“我总是感觉我电脑屏幕太暗了,有时候如果光线好一点,会看不清电脑屏幕。有什么可以把电脑调亮一点的简单方法吗?” 在我们的日常生活中,电脑已经成为我们工作、学习、娱乐不可或缺的工具。然而,长时间面对电脑屏幕可能…...

如何用WeChatExporter一键备份微信聊天记录:完整图文教程
如何用WeChatExporter一键备份微信聊天记录:完整图文教程 【免费下载链接】WeChatExporter 一个可以快速导出、查看你的微信聊天记录的工具 项目地址: https://gitcode.com/gh_mirrors/wec/WeChatExporter 你是否担心换手机后珍贵的微信聊天记录会消失&#…...

开源AI智能体dreamGPT:让大语言模型学会自主思考与目标探索
1. 项目概述:当AI学会“做梦”,一个开源智能体的自我进化实验最近在开源社区里,一个名为dreamGPT的项目引起了我的注意。它来自 DivergentAI,名字本身就充满了想象力——“梦想GPT”。这可不是一个简单的聊天机器人或者代码生成工…...

使用 SaySo 语音输入提升内容创作效率,从灵感到初稿的工作流实践
作为一个日更科技内容创作者,我每天都需要完成大量文字输出。包括工具测评、产品体验、干货笔记、技术趋势观察,以及一些观点类内容。长期写下来之后,我发现真正消耗时间的,不只是选题和思考,还有一个很容易被忽略的环…...

Java开发者如何快速接入Taotoken多模型API服务
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 Java开发者如何快速接入Taotoken多模型API服务 对于Java开发者而言,将大模型能力集成到后端应用或微服务中正成为一种常…...

VSCode配置C++开发环境:OpenCV跨平台实战指南
1. 为什么选择VSCode进行C开发? 很多刚接触C开发的同学都会纠结该用什么开发工具。我在刚入门时也试过各种IDE,从Visual Studio到CLion,最后发现VSCode才是最适合跨平台开发的轻量级选择。VSCode不仅免费开源,而且通过插件系统可以…...

Word崩溃自救指南:6大神器解决目录混乱、格式错乱等问题——从“目录生成失败“到“自动化办公“的6个神器
写论文写到一半,目录突然罢工;复制网页内容,英文全变宋体;电脑死机,三小时工作灰飞烟灭……如果你也被Word折磨过,这篇文章就是为你准备的救命指南。 一、引言:当Word成为你的"猪队友" 根据微软官方数据,全球每天有超过12亿人使用Office套件,其中Word的月活…...

011、逆Clark变换与逆Park变换
011、逆Clark变换与逆Park变换:从一次电机“鬼畜”抖动说起 有次调试一台永磁同步电机,电流环PI参数已经调得相当“丝滑”,转速响应也漂亮,结果一上负载,电机开始高频抖动,像踩了电门。示波器抓电流波形,发现三相电流里混着明显的6次谐波。当时第一反应是电流采样有问题…...

中小商家破局引流难题,AI 短剧营销系统低成本落地
一、中小商家引流普遍痛点现如今中小商家经营压力持续加大,付费推广费用高、转化不稳定,实拍广告制作成本昂贵。多数商家缺少专业运营、剪辑、策划人员,内容产出效率极低。 同时硬广营销用户抵触感强,平台审核严格,普通…...
)
用STC89C52单片机+DHT11做个简易温湿度计(附完整代码和串口打印)
基于STC89C52与DHT11的智能温湿度监测系统开发实战 在创客教育和嵌入式开发入门领域,温湿度监测系统一直是最受欢迎的实践项目之一。这个看似简单的项目实际上融合了传感器技术、单片机编程和通信协议三大核心技能,是检验初学者嵌入式开发能力的绝佳试金…...

别再只会轮询了!STM32CubeMX配置USART中断,从原理到调试一条龙指南
STM32串口中断实战:从轮询到事件驱动的效率跃迁 在嵌入式开发中,串口通信就像系统的神经末梢,负责与外界交换关键信息。传统轮询方式如同不断拨打电话确认消息,而中断机制则像设置来电提醒——只有当数据真正到达时才会唤醒CPU。这…...