01数仓平台 Hadoop介绍与安装
Hadoop概述
Hadoop 是数仓平台的核心组件。
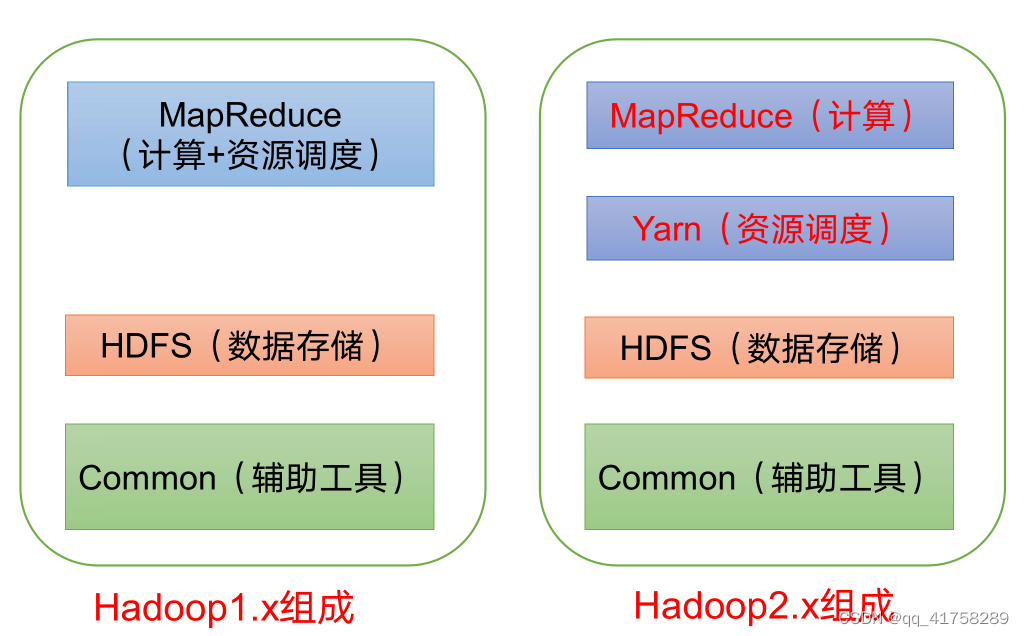
在 Hadoop1.x 时代,Hadoop 中的 MapReduce 同时处理业务逻辑运算和资源调度,耦合性较大。在 Hadoop2.x 时代,增加了 Yarn。Yarn 只负责资源的调度,MapReduce 只负责运算。Hadoop3.x 在架构上没有变化。
HDFS架构概述
Hadoop Distributed File System,简称HDFS,是一个分布式文件系统。包含NameNode(NN)、DataNode(DN)和Secondary NameNode(2NN)。
- NameNode: 存储文件的元数据,如文件名,文件目录结构,文件属性(生成时间、副本数、文件权限),以及每个文件的块列表和块所在的DataNode等。
- DataNode:在本地文件系统存储文件块数据,以及块数据的校验和。
- secondary NameNode:周期性的对NameNode元数据备份。
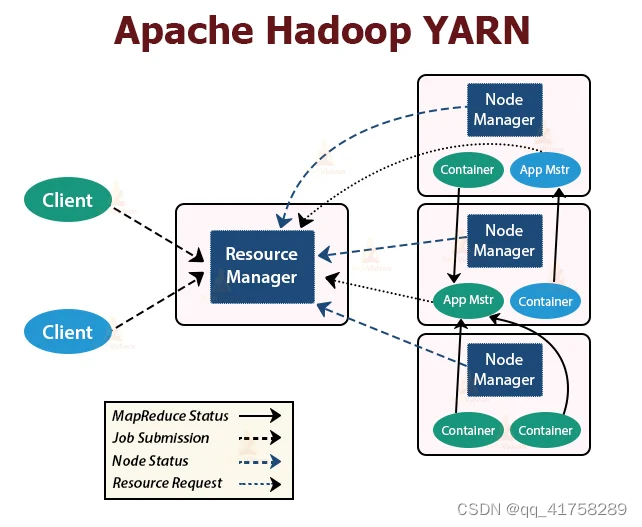
YARN架构概述
Yet Another Resource Negotiator(YARN)是资源管理协调调度工具,是Hadoop的资源管理器。
MapReduce 架构概述
MapReduce 是对数据进行计算的架构,分为 Map 和 Reduce2 个阶段。
- Map阶段并行处理输入数据
- Reduce阶段对 Map结果进行汇总
Hadoop job 执行逻辑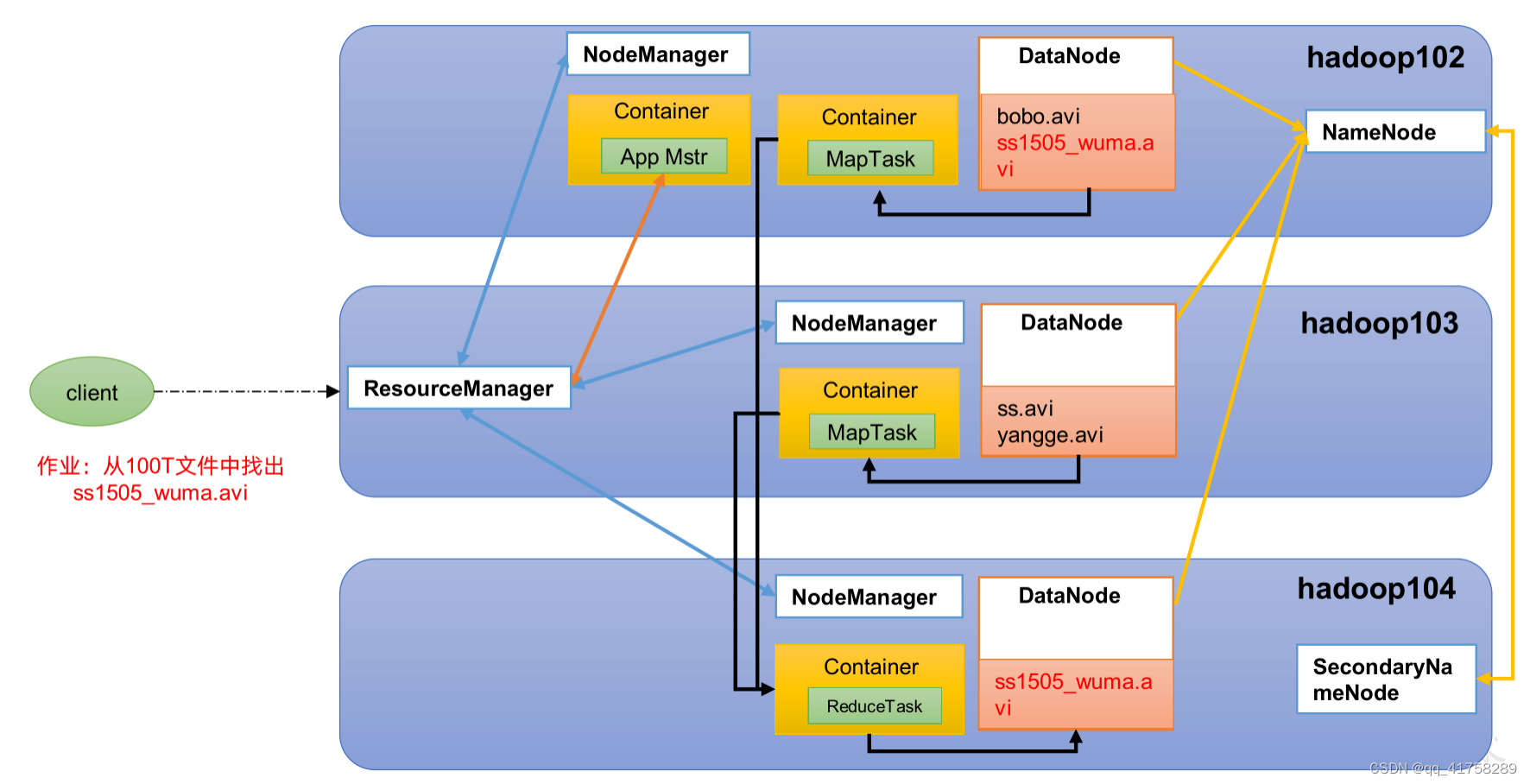
Hadoop 完全分布式运行模式(开发重点)
1)准备3台客户机(关闭防火墙、静态IP、主机名称)
2)安装JDK
3)配置环境变量
4)安装Hadoop
5)配置环境变量
6)配置集群
7)单点启动
8)配置ssh
9)群起并测试集群
配置3台服务器免密与分发脚本
免密配置
- 3台服务器上生成公钥和私钥,这里用 hadoop101 举例
[logan@hadoop101 hadoop-3.1.3]$ ssh-key-gen -t rsa - 将公钥拷贝到 3 台服务器上
[logan@hadoop101 hadoop-3.1.3]$ ssh-copy-id hadoop101
[logan@hadoop101 hadoop-3.1.3]$ ssh-copy-id hadoop102
[logan@hadoop101 hadoop-3.1.3]$ ssh-copy-id hadoop103
- 重复在 hadoop102 上生成公钥和私钥,并进行拷贝
- 重复在 hadoop103 上生成公钥和私钥,并进行拷贝
编写集群分发脚本
- 在 home 目录下创建bin 文件夹
[logan@hadoop101 ~]$ mkdir bin - 在创建的 bin 目录下创建 xsync 脚本
[logan@hadoop101 ~]$ cd /home/logan/bin/
[logan@hadoop101 bin]$ vim xsync
3.编写脚本内容如下
#!/bin/bash
#1. 判断参数个数
if [ $# -lt 1 ]
thenecho Not Enough Arguement!exit;
fi#2. 遍历集群所有机器
for host in hadoop101 hadoop102 hadoop103
doecho ==================== $host ====================#3. 遍历所有目录,挨个发送for file in $@do#4. 判断文件是否存在if [ -e $file ]then#5. 获取父目录pdir=$(cd -P $(dirname $file); pwd)#6. 获取当前文件的名称fname=$(basename $file)ssh $host "mkdir -p $pdir"rsync -av $pdir/$fname $host:$pdirelseecho $file does not exists!fidone
done
JDK准备
- 卸载 3 台服务器上的 JDK
[logan@hadoop101 bin]# sudo rpm -qa | grep -i java | xargs -n1 sudo rpm -e --nodeps[logan@hadoop102 bin]# sudo rpm -qa | grep -i java | xargs -n1 sudo rpm -e --nodeps[logan@hadoop103 bin]# sudo rpm -qa | grep -i java | xargs -n1 sudo rpm -e --nodeps
- 使用 sftp 上传或者下载 jdk1.8
- 解压jdk 文件
[logan@hadoop101 module]tar -zxvf jdk-8u212-linux-x64.tar.gz -C /opt/module/
- 配置JDK 环境变量
[logan@hadoop101 module]$ sudo vim /etc/profile.d/my_env.sh,增加以下内容
#JAVA_HOME
export JAVA_HOME=/opt/module/jdk1.8.0_212
export PATH=$PATH:$JAVA_HOME/bin
- 刷新环境变量
source /etc/profile - 检查Java 是否正常安装
java -version - 分发 JDK
xsync /opt/module/jdk1.8.0_212/ - 更新 hadoop102 和 103 上的配置文件, 检查 Java 是否正常安装
[logan@hadoop102 module]$ source /etc/profile
[logan@hadoop103 module]$ source /etc/profile
Hadoop部署
1)集群部署规划
注意:NameNode和SecondaryNameNode不要安装在同一台服务器
注意:ResourceManager也很消耗内存,不要和NameNode、SecondaryNameNode配置在同一台机器上。
2)将hadoop-3.1.3.tar.gz导入到opt目录下面的software文件夹下面
3)进入到Hadoop安装包路径下
[logan@hadoop101 ~]$ cd /opt/software/
4)解压安装文件到/opt/module下面
[logan@hadoop101 software]$ tar -zxvf hadoop-3.1.3.tar.gz -C /opt/module/
5)查看是否解压成功
ls /opt/module/hadoop-3.1.3
6)将Hadoop添加到环境变量
- 获取Hadoop安装路径
[logan@hadoop101 hadoop-3.1.3]$ pwd
/opt/module/hadoop-3.1.3
- 打开/etc/profile.d/my_env.sh文件
sudo vim /etc/profile.d/my_env.sh
- 在profile文件末尾添加JDK路径:(shitf+g)
#HADOOP_HOME
export HADOOP_HOME=/opt/module/hadoop-3.1.3
export PATH=$PATH:$HADOOP_HOME/bin
export PATH=$PATH:$HADOOP_HOME/sbin
- 保存后退出
:wq - 分发环境变量文件
sudo /home/atguigu/bin/xsync /etc/profile.d/my_env.sh - 各服务器上`source /etc/profile生效
Hadoop 核心配置
1)转到配置目录
[logan@hadoop101 hadoop]$ cd /opt/module/hadoop-3.1.3/etc/hadoop
2)配置core-site 文件vim core-site.xml
<?xml version="1.0" encoding="UTF-8"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration><!-- 指定 NameNode 的地址 --><property><name>fs.defaultFS</name><value>hdfs://hadoop101:8020</value></property><!-- 指定 hadoop 数据的存储目录 --><property><name>hadoop.tmp.dir</name><value>/opt/module/hadoop-3.1.3/data</value></property><!-- 配置 HDFS 网页登录使用的静态用户为 atguigu --><property><name>hadoop.http.staticuser.user</name><value>logan</value></property>
</configuration>
3)HDFS 配置文件vim hdfs-site.yml
<?xml version="1.0" encoding="UTF-8"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration>
<!-- nn web 端访问地址-->
<property><name>dfs.namenode.http-address</name><value>hadoop101:9870</value>
</property>
<!-- 2nn web 端访问地址--><property><name>dfs.namenode.secondary.http-address</name><value>hadoop103:9868</value></property>
<property><name>dfs.namenode.handler.count</name><value>10</value>
</property>
</configuration>
4)配置yarn-site 文件vim yarn-site.xml
<?xml version="1.0" encoding="UTF-8"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration><!-- 指定 MR 走 shuffle --><property><name>yarn.nodemanager.aux-services</name><value>mapreduce_shuffle</value></property><!-- 指定 ResourceManager 的地址--><property><name>yarn.resourcemanager.hostname</name><value>hadoop102</value></property><!-- 环境变量的继承 --><property><name>yarn.nodemanager.env-whitelist</name><value>JAVA_HOME,HADOOP_COMMON_HOME,HADOOP_HDFS_HOME,HADOOP_CO
NF_DIR,CLASSPATH_PREPEND_DISTCACHE,HADOOP_YARN_HOME,HADOOP_MAP
RED_HOME</value></property>
5)MapReduce配置文件 vim mapred-site.xml
<?xml version="1.0" encoding="UTF-8"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration>
<!-- 指定 MapReduce 程序运行在 Yarn 上 --><property><name>mapreduce.framework.name</name><value>yarn</value></property>
<property><name>yarn.app.mapreduce.am.env</name><value>HADOOP_MAPRED_HOME=/opt/module/hadoop-3.1.3</value>
</property>
<property><name>mapreduce.map.env</name><value>HADOOP_MAPRED_HOME=/opt/module/hadoop-3.1.3</value>
</property>
<property><name>mapreduce.reduce.env</name><value>HADOOP_MAPRED_HOME=/opt/module/hadoop-3.1.3</value>
</property>
</configuration>
6)配置 workers vim workers
hadoop101
hadoop102
hadoop103
配置历史服务器
- 配置
vim mapred-site.xml,在文件中新增如下内容
<!-- 历史服务器端地址 -->
<property><name>mapreduce.jobhistory.address</name><value>hadoop101:10020</value>
</property>
<!-- 历史服务器 web 端地址 -->
<property><name>mapreduce.jobhistory.webapp.address</name><value>hadoop101:19888</value>
</property>
配置日志聚集
注意:开启日志聚集功能,需要重启NodeManager、ResourceManager和 HistoryManager。
- 配置yarn-site.xml
<!-- 开启日志聚集功能 -->
<property><name>yarn.log-aggregation-enable</name><value>true</value>
</property>
<!-- 设置日志聚集服务器地址 -->
<property> <name>yarn.log.server.url</name> <value>http://hadoop101:19888/jobhistory/logs</value>
</property>
<!-- 设置日志保留时间为 7 天 -->
<property><name>yarn.log-aggregation.retain-seconds</name><value>604800</value>
</property>
</configuration>
分发 Hadoop
[logan@hadoop101 hadoop]$ xsync /opt/module/hadoop-3.1.3/
群起集群
- 第一次启动集群,需要在hadoop101上格式化 NameNode(格式化之前需要停止所有 NameNode 和 DataNode进程,然后删除data 和 log 数据)
hdfs namenode -format - 启动 HDFS
start-dfs.sh - 启动 YARN
start-yarn.sh - Web 端查看 HDFS 进行校验 http://hadoop101:9870
- Web端查看SecondaryNameNode http://hadoop103:9868
Hadoop 集群启动脚本
vim创建/home/logan/bin/hdp.sh脚本
#!/bin/bash
if [ $# -lt 1 ]
thenecho "No Args Input..."exit ;
fi
case $1 in
"start")echo " =================== 启动 hadoop集群 ==================="echo " --------------- 启动 hdfs ---------------"ssh hadoop101 "/opt/module/hadoop-3.1.3/sbin/start-dfs.sh"echo " --------------- 启动 yarn ---------------"ssh hadoop102 "/opt/module/hadoop-3.1.3/sbin/start-yarn.sh"echo " --------------- 启动 historyserver ---------------"ssh hadoop101 "/opt/module/hadoop-3.1.3/bin/mapred --daemon start historyserver"
;;
"stop")echo " =================== 关闭 hadoop集群 ==================="echo " --------------- 关闭 historyserver ---------------"ssh hadoop101 "/opt/module/hadoop-3.1.3/bin/mapred --daemon stop historyserver"echo " --------------- 关闭 yarn ---------------"ssh hadoop102 "/opt/module/hadoop-3.1.3/sbin/stop-yarn.sh"echo " --------------- 关闭 hdfs ---------------"ssh hadoop101 "/opt/module/hadoop-3.1.3/sbin/stop-dfs.sh"
;;
*)echo "Input Args Error..."
;;
esac
- 增加执行权限
chmod +x /home/logan/bin/hdp.sh
相关文章:
01数仓平台 Hadoop介绍与安装
Hadoop概述 Hadoop 是数仓平台的核心组件。 在 Hadoop1.x 时代,Hadoop 中的 MapReduce 同时处理业务逻辑运算和资源调度,耦合性较大。在 Hadoop2.x 时代,增加了 Yarn。Yarn 只负责资源的调度,MapReduce 只负责运算。Hadoop3.x 在…...

网络编程HTTP协议进化史
一、Http报文格式 具有约定格式的数据块 请求报文 request 状态行:本次请求的请求方式(post get)资源路径url http 协议的版本号,中间用空格划分 本次请求的请求方式(post get)资源路径url http 协议…...

第17章 匿名函数
第17.1节 匿名函数的基本语法 [捕获列表](参数列表) mutable(可选) 异常属性 -> 返回类型 { // 函数体 }语法规则:lambda表达式可以看成是一般函数的函数名被略去,返回值使用了一个 -> 的形式表示。唯一与普通函数不同的是增加了“捕获列表”。 …...

JVM虚拟机:JVM参数之标配参数
本文重点 本文我们将学习JVM中的标配参数 标配参数 从jdk刚开始就有的参数,比如: -version -help -showversion...

UEC++ 探索虚幻5笔记(捡金币案例) day12
吃金币案例 创建金币逻辑 之前的MyActor_One.cpp,直接添加几个资源拿着就用 //静态网格UPROPERTY(VisibleAnywhere, BlueprintReadOnly)class UStaticMeshComponent* StaticMesh;//球形碰撞体UPROPERTY(VisibleAnywhere, BlueprintReadWrite)class USphereCompone…...

Docker 安装 Redis 挂载配置
1. 创建挂载文件目录 mkdir -p /home/redis/config mkdir -p /home/redis/data # 创建配置文件:docker容器中默认不包含配置文件 touch /home/redis/config/redis.conf2. 书写配置文件 # Redis 服务器配置# 绑定的 IP 地址,默认为本地回环地址 127.0.0…...
Java操作Excel之 POI介绍和入门
POI是Apache 提供的一个开源的Java API,用于操作Microsoft文档格式,如Excel、Word和PowerPoint等。POI是Java中处理Microsoft文档最受欢迎的库。 截至2023/12, 最新版本时 POI 5.2.5。 JDK版本兼容 POI版本JDK版本4.0及之上版本> 1.83.…...

麒麟v10 数据盘初始化 gpt分区
麒麟v10 数据盘初始化 gpt分区 1、查看磁盘 lsblk2 、分区 parted2.1、 设置磁盘分区形式2.2、 设置磁盘的计量单位为磁柱2.3、 分区2.4、 查看分区 3、分区格式化4、 挂载磁盘4.1、新建挂载目录4.2、挂载磁盘4.3、查看挂载结果 5、设置开机自动挂载磁盘分区5.1、 查询磁盘分区…...

php时间和centos时间不一致
PHP 时间和 CentOS 操作系统时间不一致的问题通常是由于时区设置不同造成的。解决这个问题可以通过以下几个步骤: 检查 CentOS 系统时间: 你可以通过在终端运行命令 date 来查看当前的系统时间和时区。 配置 CentOS 的时区: 如果系统时间不正…...

软件工程 复习笔记
目录 概述 软件的定义,特点和分类 软件的定义 软件的特点 软件的分类 软件危机的定义和表现形式 软件危机 表现形式 软件危机的产生原因及解决途径 产生软件危机的原因 软件工程 概念 软件工程的研究内容和基本原理 内容 软件工程的基本原理 软件过程…...
SpringBoot_02
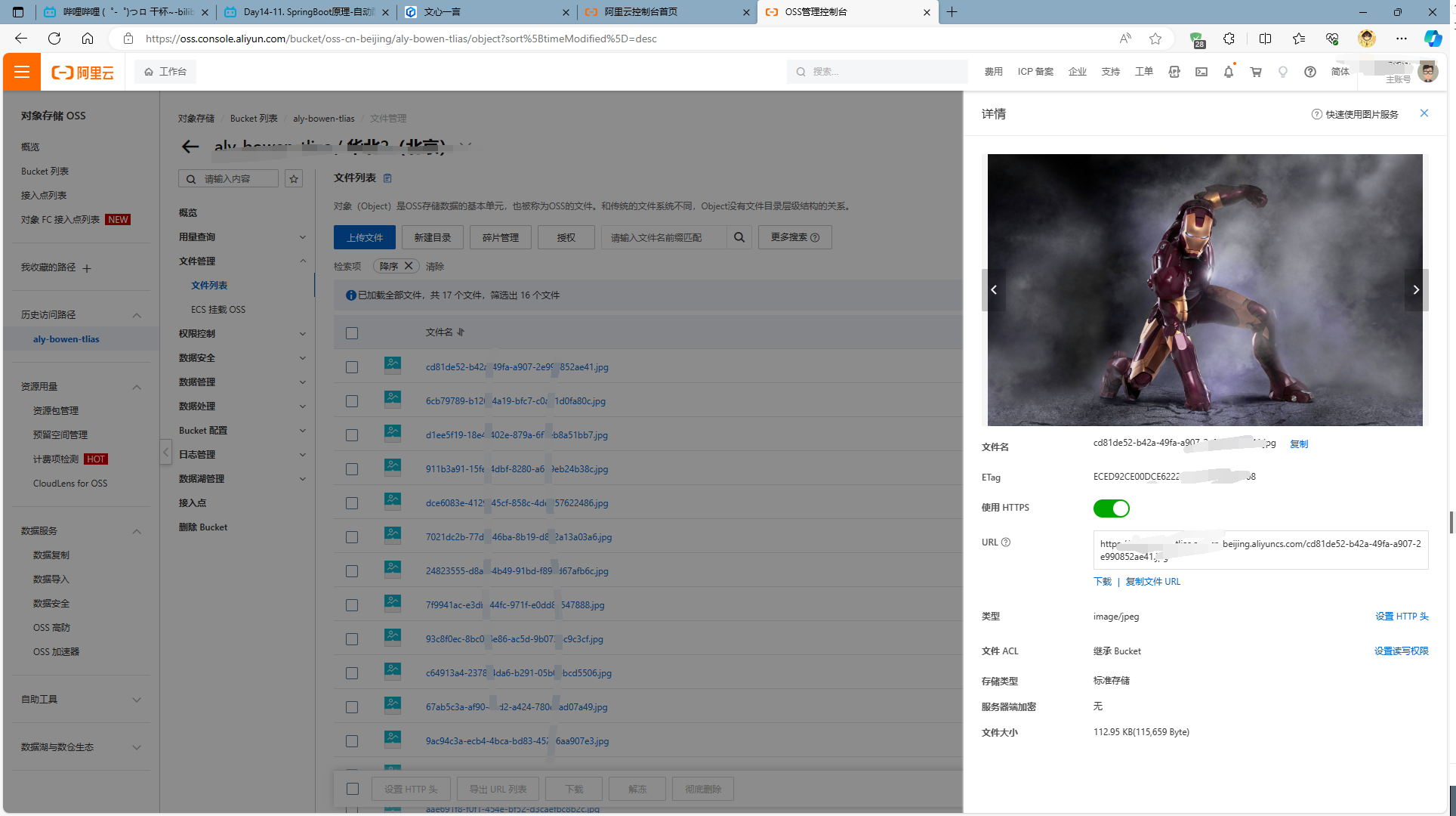
Web后端开发_07 SpringBoot_02 SpringBoot原理 1.配置优先级 1.1配置 SpringBoot中支持三种格式的配置文件: application.propertiesapplication.ymlapplication.yaml properties、yaml、yml三种配置文件,优先级最高的是properties 配置文件优先级…...

实验报告-实验四(时序系统实验)
软件模拟电路图 说明 SW:开关,共六个Q1~Q3:输出Y0~Y3:输出 74LS194 首先,要给S1和S0高电位,将A~D的数据存入寄存器中(如果开始没有存入数据,那么就是0000在里面移位,不…...

PHP+ajax+layui实现双重列表的动态绑定
需求:商户下面有若干个门店,每个门店都需要绑定上收款账户 方案一:每个门店下面添加页面,可以选择账户去绑定。(难度:简单) 方案二:从商户进入,可以自由选择门店&#…...
菜鸟学习日记(python)——条件控制
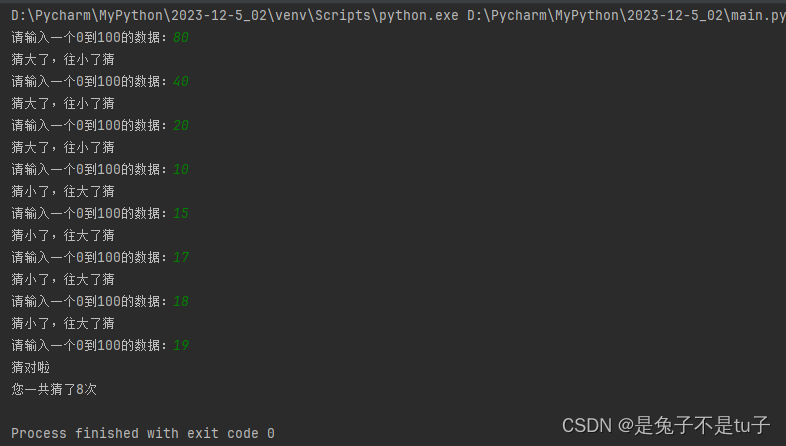
Python 中的条件语句是通过一条或多条语句的执行结果(True 或者 False)来决定执行的代码块。 它的一般格式为:if...elif...else if condition1: #条件1CodeBlock1 #代码块1 elif condition2:CodeBlock2 else:CodeBlock3 如果con…...

RabbitMQ 笔记
Message durability 确保消息在server 出现问题或者recovery能恢复: declare it as durable in the producer and consumer code. boolean durable true; channel.queueDeclare("hello", durable, false, false, null);Queue 指定 //使用指定的queue&…...
DNS协议(DNS规范、DNS报文、DNS智能选路)
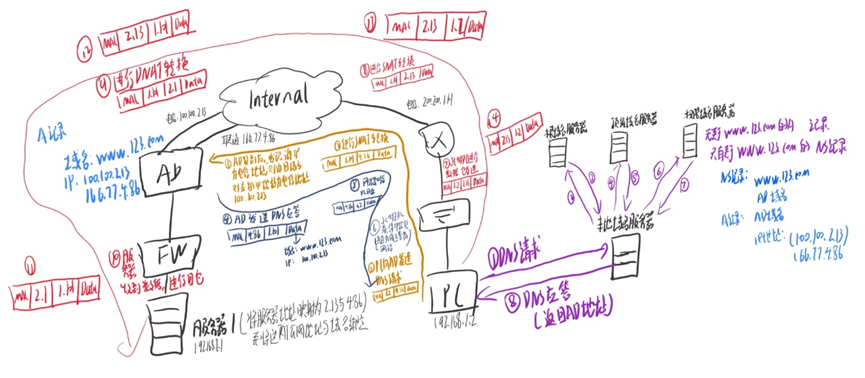
目录 DNS协议基本概念 DNS相关规范 DNS服务器的记录 DNS报文 DNS域名查询的两种方式 DNS工作过程 DNS智能选路 DNS协议基本概念 DNS的背景 我们知道主机通信需要依靠IP地址,但是每次通过输入对方的IP地址和对端通信不够方便,IP地址不好记忆 因此提…...

Python基础知识-变量、数据类型(整型、浮点型、字符类型、布尔类型)详解
1、基本的输出和计算表达式: prinit(12-3) printf(12*3) printf(12/3) prinit(12-3) printf(12*3) printf(12/3) 形如12-3称为表达式 这个表达式的运算结果称为 表达式的返回值 1 2 3 这样的数字,叫做 字面值常量 - * /称为 运算符或者操作符 在C和j…...
信息化,数字化,智能化是3种不同概念吗?与机械化,自动化矛盾吗?
先说结论: 1、信息化、数字化、智能化确实是3种不同的概念! 2、这3种概念与机械化、自动化并不矛盾,它们是制造业中不同发展阶段和不同层次的概念。 机械化:是指在生产过程中使用机械技术来辅助人工完成一些重复性、单一性、劳…...
C# WPF上位机开发(倒计时软件)
【 声明:版权所有,欢迎转载,请勿用于商业用途。 联系信箱:feixiaoxing 163.com】 生活当中,我们经常会遇到倒计时的场景,比如体育运动的时候、考试的时候等等。正好最近我们学习了c# wpf开发,完…...

Mysql timestamp和datetime区别
文章目录 一、存储范围和精度二、默认值和自动更新三、时区处理四、索引和性能五、存储空间和数据复制六、使用场景和注意事项七、时区转换 MySQL是一个常用的关系型数据库管理系统,其内置了多种数据类型用于存储和操作数据。其中,timestamp和datetime是…...

Arduino ESP32终极开发指南:从硬件抽象到物联网实战
Arduino ESP32终极开发指南:从硬件抽象到物联网实战 【免费下载链接】arduino-esp32 Arduino core for the ESP32 family of SoCs 项目地址: https://gitcode.com/GitHub_Trending/ar/arduino-esp32 ESP32作为物联网开发领域的明星芯片,以其强大的…...

八千多条提示词,装成你的「随身工具箱」
做图、想创意的时候,最烦的不是「不会写」,而是找不到、和不好管,写过的好句子不知道丢哪了。群里转发的、自己试出来的、收藏夹里吃灰的链接——真要用时,往往只记得个大概,翻半天也找不回来。 BoltPrompt 提示词库想…...

EB Garamond 12:免费获取专业复古字体与RCS学术引用系统的完整指南
EB Garamond 12:免费获取专业复古字体与RCS学术引用系统的完整指南 【免费下载链接】EBGaramond12 项目地址: https://gitcode.com/gh_mirrors/eb/EBGaramond12 想要为你的设计作品注入文艺复兴时期的优雅韵味,同时获得专业的学术引用功能吗&…...
)
别再手动绑骨了!用Mixamo+Unity 2022,5分钟搞定二次元角色动画(附材质修复全流程)
二次元角色动画高效制作指南:Mixamo与Unity 2022的完美配合 在独立游戏开发领域,角色动画制作往往是耗时最长的环节之一。传统手动绑骨流程不仅需要专业技能,还会消耗大量时间成本。对于二次元风格或Low Poly风格的独立游戏开发者来说&#x…...

国民技术N32G030K8L7芯片,用MDK从官方FTP下载到点亮LED的保姆级教程
国民技术N32G030K8L7芯片开发实战:从资料获取到LED点亮的全流程指南 拿到一块全新的开发板时,那种既兴奋又忐忑的心情想必每位工程师都经历过。N32G030K8L7作为国民技术推出的高性价比MCU,凭借其出色的性能和丰富的外设资源,正成为…...

别再手动改防火墙了!用这条组策略,一键修复AD域强制更新时的RPC报错
自动化运维实战:用组策略统一管理AD域防火墙规则 在混合Windows环境的IT运维中,手动配置每台终端设备的防火墙规则无异于一场噩梦。想象一下,当您面对数百台运行不同Windows版本的计算机时,每次组策略更新都因为防火墙拦截RPC通信…...

硬件工程师的‘第一板’:从最小系统设计到PCB Layout的STM32实战指南
STM32最小系统设计实战:从原理到PCB的工程化思维 作为一名硬件工程师,第一次独立完成PCB设计时的忐忑至今记忆犹新。那块承载着STM32最小系统的绿色电路板,不仅是我职业生涯的"第一板",更是一次从理论到实践的完整跨越。…...

如何用G-Helper轻松实现华硕笔记本CPU降压:实用调优指南
如何用G-Helper轻松实现华硕笔记本CPU降压:实用调优指南 【免费下载链接】g-helper Lightweight Armoury Crate alternative for Asus laptops with nearly the same functionality. Works with ROG Zephyrus, Flow, TUF, Strix, Scar, ProArt, Vivobook, Zenbook, …...

李辉《曾国藩日记》笔记:不要依附靠山,也不要做别人的靠山!
李辉《曾国藩日记》笔记:不要依附靠山,也不要做别人的靠山!原文:同治三年十二月廿三日早饭后清理文件。围棋一局。见客,坐见者四次,立见者一次。阅《说文》五叶。核科房批稿。中饭后再核批稿。写挂屏三幅、…...

Spring boot相关
1. ● 问题1:为什么扫描的是 com.example.demo 包?因为主入口类在这个包下。 com.example.demo …...