Spark常见算子汇总
创建RDD
在Spark中创建RDD的方式分为三种:
- 从外部存储创建RDD
- 从集合中创建RDD
- 从其他RDD创建
textfile
调用SparkContext.textFile()方法,从外部存储中读取数据来创建 RDD
parallelize
调用SparkContext 的 parallelize()方法,将一个存在的集合,变成一个RDD
makeRDD
方法一
/** Distribute a local Scala collection to form an RDD.** This method is identical to `parallelize`.*/def makeRDD[T: ClassTag](seq: Seq[T],numSlices: Int = defaultParallelism): RDD[T] = withScope {parallelize(seq, numSlices)}方法二:分配一个本地Scala集合形成一个RDD,为每个集合对象创建一个最佳分区。
/*** Distribute a local Scala collection to form an RDD, with one or more* location preferences (hostnames of Spark nodes) for each object.* Create a new partition for each collection item.*/def makeRDD[T: ClassTag](seq: Seq[(T, Seq[String])]): RDD[T] = withScope {assertNotStopped()val indexToPrefs = seq.zipWithIndex.map(t => (t._2, t._1._2)).toMapnew ParallelCollectionRDD[T](this, seq.map(_._1), math.max(seq.size, 1), indexToPrefs)}举例
scala> val rdd = sc.parallelize(1 to 6, 2)
val rdd: org.apache.spark.rdd.RDD[Int] = ParallelCollectionRDD[2] at parallelize at <console>:1scala> rdd.collect()
val res4: Array[Int] = Array(1, 2, 3, 4, 5, 6)scala> val seq = List(("American Person", List("Tom", "Jim")), ("China Person", List("LiLei", "HanMeiMei")), ("Color Type", List("Red", "Blue")))
val seq: List[(String, List[String])] = List((American Person,List(Tom, Jim)), (China Person,List(LiLei, HanMeiMei)), (Color Type,List(Red, Blue)))scala> val rdd2 = sc.makeRDD(seq)
val rdd2: org.apache.spark.rdd.RDD[String] = ParallelCollectionRDD[0] at makeRDD at <console>:1scala> rdd2.partitions.size
val res0: Int = 3scala> rdd2.foreach(println)
American Person
Color Type
China Personscala> val rdd1 = sc.parallelize(seq)
val rdd1: org.apache.spark.rdd.RDD[(String, List[String])] = ParallelCollectionRDD[1] at parallelize at <console>:1scala> rdd1.partitions.size
val res1: Int = 2scala> rdd2.collect()
val res2: Array[String] = Array(American Person, China Person, Color Type)scala> rdd1.collect()
val res3: Array[(String, List[String])] = Array((American Person,List(Tom, Jim)), (China Person,List(LiLei, HanMeiMei)), (Color Type,List(Red, Blue)))scala> var lines = sc.textFile("/root/tmp/a.txt",3)
var lines: org.apache.spark.rdd.RDD[String] = /root/tmp/a.txt MapPartitionsRDD[4] at textFile at <console>:1scala> lines.collect()
val res6: Array[String] = Array(a,b,c)scala> lines.partitions.size
val res7: Int = 3
转换算子
flatMap
map
reduceByKey
groupByKey
举例
scala> var lines = sc.textFile("/root/tmp/a.txt",3)
var lines: org.apache.spark.rdd.RDD[String] = /root/tmp/a.txt MapPartitionsRDD[13] at textFile at <console>:1scala> lines.flatMap(x=>x.split(",")).map(x=>(x,1)).reduceByKey((a,b)=>a+b).foreach(println)
(c,2)
(b,1)
(d,1)
(a,2)scala> lines.collect()
val res27: Array[String] = Array(a,b,c, c, a,d)scala> lines.map(_.split(",")).collect()
val res25: Array[Array[String]] = Array(Array(a, b, c), Array(c), Array(a, d))scala> lines.flatMap(_.split(",")).collect()
val res26: Array[String] = Array(a, b, c, c, a, d)行动算子
相关文章:

Spark常见算子汇总
创建RDD 在Spark中创建RDD的方式分为三种: 从外部存储创建RDD从集合中创建RDD从其他RDD创建 textfile 调用SparkContext.textFile()方法,从外部存储中读取数据来创建 RDD parallelize 调用SparkContext 的 parallelize()方法,将一个存在的集合&…...
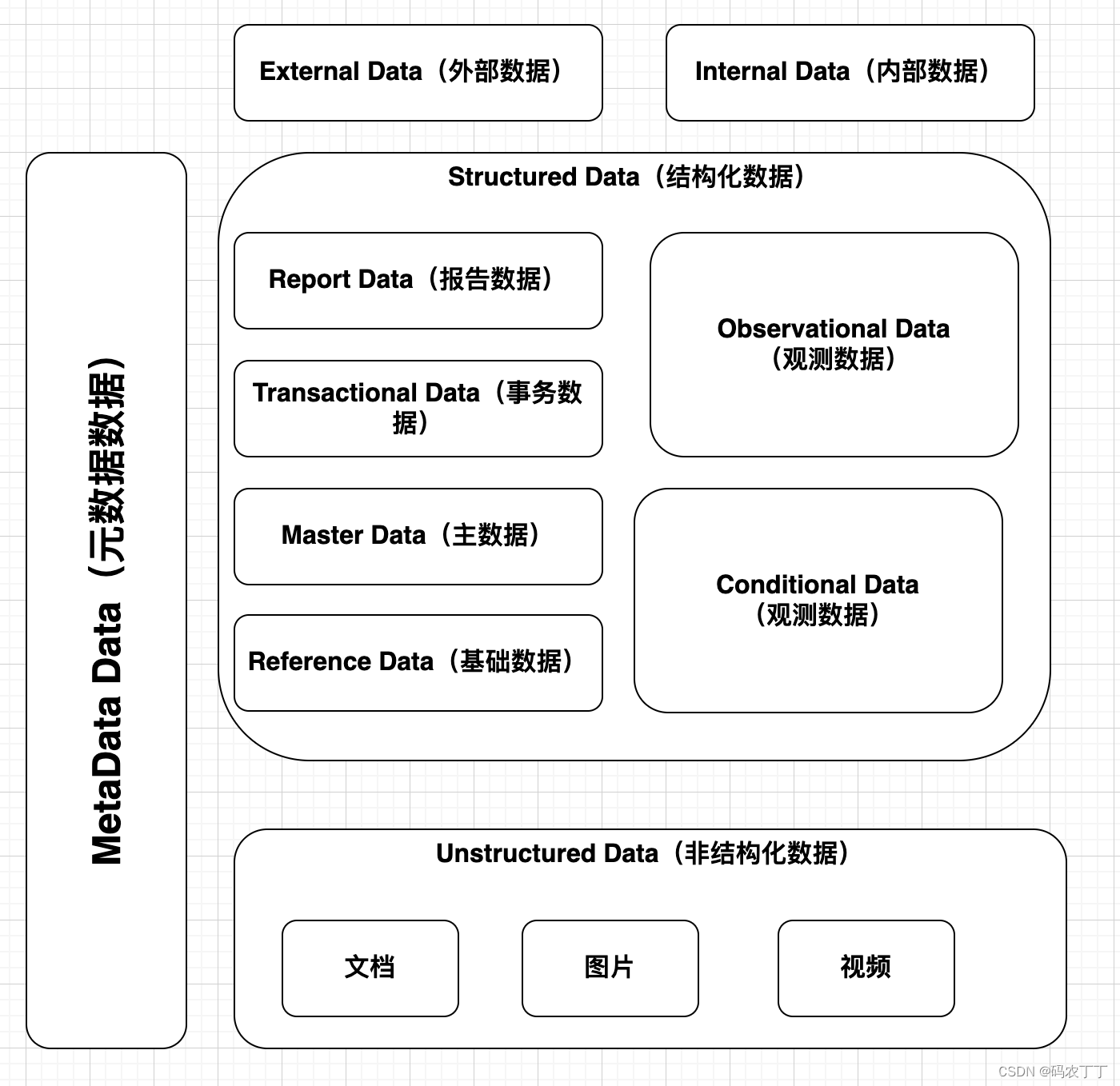
【华为数据之道学习笔记】3-1 基于数据特性的分类管理框架
华为根据数据特性及治理方法的不同对数据进行了分类定义:内部数据和外部数据、结构化数据和非结构化数据、元数据。其中,结构化数据又进一步划分为基础数据、主数据、事务数据、报告数据、观测数据和规则数据。 对上述数据分类的定义及特征描述。 分类维…...
电脑版便签软件怎么设置在桌面上显示?
对于不少上班族来说,如果想要在使用电脑办公的时候,随手记录一些常用的工作资料、工作注意事项等内容,直接在电脑上使用便签软件记录是比较方便的。电脑桌面便签工具不仅方便我们随时记录各类工作事项,而且支持我们快速便捷使用这…...
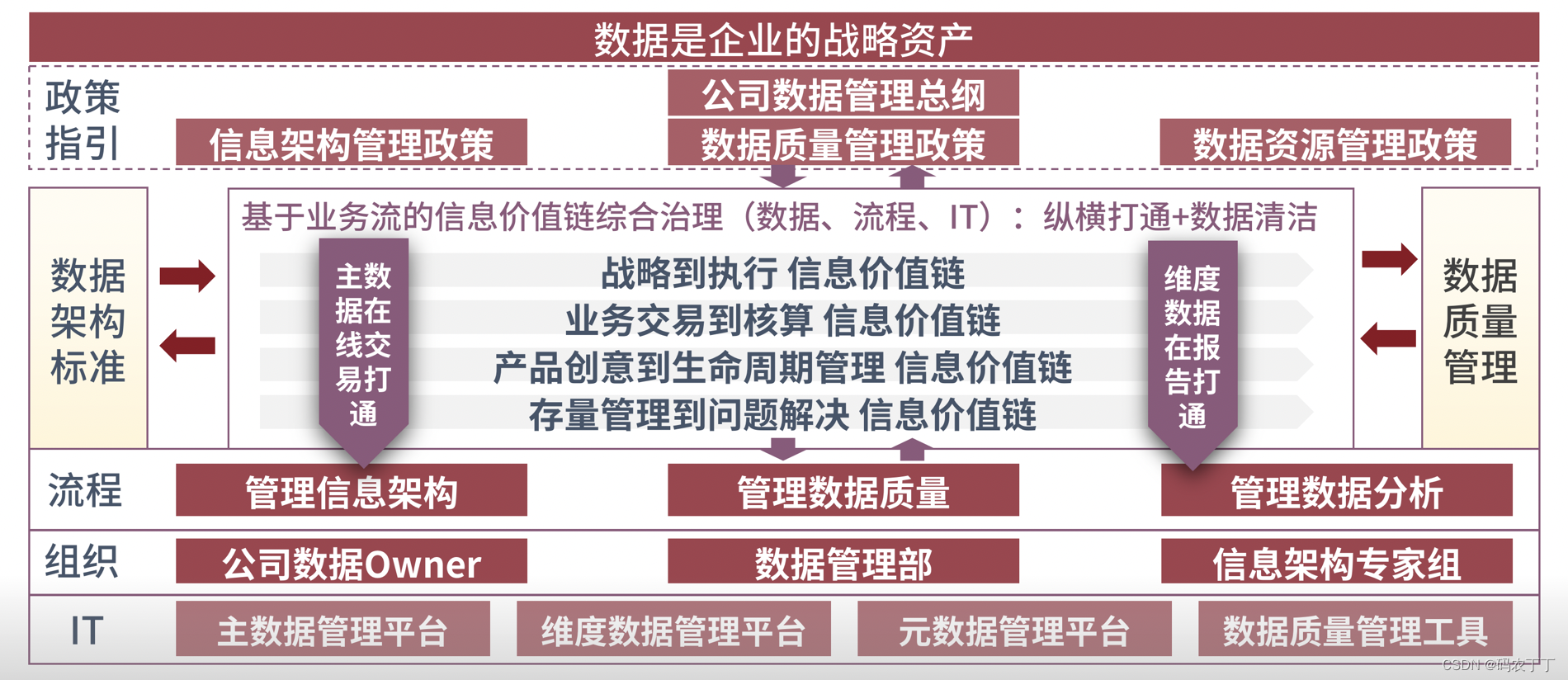
【华为数据之道学习笔记】2-建立企业级数据综合治理体系
数据作为一种新的生产要素,在企业构筑竞争优势的过程中起着重要作用,企业应将数据作为一种战略资产进行管理。数据从业务中产生,在IT系统中承载,要对数据进行有效治理,需要业务充分参与,IT系统确保遵从&…...

【IC前端虚拟项目】git和svn项目托管平台的简单使用说明
【IC前端虚拟项目】数据搬运指令处理模块前端实现虚拟项目说明-CSDN博客 代码托管在gitee平台上,进去后会看到文档目录“MVU芯片前端设计验证虚拟项目”和工程目录“mvu_prj”,可以通过git来下载工程: git clone gitgitee.com:gjm9999/ic_vi…...
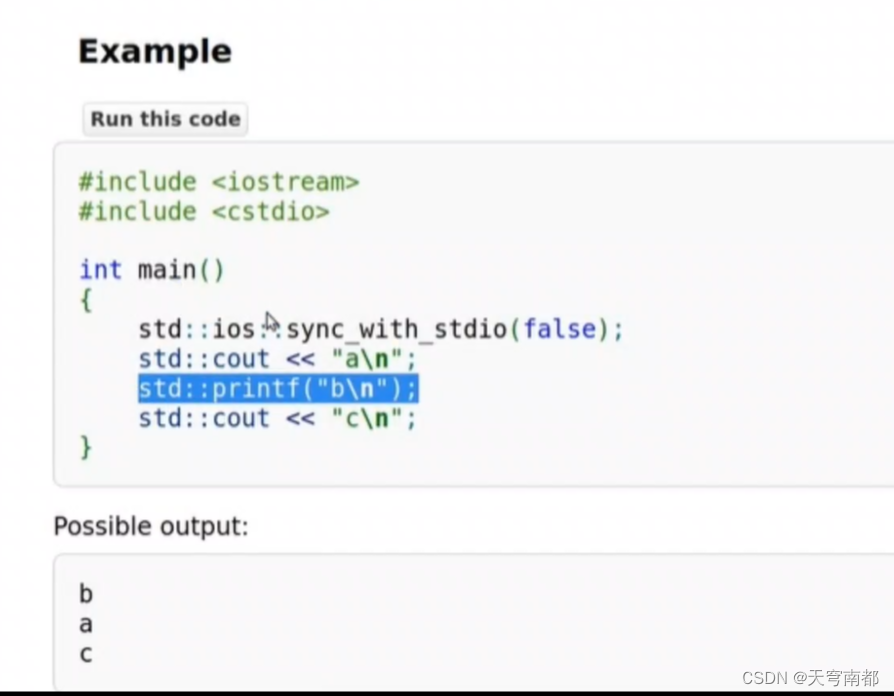
C++ IO库
IO类 IO对象不能拷贝和赋值 iostream 表示形式的变化: 将100转换成二进制序列 然后格式化输出 x,y共用一块内存 输出的时候用不同的方式解析同一块内存 操作 格式化:内部表示转换为相应字节序列 缓存:要输出的内容放到缓存 编码转换&…...

Springboot 项目关于版本升级到 3.x ,JDK升级到17的相关问题
由于spring 停止对2.x 版本的维护,以及 jdk 频繁发布等客观因素,现需要对已有springboot 工程做一次全面升级;已因对市面上第三方等依赖库的兼容问题; 现有工程使用哥技术栈是版本: freemarker :2.3.32 spr…...

QGraphicsView实现简易地图7『异步加载-多瓦片-无底图』
前文链接:QGraphicsView实现简易地图6『异步加载-单瓦片-无底图』 前一篇文章提到的异步单瓦片加载,是指线程每准备好一个瓦片数据后,立刻抛出信号让主线程加载。而本篇异步多瓦片加载是指线程准备好所有瓦片数据后,一起抛出信号让…...
:集成kafka)
Spring Boot学习(三十三):集成kafka
前言 下面是zookeeper和kafka的官网下载地址,大家可以学习下载 zookeeper下载地址:http://zookeeper.apache.org/releases.html kafka下载地址:http://kafka.apache.org/downloads.html 1、添加依赖 在 pom.xml 文件中添加kafka依赖&am…...

MOSFET
MOSFET 电子元器件百科 文章目录 MOSFET前言一、MOSFET是什么二、MOSFET类别三、MOSFET应用实例四、MOSFET作用原理总结前言 MOSFET是一种常见的半导体器件,通过栅极电场控制通道区的导通特性,以控制电流流动。它在现代电子电路中发挥着重要的作用,并广泛应用于各种应用领域…...
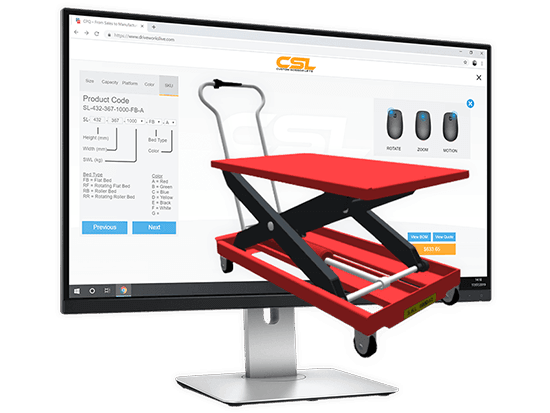
DriveWorks——参数化设计非标定制利器
DriveWorks基本介绍 DriveWorks是一套被 SOLIDWORKS 认可为金牌合作伙伴产品的设计自动化软件。DriveWorks 可自动创建特定于订单的销售文档和 SOLIDWORKS 制造数据。减少重复性任务,消除错误,增加销售额,并在创纪录的时间内交付定制产品。 为…...
DevEco Studio集成ArkUI-X
语雀知识库地址:语雀HarmonyOS知识库 飞书知识库地址:飞书HarmonyOS知识库 在上篇文章(HarmonyOS应用开发工具DevEco Studio安装与使用)中我说到官方推出了4.0 Beta版本的IDE,这篇文章就来介绍这个版本的安装与使用 该版本集成了HarmonyOS多…...

网络视频服务器的作用是什么?
随着互联网的快速发展和网络带宽的提升,网络视频已经成为人们日常生活中不可或缺的一部分。网络视频服务器作为支持和传输网络视频的关键基础设施,发挥着重要的作用。本文将以网络视频服务器的作用为方向,探讨其在现代社会中的重要性。 首先…...
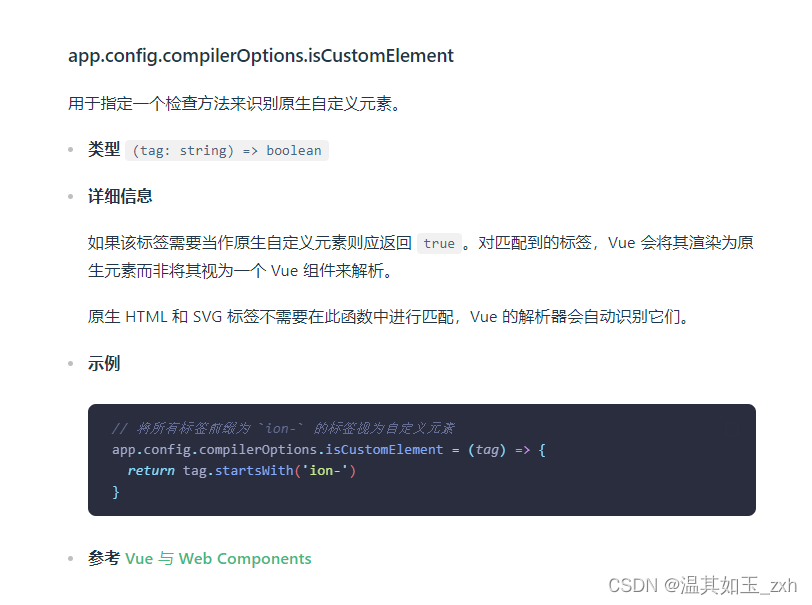
解决vue3使用iconpark控制台预警提示问题
前言 最近在项目中使用 iconpark-icon 来管理图标,一切都很顺利,引入链接后,图标正常显示,没有报错。但是控制台却发出了预警信息。 [Vue warn]: Failed to resolve component: iconpark-icon If this is a native custom eleme…...

VMware 虚拟机 NAT 模式网络配置
配置的核心点在于 网关要一致,才能访问外网 比如下面的网关都是:192.168.145.2 问题总结: 当时重启电脑后如果连不上外网了,检查下 windows 服务中 NAT服务是否已经启动...

5-redis高级-哨兵
1 哨兵 1.1 python 操作哨兵 1 哨兵 # 主从---》一主多从-主库用来写-从库用来读-主库挂了--》整个系统就不能写数据了#主从复制存在的问题:1 主从复制,主节点发生故障,需要做故障转移,可以手动转移:让其中一个slave变…...
鸿蒙HarmonyOS4.0开发应用学习笔记
黑马程序员鸿蒙4.0视频学习笔记,供自己回顾使用。1.安装开发工具DevEco Studio 鸿蒙harmony开发文档指南 DevEco Studio下载地址 选择或者安装环境 选择和下载SDK 安装总览 编辑器界面 2.TypeScript语法 2.1变量声明 //string 、number、boolean、any、u…...

联通宽带+老毛子Padavan固件 开启IP v6
联通宽带开启IP v6 参考: 联通宽带开启 IPV6 的方法_联通ipv6怎么开通-CSDN博客 个人宽带如何开启IPv6网络访问 - 知乎 (zhihu.com) 首先,你要确定当前你所在的地区运营商已经开通了IPV6,可以使用手机流量 IP查询(ipw.cn) | IPv6测试 | IPv…...

唯创知音WT2003Hx系列单片机语音芯片:家庭理疗产品的智能声音伴侣
随着科技的不断创新,家庭理疗产品正迎来一场智能化的变革。唯创知音的WT2003Hx系列单片机语音芯片以其强大的功能和高品质音频播放能力,为家庭理疗产品带来了更为智能、沉浸式的用户体验。 1. MP3高品质音频播放 WT2003Hx系列语音芯片支持高品质的MP3音…...

2023_Spark_实验二十七:Linux中Crontab(定时任务)命令详解及使用教程
Crontab介绍: Linux crontab是用来crontab命令常见于Unix和类Unix的操作系统之中,用于设置周期性被执行的指令。该命令从标准输入设备读取指令,并将其存放于“crontab”文件中,以供之后读取和执行。该词来源于希腊语 chronos(χρ…...

基于SpringBoot的公司固定资产盘点系统毕设源码
博主介绍:✌ 专注于Java,python,✌关注✌私信我✌具体的问题,我会尽力帮助你。一、研究目的本研究旨在构建一个基于Spring Boot框架的公司固定资产盘点系统以解决传统资产管理方式中存在的效率低下问题。当前企业固定资产管理工作普遍面临数据采集繁琐、…...

低成本接入GPT-4级能力:从开源模型自建到安全API实践
1. 项目概述与核心价值最近在GitHub上看到一个挺有意思的项目,叫a37836323/-chatgpt4.0-api-key。光看这个标题,很多朋友可能会立刻联想到“免费API密钥”、“共享资源”之类的。确实,在AI工具日益普及的今天,如何高效、低成本地使…...

扩展卡尔曼滤波锂电池SOC估算【附代码】
✨ 长期致力于锂离子电池、SOC估算、锂离子电池建模、EKF算法研究工作,擅长数据搜集与处理、建模仿真、程序编写、仿真设计。 ✅ 专业定制毕设、代码 ✅ 如需沟通交流,点击《获取方式》 (1)二阶RC等效电路建模与温度自适应参数修正…...
)
别再满世界找Kettle了!手把手教你定位最新官方下载源(附版本选择建议)
开源工具下载困境突围指南:以Kettle为例构建高效溯源方法论 在开源工具的使用过程中,最令人头疼的莫过于某天突然发现熟悉的下载链接失效,官网改版后找不到下载入口,或是搜索引擎返回的结果全是过时的教程。这种情况不仅发生在Ke…...

【BK3633】从规格书到实战:解锁蓝牙5.2双模芯片的十大核心应用场景
1. BK3633芯片核心特性解析 第一次拿到BK3633规格书时,我被它的参数惊艳到了——这简直是为物联网设备量身定制的瑞士军刀。作为博通集成推出的蓝牙5.2双模芯片,它完美兼顾了高性能与低功耗这对"冤家"。实测下来,全速运行电流仅5mA…...

终极指南:5步彻底解决Gopeed下载管理器403 Forbidden错误
终极指南:5步彻底解决Gopeed下载管理器403 Forbidden错误 【免费下载链接】gopeed A fast, modern download manager for HTTP, BitTorrent, Magnet, and ed2k. Cross-platform, built with Golang and Flutter. 项目地址: https://gitcode.com/GitHub_Trending/…...

企业无线准入实战:AC联动RADIUS与内置Portal构建安全访客网络
1. 为什么企业需要安全访客网络? 想象一下这样的场景:你的公司经常有合作伙伴、客户来访,他们需要临时使用Wi-Fi。如果直接开放内部网络,就像把家门钥匙随便发给陌生人;如果用简单密码共享,又像在公共场合大…...

彻底解决GeoServer跨域:手把手教你配置web.xml与添加Jetty依赖包
彻底解决GeoServer跨域问题:原理剖析与实战配置指南 当你在OpenLayers或Cesium中调用GeoServer的WMS/WFS服务时,是否遇到过令人头疼的跨域错误?这个问题看似简单,却隐藏着Web安全策略与地理信息服务集成的深层逻辑。本文将带你从H…...

Workerman-todpole 部署实战:Linux/Windows 环境配置与优化技巧 [特殊字符]
Workerman-todpole 部署实战:Linux/Windows 环境配置与优化技巧 🚀 【免费下载链接】workerman-todpole HTML5WebSocketPHP(Workerman) , rumpetroll server writen using php 项目地址: https://gitcode.com/gh_mirrors/wo/workerman-todpole Wo…...

从「PPT丑到被挂」到「评委全场抬头」!只花25元的答辩PPT救命教程
论文写到头秃,结果答辩PPT还要从零学起!😭 网上模板要么花哨得像婚礼请柬,要么把论文段落直接往上堆,交去预审,导师批注四个字:“毫无逻辑。”别慌!这篇亲妈级教程,把我答…...