Contrast and Generation Make BART a Good Dialogue Emotion Recognizer

摘要
在对话系统中,具有相似语义的话语在不同的语境下可能具有不同的情感。因此,用说话者依赖来建模长期情境情绪关系在对话情绪识别中起着至关重要的作用。同时,区分不同的情绪类别也不是很简单的,因为它们通常具有语义上相似的情绪。为此,我们采用监督对比学习,使不同的情绪相互排斥,从而更好地识别相似的情绪。同时,我们利用一个辅助反应生成任务来增强模型处理上下文信息的能力,从而迫使模型在不同的上下文中识别具有相似语义的情绪。为了实现这些目标,我们使用预先训练好的编码器-解码器模型BART作为我们的主干模型,因为它非常适合于理解和生成任务。在四个数据集上的实验表明,我们提出的模型在对话情绪识别方面比现有的模型获得了更有利的结果。消融研究进一步证明了监督对比损失和生成损失的有效性。
介绍
随着个人智能终端技术和社交网络的发展和普及,构建一个能够理解用户情绪和意图并进行有效对话互动的对话系统的重要性显著增加。对话系统中的一个关键模块是自然语言理解模块,它可以分析用户的行为,如意图或情绪。利用上下文关系分析用户情绪是简单情绪分类任务的一个高级步骤,更适合于现实世界中的使用场景,具有更多的研究价值。对话中的情感识别(ERC)的任务是为具有语境关系的历史对话中的所有话语分配情感标签。同时,每个历史对话都包含了多个不同说话者之间的交互,如图1所示。
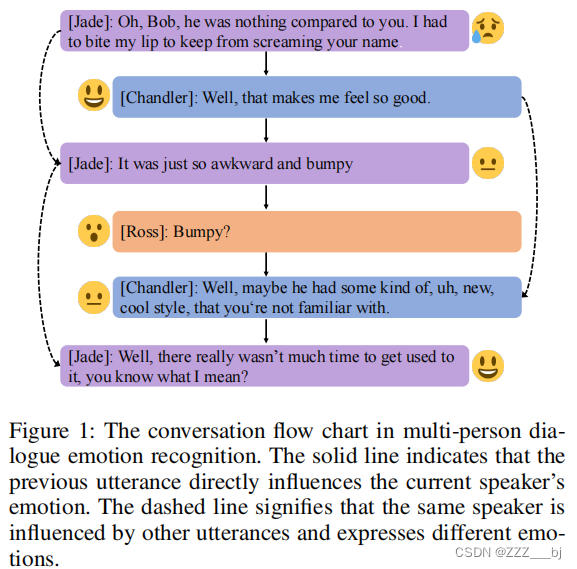
ERC面临着三个挑战。
- (1)第一个挑战是,每一个话语的情绪都可能会受到上下文信息的影响。例如,特定的情绪将取决于上下文的某些话语。同时,具有相同表达方式的话语在不同的语境中可能有完全不同的情绪。因此,有效地建模上下文依赖和说话人依赖是区分该任务与传统情绪分类的主要因素。
- (2)第二个挑战是,每个说话者的情绪都会受到谈话中其他说话者的话语的影响,所以说话者的情绪可能会发生突然的变化。
- (3)第三个挑战在于语义上相似但不同的情绪类别,比如“沮丧”到“悲伤”,“快乐”到“兴奋”,等等。很难区分这些语义上相似的情绪类别。
最近的相关工作使用各种图网络解决上下文依赖和说话者关系(Shen等2021b;Ghosal等2019年;石谷等2020年;Sheng等2020年)。然而,随着层数的加深,过度平滑的现象开始出现(Chen et al. 2020a)开始出现,导致类似情绪的表现难以区分。
这项工作通过更好地建模上下文和说话者信息和辅助生成任务来处理上述挑战。
首先,我们引入了一个对话级Transformer(Vaswani et al. 2017)层来建模话语之间的长期上下文依赖关系。一个预先训练过的语言模型捕捉了每个话语的表示。与以往仅采用预先训练好的模型作为特征提取器(Liu et al. 2019)并将提取出的特征作为下游图网络的节点表示的方法相比,纯Transformer结构做出的先前结构假设更少(Lin et al. 2021)。
其次,我们采用监督对比学习(SCL)(Khosla et al. 2020)来缓解相似情绪分类的困难,在充分利用标签信息的情况下,使具有相同情绪的凝聚和不同情绪的样本互斥。与有噪声标签的交叉熵损失相比,有监督的对比损失可以提高训练的稳定性,提高模型的泛化性(Gunel et al. 2021)。与常规的SCL不同,我们复制一批中所有样本的隐藏状态,并分离其梯度作为它的多视图表示。原因是现有ERC数据集中的类别高度不平衡,有些类别可能存在于一个只有一个样本的批次中。如果只使用原始的SCL,它将导致不正确的损失计算。
第三,我们引入了一个辅助响应生成任务,以增强ERC捕获上下文信息的能力。对下一句话语的预测使模型充分考虑了上下文的依赖性,从而迫使模型在识别对话中的情绪时,考虑上下文中的信息,并依赖于当前的话语本身。此外,通过在说话前直接将说话者拼接起来,作为说话者信息的提示,说话者和话语之间的依赖关系得到了充分的建模,并且没有额外的参数。
最后,我们利用BART(Lewis et al. 2020),一个预先训练过的具有编译码器结构的Transformer,作为我们的骨干模型,并通过对比和生成损失来增强它。我们提出的协同约束和生成增强的BART(CoG-BART)在四个ERC数据集上,与基线模型相比,获得了最先进的结果。此外,消融实验和案例研究证明了对比损失和生成损失在ERC任务中的有效性。
综上所述,我们的主要贡献可以总结如下:
- 据我们所知,我们首次在ERC中使用监督对比学习,显著提高了模型区分不同情绪的能力。
- 通过将响应生成作为辅助任务,当涉及到某些上下文信息时,ERC的性能得到了提高。
- 我们的模型很容易实现,因为它不依赖于外部资源,比如基于图的方法。
方法
问题定义
在对话情绪识别中,数据由多个对话{c1、c2、···、cN }组成,每个对话由多个话语[u1、u2、··、=]和情绪标签Yci = {y1、y2、···、ym}∈S组成,其中y表示情绪类别。对于一个话语,它由几个token=ut[wt、1、wt、2、····、wt、n]组成。对话中的每一句话都由一个说话者说,可以用p(ci)=(p(u1)、·、p(ui)、·、p(um)和p(ui)∈P表示,其中P表示说话者的类别或名称。因此,整个问题可以表示为在一段对话中根据上下文和说话者信息获取每个话语的情感标签: Yci = f(ci,p(ci))。
针对ERC的监督对比学习
话语编码
为了模拟说话者和话语之间的依赖关系,对于对话中的某个话语,我们在话语之前拼接说话者的名字或类别。在使用说话人信息的标记话语后,我们得到:
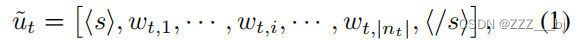
其中,,和被视为特殊的标记来表示话语的开始和结束。然后是将标记化后的token序列输入到BART的共享嵌入层,获取话语中每个标记的隐藏状态,然后将其发送给BART的编码器和解码器。将Ht发送到BART后,获得当前话语的表示:

对话建模
由BART-Model获得的表示Ht进行最大池化,以获得话语的聚合表示如下:
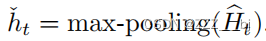
为了建模对话的历史上下文信息,我们利用对话级Transformer(Vaswani et al. 2017)层作为上下文编码器。多头注意力机制可以在多轮对话中捕捉不同对话之间的交互作用,并聚合不同的特征,得到最终的隐式表征,从而充分建模不同话语和语境关系之间的复杂依赖关系。对于一个语境中的所有话语,对话ˇhj、ˇhk中两个不同话语之间隐藏状态的多头注意得分可以通过以下公式计算:

因此,通过上述对话级Transformer,可以获得建模上下文依赖性的话语表示:
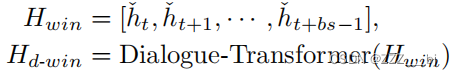
监督对比学习
监督对比学习假设一些关键方面得到注意,当在预训练模型上进行微调时,允许小样本学习更稳定(Gunel et al. 2021)。典型的对比学习只使用一对正样本,而所有其他的样本都被视为负样本。监督对比学习通过充分利用标签信息,将该批中所有具有相同标签的例子视为正样本。
对于ERC,某些数据集中每个类别的样本数量(Li et al. 2017)是高度不平衡的,而监督对比学习在计算损失时会掩盖自己。如果批中某个类别只存在一个样本,则不能直接用于计算损失。因此,通过复制话语Hd-win的隐藏状态,得到-Hd-win,并分离其梯度。并且,参数优化保持稳定。
对于有N个训练样本的批次,每个样本采用上述机制进行操作,获得多视图2N个样本,那么一个批次中所有样本的监督对比损失可以用下式表示:

辅助响应生成
为了便于模型在确定话语情绪时考虑更丰富的上下文信息,模型需要在给出当前话语ut的情况下生成其后续话语ut+1。ut+1中每个token的输出隐藏状态由BART解码器按顺序生成。
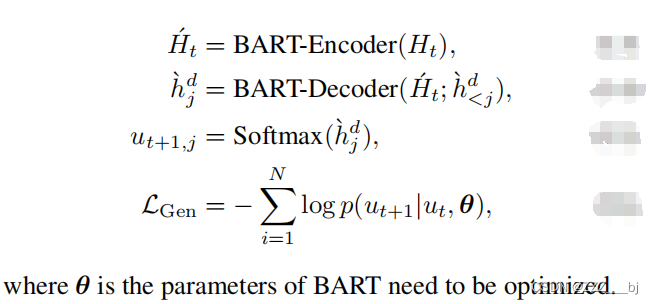
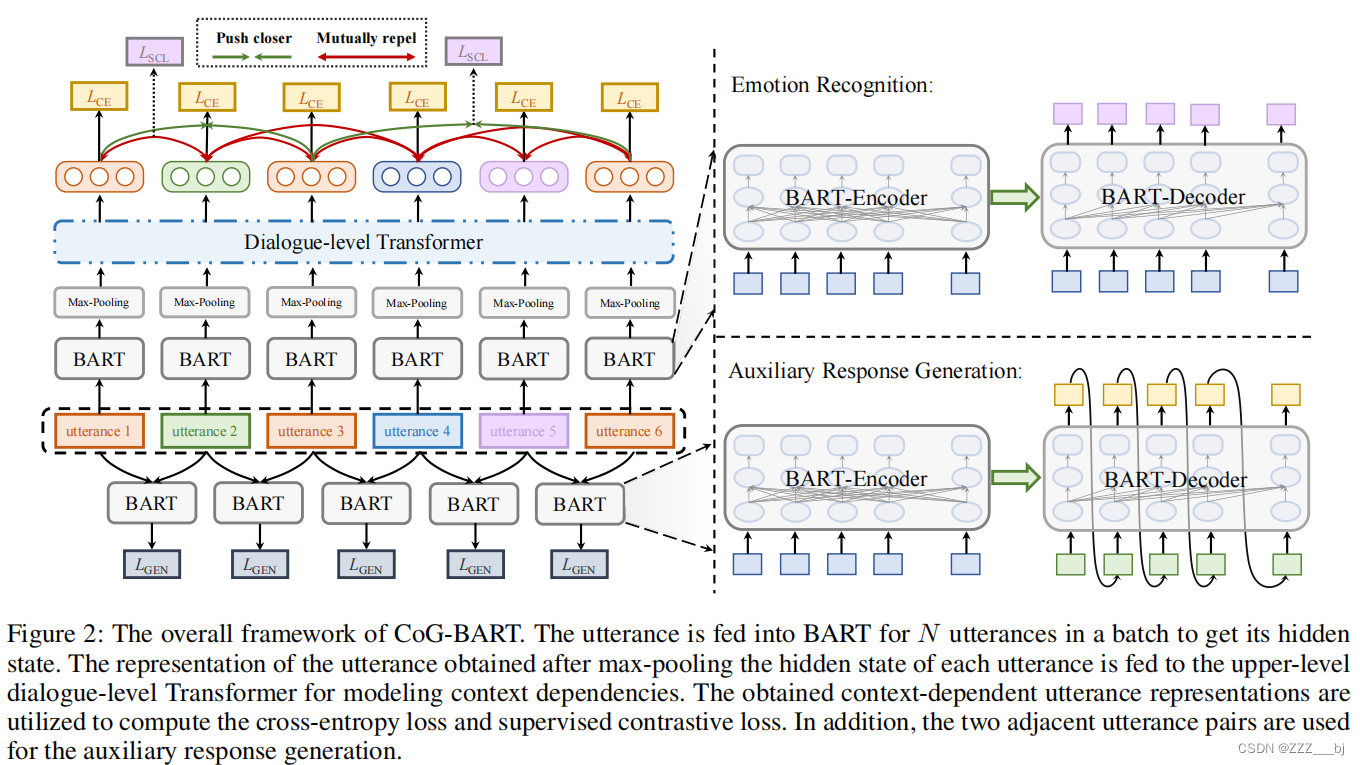
模型训练
模型训练的损失包括三个部分:上下文建模中通过多层感知器得到的隐藏状态Hd-win,以获得计算交叉熵损失。另一部分是有监督的对比损失和响应生成的损失。损失是三个分量的加权和,它们的权重的和等于1。CoG-BART的总体框架如图2所示。

实验设置
本节将详细介绍实验中采用的数据集、基线模型、实验条件和参数设置。
实验设置
BART的代码框架和初始重量来自于拥抱脸的变形金刚(Wolf et al. 2020)。应用于模型训练的优化器是一个线性计划的热身策略。本实验调整的参数包括批大小、学习率、预热率、α和β。我们通过保留的验证集对模型训练进行了超参数搜索。测试集上的结果来自于验证集中的最佳检查点,我们对来自5个不同的随机种子的得分取平均值。所有实验均在GeForce RTX 3090 GPU上进行。
数据集
四个基准数据集:MELD(Pouria等人2019年)、EmoryNLP(Zahiri和Choi2018年)、每日对话框(Li等人2017年)和IEMOCAP(Busso等人2008年),用于与基线模型进行比较。
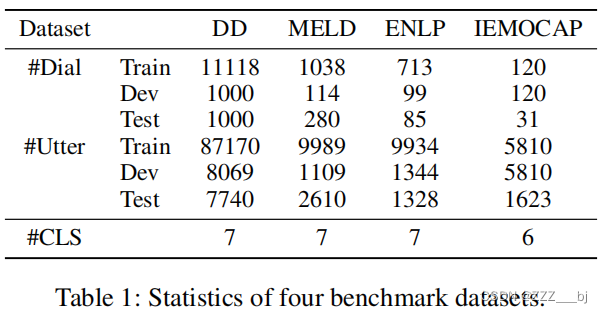
四个数据集的详细统计数据如表1所示,其中“#Dial”表示train/dev/tese/中对话的数量,“#Utter”表示对话中所有话语的数量,“#CLS”表示每个数据集的情绪类别数量。
指标
对于MELD、EmoryNLP和IEMOCAP,我们采用加权平均f1作为评价指标。由于“中性”在DailyDialog中占多数,我们采用micro-F1作为该数据集的评价指标,我们在计算结果时忽略了“中性”的标签(Zhu等,2021;Shen等,2021b)。
结果与分析
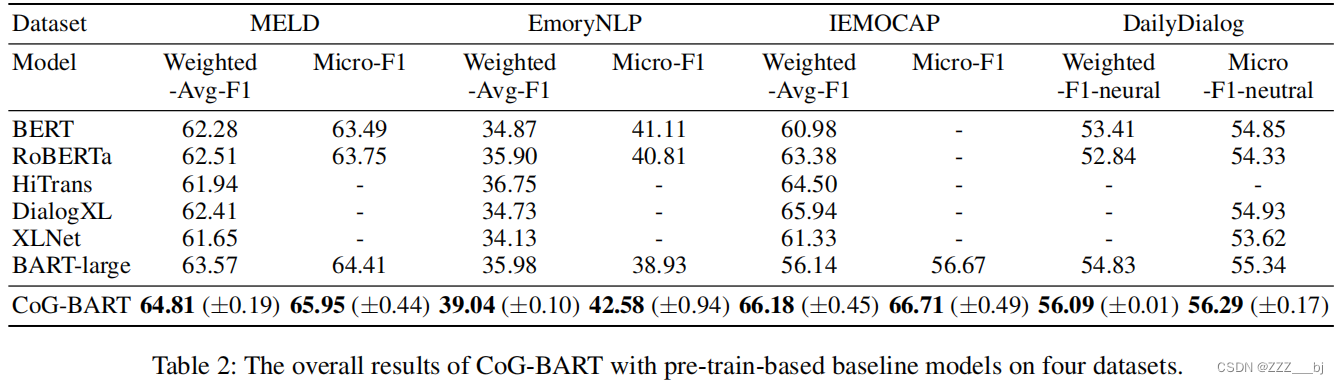
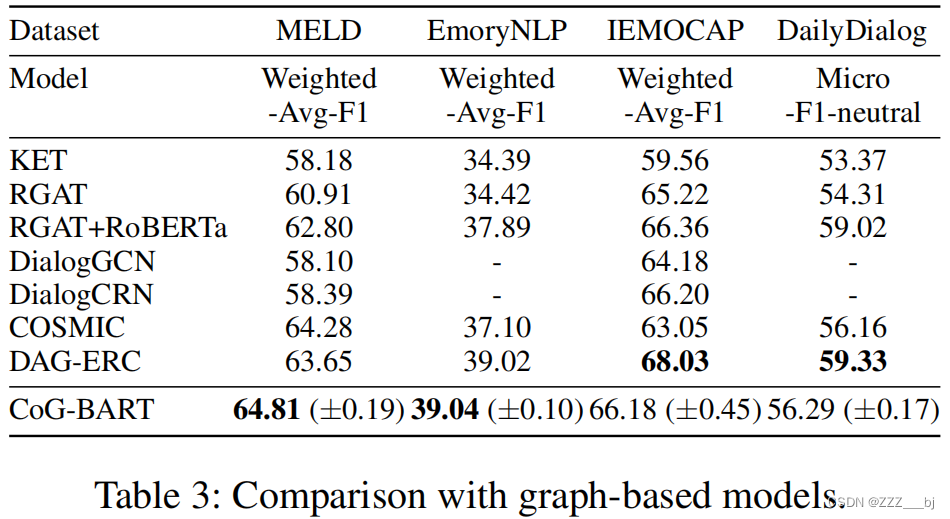
表2和表3记录了四个数据集上CoG-BART与基线模型的比较结果。
-
在基于序列的模型及其变体中,所选的基线模型包括BERT(Devlin等2019年)、RoBERTa(Liu等2019年)、HiTrans(Li等2020年)、DialogXL(Shen等2021年a)和XLNet (Yang等2019年)。在MELD(Poria等人2019年)中,CoG-BART比之前最先进的bart大有大约1.24%的改进(Lewis等人2020年)。
-
对于基于图的模型,列出了KET(钟、王、苗2019)、RGAT(石谷等2020)、 DialogGCN(Ghosal等2019)、 DialogCRN(胡、魏、淮2021)、COSMIC(对话等2020)和DAG-ERC(Shen等2021b)。 与基于图的模型相比,CoG-BART比COSMIC提高了0.53个点(Ghosal et al. 2020)。值得注意的是,COSMIC使用RoBERTa-large作为特征提取器,而CoG-BART只采用BART-large骨干结构获得竞争结果,这表明在 MELD 中,对有效模拟上下文之间依赖关系的预训练模型进行充分的知识转移也能获得可喜的结果。
-
我们可以从EmoryNLP(Zahiri和Choi 2018)的结果中观察到,使用预先训练的模型作为特征提取器的基于图的模型总体上比仅使用预先训练的模型作为主干网络的模型效果更好。同时,CoG-BART仍取得了显著的改进效果。此外,与基于预训练的模型相比,基于图的模型可以在 IEMOCAP上获得更高的F1值(Busso et al. 2008)。
相关文章:
Contrast and Generation Make BART a Good Dialogue Emotion Recognizer
摘要 在对话系统中,具有相似语义的话语在不同的语境下可能具有不同的情感。因此,用说话者依赖来建模长期情境情绪关系在对话情绪识别中起着至关重要的作用。同时,区分不同的情绪类别也不是很简单的,因为它们通常具有语义上相似的…...
图的深度优先搜索(数据结构实训)
题目: 图的深度优先搜索 描述: 图的深度优先搜索类似于树的先根遍历,是树的先根遍历的推广。即从某个结点开始,先访问该结点,然后深度访问该结点的第一棵子树,依次为第二顶子树。如此进行下去,直…...

VUEX使用总结
1、Store 使用 文件内容大概就是这三个。通俗来讲actions负责向后端获取数据的,内部执行异步操作分发 Action,调用commit提交一个 mutation。 mutations通过Action提交commit的数据进行提交荷载,使state有数据。 vuex的数据是共享的…...

指定分隔符对字符串进行分割 numpy.char.split()
【小白从小学Python、C、Java】 【计算机等考500强证书考研】 【Python-数据分析】 指定分隔符对字符串进行分割 numpy.char.split() 选择题 请问下列程序运行的的结果是: import numpy as np print("【执行】np.char.split(I.Love.China, sep .)") p…...
Android12蓝牙框架
参考: https://evilpan.com/2021/07/11/android-bt/ https://source.android.com/docs/core/connect/bluetooth?hlzh-cn https://developer.android.com/guide/topics/connectivity/bluetooth?hlzh-cn https://developer.android.com/guide/components/intents-fi…...

python文件docx转pdf
centos部署的django项目,使用libreoffice做文件转换,官网给环境安装好libreoffice后,可使用命令行来进行转化 还可转换其他的各种格式,本文只做了pdf转换 import subprocess import os def convert_to_pdf(input_file, o…...

9.基于SpringBoot3+I18N实现国际化
1. 新建资源文件 在resources目录下新建目录i18n, 然后 新建messages_en.properties文件 user.login.erroraccount or password error!新建messages_zh_CN.properties文件 user.login.error帐户或密码错误!2. 新建LocaleConfig.java文件 Configurati…...
27. 深度学习进阶 - 为什么RNN
文章目录 一个柯基的例子为什么RNN or CNN Hi,你好。我是茶桁。 这节课开始,我们将会讲一个比较重要的一种神经网络,它对应了咱们整个生活中很多类型的一种问题结构,它就是咱们的RNN网络。 咱们首先回忆一下,上节课咱…...

谈一谈柔性数组
文章目录 什么是柔性数组柔性数组有什么用 什么是柔性数组 柔性数组是一种动态可变的数组,也许你从来没有听说过这个概念,但是它确实是存在的,是在C99标准底下支持的一种语法。想要使用柔性数组需要满足3个条件: 柔性数组只能存在…...
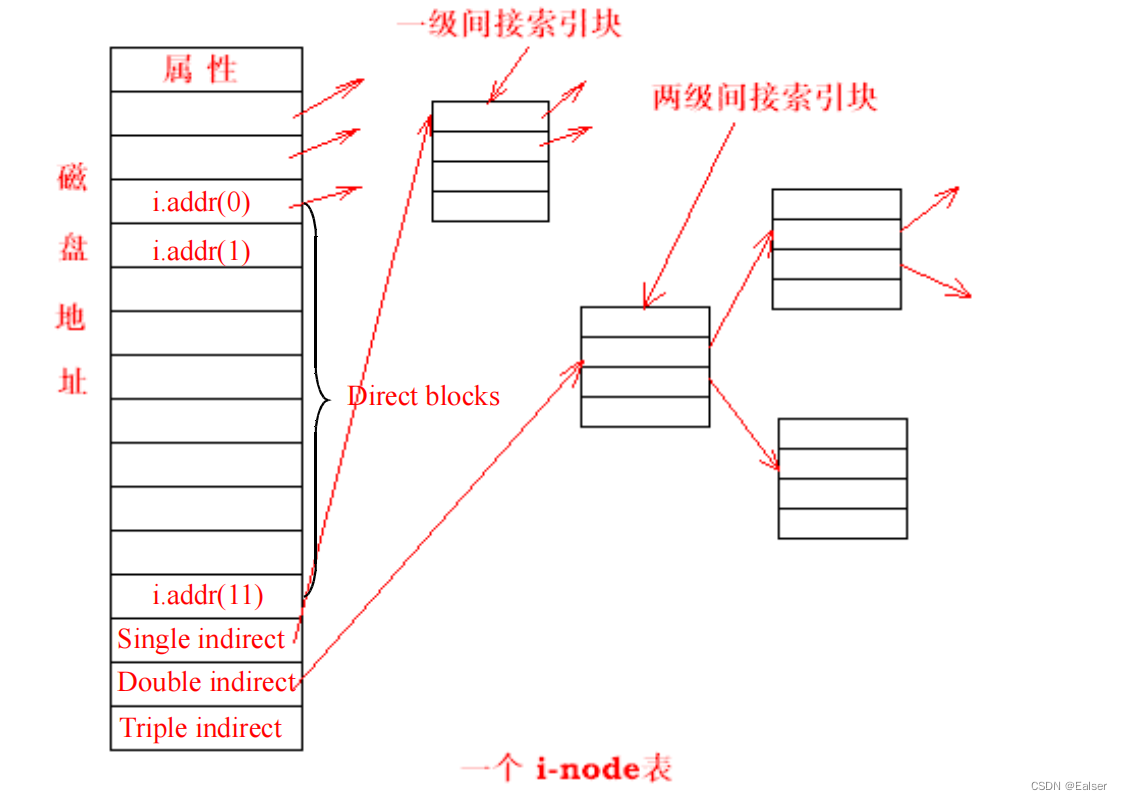
<Linux>(极简关键、省时省力)《Linux操作系统原理分析之Linux文件管理(1)》(25)
《Linux操作系统原理分析之Linux文件管理(1)》(25) 8 Linux文件管理8.1 Linux 文件系统概述8.2 EXT2 文件系统8.2.1 EXT2 文件系统的构造8.2.2 EXT2 超级块(super block)8.2.3 组描述符8.2.4 块位图 8.3 EX…...

算能PCIe开发环境搭建-一些记录
开发环境与运行环境: 开发环境是指用于模型转换或验证以及程序编译等开发过程的环境;运行环境是指在具备Sophon设备的平台上实际使用设备进行算法应用部署的运行环境。 开发环境与运行环境可能是统一的(如插有SC5加速卡的x86主机,…...

使用C#和HtmlAgilityPack打造强大的Snapchat视频爬虫
概述 Snapchat作为一款备受欢迎的社交媒体应用,允许用户分享照片和视频。然而,由于其特有的内容自动消失特性,爬虫开发面临一些挑战。本文将详细介绍如何巧妙运用C#和HtmlAgilityPack库,构建一个高效的Snapchat视频爬虫。该爬虫能…...

c/c++的字符和字符串输入输出
注: 1.下面这些为本人大学四年所用过的处理办法, 至今为止遇到的所有编程题都能够使用。如果需要了解更多关于putchar,cin.get,cin.getline等的请自行搜索。 2.getchar相当于获取一个字符,可以实现单个字符的输入以及通过循环实现多个字符输…...
学习设计模式的网站
Refactoring and Design Patternshttps://refactoring.guru/...
Hadoop学习笔记(HDP)-Part.08 部署Ambari集群
目录 Part.01 关于HDP Part.02 核心组件原理 Part.03 资源规划 Part.04 基础环境配置 Part.05 Yum源配置 Part.06 安装OracleJDK Part.07 安装MySQL Part.08 部署Ambari集群 Part.09 安装OpenLDAP Part.10 创建集群 Part.11 安装Kerberos Part.12 安装HDFS Part.13 安装Ranger …...
IDEA加载阿里Java规范插件
IDEA加载阿里巴巴Java开发手册插件,在写代码的时候会自动扫描代码规范。 1、打开Settings 2、打开Plugins 3、搜索Alibaba Java Code Guidelines(XenoAmess TPM)插件,点击Install进行安装,然后重启IDE生效。 4、鼠标右…...

【CSP】202305-1_重复局面Python实现
文章目录 [toc]试题编号试题名称时间限制内存限制题目背景问题描述输入格式输出格式样例输入样例输出样例说明子任务提示Python实现 试题编号 202305-1 试题名称 重复局面 时间限制 1.0s 内存限制 512.0MB 题目背景 国际象棋在对局时,同一局面连续或间断出现3次或3…...

html5各行各业官网模板源码下载(1)
文章目录 1.来源2.源码模板2.1 HTML5白色简洁设计师网站模板2.2 HTML5保护野生动物响应式网站模板 作者:xcLeigh 文章地址:https://blog.csdn.net/weixin_43151418/article/details/134682321 html5各行各业官网模板源码下载,这个主题覆盖各行…...
6 Redis缓存设计与性能优化
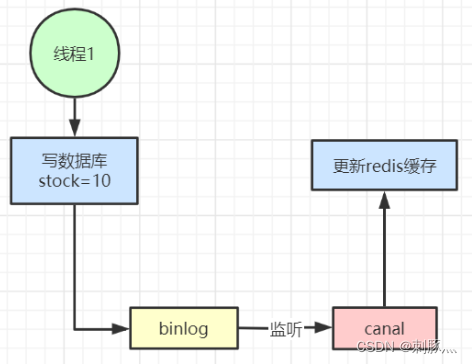
缓存穿透 缓存穿透是指查询一个根本不存在的数据, 缓存层和存储层都不会命中, 通常出于容错的考虑, 如果从存储层查不到数据则不写入缓存层。缓存穿透将导致不存在的数据每次请求都要到存储层去查询, 失去了缓存保护后端存储的意义…...

SpringCloud常见问题
1、什么是Spring Cloud? Spring Cloud是一款基于Spring Boot框架开发的微服务框架,它为开发人员提供了一系列的组件和工具,可以帮助开发人员快速构建和部署微服务,提高开发效率和项目可维护性。Spring Cloud提供了包括服务注册与…...

2026 免费在线照片换背景底色怎么做?详细操作方法 + 工具实测
想要快速改变照片背景底色却不知道怎么操作?本文为你盘点了最实用的免费在线照片换背景底色工具,涵盖详细的操作步骤和使用场景,让你轻松搞定各类背景处理需求。为什么需要在线换背景底色?在日常生活中,很多时候我们拍…...
)
别再只用Leaflet了!Mapbox GL JS加载本地MVT矢量瓦片保姆级教程(附避坑点)
从Leaflet到Mapbox GL JS:解锁MVT矢量瓦片的进阶玩法 当传统WebGIS开发者第一次看到Mapbox GL JS渲染的矢量瓦片地图时,那种震撼感不亚于从黑白电视切换到4K HDR。Leaflet就像一把可靠的瑞士军刀,而Mapbox GL JS则像一套专业厨房设备——当你…...

AI Agent设计模式:从ReAct到Plan-and-Execute
Agent 设计模式:ReAct 与 Plan-Execute 讲透Function Calling 让 Agent 会用工具,但真正让 Agent「聪明」的,是它的思考模式。这就像给你一本字典不意味着你会写文章——你需要方法论。ReAct 和 Plan-Execute 就是 Agent 的两种核心方法论。一…...

ESPHome安装后,你的第一个智能设备可以不是开关或灯
ESPHome创意实践:从温控风扇到植物管家,解锁智能设备的无限可能 当你完成ESPHome的基础安装后,脑海中浮现的第一个项目是什么?大多数人会想到开关或灯泡——这些确实是智能家居的经典起点。但ESP8266/ESP32开发板的潜力远不止于此…...

Page Assist终极指南:在浏览器侧边栏运行本地AI模型的完整解决方案
Page Assist终极指南:在浏览器侧边栏运行本地AI模型的完整解决方案 【免费下载链接】page-assist Use your locally running AI models to assist you in your web browsing 项目地址: https://gitcode.com/GitHub_Trending/pa/page-assist Page Assist是一款…...

别再被格式卡论文了!Paperxie 格式排版功能,一键搞定从本科到博士的规范难题
paperxie-免费查重复率aigc检测/开题报告/毕业论文/智能排版/文献综述/AI PPThttps://www.paperxie.cn/format/typesettinghttps://www.paperxie.cn/format/typesetting 论文季里,有多少人的崩溃,不是因为写不出内容,而是死在了格式上&#x…...

ARM Thumb指令集内存屏障详解:DMB、DSB与ISB
1. ARM Thumb指令集中的内存屏障指令概述在嵌入式系统和移动设备开发中,ARM处理器占据着主导地位。作为RISC架构的代表,ARM提供了多种指令集以适应不同场景的需求,其中Thumb指令集以其高代码密度著称。在多核处理器和并发编程场景下ÿ…...

终极免费方案:如何用Wand-Enhancer解锁WeMod高级功能完整指南
终极免费方案:如何用Wand-Enhancer解锁WeMod高级功能完整指南 【免费下载链接】Wand-Enhancer Advanced UX and interoperability extension for Wand (WeMod) app 项目地址: https://gitcode.com/gh_mirrors/we/Wand-Enhancer 你是否厌倦了WeMod免费版的种种…...

攻防演练:Ettercap 实战中间人攻击与防御指南
1. 认识Ettercap:网络攻防的双刃剑 第一次接触Ettercap是在2015年的一次企业内网渗透测试中。当时我们需要模拟黑客攻击路径,测试公司内部网络的安全性。这个看起来其貌不扬的命令行工具,只用了几条简单的ARP欺骗命令,就成功劫持了…...

两阶段目标检测器核心原理与流程详解
两阶段目标检测器的核心思想是:第一阶段先找候选区域,第二阶段再对候选区域做分类和精修。典型代表是: R-CNN Fast R-CNN Faster R-CNN Mask R-CNN现在最典型的是 Faster R-CNN / Mask R-CNN,所以我以它为主来讲。1. 两阶段目标检…...