PyTorch 基础篇(1):Pytorch 基础
Pytorch 学习开始
入门的材料来自两个地方:
第一个是官网教程:WELCOME TO PYTORCH TUTORIALS,特别是官网的六十分钟入门教程 DEEP LEARNING WITH PYTORCH: A 60 MINUTE BLITZ。
第二个是韩国大神 Yunjey Choi 的 Repo:pytorch-tutorial,代码写得干净整洁。
目的:我是直接把 Yunjey 的教程的 python 代码挪到 Jupyter Notebook 上来,一方面可以看到运行结果,另一方面可以添加注释和相关资料链接。方便后面查阅。
顺便一题,我的 Pytorch 的版本是 0.4.1
- import torch
- print(torch.version)
- 0.4.1
- # 包
- import torch
- import torchvision
- import torch.nn as nn
- import numpy as np
- import torchvision.transforms as transforms
autograd(自动求导 / 求梯度) 基础案例 1
- # 创建张量(tensors)
- x = torch.tensor(1., requires_grad=True)
- w = torch.tensor(2., requires_grad=True)
- b = torch.tensor(3., requires_grad=True)
- # 构建计算图( computational graph):前向计算
- y = w * x + b # y = 2 * x + 3
- # 反向传播,计算梯度(gradients)
- y.backward()
- # 输出梯度
- print(x.grad) # x.grad = 2
- print(w.grad) # w.grad = 1
- print(b.grad) # b.grad = 1
- tensor(2.)
- tensor(1.)
- tensor(1.)
autograd(自动求导 / 求梯度) 基础案例 2
- # 创建大小为 (10, 3) 和 (10, 2)的张量.
- x = torch.randn(10, 3)
- y = torch.randn(10, 2)
- # 构建全连接层(fully connected layer)
- linear = nn.Linear(3, 2)
- print ('w: ', linear.weight)
- print ('b: ', linear.bias)
- # 构建损失函数和优化器(loss function and optimizer)
- # 损失函数使用均方差
- # 优化器使用随机梯度下降,lr是learning rate
- criterion = nn.MSELoss()
- optimizer = torch.optim.SGD(linear.parameters(), lr=0.01)
- # 前向传播
- pred = linear(x)
- # 计算损失
- loss = criterion(pred, y)
- print('loss: ', loss.item())
- # 反向传播
- loss.backward()
- # 输出梯度
- print ('dL/dw: ', linear.weight.grad)
- print ('dL/db: ', linear.bias.grad)
- # 执行一步-梯度下降(1-step gradient descent)
- optimizer.step()
- # 更底层的实现方式是这样子的
- # linear.weight.data.sub_(0.01 * linear.weight.grad.data)
- # linear.bias.data.sub_(0.01 * linear.bias.grad.data)
- # 进行一次梯度下降之后,输出新的预测损失
- # loss的确变少了
- pred = linear(x)
- loss = criterion(pred, y)
- print(‘loss after 1 step optimization: ‘, loss.item())
- w: Parameter containing:
- tensor([[ 0.5180, 0.2238, -0.5470],
- [ 0.1531, 0.2152, -0.4022]], requires_grad=True)
- b: Parameter containing:
- tensor([-0.2110, -0.2629], requires_grad=True)
- loss: 0.8057981729507446
- dL/dw: tensor([[-0.0315, 0.1169, -0.8623],
- [ 0.4858, 0.5005, -0.0223]])
- dL/db: tensor([0.1065, 0.0955])
- loss after 1 step optimization: 0.7932316660881042
从 Numpy 装载数据
- # 创建Numpy数组
- x = np.array([[1, 2], [3, 4]])
- print(x)
- # 将numpy数组转换为torch的张量
- y = torch.from_numpy(x)
- print(y)
- # 将torch的张量转换为numpy数组
- z = y.numpy()
- print(z)
- [[1 2]
- [3 4]]
- tensor([[1, 2],
- [3, 4]])
- [[1 2]
- [3 4]]
输入工作流(Input pipeline)
- # 下载和构造CIFAR-10 数据集
- # Cifar-10数据集介绍:https://www.cs.toronto.edu/~kriz/cifar.html
- train_dataset = torchvision.datasets.CIFAR10(root=’…/…/…/data/’,
- train=True,
- transform=transforms.ToTensor(),
- download=True)
- # 获取一组数据对(从磁盘中读取)
- image, label = train_dataset[0]
- print (image.size())
- print (label)
- # 数据加载器(提供了队列和线程的简单实现)
- train_loader = torch.utils.data.DataLoader(dataset=train_dataset,
- batch_size=64,
- shuffle=True)
- # 迭代的使用
- # 当迭代开始时,队列和线程开始从文件中加载数据
- data_iter = iter(train_loader)
- # 获取一组mini-batch
- images, labels = data_iter.next()
- # 正常的使用方式如下:
- for images, labels in train_loader:
- # 在此处添加训练用的代码
- pass
- Files already downloaded and verified
- torch.Size([3, 32, 32])
- 6
自定义数据集的 Input pipeline
- # 构建自定义数据集的方式如下:
- class CustomDataset(torch.utils.data.Dataset):
- def init(self):
- # TODO
- # 1. 初始化文件路径或者文件名
- pass
- def getitem(self, index):
- # TODO
- # 1. 从文件中读取一份数据(比如使用nump.fromfile,PIL.Image.open)
- # 2. 预处理数据(比如使用 torchvision.Transform)
- # 3. 返回数据对(比如 image和label)
- pass
- def len(self):
- # 将0替换成数据集的总长度
- return 0
- # 然后就可以使用预置的数据加载器(data loader)了
- custom_dataset = CustomDataset()
- train_loader = torch.utils.data.DataLoader(dataset=custom_dataset,
- batch_size=64,
- shuffle=True)
- 预训练模型
- # 下载并加载预训练好的模型 ResNet-18
- resnet = torchvision.models.resnet18(pretrained=True)
- # 如果想要在模型仅对Top Layer进行微调的话,可以设置如下:
- # requieres_grad设置为False的话,就不会进行梯度更新,就能保持原有的参数
- for param in resnet.parameters():
- param.requires_grad = False
- # 替换TopLayer,只对这一层做微调
- resnet.fc = nn.Linear(resnet.fc.in_features, 100) # 100 is an example.
- # 前向传播
- images = torch.randn(64, 3, 224, 224)
- outputs = resnet(images)
- print (outputs.size()) # (64, 100)
- torch.Size([64, 100])
保存和加载模型
- # 保存和加载整个模型
- torch.save(resnet, ‘model.ckpt’)
- model = torch.load(‘model.ckpt’)
- # 仅保存和加载模型的参数(推荐这个方式)
- torch.save(resnet.state_dict(), ‘params.ckpt’)
- resnet.load_state_dict(torch.load(‘params.ckpt’))
相关文章:
:Pytorch 基础)
PyTorch 基础篇(1):Pytorch 基础
Pytorch 学习开始 入门的材料来自两个地方: 第一个是官网教程:WELCOME TO PYTORCH TUTORIALS,特别是官网的六十分钟入门教程 DEEP LEARNING WITH PYTORCH: A 60 MINUTE BLITZ。 第二个是韩国大神 Yunjey Choi 的 Repo:pytorch-t…...

掌握Selenium4:详解各种定位方式
Selenium4中有多种元素定位方式,主要包括以下几种: 通过ID属性定位:根据元素的id属性进行定位。通过name属性定位:当元素没有id属性而有name属性时,可以使用name属性进行元素定位。通过class name定位:可以…...

go-fastfds部署心得
我是windows系统安装 Docker Desktop部署 docker run --name go-fastdfs(任意的一个名称) --privilegedtrue -t -p 3666:8080 -v /data/fasttdfs_data:/data -e GO_FASTDFS_DIR/data sjqzhang/go-fastdfs:lastest docker run:该命令用于运…...
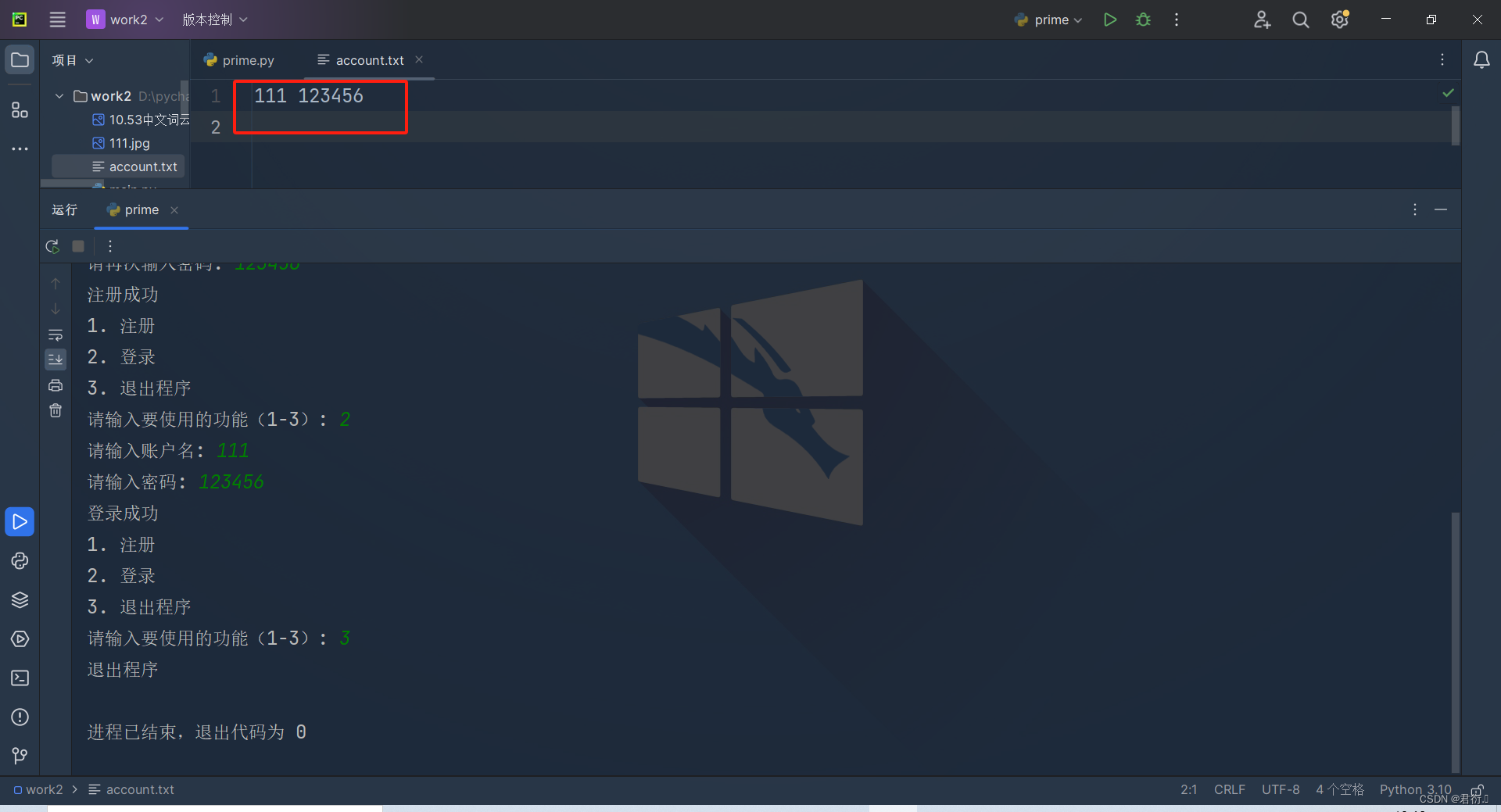
Python第三次练习
Python 一、如何判断一个字符串是否是另一个字符串的子串二、如何验证一个字符串中的每一个字符均在另一个字符串中出现三、如何判定一个字符串中既有数字又有字母四、做一个注册登录系统 一、如何判断一个字符串是否是另一个字符串的子串 实现代码: string1 inp…...

从Java8升级到Java17,特色优化点
从Java8升级到Java17,特色优化点 一、局部变量类型推断二、switch表达式三、文本块四、Records五、模式匹配instanceof六、密封类七、NullPointerException 从Java 8 到 Java 20,Java 已经走过了漫长的道路,自 Java 8 以来,Java 生…...

js实现富文本
当涉及到使用 JavaScript 实现富文本时,一种常见的方法是使用一些现成的富文本编辑器库,比如: Quill:一个功能强大、易于集成的富文本编辑器,支持自定义样式和格式,提供丰富的插件和API。 TinyMCE…...

每日OJ题_算法_双指针②_力扣1089. 复写零
目录 力扣1089. 复写零 解析代码 力扣1089. 复写零 1089. 复写零 - 力扣(LeetCode) 难度 简单 给你一个长度固定的整数数组 arr ,请你将该数组中出现的每个零都复写一遍,并将其余的元素向右平移。 注意:请不要在…...
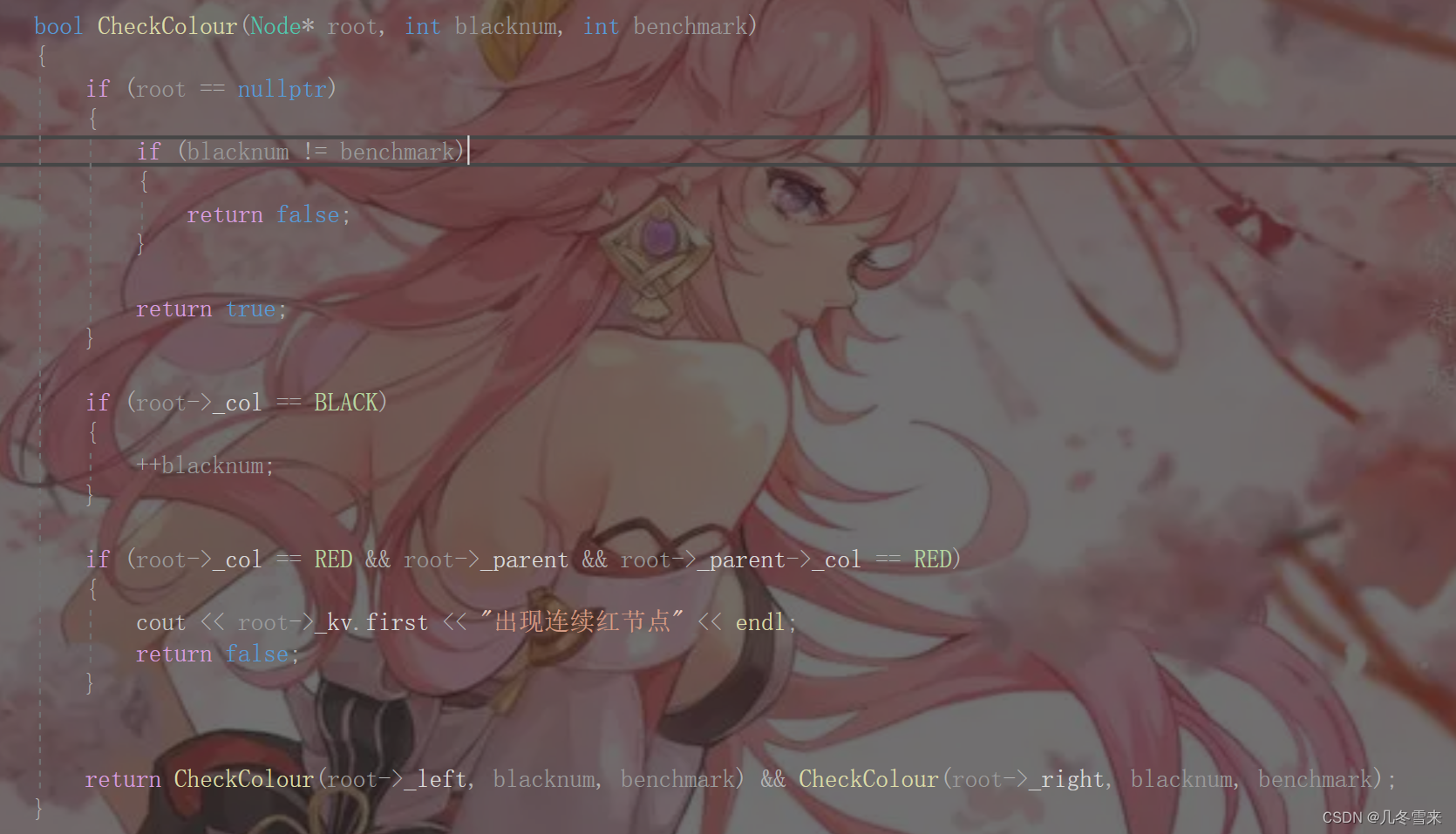
C++——红黑树
作者:几冬雪来 时间:2023年12月7日 内容:C——红黑树讲解 目录 前言: 红黑树的概念: 红黑树的性质: 红黑树的路径计算: 最长路径和最短路径: AVL树与红黑树的区别ÿ…...

【神化世界】asp网页500内部服务器错误的解决方法
问题解决方案记录 一、问题 在asp网页调试的时候,不小心改错了,好好的页面突然出现如下错误信息了: 二、解决方法 终于找到了问题所在,是sql语句出错造成的,特别记录一下。 正确的写法 sql"select * from mem…...

java面试题6
1.什么是Java中的泛型(Generic)? 答案:泛型是一种参数化类型的机制,在编译时提供类型安全性检查和重用代码的能力。使用泛型可以在编译时检测类型错误,并减少类型转换的需要。 2.Java中的反射(…...

(03)vite 处理 css
文章目录 系列全集vite 处理css流程vite如何解决协同开发,样式重复覆盖的问题?使用less通过配置,更改vite的css默认行为vite 利用postcss样式兼容低版本浏览器 系列全集 (01)vite 从启动服务器开始 (02&am…...
阿里云上传文件出现的问题解决(跨域设置)
跨域设置引起的问题 起因:开通对象存储服务后,上传文件限制在5M 大小,无法上传大文件。 1.查看报错信息 2.分析阿里云服务端响应内容 <?xml version"1.0" encoding"UTF-8"?> <Error><Code>Invali…...

利用JavaFX生成验证码图片
以下是一个基于 JavaFX 的验证码图片生成小程序的示例代码: import javafx.application.Application; import javafx.embed.swing.SwingFXUtils; import javafx.scene.Scene; import javafx.scene.canvas.Canvas; import javafx.scene.canvas.GraphicsContext; import javafx…...
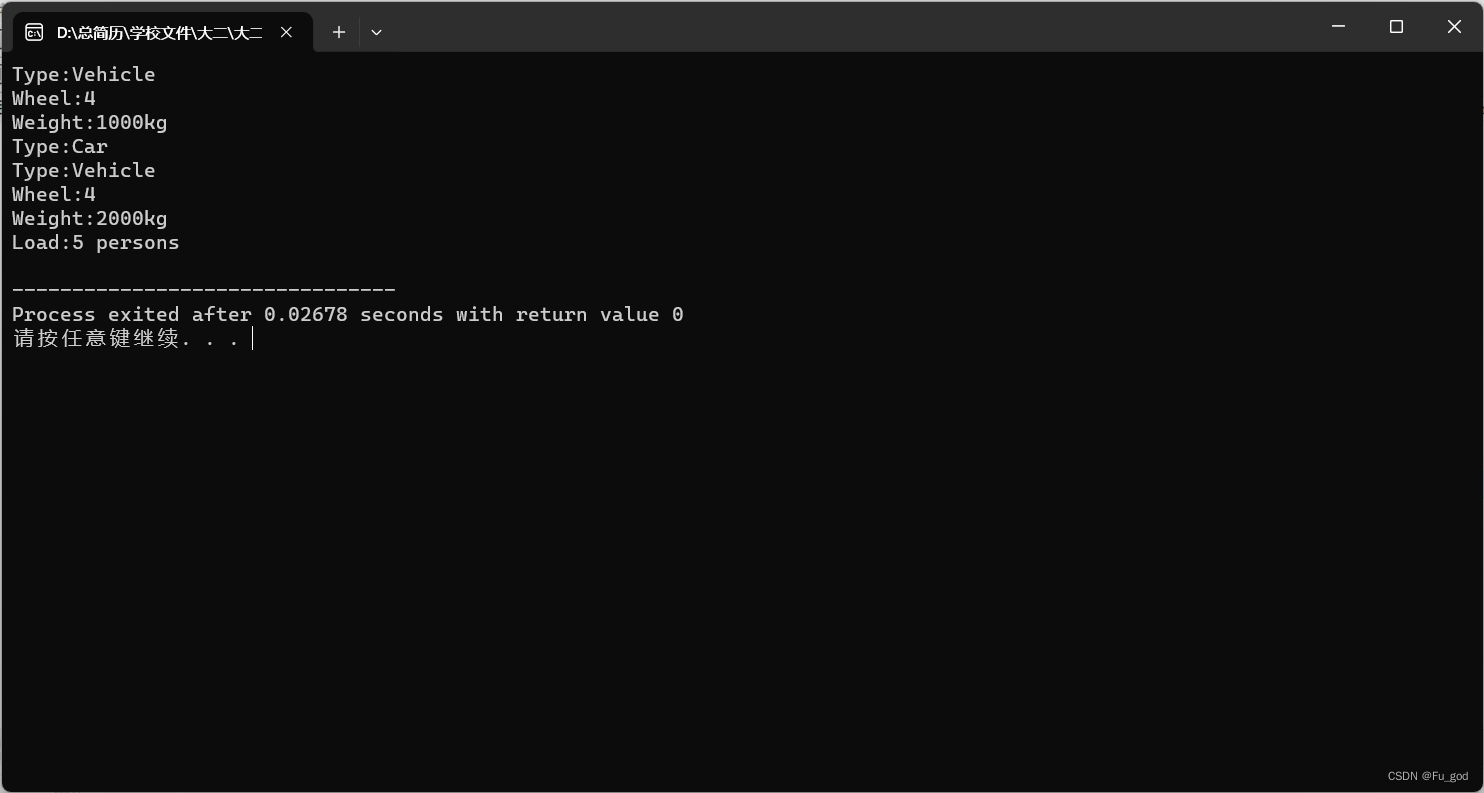
6-55.汽车类的继承
根据给定的汽车类vehicle(包含的数据成员有车轮个数wheels和车重weight)声明,完成其中成员函数的定义,之后再定义其派生类并完成测试。 小车类car是它的派生类,其中包含载人数passenger_load。每个类都有相关数据的输出…...

SCI论文——respectively用法
respectively用于配对两组(三组)事物,表明后一组与前一组按照相同的顺序排列,从而使句意明确。一般是在句子的最后,而且在respectively的前面需要一个逗号“,” 一 、两组事物: 原则是尽可能靠近第二组的…...

解决方案 | 法大大电子签约加速农牧业数字化进程
近年来,我国农业技术得到快速发展,并开发出一批实用的数字农业技术产品,建立了专用网络数字农业技术平台。数字农业是农业现代化的高级阶段,是创新推动农业农村信息化发展的有效手段,也是我国由农业大国迈向农业强国的…...
设计模式之GoF23介绍
深入探讨设计模式:构建可维护、可扩展的软件架构 一、设计模式的背景1.1 什么是设计模式1.2 设计模式的历史 二、设计模式的分类2.1 创建型模式2.2 结构型模式2.3 行为型模式 三、七大设计原则四、设计模式关系结论 :rocket: :rocket: :rocket: 在软件开发领域&…...

UDP协议实现群聊
服务端 import java.io.*; import java.net.*; import java.util.ArrayList; public class Server{public static ServerSocket server_socket;public static ArrayList<Socket> socketListnew ArrayList<Socket>(); public static void main(String []args){try{…...

lombok原理 @Slf4j 怎么生成get set log
Lombok是一种Java库,通过注解的方式提供了许多有用的功能,包括生成Getter、Setter、日志等。Slf4j注解是Lombok中的一种,它用于自动生成日志记录器(Logger)。 下面简要介绍一下Lombok的原理,以及Slf4j注解…...

【目标检测】进行实时检测计数时,在摄像头窗口显示实时计数个数
这里我是用我本地训练的基于yolov8环境的竹签计数模型,在打开摄像头窗口增加了实时计数显示的代码,可以直接运行,大家可以根据此代码进行修改,其底层原理时将检测出来的目标的个数显示了出来。 该项目链接:【目标检测…...

Haneke最佳实践:10个技巧让你的图片缓存更高效
Haneke最佳实践:10个技巧让你的图片缓存更高效 【免费下载链接】Haneke A lightweight zero-config image cache for iOS, in Objective-C. 项目地址: https://gitcode.com/gh_mirrors/ha/Haneke Haneke是一款适用于iOS平台的轻量级零配置图片缓存库…...

别再死记硬背MVSNet了!用‘一摞书’的比喻,5分钟彻底搞懂3D重建的代价体与概率体
用“一摞书”的比喻彻底理解MVSNet的3D重建原理 当你第一次接触MVSNet这类三维重建算法时,是否曾被那些抽象的专业术语所困扰?特征体、代价体、概率体...这些概念听起来就像天书一般。今天,我将用一个生活中最常见的"一摞书"的比喻…...
)
ESP32项目编译后,如何看懂Output里的内存占用(DRAM/IRAM/Flash详解)
ESP32项目编译后内存占用分析:从DRAM到Flash的深度解读 当你在VSCode中按下编译按钮,看到终端输出那一连串内存占用数据时,是否曾感到困惑?这些数字背后隐藏着ESP32内存架构的秘密,也直接关系到你的项目性能和稳定性。…...

从电压模到COT:DC-DC降压转换器控制模式演进与选型指南
1. DC-DC降压转换器控制模式概述 第一次接触电源设计时,我被各种控制模式搞得晕头转向。电压模、电流模、迟滞控制、COT...这些专业名词就像天书一样。后来在实际项目中摸爬滚打多年,才发现理解这些控制模式的关键在于抓住它们的"性格特点"——…...

锂离子动力电池机理建模与系统状态评估【附代码】
✨ 长期致力于新能源汽车、动力电池系统、状态监测与评估、Matlab/Simulink研究工作,擅长数据搜集与处理、建模仿真、程序编写、仿真设计。 ✅ 专业定制毕设、代码 ✅ 如需沟通交流,点击《获取方式》 (1)全阶电化学-热耦合模型的有…...
智能服装开发实战:基于NeoPixel与Arduino的动态光效设计与实现
1. 项目概述:打造一件会“流动”的智能光效裙几年前,当我第一次看到Phil Burgess的“Ooze Master 3000”代码时,就被那个模拟粘稠液体缓慢滴落的灯光动画迷住了。它不像普通的彩虹轮转那么直白,而是有一种有机的、近乎生物感的动态…...

RAG知识库生命周期①【第七篇】:文档新增修改删除,生产级向量同步更新方案
生产级 RAG 避坑实战合集【第七篇】文章简介:前面六篇我们搞定了文档解析、去重、文本清洗、Chunk切块、结构化元数据。绝大多数项目卡在这一关:文档内容变了怎么办?制度修改、数据订正、条款作废、资料更新。Demo可以删库重灌,生…...

一文说清:穿透式监管体系、穿透式监管平台、穿透式监管模型
最近这段时间,和不少央国企的财务、风控负责人交流,话题总绕不开穿透式监管。大家共识很强:穿透式监管必须做,也不得不做。穿透式监管建设本身,横跨了三个专业壁垒很高的领域:公司治理与风险管理、企业数字…...

半导体测试数据分析难题?STDF Viewer提供一站式专业解决方案
半导体测试数据分析难题?STDF Viewer提供一站式专业解决方案 【免费下载链接】STDF-Viewer A free GUI tool to visualize STDF (semiconductor Standard Test Data Format) data files. 项目地址: https://gitcode.com/gh_mirrors/st/STDF-Viewer 半导体测试…...

CircuitPython微控制器图形保存实战:从屏幕截图到BMP文件生成
1. 项目概述:为什么我们需要在微控制器上保存图形? 在嵌入式开发领域,尤其是当我们使用像Adafruit PyPortal、PyGamer这类带有彩色显示屏的开发板时,图形界面的调试和内容存档一直是个不大不小的痛点。想象一下,你花了…...