严蔚敏数据结构p17(2.19)——p18(2.24) (c语言代码实现)
目录
2.19已知线性表中的元素以值递增有序排列,并以单链表作存储结构。试写一高效的算法,删除表中所有值大于 mink 且小于 maxk 的元素(若表中存在这样的元素)同时释放被删结点空间,并分析你的算法的时间复杂度(注意:mink 和 maxk 是给定的个参变量,它们的值可以和表中的元素相同,也可以不同)。
2.20 同 2.19 题条件,试写一高效的算法,删除表中所有值相同的多余元素(得操作后的线性表中所有元素的值均不相同),同时释放被删结点空间,并分析你的算法的时间复杂度。
2.21 试写一算法,实现顺序表的就地逆置,即利用原表的存储空间将线性表(a1,a2,...,an)逆置为(an,...,a2,a1)。可以看下面这个(说的不好请见谅)👇
2.22试写一算法,对单链表实现就地逆置(可以看下面的视频讲解)👇
2.23 题目截图了
2.24假设有两个按元素值递增有序排列的线性表A和B均以单链表作存储结构,请编写算法将A表和B表归并成一个按元素值递减有序(即非递增有序,允许表中含有值相同的元素)排列的线性表 C,并要求利用原表(即A表和B 表)的结点空间构造C表。
2.19已知线性表中的元素以值递增有序排列,并以单链表作存储结构。试写一高效的算法,
删除表中所有值大于 mink 且小于 maxk 的元素(若表中存在这样的元素)同时释放被删结点空间,
并分析你的算法的时间复杂度(注意:mink 和 maxk 是给定的个参变量,它们的值可以和表中的元素相同,也可以不同)。
本题代码如下
void deletemidst(linklist* L, int mink, int maxk)
{lnode* p = (*L)->next, * pre = *L; // 定义指针p和pre分别指向链表头结点的下一个结点和链表头结点lnode* q; // 定义指针q用于释放临时结点while (p) // 遍历链表{if (p->data > mink && p->data < maxk) // 如果当前结点的值在指定范围内{q = p; // 将当前结点赋值给临时结点qp = p->next; // 将指针p指向下一个结点pre->next = p; // 将指针pre的next指针指向下一个结点free(q); // 释放临时结点q所占用的内存空间}else // 如果当前结点的值不在指定范围内{p = p->next; // 将指针p指向下一个结点pre = pre->next; // 将指针pre指向下一个结点}}
}完整测试代码如下
#include<stdio.h>
#include<stdlib.h>
typedef struct lnode
{int data; // 数据域,存储整数值struct lnode* next; // 指针域,指向下一个节点
}lnode, * linklist; // 定义链表结构体和指针类型
int a[8] = { 1,2,3,4,5,6,7,8 }; // 初始化数组a
int n = 8; // 数组a的长度
// 构建链表函数
void buildlinklist(linklist* L)
{*L = (lnode*)malloc(sizeof(lnode)); // 分配内存空间给链表头结点(*L)->next = NULL; // 初始化链表头结点的next指针为NULLlnode* s, * r = *L; // 定义临时结点s和当前结点rint i = 0;for (i = 0; i < n; i++) // 遍历数组a{s = (lnode*)malloc(sizeof(lnode)); // 分配内存空间给临时结点ss->data = a[i]; // 将数组a中的元素赋值给临时结点s的data域s->next = r->next; // 将当前结点的next指针指向临时结点的next指针所指向的结点r->next = s; // 将当前结点的next指针指向临时结点sr = s; // 更新当前结点r为临时结点s}r->next = NULL; // 将最后一个结点的next指针设为NULL
}
// 删除指定范围内的值函数
void deletemidst(linklist* L, int mink, int maxk)
{lnode* p = (*L)->next, * pre = *L; // 定义指针p和pre分别指向链表头结点的下一个结点和链表头结点lnode* q; // 定义指针q用于释放临时结点while (p) // 遍历链表{if (p->data > mink && p->data < maxk) // 如果当前结点的值在指定范围内{q = p; // 将当前结点赋值给临时结点qp = p->next; // 将指针p指向下一个结点pre->next = p; // 将指针pre的next指针指向下一个结点free(q); // 释放临时结点q所占用的内存空间}else // 如果当前结点的值不在指定范围内{p = p->next; // 将指针p指向下一个结点pre = pre->next; // 将指针pre指向下一个结点}}
}
// 打印链表函数
void print(linklist* L)
{lnode* k = (*L)->next; // 定义指针k指向链表头结点的下一个结点while (k) // 遍历链表{printf("%d ", k->data); // 输出当前结点的值k = k->next; // 将指针k指向下一个结点}
}int main()
{linklist L; // 定义链表Lbuildlinklist(&L); // 调用构建链表函数printf("原始单链表为:"); // 输出提示信息print(&L); // 调用打印链表函数printf("删除mink与maxk中间的值后的单链表为:"); // 输出提示信息deletemidst(&L, 2, 6); // 调用删除指定范围内的值函数print(&L); // 调用打印链表函数return 0; // 返回0表示程序正常结束
}测试结果为

2.20 同 2.19 题条件,试写一高效的算法,删除表中所有值相同的多余元素(得操作后的线性表中所有元素的值均不相同),同时释放被删结点空间,并分析你的算法的时间复杂度。
本题代码如下
void deleterepeat(linklist* L)
{lnode* p = (*L)->next, * pre = *L;//p为工作指针,pre为它的前驱指针防止断链lnode* q;while (p->next!=NULL){if (p->next->data == pre->next->data)//如果p的后继的值域等与它本身则执行删除操作{q = p;p = p->next;pre->next = p;free(q);}else//否则继续向后遍历{p = p->next;pre = pre->next;}}
}void deleterepeat(linklist* L)
{lnode* p = (*L)->next, * pre = *L;//p为工作指针,pre为它的前驱指针防止断链lnode* q;while (p->next!=NULL){if (p->next->data == pre->next->data)//如果p的后继的值域等与它本身则执行删除操作{q = p;p = p->next;pre->next = p;free(q);}else//否则继续向后遍历{p = p->next;pre = pre->next;}}
}完整测试代码
#include<stdio.h>
#include<stdlib.h>
typedef struct lnode
{int data;struct lnode* next;
}lnode,*linklist;
int a[8] = { 1,2,2,3,3,4,5,6 };
int n = 8;
void buildlinklist(linklist* L)
{*L = (lnode*)malloc(sizeof(lnode));(*L)->next = NULL;int i = 0;lnode* s, * r = *L;for (i = 0; i < n; i++){s = (lnode*)malloc(sizeof(lnode));s->data = a[i];s->next = r->next;r->next = s;r = s;}r->next = NULL;
}
void deleterepeat(linklist* L)
{lnode* p = (*L)->next, * pre = *L;//p为工作指针,pre为它的前驱指针防止断链lnode* q;while (p->next!=NULL){if (p->next->data == pre->next->data)//如果p的后继的值域等与它本身则执行删除操作{q = p;p = p->next;pre->next = p;free(q);}else//否则继续向后遍历{p = p->next;pre = pre->next;}}
}
void print(linklist* L)
{lnode* k = (*L)->next;while (k){printf("%d ", k->data);k = k->next;}
}
int main()
{linklist L;buildlinklist(&L);printf("原始单链表为:"); print(&L); // 调用打印链表函数printf("\n删除重复值后的单链表为:");deleterepeat(&L); // 调用删除重复值的函数print(&L); // 调用打印链表函数return 0; // 返回0表示程序正常结束
}测试结果为

2.21 试写一算法,实现顺序表的就地逆置,即利用原表的存储空间将线性表(a1,a2,...,an)逆置为(an,...,a2,a1)。可以看下面这个(说的不好请见谅)👇
c语言代码实现数据结构课后代码题顺序表p18 2_哔哩哔哩_bilibili
本题代码如下
void nizhi(struct sqlist *s)
{int i = 0; // 定义一个整型变量i,用于遍历顺序表int j = s->length; // 定义一个整型变量j,用于存储顺序表的长度int temp = 0; // 定义一个整型变量temp,用于临时存储元素for (i = 0; i < s->length / 2; i++) // 遍历顺序表的前半部分{temp = s->a[i]; // 将当前元素存储到temp中s->a[i] = s->a[s->length - 1 - i]; // 将后半部分的元素赋值给前半部分s->a[s->length - 1 - i] = temp; // 将temp中的元素赋值给后半部分}
}完整测试代码如下
#include<stdio.h>
#define Max 10
struct sqlist
{int a[Max];int length;
};
void nizhi(struct sqlist *s)
{int i = 0; // 定义一个整型变量i,用于遍历顺序表int j = s->length; // 定义一个整型变量j,用于存储顺序表的长度int temp = 0; // 定义一个整型变量temp,用于临时存储元素for (i = 0; i < s->length / 2; i++) // 遍历顺序表的前半部分{temp = s->a[i]; // 将当前元素存储到temp中s->a[i] = s->a[s->length - 1 - i]; // 将后半部分的元素赋值给前半部分s->a[s->length - 1 - i] = temp; // 将temp中的元素赋值给后半部分}
}
int main()
{struct sqlist s; // 定义两个顺序表变量sint i = 0; // 定义一个整型变量,用于遍历顺序表ss.length = 5; // 设置顺序表s的长度为5for (i = 0; i < s.length; i++) // 遍历交集结果scanf("%d", &s.a[i]);printf("原顺序表为:");for (i = 0; i < s.length; i++) // 遍历交集结果printf("%d ", s.a[i]); // 输出交集结果中的每个元素nizhi(&s);printf("\n逆置后的顺序表为:");for (i = 0; i < s.length; i++) // 遍历交集结果printf("%d ", s.a[i]); // 输出交集结果中的每个元素return 0; // 程序正常结束,返回0
}
测试结果为

2.22试写一算法,对单链表实现就地逆置(可以看下面的视频讲解)👇
c语言代码实现数据结构课后代码题顺序表p18 2_哔哩哔哩_bilibili
本题代码如下
void nizhi(linklist* L)//单链表就地逆置
{lnode* p = (*L)->next;lnode* r = p;(*L)->next = NULL;while (p != NULL){p = p->next;r->next = (*L)->next;(*L)->next = r;r = p;}
}完整测试代码如下
#include<stdio.h>
#define Max 50
struct sqlist
{int a[Max];int length;
};
void nizhi(struct sqlist* s)
{int temp = 0;for (int i = 0; i < s->length / 2; i++){temp = s->a[i];s->a[i] = s->a[s->length - i - 1];s->a[s->length - 1 - i] = temp;}
}
int main()
{struct sqlist s;int j = 0;s.length = 5;for (j = 0; j < s.length; j++)scanf("%d", &s.a[j]);printf("原先数组为:");for (j = 0; j < s.length; j++)printf("%d", s.a[j]);nizhi(&s);printf("\n逆置后的数组为:");for (j = 0; j < s.length; j++)printf("%d", s.a[j]);return 0;
}测试结果为

2.23
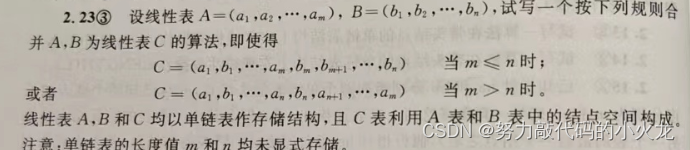
本题代码如下
linklist Union(linklist* A, linklist* B)
{lnode *C = (lnode*)malloc(sizeof(lnode));C->next = NULL;lnode* ra = (*A)->next, * rb = (*B)->next;lnode* rc = C;while (ra && rb){if (ra->data<rb->data)//若A中当前结点小于B中当前结点值{rc->next = ra;rc = ra;ra = ra->next;}else if (ra->data>rb->data)//若A中当前结点大于B中当前结点值{rc->next = rb;rc = rb;rb = rb->next;}else{rc->next = ra;rc = ra;ra = ra->next;rb= rb->next;}}while (ra)//B遍历完,A没有遍历完{rc->next= ra;rc = ra;ra = ra->next;}while (rb)//A遍历完,B没有遍历完{rc->next = rb;rc = rb;rb= rb->next;}rc->next = NULL; //结果表的表尾结点置空return C;
}完整测试代码如下
#include<stdio.h>
#include<stdlib.h>
typedef struct lnode
{int data;struct lnode* next;
}lnode, * linklist;
int na = 5;
int nb = 3;
int a[5] = { 1,3,5,7,9};
int b[3] = { 2,4,6 };
void buildlinklist(linklist* L, int arr[], int n)//创建链表
{*L = (lnode*)malloc(sizeof(lnode));(*L)->next = NULL;lnode* s = *L, * r = *L;int i = 0;for (i = 0; i < n; i++){s = (lnode*)malloc(sizeof(lnode));s->data = arr[i];s->next = r->next;r->next = s;r = s;}r->next = NULL;
}
linklist Union(linklist* A, linklist* B)
{lnode *C = (lnode*)malloc(sizeof(lnode));C->next = NULL;lnode* ra = (*A)->next, * rb = (*B)->next;lnode* rc = C;while (ra && rb){if (ra->data<rb->data)//若A中当前结点小于B中当前结点值{rc->next = ra;rc = ra;ra = ra->next;}else if (ra->data>rb->data)//若A中当前结点大于B中当前结点值{rc->next = rb;rc = rb;rb = rb->next;}else{rc->next = ra;rc = ra;ra = ra->next;rb= rb->next;}}while (ra)//B遍历完,A没有遍历完{rc->next= ra;rc = ra;ra = ra->next;}while (rb)//A遍历完,B没有遍历完{rc->next = rb;rc = rb;rb= rb->next;}rc->next = NULL; //结果表的表尾结点置空return C;
}
void print(linklist* L)//输出单链表
{lnode* k = (*L)->next;while (k){printf("%d ", k->data);k = k->next;}
}
int main()
{linklist A, B;buildlinklist(&A, a, na);buildlinklist(&B, b, nb);printf("A链表为:");print(&A);printf("\nB链表为:");print(&B);linklist C = Union(&A, &B);printf("\n合并后的链表为:");print(&C);return 0;
}测试结果如下


2.24假设有两个按元素值递增有序排列的线性表A和B均以单链表作存储结构,请编写算法将A表和B表归并成一个按元素值递减有序(即非递增有序,允许表中含有值相同的元素)排列的线性表 C,并要求利用原表(即A表和B 表)的结点空间构造C表。
本题代码如下
linklist Union(linklist* A, linklist* B)
{lnode* C = (lnode*)malloc(sizeof(lnode));C->next = NULL;lnode* ra = (*A)->next, * rb = (*B)->next;lnode* rapre = *A, * rbpre = *B;//rapre为ra的前驱指针,rbpre为rb的前去指针 lnode* rc = C;while (ra && rb){if (ra->data < rb->data)//若A中当前结点小于B中当前结点值{rapre = ra->next;ra->next=rc->next ;rc->next= ra;ra =rapre;}else if (ra->data > rb->data)//若A中当前结点大于B中当前结点值{rbpre = rb->next;rb->next = rc->next;rc->next = rb;rb = rbpre;}else{rapre = ra->next;ra->next = rc->next;rc->next = ra;ra = rapre;rb = rb->next;}}while (ra)//B遍历完,A没有遍历完{rapre = ra->next;ra->next = rc->next;rc->next = ra;ra = rapre;}while (rb)//A遍历完,B没有遍历完{rbpre = rb->next;rb->next = rc->next;rc->next = rb;rb = rbpre;}return C;
}完整测试代码如下
#include<stdio.h>
#include<stdlib.h>
typedef struct lnode
{int data;struct lnode* next;
}lnode, * linklist;
int na = 5;
int nb = 8;
int a[5] = { 1,3,5,7,9 };
int b[8] = { 2,4,6,8,10,12,14,16 };
void buildlinklist(linklist* L, int arr[], int n)//创建链表
{*L = (lnode*)malloc(sizeof(lnode));(*L)->next = NULL;lnode* s = *L, * r = *L;int i = 0;for (i = 0; i < n; i++){s = (lnode*)malloc(sizeof(lnode));s->data = arr[i];s->next = r->next;r->next = s;r = s;}r->next = NULL;
}
linklist Union(linklist* A, linklist* B)
{lnode* C = (lnode*)malloc(sizeof(lnode));C->next = NULL;lnode* ra = (*A)->next, * rb = (*B)->next;lnode* rapre = *A, * rbpre = *B;//rapre为ra的前驱指针,rbpre为rb的前去指针 lnode* rc = C;while (ra && rb){if (ra->data < rb->data)//若A中当前结点小于B中当前结点值{rapre = ra->next;ra->next=rc->next ;rc->next= ra;ra =rapre;}else if (ra->data > rb->data)//若A中当前结点大于B中当前结点值{rbpre = rb->next;rb->next = rc->next;rc->next = rb;rb = rbpre;}else{rapre = ra->next;ra->next = rc->next;rc->next = ra;ra = rapre;rb = rb->next;}}while (ra)//B遍历完,A没有遍历完{rapre = ra->next;ra->next = rc->next;rc->next = ra;ra = rapre;}while (rb)//A遍历完,B没有遍历完{rbpre = rb->next;rb->next = rc->next;rc->next = rb;rb = rbpre;}return C;
}
void print(linklist* L)//输出单链表
{lnode* k = (*L)->next;while (k){printf("%d ", k->data);k = k->next;}
}
int main()
{linklist A, B;buildlinklist(&A, a, na);buildlinklist(&B, b, nb);printf("A链表为:");print(&A);printf("\nB链表为:");print(&B);linklist C = Union(&A, &B);printf("\n合并后的链表为:");print(&C);return 0;
}测试结果如下

相关文章:
严蔚敏数据结构p17(2.19)——p18(2.24) (c语言代码实现)
目录 2.19已知线性表中的元素以值递增有序排列,并以单链表作存储结构。试写一高效的算法,删除表中所有值大于 mink 且小于 maxk 的元素(若表中存在这样的元素)同时释放被删结点空间,并分析你的算法的时间复杂度(注意:mink 和 maxk 是给定的个参变量,它们的值可以和表…...
0007Java程序设计-ssm基于微信小程序的在线考试系统
文章目录 **摘要**目 录系统实现开发环境 编程技术交流、源码分享、模板分享、网课分享 企鹅🐧裙:776871563 摘要 网络技术的快速发展给各行各业带来了很大的突破,也给各行各业提供了一种新的管理技术,基于微信小程序的在线考试…...

php 使用多线程
fpm cli socket redis PHP多线程-阿里云开发者社区 常驻内存:op cli EasyTask: PHP常驻内存多进程任务管理器,支持定时任务(PHP resident memory multi-process task manager, supports timing tasks) 协程:swoole Swoole - PHP 协…...

基于MapBox的方法封装及调用
目录 1、初始化地图 2、单独添加瓦片 3、开启绘制方法 4、移除绘制数据 5、拾取经纬度 6、加点 7、加线 8、加面 9、更改图层顺序 10、更改实体样式 11、移除实体或图层 12、定位某个点 13、定位数组 14、锁定实体跟随视角 15、获取视窗 16、设置俯仰角 17、设…...
)
华为OD机试真题-虚拟游戏理财-2023年OD统一考试(C卷)
题目描述: 在一款虚拟游戏中生活,你必须进行投资以增强在虚拟游戏中的资产以免被淘汰出局。现有一家Bank,它提供有若干理财产品m,风险及投资回报不同,你有N(元)进行投资,能接受的总风险值为X。 你要在可接受范围内选择最优的投资方式获得最大回报。 说明: 在虚拟游戏中…...

解决 video.js ios 播放一会行一会不行
最近用video 进行m3u8视频文件播放,但是途中遇到了 安卓和电脑端都能打开,ios有时可以播放有时播放不了 出现问题原因: ios拿到视频流前需要预加载视频,如果当前视频流还没有打开过,ios拿不到视频流的缓存,…...

排序分析(Ordination analysis)及R实现
在生态学、统计学和生物学等领域,排序分析是一种用于探索和展示数据结构的多元统计技术。这种分析方法通过将多维数据集中的样本或变量映射到低维空间,以便更容易理解和可视化数据之间的关系。排序分析常用于研究物种组成、生态系统结构等生态学和生物学…...

Tomcat主配置文件(server.xml)详解
前言 Tomcat主配置文件(server.xml)是Tomcat服务器的主要配置文件,文件位置在conf目录下,它包含了Tomcat的全局配置信息,包括监听端口、虚拟主机、安全配置、连接器等。 目录 1 server.xml组件类别 2 组件介绍 3 se…...
Python实现简单的区块链,实现共识算法、Merkle Tree(默克尔树)、冲突解决、添加交易等功能
Python实现简单的区块链 记录自己假期所学相关内容 文章中的内容,开源代码地址见文末。 文章目录 Python实现简单的区块链1、分模块实现简单的单节点区块链1.1 Transaction类1.2 DaDaMessage类1.3 Block类1.4 Dada_BlockCoin类1.5 主函数BlockChainApp类1.6 主函数…...
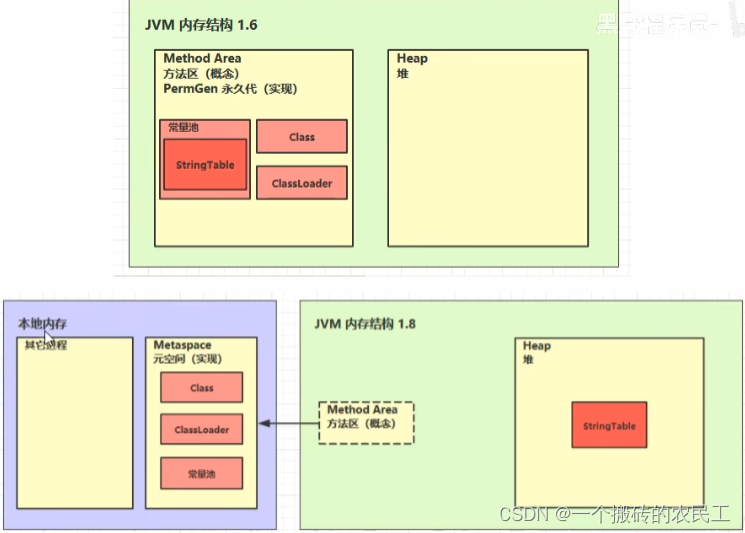
深入理解 Java 虚拟机(JVM)从入门到精通
目录 一、JVM内存结构1、堆(Heap)(1)特点(2)堆内存分配(3)晋升到老年代的方式(4)堆内存检验方式2、虚拟机栈(VM Stack)(1&…...
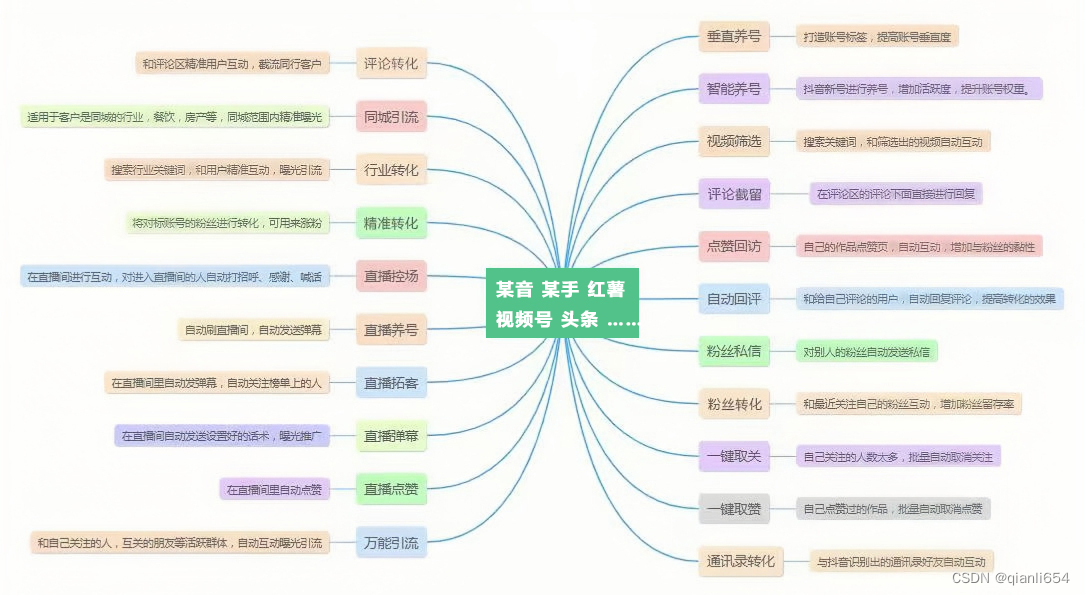
哔哩哔哩自动评论软件,其成果展示与开发流程和代码分享
先来看实操成果,↑↑需要的同学可看我名字↖↖↖↖↖,或评论888无偿分享 一、背景介绍 随着互联网的发展,哔哩哔哩作为国内最大的弹幕视频网站之一,吸引了越来越多的用户。为了更好地推广自己的作品,许多UP主希望能够通…...

Qt OpenCV 学习(一):环境搭建
对应版本 Qt 5.15.2OpenCV 3.4.9MinGW 8.1.0 32-bit 1. OpenCV 下载 确保安装 Qt 时勾选了 MinGW 编译器 本文使用 MinGW 编译好的 OpenCV 库,无需自行编译 确保下载的 MinGW 和上述安装 Qt 时勾选的 MinGW 编译器位数一致,此处均为 x86/32-bit下载地址…...

Redis——某马点评day02——商铺缓存
什么是缓存 添加Redis缓存 添加商铺缓存 Controller层中 /*** 根据id查询商铺信息* param id 商铺id* return 商铺详情数据*/GetMapping("/{id}")public Result queryShopById(PathVariable("id") Long id) {return shopService.queryById(id);} Service…...
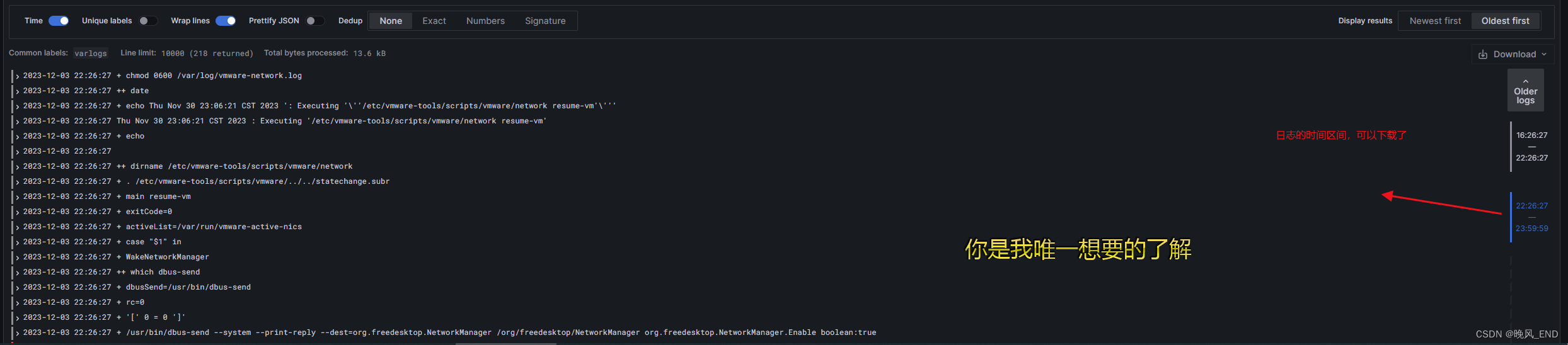
prometheus|云原生|轻型日志收集系统loki+promtail的部署说明
一, 日志聚合的概念说明 日志------ 每一个程序,服务都应该有保留日志,日志的作用第一是记录程序运行的情况,在出错的时候能够记录错误情况,简单来说就是审计工作,例如nginx服务的日志,kuber…...

MySQL 临时数据空间不足导致SQL被killed 的问题与扩展
开头还是介绍一下群,如果感兴趣PolarDB ,MongoDB ,MySQL ,PostgreSQL ,Redis, Oceanbase, Sql Server等有问题,有需求都可以加群群内,可以解决你的问题。加群请联系 liuaustin3 ,(共1730人左右 1 2 3 4 5࿰…...
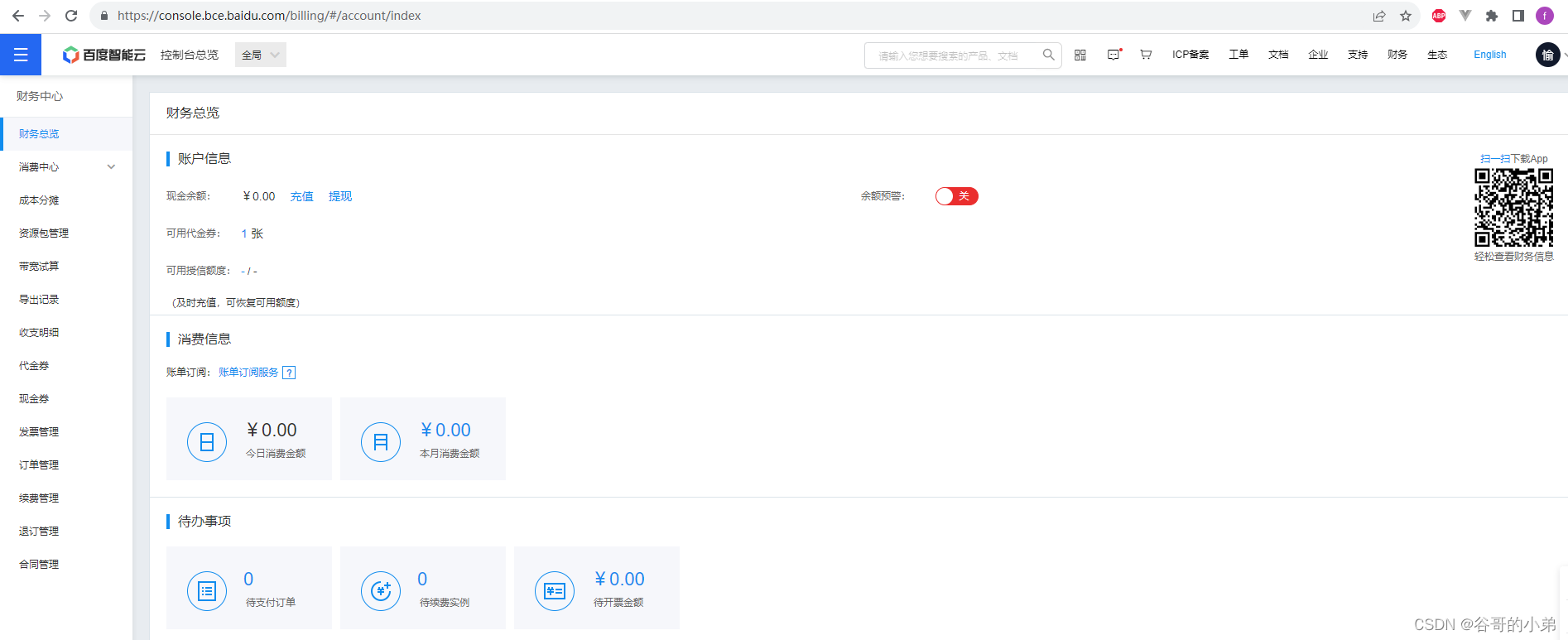
文心一言大模型应用开发入门
本文重点介绍百度智能云平台、文心一言、千帆大模型平台的基本使用与接入流程及其详细步骤。 注册文心一言 请登录文心一言官方网站 https://yiyan.baidu.com/welcome 点击登录;图示如下: 请注册文心一言账号并点击登录,图示如下࿱…...
C++新经典模板与泛型编程:SFINAE替换失败并不是一个错误
替换失败并不是一个错误(SFINAE) SFINAE是一个英文简称,全称为Substitution Failure is not an Error,翻译成中文就是“替换失败并不是一个错误”。 SFINAE可以看作C语言的一种特性或模板设计中要遵循的一个重要原则,…...
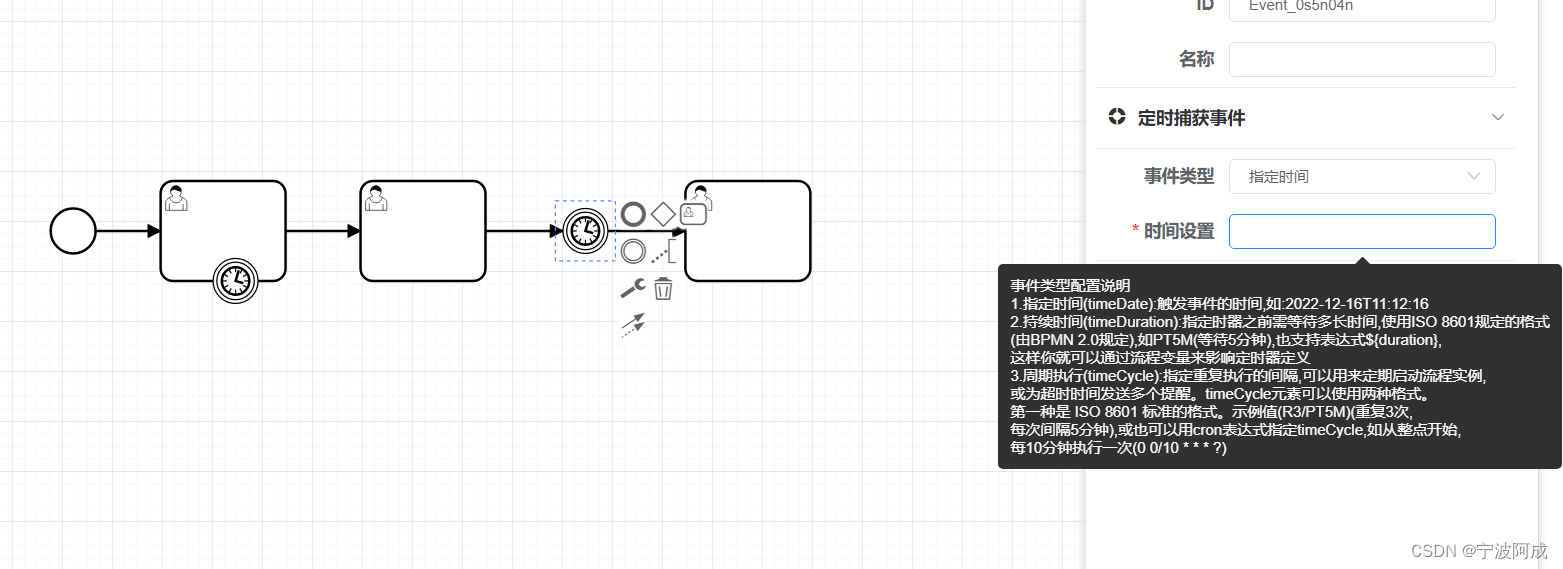
基于若依的ruoyi-nbcio流程管理系统支持支持定时边界事件和定时捕获事件
更多ruoyi-nbcio功能请看演示系统 gitee源代码地址 前后端代码: https://gitee.com/nbacheng/ruoyi-nbcio 演示地址:RuoYi-Nbcio后台管理系统 1、定时边界事件 <template><div class"panel-tab__content"><!--目前只处理定…...

递归-极其优雅的问题解决方法(Java)
递归的定义 大名鼎鼎的递归,相信你即使没接触过也或多或少听过,例如汉诺塔问题就是运用了递归的思想,对于一些学过c语言的同学来说,它可能就是噩梦,因为我当时就是这么认为的(不接受反驳doge) …...

VSCode搭建STM32开发环境
1、下载安装文件 链接:https://pan.baidu.com/s/1WnpDTgYBobiZaXh80pn5FQ 2、安装VSCodeUserSetup-x64-1.78.2.exe软件 3、 在VSCode中安装必要的插件 3、配置Keil Assistant插件 4、在环境变量中部署mingw64编译环境...

特斯拉Model 3无线充电垫DIY:基于Qi标准与3D打印的集成方案
1. 项目概述:为你的特斯拉Model 3打造专属无线充电垫作为一个喜欢在车里折腾点小玩意儿的车主,我总觉得特斯拉Model 3中控台那两个USB-C接口有点不够用,每次上车给手机充电都得插线,线缆还容易在储物格里缠成一团。原厂虽然提供了…...

2026年公司文化专题片拍摄公司排行榜:行业深度解析
引言随着企业对品牌传播和文化建设的重视程度不断提升,公司文化专题片成为展示企业形象、传递核心价值观的重要手段。越来越多的企业开始关注如何通过高质量的专题片来提升品牌形象和企业文化影响力。本文将深入分析2026年公司文化专题片拍摄行业的趋势,…...

3分钟快速上手:Windows实时语音转文字工具TMSpeech完整使用指南
3分钟快速上手:Windows实时语音转文字工具TMSpeech完整使用指南 【免费下载链接】TMSpeech 腾讯会议摸鱼工具 项目地址: https://gitcode.com/gh_mirrors/tm/TMSpeech 还在为会议记录手忙脚乱吗?是否曾因错过重要信息而懊恼?今天我要向…...

京东开源直播智能体框架:joylive-agent架构解析与实战指南
1. 项目概述与核心价值最近在开源社区里,一个名为joylive-agent的项目引起了我的注意。这个项目来自京东的开源组织jd-opensource,从名字上就能嗅到一股浓厚的“自动化”和“智能体”气息。简单来说,joylive-agent是一个旨在为直播场景&#…...

【NotebookLM语言润色功能深度解密】:20年AI写作工具实战者亲授5大未公开润色技巧,92%用户忽略的语义校准开关在哪?
更多请点击: https://intelliparadigm.com 第一章:NotebookLM语言润色功能全景认知 NotebookLM 是 Google 推出的基于用户自有文档的 AI 助手,其语言润色(Language Refinement)功能并非简单替换同义词,而是…...

基于LangChain构建AI智能体:从核心架构到生产部署实战
1. 项目概述与核心价值最近在GitHub上看到一个名为“GenAI_Agents”的项目,作者是NirDiamant。这个项目名本身就很有意思,它直指当前AI领域最火热、也最具想象力的方向之一:智能体(Agents)。简单来说,这个项…...

从零构建知识图谱:基于NLP的实体关系抽取与Neo4j存储实践
1. 项目概述:从文本到知识的桥梁最近几年,知识图谱这个概念在自然语言处理(NLP)和人工智能领域火得不行。简单来说,它就是把散落在海量文本里的“知识点”——比如实体(人物、地点、概念)和它们…...

Node.js调用Llama.cpp:本地部署大语言模型的完整指南
1. 项目概述:当Llama遇见Node.js如果你最近在折腾大语言模型(LLM)的本地部署,特别是对Meta的Llama系列模型情有独钟,同时又是一名Node.js开发者,那么你很可能已经听说过或者正在寻找一个像withcatai/node-l…...

OpenPencil Design Orchestrator:打通设计与代码的设计系统自动化工具
1. 项目概述:从开源仓库名到设计编排器的深度解读看到sorrowfulnessstaff973/openpencil-design-orchestrator这个仓库名,很多人的第一反应可能是好奇和困惑。这串字符背后,究竟隐藏着一个怎样的项目?作为一名长期混迹于开源社区、…...

基于Git与Zenn的内容管理方案:打造高效技术写作工作流
1. 项目概述:一个内容创作者的知识管理中枢 最近在技术社区里,看到不少朋友在讨论如何高效地管理自己的技术笔记、博客草稿和项目文档。我自己也在这个问题上摸索了很久,直到我遇到了一个名为 seiryuu1215/zenn-content 的GitHub仓库。这不…...