【SpringBoot高级篇】SpringBoot集成Sharding-JDBC分库分表
【SpringBoot高级篇】SpringBoot集成Sharding-JDBC分库分表
- Apache ShardingSphere
- 分库分表
- 分库分表的方式
- 垂直切分
- 垂直分表
- 垂直分库
- 水平切分
- 水平分库
- 水平分表
- 分库分表带来的问题
- 分库分表中间件
- Sharding-JDBC
- sharding-jdbc实现水平分表
- sharding-jdbc实现水平分库
- sharding-jdbc实现垂直分库
Apache ShardingSphere
Apache ShardingSphere(Incubator) 是一套开源的分布式数据库中间件解决方案组成的生态圈,它由 Sharding-JDBC、Sharding-Proxy 和 Sharding-Sidecar(规划中)这 3 款相互独立,却又能够混合部署配合使用的产品组成。它们均提供标准化的数据分片、分布式事务和数据库治理功能,可适用于如 Java 同构、异构语言、云原生等各种多样化的应用场景。
ShardingSphere 定位为关系型数据库中间件,旨在充分合理地在分布式的场景下利用关系型数据库的计算和存储能力,而并非实现一个全新的关系型数据库。它通过关注不变,进而抓住事物本质。关系型数据库当今依然占有巨大市场,是各个公司核心业务的基石,未来也难于撼动,我们目前阶段更加关注在原有基础上的增量,而非颠覆。Apache 官方发布从 4.0.0 版本开始。
分库分表
数据库中的数据量不一定是可控的,在未进行分库分表的情况下,随着时间和业务的发展,库中的表会越来越多,表中的数据量也会越来越大,相应地,数据操作,增删改查的开销也会越来越大;另外,由于无法进行分布式式部署,而一台服务器的资源(CPU、磁盘、内存、IO 等)是有限的,最终数据库所能承载的数据量、数据处理能力都将遭遇瓶颈。
分库分表就是为了解决由于数据量过大而导致数据库性能降低的问题,将原来独立的数据库拆分成若干数据库组成,将数据大表拆分成若干数据表组成,使得单一数据库、单一数据表的数据量变小,从而达到提升数据库性能的目的。
分库分表的方式
数据库的切分指的是通过某种特定的条件,将我们存放在同一个数据库中的数据分散存放到多个数据库(主机)中,以达到分散单台设备负载的效果,即分库分表。
数据的切分根据其切分规则的类型,可以分为 垂直切分 和水平切分
- 垂直切分: 把单一的表拆分成多个表,并分散到不同的数据库(主机)上
- 水平切分:根据表中数据的逻辑关系,将表中的数据按照某种条件拆分到多台数据库上
垂直切分
一个数据库有多个表构成,每个表对应不同的业务,垂直切分是只按照业务将表进行分类,将其分布到不同的数据库上,这样就将数据分担到了不同的库上(专库专用)
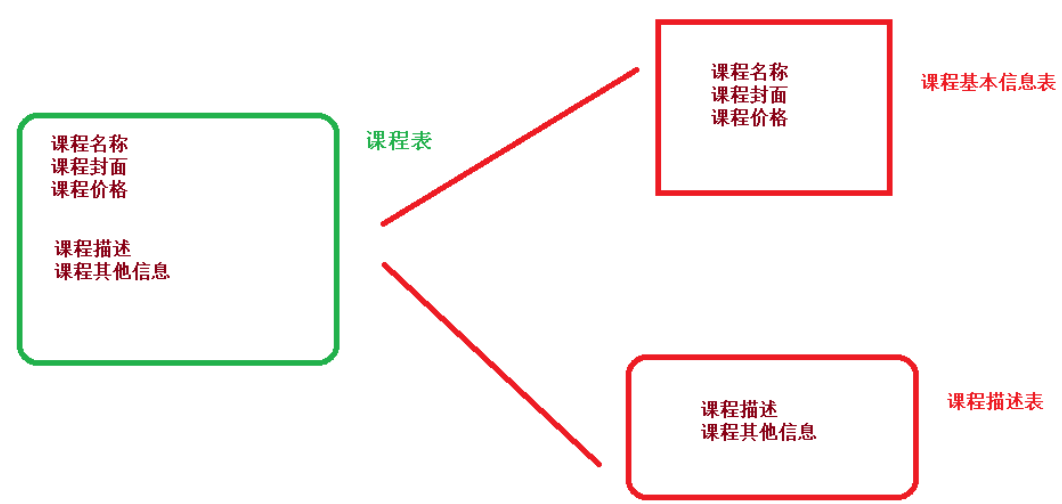
垂直分表
操作数据库中某张表,把这张表中一部分字段数据存到一张新表里面,再把这张表另一部分字段数据存到另外一张表里面
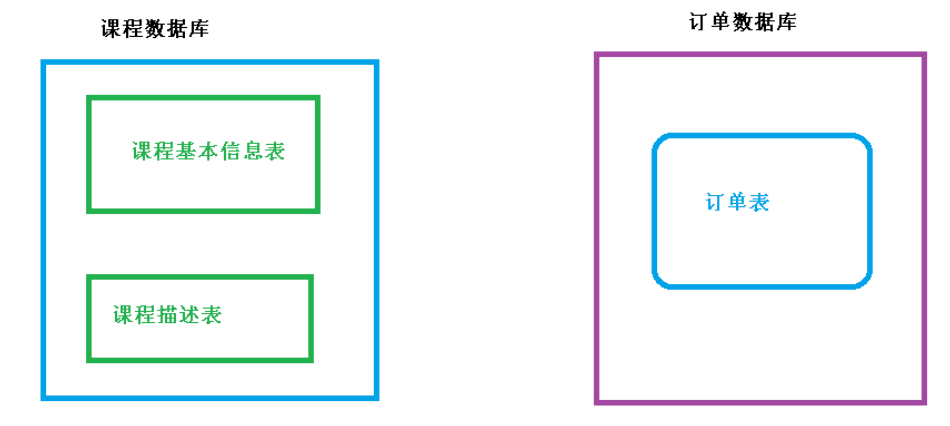
垂直分库
把单一数据库按照业务进行划分,专库专表
垂直切分的优点如下:
-
拆分后业务清晰,系统之间进行整合或扩展很容易。
-
按照成本、应用的等级、应用的类型等奖表放到不同的机器上,便于管理,数据维护简单。
垂直切分的缺点如下:
-
部分业务表无法关联(Join), 只能通过接口方式解决,提高了系统的复杂度。
-
受每种业务的不同限制,存在单库性能瓶颈,不易进行数据扩展和提升性能。
-
事务处理变得复杂。
水平切分
与垂直切分对比,水平切分不是将表进行分类,而是将其按照某个字段的某种规则分散到多个库中,在每个表中包含一部分数据,所有表加起来就是全量的数据。
简单来说,我们可以将对数据的水平切分理解为按照数据行进行切分,就是将表中的某些行切分到一个数据库表中,而将其他行切分到其他数据库表中。
水平分库
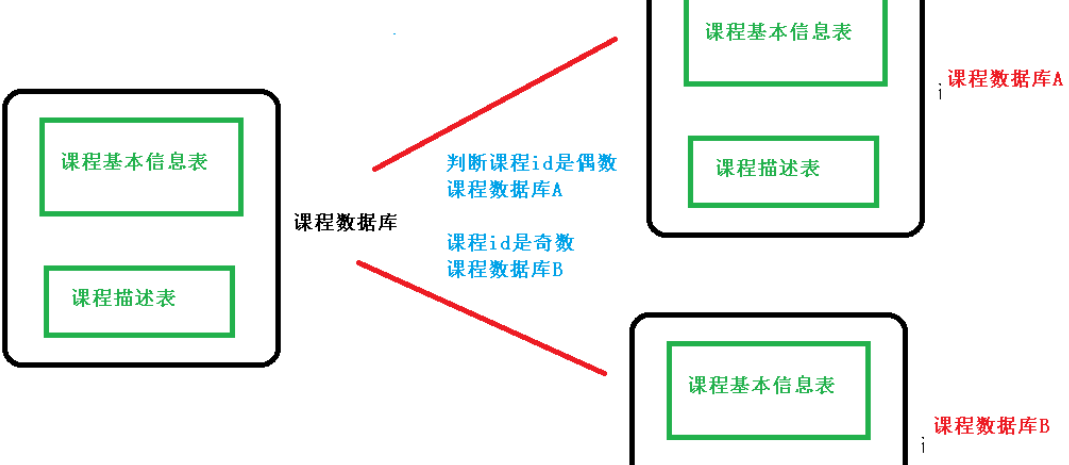
水平分表
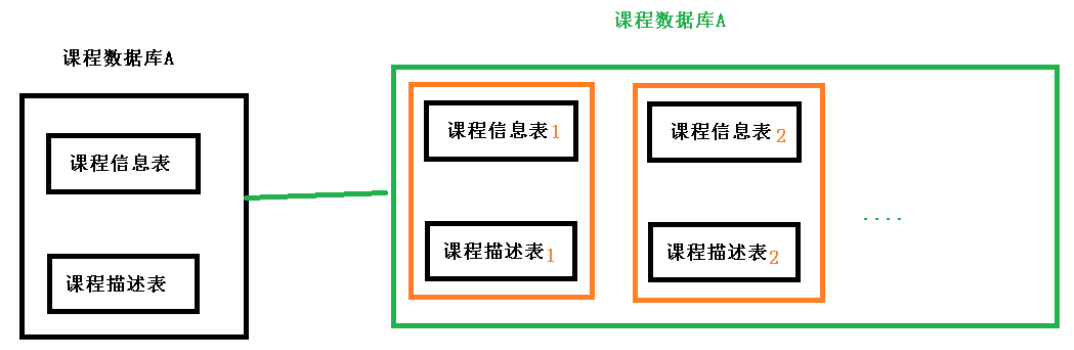
水平切分的优点:
-
单库单表的数据保持在一定的量级,有助于性能的提高。
-
切分的表的结构相同,应用层改造较少,只需要增加路由规则即可。
-
提高了系统的稳定性和负载能力。
水平切分的缺点如下:
-
切分后,数据是分散的,很难利用数据库的 Join 操作,跨库 Join 性能较差。
-
分片事务的一致性难以解决,数据扩容的难度和维护量极大。
分库分表带来的问题
- 存在跨节点 Join 的问题。
- 存在跨节点合并排序、分页的问题。
- 存在多数据源管理的问题
分库分表中间件
目前,国内使用比较多的分库分表的中间件,主要有:
- Apache ShardingSphere
- Mycat
Sharding-JDBC
Sharding-JDBC 是当当网研发的开源分布式数据库中间件,从 3.0 开始 Sharding-JDBC 被包含在 Sharding-Sphere 中,之后该项目进入进入 Apache 孵化器,4.0 版本之后的 版本为 Apache 版本。
Sharding-JDBC 是 ShardingSphere 的第一个产品,也是 ShardingSphere 的前身。 它定 位为轻量级 Java 框架,在 Java 的 JDBC 层提供的额外服务。它使用客户端直连数据库, 以 jar 包形式提供服务,无需额外部署和依赖,可理解为增强版的 JDBC 驱动,完全兼容 JDBC 和各种 ORM 框架。
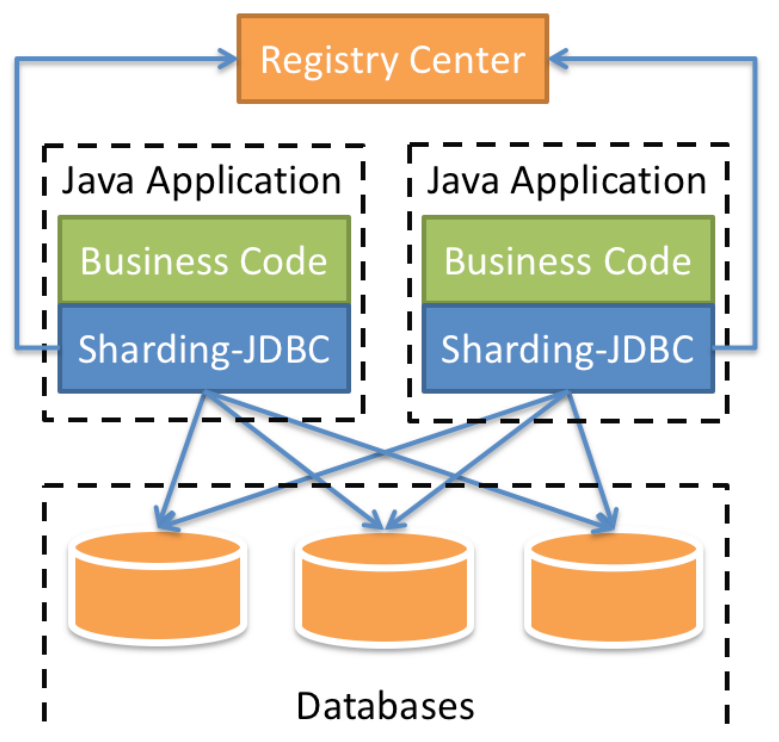
Sharding-JDBC的核心功能为数据分片和读写分离,通过Sharding-JDBC,应用可以透明的使 用jdbc访问已经分库分表、读写分离的多个数据源,而不用关心数据源的数量以及数据如何分布。
- 适用于任何基于 JDBC 的 ORM 框架,如:JPA, Hibernate, Mybatis, Spring JDBC Template 或直接使用 JDBC。
- 支持任何第三方的数据库连接池,如:DBCP, C3P0, BoneCP, Druid, HikariCP 等。
- 支持任意实现 JDBC 规范的数据库。目前支持 MySQL,Oracle,SQLServer, PostgreSQL 以及任何遵循 SQL92 标准的数据库。
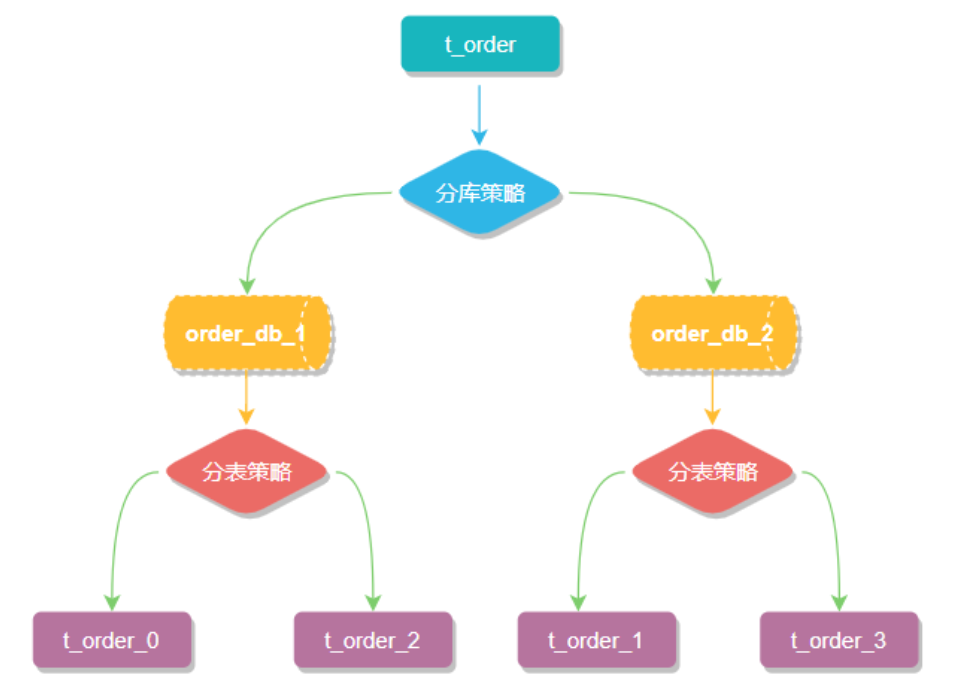
sharding-jdbc实现水平分表
spring:shardingsphere:datasource:# 配置数据源的名称names: ds1ds1:type: com.alibaba.druid.pool.DruidDataSourcedriver-class-name: com.mysql.cj.jdbc.Driverurl: jdbc:mysql://localhost:3306/cloud_user?useUnicode=true&characterEncoding=utf-8&serverTimezone=UTCusername: rootpassword: root# 打开sql输出日志props:sql:show: truesharding:tables:tb_user:# 指定tb_user表的分布情况,配置表在哪个数据库中,表名称是什么actual-data-nodes: ds1.tb_user_$->{1..2}# 指定orders表里主键id生成策略key-generator:column: idtype: SNOWFLAKE# 指定分片策略。根据id的奇偶性来判断插入到哪个表table-strategy:inline:algorithm-expression: tb_user_${id%2+1}sharding-column: id
sharding-jdbc实现水平分库
spring:shardingsphere:datasource:# 配置不同的数据源names: ds1,ds2#配置ds1数据源的基本信息ds1:driver-class-name: com.mysql.cj.jdbc.Drivertype: com.alibaba.druid.pool.DruidDataSourceurl: jdbc:mysql://localhost:3306/cloud_order?useUnicode=true&characterEncoding=utf-8&serverTimezone=UTCusername: rootpassword: root#配置ds2数据源的基本信息ds2:driver-class-name: com.mysql.cj.jdbc.Drivertype: com.alibaba.druid.pool.DruidDataSourceurl: jdbc:mysql://localhost:3306/cloud_user?useUnicode=true&characterEncoding=utf-8&serverTimezone=UTCusername: rootpassword: root#打开sql输出日志props:sql:show: truesharding:tables:tb_order:#指定数据库的分布情况actual-data-nodes: ds$->{1..2}.tb_order_$->{1..2}#指定库分片策略,根据user_id的奇偶性来添加到不同的库中database-strategy:inline:algorithm-expression: ds$->{user_id%2+1}sharding-column: user_id#指定tb_order表的主键生成策略key-generator:column: idtype: SNOWFLAKE#指定表分片策略,根据id的奇偶性来添加到不同的表中table-strategy:inline:algorithm-expression: tb_order_$->{id%2+1}sharding-column: idsharding-jdbc实现垂直分库
相关文章:
【SpringBoot高级篇】SpringBoot集成Sharding-JDBC分库分表
【SpringBoot高级篇】SpringBoot集成Sharding-JDBC分库分表Apache ShardingSphere分库分表分库分表的方式垂直切分垂直分表垂直分库水平切分水平分库水平分表分库分表带来的问题分库分表中间件Sharding-JDBCsharding-jdbc实现水平分表sharding-jdbc实现水平分库sharding-jdbc实…...

Shell特殊字符
shell语言,一些字符是有特殊意义的。 根据作用分为几种特殊符号 一、空白 shell调用函数,不像c语言那样用把参数放到括号里,用逗号分隔。而是用空格作为参数之间,参数与函数名之间的分隔符。 换行符也是特殊字符。换行符用作一条命…...

【计算机二级python】综合题目
计算机二级python真题 文章目录计算机二级python真题一、德国工业战略规划二、德国工业战略规划 第一问三、德国工业战略规划 第二问一、德国工业战略规划 描述:在右侧答题模板中修改代码,删除代码中的横线,填写代码,完成考试答案。…...

字节直播leader面
设计评论系统(缓存怎么做) mysql是否有主从延迟,如何解决 mysql有主从延迟 主从延迟主要因为mysql主从同步的机制,mysql有三种同步机制 同步复制:事务线程等待所有从库复制成功响应异步复制:事务不等待…...

PIC 单片机的时钟
注意:本文的内容无法保证绝对精确,后续可能会做改动,只是自己的笔记。这里的资料均源自数据手册本身。PIC18系列单片机的参考时钟可以选择三个基础时钟源:Primary Clock, OSC1 or OSC2,Secondary Clock,Inner clock.时钟源分为两个…...
【数据结构】关于二叉树你所应该知道的数学秘密
目录 1.什么是二叉树(可以跳过 目录跳转) 2.特殊的二叉树(满二叉树/完全二叉树) 2.1 基础知识 2.2 满二叉树 2.3 完全二叉树 3.二叉树的数学奥秘(主体) 3.1 高度与节点个数 3.2* 度 4.运用二叉树的…...

哈希表题目:猜数字游戏
文章目录题目标题和出处难度题目描述要求示例数据范围解法一思路和算法代码复杂度分析解法二思路和算法代码复杂度分析题目 标题和出处 标题:猜数字游戏 出处:299. 猜数字游戏 难度 4 级 题目描述 要求 你在和朋友一起玩猜数字(Bulls…...
项目请求地址自动加上了本地ip的解决方式
一般情况下来说都是一些粗心大意的问题导致的 场景一:少加了/ 场景二:前后多加了空格 场景三:拼接地址错误
Vue3 企业级项目实战:项目须知与课程约定
本节内容很重要,希望大家能够耐心看完。 Vue3 企业级项目实战 - 程序员十三 - 掘金小册Vue3 Element Plus Spring Boot 企业级项目开发,升职加薪,快人一步。。「Vue3 企业级项目实战」由程序员十三撰写,2744人购买https://s.ju…...

传导EMI抑制-Π型滤波器设计
1 传导电磁干扰简介 在开关电源中,开关管周期性的通断会产生周期性的电流突变(di/dt)和电压突变(dv/dt),周期性的电流变化和电压变化则会导致电磁干扰的产生。 图1所示为Buck电路的电流变化,在Buck电路中上管电流和下…...

如何在excel中创建斐波那契数列
斐波那契数列(Fibonacci sequence),又称黄金分割数列,因数学家莱昂纳多斐波那契(Leonardo Fibonacci)以兔子繁殖为例子而引入,故又称为“兔子数列”,指的是这样一个数列:…...
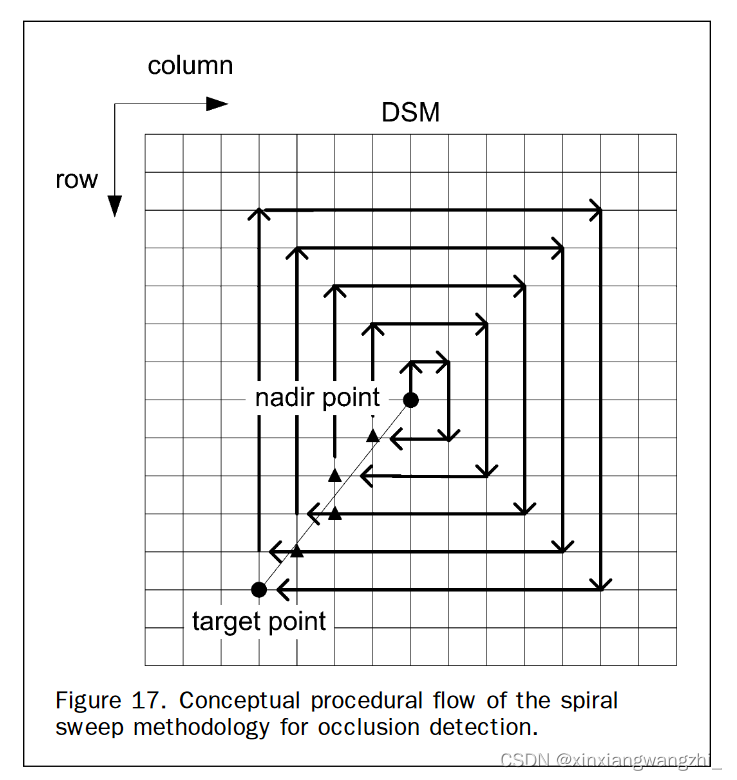
遮挡检测--基于角度的遮挡检测方法
文章目录1基于角度的遮挡检测方法2遮挡检测遍历方法2.1方法1--自适应径向扫描方法2.2方法2--螺旋扫描法参考1基于角度的遮挡检测方法 在基于角度的方法中,通过依次分析DSM中沿径向方向的投影光线的角度来识别遮挡。定义α\alphaα角:DSM三维点与相机中心…...
)
【luogu CF1098D】Eels(结论)
Eels 题目链接:luogu CF1098D 题目大意 有一个可重集,每次操作会放进去一个数或者取出一个数。 然后每次操作完之后,问你对这个集合进行操作,每次选出两个数 a,b 加起来合并回去,直到集合中只剩一个数,要…...
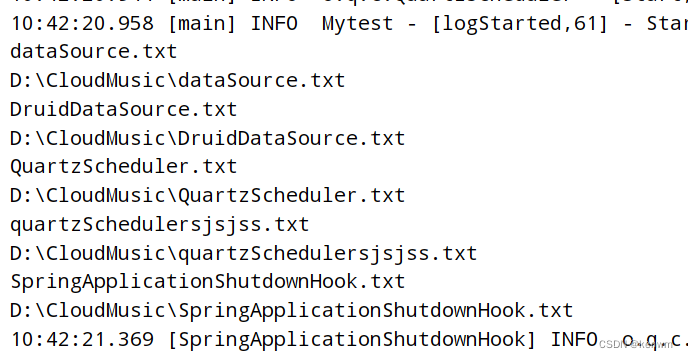
【java】遍历文件夹输出所有文件的文件名与绝对路径,在windows环境
【java】遍历文件夹输出所有文件的文件名与绝对路径,在windows环境 String filepath "D:\\CloudMusic\\";//D盘下的file文件夹的目录File file new File(filepath);//File类型可以是文件也可以是文件夹File[] fileList file.listFiles();//将该目录下的…...
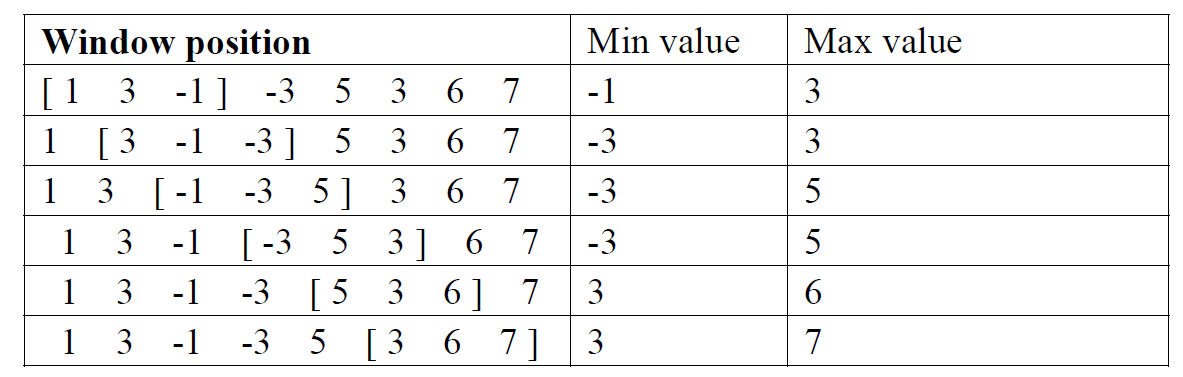
Window问题详解(下)
建议先看一下 Window问题详解(上) 思路② 既然会超时,那该怎么办呢? 显然需要一个更快速的方法来解决这个问题! 我们先来观察一下图片: 我们发现,每一次选中的数都会增加下一个。 !!!!! 因此,我们可以根据此特性优化时间!! 第一次先求出前 k − 1 k-1 k−...

Kafka部署与SpringBoot集成
Kafka与ZooKeeper Apache ZooKeeper是一个基于观察者模式的分布式服务管理框架,即服务注册中心。同时ZooKeeper还具有存储数据的能力。Kafka的每台服务器作为一个broker注册到ZooKeeper,多个broker借助ZooKeeper形成了Kafka集群。同时ZooKeeper会保存一…...
c++11 标准模板(STL)(std::unordered_set)(十三)
定义于头文件 <unordered_set> template< class Key, class Hash std::hash<Key>, class KeyEqual std::equal_to<Key>, class Allocator std::allocator<Key> > class unordered_set;(1)(C11 起)namespace pmr { templ…...

【2023】DevOps、SRE、运维开发面试宝典之ELKStack相关面试题
文章目录 1、elasticsearch的应用场景2、elasticsearch的特点3、Elasticsearch集群三种状态分别是什么?代表什么?4、Elasticsearch集群的优化方面5、Elasticsearch集群防止脑裂的配置参数?6、ELK日志采集平台架构组件介绍?7、Logstash组件的作用?8、收集Kubernetes集群程序…...

Hive中的高阶函数(二)
1、UDTF之explode函数 explode(array)将array列表里的每个元素生成一行; explode(map)将map里的每一对元素作为一行,其中key为一列,value为一列; 一般情况下,explode函数可以直接使用即可,也可以根据需要结…...

Java集合知识点总结
ArrayListLinkedListLinkedHashSetHashSetTreeSetHashTableHashMapTreeMap是否有序有序有序有序无序自然排序(Comparator)进行排序,默认升序使用的是重写comparTo方法无序无序自动排序元素是否为空可为null可为null不允许可为null不允许键允许…...

Cortex-R52性能监控与调试架构深度解析
1. Cortex-R52性能监控单元架构解析在嵌入式实时系统中,性能监控单元(PMU)如同汽车的仪表盘,为开发者提供处理器内部运行状态的实时数据。Cortex-R52的PMU模块采用三级监控架构:1.1 事件采集层处理器内部部署了45个专用硬件计数器,…...

Simulink Function子系统代码生成避坑指南:从Global配置到多输出端口的指针传递
Simulink Function子系统代码生成实战解析:从配置陷阱到高效集成 当你在Simulink中构建复杂算法时,是否遇到过这样的困境——生成的代码难以直接集成到现有系统中?传统的Simulink模型默认生成全局变量和void函数,这在需要精细控制…...

ROS2机械臂实战:ros2_control、moveit2与move_group核心问题排查与解决
1. ROS2机械臂开发中的常见问题与调试思路 最近在做一个ROS2机械臂项目,用到了ros2_control、moveit2和move_group这几个核心组件。说实话,从零开始搭建这套系统踩了不少坑,特别是硬件接口初始化、控制器配置这些环节。今天就把我遇到的一些典…...

如何准备打动评审的物联网与硬件创业技术演讲
1. 从听众到讲者:在EE Live分享你的硬件与物联网洞见如果你是一名电子设计工程师、嵌入式开发者,或者正在硬件创业的浪潮中摸索,那么EE Live这个名字对你来说应该不陌生。这个由EE Times主办的年度盛会,前身是DESIGN West…...

【限时开放】DeepSeek内部调试工具集首次对外披露:含Request ID全链路追踪、模型响应热力图与异常模式识别器
更多请点击: https://intelliparadigm.com 第一章:DeepSeek API接入开发教程 DeepSeek 提供了稳定、高性能的大模型 API 接口,支持文本生成、对话补全与函数调用等多种能力。接入前需在官方控制台申请 API Key,并确保账户已开通对…...

别再只懂BDF了!手把手教你理解PCIe ARI如何将Function数量扩展到256个
突破PCIe传统限制:深入解析ARI如何实现256个功能扩展 在数据中心和云计算架构快速发展的今天,虚拟化技术对硬件资源分配提出了更高要求。传统PCIe设备的8个功能限制已成为制约虚拟功能扩展的瓶颈,特别是在SR-IOV(单根I/O虚拟化&am…...

在Google Cloud上构建OpenAI兼容API网关:无缝对接Vertex AI模型
1. 项目概述:在Google Cloud上搭建你自己的OpenAI兼容API网关 如果你正在寻找一种方法,能够让你手头那些原本为OpenAI ChatGPT设计的应用,无缝对接上Google Cloud Vertex AI的强大模型,比如Gemini Pro、PaLM 2或者Codeyÿ…...

用emWin定时器在STM32上做个简易秒表:从对话框UI到后台逻辑的完整实现
用emWin定时器在STM32上实现高精度秒表:从UI设计到多任务协同的工程实践 在嵌入式GUI开发中,精确的时间控制往往决定着用户体验的成败。当我们需要在STM32平台上实现一个毫秒级响应的秒表应用时,emWin的窗口管理器定时器(WM_TIMER)便成为连接…...

芯片设计公司ISO 9001认证:从质量管理体系到流片成功的工程实践
1. 从一则旧闻聊起:ISO 9001认证对一家芯片设计公司意味着什么?前几天在整理资料时,偶然翻到一篇2011年的行业旧闻,说的是当时一家名为SiliconBlue Technologies的公司,获得了ISO 9001:2008质量管理体系认证。新闻稿写…...

VMware Unlocker 3.0:5分钟快速配置macOS虚拟机终极指南
VMware Unlocker 3.0:5分钟快速配置macOS虚拟机终极指南 【免费下载链接】unlocker VMware Workstation macOS 项目地址: https://gitcode.com/gh_mirrors/unloc/unlocker VMware Unlocker 3.0是一款专为破解VMware限制而设计的开源工具,让您能在…...