04数据平台Flume
Flume 功能

Flume主要作用,就是实时读取服务器本地磁盘数据,将数据写入到 HDFS。
Flume是 Cloudera提供的高可用,高可靠性,分布式的海量日志采集、聚合和传输的系统工具。
Flume 架构
Flume组成架构如下图所示:
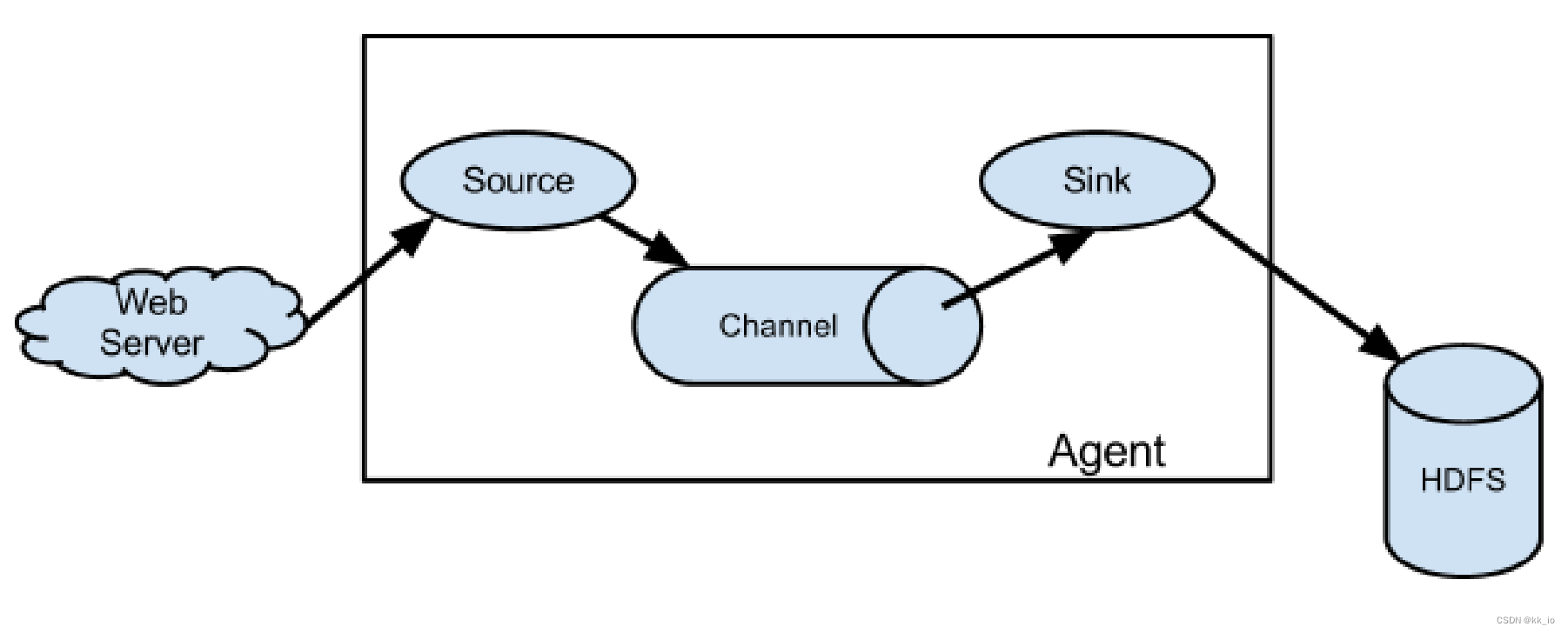
Agent
每个 Agent 代表着一个 JVM 进程,它以事件的方式将数据从源头送至目的地。
Agent 由 3 个部分组成,Source、Channel、Sink。
- Source:Source是负责接收数据到Flume Agent 的组件,Source 组件可以处理各种类型、各种格式的日志数据。
- Sink:Sink不断轮询Channel中的事件并且批量移除他们,并将这些数据批量写入到存储或者索引系统,或被发送到另一个Flume Agent。
- Channel:Channel是位于Source 和Sink 之间的缓冲区。因此,Channel允许 Source和 Sink 有不同的运行速率。Channel 是线程安全的, 可以同时处理几个 Source 的写操作和多个 Sink 的读操作。
Flume自带两种 Channel:Memory Channel 和File Channel。
Memory Channel 是一个内存队列,Source将事件写入其尾部,Sink从其头部读取事件。 Memory Channel 将源写入的事件存储在堆上。由于它将所有数据存储在内存中,因此提供了高吞吐量。 它最适合那些不担心数据丢失的流。 它不适合涉及数据丢失的数据流。
File Channel将所有事件写到磁盘。因此在程序关闭或机器宕机的情况下不会丢失数据。 - Event:Flume 传输数据的基本单元,数据以 Event的形式将数据从源头送至目的地。Event由Header 和 Body 组成,Header用来存放event 的属性,为 K-V结构,Body 用于存放数据,为字节数组结构。
安装 flume
话不多说,直接开始安装 flume。
- 前往 http://archive.apache.org/dist/flume/ , 选择1.9.0
- 将apache-flume-1.9.0-bin.tar.gz使用 sftp上传到linux的/opt/software目录下
- 解压apache-flume-1.9.0-bin.tar.gz到/opt/module/目录下
[logan@hadoop101 hadoop]$ tar -zxf /opt/software/apache-flume-1.9.0-bin.tar.gz -C /opt/module/
- 创建软链接
cd /opt/module
ln -snf flume-1.9.0/ flume
- 删除jar 包,否则会报错
cd /opt/module/flume
rm lib/guava-11.0.2.jar
注意删除guava,一定要配置 Hadoop 环境变量,否则会报错:
Caused by: java.lang.ClassNotFoundException: com.google.common.collect.Listsat java.net.URLClassLoader.findClass(URLClassLoader.java:382)at java.lang.ClassLoader.loadClass(ClassLoader.java:424)at sun.misc.Launcher$AppClassLoader.loadClass(Launcher.java:349)at java.lang.ClassLoader.loadClass(ClassLoader.java:357)... 1 more
- 修改log4j.properties配置文件
[logan@hadoop101 flume]$ vim conf/log4j.properties
# 注意是修改内容
flume.log.dir=/opt/module/flume/logs
- 验证 flume
[logan@hadoop101 flume]$ /opt/module/flume/bin/flume-ng version
Flume 1.9.0
Source code repository: https://git-wip-us.apache.org/repos/asf/flume.git
Revision: d4fcab4f501d41597bc616921329a4339f73585e
Compiled by fszabo on Mon Dec 17 20:45:25 CET 2018
From source with checksum 35db629a3bda49d23e9b3690c80737f9
Flume日志采集
配置解析
需要采集的日志文件分布在hadoop101,hadoop102两台日志服务器,故需要在hadoop101,hadoop102上配置日志采集 Flume。Flume需要采集日志文件内容,并对日志格式(JSON)进行校验,然后将校验通过的日志发送到 Kafka。
此处选择TailDirSource和 KafkaChannel。
- TailDirSource优势:支持断点续传、多目录。
- KafkaChannel优势:省去了 Sink,提高了效率。
- 日志采集 Flume关键配置 :
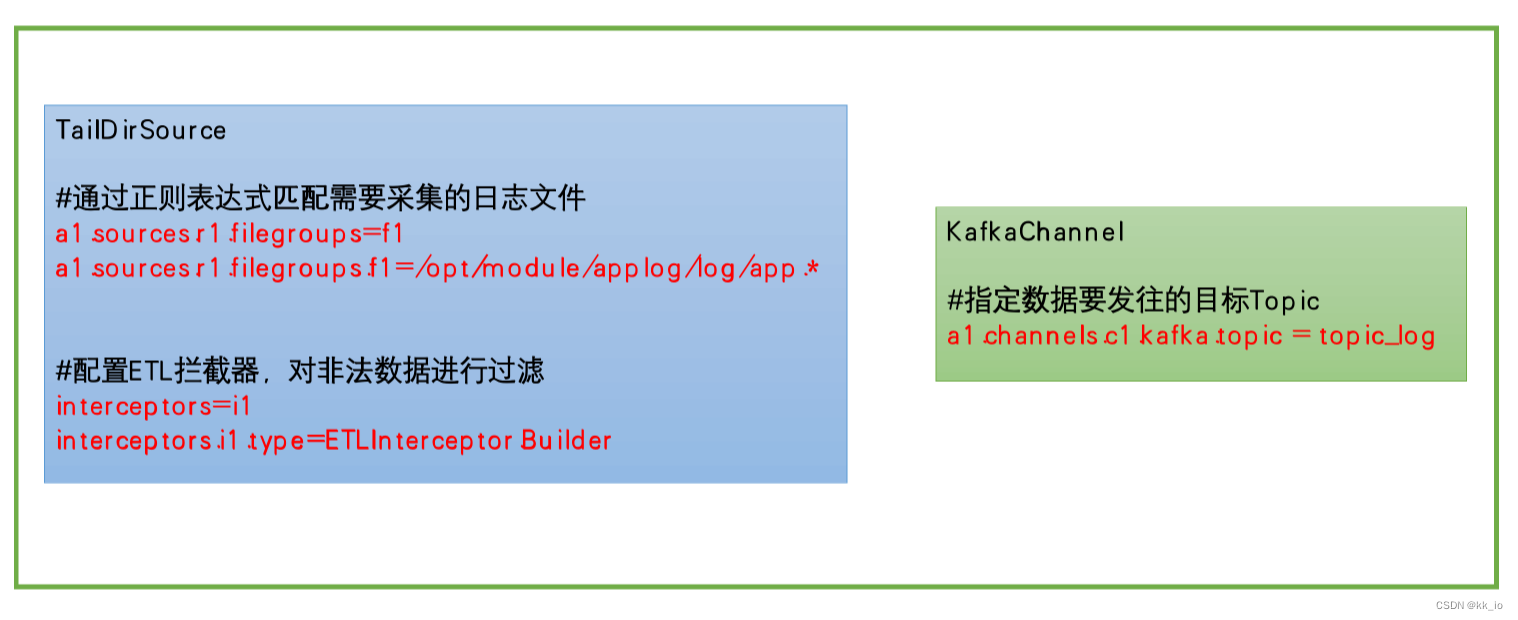
Flume日志采集配置
- 创建Flume 配置文件
[logan@hadoop101 flume]$ pwd
/opt/module/flume
[logan@hadoop101 flume]$ mkdir job
[logan@hadoop101 flume]$ vim job/file_to_kafka.conf
#定义组件
a1.sources = r1
a1.channels = c1#配置source
a1.sources.r1.type = TAILDIR
a1.sources.r1.filegroups = f1
a1.sources.r1.filegroups.f1 = /opt/module/applog/log/app.*
a1.sources.r1.positionFile = /opt/module/flume/taildir_position.json
a1.sources.r1.interceptors = i1
a1.sources.r1.interceptors.i1.type = com.logan.gmall.flume.interceptor.ETLInterceptor$Builder#配置channel
a1.channels.c1.type = org.apache.flume.channel.kafka.KafkaChannel
a1.channels.c1.kafka.bootstrap.servers = hadoop101:9092
a1.channels.c1.kafka.topic = topic_log
a1.channels.c1.parseAsFlumeEvent = false#组装
a1.sources.r1.channels = c1
- 编写拦截器
- 创建Maven工程flume-interceptor
- 创建包:com.logan.gmall.flume.interceptor
- 在pom.xml文件中添加如下配置
<dependencies><dependency><groupId>org.apache.flume</groupId><artifactId>flume-ng-core</artifactId><version>1.9.0</version><scope>provided</scope></dependency><dependency><groupId>com.alibaba</groupId><artifactId>fastjson</artifactId><version>1.2.62</version></dependency> </dependencies><build><plugins><plugin><groupId>org.apache.maven.plugins</groupId><artifactId>maven-compiler-plugin</artifactId><version>2.4</version><configuration><source>1.8</source><target>1.8</target></configuration></plugin><plugin><artifactId>maven-assembly-plugin</artifactId><configuration><descriptorRefs><descriptorRef>jar-with-dependencies</descriptorRef></descriptorRefs></configuration><executions><execution><id>make-assembly</id><phase>package</phase><goals><goal>single</goal></goals></execution></executions></plugin></plugins> </build>- 在com.logan.gmall.flume.utils包下创建JSONUtil类
package com.logan.gmall.flume.utils;import com.alibaba.fastjson.JSON; import com.alibaba.fastjson.JSONException;public class JSONUtil {/*** 通过异常判定是否是JSON字符串*/public static boolean isJSONValidate(String input){try {JSON.parseObject(input);return true;} catch (JSONException e) {return false;}} }- 在com.logan.gmall.flume.interceptor包下创建ETLInterceptor类
package com.logan.gmall.flume.interceptor;import com.logan.gmall.flume.utils.JSONUtil; import org.apache.flume.Context; import org.apache.flume.Event; import org.apache.flume.interceptor.Interceptor;import java.nio.charset.StandardCharsets; import java.util.Iterator; import java.util.List;public class ETLInterceptor implements Interceptor {@Overridepublic void initialize() {}@Overridepublic Event intercept(Event event) {//1、获取body当中的数据并转成字符串byte[] body = event.getBody();String log = new String(body, StandardCharsets.UTF_8);//2、判断字符串是否是一个合法的json,是:返回当前event;不是:返回nullif (JSONUtil.isJSONValidate(log)) {return event;} else {return null;}}@Overridepublic List<Event> intercept(List<Event> list) {Iterator<Event> iterator = list.iterator();while (iterator.hasNext()){Event next = iterator.next();if(intercept(next)==null){iterator.remove();}}return list;}public static class Builder implements Interceptor.Builder{@Overridepublic Interceptor build() {return new ETLInterceptor();}@Overridepublic void configure(Context context) {}}@Overridepublic void close() {} }- 打包
- 将打包文件放到hadoop101 的/opt/moduie/flume/lib文件夹下
采集测试
- 启动Zookeeper、Kafka集群
- 启动 hadoop101上的日志采集Flume
[logan@hadoop101 flume]$ bin/flume-ng agent -n a1 -c conf/ -f job/file_to_kafka.conf -Dflume.root.logger=info,console
- 启动一个Kafka的Console-Consumer
[logan@hadoop101 kafka]$ bin/kafka-console-consumer.sh --bootstrap-server hadoop11:9092 --topic topic_log
- 生成模拟数据
[logan@hadoop101 module]$ mkdir -p /opt/module/applog/log/
[logan@hadoop101 module]$ vim /opt/module/applog/log/app.2023-12-02.log
{"common":{"ar":"500000","ba":"iPhone","ch":"Appstore","is_new":"1","md":"iPhone Xs","mid":"mid_552171","os":"iOS 13.3.1","uid":"919","vc":"v2.1.134"},"displays":[{"display_type":"activity","item":"1","item_type":"activity_id","order":1,"pos_id":5},{"display_type":"activity","item":"2","item_type":"activity_id","order":2,"pos_id":5},{"display_type":"query","item":"19","item_type":"sku_id","order":3,"pos_id":4},{"display_type":"query","item":"3","item_type":"sku_id","order":4,"pos_id":2},{"display_type":"query","item":"5","item_type":"sku_id","order":5,"pos_id":2},{"display_type":"promotion","item":"19","item_type":"sku_id","order":6,"pos_id":4},{"display_type":"query","item":"14","item_type":"sku_id","order":7,"pos_id":2},{"display_type":"query","item":"9","item_type":"sku_id","order":8,"pos_id":2},{"display_type":"promotion","item":"35","item_type":"sku_id","order":9,"pos_id":1}],"page":{"during_time":9853,"page_id":"home"},"ts":1672512476000}
{"actions":[{"action_id":"favor_add","item":"9","item_type":"sku_id","ts":1672512480386},{"action_id":"get_coupon","item":"2","item_type":"coupon_id","ts":1672512483772}],"common":{"ar":"500000","ba":"iPhone","ch":"Appstore","is_new":"1","md":"iPhone Xs","mid":"mid_552171","os":"iOS 13.3.1","uid":"919","vc":"v2.1.134"},"displays":[{"display_type":"promotion","item":"19","item_type":"sku_id","order":1,"pos_id":4},{"display_type":"promotion","item":"14","item_type":"sku_id","order":2,"pos_id":5},{"display_type":"query","item":"21","item_type":"sku_id","order":3,"pos_id":1},{"display_type":"query","item":"11","item_type":"sku_id","order":4,"pos_id":2},{"display_type":"promotion","item":"28","item_type":"sku_id","order":5,"pos_id":1}],"page":{"during_time":10158,"item":"9","item_type":"sku_id","last_page_id":"home","page_id":"good_detail","source_type":"promotion"},"ts":1672512477000}
- 观察kafka是否有消费到数据
相关文章:
04数据平台Flume
Flume 功能 Flume主要作用,就是实时读取服务器本地磁盘数据,将数据写入到 HDFS。 Flume是 Cloudera提供的高可用,高可靠性,分布式的海量日志采集、聚合和传输的系统工具。 Flume 架构 Flume组成架构如下图所示: A…...
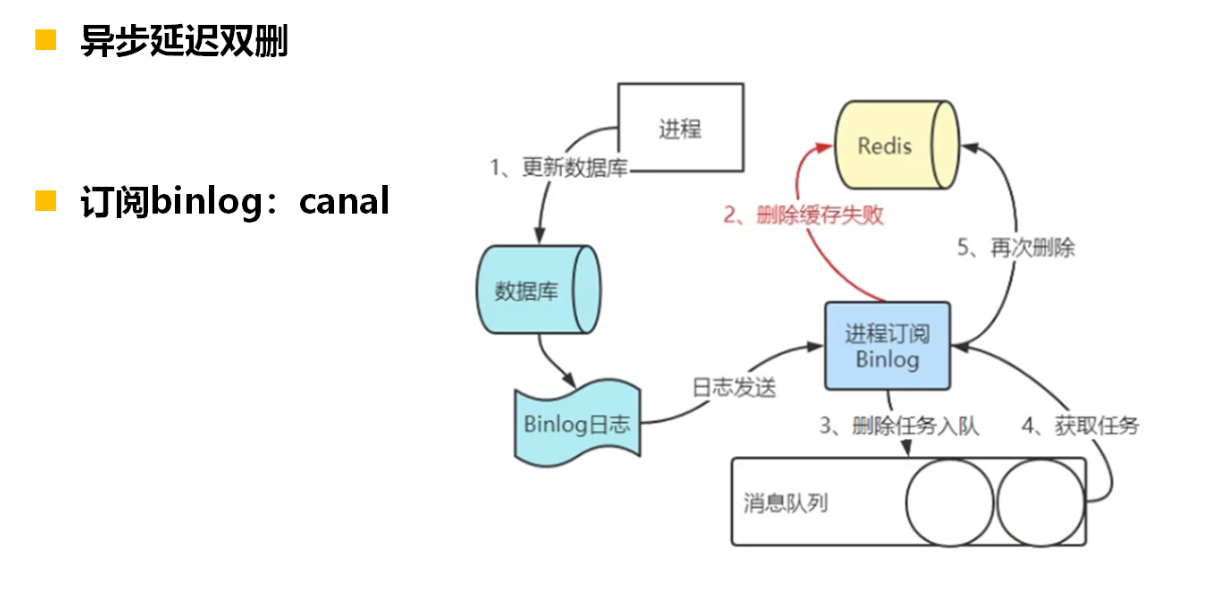
Redis--13--缓存一致性问题
提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档 文章目录 缓存一致性问题1、先更新缓存,再更新DB方案二:先更新DB,再更新缓存方案三:先删缓存,再写数据库推荐1&…...

12.7作业
1. #include "mywidget.h"MyWidget::MyWidget(QWidget *parent): QWidget(parent) {//***********窗口相关设置***********//设置窗体大小this->resize(540,410);this->setFixedSize(540,410);//取消菜单栏this->setWindowFlag(Qt::FramelessWindowHint);/…...

ssl什么是公钥和私钥?
公钥(Public Key)与私钥(Private Key)是通过加密算法得到的一个密钥对(即一个公钥和一个私钥,也就是非对称加密方式)。公钥可对会话进行加密、验证数字签名,只有使用对应的私钥才能解…...
github首次将文件合到远端分支,发现名字不是master,而是main
其中,暂存区和本地仓库的信息都存储在.git目录中 在自己的github上实践 1、刚开始,git clone gitgithub.com:lingze8678/my_github.git到本地 2、在克隆后的代码中加入一个pdf文件 3、在git bash中操作(当项目中有文件更改和删除ÿ…...

RTX 40 系彻底摆烂,NVIDIA 让三年老卡焕发第二春
AMD 前段时间发布的 RX 6750GRE 12/10G 两块新卡属实给了市场一波小小震撼。 有同学要说了,这不就是两年前的 RX 6700 系换皮嘛,典型的旧饭重恰它凭啥能火? 无他,性能合格,价格实惠,主打一个高性价比。 别…...

ELK技术栈介绍及简单使用实例
1. ELK技术栈介绍 引言 在当今数据驱动的世界里,有效地管理和分析大量日志数据变得至关重要。这里我们将深入探讨ELK技术栈,这是一种流行的日志管理解决方案,它结合了三个开源项目:Elasticsearch、Logstash和Kibana。ELK技术栈因…...

基于Java健身房课程管理系统
基于Java健身房课程管理系统 功能需求 1、课程信息管理:系统需要能够记录和管理所有课程的详细信息,包括课程名称、教练信息、课程时间、课程地点、课程容量等。管理员和教练可以添加、编辑和删除课程信息。 2、会员信息管理:系统需要能够…...
DAPP开发【02】Remix使用
系列文章目录 系列文章在DAPP开发专栏 文章目录 系列文章目录使用部署测试网上本地项目连接remix本地项目连接remix 使用 创建一个新的工作空间 部署测试网上 利用metaMask连接测试网络 添加成功,添加时需要签名 即可进行编译 即可部署 本地项目连接remix 方…...
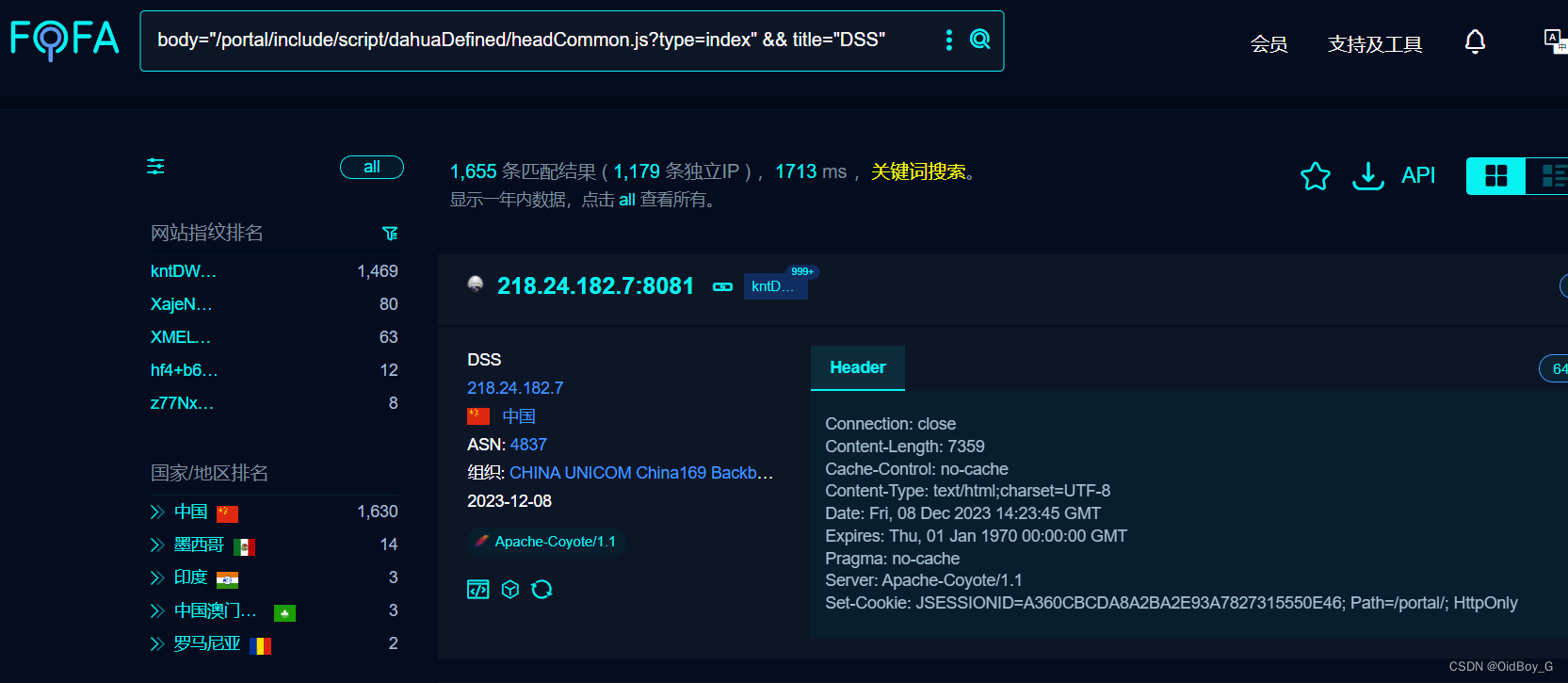
大华DSS S2-045 OGNL表达式注入漏洞复现
0x01 产品简介 大华DSS安防监控系统平台是一款集视频、报警、存储、管理于一体的综合安防解决方案。该平台支持多种接入方式,包括网络视频、模拟视频、数字视频、IP电话、对讲机等。此外,该平台还支持多种报警方式,包括移动侦测、区域入侵、越线报警、人员聚集等。 0x02 漏…...
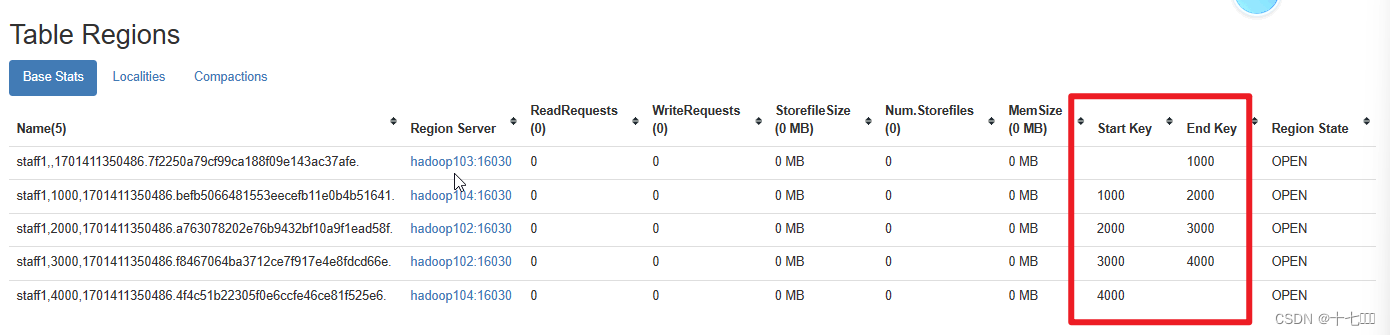
大数据之HBase(二)
Master详细架构 位置:namenode实现类:HMaster组成 负载均衡器:通过meta了解region的分配,通过zk了解rs的启动情况,5分钟调控一次分配平衡元数据表管理器:管理自己的预写日志,如果宕机ÿ…...

前后端数据传输格式(下)
作者简介:大家好,我是smart哥,前中兴通讯、美团架构师,现某互联网公司CTO 联系qq:184480602,加我进群,大家一起学习,一起进步,一起对抗互联网寒冬 上篇主要复习了HTTP以及…...

mysql pxc高可用离线部署(三)
pxc学习流程 mysql pxc高可用 单主机 多主机部署(一) mysql pxc 高可用多主机离线部署(二) mysql pxc高可用离线部署(三) mysql pxc高可用 跨主机部署pxc 本文使用docker进行安装,主机间通过…...

XXL-JOB 日志表和日志文件自动清理
🚀 作者主页: 有来技术 🔥 开源项目: youlai-mall 🍃 vue3-element-admin 🍃 youlai-boot 🌺 仓库主页: Gitee 💫 Github 💫 GitCode 💖 欢迎点赞…...

常用sql记录
备份一张表 PostgreSQL CREATE TABLE new_table AS SELECT * FROM old_table;-- 下面这个比上面好,这个复制表结构时,会把默认值、约束、注释都复制 CREATE TABLE new_table (LIKE old_table INCLUDING ALL) WITHOUT OIDS; INSERT INTO new_table SELE…...
设备温度和振动综合监测:温振一体式传感器的优点和应用
随着工业设备的复杂性和自动化程度的提高,对设备状态监测的需求也日益增加。温振一体式传感器作为一种集振动和温度监测于一体的传感器,具备多项优势,因此在工业设备状态监测领域得到广泛应用。 温振一体式传感器基于振动传感器和温度传感器的…...
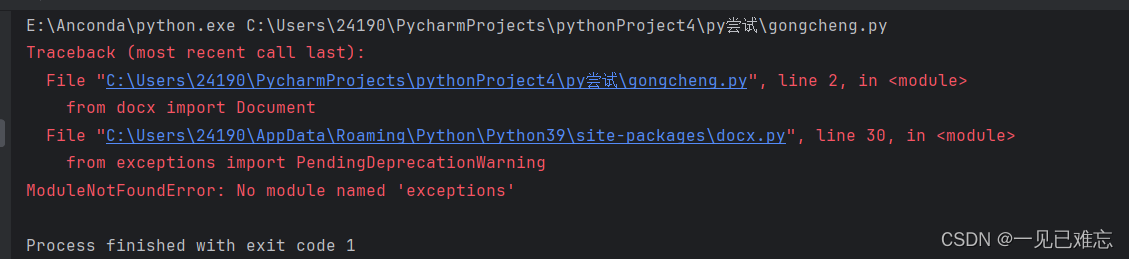
彻底解决ModuleNotFoundError: No module named ‘exceptions‘【Bug完美解决】
文章目录 项目场景:问题描述原因分析:解决方案:此Bug解决方案总结心得项目场景: 根据本文可找到bug原因并彻底解决**ModuleNotFoundError: No module named ‘exceptions‘**Bug 报错: E:\Anconda\python.exe c:\Users\24190\PycharmProjects\pythonProject4py尝试 gong…...

yarn和npm的区别
2023-12-8 yarn和npm的区别 是常用的包管理工具,用于node.js项目中安装、管理、和更新依赖项 有以下几个区别: 性能和速度:在包的安装和下载方面,yarn比npm更快速,yarn通过并行下载和缓存等优化策略,可以…...

设计图中时序图
设计图中的时序图通常用于展示两个或多个对象之间的交互和消息传递的顺序。它是一种用于描述软件或系统中的并发性和时序行为的工具。 以下是一个简单的时序图的示例: 首先,在时序图中创建两个对象,例如"对象A"和"对象B&quo…...
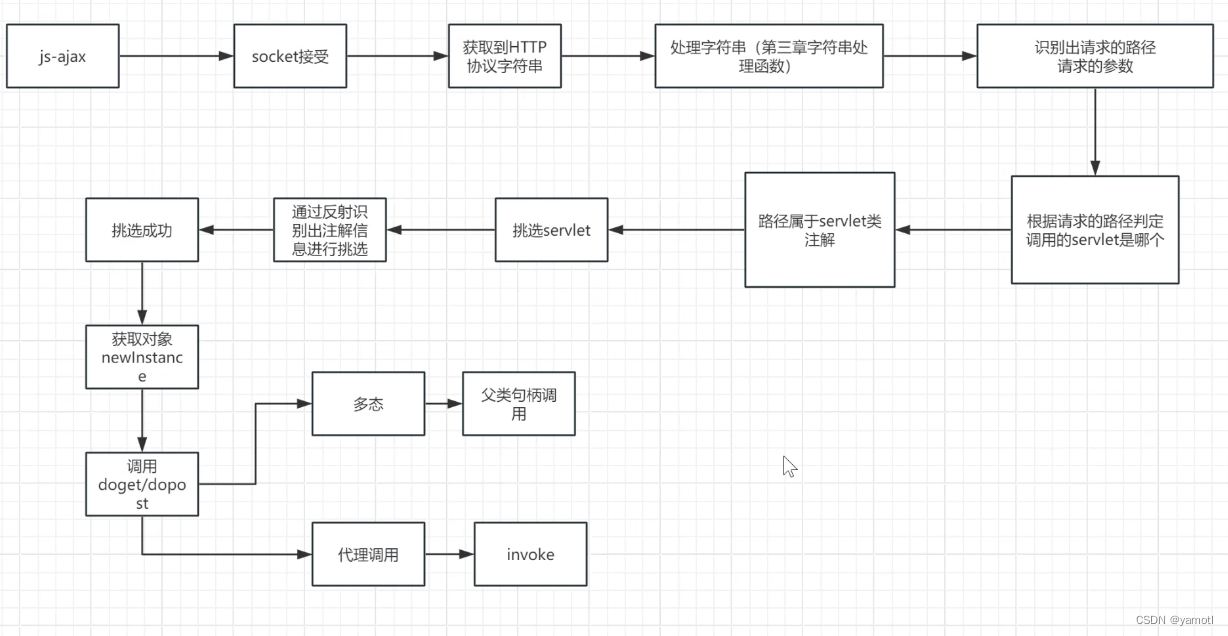
反射实现tomcat
获取类信息的方法 1.通过类对象 x.getClass() 2.通过class.forname方法 Class.forname(className);这里className是存储类名的字符串 3.通过类名.class 类名.class 通过类名创建对象 类名.newInstance(); 反射可以看到类的一切信息࿱…...

对比直接调用与通过聚合平台调用大模型的体验差异
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 对比直接调用与通过聚合平台调用大模型的体验差异 作为一名需要频繁使用多种大语言模型的开发者,我曾长期维护着来自不…...

TPS65131模块实战:单电源生成正负双电压的工程指南
1. 项目概述与核心需求解析在模拟电路、音频设备乃至一些复古的数字逻辑电路里,正负双电源轨是一个绕不开的话题。无论是给运算放大器供电,为LCD屏幕提供偏置电压,还是驱动某些老式合成器模块,你常常需要同时拥有一个正电压和一个…...

Python 开发者五分钟接入 Taotoken 调用 GPT 与 Claude 模型指南
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 Python 开发者五分钟接入 Taotoken 调用 GPT 与 Claude 模型指南 对于习惯使用 OpenAI 官方 Python SDK 的开发者来说,…...

【模拟 IC】运放失调电压的成因剖析与版图优化策略
1. 运放失调电压的本质与影响 第一次接触运放失调电压这个概念时,我也被它搞得一头雾水。简单来说,失调电压就是理想运放和实际运放之间的"性格差异"。理想情况下,当两个输入端电压相等时,输出应该是零。但现实中&#…...

从CTF逆向到软件分析:用z3-solver自动化求解约束方程
1. 为什么我们需要z3-solver? 第一次参加CTF比赛时,我遇到一道逆向题,需要解一个包含30多个变量的方程组。当时我花了整整两天时间手工计算,最后还是没能解出来。赛后才知道,原来可以用z3-solver在几分钟内自动求解。这…...

3步打造专业静态服务器:http-server零配置部署全攻略
3步打造专业静态服务器:http-server零配置部署全攻略 【免费下载链接】http-server A simple, zero-configuration, command-line http server 项目地址: https://gitcode.com/gh_mirrors/ht/http-server 你是否曾在本地开发时,为预览静态页面而反…...
【限时技术白皮书】ElevenLabs藏文模型权重结构首度曝光:Transformer Decoder层中Tibetan Syllable Tokenization模块详解
更多请点击: https://intelliparadigm.com 第一章:ElevenLabs藏文语音生成技术全景概览 ElevenLabs 作为全球领先的文本到语音(TTS)平台,目前尚未官方支持藏文(བོད་སྐད་)语音合成。其公…...
那点事儿)
从激光雷达到智能家居:深入浅出聊聊激光安全分类(Class 1/2/3/4)那点事儿
从激光雷达到智能家居:深入浅出聊聊激光安全分类(Class 1/2/3/4)那点事儿 激光技术正悄然渗透进我们生活的每个角落——从自动驾驶汽车的"眼睛"到智能门锁的指纹识别,从工业切割到医疗美容,这些看似毫不相关…...

深度解析AI模型Docker镜像:从DeepSeek部署到生产级容器化实践
1. 项目概述:一个AI模型镜像的深度解构最近在社区里看到不少朋友在讨论dirk1983/deepseek这个Docker镜像,作为一个长期在AI工程化和容器化部署一线摸爬滚打的从业者,我觉得有必要来聊聊这个看似简单的镜像背后,究竟藏着哪些门道。…...

告别硬盘数据丢失焦虑!电脑专属5种恢复方法,无踩坑,速存
日常使用电脑时,文件误删是高频突发状况——辛苦整理的办公文档、珍藏的生活影像、重要的程序安装包,一旦不小心删除,难免让人手足无措。好在2026年,随着数据存储技术的迭代与恢复工具的升级,电脑误删文件的恢复成功率…...