ES通过抽样agg聚合性能提升3-5倍
一直以来,es的agg聚合分析性能都比较差(对应sql的 group by)。特别是在超多数据中做聚合,在搜索的条件命中特别多结果的情况下,聚合分析会非常非常的慢。一个聚合条件:聚合分析请求的时间 = search time + agg timeN个聚合条件:聚合分析请求的时间 = search time + agg time * N搜索的数据范围越大,聚合请求时间越长。搜索条件命中的数据越多,聚合请求的时间越长。搜索的字段,不一样的值越多,聚合请求时间越长。例如性别字段,通常仅有3个取值(男、女、未知),这种属于取值少的。像邮箱字段,值非常多,上亿个。这种就属于高基数字段。同样的搜索条件,高基数字段的聚合耗时会多非常多!聚合请求时候非常吃cpu 和io资源的。通常在大数据检索场景下,很难支持高并发的聚合。并发上去以后,先是CPU飙升,再是IO飙升,随之load很高很高。其根本原因,从agg聚合的源码来看。因为聚合请求分为两个阶段,先根据条件查询数据。然后将命中的全部数据,放在内存中做计算。在第二个过程中,因为将所有命中的数据全部取回来,然后做计算,就涉及到了非常多的小文件的IO。IO会蹭蹭蹭的飙升。就目前而言,在不改源码的情况下,聚合性能很难有很大的突破。本篇文章,通过抽样的思路,通过抽取分片,相当于数据剪枝的方式,来节省资源消耗。提升聚合分析性能,提升大概在3-5倍。随着数据越多,分片越多,资源越少,性能提升效果越明显。
我个人是做万亿级内容数据检索的。负责搜索集群,负责搜索优化。聚合分析性能优化,我应该说已经看了全网关于优化的文章。在实际数据体量非常大的前提下,实际效果不是太明显。其中比较好的有这几篇文章。es官方博文Improving the performance of high-cardinality terms aggregations in Elasticsearch | Elastic BlogElasticsearch 聚合性能优化六大猛招-腾讯云开发者社区-腾讯云Elasticsearch聚合优化 | 聚合速度提升5倍_es聚合速度-CSDN博客
抽样聚合方案
1.es原生抽样聚合
官方提供的采样聚合
参考文档:Sampler aggregation | Elasticsearch Guide [7.11] | Elastic
ES中的抽样聚合,意思是只对高质量的数据做聚合。比如,指定搜索条件,该搜索条件命中的数据为100W,对这100W数据,根据相关性分数排序。然后对这topK的数据做聚,比如每个shard上取200条评分最高的数据,去聚合。这就是ES sampler aggregation的含义。
2.es pre-filter机制
参考文档:Elasticsearch的search之_shards skipped之谜_布道的博客-CSDN博客__shards skipped
3.es在检索过程中指定分片
GET index_name/_search?preference=_shards:0
抽样抽分片的思路,只每次固定只检测其中一个分片。例如我们的索引一共300G,每个分片30G,一共有10个分片。在检索的过程中,只对其中一个分片做检索和聚合。其最终的聚合结果,根据我们的测试来看,效果还是非常不错的。聚合结果的分布情况和本来的terms聚合相差不大。性能也能提升个几倍。注意这种方式,聚合结果是近似的,并不是完全准确的(ES本身的聚合解结果就不是100%精准的)。
在大数据随机分布的情况下。在搜索命中大量数据情况下,其结果分布也是满足正态分布的。注意在搜索结果命中的结果集越多,其结果越符合正态分布,其聚合结果越接近标准值(原生terms聚合)。这里有一个值,一个经验值,在搜索提交条件命中大于10000的时候,可以用抽样,结果偏差不大。
注意,这里具体抽哪一个分片是有说法的。我们要考虑一个问题,同一个搜索条件,聚合结果应该是一致的。这里可以将搜索条件进行md5,然后取hash值,然后将hash值模上分片总数。这里只是一个思路。
ES官方的抽样聚合说明
抽样方案对比测试
对比测试了三种聚合分析的方式,其中包含了terms、sampler terms、和shard抽样(假如有10个shard,只对其中一个shard做搜索)
先说测试结论
官方的抽样,召回的结果和标准结果偏差较大。
官方的抽样,时间花费上,并没有太大的提升。
抽取分片,召回的结果和标准结果偏差不大。
抽取分片,时间花费上,性能提升3-5倍。资源花费为分片总数分之一。
响应时间对比如下
| 检索范围 | 检索条件 | 查询语法 | 响应时间 | 备注 |
| major_index_202303 | (北京 AND 暴雨) | terms | 4561 7694 | |
| shard抽样 | 1423 2785 | 效果最好 | ||
| terms sampler | 5650 3663 | 效果没有太明显 |
召回结果对比如下
| 关键词 | terms(结果) | 抽取一个分片 | sampler terms(抽样200) | 备注 |
| 地区 | 4224 | 446 | 2094 | |
| 中国 | 3772 | 375 | - | |
| 发展 | 3605 | 342 | - | |
| 天气 | 3503 | 378 | 1942 | |
| 部分 | 2781 | 294 | 1525 | |
| 大雨 | 2395 | 236 | - | |
| 暴雨 | 2394 | 264 | 2454 | |
| 气温 | 2079 | 212 | 915 | |
| 局地 | 1851 | 199 | 1055 | |
| 工作 | 1741 | 187 | - | |
| 降雨 | - | - | 1111 | |
| 北京 | - | - | 827 | |
| 巴西 | - | - | 801 | |
| 灾害 | - | - | 801 |
检索语句
这里使用的是query_string 检索语法。对比标准的terms聚合,官方的simple抽样,和抽分片。
"query": {"query_string": {"query": """北京 AND 暴雨""","fields": ["content^1.0","title^1.0"],"type": "phrase","tie_breaker": 1,"default_operator": "and","max_determinized_states": 10000,"enable_position_increments": true,"fuzziness": "AUTO","fuzzy_prefix_length": 0,"fuzzy_max_expansions": 50,"phrase_slop": 0,"escape": false,"auto_generate_synonyms_phrase_query": true,"fuzzy_transpositions": true,"boost": 1}}
全部测试结果原始数据
| 搜索范围 | 搜索条件 | 聚合方式 | 耗时情况ms | 返回结果 |
| major_info_202303 | (北京 AND 暴雨) | terms | 4561 7694 | [ { "key" : "地区", "doc_count" : 4224 }, { "key" : "中国", "doc_count" : 3772 }, { "key" : "发展", "doc_count" : 3605 }, { "key" : "天气", "doc_count" : 3503 }, { "key" : "部分", "doc_count" : 2781 }, { "key" : "大雨", "doc_count" : 2395 }, { "key" : "暴雨", "doc_count" : 2394 }, { "key" : "气温", "doc_count" : 2079 }, { "key" : "局地", "doc_count" : 1851 }, { "key" : "工作", "doc_count" : 1741 } ] |
| terms sampler | 5650 3663 | [ { "key" : "暴雨", "doc_count" : 2454 }, { "key" : "地区", "doc_count" : 2094 }, { "key" : "天气", "doc_count" : 1942 }, { "key" : "部分", "doc_count" : 1525 }, { "key" : "降雨", "doc_count" : 1111 }, { "key" : "局地", "doc_count" : 1055 }, { "key" : "气温", "doc_count" : 915 }, { "key" : "北京", "doc_count" : 827 }, { "key" : "巴西", "doc_count" : 801 }, { "key" : "灾害", "doc_count" : 801 } ] | ||
| terms + 指定shard | 1423 2785 | [ { "key" : "地区", "doc_count" : 446 }, { "key" : "天气", "doc_count" : 378 }, { "key" : "中国", "doc_count" : 375 }, { "key" : "发展", "doc_count" : 342 }, { "key" : "部分", "doc_count" : 294 }, { "key" : "暴雨", "doc_count" : 264 }, { "key" : "大雨", "doc_count" : 236 }, { "key" : "气温", "doc_count" : 212 }, { "key" : "局地", "doc_count" : 199 }, { "key" : "工作", "doc_count" : 187 } ] |
相关文章:
ES通过抽样agg聚合性能提升3-5倍
一直以来,es的agg聚合分析性能都比较差(对应sql的 group by)。特别是在超多数据中做聚合,在搜索的条件命中特别多结果的情况下,聚合分析会非常非常的慢。 一个聚合条件:聚合分析请求的时间 search time a…...
c++详解栈
一.什么是栈 堆栈又名栈(stack),它是一种运算受限的数据结构(线性表),只不过他和数组不同,数组我们可以想象成一个装巧克力的盒子,你想拿一块巧克力,不需要改变其他巧克…...
Zabbix结合Grafana打造高逼格监控系统
📢📢📢📣📣📣 哈喽!大家好,我是【IT邦德】,江湖人称jeames007,10余年DBA及大数据工作经验 一位上进心十足的【大数据领域博主】!😜&am…...

Linux设备树
一、起源 减少垃圾代码 减轻驱动开发工作量 驱动代码和设备信息分离 参考Open Fireware设计 用来记录硬件平台中各种硬件设备的属性信息 二、基本组成 两种源文件: xxxxx.dts dts是device tree source的缩写xxxxx.dtsi dtsi是device tree source include的缩…...
计算机方向的一些重要缩写和简介
参考: 深度学习四大类网络模型 干货|机器学习超全综述! 机器学习ML、卷积神经网络CNN、循环神经网络RNN、马尔可夫蒙特卡罗MCMC、生成对抗网络GAN、图神经网络GNN——人工智能经典算法 MLP(Multi Layer Perseption)用在神经网络中…...
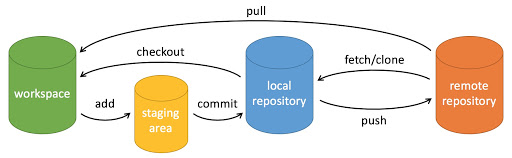
ardupilot开发 --- git 篇
一些概念 工作区:就是你在电脑里能看到的目录;暂存区:stage区 或 index区。存放在 :工作区 / .git / index 文件中;版本库:本地仓库,存放在 :工作区 / .git 中 关于 HEAD 是所有本地…...
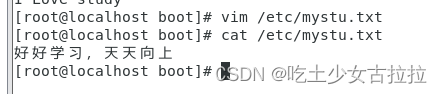
Linux基础命令练习2
案例2:创建命令练习 请在/root创建三个目录分别为student、file、stu18 请在/opt创建三个文本文件分别为1.txt、a.txt、stu.txt 案例3:复制、删除、移动 在目录/opt下创建一个子目录 etime 在目录/opt/etime/创建文件readme.txt,利用vim写入内容 …...

Vue阶段笔记(有js包)
目录 1.要先上传Vue的js包,包的路径在这: 2.获取 3.定义Vue接管的区域和他所要实现的内容 #整体代码如下: Vue的指令(被绑定得必须有声明) #v-bind #v-model #v-on #V-ifV-else-ifV-elseV-show #v-show #v-for 1.要先上传Vue的js包&…...

执行npm run dev报Error: error:0308010C:digital envelope routines::unsupported问题
vue2element-ui项目,在执行npm run dev的时候突然报错: (node:19424) [DEP0111] DeprecationWarning: Access to process.binding(http_parser) is deprecated. (Use node --trace-deprecation ... to show where the warning was created) Er…...

解决微信小程序中 ‘nbsp;‘ 空格不生效的问题
在微信小程序开发中,我们经常会使用 来表示一个空格。这是因为在 HTML 中,空格会被解析为一个普通字符,而不会产生实际的空白间距。而 是一种特殊的字符实体,它被解析为一个不可见的空格,可以在页面上产生真正的空…...

vue el-select封装及使用
基于Element UI的el-select组件进行封装的。该组件实现了一个下拉选择框,具有许多可配置的属性和事件 创建组件index.vue (src/common-ui/select/index.vue) <template><el-selectref"select"v-model"hValue":allow-create"allo…...

了解linux计划任务
本章主要介绍如何创建计划任务 使用 at 创建计划任务 使用 crontab 创建计划任务 有时需要在某个指定的时间执行一个操作,此时就要使用计划任务了。计划任务有两种: 一个是at计划任务,另一个是 crontab计划任务。 下面我们分别来看这两种计…...

等待和通知
引入 由于线程是抢占式执行的,因此线程之间的执行的先后顺序难以预知 但是实际开发中我们希望合理协调多个线程之间执行的先后顺序. 这里的干预线程先后顺序,并不是影响系统的调度策略(内核里调度线程,仍然是无序调度). 就是相当于在应用程序代码中,让后执行的线程主动放弃被…...
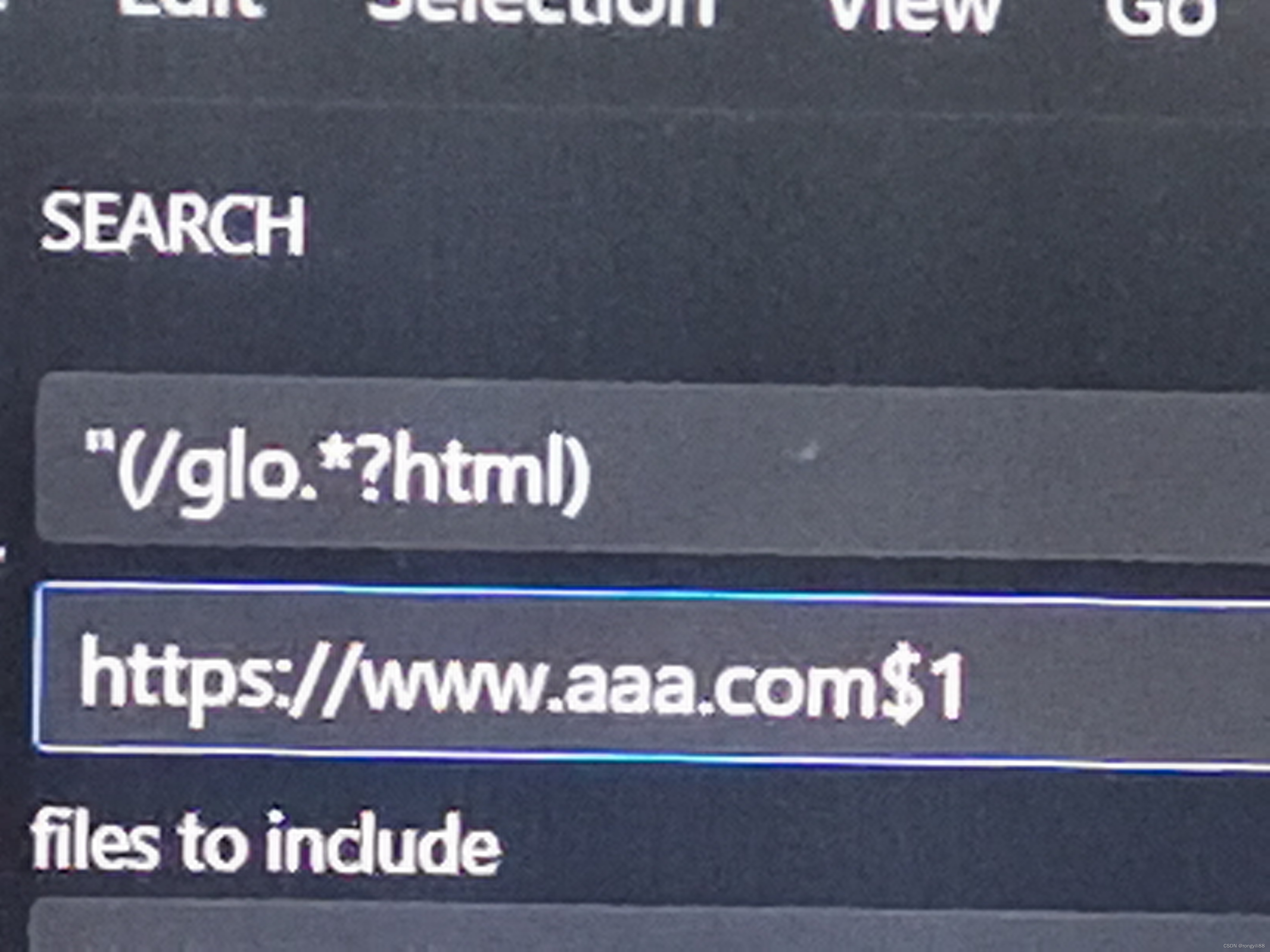
vscode 如何将正则匹配到的字符前批量加字符
最近想用vscode将正则匹配到的东西签名批量https,替换时可以用$1来替换正则匹配到的字符串,如下所示...

上个月暴涨34.6%后,SoundHound AI股票现在还能买入吗?
来源:猛兽财经 作者:猛兽财经 揭开SoundHound AI股价波动的原因 S&P Global Market Intelligence的数据显示,在摆脱了10月份的大幅下跌后,SoundHound AI的股价在11月份实现了34.6%的涨幅。 原因是该公司公布了稳健的第三季…...
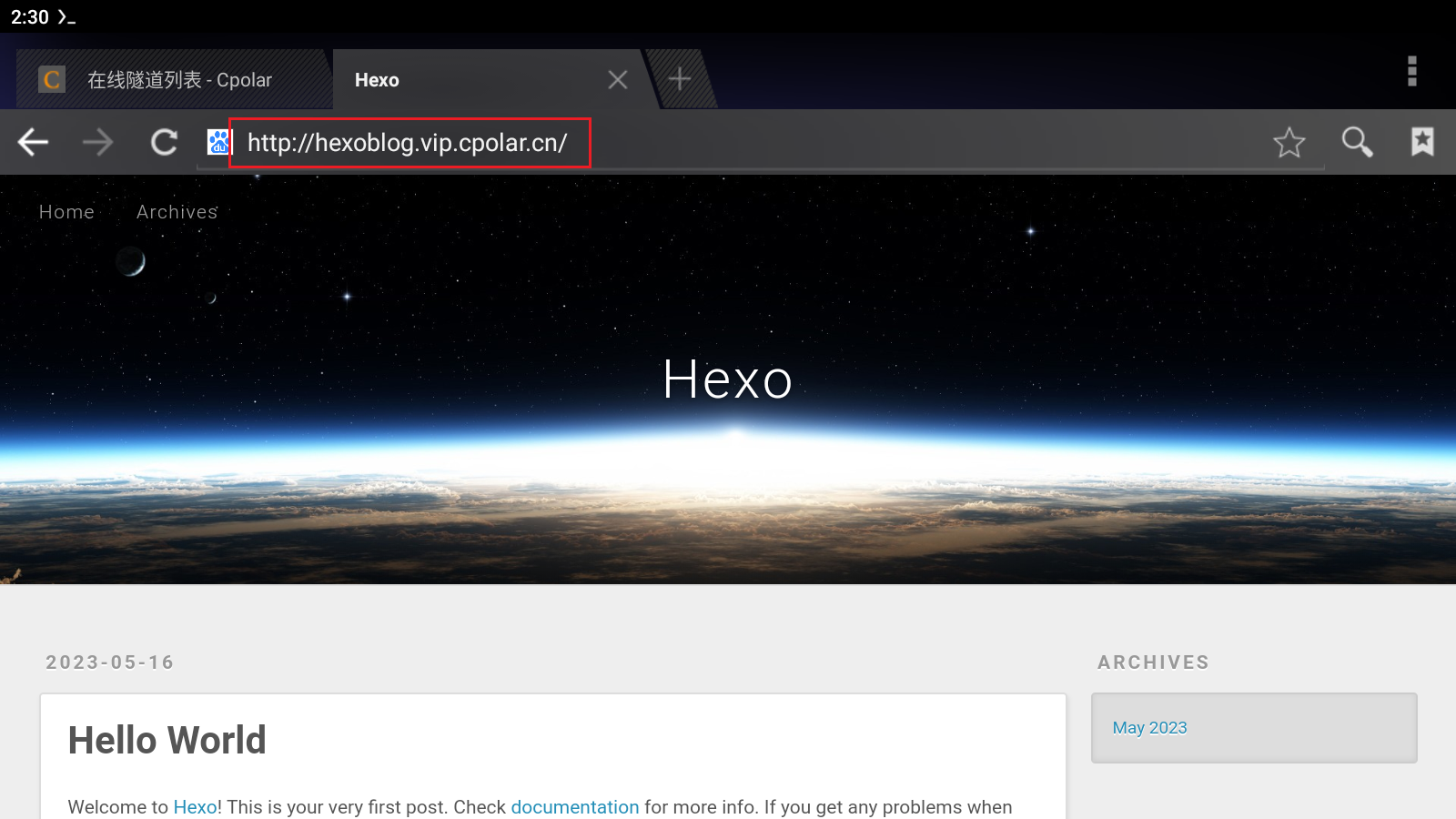
Termux+Hexo结合内网穿透轻松实现安卓手机搭建博客网站发布公网访问
文章目录 前言 1.安装 Hexo2.安装cpolar3.远程访问4.固定公网地址 前言 Hexo 是一个用 Nodejs 编写的快速、简洁且高效的博客框架。Hexo 使用 Markdown 解析文章,在几秒内,即可利用靓丽的主题生成静态网页。 下面介绍在Termux中安装个人hexo博客并结合…...

程序员的养生指南(生命诚可贵,一人永流传!珍惜生命,从你我做起)
作为程序员,我们经常需要长时间坐在电脑前工作,这对我们的身体健康造成了很大的影响。为了保持健康,我们需要采取一些养生措施来延寿。下面是我个人的一些养生经验和建议,希望能对大家有所帮助。 1、合理安排工作时间:…...

FP独立站怎么搭建?看这一篇就够了!强烈建议收藏!
在2023疫情结束年,商家为了在跨境电商市场上获取更多的份额,FP建站需求大军席卷而来,越来越多的创业者和企业开始涉足跨境电商独立站领域,尤其是FP独立站,FP商家想要通过FP独立站、FP广告投放,FP支付&#…...

【华为OD题库-068】找出经过特定点的路径长度-java
题目 输入一个字符串,都是以大写字母组成,每个相邻的距离是1,第二行输入一个字符串,表示必过的点。 说明 每个点可过多次。求解经过这些必过点的最小距离是多少? 示例1 输入输出示例仅供调试,后台判题数据一般不包含示…...
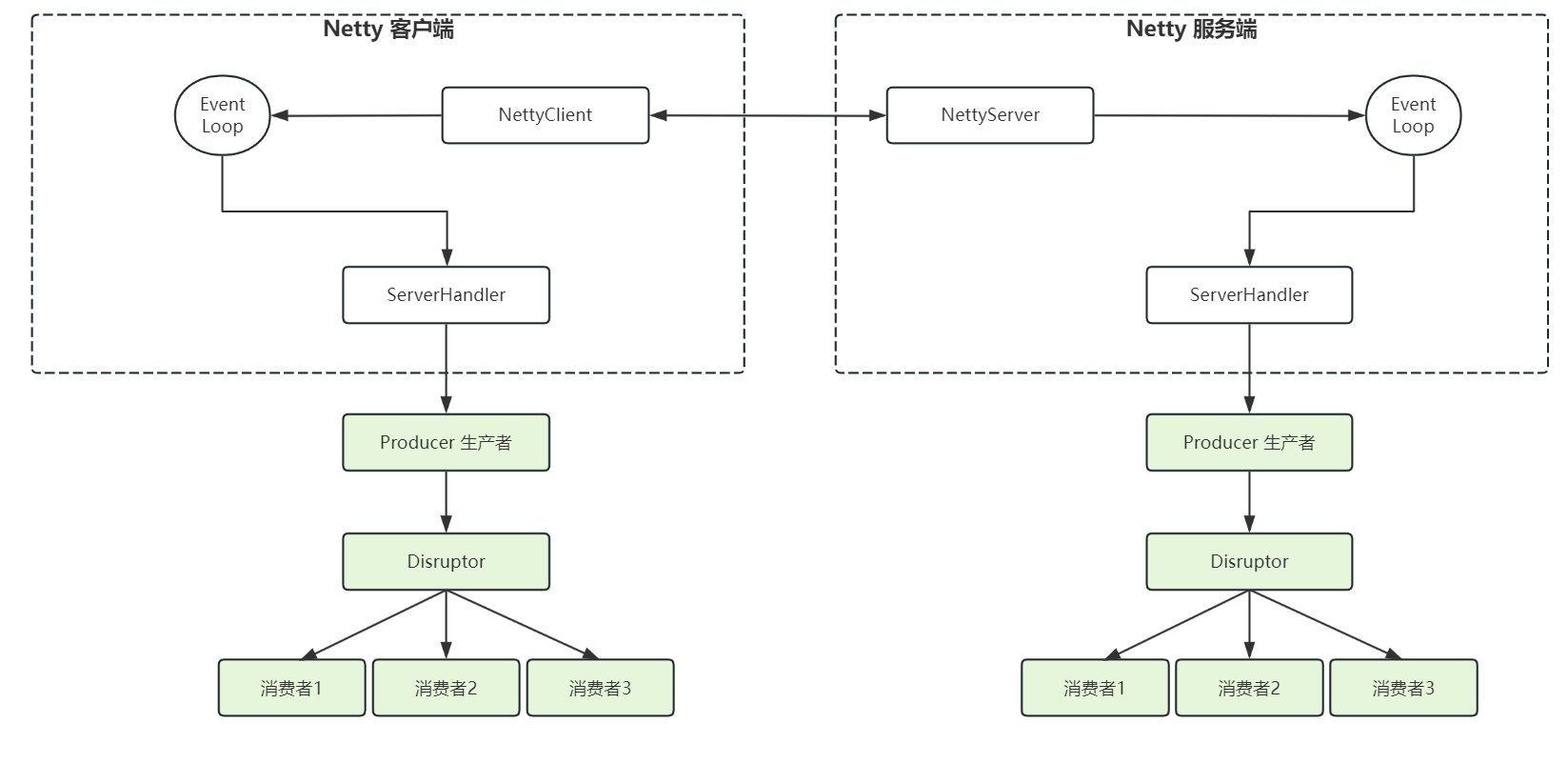
高性能队列框架-Disruptor使用、Netty结合Disruptor大幅提高数据处理性能
高性能队列框架-Disruptor 首先介绍一下 Disruptor 框架,Disruptor是一个通用解决方案,用于解决并发编程中的难题(低延迟与高吞吐量),Disruptor 在高并发场景下性能表现很好,如果有这方面需要,…...

通达信缠论插件ChanlunX:5分钟实现专业缠论分析的终极指南
通达信缠论插件ChanlunX:5分钟实现专业缠论分析的终极指南 【免费下载链接】ChanlunX 缠中说禅炒股缠论可视化插件 项目地址: https://gitcode.com/gh_mirrors/ch/ChanlunX 想要在通达信中实现专业的缠论分析吗?ChanlunX缠论插件是你的最佳选择&a…...
)
达达主义AI艺术正在消失?深度起底平台内容审核算法对“无意义美学”的误判逻辑(含绕过策略与伦理边界声明)
更多请点击: https://intelliparadigm.com 第一章:达达主义AI艺术正在消失? 达达主义以反逻辑、反美学、拥抱偶然性为内核,而当代AI艺术生成工具却日益依赖确定性提示词工程、风格迁移约束与商业审美对齐——这种张力正悄然消解达…...
)
用Wireshark抓包实战,手把手教你读懂LwIP里的TCP/IP数据帧(附真实数据解析)
Wireshark与LwIP实战:从抓包数据到协议栈实现的深度解析 当你第一次在Wireshark中看到那些密密麻麻的十六进制数据时,是否感到无从下手?作为嵌入式开发者,理解网络数据包的底层结构不仅是调试网络问题的关键,更是优化L…...

ReID跨镜还在“找相似”,镜像视界无感定位已实现“定位置”
ReID跨镜还在“找相似”,镜像视界无感定位已实现“定位置”纵观当下视频跨镜追踪行业,技术路线早已形成鲜明代际差距。传统ReID行人重识别依旧固守视觉特征比对逻辑,全程停留在画面里反复“找相似”的浅层识别阶段;而依托国家十四…...

在扁平化组织里,技术人如何建立“非职权影响力”?
一、为什么测试人更需要非职权影响力软件测试工程师的岗位设置本身就带有一种结构性矛盾:你对产品质量负责,却很少拥有对等的决策权。开发写代码,你找bug;产品定需求,你验证逻辑;项目经理排期,你…...

思源宋体TTF完全指南:7种字重免费解决中文排版难题
思源宋体TTF完全指南:7种字重免费解决中文排版难题 【免费下载链接】source-han-serif-ttf Source Han Serif TTF 项目地址: https://gitcode.com/gh_mirrors/so/source-han-serif-ttf 还在为中文设计项目找不到合适的字体而烦恼吗?无论是网页设计…...

AI赋能的两种逻辑企业如何选?:从「AI+行业」
在人工智能全面重构产业格局的今天,用不用 AI 已经不是问题,怎么用 AI 才是生死关键。同样是布局 AI,有的企业只实现小幅增效,有的企业却直接颠覆行业、重塑价值链。 核心差距,就在于选择了 「AI 行业」的加法逻辑&am…...
)
大厂4年经验Java面试题深入解析(10道)
大厂 4 年经验 Java 面试题深入解析(10 道) 这篇文章不是面向校招,也不是面向只会背八股的初级候选人,而是针对已经有 4 年左右实际项目经验、准备冲击大厂的 Java 工程师。 大厂面试更看重你是否能把基础原理、线上问题、设计取舍…...

Godot引擎集成Wwise音频中间件:从原理到实战的完整指南
1. 项目概述:当AAA级音频引擎遇见开源游戏引擎如果你是一位使用Godot引擎的游戏开发者,并且对游戏音频的品质有追求,那么你很可能听说过Wwise。Wwise,全称Audiokinetic Wwise,是游戏音频领域的行业标准,从《…...

拆解MC1496乘法器:如何在没有现成库的Multisim里,手动封装一个调幅核心模块
从零构建MC1496乘法器:Multisim高阶封装与调幅电路实战指南 在电子设计领域,仿真软件自带的元件库往往无法满足所有需求。当我们需要使用MC1496这类经典模拟乘法器时,Multisim的默认库可能让人束手无策。本文将带您深入芯片内部结构ÿ…...