clickhouse删除partition分区数据
clickhouse分布式表tencent_table_20231208_DIST,本地表tencent_table_20231208_local;
30台clickhouse存储服务器;
本地表:tencent_table_20231208_local
CREATE TABLE tencent_sz.tencent_table_20231208_local
(`id` Int64 DEFAULT CAST(0, 'Int64'),`pid` Int64,`user` String,`host` String,`db` Nullable(String),`COMMAND` String,`TIME` Int64,`STATE` Nullable(String),`source_sql` Nullable(String),`INFO` Nullable(String),`create_time` DateTime DEFAULT now(),`collect_create_time` DateTime,`instance_name` String,`source_ip` String,`source_port` UInt32,`_date` Date DEFAULT toDate(create_time),`scan_row` Int64 DEFAULT CAST(0, 'Int64'),`use_key` Nullable(String),`crc32` Int64 DEFAULT CAST(0, 'Int64')
)
ENGINE = ReplicatedMergeTree('/clickhouse/tables/{shard}/tencent_table_20231208_local', '{replica}')
PARTITION BY _date
ORDER BY (source_ip, create_time)
TTL _date + toIntervalDay(14)
SETTINGS index_granularity = 8192
分布式表:
CREATE TABLE tencent_sz.tencent_table_20231208_DIST
(`id` Int64 DEFAULT CAST(0, 'Int64'),`pid` Int64,`user` String,`host` String,`db` Nullable(String),`COMMAND` String,`TIME` Int64,`STATE` Nullable(String),`source_sql` Nullable(String),`INFO` Nullable(String),`create_time` DateTime DEFAULT now(),`collect_create_time` DateTime,`instance_name` String,`source_ip` String,`source_port` UInt32,`_date` Date DEFAULT toDate(create_time),`scan_row` Int64 DEFAULT CAST(0, 'Int64'),`use_key` Nullable(String),`crc32` Int64 DEFAULT CAST(0, 'Int64')
)
ENGINE = Distributed('clk_dba', 'tencent_sz', 'tencent_table_20231208_local', rand())
一段时间后,数据过大,手动删除;
先查询该表的所有分区:
SELECT database, table, partition, name, active FROM system.parts WHERE table = 'tencent_table_20231208_local'
输出:
┌─database─────┬─table──────────────────────────┬─partition──┬─name─────────────────┬─active─┐
│ tencent_sz │ tencent_table_20231208_local │ 2023-12-07 │ 20231207_4740_5083_4 │ 1 │
│ tencent_sz │ tencent_table_20231208_local │ 2023-12-07 │ 20231207_5084_5330_4 │ 1 │
│ tencent_sz │ tencent_table_20231208_local │ 2023-12-07 │ 20231207_5331_5441_3 │ 1 │
│ tencent_sz │ tencent_table_20231208_local │ 2023-12-07 │ 20231207_5442_5467_2 │ 1 │
│ tencent_sz │ tencent_table_20231208_local │ 2023-12-07 │ 20231207_5468_5468_0 │ 1 │
│ tencent_sz │ tencent_table_20231208_local │ 2023-12-07 │ 20231207_5469_5469_0 │ 1 │
│ tencent_sz │ tencent_table_20231208_local │ 2023-12-07 │ 20231207_5470_5470_0 │ 1 │
│ tencent_sz │ tencent_table_20231208_local │ 2023-12-08 │ 20231208_0_611_4 │ 1 │
删除分区名:
alter table tencent_sz.tencent_table_20231208_local DROP PARTITION '2023-12-07';
相关文章:

clickhouse删除partition分区数据
clickhouse分布式表tencent_table_20231208_DIST,本地表tencent_table_20231208_local; 30台clickhouse存储服务器; 本地表:tencent_table_20231208_local CREATE TABLE tencent_sz.tencent_table_20231208_local (id Int64 DEFA…...

持续集成交付CICD:CentOS 7 安装 Nexus 3.63
目录 一、实验 1.CentOS 7 安装Nexus3.63 二、问题 1.安装Nexus报错 2.Nexus启动停止相关命令 一、实验 1.CentOS 7 安装Nexus3.63 (1)当前操作系统版本&JDK版本 cat /etc/redhat-releasejava -version(2)下载Nexus新…...

Apache Flink(十):Flink集群基础环境搭建-JDK及MySQL搭建
🏡 个人主页:IT贫道_大数据OLAP体系技术栈,Apache Doris,Clickhouse 技术-CSDN博客 🚩 私聊博主:加入大数据技术讨论群聊,获取更多大数据资料。 🔔 博主个人B栈地址:豹哥教你大数据的个人空间-豹哥教你大数据个人主页-哔哩哔哩视频 目录...
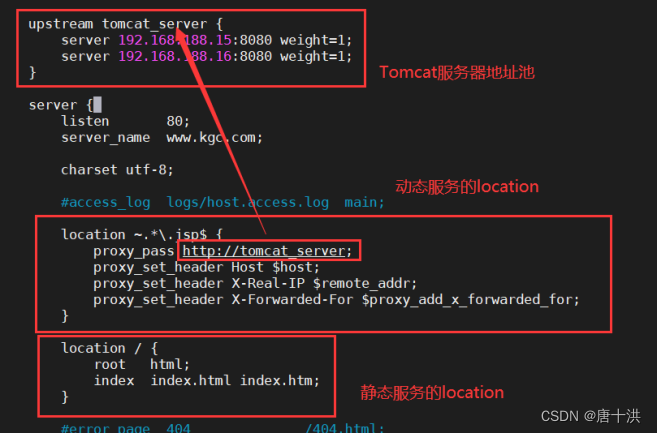
LVS-DR+Keepalived+动静分离实验
架构图 解释一下架构,大概就是用Keepalived实现两台DR服务器的LVS负载均衡,然后后端服务器是两台Nginx服务器两台Tomcat服务器并且实现动静分离这个实验其实就是把 LVS-DRKeepalived 和 动静分离 给拼起来,真的是拼起来,两个部分…...

java面试题-Hashmap、Hashtable、ConcurrentHashMap原理
远离八股文,面试大白话,通俗且易懂 看完后试着用自己的话复述出来。有问题请指出,有需要帮助理解的或者遇到的真实面试题不知道怎么总结的也请评论中写出来,大家一起解决。 java面试题汇总-目录-持续更新中 Hashmap和hashtable存储…...
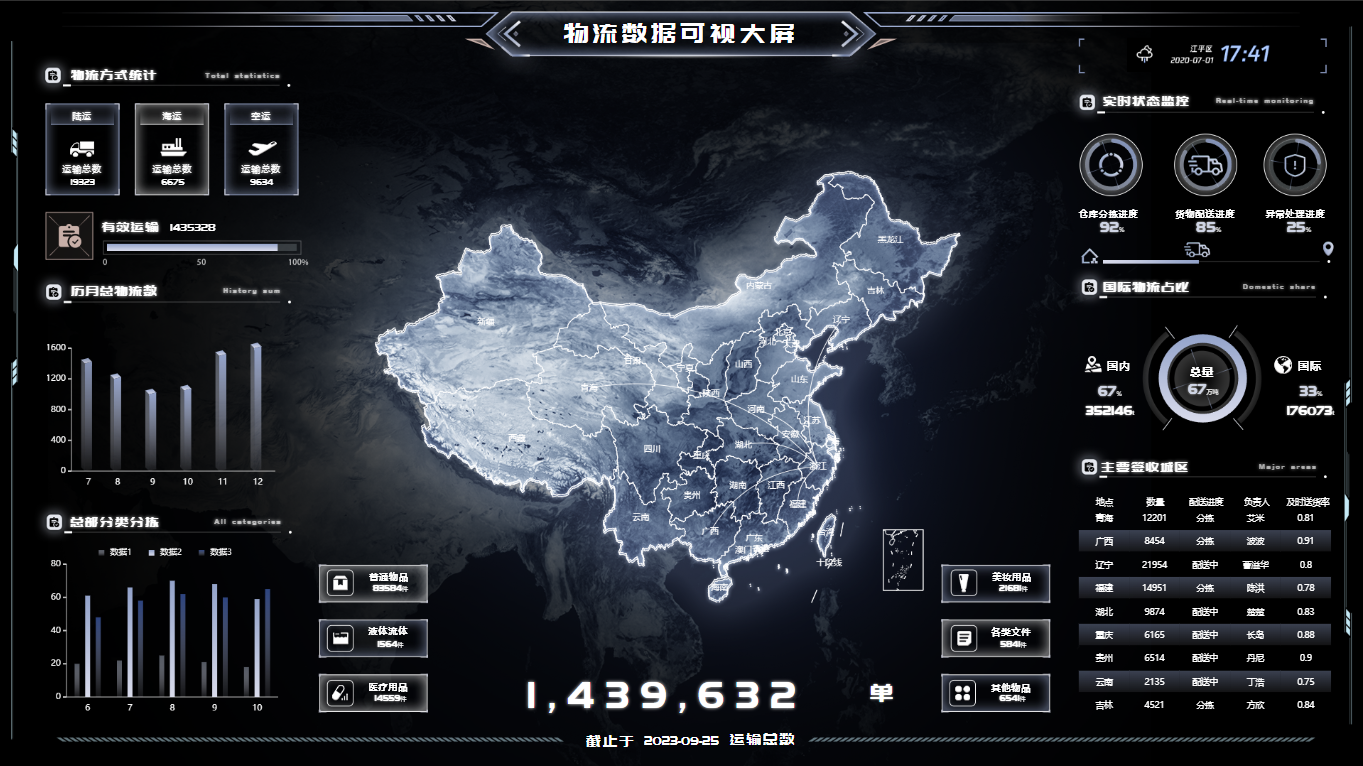
数据可视化:解锁企业经营的智慧之道
在现代企业管理中,数据可视化已经成为了一项重要的工具。它不仅仅是简单地展示数据,更是提供了深入理解数据、做出更明智决策的方法。作为一名可视化设计从业人员,我经手过一些企业自用的数据可视化项目,今天就来和大家聊聊数据可…...

JVM 性能调优
概述篇 面试题 讲讲你理解的性能评价及测试指标?(瓜子) 生产环境中的问题 生产环境发生了内存溢出该如何处理?生产环境应该给服务器分配多少内存合适?如何对垃圾回收器的性能进行调优?生产环境CPU负载飙高…...
)
linux常用命令-yum命令详解(超详细)
文章目录 前言一、yum命令介绍1. yum命令简介2. yum命令的基本语法3. 常用的yum命令选项4. 常用的yum命令参数 二、yum命令示例用法1. 安装软件包2. 更新软件包3. 删除软件包4. 搜索软件包5. 列出已安装的软件包6. 列出可用的软件包7. 清理缓存8. 禁用软件包仓库 总结 前言 yu…...

解决 Element-ui中 表格(Table)使用 v-if 条件切换后,表格的列的筛选不显示了
解决方法 在每个需要使用 v-if 或 v-else 的 el-table-column 上增加 key 作为唯一标识,这样渲染的时候就不会因为复用原则导致列数据混乱了。关于key值,一般习惯使用字段名,也可随机生成一个值,只要具有唯一性就可以。...
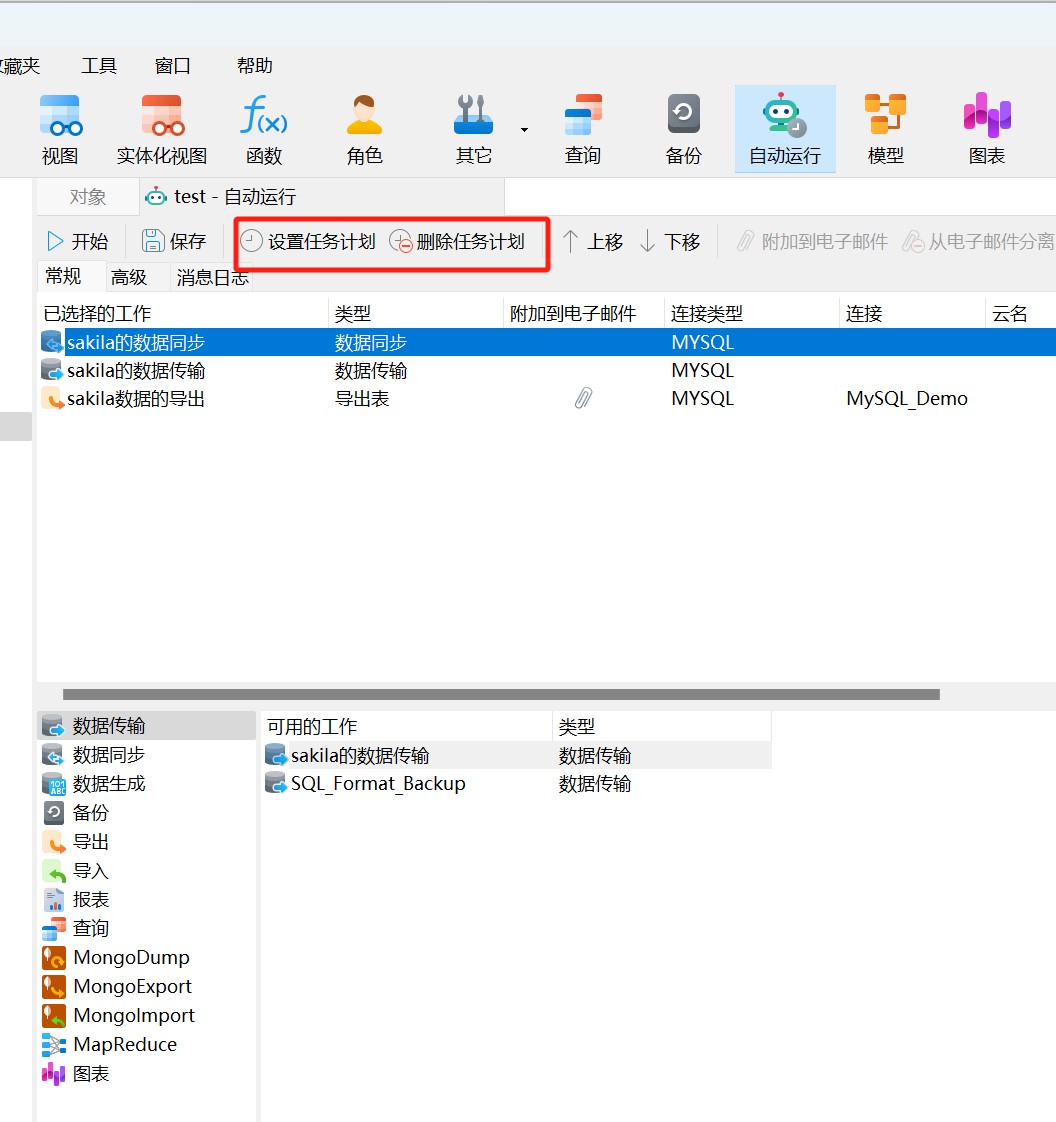
Navicat 技术指引 | 适用于 GaussDB 分布式的自动运行功能
Navicat Premium(16.3.3 Windows 版或以上)正式支持 GaussDB 分布式数据库。GaussDB 分布式模式更适合对系统可用性和数据处理能力要求较高的场景。Navicat 工具不仅提供可视化数据查看和编辑功能,还提供强大的高阶功能(如模型、结…...
爬虫 selenium语法 (八)
目录 一、为什么使用selenium 二、selenium语法——元素定位 1.根据 id 找到对象 2.根据标签属性的属性值找到对象 3.根据Xpath语句获取对象 4.根据标签名获取对象 5.使用bs语法获取对象 6.通过链接文本获取对象 三、selenium语法——访问元素信息 1.获取属性的属性值…...
技术参数分享)
NTP时钟同步服务器(校时服务器)技术参数分享
NTP时钟同步服务器(校时服务器)技术参数分享 网络校时服务器是一款先进的智能化高精度时钟同步设备。 网络校时服务器从 GPS、北斗、GLONASS、Galileo等导航定位卫星系统上获取标准时间信息,并通过 NTP/SNTP 或其他网络协议,在网络…...
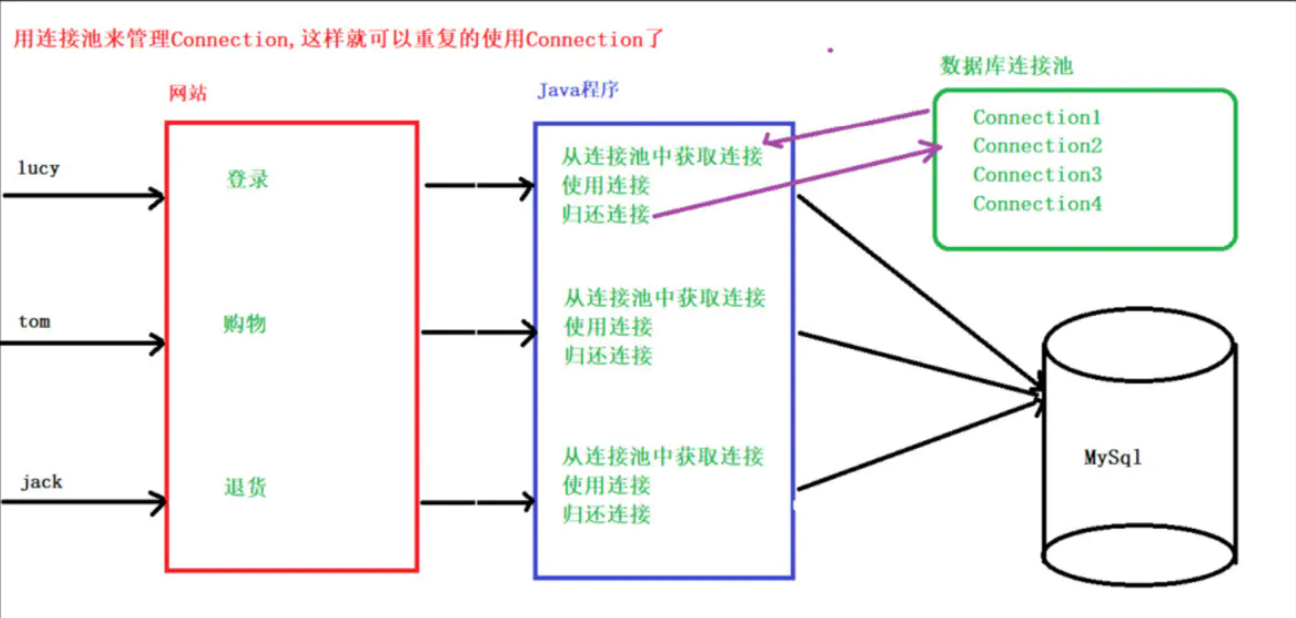
JDBC详解——增删改查(CRUD)、sql注入、事务、连接池
1. 概念: Java DataBase Connectivity, Java 数据库连接, Java语言操作数据库 JDBC本质:其实是官方(sun公司)定义的一套操作所有关系型数据库的规则,即接口。各个数据库厂商去实现这套接口&…...
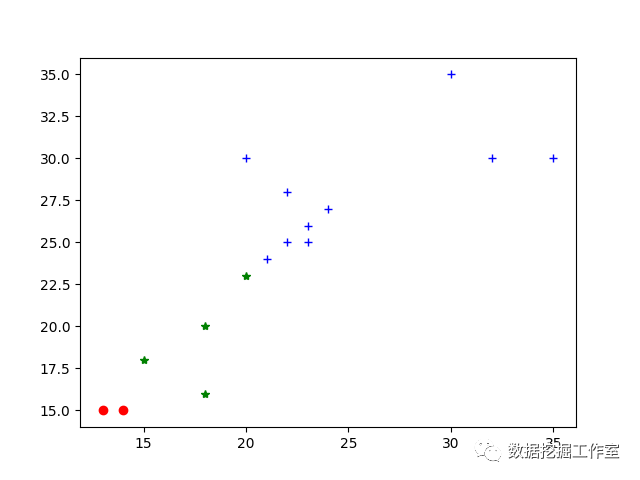
K-means算法通俗原理及Python与R语言的分别实现
K均值聚类方法是一种划分聚类方法,它是将数据分成互不相交的K类。K均值法先指定聚类数,目标是使每个数据到数据点所属聚类中心的总距离变异平方和最小,规定聚类中心时则是以该类数据点的平均值作为聚类中心。 01K均值法原理与步骤 对于有N个…...

使用 db2diag 工具来分析 db2diag 日志文件
供数据库和系统管理员使用的主日志文件为管理通知日志。db2diag 日志文件旨在供 IBM 软件支持机构用于进行故障诊断。 管理通知日志消息也以标准化消息格式记录到 db2diag 日志文件。 db2diag 工具用于对 db2diag 日志文件中的大量信息进行过滤和格式化。过滤 db2diag 日志文…...
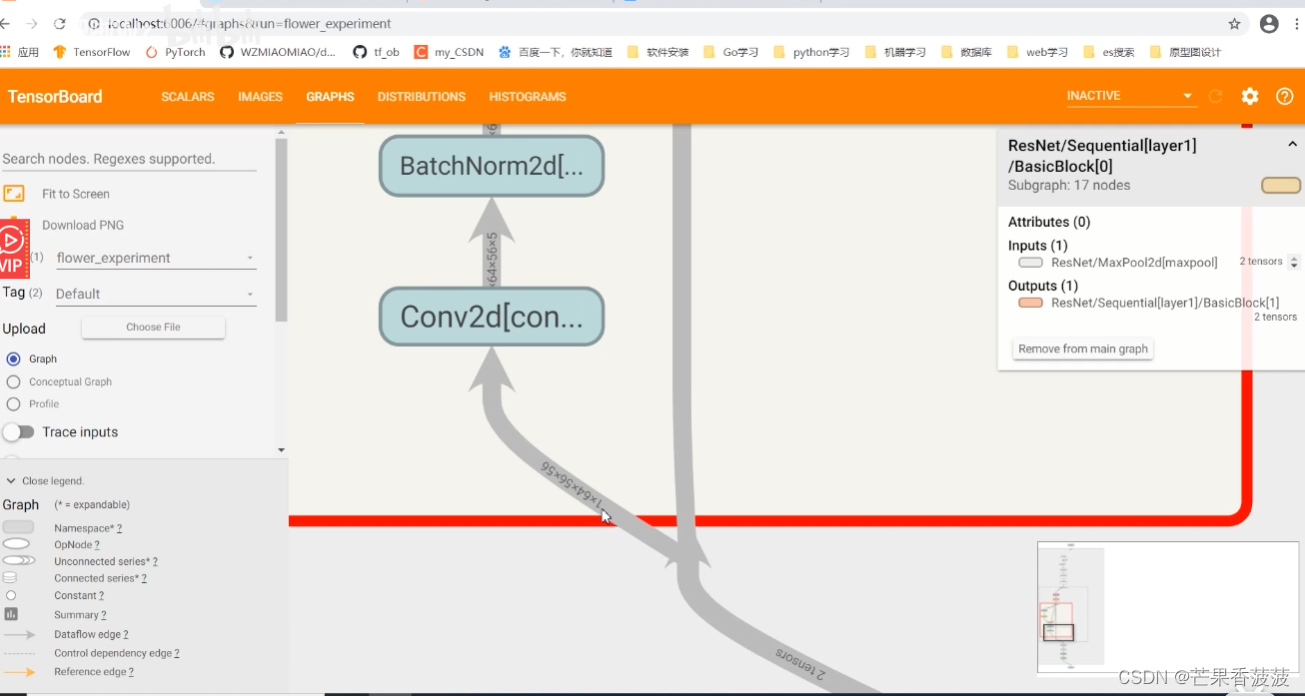
在Pytorch中使用Tensorboard可视化训练过程
这篇是我对哔哩哔哩up主 霹雳吧啦Wz 的视频的文字版学习笔记 感谢他对知识的分享 本节课我们来讲一下如何在pytouch当中去使用我们的tensorboard 对我们的训练过程进行一个可视化 左边有一个visualizing models data and training with tensorboard 主要是这么一个教程 那么这里…...
Redis 命令全解析之 Hash类型
文章目录 ⛄介绍⛄命令⛄RedisTemplate API⛄应用场景 ⛄介绍 Hash类型,也叫散列,其value是一个无序字典,类似于Java中的 HashMap 结构。 String结构是将对象序列化为JSON字符串后存储,当需要修改对象某个字段时很不方便…...

postgresql数据库配置主从并配置ssl加密
1、先将postgresql数据库主从配置好 参考:postgresql主从配置 2、在主节点配置ssl加密,使用navicat测试是否可以连接 参考:postgresql配置ssl 3、正常连接无误后,将root.crt、server.crt、server.key复制到从数据库节点的存储…...
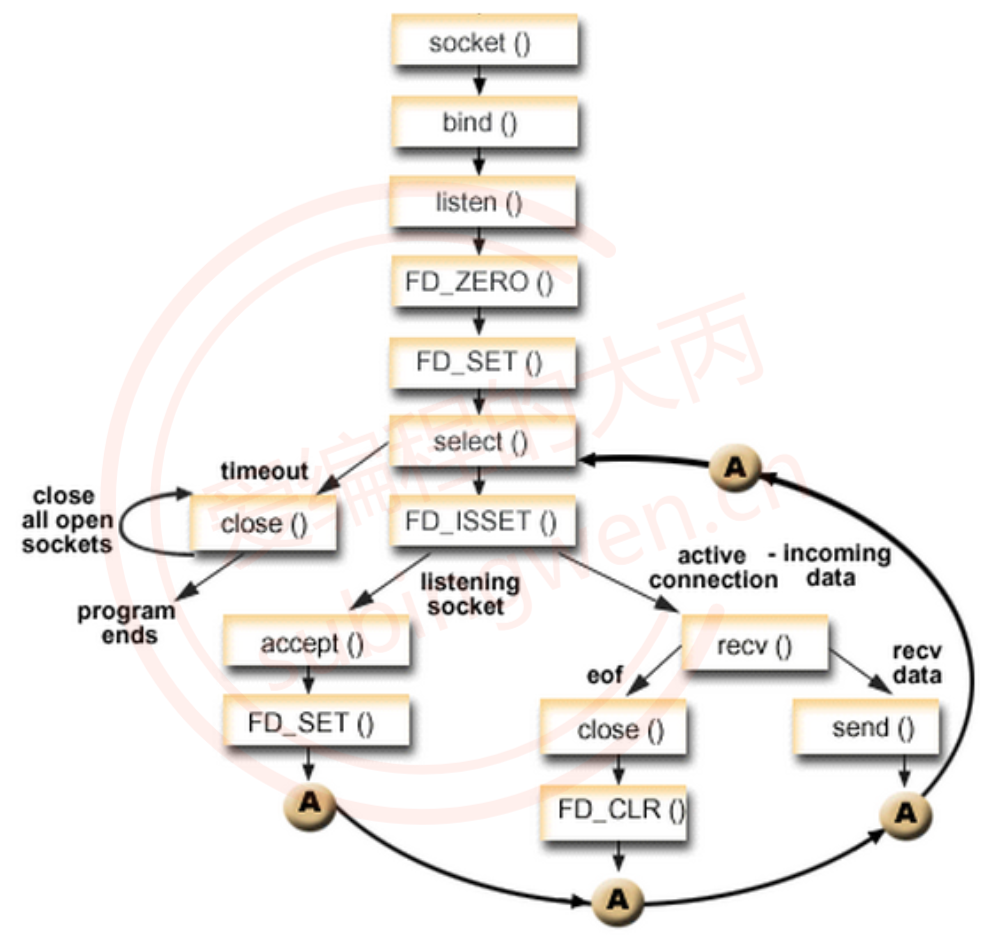
IO多路转接之select
IO多路转接之select 1. IO多路转接(复用)2. select2.1 函数原型2.2 细节描述 3. 并发处理3.1 处理流程3.2 通信代码 原文链接 1. IO多路转接(复用) IO多路转接也称为IO多路复用,它是一种网络通信的手段(机…...
)
linux如何删除大文件的第一行(sed)
可以用sed命令实现: 删除文档的第一行 1. sed -i 1d <file>删除文档的最后一行 1. sed -i $d <file>在文档指定行中增加一行 # 示例如下: echo "1"; echo "2"; echo "4"; echo "5"; # 想要在echo…...

终极指南:使用XNBCLI高效解包打包星露谷物语XNB游戏资源文件
终极指南:使用XNBCLI高效解包打包星露谷物语XNB游戏资源文件 【免费下载链接】xnbcli A CLI tool for XNB packing/unpacking purpose built for Stardew Valley. 项目地址: https://gitcode.com/gh_mirrors/xn/xnbcli XNB文件是星露谷物语等XNA游戏引擎使用…...
:Offload、Flow、NUMA、IOVA 与性能剖析)
DPDK 教程(四):Offload、Flow、NUMA、IOVA 与性能剖析
DPDK 教程(四):Offload、Flow、NUMA、IOVA 与性能剖析 本文对应学习路径第四步:在已能跑通 多队列转发 后,把系统从“能跑”推到“可解释、可优化”。重点放在:硬件卸载的正确语义、Flow 与 RSS 的分工、NU…...

基于CircuitPython与CRICKIT的仿生机械手制作:从PWM控制到交互实现
1. 项目概述:从零打造一个会“听话”的机械手如果你对机器人、自动化或者仅仅是让东西“动起来”感兴趣,那么用微控制器控制伺服电机绝对是一个绕不开的经典课题。这不仅仅是让一个舵机转来转去那么简单,它背后是一整套关于信号控制、机械传动…...
)
从Excel到数据库:用Pandas Timestamp统一你的时间数据(pd.to_datetime实战解析)
从Excel到数据库:用Pandas Timestamp统一你的时间数据(pd.to_datetime实战解析) 在数据工程领域,时间数据的标准化处理往往是ETL流程中最容易被低估的痛点。当Excel表格中的"2023/1/15"遇上数据库里的"15-JAN-23&q…...

树莓派Pico W到手后,除了Wi-Fi,这几点硬件细节和Pico真不一样
树莓派Pico W硬件深度解析:超越Wi-Fi的工程细节 当我第一次拿到树莓派Pico W时,表面看起来它只是Pico的无线版本——同样的RP2040芯片、相似的引脚布局和几乎一致的尺寸。但当我开始实际项目开发时,才发现这些"看似相同"背后隐藏着…...

产品经理面试与求职攻略:Awesome Product Management 职业转型成功案例
产品经理面试与求职攻略:Awesome Product Management 职业转型成功案例 【免费下载链接】awesome-product-management 🚀 A curated list of awesome resources for product/program managers to learn and grow. 项目地址: https://gitcode.com/gh_mi…...

开源RPA工具Clawless:本地化低代码自动化实战与核心原理
1. 项目概述:从“无爪”到“有手”,一个开源RPA项目的诞生最近在GitHub上闲逛,发现了一个挺有意思的项目,叫“Clawless”,直译过来是“无爪”。初看这个标题,你可能会有点摸不着头脑,这跟自动化…...

二维码扫描模块价格解析:从几十元到上千元,如何根据应用场景选型?
1. 项目概述:解码二维码扫描模块的价格迷思每次和做硬件集成的朋友聊天,或者接到客户关于自助终端、智能门禁的咨询,总绕不开一个最实际的问题:“你们用的那个扫码模块,到底多少钱一个?” 这问题看似简单&a…...

Python实时通信实战:Flask-SocketIO深度解析
Python实时通信实战:Flask-SocketIO深度解析 引言 在Python开发中,实时通信是构建现代Web应用的核心技术。作为一名从Rust转向Python的后端开发者,我深刻体会到Flask-SocketIO在实时通信方面的优势。Flask-SocketIO为Flask应用提供了WebSocke…...

ChatGPT Google Extension容器化部署终极指南:Docker与CI/CD完全集成方案
ChatGPT Google Extension容器化部署终极指南:Docker与CI/CD完全集成方案 【免费下载链接】chatgpt-google-extension This project is deprecated. Check my new project ChatHub: 项目地址: https://gitcode.com/gh_mirrors/ch/chatgpt-google-extension 在…...