大三上实训内容
项目一:爬取天气预报数据
【内容】
在中国天气网(http://www.weather.com.cn)中输入城市的名称,例如输入信阳,进入http://www.weather.com.cn/weather1d/101180601.shtml#input
的网页显示信阳的天气预报,其中101180601是信阳的代码,每个城市或者地区都有一个代码。如下图所示,请爬取河南所有城市15天的天气预报数据。
1到7天代码
import requests
from bs4 import BeautifulSoup
import csvheaders = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/107.0.0.0 Safari/537.36','Accept-Encoding': 'gzip, deflate'
}
city_list = [101180101,101180901,101180801,101180301,101180501,101181101,101180201,101181201,101181501,101180701,101180601,101181401,101181001,101180401,101181701,101181601,101181301]
city_name_dict = {101180101: "郑州市",101180901: "洛阳市",101180801: "开封市",101180301: "新乡市",101180501: "平顶山市",101181101: "焦作市",101180201: "安阳市",101181201: "鹤壁市",101181501: "漯河市",101180701: "南阳市",101180601: "信阳市",101181401: "周口市",101181001: "商丘市",101180401: "许昌市",101181701: "三门峡市",101181601: "驻马店市",101181301: "濮阳"
}# 创建csv文件
with open('河南地级市7天天气情况.csv', 'w', newline='', encoding='utf-8') as csvfile:csv_writer = csv.writer(csvfile)# 写入表头csv_writer.writerow(['City ID', 'City Name', 'Weather Info'])for city in city_list:city_id = citycity_name = city_name_dict.get(city_id, "未知城市")print(f"City ID: {city_id}, City Name: {city_name}")url = f'http://www.weather.com.cn/weather/{city}.shtml'response = requests.get(headers=headers, url=url)soup = BeautifulSoup(response.content.decode('utf-8'), 'html.parser')# 找到v<div id="7d" class="c7d">标签v_div = soup.find('div', {'id': '7d'})# 提取v<div id="7d" class="c7d">下的天气相关的网页信息weather_info = v_div.find('ul', {'class': 't clearfix'})# 提取li标签下的内容,每个标签下的分行打印,移除打印结果之间的空格weather_list = []for li in weather_info.find_all('li'):weather_list.append(li.text.strip().replace('\n', ''))# 将城市ID、城市名称和天气信息写入csv文件csv_writer.writerow([city_id, city_name, ', '.join(weather_list)])
8到15天的代码
import requests
from bs4 import BeautifulSoup
import csvheaders = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/107.0.0.0 Safari/537.36','Accept-Encoding': 'gzip, deflate'
}
city_list = [101180101, 101180901, 101180801, 101180301, 101180501, 101181101, 101180201, 101181201, 101181501,101180701, 101180601, 101181401, 101181001, 101180401, 101181701, 101181601, 101181301]
city_name_dict = {101180101: "郑州市",101180901: "洛阳市",101180801: "开封市",101180301: "新乡市",101180501: "平顶山市",101181101: "焦作市",101180201: "安阳市",101181201: "鹤壁市",101181501: "漯河市",101180701: "南阳市",101180601: "信阳市",101181401: "周口市",101181001: "商丘市",101180401: "许昌市",101181701: "三门峡市",101181601: "驻马店市",101181301: "濮阳"
}
# 创建csv文件
with open('河南地级市8-15天天气情况.csv', 'w', newline='', encoding='utf-8') as csvfile:csv_writer = csv.writer(csvfile)# 写入表头csv_writer.writerow(['City ID', 'City Name', 'Weather Info'])for city in city_list:city_id = citycity_name = city_name_dict.get(city_id, "未知城市")print(f"City ID: {city_id}, City Name: {city_name}")url = f'http://www.weather.com.cn/weather15d/{city}.shtml'response = requests.get(headers=headers, url=url)soup = BeautifulSoup(response.content.decode('utf-8'), 'html.parser')# 找到v<div id="15d" class="c15d">标签v_div = soup.find('div', {'id': '15d'})# 提取v<div id="15d" class="c15d">下的天气相关的网页信息weather_info = v_div.find('ul', {'class': 't clearfix'})# 提取li标签下的信息for li in weather_info.find_all('li'):time = li.find('span', {'class': 'time'}).textwea = li.find('span', {'class': 'wea'}).texttem = li.find('span', {'class': 'tem'}).textwind = li.find('span', {'class': 'wind'}).textwind1 = li.find('span', {'class': 'wind1'}).textcsv_writer.writerow([city_id, city_name, f"时间:{time},天气:{wea},温度:{tem},风向:{wind},风力:{wind1}"])
15天代码
import requests
from bs4 import BeautifulSoup
import csvheaders = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/107.0.0.0 Safari/537.36','Accept-Encoding': 'gzip, deflate'
}
city_list = [101180101, 101180901, 101180801, 101180301, 101180501, 101181101, 101180201, 101181201, 101181501,101180701, 101180601, 101181401, 101181001, 101180401, 101181701, 101181601, 101181301]
city_name_dict = {101180101: "郑州市",101180901: "洛阳市",101180801: "开封市",101180301: "新乡市",101180501: "平顶山市",101181101: "焦作市",101180201: "安阳市",101181201: "鹤壁市",101181501: "漯河市",101180701: "南阳市",101180601: "信阳市",101181401: "周口市",101181001: "商丘市",101180401: "许昌市",101181701: "三门峡市",101181601: "驻马店市",101181301: "濮阳"
}# 创建csv文件
with open('河南地级市1-15天天气情况.csv', 'w', newline='', encoding='utf-8') as csvfile:csv_writer = csv.writer(csvfile)# 写入表头csv_writer.writerow(['City ID', 'City Name', 'Weather Info'])for city in city_list:city_id = citycity_name = city_name_dict.get(city_id, "未知城市")print(f"City ID: {city_id}, City Name: {city_name}")# 爬取1-7天天气情况url_7d = f'http://www.weather.com.cn/weather/{city}.shtml'response_7d = requests.get(headers=headers, url=url_7d)soup_7d = BeautifulSoup(response_7d.content.decode('utf-8'), 'html.parser')v_div_7d = soup_7d.find('div', {'id': '7d'})weather_info_7d = v_div_7d.find('ul', {'class': 't clearfix'})weather_list_7d = []for li in weather_info_7d.find_all('li'):weather_list_7d.append(li.text.strip().replace('\n', ''))# 爬取8-15天天气情况url_15d = f'http://www.weather.com.cn/weather15d/{city}.shtml'response_15d = requests.get(headers=headers, url=url_15d)soup_15d = BeautifulSoup(response_15d.content.decode('utf-8'), 'html.parser')v_div_15d = soup_15d.find('div', {'id': '15d'})weather_info_15d = v_div_15d.find('ul', {'class': 't clearfix'})weather_list_15d = []for li in weather_info_15d.find_all('li'):time = li.find('span', {'class': 'time'}).textwea = li.find('span', {'class': 'wea'}).texttem = li.find('span', {'class': 'tem'}).textwind = li.find('span', {'class': 'wind'}).textwind1 = li.find('span', {'class': 'wind1'}).textweather_list_15d.append(f"时间:{time},天气:{wea},温度:{tem},风向:{wind},风力:{wind1}")# 将城市ID、城市名称和天气信息写入csv文件csv_writer.writerow([city_id, city_name, ', '.join(weather_list_7d+weather_list_15d)])项目二:爬取红色旅游数据
【内容】
信阳是大别山革命根据地,红色旅游资源非常丰富,爬取http://www.bytravel.cn/view/red/index441_list.html 网页的红色旅游景点,并在地图上标注出来。
相关代码
import requests # 导入requests库,用于发送HTTP请求
import csv # 导入csv库,用于处理CSV文件
from bs4 import BeautifulSoup # 导入BeautifulSoup库,用于解析HTML文档headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/107.0.0 Safari/537.36','Accept-Encoding': 'gzip, deflate' # 设置请求头,模拟浏览器访问
}# 创建csv文件并写入表头
csv_file = open('信阳红色景点.csv', 'w', newline='', encoding='utf-8') # 打开csv文件,以写入模式
csv_writer = csv.writer(csv_file) # 创建csv写入对象
csv_writer.writerow(['景点名称', '景点简介', '星级', '图片链接']) # 写入表头# 爬取第一页
url = 'http://www.bytravel.cn/view/red/index441_list.html' # 定义要爬取的网页URL
response = requests.get(headers=headers, url=url) # 发送GET请求,获取网页内容
soup = BeautifulSoup(response.content.decode('gbk'), 'html.parser') # 使用BeautifulSoup解析网页内容target_div = soup.find('div', {'style': 'margin:5px 10px 0 10px'}) # 在解析后的HTML中查找目标divfor div in target_div.find_all('div', {'style': 'margin:2px 10px 0 7px;padding:3px 0 0 0'}): # 在目标div中查找所有符合条件的子divtitle_element = div.find('a', {'class': 'blue14b'}) # 在子div中查找标题元素if title_element: # 如果找到了标题元素title = title_element.text # 获取标题文本else:title = "未找到标题" # 如果没有找到标题元素,设置默认值Introduction_element = div.find('div', id='tctitletop102') # 在子div中查找简介元素if Introduction_element: # 如果找到了简介元素intro = Introduction_element.text.strip().replace("[详细]", "") # 获取简介文本,去除首尾空格和"[详细]"标记else:intro = "无简介" # 如果没有找到简介元素,设置默认值star_element = div.find('font', {'class': 'f14'}) # 在子div中查找星级元素if star_element: # 如果找到了星级元素star = star_element.text # 获取星级文本else:star = "无星级" # 如果没有找到星级元素,设置默认值img_url_element = div.find('img', {'class': 'hpic'}) # 在子div中查找图片链接元素if img_url_element: # 如果找到了图片链接元素img_url = img_url_element['src'] # 获取图片链接else:img_url = "无图片链接" # 如果没有找到图片链接元素,设置默认值print('景点名称:', title) # 打印景点名称print('景点简介:', intro) # 打印景点简介print('星级:', star) # 打印星级print('图片链接:', img_url) # 打印图片链接# 将数据写入csv文件csv_writer.writerow([title, intro, star, img_url]) # 将景点名称、简介、星级和图片链接写入csv文件# 爬取第二页到第五页
for page in range(1, 5): # 遍历第二页到第五页url = f'http://www.bytravel.cn/view/red/index441_list{page}.html' # 构造每一页的URLresponse = requests.get(headers=headers, url=url) # 发送GET请求,获取网页内容soup = BeautifulSoup(response.content.decode('gbk'), 'html.parser') # 使用BeautifulSoup解析网页内容target_div = soup.find('div', {'style': 'margin:5px 10px 0 10px'}) # 在解析后的HTML中查找目标divfor div in target_div.find_all('div', {'style': 'margin:2px 10px 0 7px;padding:3px 0 0 0'}): # 在目标div中查找所有符合条件的子divtitle_element = div.find('a', {'class': 'blue14b'}) # 在子div中查找标题元素if title_element: # 如果找到了标题元素title = title_element.text # 获取标题文本else:title = "未找到标题" # 如果没有找到标题元素,设置默认值Introduction_element = div.find('div', id='tctitletop102') # 在子div中查找简介元素if Introduction_element: # 如果找到了简介元素intro = Introduction_element.text.strip().replace("[详细]", "") # 获取简介文本,去除首尾空格和"[详细]"标记else:intro = "无简介" # 如果没有找到简介元素,设置默认值star_element = div.find('font', {'class': 'f14'}) # 在子div中查找星级元素if star_element: # 如果找到了星级元素star = star_element.text # 获取星级文本else:star = "无星级" # 如果没有找到星级元素,设置默认值img_url_element = div.find('img', {'class': 'hpic'}) # 在子div中查找图片链接元素if img_url_element: # 如果找到了图片链接元素img_url = img_url_element['src'] # 获取图片链接else:img_url = "无图片链接" # 如果没有找到图片链接元素,设置默认值print('景点名称:', title) # 打印景点名称print('景点简介:', intro) # 打印景点简介print('星级:', star) # 打印星级print('图片链接:', img_url) # 打印图片链接# 将数据写入csv文件csv_writer.writerow([title, intro, star, img_url]) # 将景点名称、简介、星级和图片链接写入csv文件# 关闭csv文件
csv_file.close()
项目三:豆瓣网爬取top250电影数据
【内容】
运用scrapy框架从豆瓣电影top250网站爬取全部上榜的电影信息,并将电影的名称、评分、排名、一句影评、剧情简介分别保存都mysql 和mongodb 库里面。

douban.py
import scrapy # 导入scrapy库
from scrapy import Selector, Request # 从scrapy库中导入Selector和Request类
from scrapy.http import HtmlResponse # 从scrapy库中导入HtmlResponse类
from ..items import DoubanspidersItem # 从当前目录下的items模块中导入DoubanspidersItem类class DoubanSpider(scrapy.Spider): # 定义一个名为DoubanSpider的爬虫类,继承自scrapy.Spidername = 'douban' # 设置爬虫的名称为'douban'allowed_domains = ['movie.douban.com'] # 设置允许爬取的域名为'movie.douban.com'# start_urls = ['http://movie.douban.com/top250'] # 设置起始URL,但注释掉了,所以不会自动开始爬取def start_requests(self): # 定义start_requests方法,用于生成初始请求for page in range(10): # 循环10次,每次生成一个请求,爬取豆瓣电影Top250的前10页数据yield Request(url=f'https://movie.douban.com/top250?start={page * 25}&filt=') # 使用yield关键字返回请求对象,Scrapy会自动处理请求并调用回调函数def parse(self, response: HtmlResponse, **kwargs): # 定义parse方法,用于解析响应数据sel = Selector(response) # 使用Selector类解析响应数据list_items = sel.css('#content > div > div.article > ol > li') # 使用CSS选择器提取电影列表项for list_item in list_items: # 遍历电影列表项detail_url = list_item.css('div.info > div.hd > a::attr(href)').extract_first() # 提取电影详情页的URLmovie_item = DoubanspidersItem() # 创建一个DoubanspidersItem实例movie_item['name'] = list_item.css('span.title::text').extract_first() # 提取电影名称movie_item['score'] = list_item.css('span.rating_num::text').extract_first() # 提取电影评分movie_item['top'] = list_item.css('div.pic em ::text').extract_first() # 提取电影排名yield Request( # 使用yield关键字返回请求对象,Scrapy会自动处理请求并调用回调函数url=detail_url, callback=self.parse_movie_info, cb_kwargs={'item': movie_item})def parse_movie_info(self, response, **kwargs): # 定义parse_movie_info方法,用于解析电影详情页数据movie_item = kwargs['item'] # 获取传入的DoubanspidersItem实例sel = Selector(response) # 使用Selector类解析响应数据movie_item['comment'] = sel.css('div.comment p.comment-content span.short::text').extract_first() # 提取电影评论movie_item['introduction'] = sel.css('span[property="v:summary"]::text').extract_first().strip() or '' # 提取电影简介yield movie_item # 返回处理后的DoubanspidersItem实例,Scrapy会自动处理并保存结果
items.py
import scrapyclass DoubanspidersItem(scrapy.Item):# define the fields for your item here like:# name = scrapy.Field()# passtop = scrapy.Field()name = scrapy.Field()score = scrapy.Field()introduction = scrapy.Field()comment = scrapy.Field()pipelines.py
from itemadapter import ItemAdapter
import openpyxl
import pymysqlclass DoubanspidersPipeline:def __init__(self):self.conn = pymysql.connect(host='localhost',port=3306,user='root',password='789456MLq',db='sx_douban250',charset='utf8mb4')self.cursor = self.conn.cursor()self.data = []def close_spider(self,spider):if len(self.data) > 0:self._write_to_db()self.conn.close()def process_item(self, item, spider):self.data.append((item['top'],item['name'],item['score'],item['introduction'],item['comment']))if len(self.data) == 100:self._writer_to_db()self.data.clear()return itemdef _writer_to_db(self):self.cursor.executemany('insert into doubantop250 (top,name,score,introduction,comment)''values (%s,%s,%s,%s,%s)',self.data)self.conn.commit()from pymongo import MongoClientclass MyMongoDBPipeline:def __init__(self):self.client = MongoClient('mongodb://localhost:27017/')self.db = self.client['sx_douban250']self.collection = self.db['doubantop250']self.data = []def close_spider(self, spider):if len(self.data) > 0:self._write_to_db()self.client.close()def process_item(self, item, spider):self.data.append({'top': item['top'],'name': item['name'],'score': item['score'],'introduction': item['introduction'],'comment': item['comment']})if len(self.data) == 100:self._write_to_db()self.data.clear()return itemdef _write_to_db(self):self.collection.insert_many(self.data)self.data.clear()class ExcelPipeline:def __init__(self):self.wb = openpyxl.Workbook()self.ws = self.wb.activeself.ws.title = 'Top250'self.ws.append(('排名','评分','主题','简介','评论'))def open_spider(self,spider):passdef close_spider(self,spider):self.wb.save('豆瓣Top250.xlsx')def process_item(self,item,spider):self.ws.append((item['top'], item['name'], item['score'], item['introduction'], item['comment']))return itemsettings.py相关内容修改


相关文章:
大三上实训内容
项目一:爬取天气预报数据 【内容】 在中国天气网(http://www.weather.com.cn)中输入城市的名称,例如输入信阳,进入http://www.weather.com.cn/weather1d/101180601.shtml#input 的网页显示信阳的天气预报,其中101180601是信阳的…...

IOT安全学习路标
1. 物联网基础知识 首先,你需要建立坚实的物联网基础知识,包括IoT的架构和组件,传感器和设备的连接和通信技术,云端和边缘计算等。 2. 通信和网络安全 学习关于物联网通信和网络安全的基础知识,包括加密和认证技术、…...

java中线程的状态是如何转换的?
在 Java 中,线程有几种状态,主要包括 NEW(新建)、RUNNABLE(可运行)、BLOCKED(阻塞)、WAITING(等待)、TIMED_WAITING(计时等待)、和 TE…...

处理合并目录下的Excel文件数据并指定列去重
处理合并目录下的Excel文件数据并指定列去重 需求:读取指定目录下的Excel文件并给数据做合并与去重处理 Python代码实现 import os import pandas as pd import warnings import time from tqdm import tqdm #进度条展示def read_excel(path):dfs []for file in…...

Numpy数组的去重 np.unique()(第15讲)
Numpy数组的去重 np.unique()(第15讲) 🍹博主 侯小啾 感谢您的支持与信赖。☀️ 🌹꧔ꦿ🌹꧔ꦿ🌹꧔ꦿ🌹꧔ꦿ🌹꧔ꦿ🌹꧔ꦿ🌹꧔ꦿ🌹꧔ꦿ🌹꧔ꦿ🌹꧔ꦿ🌹꧔ꦿ🌹꧔ꦿ🌹꧔ꦿ🌹꧔ꦿ🌹꧔ꦿ🌹꧔ꦿ🌹꧔ꦿ🌹꧔ꦿ🌹꧔ꦿ🌹꧔ꦿ�…...

ROS-log功能区别
ROS使用rosout包来记录各个节点的log信息,通常这些log信息是一些可以读懂的字符串信息,这些信息一般用来记录节点的运行状态。 ROS有五种不同类型的log信息,分别为:logdebug、loginfo、logwarn、logerr、logfatal。 等级由低到高&…...

学习git后,真正在项目中如何使用?
文章目录 前言下载和安装Git克隆远程仓库PyCharm链接本地Git创建分支修改项目工程并提交到本地仓库推送到远程仓库小结 前言 网上学习git的教程,甚至还有很多可视化很好的git教程,入门git也不是什么难事。但我发现,当我真的要从网上克隆一个…...
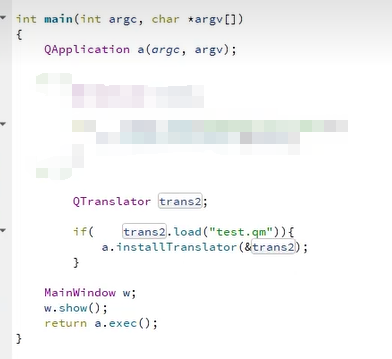
Qt国际化翻译Linguist使用
QT的国际化是非常方便的,简单的说就是QT有自带的翻译工具把我们源代码中的字符串翻译成任何语言文件,再把这个语言文件加载到项目中就可以显示不同的语言。下面直接上手: 步骤一:打开pro文件,添加:TRANSLA…...

ShardingSphere数据分片之分表操作
1、概述 Apache ShardingSphere 是一款分布式的数据库生态系统, 可以将任意数据库转换为分布式数据库,并通过数据分片、弹性伸缩、加密等能力对原有数据库进行增强。 Apache ShardingSphere 设计哲学为 Database Plus,旨在构建异构数据库上…...
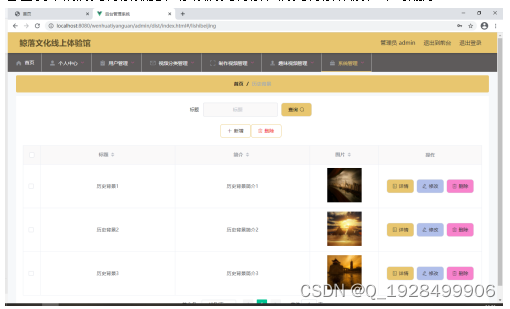
基于ssm鲸落文化线上体验馆论文
摘 要 现代经济快节奏发展以及不断完善升级的信息化技术,让传统数据信息的管理升级为软件存储,归纳,集中处理数据信息的管理方式。本鲸落文化线上体验馆就是在这样的大环境下诞生,其可以帮助管理者在短时间内处理完毕庞大的数据信…...

LeetCode Hot100 131.分割回文串
题目: 给你一个字符串 s,请你将 s 分割成一些子串,使每个子串都是 回文串 。返回 s 所有可能的分割方案。 回文串 是正着读和反着读都一样的字符串。 方法:灵神-子集型回溯 假设每对相邻字符之间有个逗号,那么就看…...
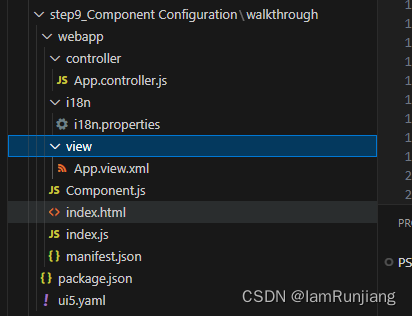
SAP UI5 walkthrough step9 Component Configuration
在之前的章节中,我们已经介绍完了MVC的架构和实现,现在我们来讲一下,SAPUI5的结构 这一步,我们将所有的UI资产从index.html里面独立封装在一个组件里面 这样组件就变得独立,可复用了。这样,无所什么时候我…...
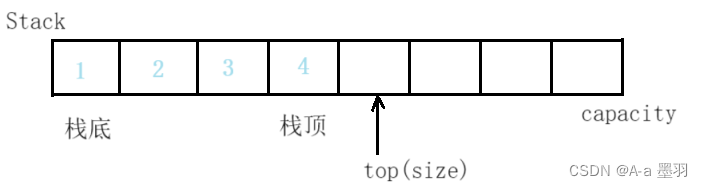
【数据结构和算法】--- 栈
目录 栈的概念及结构栈的实现初始化栈入栈出栈其他一些栈函数 小结栈相关的题目 栈的概念及结构 栈是一种特殊的线性表。相比于链表和顺序表,栈只允许在固定的一端进行插入和删除元素操作。进行数据插入和删除操作的一端称为栈顶,另一端称为栈底。栈中的…...

CentOS7.0 下rpm安装MySQL5.5.60
下载 下载路径: MySQL :: Download MySQL Community Server -->looking for the latest GA version-->5.5.60 此压缩包中有多个rpm包 有四个不是必须的,只需安装这三个 MySQL-server-5.5.60-1.el6.x86_64 MySQL-devel-5.5.60-1.el6.x86_64 MySQL-client-5.5.60-1.el6.x8…...

智慧能源:数字孪生压缩空气储能管控平台
压缩空气储能在解决可再生能源不稳定性和提供可靠能源供应方面具有重要的优势。压缩空气储能,是指在电网负荷低谷期将电能用于压缩空气,在电网负荷高峰期释放压缩空气推动汽轮机发电的储能方式。通过提高能量转换效率、增加储能密度、快速启动和调节能力…...

【链表OJ—反转链表】
提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档 目录 前言 1、反转链表题目: 2、方法讲解: 解法一: 解法二: 总结 前言 世上有两种耀眼的光芒,一种是正在升起的太…...
TCP一对一聊天
客户端 import java.awt.BorderLayout; import java.awt.Color; import java.awt.Dimension; import java.awt.Font; import java.awt.event.ActionEvent; import java.awt.event.ActionListener; import java.io.BufferedReader; import java.io.IOException; import java.io…...
基于Java的招聘系统的设计与实现
末尾获取源码 开发语言:Java Java开发工具:JDK1.8 后端框架:SSM 前端:Vue 数据库:MySQL5.7和Navicat管理工具结合 服务器:Tomcat8.5 开发软件:IDEA / Eclipse 是否Maven项目:是 目录…...

spring boot整合mybatis进行部门管理管理的增删改查
部门列表查询: 功能实现: 需求:查询数据库表中的所有部门数据,展示在页面上。 准备工作: 准备数据库表dept(部门表),实体类Dept。在项目中引入mybatis的起步依赖,mysql的…...

微软 Power Platform 零基础 Power Pages 网页搭建高阶实际案例实践(四)
微软 Power Platform 零基础 Power Pages 网页搭建教程之高阶案例实践学习(四) Power Pages 实际案例学习进阶 微软 Power Platform 零基础 Power Pages 网页搭建教程之高阶案例实践学习(四)1、新增视图,添加List页面2…...

如何用500KB工具完全替代AWCC:AlienFX Tools终极指南
如何用500KB工具完全替代AWCC:AlienFX Tools终极指南 【免费下载链接】alienfx-tools Alienware systems lights, fans, and power control tools and apps 项目地址: https://gitcode.com/gh_mirrors/al/alienfx-tools 你是否厌倦了Alienware Command Cente…...

别急着买内存条!先花5分钟用Win自带工具查清你的笔记本有几个卡槽、最大支持多少G
笔记本内存升级避坑指南:5分钟摸清扩容上限与双通道配置每次打开浏览器标签超过十个就开始卡顿,PS处理图片时进度条仿佛在爬行,剪辑视频时渲染时间足够泡一杯咖啡——这些场景是否让你动了升级笔记本内存的念头?先别急着下单&…...

2023B卷,最佳植树距离
👨⚕️ 主页: gis分享者 👨⚕️ 感谢各位大佬 点赞👍 收藏⭐ 留言📝 加关注✅! 👨⚕️ 收录于专栏:华为OD面试 文章目录 一、🍀前言 1.1 ☘️题目详情 1.2 ☘️参考解题答案 一、🍀前言 2023B卷,最佳植树距离。 1.1 ☘️题目详情 题目: 小明在直…...
)
别再死记硬背公式了!用UE5的Lerp节点玩转材质混合(附灰度图实战案例)
别再死记硬背公式了!用UE5的Lerp节点玩转材质混合(附灰度图实战案例)在游戏开发中,材质混合是创造丰富视觉效果的关键技术。对于Unreal Engine 5的初学者来说,LinearInterpolate(简称Lerp)节点可…...

机器学习预测细菌耐药性:从全基因组数据到公共卫生预警
1. 项目概述与核心价值抗菌药物耐药性(AMR)这事儿,现在谁提起来都头疼。它不再是实验室报告上的一个数字,而是直接关系到我们每个人生病了还有没有药可用的现实问题。弯曲杆菌,这个听起来有点拗口的名字,其…...

抖音下载神器终极指南:免费批量下载视频、直播回放和音乐原声
抖音下载神器终极指南:免费批量下载视频、直播回放和音乐原声 【免费下载链接】douyin-downloader A practical Douyin downloader for both single-item and profile batch downloads, with progress display, retries, SQLite deduplication, and browser fallbac…...

CTF实战:手把手教你用phar伪协议绕过NSS靶场文件上传限制
CTF实战:手把手教你用phar伪协议绕过NSS靶场文件上传限制 在网络安全竞赛和渗透测试中,文件上传漏洞一直是高频考点。今天我们将深入探讨如何利用PHP的phar伪协议,绕过NSSCTF平台"bingdundun"题目的文件上传限制,实现远…...
)
告别Godot默认编辑器:手把手教你用VSCode配置C#开发环境(解决中文乱码)
告别Godot默认编辑器:手把手教你用VSCode配置C#开发环境(解决中文乱码)当你在Godot中编写C#脚本时,是否曾为默认编辑器的功能限制感到困扰?代码补全不够智能、调试功能简陋、界面不够友好——这些问题都会显著降低开发…...

基于强化学习的量子传感器电路优化:多目标权衡与工程实践
1. 量子传感器电路优化的核心挑战与机遇量子传感器,这个听起来有些科幻的名词,正逐渐从实验室走向现实应用的前沿。它的核心魅力在于,能够利用量子力学中那些“反直觉”的特性——比如叠加和纠缠——来感知我们周围世界极其微小的变化&#x…...

显示what failed:VMMR0.r0--已解决
VirtualBox版本5.2.44 win11家庭中文版 以下是已经尝试内核隔离无用的情况下,所写出的解决方案。 winR,输入services.msc 禁用该服务后 管理员身份打开cmd,输入bcdedit /set hypervisorlaunchtype off 重启后确认查看方式 ①管理员身…...