【小沐学Python】Python实现语音识别(Whisper)
文章目录
- 1、简介
- 1.1 whisper简介
- 1.2 whisper模型
- 2、安装
- 2.1 whisper
- 2.2 pytorch
- 2.3 ffmpeg
- 3、测试
- 3.1 命令测试
- 3.2 代码测试:识别声音文件
- 3.3 代码测试:实时录音识别
- 结语
1、简介
https://github.com/openai/whisper

1.1 whisper简介
Whisper 是一种通用的语音识别模型。它是在包含各种音频的大型数据集上训练的,也是一个多任务模型,可以执行多语言语音识别、语音翻译和语言识别。
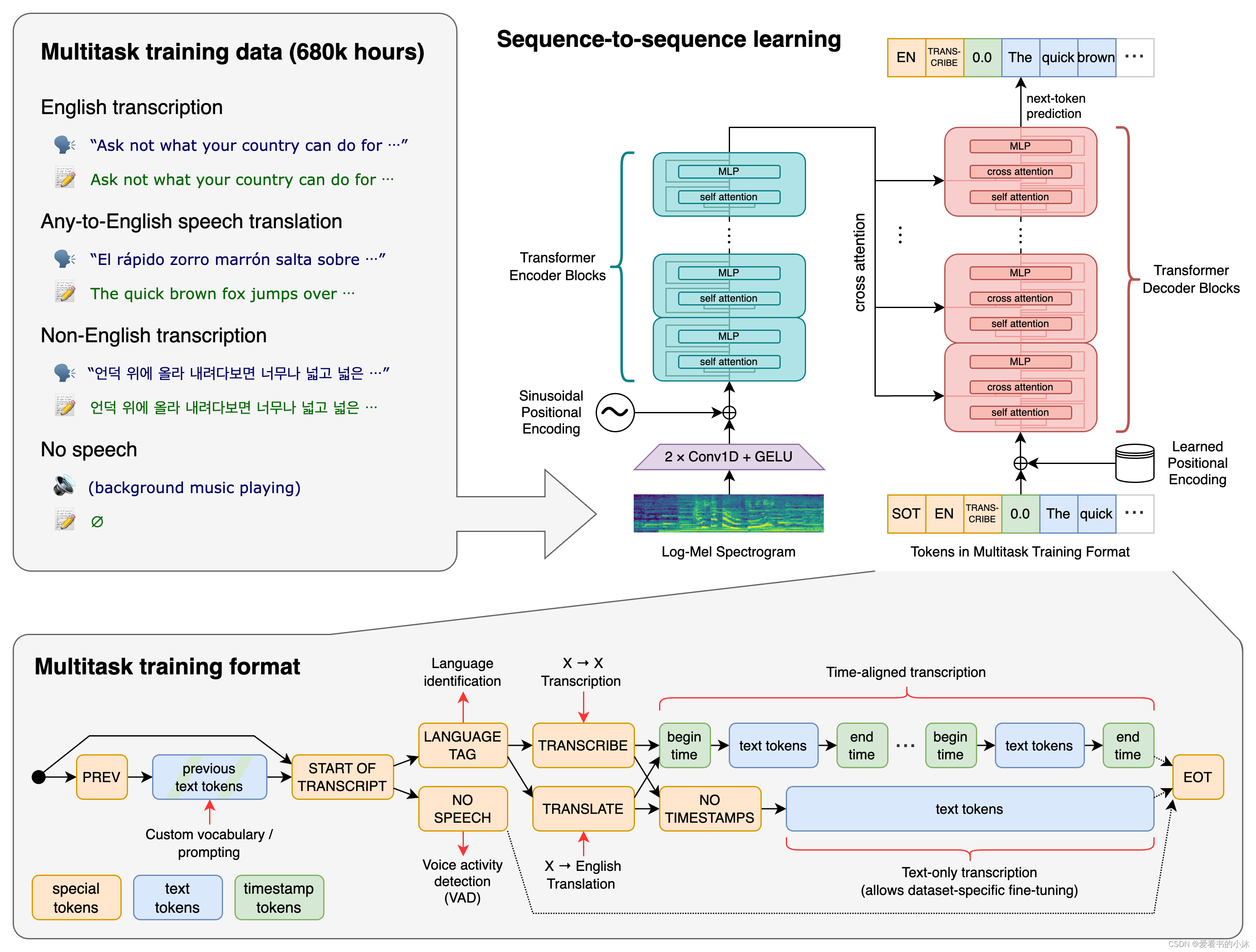
Open AI在2022年9月21日开源了号称其英文语音辨识能力已达到人类水准的Whisper神经网络,且它亦支持其它98种语言的自动语音辨识。 Whisper系统所提供的自动语音辨识(Automatic Speech Recognition,ASR)模型是被训练来运行语音辨识与翻译任务的,它们能将各种语言的语音变成文本,也能将这些文本翻译成英文。
1.2 whisper模型
以下是可用模型的名称及其相对于大型模型的近似内存要求和推理速度;实际速度可能因许多因素而异,包括可用的硬件。
| Size | Parameters | English-only model | Multilingual model | Required VRAM | Relative speed |
|---|---|---|---|---|---|
| tiny | 39 M | tiny.en | tiny | ~1 GB | ~32x |
| base | 74 M | base.en | base | ~1 GB | ~16x |
| small | 244 M | small.en | smal | l ~2 GB | ~6x |
| medium | 769 M | medium.en | medium | ~5 GB | ~2x |
| large | 1550 M | N/A | large | ~10 GB | 1x |
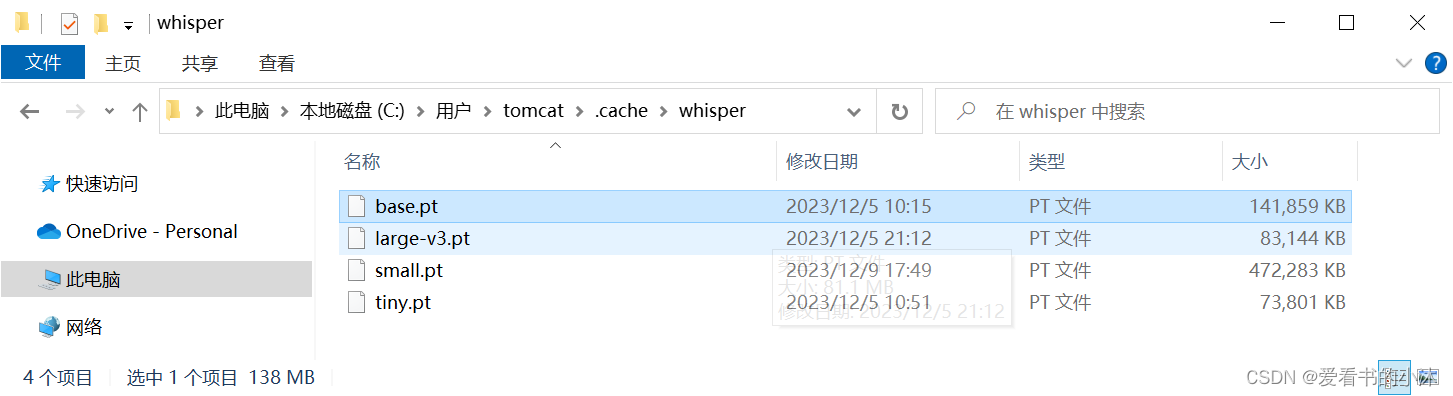
它自动下载的模型缓存,如下:
2、安装
2.1 whisper
pip install -U openai-whisper
# pip install git+https://github.com/openai/whisper.git
pip install --upgrade --no-deps --force-reinstall git+https://github.com/openai/whisper.git
pip install zhconv
pip3 install wheelpip3 install torch torchvision torchaudio
# 注:没科学上网会下载有可能很慢,可以替换成国内镜像加快下载速度
pip3 install torch torchvision torchaudio -i https://pypi.tuna.tsinghua.edu.cn/simple
2.2 pytorch
https://pytorch.org/
选择的是稳定版,windows系统,pip安装方式,python语言、cpu版本的软件。
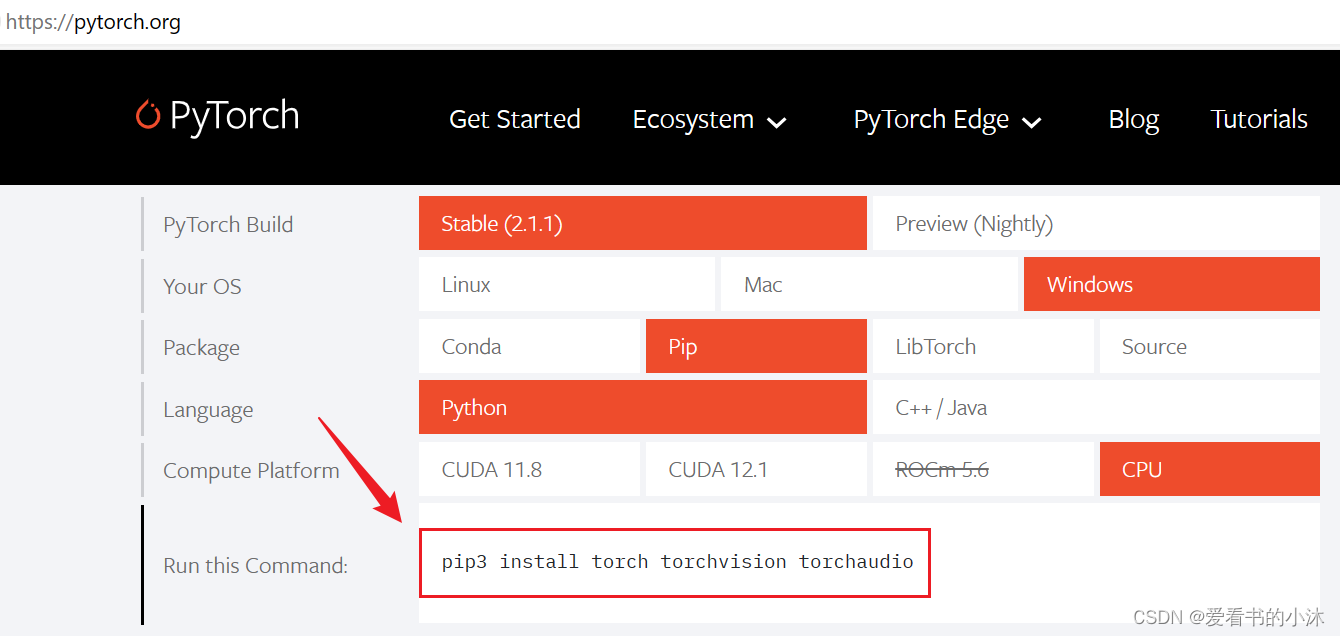
pip3 install torch torchvision torchaudio
2.3 ffmpeg
https://github.com/BtbN/FFmpeg-Builds/releases
解压后,找到bin文件夹下的“ffmpeg.exe”,将它复制到一个文件夹中,假设这个文件夹的路径是"D:\software\ffmpeg",然后将"D:/software/ffmpeg"添加到系统环境变量PATH。
3、测试
3.1 命令测试
whisper audio.mp3
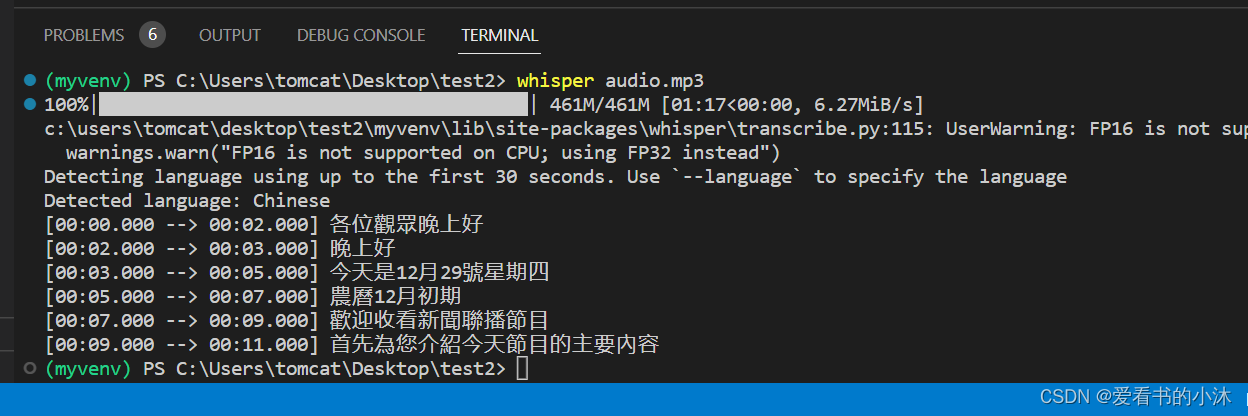
以上whisper audio.mp3的命令形式是最简单的一种,它默认使用的是small模式的模型转写,我们还可以使用更高等级的模型来提高正确率。 比如:
whisper audio.mp3 --model medium
whisper japanese.wav --language Japanese
whisper chinese.mp4 --language Chinese --task translate
whisper audio.flac audio.mp3 audio.wav --model medium
whisper output.wav --model medium --language Chinese
同时默认会生成5个文件,文件名和你的源文件一样,但扩展名分别是:.json、.srt、.tsv、.txt、.vtt。除了普通文本,也可以直接生成电影字幕,还可以调json格式做开发处理。
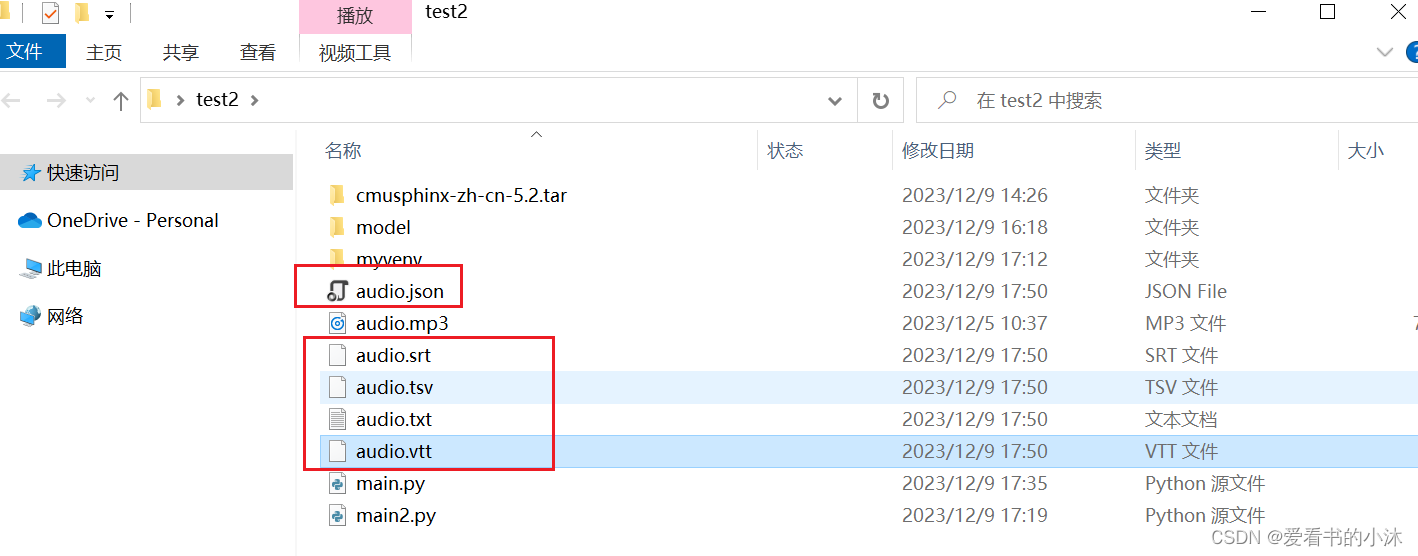
常用参数如下:
--task: 指定转录方式,默认使用 --task transcribe 转录模式,--task translate 则为 翻译模式,目前只支持翻译成英文。
--model:指定使用模型,默认使用 --model small,Whisper 还有 英文专用模型,就是在名称后加上 .en,这样速度更快。
--language:指定转录语言,默认会截取 30 秒来判断语种,但最好指定为某种语言,比如指定中文是 --language Chinese。
--device:指定硬件加速,默认使用 auto 自动选择,--device cuda 则为显卡,cpu 就是 CPU, mps 为苹果 M1 芯片。
--output_format:指定字幕文件的生成格式,txt,vtt,srt,tsv,json,all,指定多个可以用大括号{}包裹,不设置默认all。
-- output_dir: 指定字幕文件的输出目录,不设置默认输出到当前目录下。
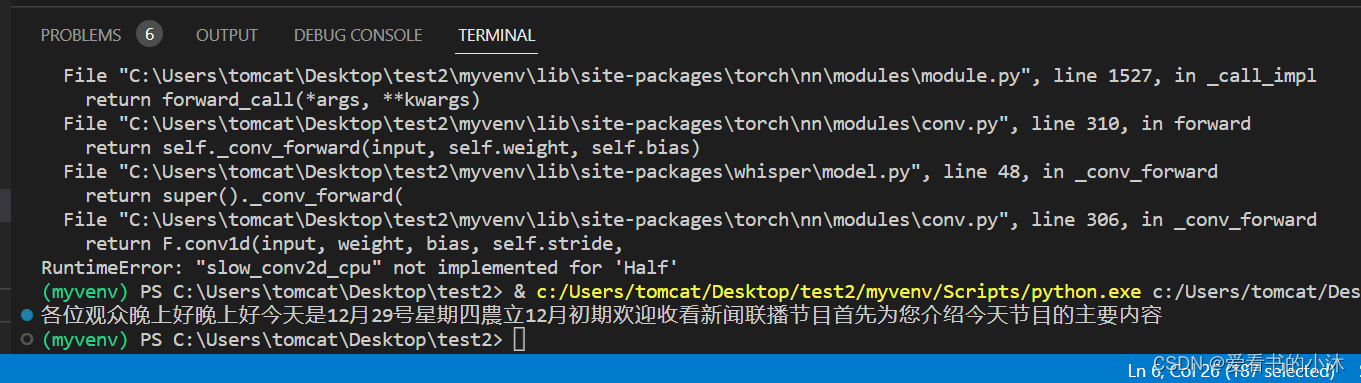
--fp16:默认True,使用16位浮点数进行计算,可以在一定程度上减少计算和存储开销,可能存在精度丢失,笔者CPU不支持,会出现下述警告,指定它为False就不会出现了,即采用32位浮点数进行计算。
3.2 代码测试:识别声音文件
import whisperif __name__ == '__main__':model = whisper.load_model("tiny")result = model.transcribe("audio.mp3", fp16=False, language="Chinese")print(result["text"])
3.3 代码测试:实时录音识别
import whisper
import zhconv
import wave # 使用wave库可读、写wav类型的音频文件
import pyaudio # 使用pyaudio库可以进行录音,播放,生成wav文件def record(time): # 录音程序# 定义数据流块CHUNK = 1024 # 音频帧率(也就是每次读取的数据是多少,默认1024)FORMAT = pyaudio.paInt16 # 采样时生成wav文件正常格式CHANNELS = 1 # 音轨数(每条音轨定义了该条音轨的属性,如音轨的音色、音色库、通道数、输入/输出端口、音量等。可以多个音轨,不唯一)RATE = 16000 # 采样率(即每秒采样多少数据)RECORD_SECONDS = time # 录音时间WAVE_OUTPUT_FILENAME = "./output.wav" # 保存音频路径p = pyaudio.PyAudio() # 创建PyAudio对象stream = p.open(format=FORMAT, # 采样生成wav文件的正常格式channels=CHANNELS, # 音轨数rate=RATE, # 采样率input=True, # Ture代表这是一条输入流,False代表这不是输入流frames_per_buffer=CHUNK) # 每个缓冲多少帧print("* recording") # 开始录音标志frames = [] # 定义frames为一个空列表for i in range(0, int(RATE / CHUNK * RECORD_SECONDS)): # 计算要读多少次,每秒的采样率/每次读多少数据*录音时间=需要读多少次data = stream.read(CHUNK) # 每次读chunk个数据frames.append(data) # 将读出的数据保存到列表中print("* done recording") # 结束录音标志stream.stop_stream() # 停止输入流stream.close() # 关闭输入流p.terminate() # 终止pyaudiowf = wave.open(WAVE_OUTPUT_FILENAME, 'wb') # 以’wb‘二进制流写的方式打开一个文件wf.setnchannels(CHANNELS) # 设置音轨数wf.setsampwidth(p.get_sample_size(FORMAT)) # 设置采样点数据的格式,和FOMART保持一致wf.setframerate(RATE) # 设置采样率与RATE要一致wf.writeframes(b''.join(frames)) # 将声音数据写入文件wf.close() # 数据流保存完,关闭文件if __name__ == '__main__':model = whisper.load_model("tiny")record(3) # 定义录音时间,单位/sresult = model.transcribe("output.wav",language='Chinese',fp16 = True)s = result["text"]s1 = zhconv.convert(s, 'zh-cn')print(s1)
结语
如果您觉得该方法或代码有一点点用处,可以给作者点个赞,或打赏杯咖啡;╮( ̄▽ ̄)╭
如果您感觉方法或代码不咋地//(ㄒoㄒ)//,就在评论处留言,作者继续改进;o_O???
如果您需要相关功能的代码定制化开发,可以留言私信作者;(✿◡‿◡)
感谢各位大佬童鞋们的支持!( ´ ▽´ )ノ ( ´ ▽´)っ!!!
相关文章:
【小沐学Python】Python实现语音识别(Whisper)
文章目录 1、简介1.1 whisper简介1.2 whisper模型 2、安装2.1 whisper2.2 pytorch2.3 ffmpeg 3、测试3.1 命令测试3.2 代码测试:识别声音文件3.3 代码测试:实时录音识别 结语 1、简介 https://github.com/openai/whisper 1.1 whisper简介 Whisper 是…...
Nginx负载均衡实战
🎵负载均衡组件 ngx_http_upstream_module https://nginx.org/en/docs/http/ngx_http_upstream_module.html upstream模块允许Nginx定义一组或多组节点服务器组,使用时可以通过多种方式去定义服务器组 样例: upstream backend {server back…...
)
Redis skiplist源码解析(支持范围查询)
跳表是一个多层的有序链表,在跳表中进行查询操作时,查询代码可以从最高层开始查询。层数越高,结点数越少,同时高层结点的跨度会比较大。因此,在高层查询结点时,查询一个结点可能就已经查到了链表的中间位置…...
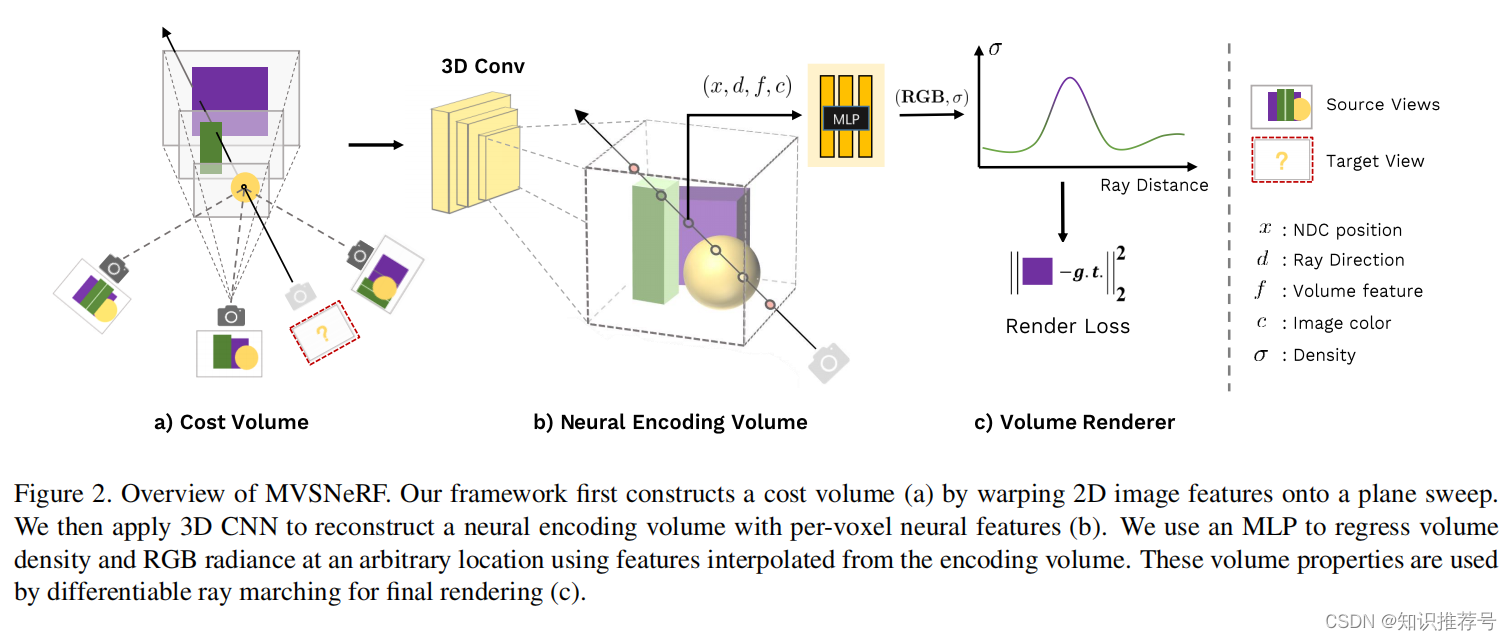
MVSNeRF:多视图立体视觉的快速推广辐射场重建(2021年)
MVSNeRF:多视图立体视觉的快速推广辐射场重建(2021年) 摘要1 引言2 相关工作3 MVSNeRF实现方法3.1 构建代价体3.2 辐射场的重建3.3 体渲染和端到端训练 3.4 优化神经编码体 Anpei Chen and Zexiang Xu and Fuqiang Zhao et al. MVSNeRF: Fast…...
)
华为OD机试真题-CPU算力分配-2023年OD统一考试(C卷)
题目描述: 现有两组服务器A和B,每组有多个算力不同的CPU,其中A[i]是A组第i个CPU的运算能力,B[i]是B组第i个CPU的运算能力。一组服务器的总算力是各CPU的算力之和。为了让两组服务器的算力相等,允许从每组各选出一个CPU进行一次交换,求两组服务器中,用于交换的CPU的算力,…...
)
校验数据是否重叠(各种操作符>,<,>=,<=,or,and)
最近接到一个需求,其中部分功能涉及到数据的重叠校验,并且录入的数据需要包含各种操作符。如果只通过java代码来查询并进行循环判断的话,判断情况会很复杂,幸好有同事的帮忙提供了一个用sql查询重叠部分的方法,现在分享…...

大一C语言作业 12.8
1.C 对一维数组初始化时,如果全部元素都赋了初值,可以省略数组长度。 这里没有指定数组长度,编译器会根据初始化列表的元素个数来确定数组长度。 2.C 在C语言中,字符数组是不能用赋值运算符直接赋值的。 3.C 在二维数组a中&#x…...
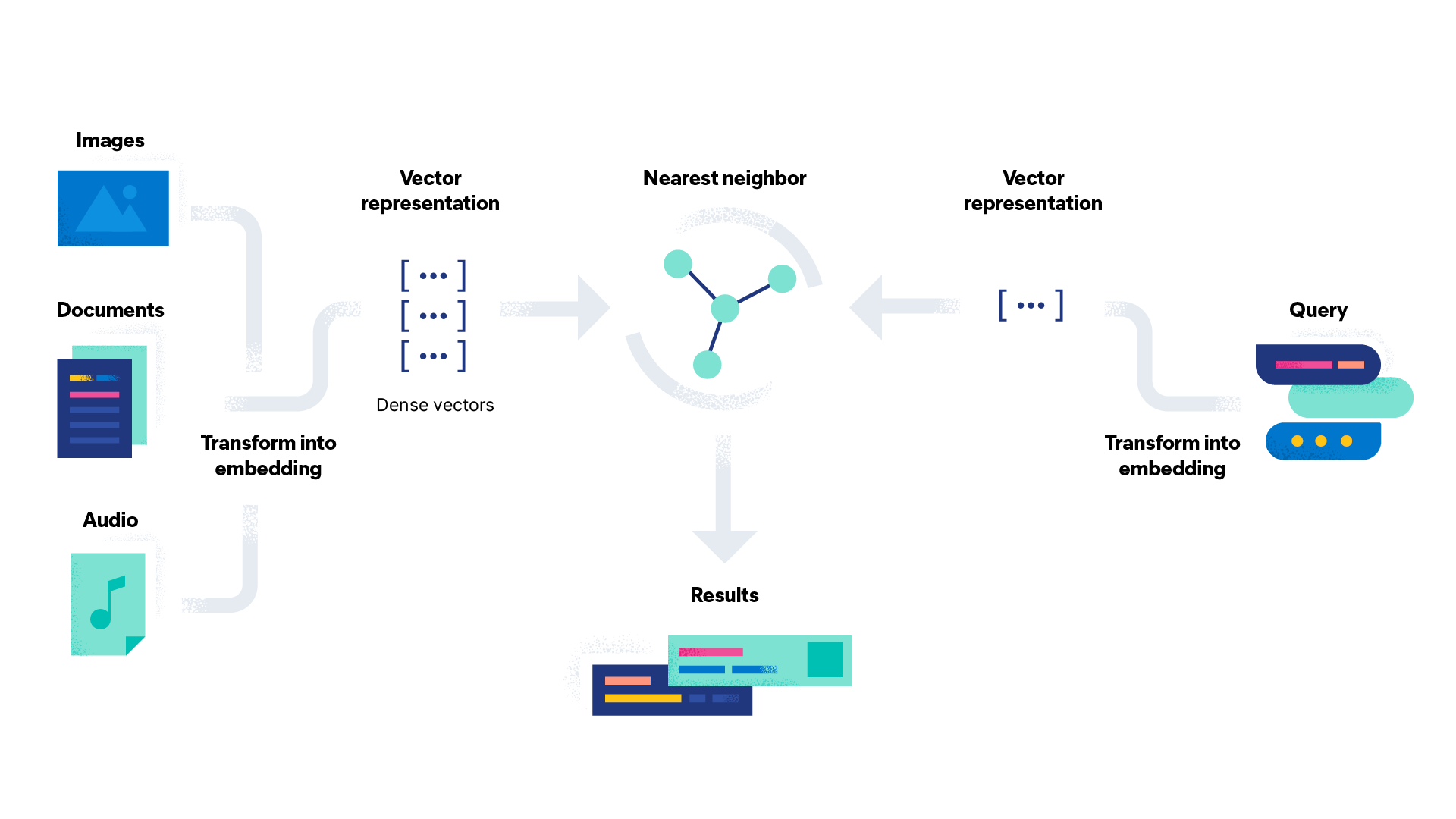
ELasticsearch:什么是语义搜索?
语义搜索定义 语义搜索是一种解释单词和短语含义的搜索引擎技术。 语义搜索的结果将返回与查询含义匹配的内容,而不是与查询中的单词字面匹配的内容。 语义搜索是一组搜索引擎功能,其中包括根据搜索者的意图及其搜索上下文理解单词。 此类搜索旨在通过…...

ooTD I 女儿是自己的,尽情打扮尽情可爱
分享女宝的时尚穿搭 奶乎乎的黄色也太好看了 超足充绒量+优质面料 柔软蓬松上身体验感超赞 怎么穿都好看系列 轻轻松松打造时尚造型!!...
)
第62天:django学习(十一)
cookie和session 发展史 一开始,只有一个页面,没有登录功能,大家看到东西都一样。 时代发展,出现了需要登录注册的网站,要有一门技术存储我们的登录信息,于是cookie诞生了。 cookie: - 存储形式:k:v键值对…...
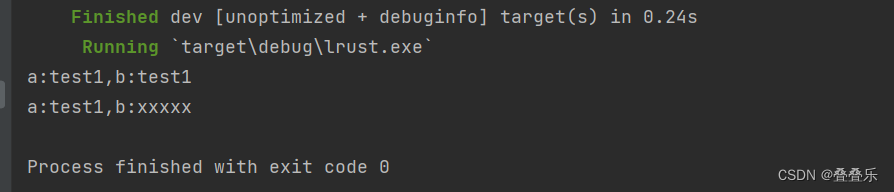
Rust测试字符串的移动,Move
代码创建了一个结构体,结构体有test1 字符串,还有指向字符串的指针。一共创建了两个。 然后我们使用swap 函数 交换两个结构体内存的内容。 最后如上图。相同的地址,变成了另外结构体的内容。注意看指针部分,还是指向原来的地址…...
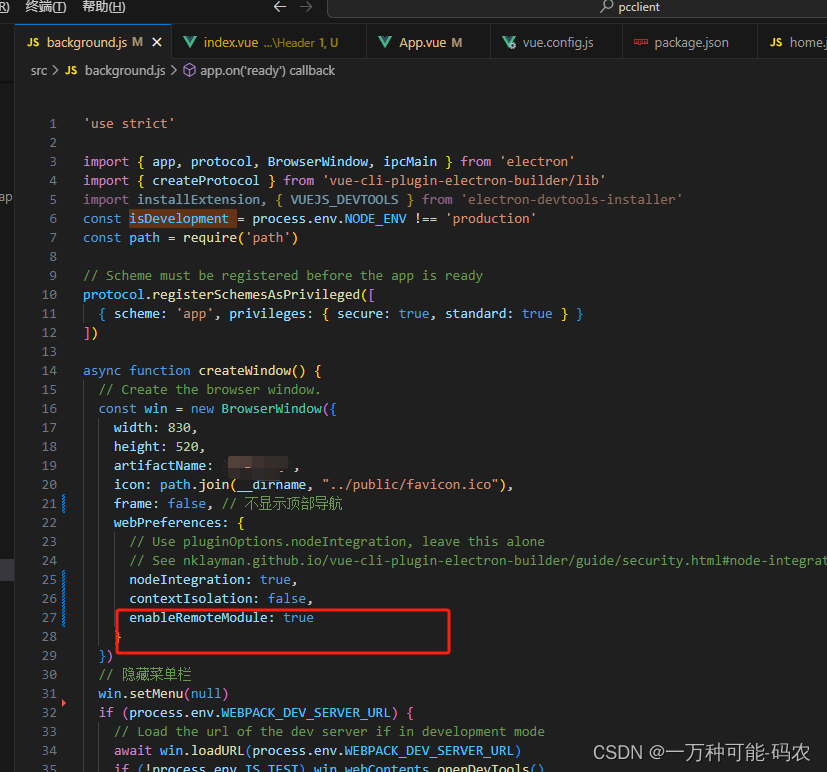
vue+electron问题汇总
1. Vue_Bug Failed to fetch extension, trying 4 more times 描述:项目启动时报错 解决:注释图片中内容 2. Module not found: Error: Can’t resolve ‘fs’ in 描述:项目启动报错 解决:vue.config.js中添加图中数据 3.导入…...
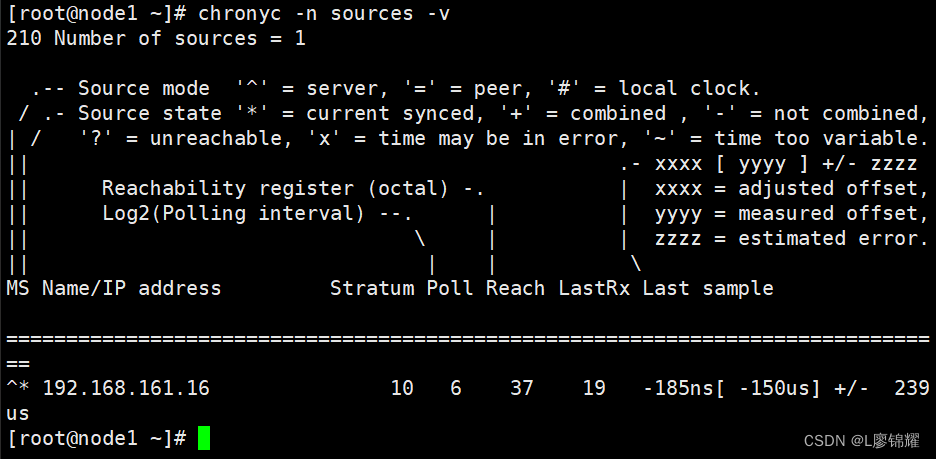
Linux中的网络时间服务器
本章主要介绍网络时间的服务器 使用chrony配置时间服务器配置chrony客户端服务器同步时间 1.1 时间同步的重要性 一些服务对时间要求非常严格,例如如图所示的由三台服务器搭建的ceph集群 这三台服务器的时间必须保持一致,如果不一致,就会显…...

fastadmin打印页面
如下图选中订单号进行打印 html中增加代码 <div id"toolbar" class"toolbar"><a href"javascript:;" class"btn btn-primary btn-refresh" title"{:__(Refresh)}" ><i class"fa fa-refresh">&l…...

Java 将word转为PDF的三种方式和处理在服务器上下载后乱码的格式
我这边是因为业务需要将之前导出的word文档转换为PDF文件,然后页面预览下载这样的情况。之前导出word文档又不是我做的,所以为了不影响业务,只是将最后在输出流时转换成了PDF,当时本地调用没什么问题,一切正常…...

C\C++ 获取最值
C C 语言的不同类型的最值可以在 limits.h 头文件里找到定义 #include <limits.h>int main() {printf("%d", INT_MAX); // 整数最大值printf("%d", INT_MIN); // 整数最小值 } C C 有模板,可以通过替换下面的 int 和 doubleÿ…...

机器学习之无监督学习:九大聚类算法
今天,和大家分享一下机器学习之无监督学习中的常见的聚类方法。 今天,和大家分享一下机器学习之无监督学习中的常见的聚类方法。 在无监督学习中,我们的数据并不带有任何标签,因此在无监督学习中要做的就是将这一系列无标签的数…...
Linux高级管理-搭建网站服务
在Ihternet 网络环境中,Web 服务无疑是最为流行的应用系统。有了Web站点,企业可以充分 展示自己的产品,宣传企业形象。Web站点还为企业提供了与客户交流、电子商务交易平台等丰富 的网络应用。部署与维护Web 服务是运维工程师必须掌握的一个技…...
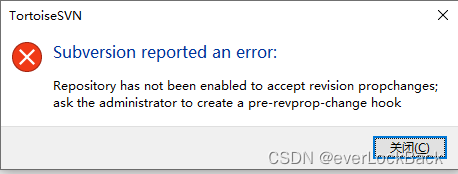
Windows 系统,TortoiseSVN 无法修改 Log 信息解决方法
使用SVN提交版本信息时,注释内容写的不全。通过右键TortoiseSVN的Show log看到提交的的注释,右键看到Edit log message的选项,然而提交后却给出错误提示: Repository has not been enabled to accept revision propchanges; ask …...

编译 Android gradle-4.6-all.zip 报错问题记录
编译 Android gradle-4.6-all.zip 报错问题记录 方法一:替换资源:方法二:修改源方法三:修改版本 编译时候无法下载 gradle-4.6-all Downloading https://services.gradle.org/distributions/gradle-4.6-all.zip 方法一…...

构建 AI Agent Harness Engineering 时常见的十个错误
构建 AI Agent Harness Engineering 时常见的十个错误 | 从翻车案例到生产级落地最佳实践 引入:85%的Agent上线失败,问题都出在「缰绳」上 2024年Q2,国内某股份制银行上线的智能理财顾问Agent,上线仅3天就触发了3起严重合规事故:风险承受能力等级为C1(最低风险等级)的用…...

Terraform 实战:用 for 表达式将列表元素转换为大写
Terraform 技巧:使用 for 表达式将列表元素转换为大写 在 Terraform 配置中,我们经常需要对列表中的字符串进行批量转换,例如将小写名称统一转为大写,以满足某些标签规范或命名约定。本文以 var.names 列表为例,演示如何通过 for 表达式结合 upper 函数,生成一个全大写的…...

C51开发中枚举类型安全与防御性编程实践
1. C51开发中的枚举类型陷阱与防御性编程实践在嵌入式C开发领域,Keil C51编译器因其对8051架构的深度优化而广受欢迎。但就像我十年前第一次使用typedef enum时踩过的坑一样,许多开发者会惊讶地发现:编译器竟然允许将任意整数值赋给枚举变量&…...
)
Unity 2D游戏地图制作:从零上手Tile Palette的7个核心工具(附快捷键清单)
Unity 2D游戏地图制作:从零上手Tile Palette的7个核心工具(附快捷键清单)在独立游戏开发领域,2D游戏因其独特的艺术风格和相对较低的开发门槛,始终保持着旺盛的生命力。无论是复古风格的平台跳跃游戏,还是精…...

Unity入门:从创建立方体理解组件化三维工作流
1. 这不是“Hello World”,而是你和Unity第一次真正握手很多人点开Unity安装包那一刻,以为接下来就是拖拽、点击、三分钟出效果——结果新建项目后面对空荡荡的Scene视图和一堆灰色面板,连“立方体在哪”都找不到。我带过三十多期Unity新手训…...

全波形反演新思路:大步长梯度优化器如何克服周波跳跃难题
1. 项目概述:当梯度优化器“大步快跑”时,它能跳出周波跳跃的陷阱吗?在地球物理勘探领域,全波形反演(FWI)被誉为速度建模的“圣杯”,它通过迭代匹配模拟地震数据与观测数据,来反推地…...

量子机器学习模拟器性能优化与门层特性解析
1. 量子机器学习模拟器的性能优化之道量子机器学习(QML)作为量子计算与经典机器学习的交叉领域,其核心挑战在于如何高效模拟量子电路的演化过程。传统量子模拟器如PennyLane的default.qubit采用通用方法处理各类量子门操作,未能充分考虑不同门类型的数学…...

企业官网后台的工程化设计:内容建模、所见即所得与源码自主可控
企业官网后台的工程化设计:内容建模、所见即所得与源码自主可控 “网站做完我们自己能改吗?要不要技术?”——这个业务问题,在工程层面其实是问:这套 CMS 的内容模型、编辑体验、权限和可维护性设计得怎么样。 后台&qu…...

Win10硬盘分区后盘符出现黄色感叹号?别慌,这是BitLocker在‘待机’,教你5分钟彻底关闭它
Win10硬盘分区后盘符出现黄色感叹号?5分钟解除BitLocker待机状态全指南当你完成Win10硬盘分区调整后,突然发现资源管理器中的盘符旁出现了醒目的黄色感叹号标志,这确实会让人心头一紧。别担心,这并非硬盘故障或数据丢失的征兆&…...

Qt应用AES/RSA加密监控:Frida+对象生命周期追踪框架
1. 这不是“又一个 Frida 教程”,而是一套可复用的逆向监控工程框架你有没有遇到过这样的场景:在分析一款 Qt 桌面客户端时,发现它用 AES 加密了用户登录凭证,用 RSA 加密了设备指纹,但所有加解密逻辑都藏在QByteArray…...