urllib爬虫 应用实例(三)
目录
一、 ajax的get请求豆瓣电影第一页
二、ajax的get请求豆瓣电影前十页
三、ajax的post请求肯德基官网
一、 ajax的get请求豆瓣电影第一页
目标:获取豆瓣电影第一页的数据,并保存为json文件
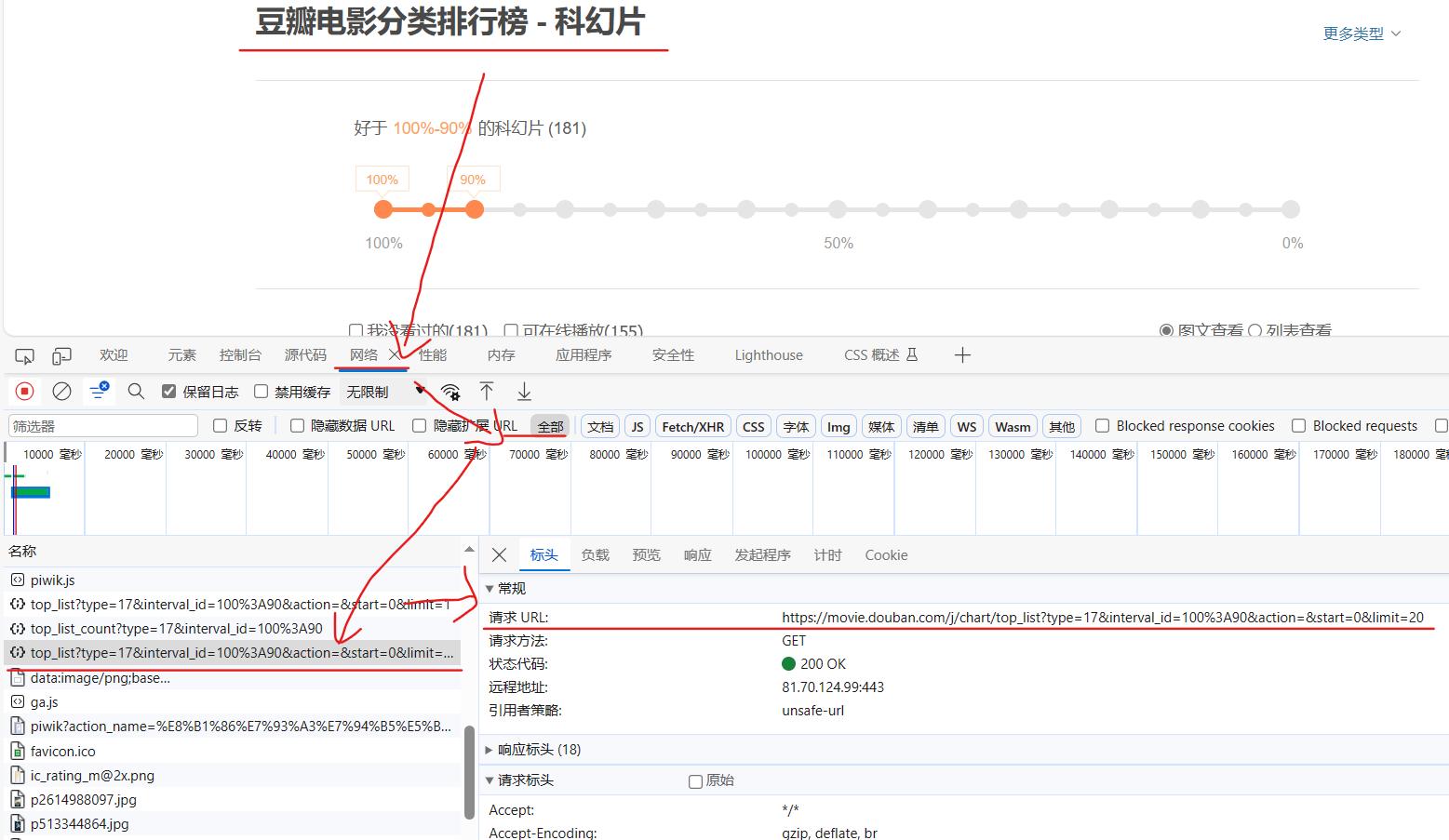
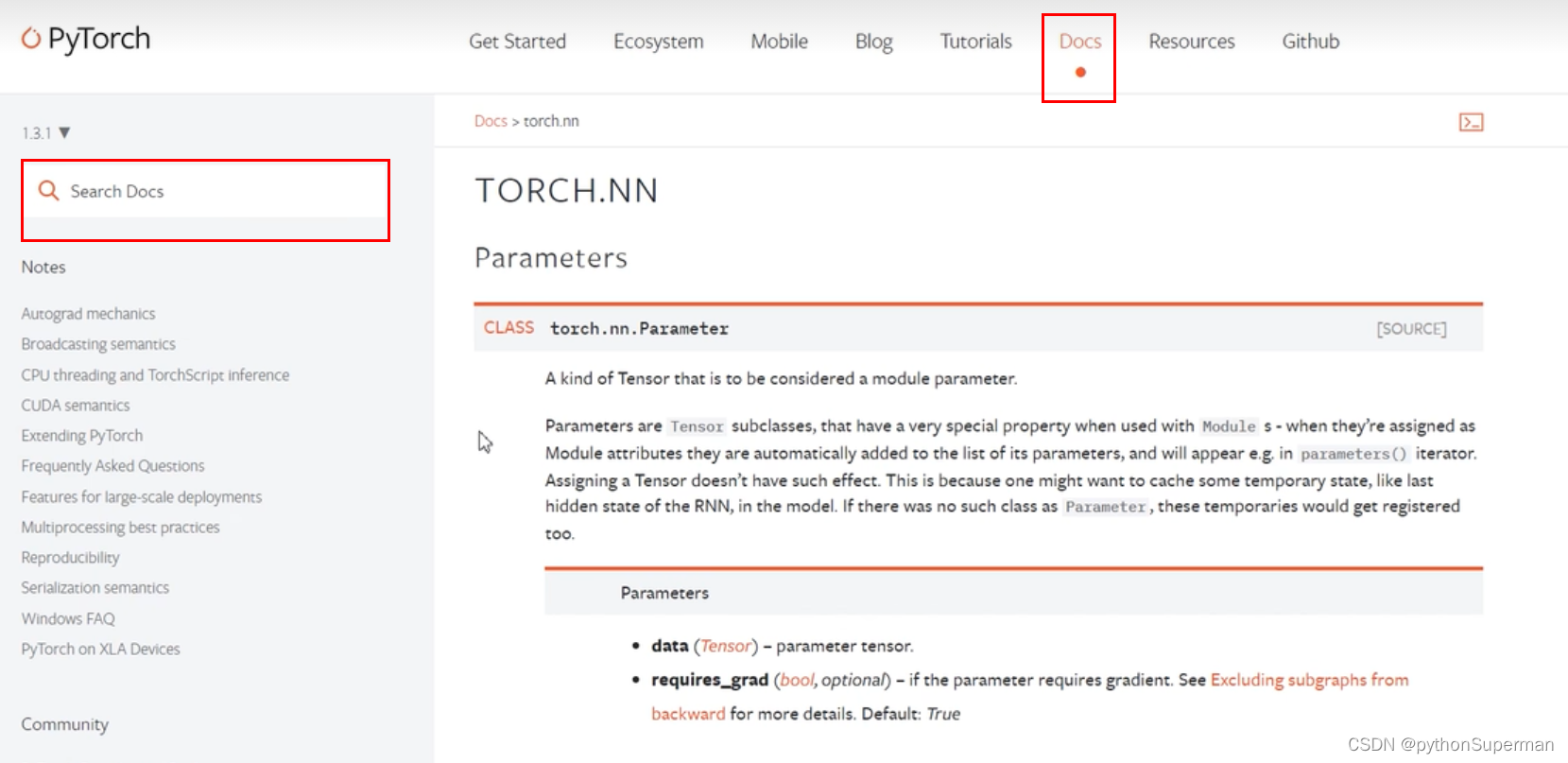
设置url,检查 --> 网络 --> 全部 --> top_list --> 标头 --> 请求URL
完整代码:
import urllib.request"""
# get请求
# 获取豆瓣电影第一页的数据,并保存为json文件
"""
url = 'https://movie.douban.com/j/chart/top_list?type=17&interval_id=100%3A90&action=&start=0&limit=20'
headers = {"User-Agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/118.0.0.0 Safari/537.36 Edg/118.0.2088.76"
}# 请求对象的定制
request = urllib.request.Request(url, headers=headers)# 获取响应的数据
response = urllib.request.urlopen(request)
content = response.read().decode('utf-8')
print(content)# 数据下载到本地
with open('douban.json','w', encoding='utf-8') as file:file.write(content)# import json
# with open('douban.json','w', encoding='utf-8') as file:
# json.dump(content, file, ensure_ascii=False)
"""
通常是因为默认情况下,json.dump() 使用的编码是 ASCII,不支持包含非ASCII字符(如中文)的文本。为了在 JSON 文件中包含中文字符,你可以指定 ensure_ascii=False 参数,以确保不将中文字符转换为 Unicode 转义序列。
"""
二、ajax的get请求豆瓣电影前十页
目标:下载豆瓣电影前十页的数据
知识点:问题的关键在于观察url的规律,然后迭代获取数据
1.设置url
找规律
点击top_list获取第一页的request url,复制url,点击清空,下拉滚动条,再次出现top_list时复制第二页的request url,重复操作,我们可以找到规律。

观察链接,可以看到page和start之间的关系
# url 规律
'https://movie.douban.com/j/chart/top_list?type=17&interval_id=100%3A90&action=&start=0&limit=20'
'https://movie.douban.com/j/chart/top_list?type=17&interval_id=100%3A90&action=&start=20&limit=20'
'https://movie.douban.com/j/chart/top_list?type=17&interval_id=100%3A90&action=&start=40&limit=20'
'https://movie.douban.com/j/chart/top_list?type=17&interval_id=100%3A90&action=&start=60&limit=20'# page 1 2 3 4
# start 0 20 40 602.定义请求对象定制的函数
def create_request(page):base_url = 'https://movie.douban.com/j/chart/top_list?type=17&interval_id=100%3A90&action=&'data={'start':(page-1)*20,'limit':20}data = urllib.parse.urlencode(data)url = base_url+dataheaders = {"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/118.0.0.0 Safari/537.36 Edg/118.0.2088.76"}# 请求对象的定制request = urllib.request.Request(url, headers=headers)return request3.定义获取响应的数据的函数
def get_content(request):# 获取响应的数据response = urllib.request.urlopen(request)content = response.read().decode('utf-8')return content4.定义下载函数
def down_load(content,page):with open('daouban_'+str(page)+'.json','w',encoding='utf-8') as file:file.write(content)5.调用这些函数,完成数据抓取
start_page = int(input("请输入起始页码"))
end_page = int(input("请输入结束的代码"))for page in range(start_page, end_page+1):# 请求对象的定制request = create_request(page)# 获取响应的数据content = get_content(request)# 下载down_load(content,page)print(f"done_{page}")完整代码
import urllib.request
import urllib.parse
# url 规律
'https://movie.douban.com/j/chart/top_list?type=17&interval_id=100%3A90&action=&start=0&limit=20'
'https://movie.douban.com/j/chart/top_list?type=17&interval_id=100%3A90&action=&start=20&limit=20'
'https://movie.douban.com/j/chart/top_list?type=17&interval_id=100%3A90&action=&start=40&limit=20'
'https://movie.douban.com/j/chart/top_list?type=17&interval_id=100%3A90&action=&start=60&limit=20'# page 1 2 3 4
# start 0 20 40 60# 全部工作:下载豆瓣电影前十页的数据
# 请求对象的定制
# 获取响应的数据
# 下载数据def create_request(page):base_url = 'https://movie.douban.com/j/chart/top_list?type=17&interval_id=100%3A90&action=&'data={'start':(page-1)*20,'limit':20}data = urllib.parse.urlencode(data)url = base_url+dataheaders = {"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/118.0.0.0 Safari/537.36 Edg/118.0.2088.76"}# 请求对象的定制request = urllib.request.Request(url, headers=headers)return requestdef get_content(request):# 获取响应的数据response = urllib.request.urlopen(request)content = response.read().decode('utf-8')return contentdef down_load(content,page):with open('daouban_'+str(page)+'.json','w',encoding='utf-8') as file:file.write(content)start_page = int(input("请输入起始页码"))
end_page = int(input("请输入结束的代码"))for page in range(start_page, end_page+1):# 请求对象的定制request = create_request(page)# 获取响应的数据content = get_content(request)# 下载down_load(content,page)print(f"done_{page}")
三、ajax的post请求肯德基官网
目标:查询肯德基某地区餐厅前十页的信息
1.设置url
进入肯德基官网,点击餐厅查询,右键检查
网络 --> 名称 --> 标头 --> 请求URL
然后点击清空(左上角的 ∅),点击第二页,再次获取链接信息及负载中的表单数据,找规律

可以找到如下规律
pageIndex就是页码
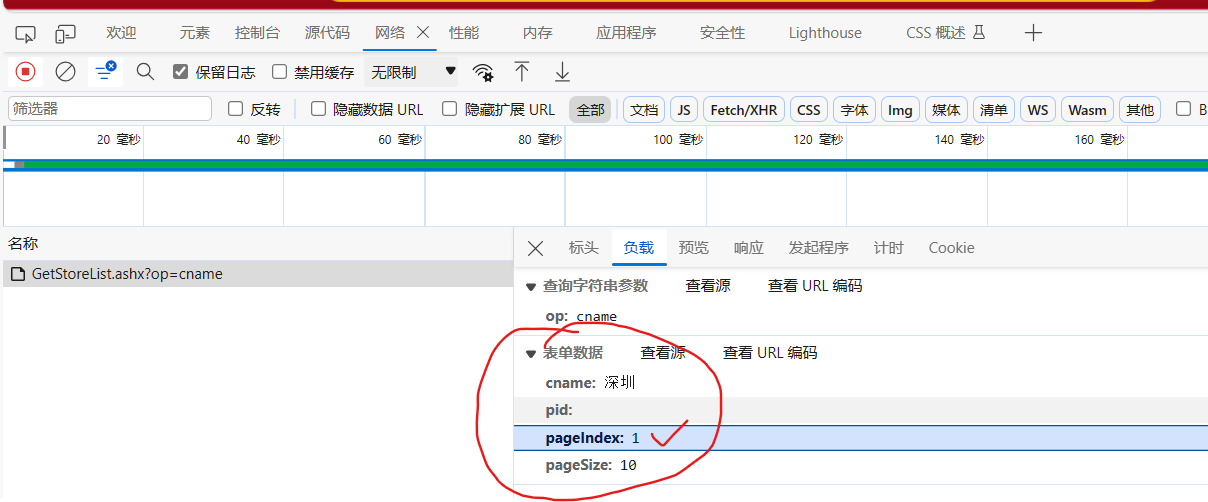
# 第1页
# cname: 深圳
# pid:
# pageIndex: 1
# pageSize: 10# 第2页
# http://www.kfc.com.cn/kfccda/ashx/GetStoreList.ashx?op=cname
# cname: 深圳
# pid:
# pageIndex: 2
# pageSize: 102.定义请求对象地址的函数
def create_request(page):base_url = 'http://www.kfc.com.cn/kfccda/ashx/GetStoreList.ashx?op=cname'data={'cname': '深圳','pid': '','pageIndex': page,'pageSize': '10'}data = urllib.parse.urlencode(data).encode('utf-8')headers = {"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/118.0.0.0 Safari/537.36 Edg/118.0.2088.76"}request = urllib.request.Request(base_url, data, headers)return request3.获取网页源码
def get_content(request):response = urllib.request.urlopen(request)content = response.read().decode('utf-8')return content4.下载
def download(content, page):with open ('kfc_'+str(page)+'.json','w',encoding='utf-8') as file:file.write(content)5.调用函数
start_page = int(input('请输入起始页码'))
end_page = int(input('请输入结束页码'))
for page in range(start_page, end_page+1):# 请求对象定制response = create_request(page)# 获取网页源码content = get_content(response)# 下载1download(content, page)完整代码:
import urllib.request
import urllib.parse# 第1页
# cname: 深圳
# pid:
# pageIndex: 1
# pageSize: 10# 第2页
# http://www.kfc.com.cn/kfccda/ashx/GetStoreList.ashx?op=cname
# cname: 深圳
# pid:
# pageIndex: 2
# pageSize: 10def create_request(page):base_url = 'http://www.kfc.com.cn/kfccda/ashx/GetStoreList.ashx?op=cname'data={'cname': '深圳','pid': '','pageIndex': page,'pageSize': '10'}data = urllib.parse.urlencode(data).encode('utf-8')headers = {"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/118.0.0.0 Safari/537.36 Edg/118.0.2088.76"}request = urllib.request.Request(base_url, data, headers)return requestdef get_content(request):response = urllib.request.urlopen(request)content = response.read().decode('utf-8')return contentdef download(content, page):with open ('kfc_'+str(page)+'.json','w',encoding='utf-8') as file:file.write(content)start_page = int(input('请输入起始页码'))
end_page = int(input('请输入结束页码'))
for page in range(start_page, end_page+1):# 请求对象定制response = create_request(page)# 获取网页源码content = get_content(response)# 下载1download(content, page)参考
尚硅谷Python爬虫教程小白零基础速通(含python基础+爬虫案例)
相关文章:
urllib爬虫 应用实例(三)
目录 一、 ajax的get请求豆瓣电影第一页 二、ajax的get请求豆瓣电影前十页 三、ajax的post请求肯德基官网 一、 ajax的get请求豆瓣电影第一页 目标:获取豆瓣电影第一页的数据,并保存为json文件 设置url,检查 --> 网络 --> 全部 -…...

【数据挖掘】国科大苏桂平老师数据库新技术课程作业 —— 第三次作业
part 1 设计一个学籍管理小系统。系统包含以下信息: 学号、学生姓名、性别、出生日、学生所在系名、学生所在系号、课程名、课程号、课程类型(必修、选修、任选)、学分、任课教师姓名、教师编号、教师职称、教师所属系名、系号、学生所选课…...
TP5上传图片压缩尺寸
图片上传,最简单的就是, 方法一: 修改上传限制,不让上传大于多少多少的图片 改一下size即可,默认单位是B换算成M还需要除以两次1024 方法二: 对上传的图片进行缩放,此办法网上找了不少的代码…...

使用 Tailwind CSS 完成导航栏效果
使用 Tailwind CSS 完成导航栏效果 本文将向您介绍如何使用 Tailwind CSS 创建一个漂亮的导航栏。通过逐步演示和示例代码,您将学习如何使用 Tailwind CSS 的类来设计和定制导航栏的样式。 准备工作 在开始之前,请确保已经安装了 Tailwind CSS。如果没…...
docker容器配置MySQL与远程连接设置(纯步骤)
以下为ubuntu20.04环境,默认已安装docker,没安装的网上随便找个教程就好了 拉去mysql镜像 docker pull mysql这样是默认拉取最新的版本latest 这样是指定版本拉取 docker pull mysql:5.7查看已安装的mysql镜像 docker images通过镜像生成容器 docke…...

什么是网站劫持
网站劫持是一种网络安全威胁,它通过非法访问或篡改网站的内容来获取机密信息或者破坏计算机系统。如果您遇到了网站劫持问题,建议您立即联系相关的安全机构或者技术支持团队,以获得更专业的帮助和解决方案。...
LeNet
概念 代码 model import torch.nn as nn import torch.nn.functional as Fclass LeNet(nn.Module):def __init__(self):super(LeNet, self).__init__() # super()继承父类的构造函数self.conv1 nn.Conv2d(3, 16, 5)self.pool1 nn.MaxPool2d(2, 2)self.conv2 nn.Conv2d(16…...
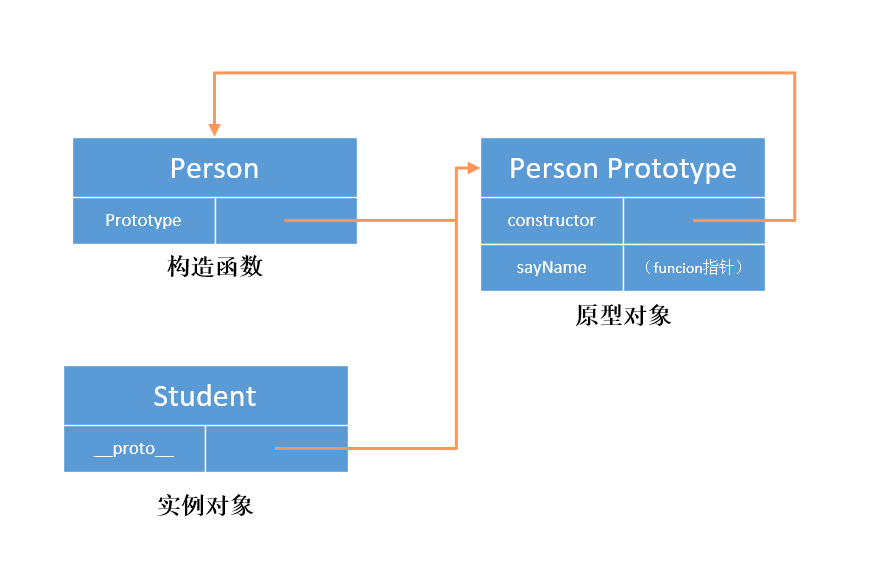
JavaScript 简单理解原型和创建实例时 new 操作符的执行操作
function Person(){// 构造函数// 当函数创建,prototype 属性指向一个原型对象时,在默认情况下,// 这个原型对象将会获得一个 constructor 属性,这个属性是一个指针,指向 prototype 所在的函数对象。 } // 为原型对象添…...
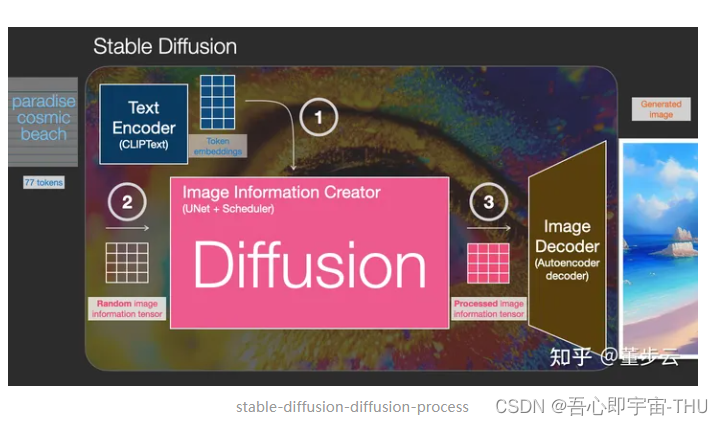
生成对抗网络——研讨会
时隔一年,再跟着李沐大师学习了GAN之后,仍旧没能在离散优化中实现通用的应用,实在惭愧,借着组内研讨会的机会,再队GAN的前世今生做一个简单的综述。 GAN产生的背景 目前与GAN相关的应用 去reddit社区的机器学习板块…...
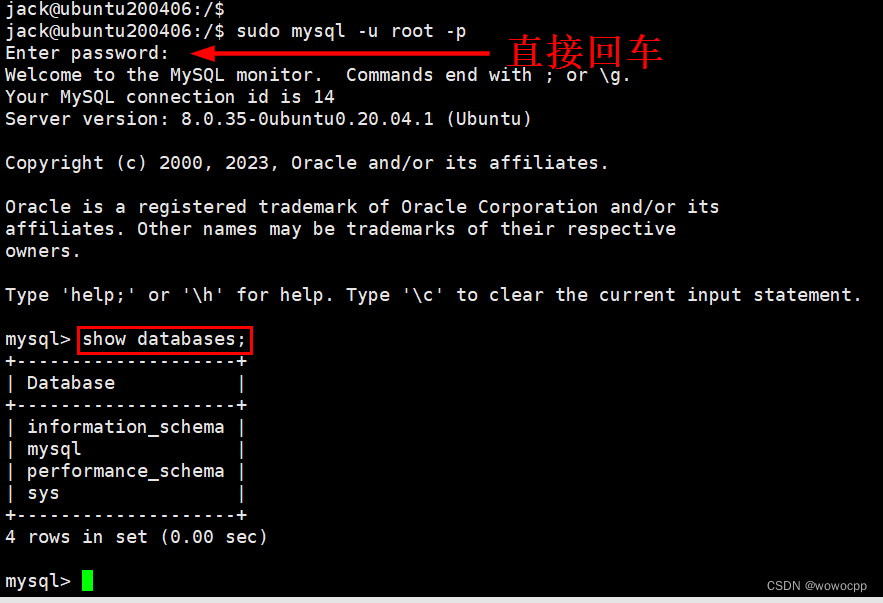
Ubuntu 20.04 安装 mysql8 LTS
Ubuntu 20.04 安装 mysql8 LTS sudo apt-get update sudo apt-get install mysql-server -y mysql --version mysql Ver 8.0.35-0ubuntu0.20.04.1 for Linux on x86_64 ((Ubuntu)) Ubuntu20.04 是自带了 MySQL8. 几版本的,低于 20.04 则默认安装是 MySQL5.7.33…...

蓝桥杯:货物摆放
小蓝有一个超大的仓库,可以摆放很多货物。 现在,小蓝有 n 箱货物要摆放在仓库,每箱货物都是规则的正方体。小蓝规定了长、宽、高三个互相垂直的方向,每箱货物的边都必须严格平行于长、宽、高。 小蓝希望所有的货物最终摆成一个大…...
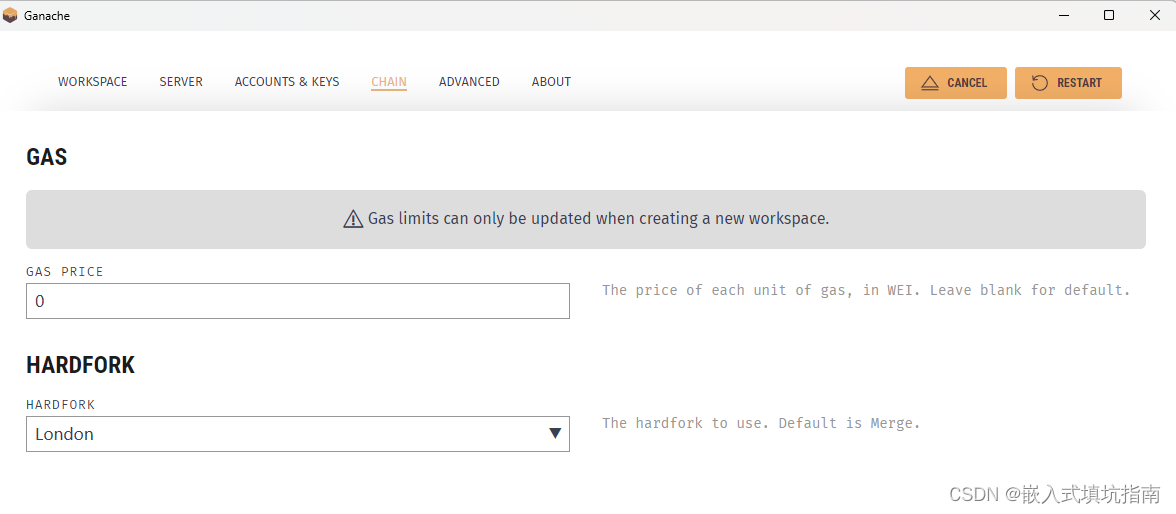
ganache部署智能合约报错VM Exception while processing transaction: invalid opcode
这是因为编译的字节码不正确,ganache和remix编译时需要选择相同的evm version 如下图所示: remix: ganache: 确保两者都选择london或者其他evm,只要确保EVM一致就可以正确编译并部署, 不会再出现VM Exception while processing…...

金融银行业更适合申请哪种SSL证书?
在当今数字化时代,金融行业的重要性日益增加。越来越多的金融交易和敏感信息在线进行,金融银行机构必须采取必要的措施来保护客户数据的安全。SSL证书作为一种重要的安全技术工具,可以帮助金融银行机构加密数据传输,验证网站身份&…...
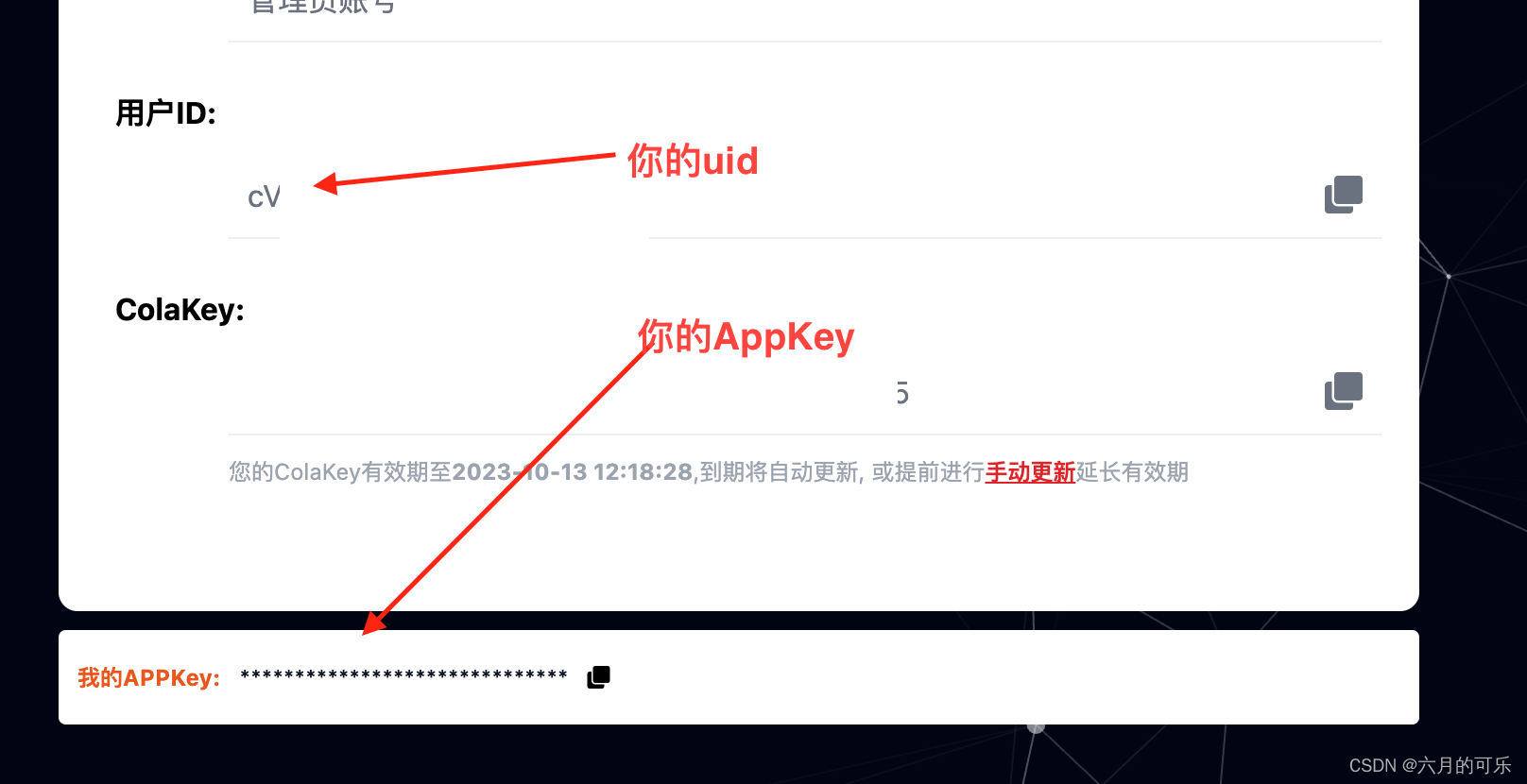
文心一言API(高级版)使用
文心一言API高级版使用 一、百度文心一言API(高级版)二、使用步骤1、接口2、请求参数3、请求参数示例4、接口 返回示例 三、 如何获取appKey和uid1、申请appKey:2、获取appKey和uid 四、重要说明 一、百度文心一言API(高级版) 基于百度文心一言语言大模型的智能文本对话AI机器…...
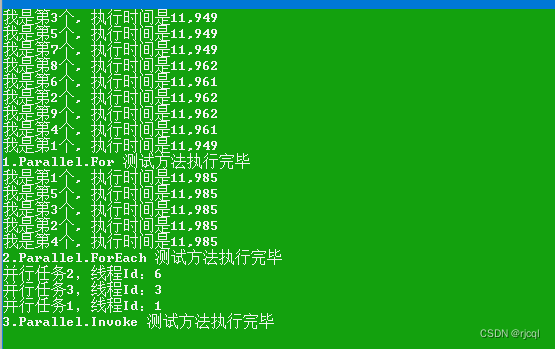
C# 任务并行类库Parallel调用示例
写在前面 Task Parallel Library 是微软.NET框架基础类库(BCL)中的一个,主要目的是为了简化并行编程,可以实现在不同的处理器上并行处理不同任务,以提升运行效率。Parallel常用的方法有For/ForEach/Invoke三个静态方法…...

2024年江苏省职业院校技能大赛信息安全管理与评估 第二阶段学生组(样卷)
2024年江苏省职业院校技能大赛信息安全管理与评估 第二阶段学生组(样卷) 竞赛项目赛题 本文件为信息安全管理与评估项目竞赛-第二阶段样题,内容包括:网络安全事件响应、数字取证调查、应用程序安全。 本次比赛时间为180分钟。 …...

飞天使-linux操作的一些技巧与知识点3
http工作原理 http1.0 协议 使用的是短连接,建立一次tcp连接,发起一次http的请求,结束,tcp断开 http1.1 协议使用的是长连接,建立一次tcp的连接,发起多次http的请求,结束,tcp断开ngi…...

Appium获取toast方法封装
一、前置说明 toast消失的很快,并且通过uiautomatorviewer也不能获取到它的定位信息,如下图: 二、操作步骤 toast的class name值为android.widget.Toast,虽然toast消失的很快,但是它终究是在Dom结构中出现过&…...

Google Guava简析
Google Guava 是Google开源的一个Java类库,对基本类库做了扩充。感觉最大的价值点在于其 集合类、Cache和String工具类。 github项目地址:GitHub - google/guava: Google core libraries for Java github文档地址:Home google/guava Wiki …...
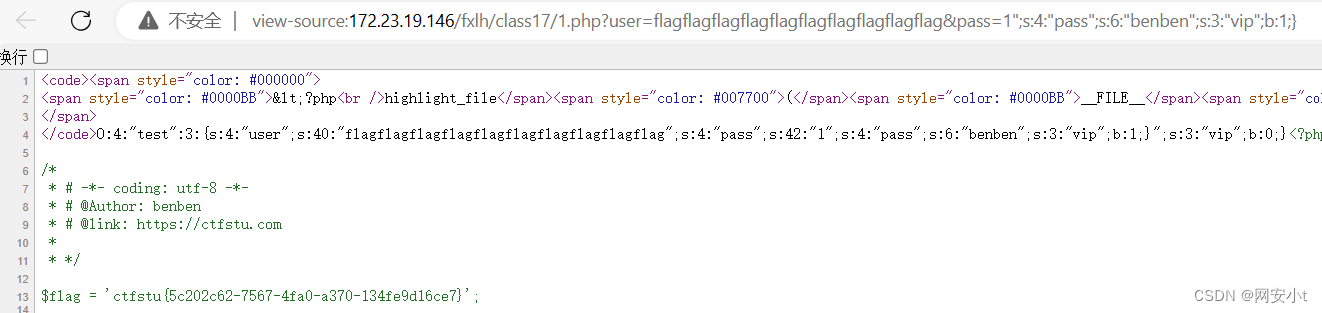
反序列化漏洞详解(二)
目录 pop链前置知识,魔术方法触发规则 pop构造链解释(开始烧脑了) 字符串逃逸基础 字符减少 字符串逃逸基础 字符增加 实例获取flag 字符串增多逃逸 字符串减少逃逸 延续反序列化漏洞(一)的内容 pop链前置知识,魔术方法触…...

初创公司如何通过Taotoken的Token Plan套餐有效控制AI实验成本
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 初创公司如何通过Taotoken的Token Plan套餐有效控制AI实验成本 对于初创公司而言,在产品原型开发和AI功能探索阶段&…...

解决Keil MDK中RL-ARM许可证错误L9937E的方法
1. 问题现象与背景解析最近在维护一个基于Keil MDK的嵌入式老项目时,遇到了一个棘手的许可证错误。项目需要使用RL-ARM实时库(Real-Time Library),但编译时出现了以下错误提示:Error: L9937E: RL-ARM is not allowed w…...

Unity热更新实战:YooAsset与HybridCLR协同落地指南
1. 这不是“加个插件就能热更”的童话,而是Unity项目里最真实的代码热更新落地现场在Unity游戏开发中,“热更新”三个字背后藏着太多被轻描淡写的代价:策划说“今天上线新活动,明天要热更”,程序却在凌晨三点对着Asset…...

拉格朗日平衡传播:动态系统的梯度估计新方法
1. 拉格朗日平衡传播的理论框架1.1 能量基模型与平衡传播基础能量基模型(Energy-Based Models, EBMs)的核心思想是将预测问题转化为能量最小化问题。这类模型通过定义能量函数E(s,θ,x)来描述系统状态s与参数θ、输入x之间的关系,模型的预测输…...

双向可控硅交流控制电路基础知识及Multisim电路仿真
目录 2.2.2 双向可控硅交流控制电路 2.2.2.1 双向可控硅交流控制电路基础知识 2.2.2.2 双向可控硅交流控制Multisim电路仿真 摘要:本文介绍了双向可控硅交流控制电路的工作原理及Multisim仿真。该电路通过光耦隔离实现低压控制高压交流负载,采用过零触发方式降低干扰。控制…...

Unity InputField组件保姆级配置指南:从登录框到聊天框,一次搞定所有输入场景
Unity InputField组件实战配置指南:从登录验证到聊天系统的深度优化在游戏开发中,用户输入交互是连接玩家与游戏世界的重要桥梁。Unity的InputField组件作为最常用的输入控件之一,其配置灵活性直接影响用户体验的流畅度。本文将深入探讨如何针…...

为什么92.7%的用户装错ChatGPT桌面版?——20年IT架构师亲测:3个隐藏配置项决定响应速度与上下文留存能力
更多请点击: https://codechina.net 第一章:ChatGPT桌面版下载安装 OpenAI 官方尚未发布官方支持的 ChatGPT 桌面应用程序(截至 2024 年底),但社区提供了稳定、安全且功能完整的开源桌面客户端,其中 Chat…...

【前端无障碍】无障碍测试:确保你的应用对所有人友好
【前端无障碍】无障碍测试:确保你的应用对所有人友好 前言 大家好,我是cannonmonster01!今天咱们来聊聊无障碍测试这个话题。无障碍设计不仅仅是开发阶段的事情,测试阶段同样重要。只有通过全面的测试,才能确保你的应用…...

DeepSeek总结的DuckDB动态函数应用插件
来源:https://github.com/teaguesterling/duckdb_func_apply DuckDB FuncApply 扩展 DuckDB 的动态函数应用 - 在运行时通过名称调用函数。 概述 FuncApply 扩展为 DuckDB 提供了动态函数调用能力,允许您: 使用 apply() 通过名称调用任何…...

LinkSwift网盘直链下载助手:一站式解决9大网盘下载难题
LinkSwift网盘直链下载助手:一站式解决9大网盘下载难题 【免费下载链接】Online-disk-direct-link-download-assistant 一个基于 JavaScript 的网盘文件下载地址获取工具。基于【网盘直链下载助手】修改 ,支持 百度网盘 / 阿里云盘 / 中国移动云盘 / 天翼…...