ELK(四)—els基本操作
目录
- elasticsearch基本概念
- RESTful API
- 创建非结构化索引
- (增)创建空索引
- (删)删除索引
- (改)插入数据
- (改)数据更新
- (查)搜索数据(id)
- (查)搜索数据(全部)
- (查)关键字搜索数据
- (查)DSL搜索
- 其他(聚合)
elasticsearch基本概念
Elasticsearch 是一个分布式搜索引擎,用于全文搜索、分析和可视化大规模数据。以下是 Elasticsearch 中一些基本概念:
- 索引(Index):
- Elasticsearch 中的数据存储单元,类似于传统数据库中的数据库。每个索引包含一组相关的文档。
- 文档(Document):
- 索引中的基本信息单元,可以是 JSON、XML、或其他格式的数据。文档是 Elasticsearch 中可被索引和搜索的基本数据单元。
- 类型(Type)(在7.x版本之前):
- Elasticsearch 6.x及更早版本中,索引可以包含一个或多个类型,每个类型定义了文档的结构。从 Elasticsearch 7.x 开始,不再支持多类型,一个索引只有一个默认类型 “_doc”。
- 映射(Mapping):
- 定义了索引中的文档结构,包括每个字段的类型和属性。映射在创建索引时自动创建,也可以手动定义。
- 节点(Node):
- Elasticsearch 集群中的单个服务器,用于存储数据和执行数据操作。每个节点属于一个集群,并且有唯一的名称。
- 集群(Cluster):
- 由一个或多个节点组成的集合,共同存储数据并提供联合的搜索能力。集群有一个唯一的名称。
- 分片(Shard):
- 索引可以被分割成多个分片,每个分片是一个独立的索引。分片允许数据水平扩展,提高并发性能。
- 副本(Replica):
- 每个分片可以有零个或多个副本。副本是分片的精确拷贝,用于提高高可用性和故障恢复。
- 查询(Query):
- 用于搜索 Elasticsearch 中文档的条件。可以通过查询DSL(Domain Specific Language)来构建各种类型的查询。
- 聚合(Aggregation):
- 用于分析和统计数据的机制,可以计算平均值、总和、最小值等。
- 索引别名(Index Alias):
- 为索引提供一个可读的名称,可以用于简化索引操作和在查询中引用多个索引。
- 分析器(Analyzer):
- 用于在索引和查询阶段处理文本数据的组件,包括分词、小写化、去停用词等。
- 倒排索引(Inverted Index):
- Elasticsearch 使用倒排索引来加速搜索,它记录了每个词项出现在哪些文档中。
这些是 Elasticsearch 中一些基本的概念,了解它们有助于更好地理解和使用 Elasticsearch 进行数据存储和检索。
RESTful API
在Elasticsearch中,提供了功能丰富的RESTful API的操作,包括基本的CRUD、创建索引、删除索引等操作。
创建非结构化索引
在Lucene中,创建索引是需要定义字段名称以及字段的类型的,在Elasticsearch中提供了非结构化的索引,就是不需要创建索引结构,即可写入数据到索引中,实际上在Elasticsearch底层会进行结构化操作,此操作对用户是透明的。
(增)创建空索引
PUT /elk
{"settings":{"index":{"number_of_shards":"2","number_of_replicas":"0"}}
}
这里我选择postman进行测试。
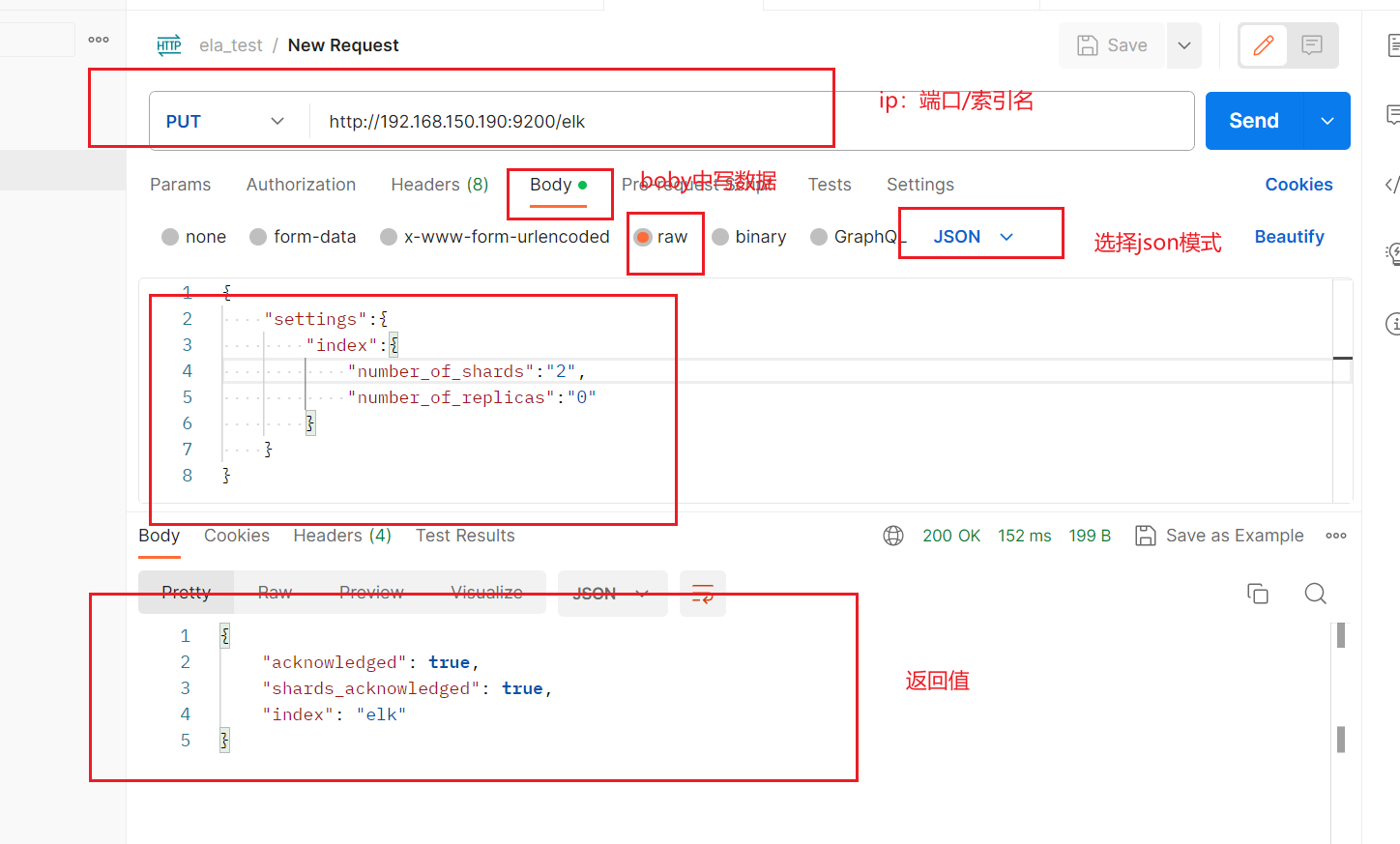
去elasticsearch-head看是否索引创建是否成功。
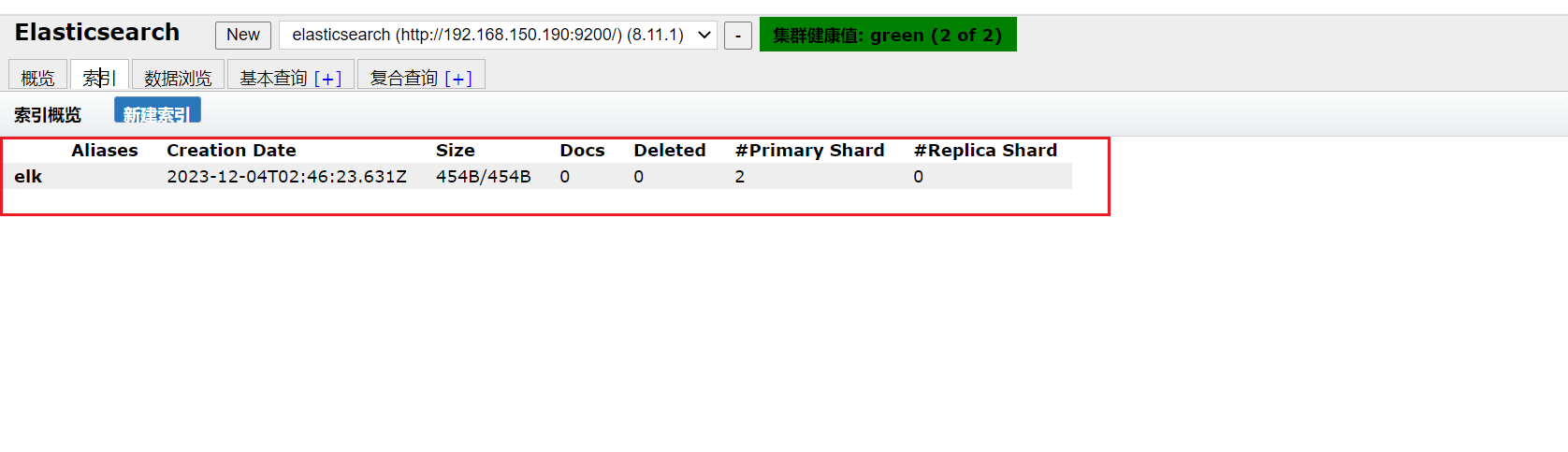
可以看到索引已经创建成功了。
(删)删除索引
DELETE /elk
{"acknowledged": true
}
在postman中进行删除操作

检查是否删除成功
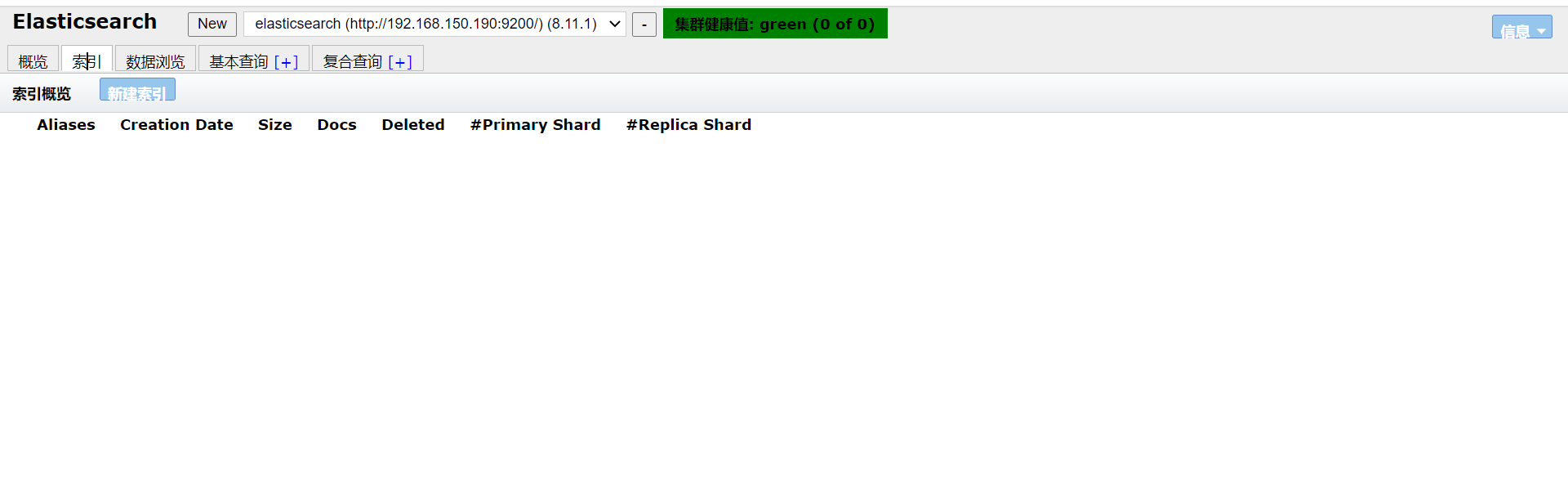
可以看到已经删除成功了
(改)插入数据
上面我们已经学会了如何创建好删除索引,现在我们进行数据的添加操作。
URL规则:
POST /{索引}/{类型}/{id}
插入如下数据。
{
"id":1001,
"name":"王五",
"age":18,
"sex":"男"
}

postman中显示插入成功了。
浏览器上是否也是插入成功呢?
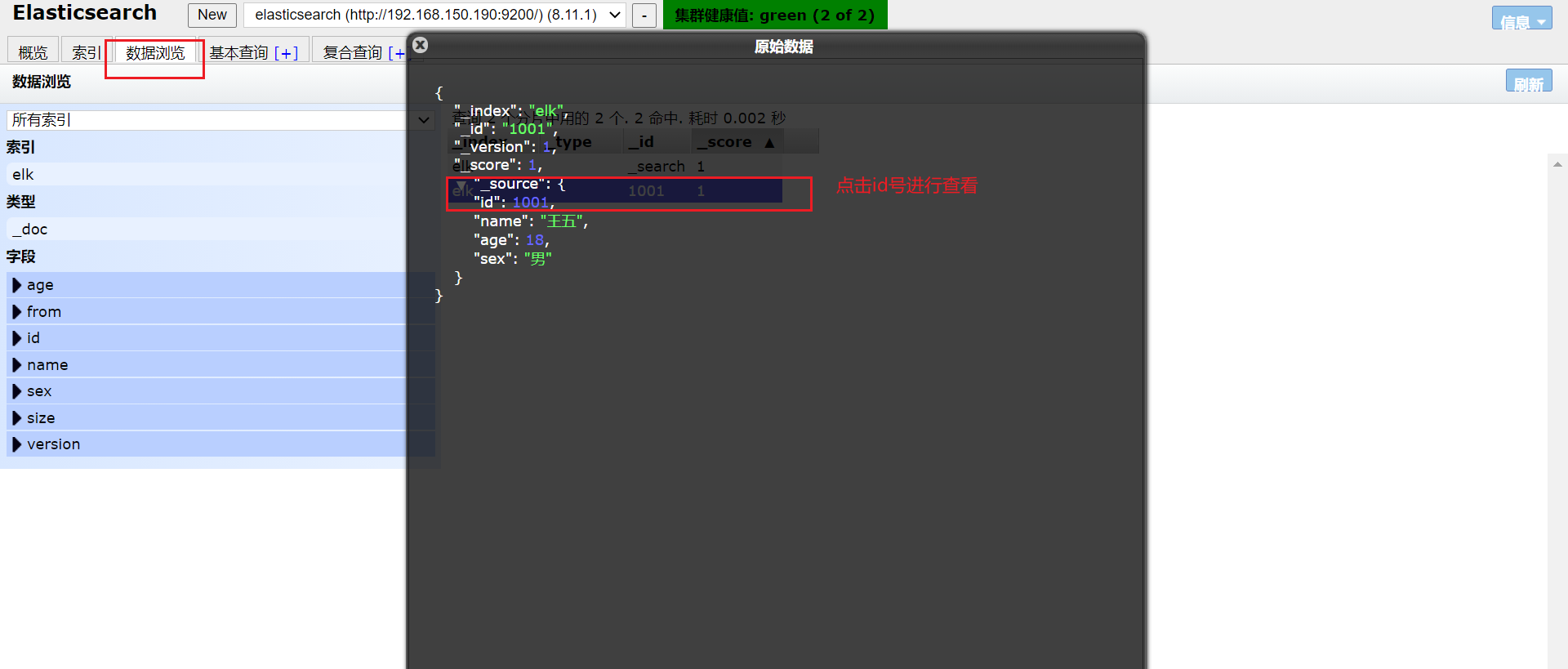
可以看到数据已经成功插入了。
(改)数据更新
在Elasticsearch中,文档数据是不为修改的,但是可以通过覆盖的方式进行更新。
{
"id":1001,
"name":"王老五",
"age":55,
"sex":"男"
}
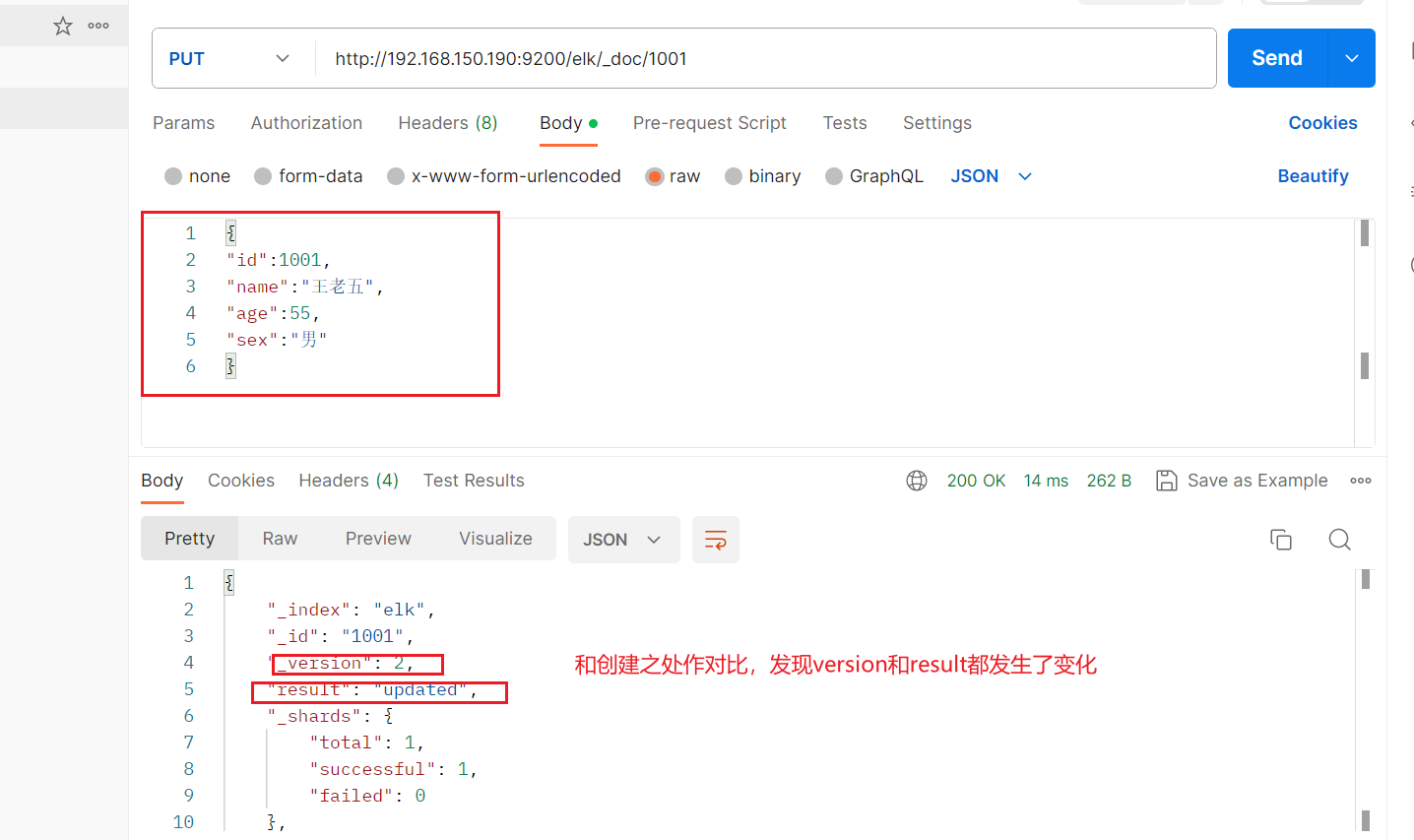
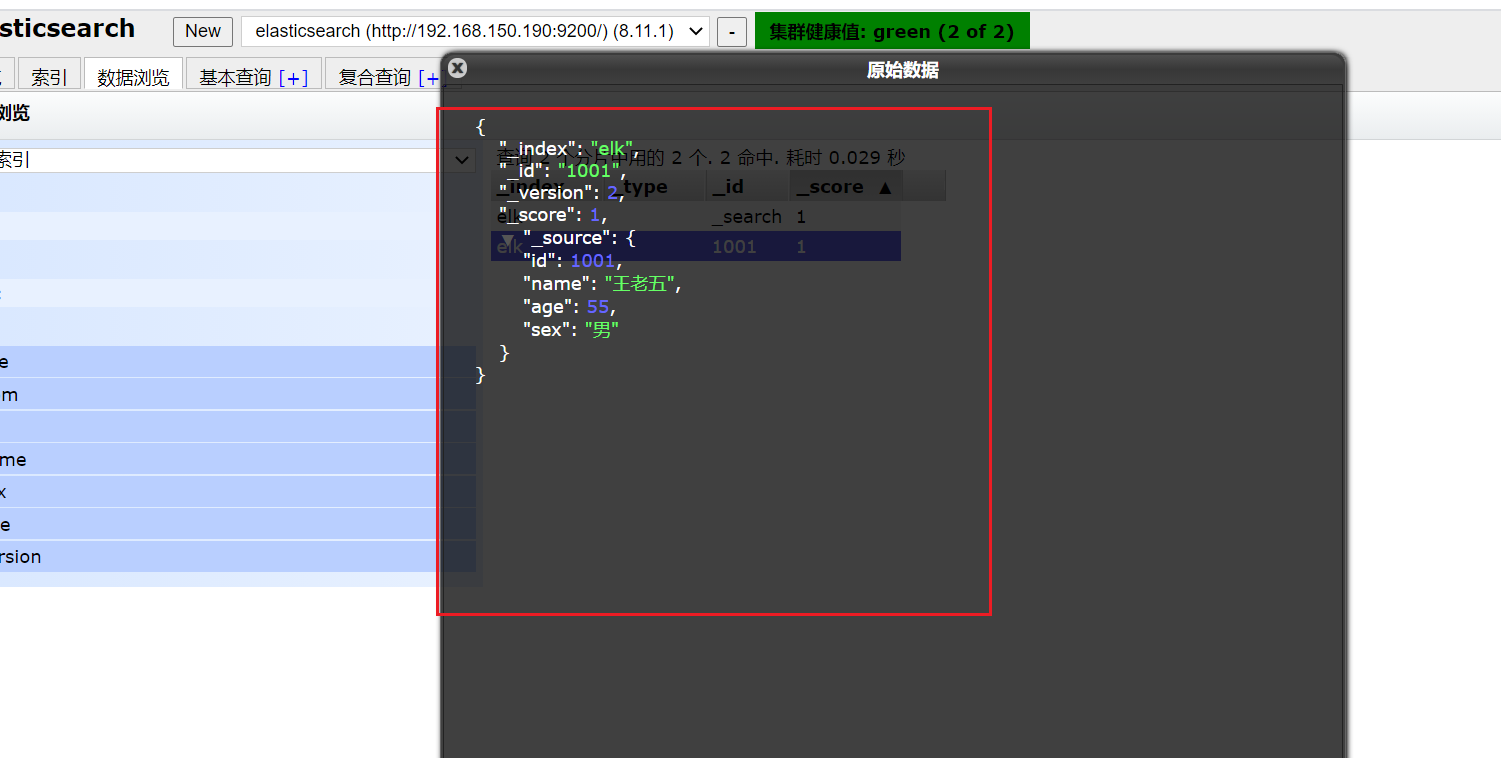
服务器中的数据也成功更新了。
问题与探究问题与探究问题与探究
可以看到数据已经被覆盖了。问题来了,可以局部更新吗? – 可以的。前面不是说,文档数据不能更新吗?
其实是这样的:在内部,依然会查询到这个文档数据,然后进行覆盖操作,步骤如下:
- 从旧文档中检索JSON
- 修改它
- 删除旧文档
- 索引新文档
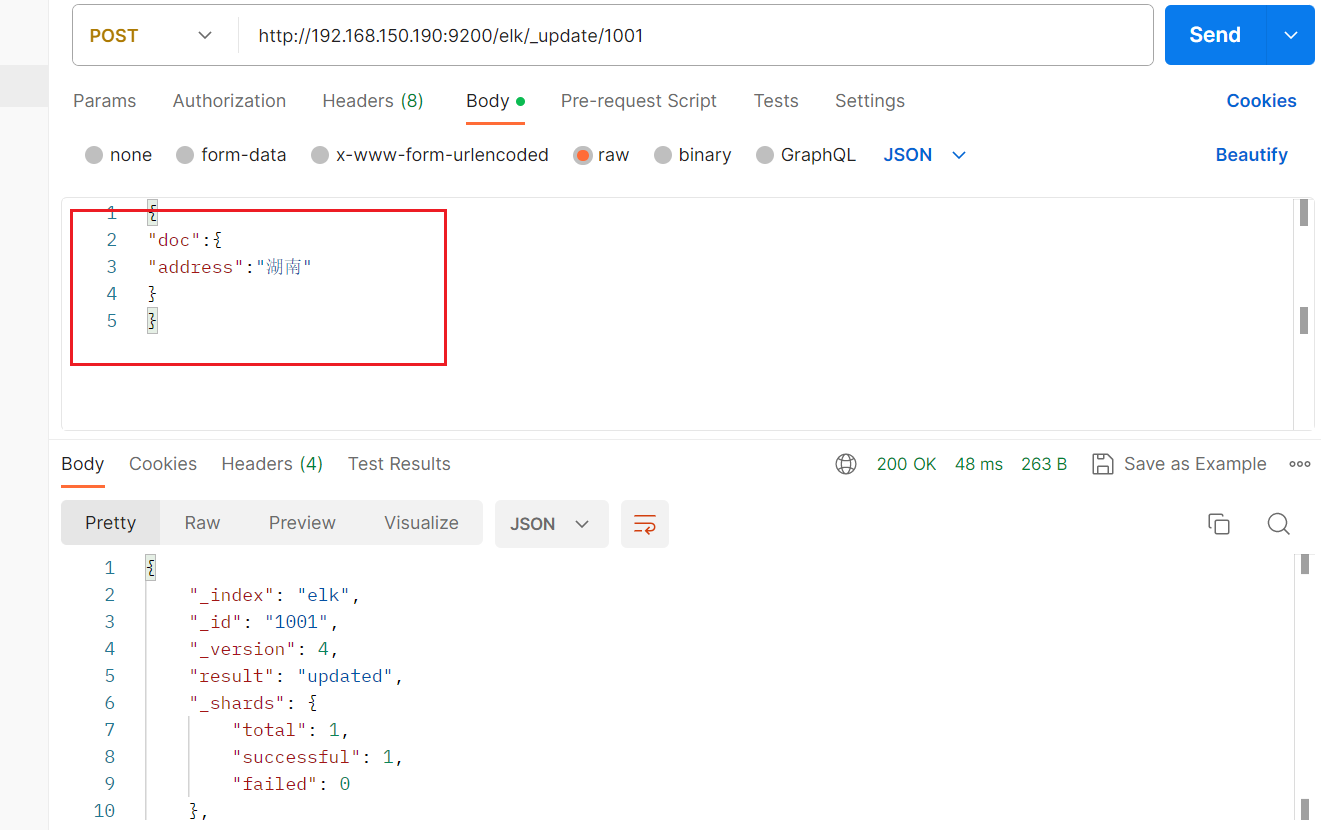
#注意:这里多了_update标识POST /haoke/_update/1001
{
"doc":{
"age":66
}
}
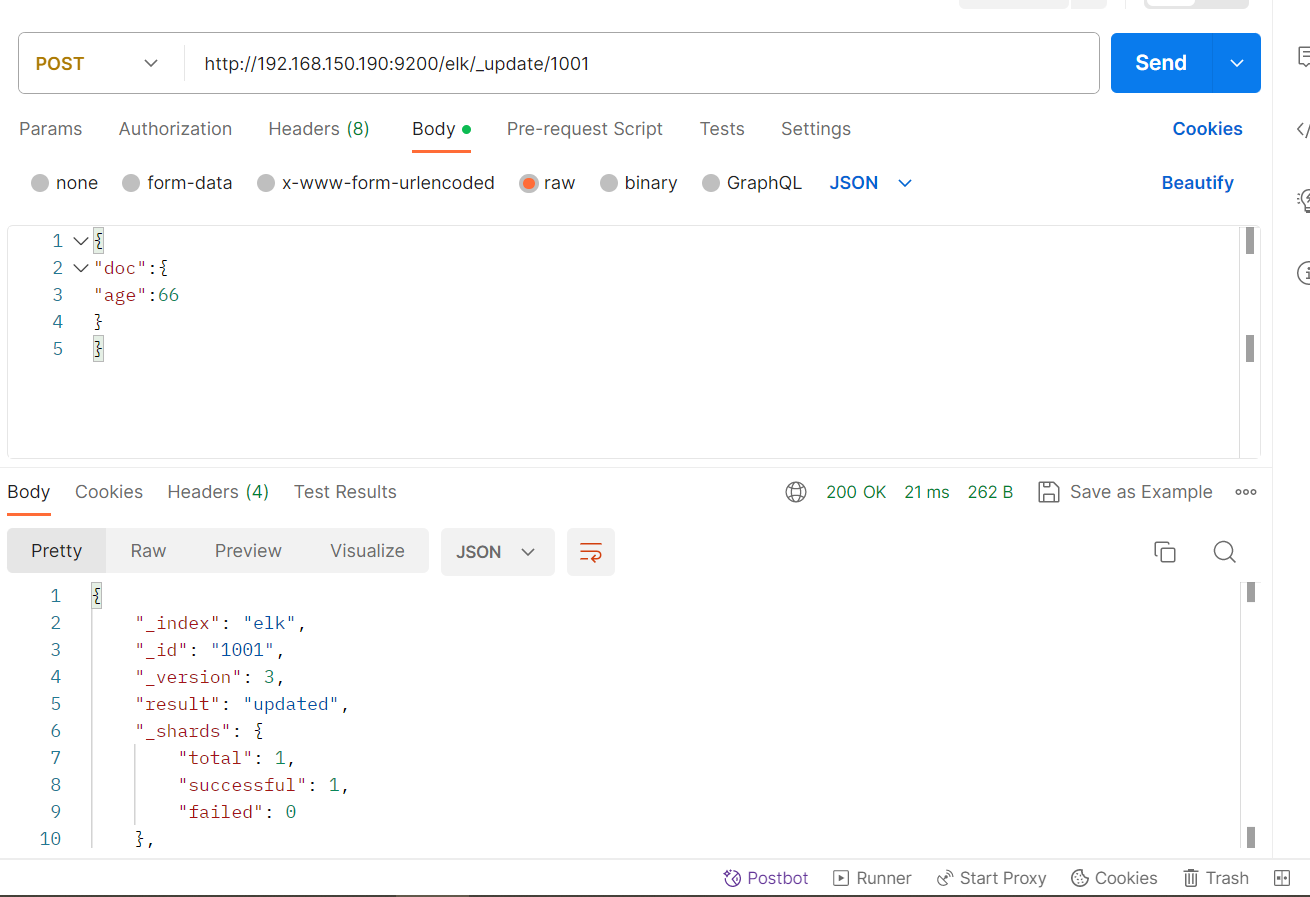
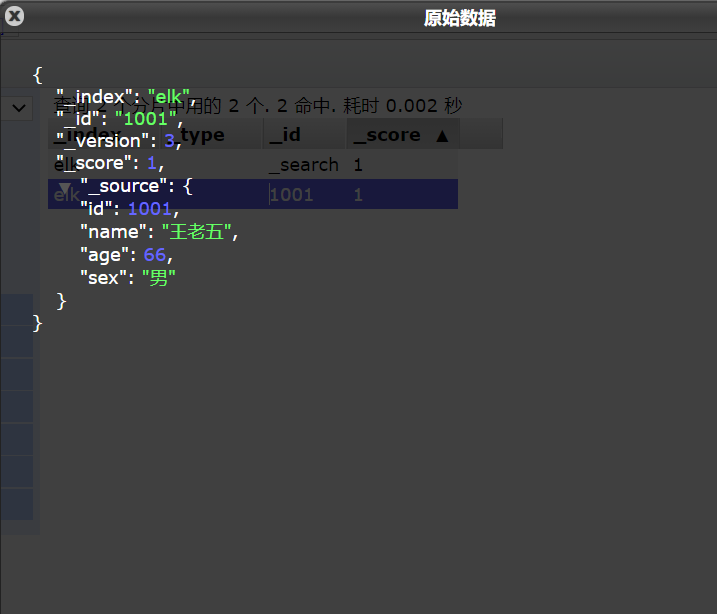
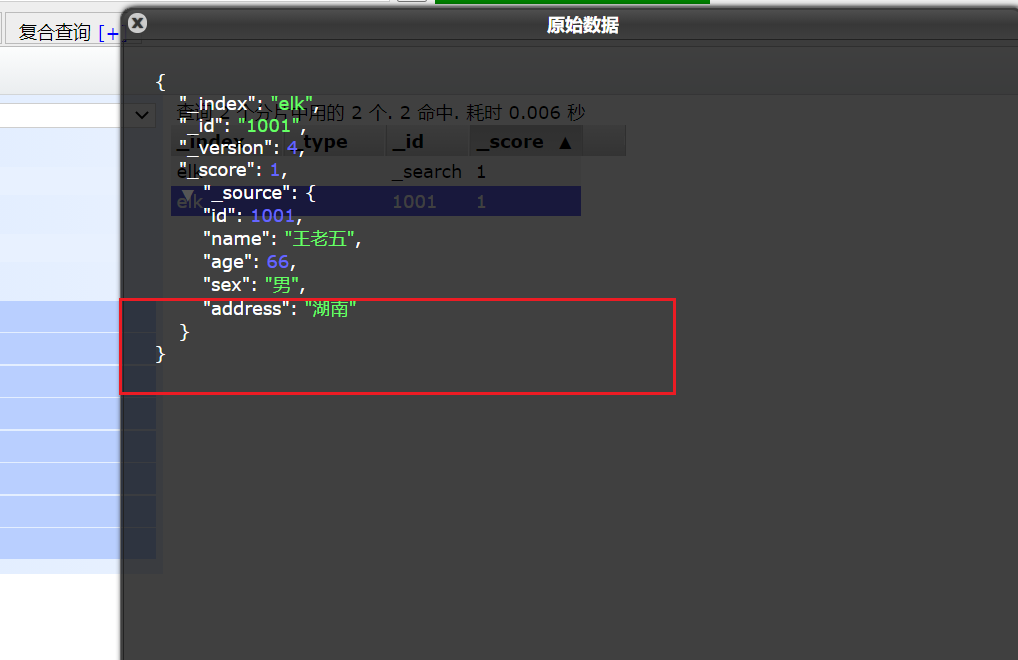
可以看到数据已经成功更新了。
我们需要id存在,否则会报错,也就是404
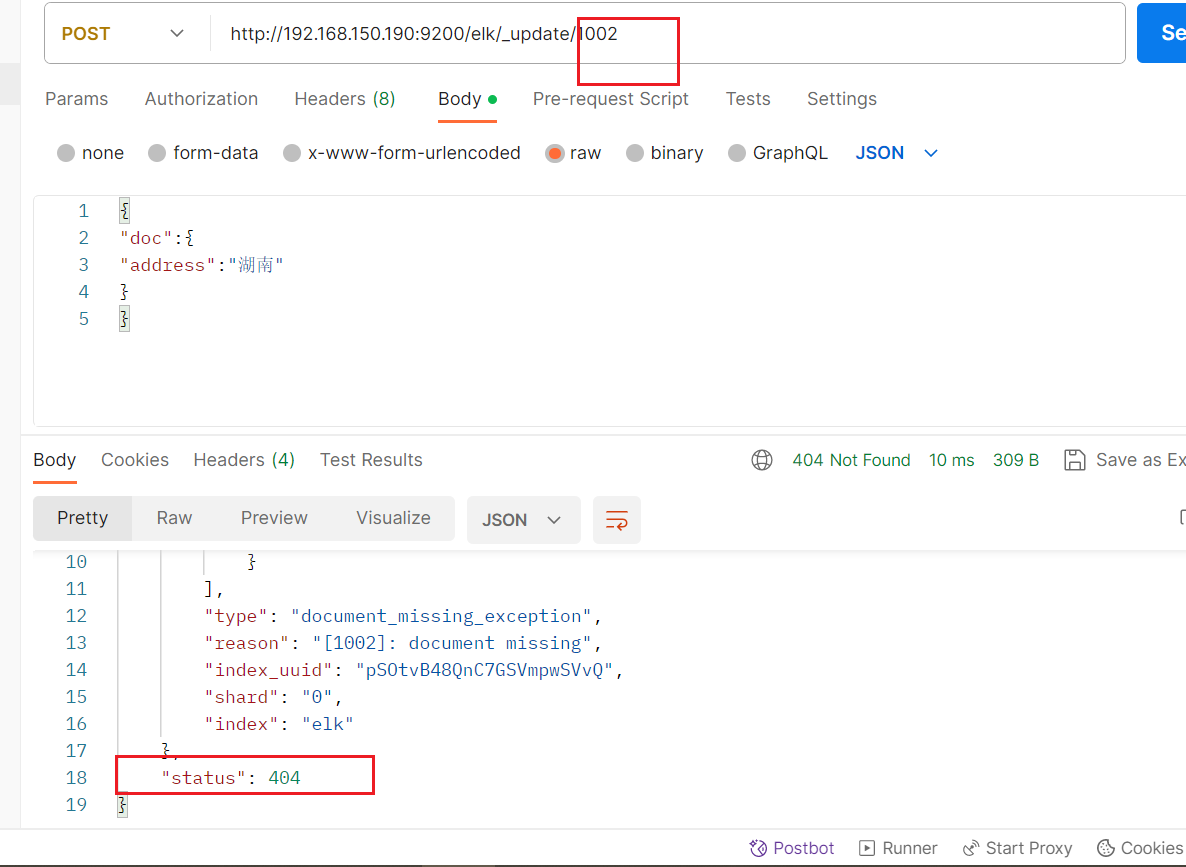
当id存在,我们可以往数据添加原先没有的数据。
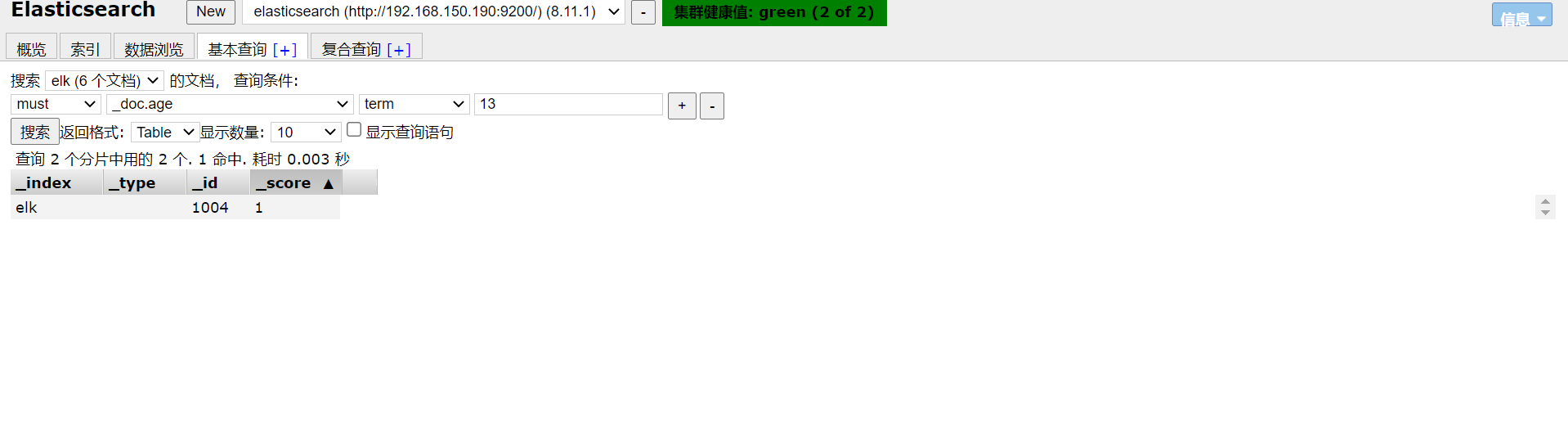
(查)搜索数据(id)
GET /elk/_doc/id
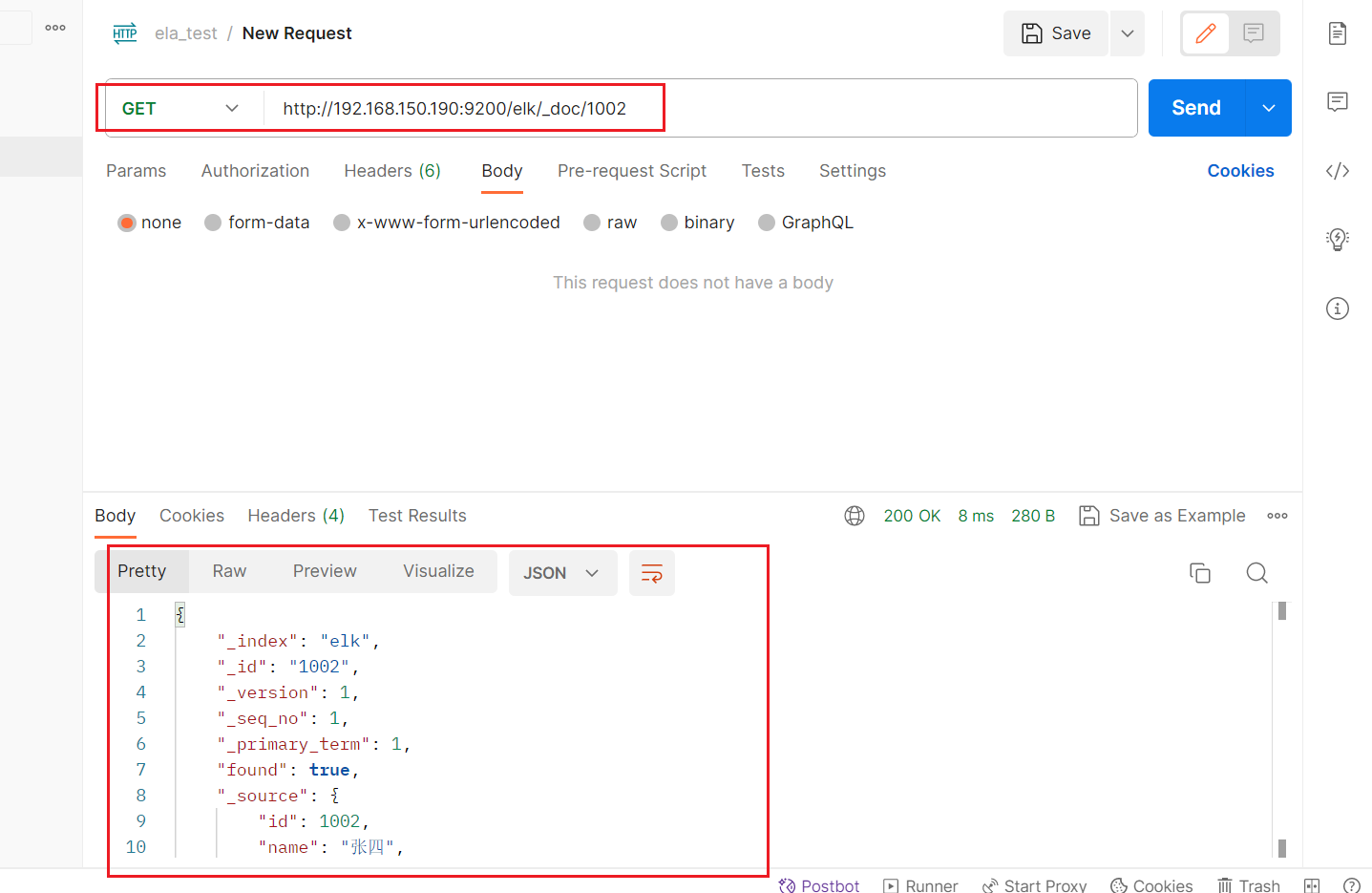
我们也可以直接在elasticsearch中进行搜索
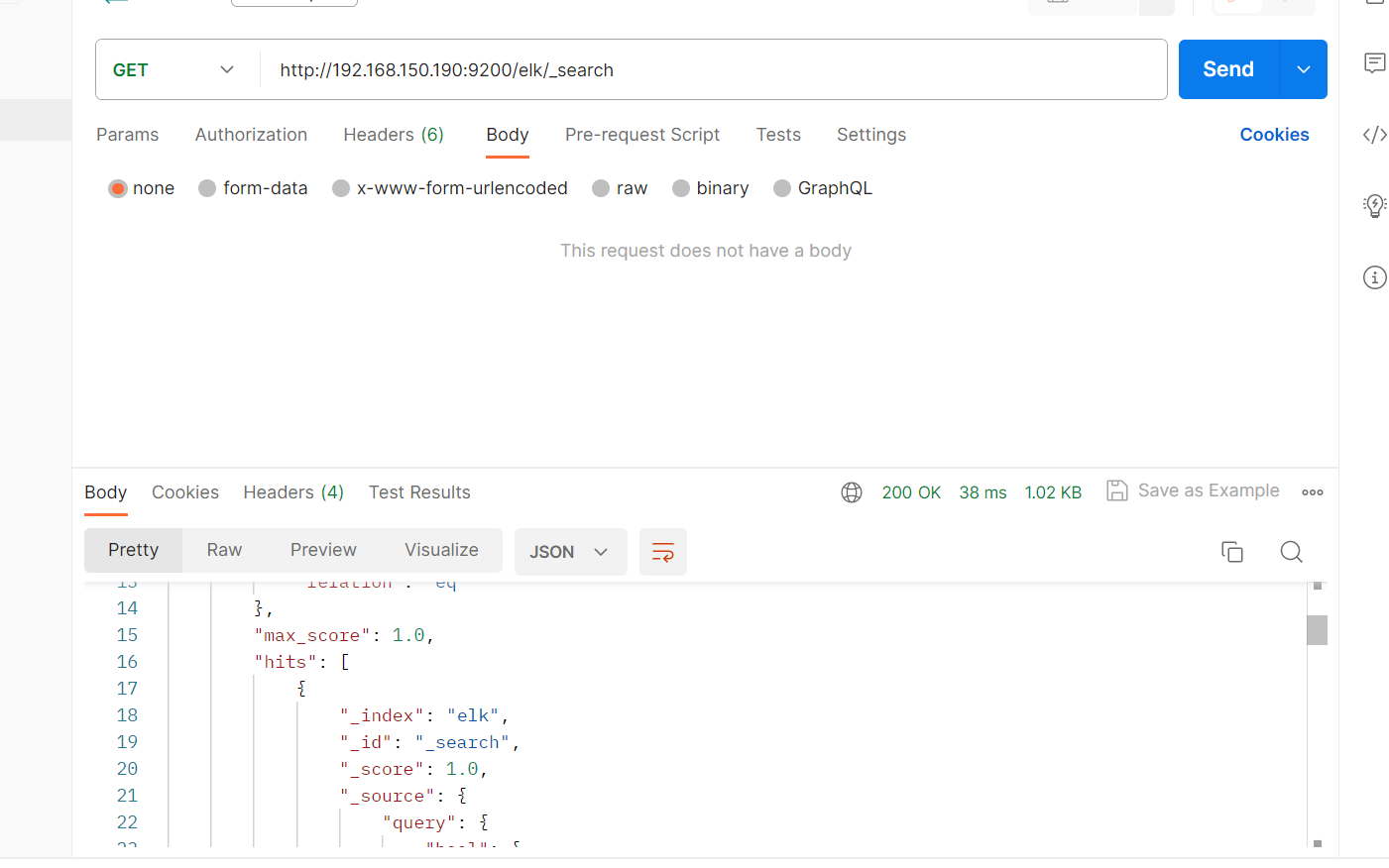
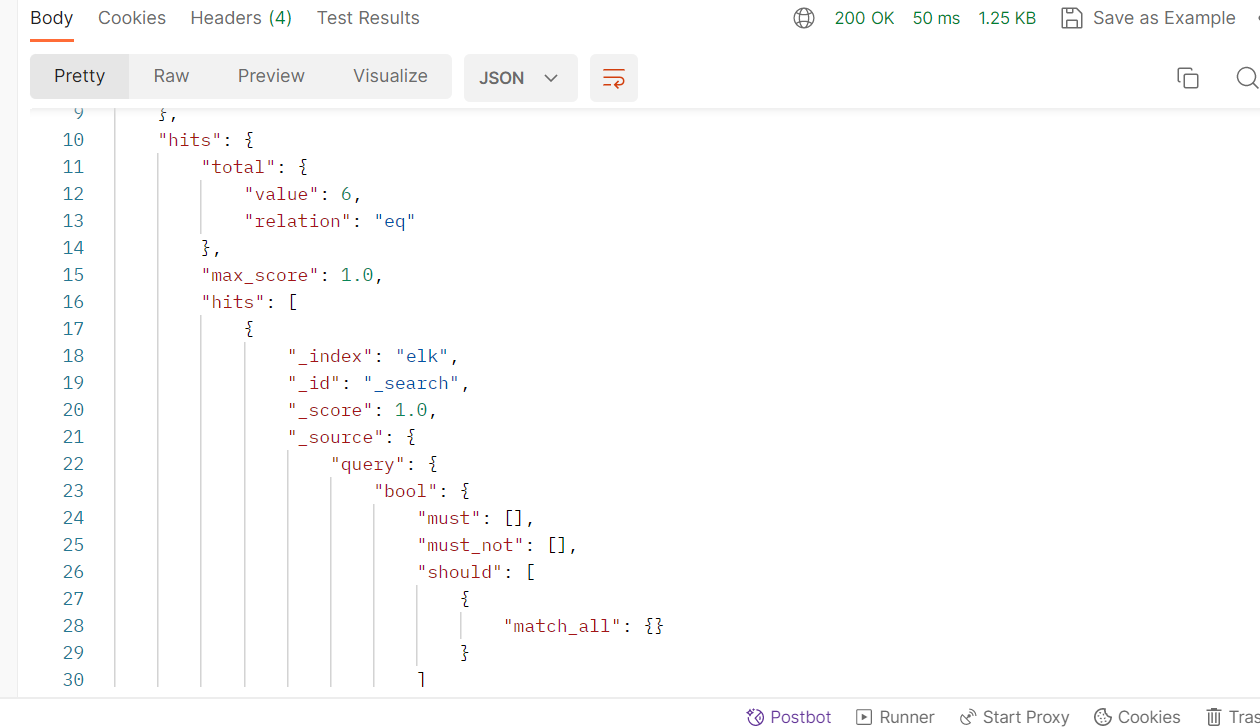
(查)搜索数据(全部)
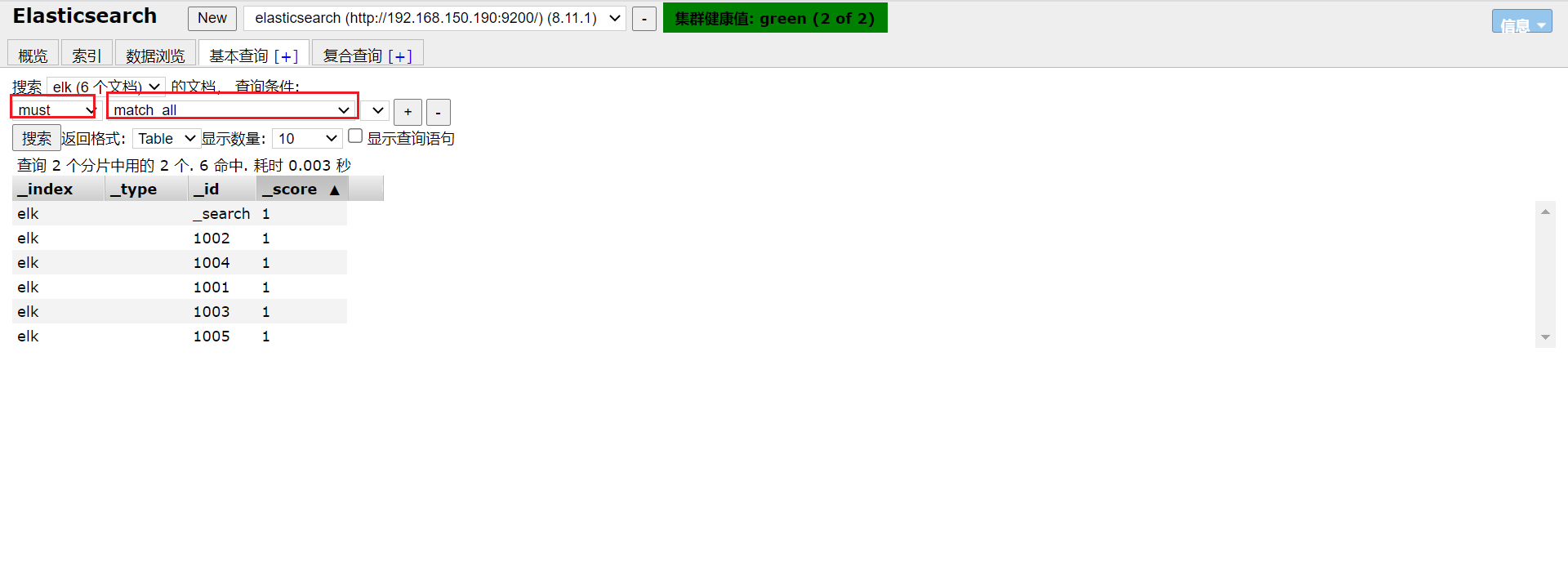
GET /elk/_search
同样的,查询全部也可以直接在elasticsearch-head中的基本查询中进行搜索。
(查)关键字搜索数据
#格式
GET /elk/_search?q=字段名:对应值#查询年龄等于13的用户
GET /elk/_search?q=age:20
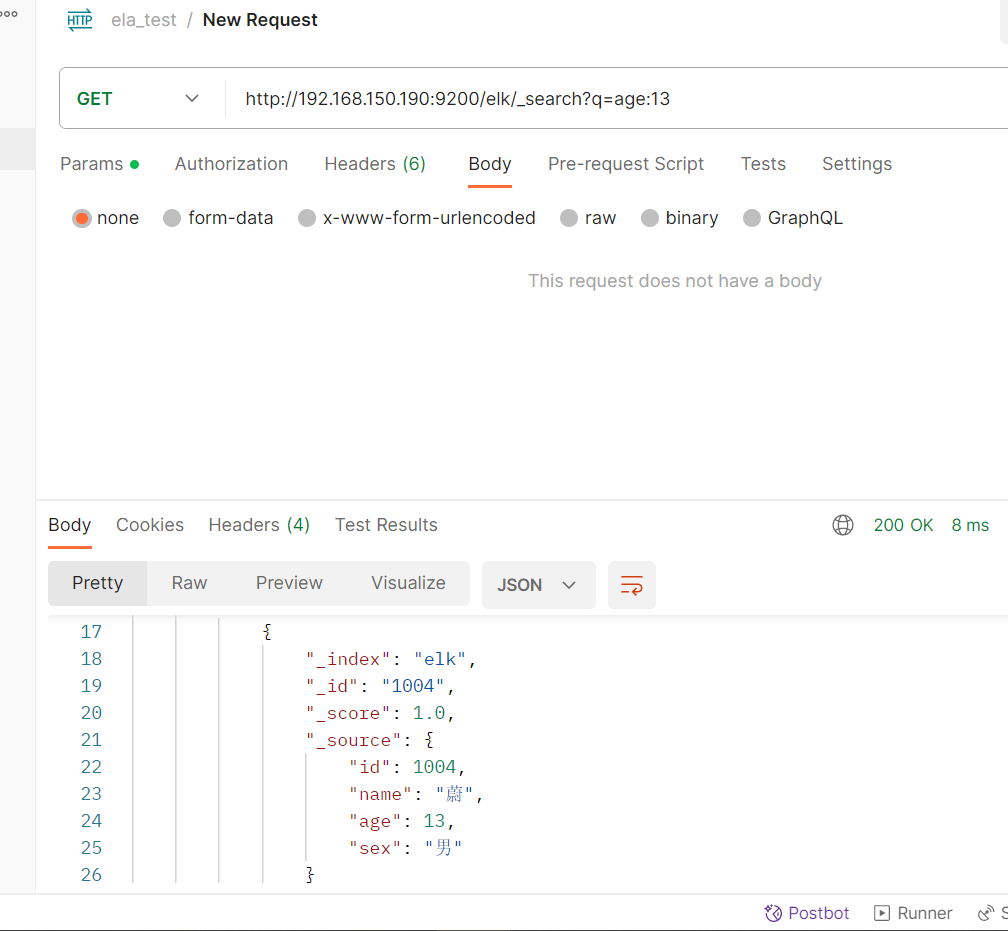
#查询年龄等于13的用户
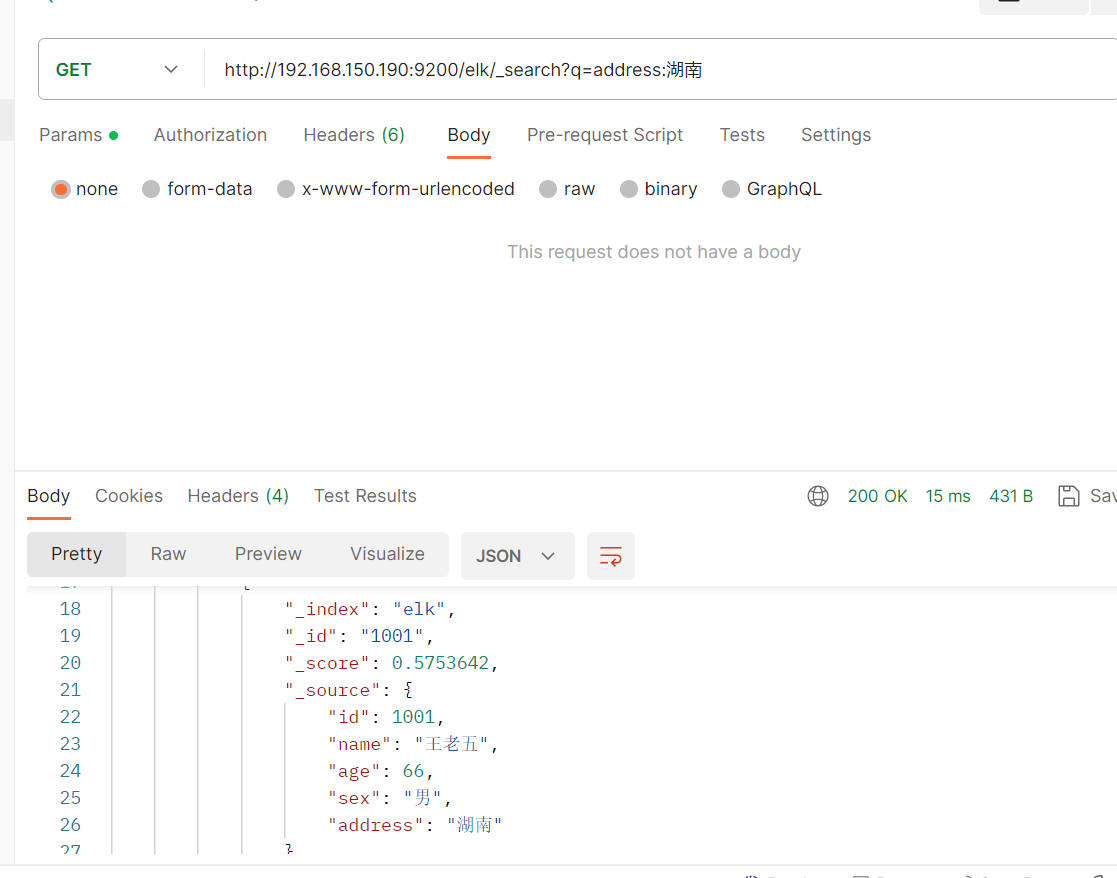
GET /elk/_search?q=address:湖南
(查)DSL搜索
Elasticsearch的DSL(Domain-Specific Language)是一种查询语言,用于在Elasticsearch中执行搜索操作。DSL允许用户以结构化的方式构建复杂的查询,以满足不同的搜索需求。DSL查询通常以JSON格式表示,并包含各种查询和过滤条件。
以下是一些常见的DSL查询语法和查询类型的详细解释:
-
Match Query:
Match查询用于执行全文本搜索,它会在指定的字段中查找包含特定词语的文档。{"query": {"match": {"field_name": "search_term"}} }匹配年龄为20的数据
POST /elk/_search #请求体 {"query" : {"match" : {"age" : 23}} }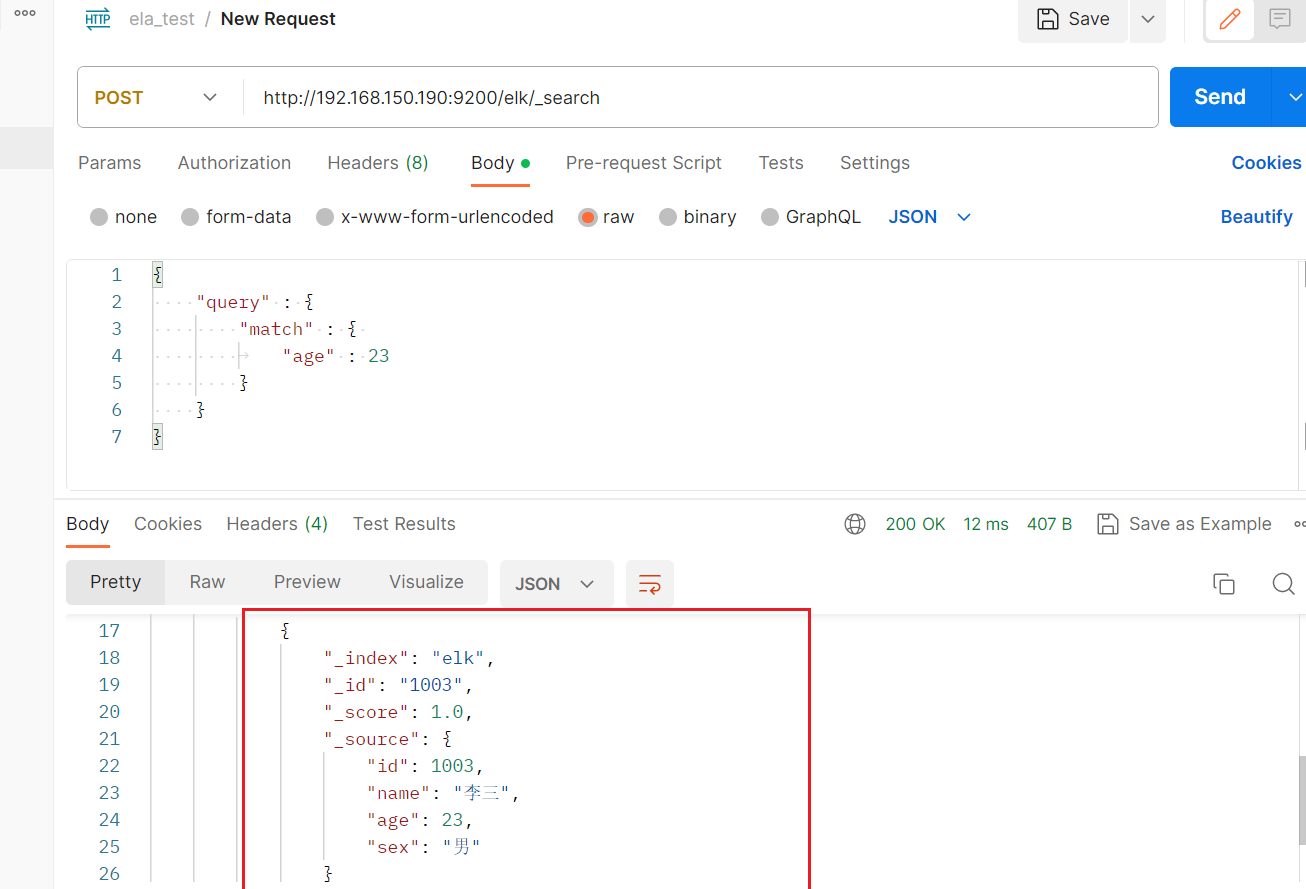
匹配多个姓名数据
POST /elk/_search #请求数据 {"query" : {"match" : {"name" : "张四 李三 王老五"}} }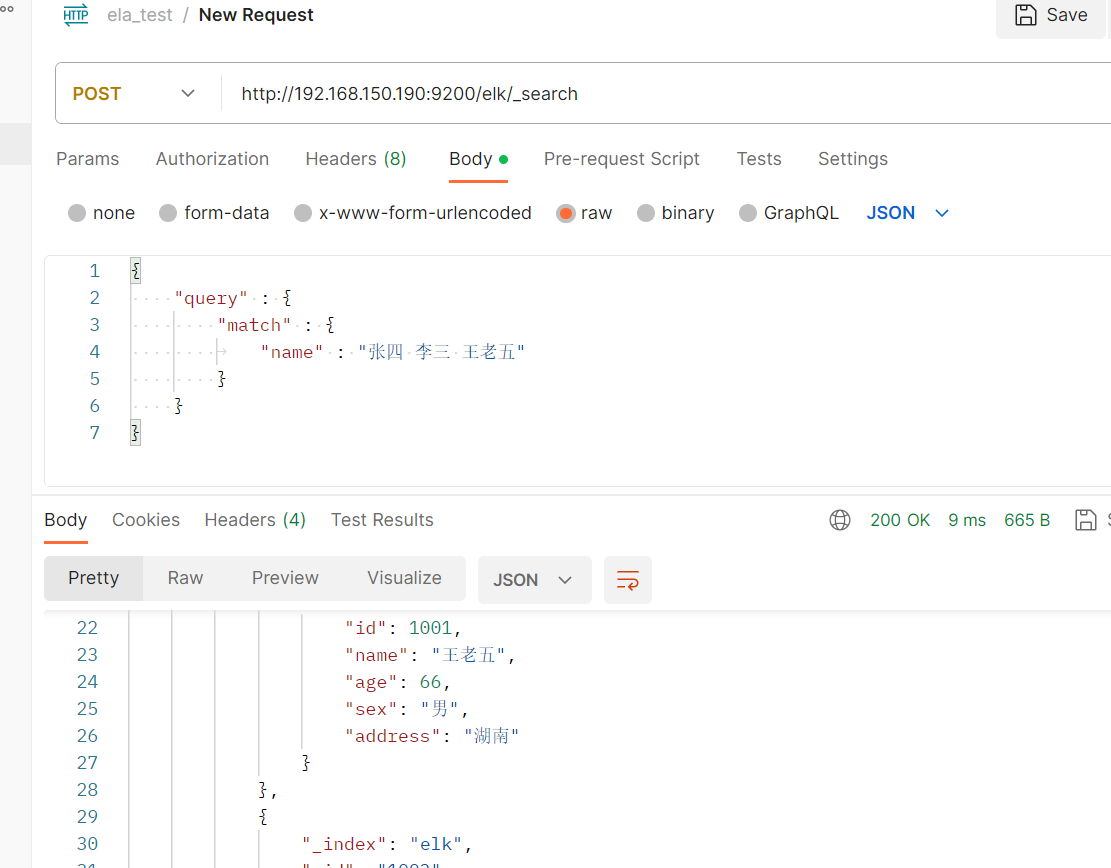
高亮显示
POST /elk/_search #请求数据 {"query": {"match": {"name": "王老五"}},"highlight": {"fields": {"name": {}}} }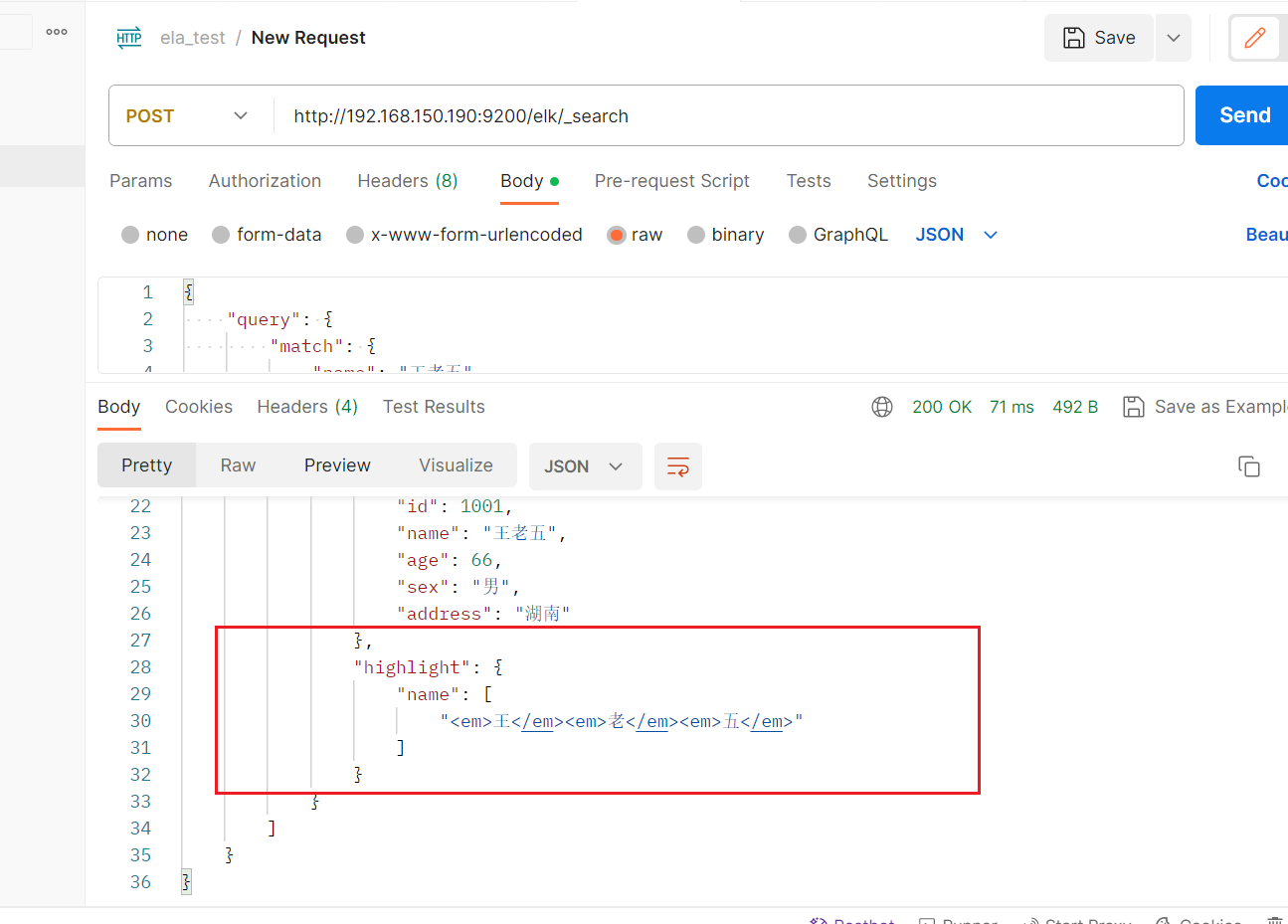
-
Term Query:
Term查询用于匹配确切的词语。它通常用于精确匹配,而不进行全文本搜索。{"query": {"term": {"field_name": "exact_term"}} } -
Bool Query: Bool查询允许将多个查询组合在一起,并使用逻辑运算符(must、must_not、should)来定义查询逻辑。
{"query": {"bool": {"must": [{ "match": { "field1": "value1" } },{ "term": { "field2": "value2" } }],"must_not": [{ "range": { "field3": { "gte": "2022-01-01" } } }],"should": [{ "term": { "field4": "value3" } }]}} }查询年龄大于18岁的男性用户。
POST /elk/user/_search #请求数据 {"query": {"bool": {"filter": {"range": {"age": {"gt": 18}}},"must": {"match": {"sex": "男"}}}} } -
Range Query:
Range查询用于匹配指定范围内的值。{"query": {"range": {"field_name": {"gte": "min_value","lte": "max_value"}}} } -
Wildcard Query:
通配符查询允许使用通配符进行模糊匹配。{"query": {"wildcard": {"field_name": "search*term"}} } -
Nested Query:
Nested查询用于在嵌套文档中执行查询。{"query": {"nested": {"path": "nested_field","query": {"match": {"nested_field.property": "value"}}}} }
这些是一些基本的DSL查询示例。在实际应用中,可以将这些查询类型组合使用,以满足特定的搜索需求。此外,Elasticsearch还支持聚合(Aggregation)、排序(Sorting)、分页(Pagination)等高级功能,可以进一步扩展查询的能力。
其他(聚合)
在Elasticsearch中,支持聚合操作,类似SQL中的group by操作。
POST /elk/_search
{"aggs": {"all_interests": {"terms": {"field": "age"}}}
}
相关文章:
ELK(四)—els基本操作
目录 elasticsearch基本概念RESTful API创建非结构化索引(增)创建空索引(删)删除索引(改)插入数据(改)数据更新(查)搜索数据(id)&…...
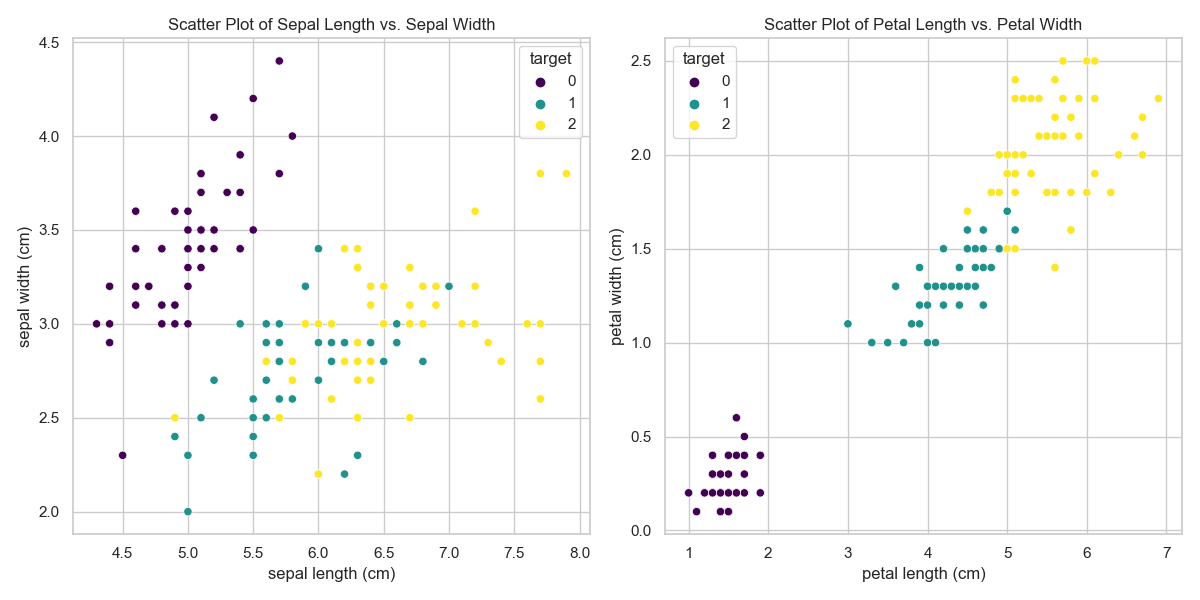
【100天精通Python】Day75:Python机器学习-第一个机器学习小项目_鸾尾花分类项目(上)
目录 1 机器学习中的Helloworld _鸾尾花分类项目 2 导入项目所需类库和鸾尾花数据集 2.1 导入类库 2.2 scikit-learn 库介绍 (1)主要特点: (2)常见的子模块: 3 导入鸾尾花数据集 3.1 概述数据 3.…...
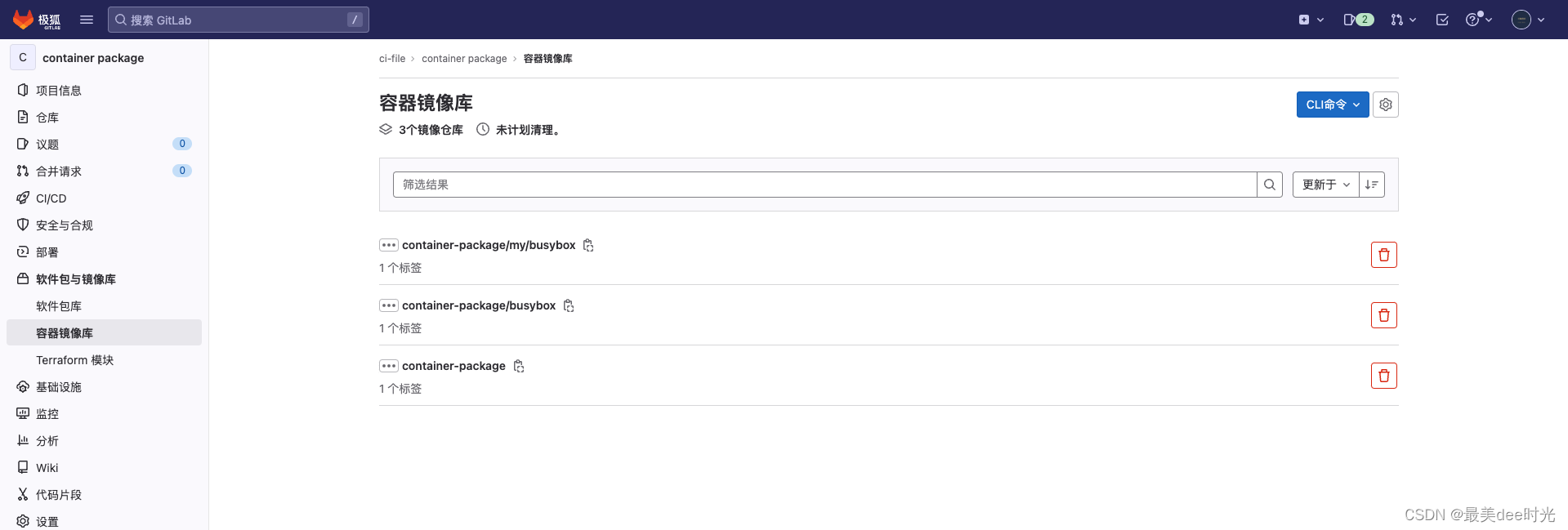
gitlab高级功能之容器镜像仓库
今天给大家介绍一个gitlab的高级功能 - Container Registry,该功能可以实现docker镜像的仓库功能,将gitlab上的代码仓的代码通过docker构建后并推入到容器仓库中,好处就是无需再额外部署一套docker仓库。 文章目录 1. 参考文档2. Container R…...
)
线程的使用(二)
新增实现方式之实现Callable接口 特点 1、可以有返回值。 2、方法可以抛异常。 3、支持泛型的返回值。 4、需借助FutureTask类,比如获取返回值。 步骤 1、创建一个实现Callable接口的实现类。 2、重写call方法, 将此线程需执行的操作声明在call&…...
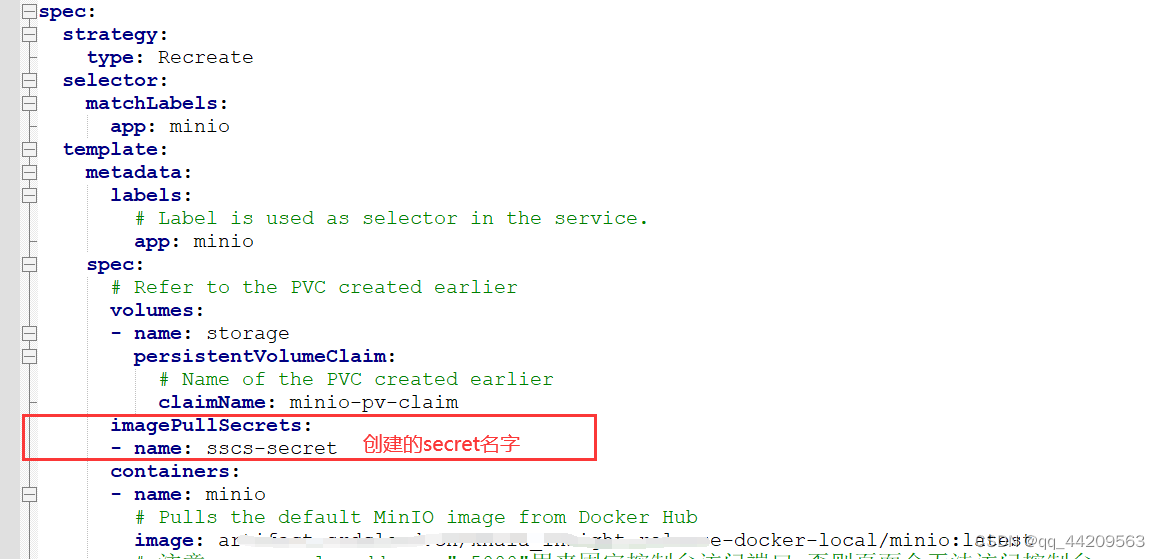
k8s之镜像拉取时使用secret
k8s之secret使用 一、说明二、secret使用2.1 secret类型2.2 创建secret2.3 配置secret 一、说明 从公司搭建的网站镜像仓库,使用k8s部署服务时拉取镜像失败,显示未授权: 需要在拉取镜像时添加认证信息. 关于secret信息,参考: https://www.…...

mysql面试题——MVCC
一:什么是MVCC? 多版本并发控制,更好的方式去处理读-写冲突,就是为了查询一些正在被另一个事务更新的行,并且可以看到它们被更新之前的值,这样在做查询的时候就不用等待另一个事务释放锁。 二:…...
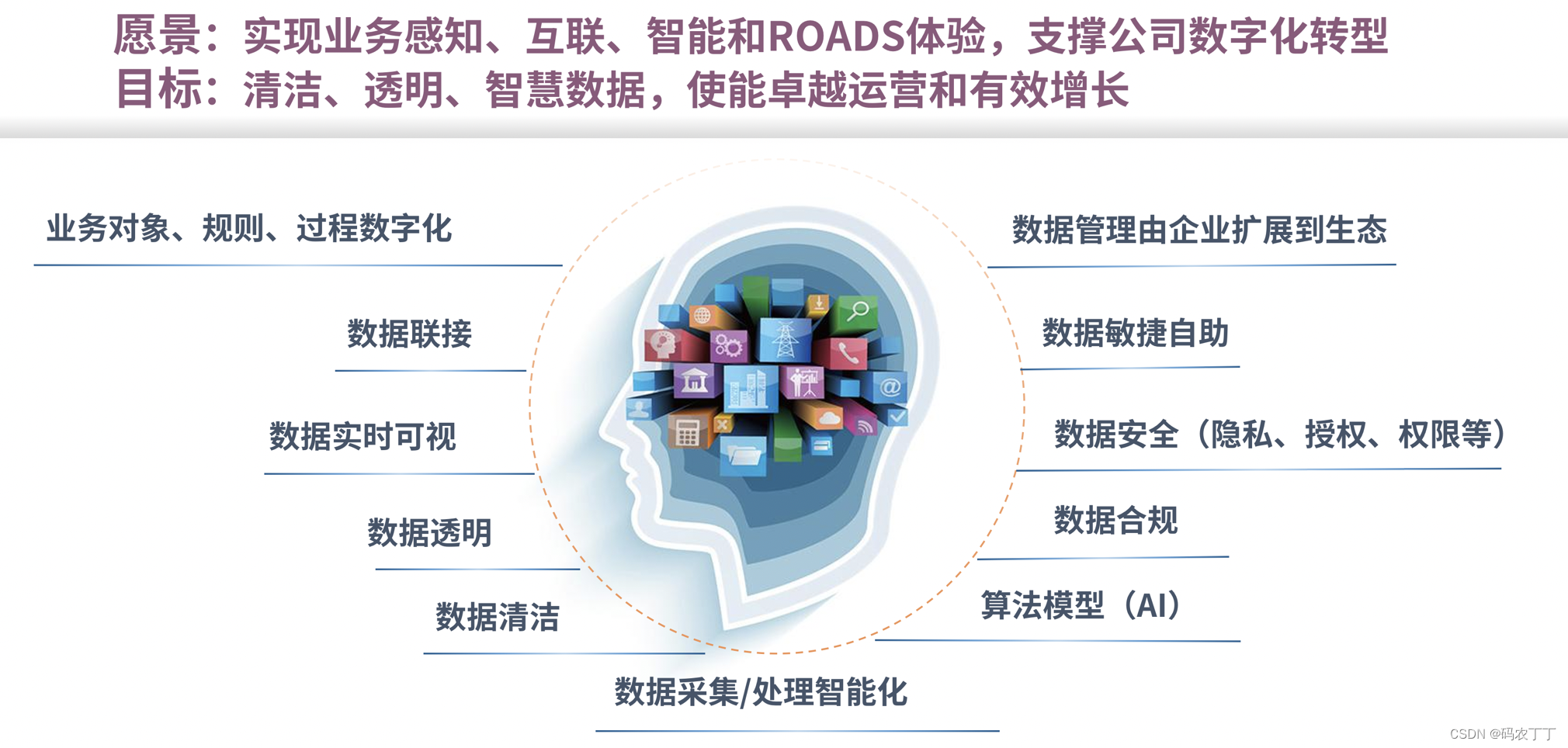
【华为数据之道学习笔记】1-2华为数字化转型与数据治理
传统企业通过制造先进的机器来提升生产效率,但是未来,如何结构性地提升服务和运营效率,如何用更低的成本获取更好的产品,成了时代性的问题。数字化转型归根结底就是要解决企业的两大问题:成本和效率,并围绕…...
微服务01
笔记: day03-微服务01 - 飞书云文档 (feishu.cn) 数据库连接不上? 要在虚拟机启动MySQL容器。docker start mysql 服务治理 服务提供者:暴露服务接口,供其他服务调用 服务消费者:调用其他服务提供的接口 注册中心&…...
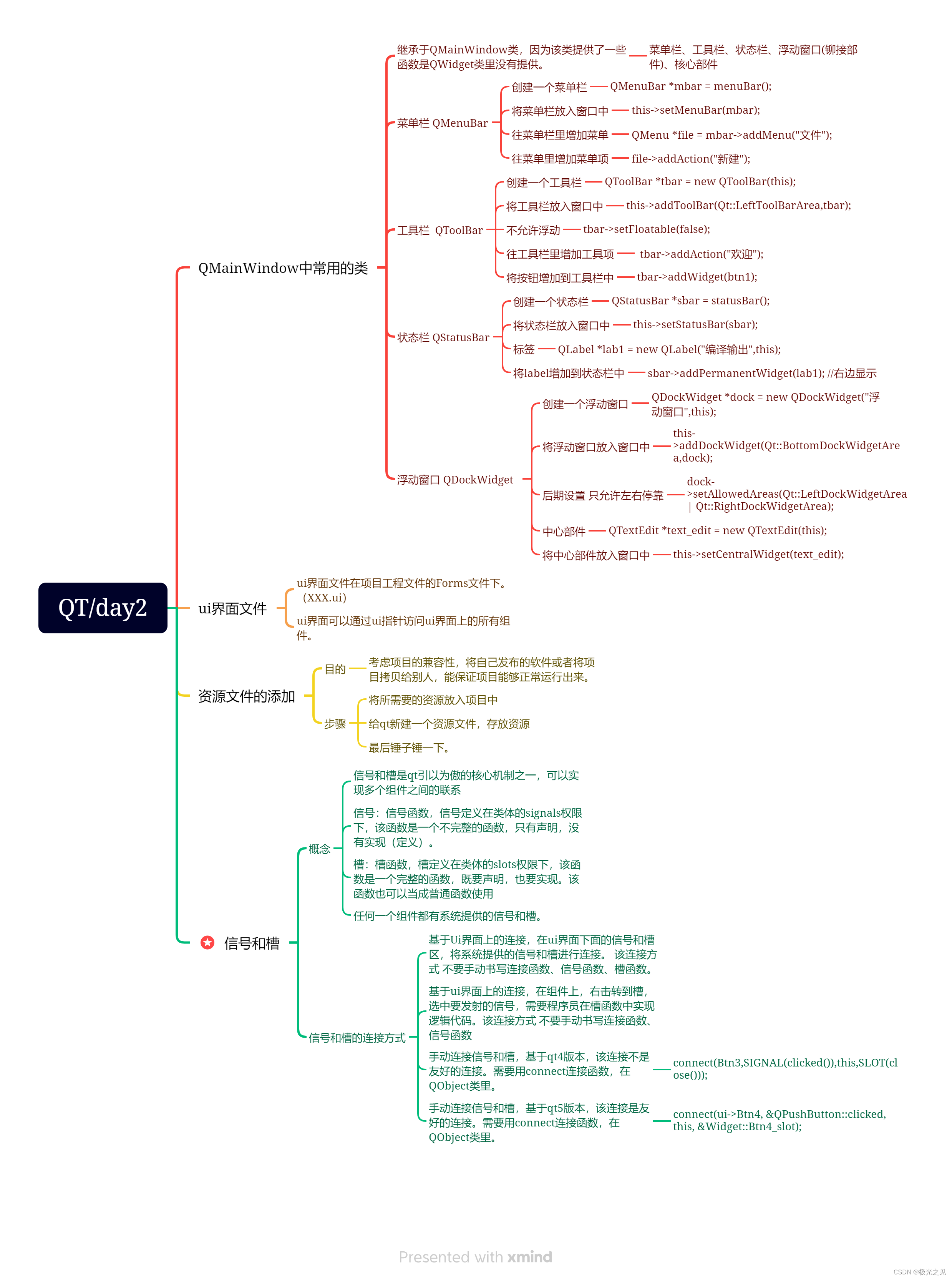
作业12.8
1. 使用手动连接,将登录框中的取消按钮使用qt4版本的连接到自定义的槽函数中,在自定义的槽函数中调用关闭函数。将登录按钮使用qt5版本的连接到自定义的槽函数中,在槽函数中判断ui界面上输入的账号是否为"admin",密码是…...

已解决error: (-215:Assertion failed) inv_scale_x > 0 in function ‘cv::resize‘
需求背景 欲使用opencv的resize函数将图像沿着纵轴放大一倍,即原来的图像大小为(384, 512), 现在需要将图像放大为(768, 512)。 源码 import cv2 import numpy as np# 生成初始图像 img np.zeros((384, 512), dtypenp.uint8) img[172:212, 32:-32] 255 H, W …...

Android View.inflate 和 LayoutInflater.from(this).inflate 的区别
前言 两个都是布局加载器,而View.inflate是对 LayoutInflater.from(context).inflate的封装,功能相同,案例使用了dataBinding。 View.inflate(context, layoutResId, root) LayoutInflater.from(context).inflate(layoutResId, root, fals…...
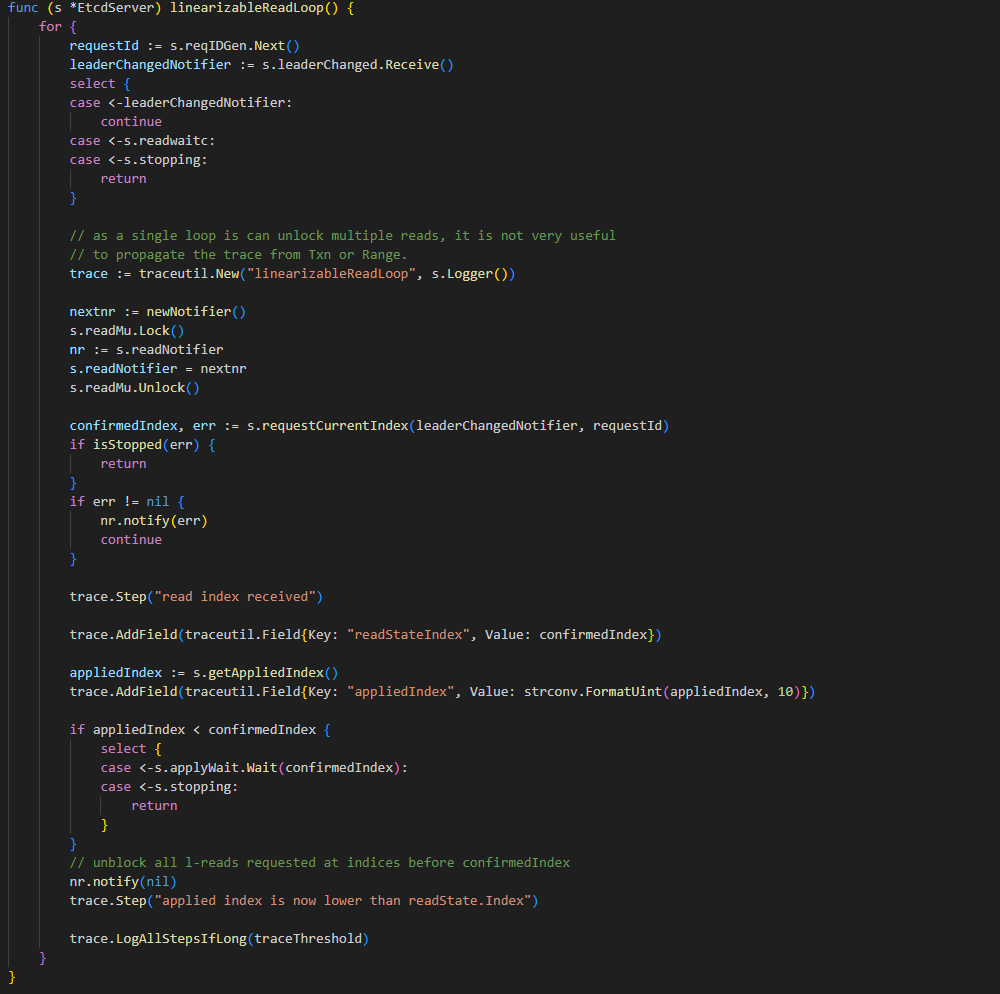
etcd 与 Consul 的一致性读对比
本文分享和对比了 etcd 和 Consul 这两个存储的一致性读的实现。 作者:戴岳兵,爱可生研发中心工程师,负责项目的需求开发与维护工作。 爱可生开源社区出品,原创内容未经授权不得随意使用,转载请联系小编并注明来源。 本…...
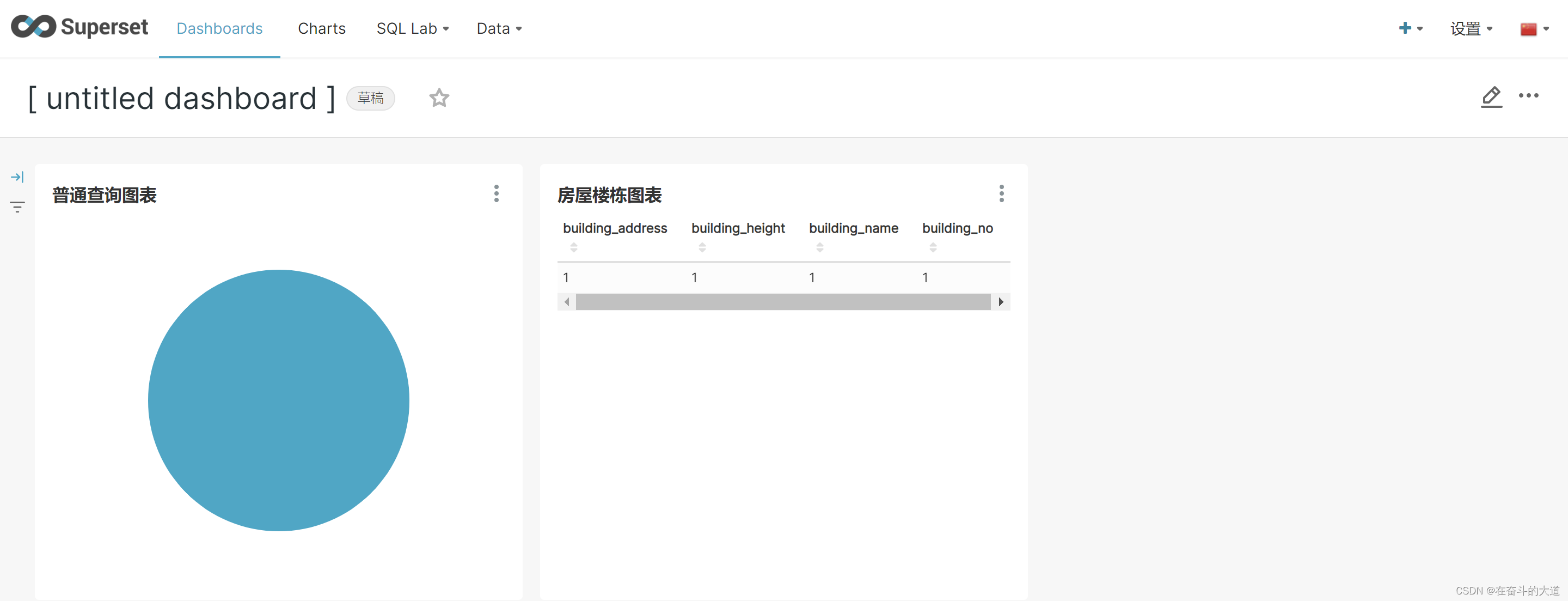
Docker 安装Apache Superset 并实现汉化和快速入门
什么是Apache Superset Apache Superset是一个现代化的企业级商业智能Web应用程序。Apache Superset 支持用户的各种数据类型可视化和数据分析,支持简单图饼图到复杂的地理空间图表。Apache Superset 是一个轻量级、简单化、直观化、可配置的BI 框架。 Docker 安…...
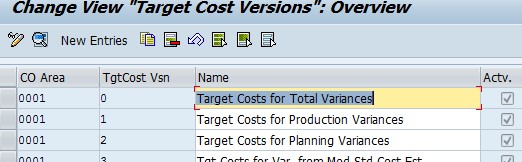
差异计算基础知识 - 了解期末业务操作、WIP 和差异
原文地址:Basics of variance calculation-Understanding Period End activities, WIP and Variances | SAP Blogs 大家好, 这是我在成本核算方面的第六份文件,旨在解释期末的差异计算和相关活动。 我将引导您完成期末活动和差异计算。在本文…...
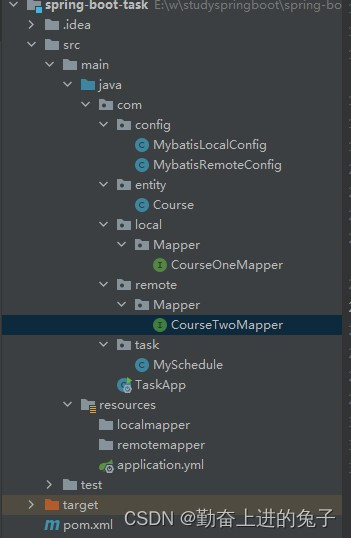
spring boot定时器实现定时同步数据
文章目录 目录 文章目录 前言 一、依赖和目录结构 二、使用步骤 2.1 两个数据源的不同引用配置 2.2 对应的mapper 2.3 定时任务处理 总结 前言 一、依赖和目录结构 <dependencies><dependency><groupId>org.springframework.boot</groupId><artifa…...

第一百九十六回 通过蓝牙发送数据的细节
文章目录 1. 概念介绍2. 实现方法3. 代码与效果3.1 示例代码3.2 运行效果4. 经验总结我们在上一章回中介绍了"分享三个使用TextField的细节"沉浸式状态样相关的内容,本章回中将介绍SliverList组件.闲话休提,让我们一起Talk Flutter吧。 1. 概念介绍 通过蓝牙设备…...

26.Python 网络爬虫
目录 1.网络爬虫简介2.使用urllib3.使用request4.使用BeautifulSoup 1.网络爬虫简介 网络爬虫是一种按照一定的规则,自动爬去万维网信息的程序或脚本。一般从某个网站某个网页开始,读取网页的内容,同时检索页面包含的有用链接地址࿰…...

Spring Boot 在启动之前还做了哪些准备工作?
目录 一:初始化资源加载器 二:校验主要源 三:设置主要源 四:推断 Web 应用类型<...
)
SQL语句常用语法(开发场景中)
一、SQL语句常用小场景 1.查询某个表信息,表中某些字段为数据字典需要进行转义 SELECTt.ID,CASEWHEN t.DINING_TYPE 1 THEN早餐WHEN t.DINING_TYPE 2 THEN午餐WHEN t.DINING_TYPE 3 THEN晚餐END AS diningTypeStr from student t 2.联表查询语法 select si.*…...

HarmonyOS应用开发者认证:开启全新的智能设备开发之旅
随着科技的不断发展,人工智能、物联网等技术逐渐渗透到我们的日常生活中。在这个智能化的时代,华为推出了一款全新的操作系统——HarmonyOS,旨在为各种智能设备提供统一的操作系统,实现设备之间的无缝连接和协同工作。作为开发者&…...

5大AI音频处理插件:用OpenVINO为Audacity注入本地智能处理能力
5大AI音频处理插件:用OpenVINO为Audacity注入本地智能处理能力 【免费下载链接】openvino-plugins-ai-audacity A set of AI-enabled effects, generators, and analyzers for Audacity. 项目地址: https://gitcode.com/gh_mirrors/op/openvino-plugins-ai-audaci…...

【限时解锁】Gemini深度研究模式私有化部署方案:仅3家头部科研机构掌握的本地化推理链配置
更多请点击: https://codechina.net 第一章:Gemini深度研究模式的核心原理与能力边界 Gemini深度研究模式并非简单增强上下文长度的推理机制,而是一种面向复杂知识密集型任务的分层式认知架构。其核心原理在于动态构建“问题-证据-推理”三元…...

AI 伪造图像在电信诈骗攻防中的应用与治理研究 —— 以韩国诱捕诈骗快递员案为例
摘要 2026 年 5 月 22 日韩国首尔西部地方法院审理的投资类电信诈骗案件中,受害人在遭遇假冒分析师诱导、虚假证券 APP 欺诈并已损失 1200 万韩元后,面对诈骗团伙以 “提现手续费” 为名进一步索要 1990 万韩元现金的行为,利用 AI 生成伪造现…...

基于C#实现的支持五笔和拼音输入的输入法
一、核心架构设计 二、关键代码实现 1. 输入法核心类 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72…...

企业内统一AI开发环境借助TaotokenCLI工具一键配置
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 企业内统一AI开发环境借助Taotoken CLI工具一键配置 在中大型企业的技术团队中,为所有开发者提供统一、标准化的AI服务…...

为团队统一开发环境使用Taotoken CLI一键配置所有成员的API密钥
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 为团队统一开发环境使用Taotoken CLI一键配置所有成员的API密钥 当团队协作参与项目或比赛时,统一API接入配置能提升效…...

零起点Python机器学习快速入门【1.1】
1.4 机器学习经典案例目前人工智能、机器学习正处于黄金时期,各种应用随处可见,以下是一些常见的机器学习应用案例。 机器人客服:当你拨打移动、银行等公司的服务热线时,大部分都是通过人工智能技术合成的电脑客服在和你沟通&am…...

Android应用架构规范深度解析与面试指南
引言 在Android应用开发中,架构设计是确保应用可维护性、可扩展性和稳定性的核心要素。随着移动应用的复杂度日益增加,采用规范的架构模式不仅能提升开发效率,还能减少错误和重构成本。本文将以“架构规范”为核心重点领域,深入探讨Android应用的主流架构模式、实现细节、…...

在Node.js后端服务中集成统一的大模型调用层
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 在Node.js后端服务中集成统一的大模型调用层 在构建现代Web应用时,为不同功能模块引入AI能力已成为提升用户体验和产品…...

响应安全规程硬性要求,无感定位规范井下人员管理 ——矿山合规化人员智能管控技术方案
响应安全规程硬性要求,无感定位规范井下人员管理——矿山合规化人员智能管控技术方案一、方案引言国家矿山安全相关规程规范、地方煤炭行业监管条例,对井下人员在岗管控、动态监测、危险行为约束、应急人员统计等方面划定明确硬性执行标准。历次安全检查…...