【ML】LSTM应用——预测股票(基于 tensorflow2)
LSTM 应用预测股票数据
所用数据集:https://www.kaggle.com/datasets/yuanheqiuye/bank-stock
基于:tensorFlow 2.x
数据处理
import numpy as np
import pandas as pd
from matplotlib import pyplot as plt
from sklearn.model_selection import train_test_split
# 读取数据
data = pd.read_csv('data.csv', index_col=0)# 将数据分为特征和目标变量
y = np.array(data['open'], dtype='float32').reshape(-1, 1)
X = np.array(data.drop('open', axis=1)).astype('float32')# 划分数据集为训练集和测试集(95%训练,5%测试)
train_xs, test_xs, train_ys, test_ys = train_test_split(X, y, test_size=0.05, random_state=42)# y 归一化处理
min_train_ys = train_ys.min()
max_train_ys = train_ys.max()
train_ys = (train_ys - min_train_ys) / (max_train_ys - min_train_ys)
test_ys = (test_ys - min_train_ys) / (max_train_ys - min_train_ys)# 对x特征进行归一化处理
for dim in range(train_xs.shape[1]):min_val = train_xs[:, dim].min()max_val = train_xs[:, dim].max()train_xs[:, dim] = (train_xs[:, dim] - min_val) / (max_val - min_val)test_xs[:, dim] = (test_xs[:, dim] - min_val) / (max_val - min_val)# 重新排列数据以创建时间序列
time_step = 5
input_dim = 13def create_time_series_data(xs, ys, time_step):aranged_xs = np.zeros(shape=(xs.shape[0] - time_step + 1, time_step, input_dim))for idx in range(aranged_xs.shape[0]):aranged_xs[idx] = xs[idx:idx + time_step]aranged_ys = ys[time_step - 1:]return aranged_xs, aranged_ysaranged_train_xs, aranged_train_ys = create_time_series_data(train_xs, train_ys, time_step)
aranged_test_xs, aranged_test_ys = create_time_series_data(test_xs, test_ys, time_step)# 保存数据
np.save(r'train_x_batch.npy', aranged_train_xs)
np.save(r'train_y_batch.npy', aranged_train_ys)
np.save(r'test_x_batch.npy', aranged_test_xs)
np.save(r'test_y_batch.npy', aranged_test_ys)
模型训练
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import tensorflow as tf# Hyperparams
batch_size = 128 # 批量大小,指定每次迭代训练时传入模型的样本数量。较大的批量大小可以加快训练速度,但可能会占用更多的内存资源。
lr = 1e-4 # 控制模型在每次迭代时更新权重的步长。较小的学习率可以使模型收敛得更慢但更稳定,较大的学习率可以加快收敛速度但可能导致不稳定的训练过程。
epochs = 400 # 训练轮数,指定模型要遍历整个训练数据集的次数。每个 epoch 包含多个批次的训练。
num_neurons = [32, 32, 64, 64, 128, 128] # 神经元数量,指定每个隐藏层的神经元数量。这里给出了一个列表,表示了模型中每个隐藏层的神经元数量。通常情况下,增加神经元数量可以增加模型的表达能力,但也可能增加过拟合的风险。
kp = 0.99 # 保持概率(keep probability),用于控制 Dropout 正则化的保留概率。Dropout 是一种正则化技术,通过随机地丢弃一部分神经元的输出来减少过拟合。保持概率 kp 指定了要保留的神经元输出的比例,例如 kp=1.0 表示保留全部输出。def load_data():train_x_batch = np.load(r'train_x_batch.npy', allow_pickle=True)train_y_batch = np.load(r'train_y_batch.npy', allow_pickle=True)return (train_x_batch, train_y_batch)# 载入数据
(train_x, train_y) = load_data()
train_data = tf.data.Dataset.from_tensor_slices((train_x, train_y)).shuffle(buffer_size=128).batch(batch_size)# 定义模型
model = tf.keras.Sequential([tf.keras.layers.LSTM(num_neurons[0], return_sequences=True, input_shape=(5, 13)),tf.keras.layers.Dropout(1 - kp),tf.keras.layers.LSTM(num_neurons[1], return_sequences=True),tf.keras.layers.Dropout(1 - kp),tf.keras.layers.LSTM(num_neurons[2], return_sequences=True),tf.keras.layers.Dropout(1 - kp),tf.keras.layers.LSTM(num_neurons[3], return_sequences=True),tf.keras.layers.Dropout(1 - kp),tf.keras.layers.LSTM(num_neurons[4], return_sequences=True),tf.keras.layers.Dropout(1 - kp),tf.keras.layers.LSTM(num_neurons[5]),tf.keras.layers.Dense(1)
])# 编译模型
model.compile(optimizer=tf.keras.optimizers.legacy.SGD(learning_rate=lr), loss='mean_squared_error')# 使用提前停止
early_stopping = tf.keras.callbacks.EarlyStopping(monitor='loss', patience=5)# 训练模型
history = model.fit(train_data, epochs=epochs, callbacks=[early_stopping])# 可视化训练过程
plt.plot(history.history['loss'])
plt.ylim(0, 1.2 * max(history.history['loss']))
plt.title('loss trend')
plt.xlabel('Epoch')
plt.ylabel('loss')
plt.show()# 保存模型
model.save(r'stock_lstm_model.keras')预测
import numpy as np
import matplotlib.pyplot as plt
import tensorflow as tfdef load_data():test_x_batch = np.load(r'test_x_batch.npy', allow_pickle=True)test_y_batch = np.load(r'test_y_batch.npy', allow_pickle=True)return (test_x_batch, test_y_batch)# 超参数
num_neurons = [32, 32, 64, 64, 128, 128]# 定义模型
model = tf.keras.Sequential([tf.keras.layers.LSTM(num_neurons[0], return_sequences=True, input_shape=(None, 13)),tf.keras.layers.LSTM(num_neurons[1], return_sequences=True),tf.keras.layers.LSTM(num_neurons[2], return_sequences=True),tf.keras.layers.LSTM(num_neurons[3], return_sequences=True),tf.keras.layers.LSTM(num_neurons[4], return_sequences=True),tf.keras.layers.LSTM(num_neurons[5]),tf.keras.layers.Dense(1)
])# 尝试加载模型权重
model.load_weights(r'stock_lstm_model.keras')# 载入数据
test_x, test_y = load_data()# 预测
predicts = model.predict(test_x)
predicts = ((predicts.max() - predicts) / (predicts.max() - predicts.min())) # 数学校准# 可视化
plt.figure(figsize=(12, 6))
plt.plot(predicts, 'r', label='predict')
plt.plot(test_y, 'g', label='real')
plt.xlabel('days')
plt.ylabel('open')
plt.title('predict trend')
plt.legend()
plt.show()相关文章:
)
【ML】LSTM应用——预测股票(基于 tensorflow2)
LSTM 应用预测股票数据 所用数据集:https://www.kaggle.com/datasets/yuanheqiuye/bank-stock 基于:tensorFlow 2.x 数据处理 import numpy as np import pandas as pd from matplotlib import pyplot as plt from sklearn.model_selection import tr…...

汇编语言程序设计实验报告
一、实验一 1、实验内容 (1)用Debug命令查看寄存器和内存中的内容 (2)上机过程及程序调试 2、实验目的 (1)要求掌握使用Debug命令查看寄存器和内存的方法; (2)通过…...
设备通信过程(通信流程、通信步骤、通信顺序、设备通信、主机通信)(MAC地址在本地链路中的作用)跳跃(hop))
广域网(WAN)设备通信过程(通信流程、通信步骤、通信顺序、设备通信、主机通信)(MAC地址在本地链路中的作用)跳跃(hop)
文章目录 广域网(WAN)通信:MAC地址在本地链路中的作用引言MAC地址概述什么是MAC地址?如何工作? MAC地址与广域网MAC地址的局限性IP地址和路由 广域网设备通信过程1. 请求生成2. 封装数据帧3. 确定下一跳4. 数据传输5. …...

ExoPlayer架构详解与源码分析(10)——H264Reader
系列文章目录 ExoPlayer架构详解与源码分析(1)——前言 ExoPlayer架构详解与源码分析(2)——Player ExoPlayer架构详解与源码分析(3)——Timeline ExoPlayer架构详解与源码分析(4)—…...

智能优化算法应用:基于粒子群算法3D无线传感器网络(WSN)覆盖优化 - 附代码
智能优化算法应用:基于粒子群算法3D无线传感器网络(WSN)覆盖优化 - 附代码 文章目录 智能优化算法应用:基于粒子群算法3D无线传感器网络(WSN)覆盖优化 - 附代码1.无线传感网络节点模型2.覆盖数学模型及分析3.粒子群算法4.实验参数设定5.算法结果6.参考文…...

微积分-序言
大家好,这里我将为大家带来一个全新的专栏“微积分”。在这里我将为大家讲解微积分的内容,我会从最基础的内容开始讲解。争取让零基础的人也可以看懂和学会。 我也会在后续出一些微积分的题,让大家可以进行巩固和提高。 学习微积分那么就需要…...

ArchLinux安装详细步骤
下载(略)安装VirtualBox(略)新建虚拟机(略)启动 进入提示符 进入安装设置界面 archinstall出现界面: 逐项设置。 Disk我选择了ext4 在Profile中 我选择了KDE作为桌面(选择后按回车…...

react 学习笔记 李立超老师 | (学习中~)
文章目录 react学习笔记01入门概述React 基础案例HelloWorld三个API介绍 JSXJSX 解构数组 创建react项目(手动)创建React项目(自动) | create-react-app事件处理React中的CSS样式内联样式 | 内联样式中使用state (不建议使用)外部样式表 | CSS Module React组件函数式组件和类组…...

Docker镜像和容器的简单操作
1.镜像管理 搜索镜像: 这种方法只能用于官方镜像库 搜索基于 centos 操作系统的镜像 # docker search centos 按星级搜索镜像: 查找 star 数至少为 100 的镜像,默认不加 s 选项找出所有相关 ubuntu 镜像…...

章鱼网络进展月报 | 2023.11.1-11.30
章鱼网络大事摘要 1、2023年12月,Octopus 2.0 将会正式启动。 2、隐私协议 Secret Network 宣布使用 Octopus Network 构建的 NEAR-IBC 连接 NEAR 生态。 3、Louis 受邀作为嘉宾,在 NEARCON2023 的多链网络主题沙龙中发言:我们依然处于区…...
基于Maven构建OSGI应用(Maven和OSGI结合)
基于Maven构建OSGI应用。 使用Maven来构建项目,包括项目的创建、子模块buldle的创建等。使用OSGI来实现动态模块化管理,实现模块的热插拔效果(即插即用)。 创建一个Maven项目:helloworld,并在该项目下创建…...

oracle分组排序后取第一条
在 Oracle 中,可以使用「ROW_NUMBER」函数对某个列进行分组并排序,然后通过「WHERE」语句取第一条记录。 假设有一张「USERS」表,其中包含「ID」、「NAME」、「AGE」和「COUNTRY」列,您可以使用以下 SQL 语句对「AGE」列进行分组…...

MAMBA介绍:一种新的可能超过Transformer的AI架构
有人说,“理解了人类的语言,就理解了世界”。一直以来,人工智能领域的学者和工程师们都试图让机器学习人类的语言和说话方式,但进展始终不大。因为人类的语言太复杂,太多样,而组成它背后的机制,…...
win系统一台电脑安装两个不同版本的mysql教程
文章目录 1.mysql下载zip包(地址)2.解压在你的电脑上(不要再C盘和带中文的路径)3.创建my.ini文件4.更改环境变量(方便使用, 可选)5.打包mysql服务6.初始化mysql的data7.启动刚刚打包的服务8.更改密码 1.mys…...

esp32-s3部署yolox_nano进行目标检测
ESP32-S3部署yolox_nano进行目标检测 一、生成模型部署项目01 环境02 配置TVM包03 模型量化3.1预处理3.2 量化 04 生成项目 二、烧录程序 手上的是ESP32-S3-WROOM-1 N8R8芯片,整个链路跑通了,但是识别速度太慢了,20秒一张图,所以暂…...
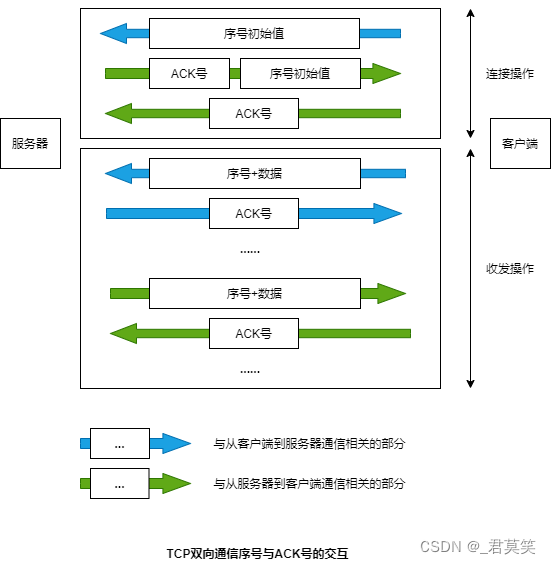
TCP传输数据的确认机制
实际的TCP收发数据的过程是双向的。 TCP采用这样的方式确认对方是否收到了数据,在得到对方确认之前,发送过的包都会保存在发送缓冲区中。如果对方没有返回某些包对应的ACK号,那么就重新发送这些包。 这一机制非常强大。通过这一机制…...

使用Ansible Expect模块实现自动化交互式任务
Ansible是一种功能强大的自动化工具,可用于自动化配置管理、部署和任务执行。其中的Expect模块是Ansible的一个重要组件,它允许我们自动化处理需要与交互式命令行进行交互的任务。本文将介绍如何使用Ansible的Expect模块,并提供一些示例来说明…...
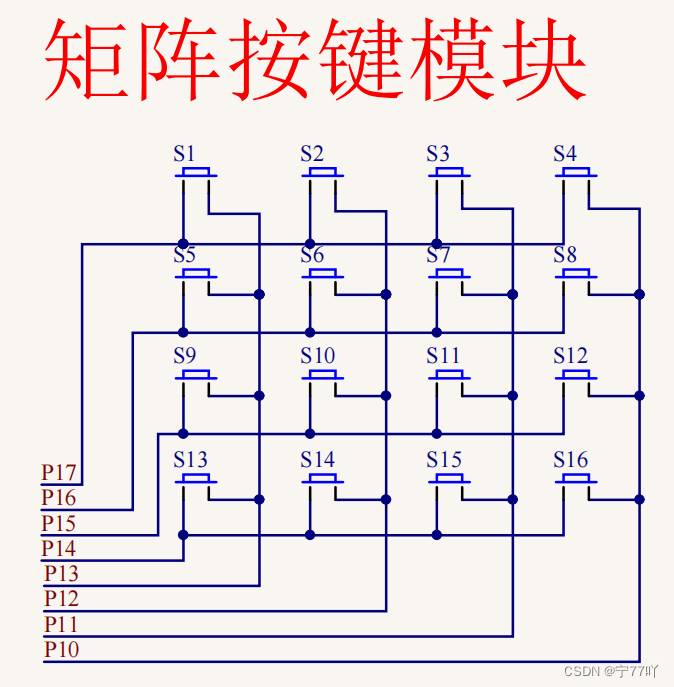
51单片机独立按键以及矩阵按键的使用以及其原理--独立按键 K1 控制 D1 指示灯亮灭以及数码管显示矩阵按键 S1-S16 按下后键值 0-F
IO 的使用–按键 本文主要涉及8051单片机按键的使用,包括独立按键以及矩阵按键的使用以及其原理,其中代码实例包括: 1.独立按键 K1 控制 D1 指示灯亮灭 2.通过数码管显示矩阵按键 S1-S16 按下后键值 0-F 文章目录 IO 的使用--按键一、按键消抖二、独立按…...
chrome安装jsonview
写在前面 通过jsonview可以实现,当http响应时application/json时直接在浏览器格式化显示,增加可读性。本文看下如何安装该插件到chrome中。 1:安装 首先在这里 下载插件包,然后解压备用。接着在chrome按照如下步骤操作…...
使用TouchSocket适配一个c++的自定义协议
这里写目录标题 说明一、新建项目二、创建适配器三、创建服务器和客户端3.1 服务器3.2 客户端3.3 客户端发送3.4 客户端接收3.5 服务器接收与发送 四、关于同步Send 说明 今天有小伙伴咨询我,他和同事(c端)协商了一个协议,如果使…...

Hotkey Detective:3分钟解决Windows热键冲突的专业侦探工具
Hotkey Detective:3分钟解决Windows热键冲突的专业侦探工具 【免费下载链接】hotkey-detective A small program for investigating stolen key combinations under Windows 7 and later. 项目地址: https://gitcode.com/gh_mirrors/ho/hotkey-detective 你是…...

如何用Python双引擎架构实现90%成功率的自动抢票系统?
如何用Python双引擎架构实现90%成功率的自动抢票系统? 【免费下载链接】Automatic_ticket_purchase 大麦网抢票脚本 项目地址: https://gitcode.com/GitHub_Trending/au/Automatic_ticket_purchase 当热门演唱会门票在几秒内售罄,当体育赛事门票成…...

Thorium浏览器:面向企业级部署的技术选型与架构决策指南
Thorium浏览器:面向企业级部署的技术选型与架构决策指南 【免费下载链接】thorium Chromium fork named after radioactive element No. 90. Source code and Linux releases. Windows/MacOS/ARM builds served in different repos, links are towards the top of t…...

微信小程序逆向:基于Frida Hook WeChatAppHost.dll解密wxapkg
1. 这不是“破解”,而是一次对微信小程序加载机制的逆向观察WeChatAppHost.dll 是 Windows 版微信客户端中承载小程序运行环境的核心动态链接库,它不对外公开接口,也不提供调试符号,但却是所有小程序资源加载、解密、注入与执行的…...
)
别再死记硬背了!用Python手把手拆解卡尔曼滤波的5个核心公式(附filterpy/OpenCV两种实现)
别再死记硬背了!用Python手把手拆解卡尔曼滤波的5个核心公式(附filterpy/OpenCV两种实现)卡尔曼滤波就像一位隐形的数据调酒师,它能将嘈杂的观测数据与不完美的预测模型混合,调制出一杯接近真实状态的"鸡尾酒&quo…...

如何用roop-unleashed实现零门槛AI换脸:三分钟制作专业级视频的完整指南
如何用roop-unleashed实现零门槛AI换脸:三分钟制作专业级视频的完整指南 【免费下载链接】roop-unleashed Evolved Fork of roop with Web Server and lots of additions 项目地址: https://gitcode.com/gh_mirrors/ro/roop-unleashed 想要制作令人惊艳的AI换…...

Sunshine虚拟手柄终极指南:解决游戏串流控制难题
Sunshine虚拟手柄终极指南:解决游戏串流控制难题 【免费下载链接】Sunshine Self-hosted game stream host for Moonlight. 项目地址: https://gitcode.com/GitHub_Trending/su/Sunshine 在游戏串流体验中,最令人沮丧的莫过于手柄连接失败、按键映…...

Win10下ENSP USG6000镜像加载卡在###?别慌,VirtualBox网卡桥接这个设置是关键
Win10下ENSP USG6000镜像加载卡在###的终极解决方案 当你满怀期待地在Windows 10上启动ENSP模拟器,拖入USG6000防火墙设备,却只看到一串无情的 ### 符号时,那种挫败感我深有体会。作为一名曾经被这个问题折磨数小时的网络工程师,…...

如何解决网易云音乐NCM格式限制:ncmdump完整实战指南
如何解决网易云音乐NCM格式限制:ncmdump完整实战指南 【免费下载链接】ncmdump 项目地址: https://gitcode.com/gh_mirrors/ncmd/ncmdump 你是否曾因网易云音乐的NCM加密格式而无法在喜欢的播放器上聆听音乐?ncmdump正是你需要的解决方案。这款开…...

智能诊断指南:5步实现浏览器扩展资源嗅探优化
智能诊断指南:5步实现浏览器扩展资源嗅探优化 【免费下载链接】cat-catch 猫抓 浏览器资源嗅探扩展 / cat-catch Browser Resource Sniffing Extension 项目地址: https://gitcode.com/GitHub_Trending/ca/cat-catch 想要轻松捕获在线视频资源却不知从何下手…...