diffusers pipeline拆解:理解pipelines、models和schedulers
diffusers pipeline拆解:理解pipelines、models和schedulers
翻译自:https://huggingface.co/docs/diffusers/using-diffusers/write_own_pipeline v0.24.0
diffusers 设计初衷就是作为一个简单且易用的工具包,来帮助你在自己的使用场景中构建 diffusion 系统。diffusers 的核心是 models 和 schedulers。而 DiffusionPipeline 则将这些组件打包到一起,从而可以简便地使用。在了解其中原理之后,你也可以将这些组件(models 和 schedulers)拆开,来构建适合自己场景的 diffusion 系统。
本文将介绍如何使用 models 和 schedulers 来组建一个 diffusion 系统用作推理生图。我们先从最基础的 DDPMPipeline 开始,然后介绍更复杂、更常用的 StableDiffusionPipeline。
解构DDPMPipeline
以下是 DDPMPipeline 构建和推理的示例:
from diffusers import DDPMPipelineddpm = DDPMPipeline.from_pretrained("google/ddpm-cat-256", use_safetensors=True).to("cuda")
image = ddpm(num_inference_steps=25).images[0]
image

这就是 diffusers 中使用 pipeline 进行推理生图的全部步骤了,是不是超级简单!那么,在 pipeline 背后实际上都做了什么呢?我们接下来将 pipeline 拆解开,看一下它具体做了什么事。
我们提到,pipeline 主要的组件是 models 和 schedulers,在上面的 DDPMPipeline 中,就包含了 UNet2DModel 和 DDPMScheduler。该 pipeline 首先产生一个与输出图片尺寸相同的噪声图,在每个时间步(timestep),将噪声图传给 model 来预测噪声残差(noise residual),然后 scheduler 会根据预测出的噪声残差得到一张噪声稍小的图像,如此反复,直到达到预设的最大时间步,就得到了一张高质量生成图像。
我们可以不直接调用 pipeline 的 API,根据下面的步骤自己走一遍 pipeline 做的事情:
加载模型 model 和 scheduler
from diffusers import DDPMScheduler, UNet2DModelscheduler = DDPMScheduler.from_pretrained("google/ddpm-cat-256")
model = UNet2DModel.from_pretrained("google/ddpm-cat-256", use_safetensors=True).to("cuda")
设置timesteps
scheduler.set_timesteps(50)
scheduler.timesteps
# 输出:
tensor([980, 960, 940, 920, 900, 880, 860, 840, 820, 800, 780, 760, 740, 720,700, 680, 660, 640, 620, 600, 580, 560, 540, 520, 500, 480, 460, 440,420, 400, 380, 360, 340, 320, 300, 280, 260, 240, 220, 200, 180, 160,140, 120, 100, 80, 60, 40, 20, 0])
在对 scheduler 设置好总的去噪步数之后,ddpm scheduler 会创建一组均匀间隔的数组,本例中我们将 temesteps 设置为 50,所以该数组的长度为 50。在进行去噪时,数组中的每个元素对应了一个时间步,在之后不断循环的去噪中,我们在每一步会遍历用到这个数组的元素。
采样随机噪声
采样一个与输出图片尺寸相同的随机噪声:
import torchsample_size = model.config.sample_size
noise = torch.randn((1, 3, sample_size, sample_size), device="cuda")
实现迭代去噪循环
然后我们写一个循环,来迭代这些时间步。在每个 step,UNet2DModel 都会进行一次 forward,并返回预测的噪声残差。scheduler 的 step 方法接收 噪声残差 noisy_residual 、当前时间步 t 和 input 作为输入,输出前一时间步的噪声稍小的图片。然后该输出会作为下一时间步的模型输入。反复迭代这个过程,直到将 timesteps 迭代完。
input = noisefor t in scheduler.timesteps:with torch.no_grad():noisy_residual = model(input, t).sampleprevious_noisy_sample = scheduler.step(noisy_residual, t, input).prev_sampleinput = previous_noisy_sample
以上就是完整的去噪过程了,你也可以使用类似的方式来实现自己的 diffusion 系统。
-
最后一步我们将去噪输出转换为 pillow 图片,看一下结果:
from PIL import Image import numpy as npimage = (input / 2 + 0.5).clamp(0, 1).squeeze() image = (image.permute(1, 2, 0) * 255).round().to(torch.uint8).cpu().numpy() image = Image.fromarray(image) image
以上就是基础的 DDPMPipeline 背后实际做的事情了。首先,初始化 model 和 scheduler,然后为 scheduler 设置最大时间步,创建一个时间步数组,然后我们采样一个随机噪声,循环遍历 timestep,在每个 step,模型会预测出一个噪声残差,scheduler 根据这个噪声残差来生成一个噪声稍小的图片,如此迭代,直到走完所有 step。
接下来我们将看一下更复杂、更强大的 StableDiffusionPipeline,整体的步骤与上面的 DDPMPipeline 类似。
解构StableDiffusionPipeline
Stable Diffusion 是一种 latent diffusion 的文生图模型。所谓 latent diffusion,指的是其扩散过程是发生在低维度的隐层空间,而非真实的像素空间。这样的模型比较省内存。vae encoder 将图片压缩成一个低维的表示,vae decoder 则负责将压缩特征转换回为真实图片。对于文生图的模型,我们还需要一个 tokenizer 和一个 text encoder 来生成 text embedding,还有,在前面的 DDPMPipeline 中已经提到的 Unet model 和 scheduler。可以看到,Stable Diffusion 已经比 DDPM pipeline 要复杂的多了,它包含了三个独立的预训练模型。
加载模型、设置参数
现在我们先将各个组件通过 from_pretrained 方法加载进来。这里我们先用 SD1.5 的预训练权重,每个组件存放在不同的子目录中:
from PIL import Image
import torch
from transformers import CLIPTextModel, CLIPTokenizer
from diffusers import AutoencoderKL, UNet2DConditionModel, PNDMSchedulervae = AutoencoderKL.from_pretrained("CompVis/stable-diffusion-v1-4", subfolder="vae", use_safetensors=True)
tokenizer = CLIPTokenizer.from_pretrained("CompVis/stable-diffusion-v1-4", subfolder="tokenizer")
text_encoder = CLIPTextModel.from_pretrained("CompVis/stable-diffusion-v1-4", subfolder="text_encoder", use_safetensors=True
)
unet = UNet2DConditionModel.from_pretrained("CompVis/stable-diffusion-v1-4", subfolder="unet", use_safetensors=True
)
这里我们使用 UniPCMultistepScheduler 来替换掉默认的 PNDMScheduler。没别的意思,就为了展示一下替换一个其他的 scheduler 组件有多么简单:
from diffusers import UniPCMultistepSchedulerscheduler = UniPCMultistepScheduler.from_pretrained("CompVis/stable-diffusion-v1-4", subfolder="scheduler")
然后将各个模型放到 cuda 上:
torch_device = "cuda"
vae.to(torch_device)
text_encoder.to(torch_device)
unet.to(torch_device)
配置一些参数:
prompt = ["a photograph of an astronaut riding a horse"] # prompt按自己喜好设置,想生成什么就描述什么
height = 512 # SD 默认高
width = 512 # SD 默认款
num_inference_steps = 25 # 去噪步数
guidance_scale = 7.5 # classifier-free guidance (CFG) scale
generator = torch.manual_seed(0) # 随机种子生成器,用于控制初始的噪声图
batch_size = len(prompt)
其中 guidance_scale 参数表示图片生成过程中考虑 prompt 的权重。
创建 text embedding
接下来,我们来对条件 prompt 进行 tokenize,并通过 text encoder 模型产生文本 embedding:
text_input = tokenizer(prompt, padding="max_length", max_length=tokenizer.model_max_length, truncation=True, return_tensors="pt"
)with torch.no_grad():text_embeddings = text_encoder(text_input.input_ids.to(torch_device))[0]
我们还需要产生无条件的 text tokens,其完全有 padding token 组成,然后经过 text encoder,得到 uncond_embedding 的 batch_size 和 seq_length 需要与刚刚得到的条件 text embedding 相等。我们将 条件 embedding 和无条件 embedding 拼起来,从而进行并行的 forward:
max_length = text_input.input_ids.shape[-1]
uncond_input = tokenizer([""] * batch_size, padding="max_length", max_length=max_length, return_tensors="pt")
uncond_embeddings = text_encoder(uncond_input.input_ids.to(torch_device))[0]text_embeddings = torch.cat([uncond_embeddings, text_embeddings])
采样随机噪声
之前提到,SD 的扩散过程是在低维度的 latent 空间进行的,因此此时采样的随机噪声的尺寸比最终生成图片小。对这个 latent 噪声进行迭代去噪。我们随后会通过 vae decoder 将它解码到真实图片的尺寸,即 512。
vae enoder (在 img2img 中使用, text2img 不需要) 和 vae decoder 分别用于将真实尺寸的图片映射到低维 latent 空间,和将低维 latent 解码为真实图片。由于 vae 有三个降采样层,每次会将图片尺寸缩小一半,从而总共缩小了 2**3=8 倍,因此我们将原图的尺寸缩小 8 倍,得到 latent 空间的噪声尺寸。
# 2 ** (len(vae.config.block_out_channels) - 1) == 8latents = torch.randn((batch_size, unet.config.in_channels, height // 8, width // 8),generator=generator,device=torch_device,
)
对图像进行去噪
首先我们要先对噪声进行放缩,乘上一个系数 sigma,这可以提升某些 schedulers 的效果,比如我们刚替换的 UniPCMultistepScheduler:
latents = latents * scheduler.init_noise_sigma
然后,我们写一个循环,将 latent 空间的纯噪声一步步地去噪为关于我们 prompt 的 latent 图。和之前 DDPM 的循环类似,整体上我们要做三件事情:
- 设置 scheduler 的总去噪步数
- 迭代进行这些去噪步
- 在每一步,使用 UNet model 来预测噪声残差,并将其传给 scheduler ,生成出上一步的噪声图片
不同的是,我们这里的 SD 需要做 classifer-guidance generation:
from tqdm.auto import tqdmscheduler.set_timesteps(num_inference_steps)for t in tqdm(scheduler.timesteps):# 我们要做 classifier-guidance generation,所以先扩一下 latent,方便并行推理latent_model_input = torch.cat([latents] * 2)latent_model_input = scheduler.scale_model_input(latent_model_input, timestep=t)# 预测噪声残差with torch.no_grad():noise_pred = unet(latent_model_input, t, encoder_hidden_states=text_embeddings).sample# 进行引导noise_pred_uncond, noise_pred_text = noise_pred.chunk(2)noise_pred = noise_pred_uncond + guidance_scale * (noise_pred_text - noise_pred_uncond)# 生成前一步的 x_t -> x_t-1latents = scheduler.step(noise_pred, t, latents).prev_sample
图片解码
最后一步我们使用 vae decoder 来对去噪之后 latent representation 进行解码生成出真实图片。并转换成 pillow image 查看结果。
# scale and decode the image latents with vae
latents = 1 / 0.18215 * latents
with torch.no_grad():image = vae.decode(latents).sampleimage = (image / 2 + 0.5).clamp(0, 1).squeeze()
image = (image.permute(1, 2, 0) * 255).to(torch.uint8).cpu().numpy()
images = (image * 255).round().astype("uint8")
image = Image.fromarray(image)
image

从基础的 DDPMPipeline 到更复杂的 StableDiffusionPipeline,我们了解了如何构建自己的 diffusion 系统。关键就是在迭代去噪循环的视线。主要包含设定 timesteps、遍历 timesteps 并交替使用 UNet model 进行噪声预测和使用 scheduler 进行前一步图的计算。这就是 diffusers 库的设计理念,既可以直接通过封装好的 pipeline 直接生图,也可以用其中的各个组件方便地自己构建 diffusion 系统的 pipeline。
下一步,我们可以:
- 探索其他 diffusers 库中已有的 pipeline,像本文介绍的那样试着自己对其进行结构,并自行从头实现。
- 试着自己构造一个全新的 pipeline 并贡献到 diffusers 库 参考
相关文章:
diffusers pipeline拆解:理解pipelines、models和schedulers
diffusers pipeline拆解:理解pipelines、models和schedulers 翻译自:https://huggingface.co/docs/diffusers/using-diffusers/write_own_pipeline v0.24.0 diffusers 设计初衷就是作为一个简单且易用的工具包,来帮助你在自己的使用场景中构建…...

Spring 装配Bean详解
一、简介 Spring容器负责创建应用程序中的bean并通过DI来协调这些对象之间的关系。Spring具有非常大的灵活性,它提供了三种主要的装配机制: 在XML中进行显示配置;在Java中进行显示配置;隐式的bean发现机制和自动装配。 二、…...
udp多播组播
import socket ,struct,time# 组播地址和端口号 MCAST_GRP 239.0.0.1 MCAST_PORT 8888 # 创建UDP socket对象 sock socket.socket(socket.AF_INET, socket.SOCK_DGRAM, socket.IPPROTO_UDP) # 绑定socket对象到本地端口号 # sock.bind((MCAST_GRP, MCAST_PORT)) …...

逆向修改Unity的安卓包资源并重新打包
在上一篇文章中,我已经讲过如何逆向获取unity打包出来的源代码和资源了,那么这一节我将介绍如何将解密出来的源代码进行修改并重新压缩到apk中。 其实在很多时候,我们不仅仅想要看Unity的源码,我们还要对他们的客户端源码进行修改和调整,比如替换资源,替换服务器连接地址…...
pycharm中py文件设置参数
在py文件中右键 直接对应复制进去即可...
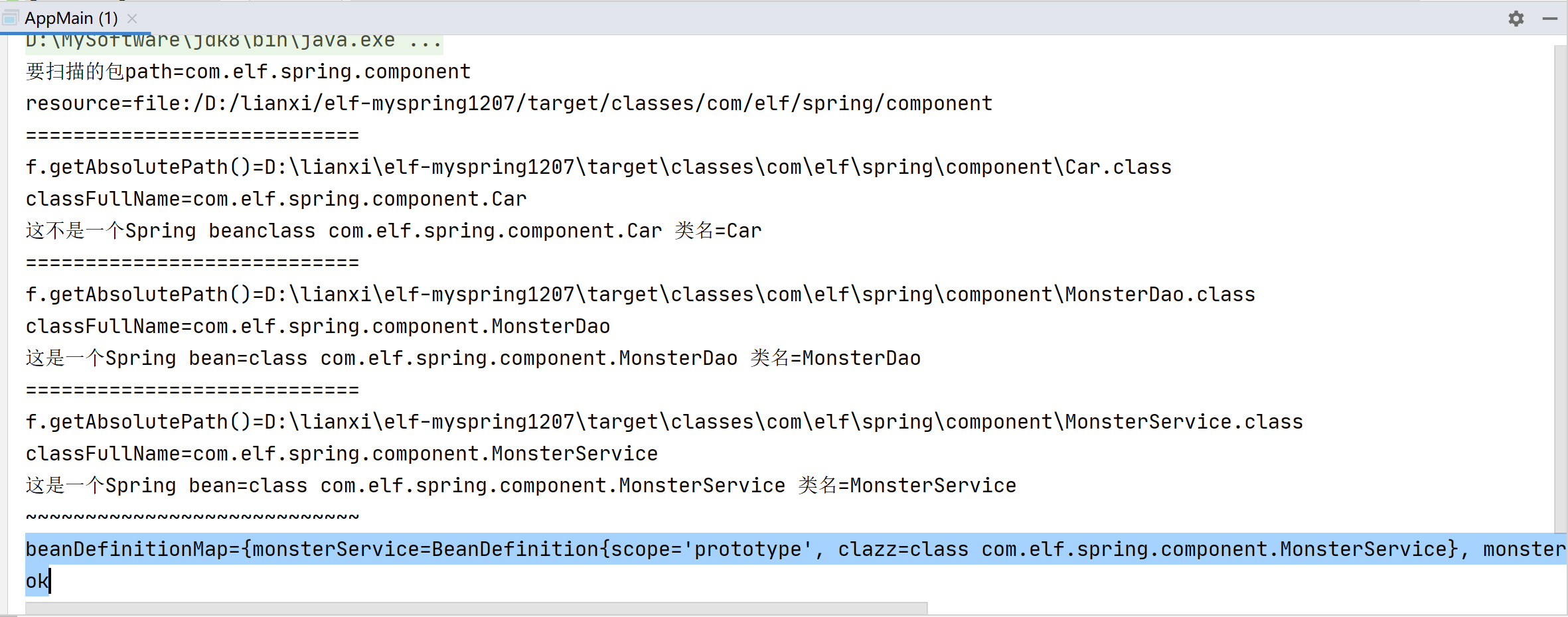
简单实现Spring容器(二) 封装BeanDefinition对象放入Map
阶段2: // 1.编写自己的Spring容器,实现扫描包,得到bean的class对象.2.扫描将 bean 信息封装到 BeanDefinition对象,并放入到Map.思路: 1.将 bean 信息封装到 BeanDefinition对象中,再将其放入到BeanDefinitionMap集合中,集合的结构大概是 key[beanName]–value[beanDefintion…...

信创运维产业的发展与趋势:IT管理的新视角
随着数字化时代的来临,信息技术应用的各个方面都在发生变革。在这个过程中,信创运维产业的发展尤为引人注目。它不仅是数字化转型的关键驱动力,也是国家经济发展的重要支柱。本文将探讨信创运维产业的发展与趋势,以及国家如何管理…...

算法通关村第十七关 | 黄金挑战 | 跳跃游戏
1.跳跃游戏 原题:力扣55. 逐步判断下一步的覆盖范围,根据范围去推断是否能到达终点,不用计较每一步走到哪里。 public boolean canJump(int[] nums) {// 题目规定 nums 长度大于等于1if (nums.length 1) {return true;}int cover 0;// f…...
思科最新版Cisco Packet Tracer 8.2.1安装
思科最新版Cisco Packet Tracer 8.2.1安装 一. 注册并登录CISCO账号二. 下载 Cisco Packet Tracer 8.2.1三. 安装四. 汉化五. cisco packet tracer教学文档六. 正常使用图 前言 这是我在这个网站整理的笔记,有错误的地方请指出,关注我,接下来还会持续更新…...

【LeetCode热题100】【滑动窗口】找到字符串中所有字母异位词
给定两个字符串 s 和 p,找到 s 中所有 p 的 异位词 的子串,返回这些子串的起始索引。不考虑答案输出的顺序。 异位词 指由相同字母重排列形成的字符串(包括相同的字符串)。 示例 1: 输入: s "cbaebabacd", p "…...
logback的使用
1 logback概述 SLF4J的日志实现组件关系图如下所示。 SLF4J,即Java中的简单日志门面(Simple Logging Facade for Java),它为各种日志框架提供简单的抽象接口。 SLF4J最常用的日志实现框架是:log4j、logback。一般有s…...

IntelliJ IDEA无公网远程连接Windows本地Mysql数据库提高开发效率
🔥博客主页: 小羊失眠啦. 🎥系列专栏:《C语言》 《数据结构》 《Linux》《Cpolar》 ❤️感谢大家点赞👍收藏⭐评论✍️ 前些天发现了一个巨牛的人工智能学习网站,通俗易懂,风趣幽默,…...
VS Code使用教程
链接远程服务器 https://blog.csdn.net/zhaxun/article/details/120568402 免密登陆服务器 1生成客户机(个人PC)密令 ssh-keygen -t rsa生成的文件在主目录的.ssh文件当中。 查看密令并复制到linux系统当中 cat id_rsa.pub 2复制到服务器中 echo …...

StarRocks数据模型之主键模型(当前版本v3.1)
StarRocks表设计数据模型,有四种:分别是明细模型(Dumplicate Key table),聚合模型(Aggregate table),更新模型(Unique Key table),主键模型&#…...

正确使用React组件缓存
简介 正常来讲的话当我们点击组件的时候,该组件以及该组件的子组件都会重新渲染,但是如何避免子组件重新渲染呢,我们经常用memo来解决 React.memo配合useCallback缓存组件 父组件没有传props const Index ()> {console.log(子组件刷新…...
AMEYA360:大唐恩智浦荣获 2023芯向亦庄 “汽车芯片50强”
2023年11月28日,由北京市科学技术委员会和北京市经济和信息化局指导、北京经济技术开发区管理委员会主办、盖世汽车协办的“芯向亦庄”汽车芯片大赛在北京亦庄成功闭幕。 在本次大赛中 大唐恩智浦的 电池管理芯片DNB1168 (应用于新能源汽车BMS系统) 凭卓越的性能及高…...

在Arch Linux上安装yay
有点麻烦。 准备 # pacman -Syu # pacman -S --needed base-devel git 变身为普通用户 不能使用root下载代码。所以要变身为普通用户: # sueradd tsit # su tsit 下载代码 $ git clone https://aur.archlinux.org/yay.git 编译安装 $ cd yay $ makepkg -si…...

PHP案例:探究MySQL应用开发喜好的网络调查
文章目录 一、知识准备(一)数据库与表的创建(二)录入调查选项(三)创建问卷页面(四)处理投票数据(五)显示调查结果二、实现步骤(一)创建数据库与表(二)录入若干调查选项(三)创建问卷页面(四)创建调查结果页面(五)体验运行结果(六)查看最终生成的HTML代码很…...

力扣第374场周赛题解
这一场周赛的题目是比较难的一次,写了1个多小时就写了两个题目。 首先第一题: 纯水题,遍历然后进行一下判断就可以解决了。这边就不放代码了。 第二题: 这个题目,我觉得难度非常大,其实代码量也不大都是很…...
Linux Docker 安装Nginx
1.21、查看可用的Nginx版本 访问Nginx镜像库地址:https://hub.docker.com/_/nginx 2、拉取指定版本的Nginx镜像 docker pull nginx:latest #安装最新版 docker pull nginx:1.25.3 #安装指定版本的Nginx 3、查看本地镜像 docker images 4、根据镜像创建并运行…...

对比直接使用官方api与通过taotoken接入后的网络连接稳定性体验
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 对比直接使用官方 API 与通过 Taotoken 接入后的网络连接稳定性体验 1. 引言 在开发基于大语言模型的应用程序时,一个…...

Unity纹理保真优化:ASTC压缩与Mipmap精准控制方案
1. 这不是“去马赛克”,而是精准还原被压缩破坏的视觉信息Unity游戏开发中,你有没有遇到过这样的场景:美术同事发来一张4K高清角色贴图,你兴冲冲拖进Unity,设置成Texture Type Default、Compression ASTC_6x6&#x…...

抖音资源下载新体验:douyin-downloader一站式解决方案
抖音资源下载新体验:douyin-downloader一站式解决方案 【免费下载链接】douyin-downloader A practical Douyin downloader for both single-item and profile batch downloads, with progress display, retries, SQLite deduplication, and browser fallback suppo…...
 深度解析:从架构原理到自动化实战)
Android Debug Bridge (adb) 深度解析:从架构原理到自动化实战
1. 项目概述:从“黑盒”到“白盒”的调试桥梁如果你是一名移动应用开发者、测试工程师,或者是一名热衷于折腾手机、平板的极客,那么“adb”这个词对你来说一定不陌生。它就像一把万能钥匙,静静地躺在你的开发工具目录里࿰…...

边缘AI语音交互实战:从唤醒词识别到MCP外设控制的嵌入式实现
1. 项目概述:当边缘计算遇见语音交互 最近在折腾一个挺有意思的项目,核心是把语音交互的能力从云端“拽”下来,直接部署到边缘设备上,然后让它去控制各种MCP(Microcontroller Peripheral)外设。听起来像是智…...

3分钟掌握Windows驱动管理的终极利器:DriverStore Explorer完全指南
3分钟掌握Windows驱动管理的终极利器:DriverStore Explorer完全指南 【免费下载链接】DriverStoreExplorer Driver Store Explorer 项目地址: https://gitcode.com/gh_mirrors/dr/DriverStoreExplorer 你是否曾为Windows系统越来越慢而烦恼?是否发…...

JSON差异对比终极指南:快速定位JSON数据变化的免费在线工具
JSON差异对比终极指南:快速定位JSON数据变化的免费在线工具 【免费下载链接】online-json-diff 项目地址: https://gitcode.com/gh_mirrors/on/online-json-diff 还在为JSON数据对比而烦恼吗?无论你是前端开发者、后端工程师,还是数据…...

从状态机视角理解程序:形式化方法如何保证复杂系统正确性
1. 从数学视角审视程序:为什么我们需要形式化思维在软件开发的日常里,我们常常埋头于代码的细节:这个循环边界对不对?那个指针会不会为空?这个API调用返回错误该怎么处理?我们依赖编译器、静态分析工具、单…...
)
2026年精选AI写作辅助网站合集(实测甄选版)
为解决学术写作中效率与合规两大核心痛点,以下精选8款高适配性 AI 论文写作工具(按综合优先级排序),围绕中文学术规范适配、真实参考文献生成、格式标准化、高性价比四大核心维度筛选,同时配套分场景精准选型方案与学术…...

Awesome Video终极指南:从零开始掌握流媒体视频技术栈
Awesome Video终极指南:从零开始掌握流媒体视频技术栈 【免费下载链接】awesome-video A curated list of awesome streaming video tools, frameworks, libraries, and learning resources. 项目地址: https://gitcode.com/gh_mirrors/aw/awesome-video 流媒…...