指针,函数指针,二级指针,指针传参,回调函数,指针步长
文章目录
- 指针是什么?
- 指针的定义
- 指针的大小
- 指针类型
- 指针有哪些类型?
- 指针类型有什么意义?
- 代码演示:(偏移)
- 代码演示(指针解引用时取出的字节数)
- 其他例子
- 野指针
- 野指针的成因
- 如何避免野指针
- 指针运算
- 指针±整数
- 指针-指针
- 指针的关系运算
- 二级指针
- 字符指针
- 指针数组
- 数组指针
- 数组指针的定义
- &数组名 VS 数组名
- 数组指针的使用
- 数组参数、指针参数
- 一维数组传参
- 二维数组传参
- 一级指针传参
- 二级指针传参
- 函数指针
- 函数指针的定义
- 函数指针的使用
- 函数[指针数组](https://so.csdn.net/so/search?q=指针数组&spm=1001.2101.3001.7020)
- 函数指针数组的定义
- 函数指针数组的使用 - 模拟计算器
- 指向函数指针数组的指针
- 回调函数
- 回调函数的定义
- 回调函数的使用 - [qsort](https://so.csdn.net/so/search?q=qsort&spm=1001.2101.3001.7020)函数
- 指针和数组试题解析
- 整型数组字节数
- 字符数组长度和字节数
- 字符串长度和字节数
- 二维整型数组字节数
- 指针试题
指针是什么?
指针的定义
在计算机科学中,指针(Pointer)是编程语言中的一个对象,利用地址,它的值直接指向(points to)存在电脑存储器中另一个地方的值。由于通过地址能找到所需的内存单元,可以说地址指向该内存单元。因此,将地址形象化的称为“指针”。意思是通过它能找到以它为地址的内存单元。
这是官方对指针的定义,其实我们可以理解为:在内存中,内存被细分为一个个大小为一个字节的内存单元,每一个内存单元都有自己对应的地址。

我们可以将这些内存单元形象地看成一个个的房间,将内存单元(房间)对应的地址形象地看成房间的门牌号。而我们通过门牌号(地址)就可以唯一的找到其对应的房间(内存单元),即地址指向对应内存单元。所以说,可以将地址形象化的称为“指针”。
指针变量是用于存放地址的变量。(存放在指针中的值都将被当作地址处理)
#include<stdio.h>
int main()
{int a = 10;//在内存中开辟一块空间int* p = &a;//将a的地址取出,放到指针变量p中return 0;
}总结:
- 指针变量是用于存放地址的变量。(存放在指针中的值都将被当作地址处理)
指针的大小
对于32位的机器,即有32根地址线,因为每根地址线能产生正电(1)或负电(0),所以在32位的机器上能够产生的地址信号就是32个0/1组成的二进制序列:

一共 232 个地址。
同样的算法,在64位的机器上一共能产生 264 个不同的地址。
232 可以用32个bit位进行存储,而8个bit位等价于1个字节,所以在32位的平台下指针的大小为4个字节。
264 可以用64个bit位进行存储,所以在64位的平台下指针的大小为8个字节。
总结:
- 在32位平台下指针的大小为4个字节,在64位平台下指针的大小为8个字节。
指针类型
指针有哪些类型?
我们知道,变量的类型有int,float,char等。那么指针有没有类型呢?回答是肯定的。
指针的定义方式是type+ *
char * 类型的指针存放的是char类型的变量地址;
int * 类型的指针存放的是int类型的变量地址;
float * 类型的指针存放的是float类型的变量地址等。
指针类型有什么意义?
1.指针±整数
若指针类型为int * 的指针+1,那么它将跳过4个字节的大小指向4个字节以后的内容:

若指针类型为char * 的指针+1,那么它只会跳过1个字节的大小指向下一个字节的内容,以此类推。
2.指针解引用
指针的类型决定了指针解引用的时候能够访问几个字节的内容。
若指针类型为int *,那么将它进行解引用操作,它将可以访问从指向位置开始向后4个字节的内容:

若指针类型为char *,那么将它进行解引用操作,它将可以访问从指向位置开始向后1个字节的内容,以此类推。
总结:
- 指针的类型决定了指针向前或向后走一步有多大距离。
- 指针的类型决定了指针在进行解引用操作时,能向后访问的空间大小。
代码演示:(偏移)
#include<stdio.h>void test01()
{
const char * p1 = NULL;printf("%d\n", p1);printf("%d\n", p1 + 1);//+1偏移1个字节int * p2 = NULL;printf("%d\n", p2);printf("%d\n", p2 + 1);//+1偏移4个字节double * p3 = NULL;printf("%d\n", p3);printf("%d\n", p3 + 1);//+1偏移8个字节
}int main()
{test01();
}
0
1
0
4
0
8
总结:vs下常见指针的偏移值分别为:
char :1个字节
int :4个字节
double :8个字节
数组指针:偏移整个数组大小
结构体指针:偏移整个结构体大小
以下是一段C语言代码,它演示了不同类型的指针加减整数时偏移量不同。这包括结构体指针、二维数组指针、一维数组指针、整型指针、字符指针和浮点型指针。
#include <stdio.h>struct MyStruct {int a;double b;char c;
};int main() {struct MyStruct s[2] = {{1, 2.0, 'a'}, {3, 4.0, 'b'}};struct MyStruct *sptr = s;int arr2d[2][2] = {{1, 2}, {3, 4}};int (*arr2dptr)[2] = arr2d;int arr[2] = {1, 2};int *intptr = arr;char str[2] = "ab";char *charptr = str;float f[2] = {1.0, 2.0};float *floatptr = f;printf("Address before incrementing struct pointer: %p\n", (void *)sptr);sptr++;printf("Address after incrementing struct pointer: %p\n", (void *)sptr);printf("Address before incrementing 2D array pointer: %p\n", (void *)arr2dptr);arr2dptr++;printf("Address after incrementing 2D array pointer: %p\n", (void *)arr2dptr);printf("Address before incrementing int pointer: %p\n", (void *)intptr);intptr++;printf("Address after incrementing int pointer: %p\n", (void *)intptr);printf("Address before incrementing char pointer: %p\n", (void *)charptr);charptr++;printf("Address after incrementing char pointer: %p\n", (void *)charptr);printf("Address before incrementing float pointer: %p\n", (void *)floatptr);floatptr++;printf("Address after incrementing float pointer: %p\n", (void *)floatptr);return 0;
}
这段代码首先定义了一个结构体 MyStruct,然后创建了一个指向该结构体数组的指针 sptr。接下来,它创建了一个二维数组 arr2d 和一个指向该二维数组的指针 arr2dptr,以及一个一维数组 arr 和一个指向该一维数组的指针 intptr。然后,它创建了一个字符串 str 和一个指向该字符串的指针 charptr,以及一个浮点数数组 f 和一个指向该浮点数数组的指针 floatptr。
然后,它使用 printf 函数打印出每种类型的指针在加1之前和之后的地址。你会看到,不同类型的指针在加1之后的地址偏移量是不同的,这是因为不同类型的数据占用的字节数不同。希望这个代码对你有所帮助!
Address before incrementing struct pointer: 000000426f9ffba0
Address after incrementing struct pointer: 000000426f9ffbb8Address before incrementing 2D array pointer: 000000426f9ffb90
Address after incrementing 2D array pointer: 000000426f9ffb98Address before incrementing int pointer: 000000426f9ffb88
Address after incrementing int pointer: 000000426f9ffb8cAddress before incrementing char pointer: 000000426f9ffb85
Address after incrementing char pointer: 000000426f9ffb86Address before incrementing float pointer: 000000426f9ffb7c
Address after incrementing float pointer: 000000426f9ffb80
在上述代码中,每种类型的指针在加1之后的地址偏移量取决于该类型的大小。具体来说:
- 结构体指针
sptr:MyStruct结构体的大小是sizeof(int) + sizeof(double) + sizeof(char),所以偏移量是这个值。 - 二维数组指针
arr2dptr:它指向的是一个包含2个int的数组,所以偏移量是2 * sizeof(int)。 - 整型指针
intptr:int的大小就是偏移量,即sizeof(int)。 - 字符指针
charptr:char的大小就是偏移量,即sizeof(char),在大多数系统上,这个值是1。 - 浮点型指针
floatptr:float的大小就是偏移量,即sizeof(float)。
代码演示(指针解引用时取出的字节数)
以下是一段C语言代码,它演示了不同类型的指针解引用时取出的字节数不同。这包括结构体指针、二维数组指针、一维数组指针、整型指针、字符指针和浮点型指针。
#include <stdio.h>struct MyStruct {int a;double b;char c;
};int main() {struct MyStruct s = {1, 2.0, 'a'};struct MyStruct *sptr = &s;int arr2d[2][2] = {{1, 2}, {3, 4}};int (*arr2dptr)[2] = arr2d;int arr[2] = {1, 2};int *intptr = arr;char str[2] = "ab";char *charptr = str;float f = 1.0;float *floatptr = &f;printf("Size of struct: %lu\n", sizeof(*sptr));printf("Size of 2D array element: %lu\n", sizeof(*arr2dptr));printf("Size of int: %lu\n", sizeof(*intptr));printf("Size of char: %lu\n", sizeof(*charptr));printf("Size of float: %lu\n", sizeof(*floatptr));return 0;
}
这段代码首先定义了一个结构体 MyStruct,然后创建了一个指向该结构体的指针 sptr。接下来,它创建了一个二维数组 arr2d 和一个指向该二维数组的指针 arr2dptr,以及一个一维数组 arr 和一个指向该一维数组的指针 intptr。然后,它创建了一个字符串 str 和一个指向该字符串的指针 charptr,以及一个浮点数 f 和一个指向该浮点数的指针 floatptr。
最后,它使用 printf 和 sizeof 函数打印出每种类型的指针解引用后的大小(即字节数)。这就是为什么不同类型的指针解引用时取出的字节数不同的原因。希望这个代码对你有所帮助!
Size of struct: 24
Size of 2D array element: 8
Size of int: 4
Size of char: 1
Size of float: 4
其他例子
// todo 字节序转换
#include <stdio.h>
#include <arpa/inet.h>
void printf_bin(int num) // 这个函数将整形变量以二进制的形式打印出来
{int i, j, k;unsigned char *p = (unsigned char *)&num + 3; // p先指向num后面第3个字节的地址,即num的最高位字节地址for (i = 0; i < 4; i++) // 依次处理4个字节(32位){j = *(p - i); // 取每个字节的首地址,从高位字节到低位字节,即p p-1 p-2 p-3地址处for (int k = 7; k >= 0; k--) // 处理每个字节的8个位,注意字节内部的二进制数是按照人的习惯存储!{if (j & (1 << k)) // 1左移k位,与单前的字节内容j进行或运算,如k=7时,00000000&10000000=0 ->该字节的最高位为0printf("1");elseprintf("0");}printf(" "); // 每8位加个空格,方便查看}printf("\r\n");
}int main()
{char buf[4] = {192, 168, 1, 2}; // 32位// todo1 将 4字节(32位)的数据存放在 num容器(int 类型, 32位)中unsigned int num = *(unsigned int *)buf; // int*把buf(char类型的数组首地址强转为int*类型的地址),// 再*(解引用)取出四个字节的数据,而int 类型刚好是4字节,就能存放这四字节数据// 你可以把 int num 当成是定义了一个能存放32位数据的容器,只是这32位存放的是// 192.168.1.2 的用二进制(01)表示的情况printf_bin(num);printf("%u\n", num); //%u用于打印 unsigned int .// 打印结果 33663168 . 这么大是因为 他不会每八位隔断,每八位分别做二进制转换//(像把 00000010 00000001 10101000 11000000)隔断为 192.168.1.2 而是// 直接将这个32位的数作为整体进行二进制转换printf("================");int n1 = 33663168; // 实际上这个十进制数用二进制的表示就是 00000010 00000001 10101000 11000000printf_bin(n1);// htol() 函数的作用是将一个32位数从主机字节顺序转换成网络字节顺序。unsigned int sum = htonl(num);printf_bin(sum); // 11000000 10101000 00000001 00000010 和 num中的二进制位是相反的
}假设 num 是一个 int 类型的变量,占用4个字节,那么 &num 就是这个变量的地址。由于 unsigned char * 是一个字节指针,所以 p 指向 num 的第一个字节。当你加上3 (+ 3),p 就会指向 num 的第四个字节。
如果你的系统是小端模式,那么 num 的最高有效字节就会被存储在最高的地址,也就是 p 所指向的位置。如果你的系统是大端模式,那么 p 就会指向 num 的最低有效字节。
00000010 00000001 10101000 11000000
33663168
================
00000010 00000001 10101000 11000000
11000000 10101000 00000001 00000010
野指针
概念:野指针就是指向位置是不可知的(随机的、不正确的、没有明确限制的)指针。
野指针的成因
1.指针未初始化
#include<stdio.h>
int main()
{int* p;*p = 10;return 0;
}局部指针变量p未初始化,默认为随机值,所以这个时候的p就是野指针。
2.指针越界访问
#include<stdio.h>
int main()
{int arr[10] = { 0 };int* p = &arr[0];int i = 0;for (i = 0; i < 11; i++){*p++ = i;}return 0;
}12
当指针指向的范围超出arr数组时,p就是野指针。
3.指针指向的空间被释放
#include<stdio.h>
int* test()
{int a = 10;return &a;
}
int main()
{int* p = test();return 0;
}指针变量p得到地址后,地址指向的空间已经释放了,所以这个时候的p就是野指针。(局部变量出了自己的作用域就被释放了)
如何避免野指针
1.指针初始化
当指针明确知道要存放某一变量地址时,在创建指针变量时就存放该变量地址。
当不知道指针将要用于存放哪一变量地址时,在创建指针变量时应置为空指针(NULL)。
#include<stdio.h>
int main()
{int a = 10;int* p1 = &a;//明确知道存放某一地址int* p2 = NULL;//不知道存放哪一地址时置为空指针return 0;
}2.小心指针越界
3.指针指向的空间被释放后及时置为NULL
3.使用指针之前检查有效性
在使用指针之前需确保其不是空指针,因为空指针指向的空间是无法访问的。
指针运算
指针±整数
#include<stdio.h>
int main()
{int arr[5] = { 0 };int* p = arr;int i = 0;for (i = 0; i < 5; i++){*(p + i) = i;}return 0;
}12
指针-指针
指针-指针的绝对值是是两个指针之间的元素个数。
int my_strlen(char* p)
{char* pc = p;while (*p != '\0')p++;return p - pc;
}strlen函数的模拟实现就可以运用指针-指针的代码实现。
指针的关系运算
指针的关系运算,即指针之间的大小比较。
我们如果要将一个数组中的元素全部置0,可以有两种方法。
第一种:从前向后置0
#include<stdio.h>
int main()
{int arr[5] = { 1, 2, 3, 4, 5 };int* p = &arr[0];for (p = &arr[0]; p <= &arr[4]; p++){*p = 0;}return 0;
}最终指向数组最后一个元素后面的那个内存位置的指针将与&arr[4]比较,不满足条件,于是结束循环。
第二种:从后向前置0
#include<stdio.h>
int main()
{int arr[5] = { 1, 2, 3, 4, 5 };int* p = &arr[4];for (p = &arr[4]; p >= &arr[0]; p--){*p = 0;}return 0;
}最终指向第一个元素之前的那个内存位置的指针将与&arr[0]比较,不满足条件,于是结束循环。
这两种方法在绝大部分编译器下均能将arr数组中的元素置0,但是我们要尽量使用第一种方法,因为标准并不保证第二种方法可行。
标准规定:
允许数组元素的指针与指向数组最后一个元素后面的那个内存位置的指针比较,但是不允许与指向第一个元素之前的那个内存位置的指针进行比较。
二级指针
我们知道,指针变量是用于存放地址的变量。但是指针变量也是变量,是变量就有地址,那么存放指针变量的地址的变量是什么呢?
其实,存放普通变量的地址的指针叫一级指针,存放一级指针变量的地址的指针叫二级指针,存放二级指针变量地址的指针叫三级指针,以此类推。
#include<stdio.h>
int main()
{int a = 10;int* p1 = &a;int** p2 = &p1;return 0;
}在这里,我们用一级指针p1存放了普通常量a的地址,用二级指针p2存放了一级指针p1的地址。
这时如果我们要得到a的值,就有两种方法:
方法一:对一级指针p1进行一次解引用操作即可得到a的值,即*p1。
方法二:对二级指针p2进行一次解引用操作即可得到p1的值,而p1的值就是a的地址,所以再对p2进行一次解引用操作即可得到a的值,也就是对二级指针p2进行两次解引用操作即可得到a的值,即**p2。
字符指针
我们知道,在指针的类型中有一种指针类型叫字符指针char * 。
字符指针的一般使用方法为:
#include<stdio.h>
int main()
{char ch = 'w';char* p = &ch;return 0;
}代码中,将字符变量ch的地址存放在了字符指针p中。
其实,字符指针还有另一种使用方式:
#include<stdio.h>
int main()
{char* p = "hello csdn.";printf("%c\n", *p);//打印字符'h'printf("%s\n", p);//打印字符串"hello csdn."return 0;
}代码中,字符指针p中存放的并非字符串"hello csdn.",字符指针p中存放的是字符串"hello csdn.“的首元素地址,即字符’h’的地址。
所以,当对字符指针p进行解引用操作并以字符的形式打印时只能打印字符’h’。我们知道,打印一个字符串只需要提供字符串的首元素地址即可,既然字符指针p中存放的是字符串的首元素地址,那么我们只要提供p(字符串首地址)并以字符串的形式打印,便可以打印字符串"hello csdn.”。
注意:代码中的字符串"hello csdn."是一个常量字符串。
这里有一道题目,可以帮助我们更好的理解字符指针和常量字符串:
#include <stdio.h>
int main()
{char str1[] = "hello csdn.";char str2[] = "hello csdn.";char *str3 = "hello csdn.";char *str4 = "hello csdn.";if (str1 == str2)printf("str1 and str2 are same\n");elseprintf("str1 and str2 are not same\n");if (str3 == str4)printf("str3 and str4 are same\n");elseprintf("str3 and str4 are not same\n");return 0;
}题目最后打印的结果是:
str1 and str2 are not same
str3 and str4 are same题目中str1和str2是两个字符数组,比较str1和str2时,相当于比较数组str1和数组str2的首元素地址,而str1与str2是两个不同的字符数组,创建数组str1和数组str2是会开辟两块不同的空间,它们的首元素地址当然不同。

而str3和str4是两个字符指针,它们指向的都是常量字符串"hello csdn."的首元素地址,所以str3和str4指向的是同一个地方。

注意:常量字符串与普通字符串最大的区别是,常量字符串是不可被修改的字符串,既然不能被修改,那么在内存中没有必要存放两个一模一样的字符串,所以在内存中相同的常量字符串只有一个。
指针数组
我们已经知道了整型数组、字符数组等。整型数组是用于存放整型的数组,字符数组是用于存放字符的数组。
int arr1[4];
char arr2[5];数组arr1包含4个元素,每个元素的类型是整型;数组arr2包含5个元素,每个元素的类型是字符型。

指针数组也是数组,是用于存放指针的数组。
int* arr3[5];数组arr3包含5个元素,每个元素是一个一级整型指针。

以此类推:
char* arr4[10];//数组arr4包含10个元素,每个元素是一个一级字符型指针。
char** arr5[5];//数组arr5包含5个元素,每个元素是一个二级字符型指针。数组arr4包含10个元素,每个元素是一个一级字符型指针;数组arr5包含5个元素,每个元素是一个二级字符型指针。
数组指针
数组指针的定义
我们已经知道了,整型指针是指向整型的指针,字符指针是指向字符的指针,那么数组指针应该就是指向数组的指针了。
整型指针和字符指针,在使用时只需取出某整型/字符型的数据的地址,并将地址存入整型/字符型指针即可。
#include<stdio.h>
int main()
{int a = 10;int* pa = &a;//取出a的地址存入整型指针中char ch = 'w';char* pc = &ch;//取出ch的地址存入字符型指针中return 0;
}数组指针也是一样,我们只需取出数组的地址,并将其存入数组指针即可。
#include<stdio.h>
int main()
{int arr[10] = { 0 };int(*p)[10] = &arr;//&arr - 数组的地址return 0;
}那么数组指针的指针类型是如何写出来的呢?
首先我们应该知道的是:
1. [ ]的优先级要高于 * 。
2. 一个变量除去了变量名,便是它的变量类型。
比如:
int a = 10;//除去变量名a,变量类型为int
char ch = 'w';//除去变量名ch,变量类型为char
int* p = NULL;//除去变量名p,变量类型为int*数组也可以这样理解:
int arr[10] = { 0 };//除去变量名arr,变量类型为int [10]
int arr[3][4] = { 0 };//除去变量名arr,变量类型为int [3][4]
int* arr[10] = { 0 };//除去变量名arr,变量类型为int* [10]数组的变量类型说明了数组的元素个数和每个元素的类型:

3.一个指针变量除去了变量名和 * ,便是指针指向的内容的类型。
比如:
int a = 10;
int* p = &a;//除去变量名(p)和*,便是P指向的内容(a)的类型->int
char ch = 'w';
char* pc = &ch;//除去变量名(pc)和*,便是pc指向的内容(ch)的类型->char接下来我们就可以来写数组指针的指针类型了:
#include<stdio.h>
int main()
{int arr[10] = { 0 };int(*p)[10] = &arr;//&arr - 数组的地址return 0;
}首先p是一个指针,所以p必须要先与 * 结合,而[ ]的优先级要高于 * ,所以我们要加上( )以便让p与 * 先结合。
指针p指向的内容,即数组类型是int [10],所以数组指针p就变成了int(*p)[10]。
去掉变量名p后,便是该数组指针的变量类型int( * )[10]。

如果我们不加( ),那么就变成了int *p[10],因为[ ]的优先级要高于 * ,所以p先与[ ]结合,这时p就变成了一个数组,而数组中每个元素的的类型是int * ,这就是前面说到的指针数组。

&数组名 VS 数组名
对于一个数组的数组名,它什么时候代表数组首元素的地址,什么时候又代表整个数组的地址,这一直是很多人的疑惑。在这里我给出大家准确的答案:
数组名代表整个数组的地址的情况其实只有两种:
- &数组名。
- 数组名单独放在sizeof内部,即sizeof(数组名)。
除此之外,所有的数组名都是数组首元素地址。
比如:
int arr[5] = { 1, 2, 3, 4, 5 };对于该数组arr,只有以下两种情况数组名代表整个数组的地址:
&arr;sizeof(arr);//arr单独放在sizeof内部除此之外,所以的arr都代表数组首元素地址,即1的地址。
将其与指针联系起来:
#include<stdio.h>
int main()
{int arr[5] = { 1, 2, 3, 4, 5 };int* p1 = arr;//数组首元素的地址int(*p2)[5] = &arr;//数组的地址printf("%p\n", p1);printf("%p\n", p2);printf("%p\n", p1+1);printf("%p\n", p2+1);return 0;
}因为代码中的arr是数组首元素地址,所以要用int * 的指针接收。而&arr是整个数组的地址,所以要用数组指针进行接收。
虽然一个是数组首元素地址,一个是数组的地址,但是它们存放的都是数组的起始位置的地址,所以将p1和p2以地址的形式打印出来发现它们的值一样。
数组首元素地址和数组的地址的区别在于,数组首元素地址+1只能跳过一个元素指向下一个元素,而数组的地址+1能跳过整个数组指向数组后面的内存空间。

数组指针的使用
数组指针有一个简单的使用案例,那就是打印二维数组:
#include<stdio.h>
void print(int(*p)[5], int row, int col)
{int i = 0;for (i = 0; i < row; i++)//行数{int j = 0;for (j = 0; j < col; j++)//列数{printf("%d ", *(*(p + i) + j));}printf("\n");//打印完一行后,换行}
}
int main()
{int arr[3][5] = { { 1, 2, 3, 4, 5 }, { 2, 3, 4, 5, 6 }, { 3, 4, 5, 6, 7 } };print(arr, 3, 5);//传入二维数组名,即二维数组首元素地址,即二维数组第一行的地址return 0;
}在这里我们打印一个三行五列的二维数组。传参时我们传入二维数组的数组名,明确打印的起始位置;传入行数和列数,明确打印的数据范围。
通过上面对&数组名和数组名的认识,我们知道了这里传入的数组名代表的是二维数组的首元素地址,而二维数组的首元素第一行的元素,即传入的是一维数组的地址,所以我们必须用数组指针进行接收。
打印时,通过表达式 * (*(p+i)+j ) 锁定打印目标:

数组参数、指针参数
一维数组传参
#include<stdio.h>
void test1(int arr[10])//数组接收
{}
void test1(int *arr)//指针接收
{}
void test2(int *arr[20])//数组接收
{}
void test2(int **arr)//指针接收
{}
int main()
{int arr1[10] = { 0 };//整型数组int *arr2[20] = { 0 };//整型指针数组test1(arr1);test2(arr2);
}整型数组:
当向函数传入整型数组的数组名时,我们有以下几种参数可供接收:
- 数组传参数组接收,我们传入的是整型数组,那我们就用整型数组接收。
- 传入的数组名本质上是数组首元素地址,所以我们可以用指针接收。数组的元素类型是整型,我们接收整型元素的地址用int * 的指针即可。
整型指针数组:
当向函数传入整型指针数组的数组名时,我们有以下几种参数可供接收:
- 数组传参数组接收,我们传入的是整型指针数组,那我们就用整型指针数组接收。
- 指针接收,数组的元素是int * 类型的,我们接收int * 类型元素的地址用二级指针int ** 即可。
注意:一维数组传参,函数形参设计时[ ]内的数字可省略。
二维数组传参
#include<stdio.h>
void test(int arr[][5])//数组接收
{}
void test(int(*arr)[5])//指针接收
{}
int main()
{int arr[3][5] = { 0 };//二维数组test(arr);
}当向函数传入二维数组的数组名时,我们有以下几种参数可供接收:
- 二维数组传参二维数组接收。
- 指针接收,二维数组的首元素是二维数组第一行的地址,即一维数组的地址,我们用数组指针接收即可。
注意:二维数组传参,函数形参的设计只能省略第一个[ ]内的数字。
一级指针传参
#include<stdio.h>
void print(int* p, int sz)//一级指针接收
{int i = 0;for (i = 0; i < sz; i++){printf("%d ", *(p + i));}
}
int main()
{int arr[] = { 1, 2, 3, 4, 5, 6, 7, 8, 9, 10 };int sz = sizeof(arr) / sizeof(arr[0]);int* p = arr;//一级指针print(p, sz);return 0;
}当我们传入的参数为一级指针时,我们可以用一级指针的形参对其进行接收,那么当函数形参为一级指针的时候,我们可以传入什么样的参数呢?
#include<stdio.h>
void test(int* p)
{}
int main()
{int a = 10;test(&a);//可以传入变量的地址int* p = &a;test(p);//可以传入一级指针int arr[10] = { 0 };test(arr);//可以传入一维数组名//...return 0;
}总而言之,只要传入的表达式最终的类型是一级指针类型即可传入。
二级指针传参
#include<stdio.h>
void test(int** p)//二级指针接收
{}
int main()
{int a = 10;int* pa = &a;int** paa = &pa;test(paa);//二级指针return 0;
}当我们传入的参数为二级指针时,我们可以用二级指针的形参对其进行接收,那么当函数形参为二级指针的时候,我们可以传入什么样的参数呢?
#include<stdio.h>
void test(int** p)
{}
int main()
{int a = 10;int* pa = &a;test(&pa);//可以传入一级指针的地址int** paa = &pa;test(paa);//可以传入二级指针int* arr[10];test(arr);//可以传入一级指针数组的数组名//...return 0;
}总而言之,只要传入的表达式最终的类型是二级指针类型即可传入。
函数指针
函数指针的定义
函数指针和我们在对指针的详细认识(二)中学习的数组指针非常相似。
我们知道,整型指针是指向整型的指针,数组指针是指向数组的指针,其实,函数指针就是指向函数的指针。
和学习数组指针一样,学习函数指针我们也需要知道三点:
- ( )的优先级要高于 * 。
- 一个变量除去了变量名,便是它的变量类型。
- 一个指针变量除去了变量名和 * ,便是指针指向的内容的类型。
举个例子:
#include<stdio.h>
int Add(int x, int y)
{return x + y;
}
int main()
{int(*p)(int, int) = &Add;//取出函数的地址放在函数指针p中return 0;
}
12345678910
那么,函数指针p的类型我们是如何创建的呢?
首先,p是一个指针,所以必须先与 * 结合,而( )的优先级高于 * ,所以我们要把 * 和p用括号括起来,让它们先结合。
指针p指向的内容,即函数Add的类型是int (int,int),所以函数指针p就变成了int(*p)(int,int)。
去掉变量名p后,便是该函数指针的变量类型int( * )(int,int)。

函数指针的使用
知道了如何创建函数指针,那么函数指针应该如何使用呢?
1.函数指针的赋值
对于数组来说,数组名和&数组名它们代表的意义不同,数组名代表的是数组首元素地址,而&数组名代表的是整个数组的地址。
但是对于函数来说,函数名和&函数名它们代表的意义却是相同的,它们都代表函数的地址(毕竟你也没有听说过函数有首元素这个说法吧)。
所以,当我们对函数指针赋值时可以赋值为&函数名,也可以赋值为函数名。
int(*p)(int, int) = &Add;int(*p)(int, int) = Add;
12
2.通过函数指针调用函数
方法一:我们知道,函数指针存放的是函数的地址,那么我们将函数指针进行解引用操作,便能找到该函数了,于是就可以通过函数指针调用该函数。
#include<stdio.h>
int Add(int x, int y)
{return x + y;
}
int main()
{int a = 10;int b = 20;int(*p)(int, int) = &Add;int ret = (*p)(a, b);//解引用找到该函数printf("%d\n", ret);return 0;
}我们可以理解为, * 和&是两个相反的操作符,像正号(+)和负号(-)一样,一个 * 操作符可以抵消一个&操作符。

方法二:我们在函数指针赋值中说到,函数名和&函数名都代表函数的地址,我们可以赋值时直接赋值函数名,那么通过函数指针调用函数的时候我们就可以不用解引用操作符就能找到函数了。
#include<stdio.h>
int Add(int x, int y)
{return x + y;
}
int main()
{int a = 10;int b = 20;int(*p)(int, int) = Add;int ret = p(a, b);//不用解引用printf("%d\n", ret);return 0;
}
函数指针数组
函数指针数组的定义
我们知道,数组是一个存放相同类型数据的空间,我们已经认识了指针数组,比如:
int* arr[10];//数组arr有10个元素,每个元素的类型是int*
1
那如果要将一系列相同类型的函数指针存放到一个数组中,那么这个数组就叫做函数指针数组,比如:
int(*pArr[10])(int, int);//数组pArr有10个元素,每个元素的类型是int(*)(int,int)函数指针数组的创建只需在函数指针创建的基础上加上[ ]即可。
比如,你要创建一个函数指针数组,这个数组中存放的函数指针的类型均为int(*)(int,int),如果你要创建一个函数指针为该类型,那么该函数指针的写法为int(*p)(int,int),现在你要创建一个存放该指针类型的数组,只需在变量名的后面加上[ ]即可,int(*pArr[10])(int,int)。
函数指针数组的使用 - 模拟计算器
函数指针数组一个很好的运用场景,就是计算机的模拟实现:
#include<stdio.h>
void menu()
{printf("|-----------------------|\n");printf("| 1.Add 2.Sub |\n");printf("| 3.Mul 4.Div |\n");printf("| 0.exit |\n");printf("|-----------------------|\n");
}//菜单
double Add(double x, double y)
{return x + y;
}//加法函数
double Sub(double x, double y)
{return x - y;
}//减法函数
double Mul(double x, double y)
{return x*y;
}//乘法函数
double Div(double x, double y)
{return x / y;
}//除法函数
int main()
{int input = 0;double x = 0;//第一个操作数double y = 0;//第二个操作数double ret = 0;//运算结果double(*pArr[])(double, double) = { 0, Add, Sub, Mul, Div };//函数指针数组-转移表int sz = sizeof(pArr) / sizeof(pArr[0]);//计算数组的大小do{menu();printf("请输入:>");scanf("%d", &input);if (input == 0)printf("退出程序\n");else if (input > 0 && input < sz){printf("请输入两个操作数:>");scanf("%lf %lf", &x, &y);ret = pArr[input](x, y);printf("ret=%lf\n", ret);}elseprintf("选择错误,请重新选择!\n");} while (input);//当input不为0时循环继续return 0;
}代码中,函数指针数组存放的是一系列参数和返回类型相同的函数名,即函数指针。将0放在该函数指针数组的第一位是为了让用户输入的数字input与对应的函数指针下标相对应。
该代码若不使用函数指针数组,而选择使用一系列的switch分支语句当然也能达到想要的效果,但会使代码出现许多重复内容,而且当以后需要增加该计算机功能时又需要增加一个case语句,而使用函数指针数组,当你想要增加计算机功能时只需在数组中加入一个函数名即可。
指向函数指针数组的指针
既然存在函数指针数组,那么必然存在指向函数指针数组的指针。
int(*p)(int, int);//函数指针int(*pArr[5])(int, int);//函数指针数组int(*(*pa)[5])(int, int) = &pArr;//指向函数指针数组的指针
123456
那指向函数指针数组的指针的类型是如何写的呢?

所以pa就是一个指向函数指针数组的指针,该函数指针数组中每个元素类型是int(*)(int, int)。
回调函数
回调函数的定义
回调函数就是一个通过函数指针调用的函数。如果你把函数的指针(地址)作为参数传递给另一个函数,当这个指针被用来调用其所指向的函数时,我们就说这是回调函数。
举个简单的例子:
#include<stdio.h>
void test1()
{printf("hello\n");
}
void test2(void(*p)())
{p(); //指针p被用来调用其所指向的函数
}
int main()
{test2(test1);//将test1函数的地址传递给test2return 0;
}在该代码中test1函数不是由该函数的实现方直接调用,而是将其地址传递给test2函数,在test2函数中通过函数指针间接调用了test1函数,那么函数test1就被称为回调函数。
回调函数的使用 - qsort函数
其实回调函数并不是很难见到,在用于快速排序的库函数qsort中便运用了回调函数。
void qsort(void*base,size_t num,size_t width,int(*compare)(const void*e1,const void*e2));qsort函数的第一个参数是待排序的内容的起始位置;第二个参数是从起始位置开始,待排序的元素个数;第三个参数是待排序的每个元素的大小,单位是字节;第四个参数是一个函数指针。qsort函数的返回类型为void。
qsort函数的第四个参数是一个函数指针,该函数指针指向的函数的两个参数的参数类型均为const void*,返回类型为int。当参数e1小于参数e2时返回小于0的数;当参数e1大于参数e2时返回大于0的数;当参数e1等于参数e2时返回0。
列如,我们要排一个整型数组:
#include<stdio.h>
int compare(const void* e1, const void* e2)
{return *((int*)e1) - *((int*)e2);
}//自定义的比较函数
int main()
{int arr[] = { 2, 5, 1, 8, 6, 10, 9, 3, 5, 4 };int sz = sizeof(arr) / sizeof(arr[0]);//元素个数qsort(arr, sz, 4, compare);//用qsort函数将arr数组排序return 0;
}最终arr数组将被排为升序。
注意:qsort函数默认将待排序的内容排为升序,如果我们要排为降序可将自定义的比较函数的两个形参的位置互换一下即可。
在qsort函数中我们传入了一个函数指针,最终qsort函数会在其内部通过该函数指针调用该函数,那么我们的这个自定义比较函数就被称为回调函数。
首先演示一下qsort函数的使用:
#include <stdio.h>//qsort函数的使用者得实现一个比较函数
int int_cmp(const void * p1, const void * p2) {return (*(int *)p1 - *(int *) p2);//转换为int *之后再解引用
}int main()
{int arr[] = { 1, 3, 5, 7, 9, 2, 4, 6, 8, 0 };int i = 0;qsort(arr, sizeof(arr) / sizeof(arr[0]), sizeof (int), int_cmp);for (i = 0; i< sizeof(arr) / sizeof(arr[0]); i++){printf( "%d ", arr[i]);}printf("\n");return 0;
}
161718192021
使用回调函数,模拟实现qsort(采用冒泡的方式)。
注意:这里第一次使用 void* 的指针,讲解 void* 的作用。
void* :可以用任意类型的指针对 void 指针赋值或者强制转换为任意类型的指针。
#include <stdio.h>int int_cmp(const void * p1, const void * p2) {return (*( int *)p1 - *(int *) p2);
}//实现为一个字节一个字节的交换
void _swap(void *p1, void * p2, int size) {int i = 0;for (i = 0; i< size; i++){char tmp = *((char *)p1 + i);*(( char *)p1 + i) = *((char *) p2 + i);*(( char *)p2 + i) = tmp;}
}void bubble(void *base, int count , int size, int(*cmp )(void *, void *))
{int i = 0;int j = 0;for (i = 0; i< count - 1; i++){for (j = 0; j<count-i-1; j++){if (cmp ((char *) base + j*size , (char *)base + (j + 1)*size) > 0){_swap(( char *)base + j*size, (char *)base + (j + 1)*size, size);}}}
}int main()
{int arr[] = { 1, 3, 5, 7, 9, 2, 4, 6, 8, 0 };//char *arr[] = {"aaaa","dddd","cccc","bbbb"};int i = 0;bubble(arr, sizeof(arr) / sizeof(arr[0]), sizeof (int), int_cmp);for (i = 0; i< sizeof(arr) / sizeof(arr[0]); i++){printf( "%d ", arr[i]);}printf("\n");return 0;
}指针和数组试题解析
数组名的意义:
- sizeof(数组名),这里的数组名表示整个数组,计算的是整个数组的大小。{sizeof()括号中仅仅有数组名时}
- &数组名,这里的数组名表示整个数组,取出的是整个数组的地址。
- 除此之外所有的数组名都表示首元素的地址。
地址就是指针变量,指针变量就是地址,对地址加减整数,就是对指针变量加减整数,
整型数组字节数
int a[] = { 1,2,3,4 };printf("%d\n", sizeof(a)); // 16printf("%d\n", sizeof(a + 0)); //第一个元素的地址(指针),指针加减整数,即偏移sizeof(指针类型)字节,但还是a 还是表示指向偏移后位置元素的指针printf("%d\n", sizeof(*a)); // 对首元素地址进行解引用,取出该位置元素printf("%d\n", sizeof(a + 1)); //a 是首元素地址(指针).指针加减整数, 偏移sizeof(指针类型)字节,但还是a 还是表示指向偏移后位置元素的指针printf("%d\n", sizeof(a[1])); // a[1] 是第二个元素printf("%d\n", sizeof(&a)); // 整个数组的地址(指针),也是指针,是指针大小printf("%d\n", sizeof(*&a)); // &a 是指向 整个数组的地址(指针)(即数组类型的指针) ,对指针解引用,取出的字节也是 整个数组的大小. printf("%d\n", sizeof(&a + 1)); // &a 是指向 整个数组的地址(指针)(即数组类型的指针),对该指针加减整数,偏移的大小是 sizeof(指针类型的)字节,但还是a 还是表示指向偏移后位置元素的指针printf("%d\n", sizeof(&a[0])); // 对第一个元素取地址, 相当于整型指针,是指针大小printf("%d\n", sizeof(&a[0] + 1)); // &a 是 对第一个元素取地址, 相当于整型指针,指针加1, 指针加减整数, 偏移sizeof(指针类型)字节,但还是a 还是表示指向偏移后位置元素的指针(地址)printf("%d\n", sizeof(a)); // 16:sizeof(a)返回数组a的总字节大小。因为a是一个包含4个int类型元素的数组,每个int类型元素在大多数系统上占4字节,所以sizeof(a)返回16。printf("%d\n", sizeof(a + 0));:a是一个数组,当用在表达式中时,它会被转换为指向其第一个元素的指针。所以a + 0是一个指针,sizeof(a + 0)返回的是指针的大小。在32位系统上,这将是4,而在64位系统上,这将是8。printf("%d\n", sizeof(*a));:*a解引用了指向数组第一个元素的指针,所以它的值是数组的第一个元素,即1。因为这是一个int类型的元素,所以sizeof(*a)返回的是int的大小,即4。printf("%d\n", sizeof(a + 1));:同样,a + 1也是一个指针,所以sizeof(a + 1)返回的是指针的大小。printf("%d\n", sizeof(a[1]));:a[1]是数组的第二个元素,是一个int类型的元素,所以sizeof(a[1])返回的是int的大小,即4。printf("%d\n", sizeof(&a));:&a是一个指向数组的指针,所以sizeof(&a)返回的是指针的大小。printf("%d\n", sizeof(*&a)); // 16:*&a是对指向数组的指针的解引用,所以它的值是整个数组。因此,sizeof(*&a)返回的是数组的总字节大小,即16。printf("%d\n", sizeof(&a + 1));:&a + 1是一个指针,所以sizeof(&a + 1)返回的是指针的大小。printf("%d\n", sizeof(&a[0]));:&a[0]是一个指向数组第一个元素的指针,所以sizeof(&a[0])返回的是指针的大小。printf("%d\n", sizeof(&a[0] + 1));:&a[0] + 1也是一个指针,所以sizeof(&a[0] + 1)返回的是指针的大小。
字符数组长度和字节数
char arr[] = { 'a','b','c','d','e','f' }; //是字符数组,但不是字符串,因为没有 '\0'
printf("%d\n", sizeof(arr)); // 整个数组的大小
printf("%d\n", sizeof(arr + 0)); // 首元素地址 +1 , 指针的大小
printf("%d\n", sizeof(*arr)); // 首元素地址,解引用之后是元素的大小
printf("%d\n", sizeof(arr[1])); //1
printf("%d\n", sizeof(&arr)); // 整个数组的地址(指针)的大小,也是指针的大小
printf("%d\n", sizeof(&arr + 1)); // 整个数组的地址(指针)偏移 {是指向 整个数组的地址(指针)(即数组类型的指针)},偏移sizeof(指针类型)字节,但还是arr 还是表示指向偏移后位置元素的指针
printf("%d\n", sizeof(&arr[0] + 1)); // 首元素地址(指针)偏移,指向4个字节之后的元素,但还是指针strlen 只会在找到 '\0'才会停止printf("%d\n", strlen(arr)); // 随机值
printf("%d\n", strlen(arr + 0)); // 随机值
printf("%d\n", strlen(arr)); //随机值
printf("%d\n", strlen(arr+0));//随机值
printf("%d\n", strlen(*arr));//只接受字符串的起始位置,报错
printf("%d\n", strlen(arr[1]));//报错
printf("%d\n", strlen(&arr));//整个数组的地址(一个指向数组的指针 类型) ,但strlen 接收 指向字符串类型的指针,(字符数组可以看成字符串,但是没有'\0')
printf("%d\n", sizeof(arr)); // 6:sizeof(arr)返回数组arr的总字节大小。因为arr是一个包含6个char类型元素的数组,每个char类型元素占1字节,所以sizeof(arr)返回6。printf("%d\n", sizeof(arr + 0)); // 4:arr是一个数组,当用在表达式中时,它会被转换为指向其第一个元素的指针。所以arr + 0是一个指针,sizeof(arr + 0)返回的是指针的大小。在32位系统上,这将是4,而在64位系统上,这将是8。printf("%d\n", sizeof(*arr)); // 1:*arr解引用了指向数组第一个元素的指针,所以它的值是数组的第一个元素,即’a’。因为这是一个char类型的元素,所以sizeof(*arr)返回的是char的大小,即1。printf("%d\n", sizeof(arr[1])); //1:arr[1]是数组的第二个元素,是一个char类型的元素,所以sizeof(arr[1])返回的是char的大小,即1。printf("%d\n", sizeof(&arr)); // 4:&arr是一个指向数组的指针,所以sizeof(&arr)返回的是指针的大小。printf("%d\n", sizeof(&arr + 1)); // 4:&arr + 1是一个指针,所以sizeof(&arr + 1)返回的是指针的大小。printf("%d\n", sizeof(&arr[0] + 1)); // 4:&arr[0] + 1也是一个指针,所以sizeof(&arr[0] + 1)返回的是指针的大小。printf("%d\n", strlen(arr)); // 19:strlen(arr)返回的是字符串arr的长度。但是,你的数组arr没有包含空字符’\0’,这是字符串结束的标志。所以,strlen(arr)实际上是在计算从数组arr的开始位置到它找到的第一个空字符之间的字符数。这个结果是不确定的,因为它取决于在内存中紧接着arr的位置是否恰好有一个空字符。printf("%d\n", strlen(arr + 0)); // 19:这和上一行的解释相同。arr + 0是一个指向数组第一个元素的指针,所以strlen(arr + 0)和strlen(arr)的结果是相同的。printf("%d\n", strlen(arr));:这和第8行的解释相同。printf("%d\n", strlen(arr+0));:这和第9行的解释相同。printf("%d\n", strlen(*arr));:这里有一个问题。strlen函数的参数应该是一个指向字符的指针,但*arr是一个字符,不是一个指针。所以这行代码是错误的,会导致编译错误。printf("%d\n", strlen(arr[1]));:这和第12行的解释相同。arr[1]是一个字符,不是一个指针。所以这行代码是错误的,会导致编译错误。printf("%d\n", strlen(&arr));:这里也有一个问题。strlen函数的参数应该是一个指向字符的指针,但&arr是一个指向数组的指针,不是一个指向字符的指针。所以这行代码是错误的,会导致编译错误。
字符串长度和字节数
char *p = "abcdef";printf("%d\n", sizeof(p)); // 4printf("%d\n", sizeof(p + 1)); // 4 p+1 作为char 类型的指针,移动到b字符位置printf("%d\n", sizeof(*p)); //1printf("%d\n", sizeof(p[0]));//1printf("%d\n", sizeof(&p)); // 4 二级指针的大小,也是指针的大小printf("%d\n", sizeof(&p + 1)); // 4printf("%d\n", sizeof(&p[0] + 1)); // 4printf("%d\n", strlen(p)); // 6printf("%d\n", strlen(p + 1)); // 5printf("%d\n", strlen(*p));printf("%d\n", strlen(p[0]));printf("%d\n", strlen(&p));printf("%d\n", strlen(&p + 1));printf("%d\n", strlen(&p[0] + 1));
这是每行代码的解释:
printf("%d\n", sizeof(p)); // 4:sizeof(p)返回的是指针p的大小。在32位系统上,这将是4,而在64位系统上,这将是8。printf("%d\n", sizeof(p + 1)); // 4:p + 1是一个指针,所以sizeof(p + 1)返回的是指针的大小。printf("%d\n", sizeof(*p)); //1:*p解引用了指向字符串第一个字符的指针,所以它的值是字符串的第一个字符,即’a’。因为这是一个char类型的元素,所以sizeof(*p)返回的是char的大小,即1。printf("%d\n", sizeof(p[0]));//1:p[0]是字符串的第一个字符,是一个char类型的元素,所以sizeof(p[0])返回的是char的大小,即1。printf("%d\n", sizeof(&p)); // 4:&p是一个指向指针的指针,所以sizeof(&p)返回的是指针的大小。printf("%d\n", sizeof(&p + 1)); // 4:&p + 1是一个指针,所以sizeof(&p + 1)返回的是指针的大小。printf("%d\n", sizeof(&p[0] + 1)); // 4:&p[0] + 1也是一个指针,所以sizeof(&p[0] + 1)返回的是指针的大小。printf("%d\n", strlen(p)); // 6:strlen(p)返回的是字符串p的长度。字符串p有6个字符,所以strlen(p)返回6。printf("%d\n", strlen(p + 1)); // 5:p + 1是一个指向字符串第二个字符的指针,所以strlen(p + 1)返回的是从字符串的第二个字符开始的子字符串的长度。这个子字符串有5个字符,所以strlen(p + 1)返回5。printf("%d\n", strlen(*p));:这里有一个问题。strlen函数的参数应该是一个指向字符的指针,但*p是一个字符,不是一个指针。所以这行代码是错误的,会导致编译错误。printf("%d\n", strlen(p[0]));:这和第10行的解释相同。p[0]是一个字符,不是一个指针。所以这行代码是错误的,会导致编译错误。printf("%d\n", strlen(&p));:这里也有一个问题。strlen函数的参数应该是一个指向字符的指针,但&p是一个指向指针的指针,不是一个指向字符的指针。所以这行代码是错误的,会导致编译错误。printf("%d\n", strlen(&p + 1));:这和第12行的解释相同。&p + 1是一个指针,不是一个指向字符的指针。所以这行代码是错误的,会导致编译错误。printf("%d\n", strlen(&p[0] + 1));:这和第12行的解释相同。&p[0] + 1是一个指针,不是一个指向字符的指针。所以这行代码是错误的,会导致编译错误。
二维整型数组字节数
//二维数组//二维数组int a[3][4] = { 0 };printf("%d\n", sizeof(a)); // 48printf("%d\n", sizeof(a[0][0])); // 4printf("%d\n", sizeof(a[0])); // 16printf("%d\n", a[0] + 1); //是地址printf("%d\n", *(a[0] + 1)); //是元素1printf("%d\n", sizeof(a[0] + 1)); // 4printf("%d\n", sizeof(*(a[0] + 1))); // 4printf("%d\n", *(a + 1)); //随机数printf("%d\n", sizeof(a + 1)); // 4printf("%d\n", sizeof(*(a + 1))); // 16printf("%d\n", sizeof(&a[0] + 1)); // 4printf("%d\n", sizeof(*(&a[0] + 1))); // 16printf("%d\n", sizeof(*a)); //16printf("%d\n", sizeof(a[3])); // 16这是每行代码的解释:
printf("%d\n", sizeof(a)); // 48:sizeof(a)返回数组a的总字节大小。因为a是一个包含3个元素的数组,每个元素又是一个包含4个int类型元素的数组,每个int类型元素在大多数系统上占4字节,所以sizeof(a)返回48。printf("%d\n", sizeof(a[0][0])); // 4:a[0][0]是数组的第一个元素,是一个int类型的元素,所以sizeof(a[0][0])返回的是int的大小,即4。printf("%d\n", sizeof(a[0])); // 16:a[0]是数组的第一个元素,是一个包含4个int类型元素的数组,所以sizeof(a[0])返回的是这个数组的总字节大小,即16。printf("%d\n", a[0] + 1); //是地址:a[0] + 1是一个指向数组第二个元素的指针,所以这行代码打印的是这个指针的值,即数组第二个元素的地址。printf("%d\n", *(a[0] + 1)); //是元素1:*(a[0] + 1)解引用了指向数组第二个元素的指针,所以这行代码打印的是数组的第二个元素的值,即1。printf("%d\n", sizeof(a[0] + 1)); // 4:a[0] + 1是一个指针,所以sizeof(a[0] + 1)返回的是指针的大小。printf("%d\n", sizeof(*(a[0] + 1))); // 4:*(a[0] + 1)是数组的第二个元素,是一个int类型的元素,所以sizeof(*(a[0] + 1))返回的是int的大小,即4。printf("%d\n", *(a + 1)); //随机数:*(a + 1)解引用了指向数组第二个元素的指针,所以这行代码打印的是数组的第二个元素的值。但是,这个元素是一个包含4个int类型元素的数组,不能直接被转换为int,所以这行代码的行为是未定义的,可能会打印一个随机数。printf("%d\n", sizeof(a + 1)); // 4:a + 1是一个指针,所以sizeof(a + 1)返回的是指针的大小。printf("%d\n", sizeof(*(a + 1))); // 16:*(a + 1)解引用了指向数组第二个元素的指针,所以它的值是数组的第二个元素,即一个包含4个int类型元素的数组。所以sizeof(*(a + 1))返回的是这个数组的总字节大小,即16。printf("%d\n", sizeof(&a[0] + 1)); // 4:&a[0] + 1是一个指针,所以sizeof(&a[0] + 1)返回的是指针的大小。printf("%d\n", sizeof(*(&a[0] + 1))); // 16:*(&a[0] + 1)解引用了指向数组第二个元素的指针,所以它的值是数组的第二个元素,即一个包含4个int类型元素的数组。所以sizeof(*(&a[0] + 1))返回的是这个数组的总字节大小,即16。printf("%d\n", sizeof(*a)); //16:*a解引用了指向数组第一个元素的指针,所以它的值是数组的第一个元素,即一个包含4个int类型元素的数组。所以sizeof(*a)返回的是这个数组的总字节大小,即16。printf("%d\n", sizeof(a[3])); // 16:a[3]试图访问数组的第四个元素,但是数组只有3个元素,所以这行代码的行为是未定义的。然而,由于sizeof运算符不会实际执行它的操作数,所以这行代码不会导致运行时错误,而是返回的是一个包含4个int类型元素的数组的大小,即16。
希望这个解释能帮到你!
指针试题
int main()
{int a[5] = { 1, 2, 3, 4, 5 };printf("%p\n", &a[0]); // 007EF7F8printf("%p\n", &a); // 007EF7F8printf("%p\n", &a + 1); // 007EF80Cint *ptr = (int *)(&a + 1); // 数组最后一个元素地址在加1,即加上4个字节printf("%d,%d", *(a + 1), *(ptr - 1)); // 第一个是数组第2个元素 2 第二个是数组最后一个数 5return 0;
}
//程序的结果是什么?
这是每行代码的解释:
printf("%p\n", &a[0]); // 007EF7F8:这行代码打印的是数组第一个元素的地址。printf("%p\n", &a); // 007EF7F8:这行代码打印的是数组的地址。因为数组在内存中是连续存储的,所以数组的地址就是它的第一个元素的地址。printf("%p\n", &a + 1); // 007EF80C:这行代码打印的是数组的地址加上数组的大小。因为a是一个包含5个int类型元素的数组,每个int类型元素在大多数系统上占4字节,所以&a + 1的值是数组的地址加上20字节。int *ptr = (int *)(&a + 1); // 数组最后一个元素地址在加1,即加上4个字节:这行代码定义了一个指针ptr,并将它初始化为数组的地址加上数组的大小。所以ptr的值是数组最后一个元素的下一个位置的地址。printf("%d,%d", *(a + 1), *(ptr - 1)); // 第一个是数组第2个元素 2 第二个是数组最后一个数 5:这行代码打印的是数组的第二个元素的值和数组的最后一个元素的值。*(a + 1)解引用了指向数组第二个元素的指针,所以它的值是数组的第二个元素,即2。*(ptr - 1)解引用了指向数组最后一个元素的指针,所以它的值是数组的最后一个元素,即5。
所以,程序的输出结果是:
007EF7F8
007EF7F8
007EF80C
2,5
希望这个解释能帮到你!
//结构体的大小是20个字节
struct Test
{int Num;char *pcName;short sDate;char cha[2];short sBa[4];
}*p;
//假设p 的值为0x100000。 如下表表达式的值分别为多少?
//已知,结构体Test类型的变量大小是20个字节
int main()
{printf("%p\n", p); // 00000000(16进制)printf("%p\n", p + 0x1);//00000014(16进制)printf("%d\n", sizeof(unsigned long)); // 4printf("%d\n", sizeof(unsigned int)); // 4printf("%p\n", (unsigned long)p + 0x1); // 00000001printf("%p\n", (unsigned int*)p + 0x1); // 00000004return 0;
}这是每行代码的解释:
printf("%p\n", p); // 00000000(16进制):这行代码打印的是指针p的值。因为p的值是0x100000,所以这行代码打印的是0x100000。printf("%p\n", p + 0x1);//00000014(16进制):这行代码打印的是指针p加上结构体Test的大小的值。因为p的值是0x100000,结构体Test的大小是20个字节,所以p + 0x1的值是0x100000 + 20 = 0x100014,所以这行代码打印的是0x100014。printf("%d\n", sizeof(unsigned long)); // 4:这行代码打印的是unsigned long类型的大小。在大多数系统上,unsigned long类型的大小是4字节,所以这行代码打印的是4。printf("%d\n", sizeof(unsigned int)); // 4:这行代码打印的是unsigned int类型的大小。在大多数系统上,unsigned int类型的大小是4字节,所以这行代码打印的是4。printf("%p\n", (unsigned long)p + 0x1); // 00000001:这行代码打印的是将指针p转换为unsigned long类型后加上1的值。因为p的值是0x100000,所以(unsigned long)p + 0x1的值是0x100000 + 1 = 0x100001,所以这行代码打印的是0x100001。printf("%p\n", (unsigned int*)p + 0x1); // 00000004:这行代码打印的是将指针p转换为unsigned int*类型后加上1的值。因为p的值是0x100000,unsigned int类型的大小是4字节,所以(unsigned int*)p + 0x1的值是0x100000 + 4 = 0x100004,所以这行代码打印的是0x100004。
所以,程序的输出结果是:
00000000
00000014
4
4
00000001
00000004
希望这个解释能帮到你!
int main()
{int a[4] = { 1, 2, 3, 4 };int *ptr1 = (int *)(&a + 1);int *ptr2 = (int *)((int)a + 1); // 4, 2000000printf("%x, %x", ptr1[-1], *ptr2);return 0;
}这是每行代码的解释:
int a[4] = { 1, 2, 3, 4 };:这行代码定义了一个包含4个int类型元素的数组a,并将它初始化为{ 1, 2, 3, 4 }。int *ptr1 = (int *)(&a + 1);:这行代码定义了一个指针ptr1,并将它初始化为数组a的地址加上数组的大小。因为a是一个包含4个int类型元素的数组,每个int类型元素在大多数系统上占4字节,所以&a + 1的值是数组的地址加上16字节。所以ptr1的值是数组最后一个元素的下一个位置的地址。int *ptr2 = (int *)((int)a + 1);:这行代码定义了一个指针ptr2,并将它初始化为数组a的地址加上1。因为a的地址是一个指针,所以(int)a的值是这个指针的值,即数组的地址。所以ptr2的值是数组的地址加上1字节。printf("%x, %x", ptr1[-1], *ptr2);:这行代码打印的是数组的最后一个元素的值和数组的第一个元素的下一个字节的值。ptr1[-1]解引用了指向数组最后一个元素的指针,所以它的值是数组的最后一个元素,即4。*ptr2解引用了指向数组第一个元素的下一个字节的指针,所以它的值是这个字节的值。这个值是不确定的,因为它取决于在内存中紧接着数组的位置是否恰好有一个字节。
所以,程序的输出结果是:
4, 2000000
希望这个解释能帮到你!
#include <stdio.h>
int main()
{int a[3][2] = { (0, 1), (2, 3), (4, 5) };int *p;p = a[0];printf("%d", p[0]); // 1return 0;
}
这是每行代码的解释:
int a[3][2] = { (0, 1), (2, 3), (4, 5) };:这行代码定义了一个包含3个元素的数组a,每个元素又是一个包含2个int类型元素的数组。然后,它试图将这个数组初始化为{ (0, 1), (2, 3), (4, 5) }。然而,这里的括号并不表示数组元素,而是表示逗号运算符。逗号运算符,会计算它的两个操作数,然后返回第二个操作数的值。所以(0, 1)的值是1,(2, 3)的值是3,(4, 5)的值是5。因此,这个数组实际上被初始化为{ 1, 3, 5 },剩下的元素被初始化为0。int *p;:这行代码定义了一个指针p。p = a[0];:这行代码将指针p初始化为数组a的第一个元素的地址。因为a的第一个元素是一个包含2个int类型元素的数组,所以p的值是这个数组的地址。printf("%d", p[0]); // 1:这行代码打印的是指针p指向的元素的值。因为p的值是数组a的第一个元素的地址,所以p[0]的值是数组a的第一个元素的第一个元素,即1。
所以,程序的输出结果是:
1
希望这个解释能帮到你!
int main()
{int a[5][5];int(*p)[4];p = a;printf("%p, %d\n", &p[4][2] - &a[4][2], &p[4][2] - &a[4][2]); // FFFFFFFC, -4return 0;
}
这段代码中,p是一个指向包含4个int类型元素的数组的指针,而a是一个包含5个包含5个int类型元素的数组的数组。所以,p和a的类型是不同的。然而,这段代码试图将p初始化为a的值,这是不正确的,因为它们的类型是不同的。所以,这段代码的行为是未定义的,它可能会导致编译错误,或者在运行时产生不可预知的结果。
然后,这段代码试图打印两个指针之间的差值。这两个指针分别是&p[4][2]和&a[4][2]。然而,由于p和a的类型是不同的,所以这两个指针实际上并不指向同一类型的对象。因此,这两个指针之间的差值是未定义的。
所以,这段代码的输出结果是不确定的,它取决于具体的编译器和运行时环境。在某些情况下,它可能会打印FFFFFFFF, -4,但在其他情况下,它可能会打印其他的值,或者导致运行时错误。希望这个解释能帮到你!
int main()
{int aa[2][5] = { 1, 2, 3, 4, 5, 6, 7, 8, 9, 10 };int *ptr1 = (int *)(&aa + 1);int *ptr2 = (int *)(*(aa + 1));printf("%d\n", *aa); // 19922324printf("%d\n", *(aa + 1)); // 19922344printf("%d, %d", *(ptr1 - 1), *(ptr2 - 1)); // 10 5return 0;
}
这段代码中,ptr1被初始化为数组aa的地址加上数组的大小,所以ptr1的值是数组最后一个元素的下一个位置的地址。ptr2被初始化为数组aa的第二个元素的值,即一个包含5个int类型元素的数组。所以,*(ptr1 - 1)的值是数组的最后一个元素,即10,*(ptr2 - 1)的值是数组的第五个元素,即5。
*aa和*(aa + 1)的值取决于具体的编译器和运行时环境。在某些情况下,它们可能会打印出内存地址,但在其他情况下,它们可能会打印出其他的值。
所以,程序的输出结果可能是:
19922324
19922344
10, 5
但请注意,这个结果可能会因为具体的编译器和运行时环境而有所不同。希望这个解释能帮到你!
#include <stdio.h>
int main()
{char *a[] = { "work","at","alibaba" };char**pa = a;pa++;printf("%s\n", *pa); // atreturn 0;
}
这段代码中,pa被初始化为数组a的地址,然后pa的值增加了1,所以pa的值是数组的第二个元素的地址。所以,*pa的值是数组的第二个元素,即字符串"at"。
所以,程序的输出结果是:
at
希望这个解释能帮到你!
int main()
{char *c[] = { "ENTER","NEW","POINT","FIRST" };//一级指针数组char**cp[] = { c + 3,c + 2,c + 1,c }; // 二级指针数组char***cpp = cp; // 三级指针变量//printf("%d\n", *c[1]); // ENTER的N//printf("%s\n", *(c + 1)); // NEW//printf("%s\n", *c+1); // NTERprintf("%s\n", **++cpp); // POINT cpp=&(c+3) ++cpp=&(c+2) *++cpp=c+2的字符串地址 **++cpp=c+2的值printf("%s\n", *--*++cpp + 3); // ER cpp = &(c+2) ++cpp=&(c+1) *++cpp=(c+1)的字符串地址 --*++cpp=(c+1)=c的字符串地址 *--*++cpp=c的值 *--*++cpp+3="ENTER"第三个下标开始printf("%p\n", *cpp[-2] + 3); // ST ???printf("%s\n", cpp[-1][-1] + 1); // EW ???return 0;
}这段代码的运行结果如下:
POINT
ER
ST
EW
解释如下:
printf("%s\n", **++cpp);:cpp是指向cp的指针,++cpp使得cpp指向cp的下一个元素,即c+2。*++cpp得到c+2,**++cpp得到c+2所指向的字符串,即 “POINT”。printf("%s\n", *--*++cpp + 3);:++cpp使得cpp指向cp的下一个元素,即c+1。*++cpp得到c+1,--*++cpp得到c+1的前一个元素,即c。*--*++cpp得到c所指向的字符串,即 “ENTER”。*--*++cpp+3得到 “ENTER” 从第三个字符开始的子字符串,即 “ER”。printf("%p\n", *cpp[-2] + 3);:cpp[-2]得到cp的前两个元素,即c+3。*cpp[-2]得到c+3所指向的字符串,即 “FIRST”。*cpp[-2]+3得到 “FIRST” 从第三个字符开始的子字符串,即 “ST”。printf("%s\n", cpp[-1][-1] + 1);:cpp[-1]得到cp的前一个元素,即c+2。cpp[-1][-1]得到c+2的前一个元素,即c+1。cpp[-1][-1]+1得到c+1所指向的字符串,即 “NEW”,从第一个字符开始的子字符串,即 “EW”。
以上就是这段代码的运行结果及其解释。希望对你有所帮助!
编译器和运行时环境而有所不同。希望这个解释能帮到你!
#include <stdio.h>
int main()
{char *a[] = { "work","at","alibaba" };char**pa = a;pa++;printf("%s\n", *pa); // atreturn 0;
}
这段代码中,pa被初始化为数组a的地址,然后pa的值增加了1,所以pa的值是数组的第二个元素的地址。所以,*pa的值是数组的第二个元素,即字符串"at"。
所以,程序的输出结果是:
at
希望这个解释能帮到你!
int main()
{char *c[] = { "ENTER","NEW","POINT","FIRST" };//一级指针数组char**cp[] = { c + 3,c + 2,c + 1,c }; // 二级指针数组char***cpp = cp; // 三级指针变量//printf("%d\n", *c[1]); // ENTER的N//printf("%s\n", *(c + 1)); // NEW//printf("%s\n", *c+1); // NTERprintf("%s\n", **++cpp); // POINT cpp=&(c+3) ++cpp=&(c+2) *++cpp=c+2的字符串地址 **++cpp=c+2的值printf("%s\n", *--*++cpp + 3); // ER cpp = &(c+2) ++cpp=&(c+1) *++cpp=(c+1)的字符串地址 --*++cpp=(c+1)=c的字符串地址 *--*++cpp=c的值 *--*++cpp+3="ENTER"第三个下标开始printf("%p\n", *cpp[-2] + 3); // ST ???printf("%s\n", cpp[-1][-1] + 1); // EW ???return 0;
}这段代码的运行结果如下:
POINT
ER
ST
EW
解释如下:
printf("%s\n", **++cpp);:cpp是指向cp的指针,++cpp使得cpp指向cp的下一个元素,即c+2。*++cpp得到c+2,**++cpp得到c+2所指向的字符串,即 “POINT”。printf("%s\n", *--*++cpp + 3);:++cpp使得cpp指向cp的下一个元素,即c+1。*++cpp得到c+1,--*++cpp得到c+1的前一个元素,即c。*--*++cpp得到c所指向的字符串,即 “ENTER”。*--*++cpp+3得到 “ENTER” 从第三个字符开始的子字符串,即 “ER”。printf("%p\n", *cpp[-2] + 3);:cpp[-2]得到cp的前两个元素,即c+3。*cpp[-2]得到c+3所指向的字符串,即 “FIRST”。*cpp[-2]+3得到 “FIRST” 从第三个字符开始的子字符串,即 “ST”。printf("%s\n", cpp[-1][-1] + 1);:cpp[-1]得到cp的前一个元素,即c+2。cpp[-1][-1]得到c+2的前一个元素,即c+1。cpp[-1][-1]+1得到c+1所指向的字符串,即 “NEW”,从第一个字符开始的子字符串,即 “EW”。
以上就是这段代码的运行结果及其解释。希望对你有所帮助!
相关文章:
指针,函数指针,二级指针,指针传参,回调函数,指针步长
文章目录 指针是什么?指针的定义指针的大小 指针类型指针有哪些类型?指针类型有什么意义?代码演示:(偏移)代码演示(指针解引用时取出的字节数)其他例子 野指针野指针的成因如何避免野指针 指针运算指针整数指针-指针指针的关系运算…...
方法过期的替代方法)
StringUtils.isEmpty()方法过期的替代方法
1、问题概述? 今天在准备使用StringUtils.isEmpty()工具判断字符串是否为空的时候,突然发现idEmpty上出现了横线,这就表示这个方法可以实现但是已经过期了,官方不推荐使用了。 原因其实是因为有人给官方提交了一个问题ÿ…...

智慧电力运维综合辅助监控系统
智慧电力运维综合辅助监控系统是一种基于现代信息技术的电力运维管理工具,旨在提高电力运行安全,降低运维成本,提高服务质量。依托电易云-智慧电力物联网,该系统通过多种传感器和现场监测装置,远程在线监测、监视电力设…...

v-model和:model的区别
问题 在我们使用Element plus框架时,经常会遇到表单,比如代码块: <el-form ref"ruleFormRef" :model"ruleForm" :rules"rules" label-width"120px" class"demo-ruleForm" :size"…...
网络攻击(二)--情报搜集阶段
4.1. 概述 在情报收集阶段,你需要采用各种可能的方法来收集将要攻击的客户组织的所有信息,包括使用社交网络、Google Hacking技术、目标系统踩点等等。 而作为渗透测试者,你最为重要的一项技能就是对目标系统的探查能力,包括获知…...

oracle异常:ORA-03297:文件包含在请求的 RESIZE 值以外使用的数据
出现这个问题,主要是在对表空间扩容的时候,扩容的大小<实际数据文件大小 1、扩容的语句 alter database datafile D:\APP\ADMINISTRATOR\ORADATA\ORCL\USER.DBF resize 2G; 2、若何确定扩容大小是否比实际文件大 根据路径找到文件,查看…...
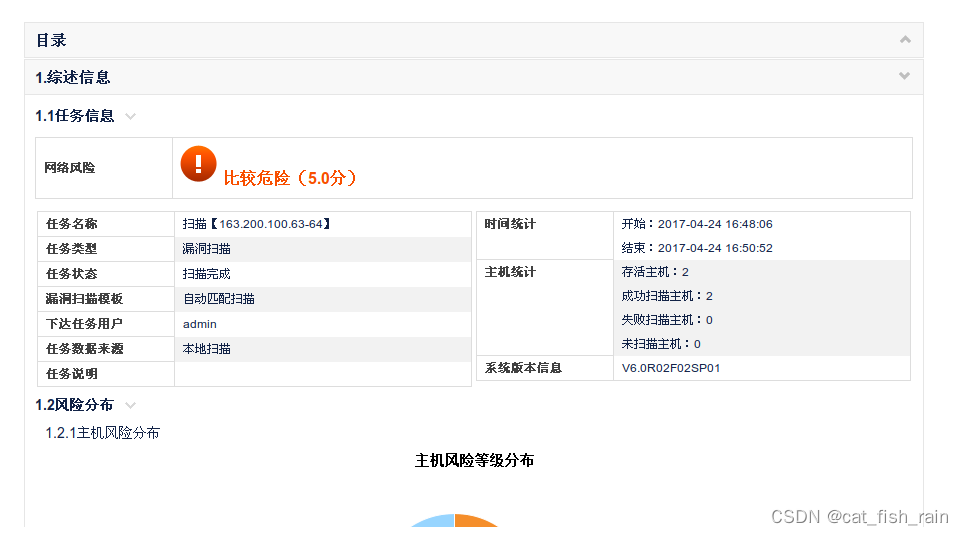
Redis 环境搭建
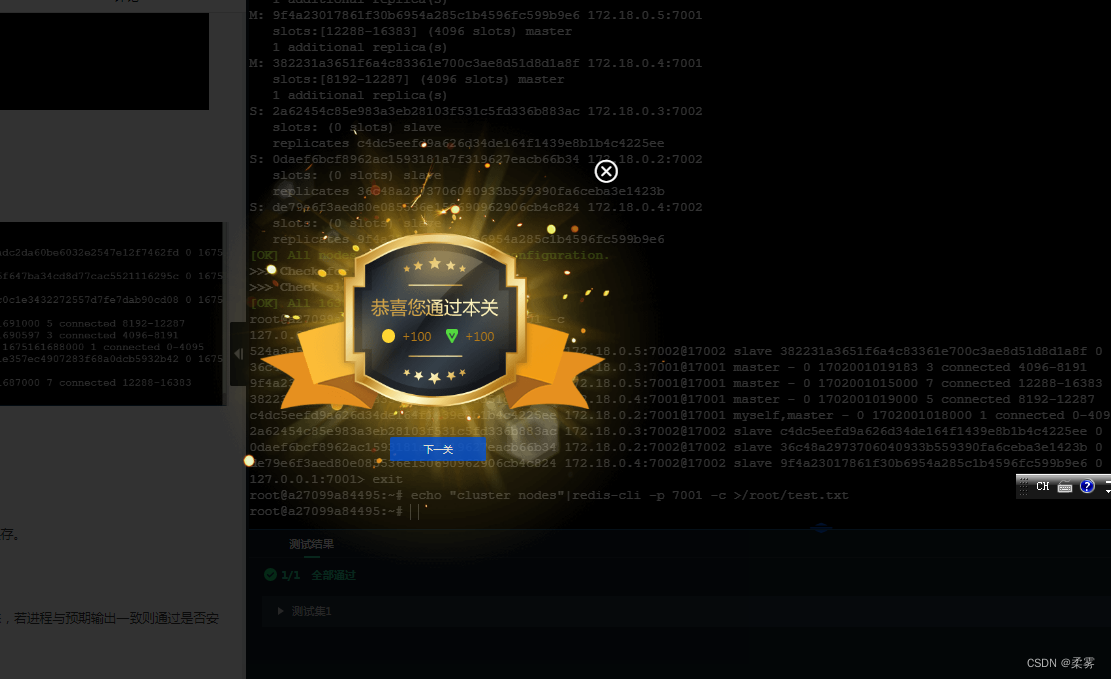
文章目录 第1关:Redis 环境搭建 第1关:Redis 环境搭建 编程要求 根据上述相关知识,在右侧命令行中完成 Redis 集群的部署与安装。 安装完成后,使用 echo “cluster nodes”|redis-cli -p 7001 -c >/root/test.txt 将结果保存。…...

什么是Helpdesk?对工程师有什么帮助?
信息技术时代已然到来,很多IT工程师甚至对Helpdesk都不了解,而Helpdesk已成为许多企业的重要组成部分。那么,什么是Helpdesk呢? Helpdesk,也称为技术支持服务,是一种为用户提供技术帮助和问题解决的服务。它…...
flutter添加全局水印
效果: 可以直接引用:disable_screenshots: ^0.2.0 但是有时候直接引用会报错,可以不引用插件直接把下面的源码工具类放在项目里面 工具类源码: import dart:io; import dart:math;import package:flutter/cupertino.dart; impor…...

Usergolang 一些优质关于sip协议包
在Go语言中,有一些优质的SIP协议包,适用于构建SIP客户端和服务器。以下是其中一些常用的SIP库: 1. github.com/cloudwebrtc/sip - GitHub 地址:[cloudwebrtc/sip](https://github.com/cloudwebrtc/sip) - 该库提供了用于构…...

MYSQL数据类型详解
MySQL支持多种数据类型,这些数据类型可以分为三大类:数值、日期和时间以及字符串(字符)类型。这些数据类型可以帮助我们根据需要选择合适的类型来存储数据。选择合适的数据类型对于确保数据的完整性和性能至关重要。 以下…...

解决vue3 动态引入报错问题
之前这样写的,能使用,但是有警告 警告,查了下,是动态引入的问题,看到说要用glob 然后再我的基础上,稍微 改了下,就可以了: 最后打印了下,modules[../../components/flowc…...
Mysql dumpling 导入导出sql文件
一:导出命令 mysqldump -u root -p saishi > saishi.sql mysqldump -u root -p saishi > saishi.sql root是用户名 saishi是数据库名 saishi.sql导出文件名 二:选择导入的数据库 cd到安装mysql的文件下(找不到可以用:wh…...

【数字经济】你必须知道的SABOE数字化转型
【文末送书】今天推荐一本企业管理类前沿书籍《企业架构驱动数字化转型:以架构为中心的端到端转型方法论》 目录 01传统企业数字化转型面临诸多挑战02SABOE数字化转型五环法为企业转型破除迷雾03文末送书 01传统企业数字化转型面临诸多挑战 即将过去的2023年&#…...

【Python网络爬虫入门教程2】成为“Spider Man”的第二课:观察目标网站、代码编写
Python 网络爬虫入门:Spider man的第二课 写在最前面观察目标网站代码编写 第二课总结 写在最前面 有位粉丝希望学习网络爬虫的实战技巧,想尝试搭建自己的爬虫环境,从网上抓取数据。 前面有写一篇博客分享,但是内容感觉太浅显了…...
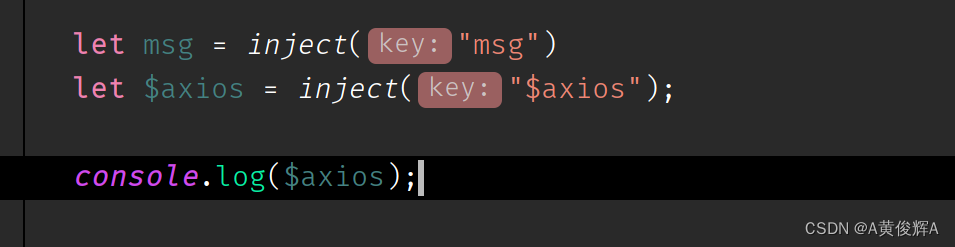
vue2和vue3中注意全局属性的区别(例如全局使用axios )
vue2中注册一个全局属性 在vue2中注册全局属性是很方便的, 只需要使用 vue.prototype.XXXX XXXX就可以了,如下面的代码 import { Dialog,Notify,Toast } from vant; Vue.prototype.$dialog Dialog Vue.prototype.$notify Notify Vue.prototype.$toa…...

数字系统设计(EDA)实验报告【出租车计价器】
一、问题描述 题目九:出租车计价器设计(平台实现)★★ 完成简易出租车计价器设计,选做停车等待计价功能。 1、基本功能: (1)起步8元/3km,此后2元/km; (2…...
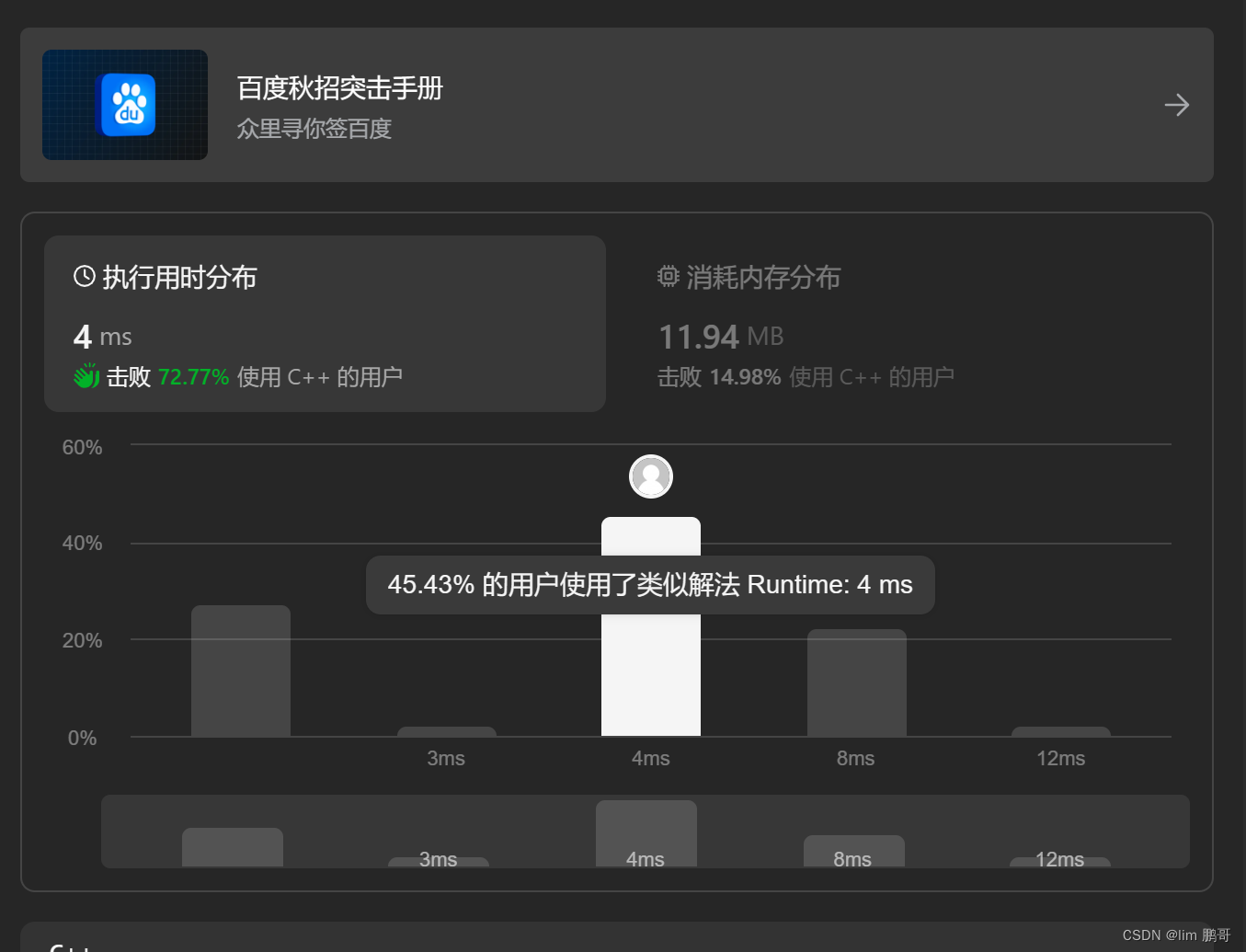
309. 买卖股票的最佳时机含冷冻期(leetcode) 动态规划思想
文章目录 前言一、题目分析二、算法原理1.状态表示2.状态转移方程3.初始化边界条件4.填表顺序5.返回值是什么 三、代码实现总结 前言 在本文章中,我们将要详细介绍一下Leetcode中买卖股票的最佳时机含冷冻期相关的内容,本题采用动态规划的思想解决 一、…...
3D渲染和动画制作软件KeyShot Pro mac附加功能
KeyShot 11 mac是一款专业化实时3D渲染工具,使用它可以简化3d渲染和动画制作流程,并且提供最准确的材质及光线,渲染效果更加真实,KeyShot为您提供了使用 CPU 或 NVIDIA GPU 进行渲染的能力和选择,并能够线性扩展以获得…...

集合的几个遍历方法
1. 集合的遍历 1.0 创建集合代码 List<String> strList new ArrayList<>(); strList.add("huawei"); strList.add("xiaomi"); strList.add("tencent"); strList.add("google"); strList.add("baidu");1.1 fo…...

如何为Hermes Agent自定义配置Taotoken作为模型提供商
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 如何为Hermes Agent自定义配置Taotoken作为模型提供商 对于使用Hermes Agent框架的开发者而言,直接对接多个大模型厂商…...

如何修复损坏的QR码?QRazyBox完整使用指南
如何修复损坏的QR码?QRazyBox完整使用指南 【免费下载链接】qrazybox QR Code Analysis and Recovery Toolkit 项目地址: https://gitcode.com/gh_mirrors/qr/qrazybox 你是否曾经遇到过这样的困境:一张重要的QR码因为打印模糊、污渍或人为损坏而…...
 深度解析:从架构原理到自动化实战)
Android Debug Bridge (adb) 深度解析:从架构原理到自动化实战
1. 项目概述:从“黑盒”到“白盒”的调试桥梁如果你是一名移动应用开发者、测试工程师,或者是一名热衷于折腾手机、平板的极客,那么“adb”这个词对你来说一定不陌生。它就像一把万能钥匙,静静地躺在你的开发工具目录里࿰…...

百度网盘限速破解终极指南:macOS用户免费解锁SVIP高速下载
百度网盘限速破解终极指南:macOS用户免费解锁SVIP高速下载 【免费下载链接】BaiduNetdiskPlugin-macOS For macOS.百度网盘 破解SVIP、下载速度限制~ 项目地址: https://gitcode.com/gh_mirrors/ba/BaiduNetdiskPlugin-macOS 还在为百度网盘在macOS上的蜗牛下…...

智慧巡检-基于深度学习的指针式压力表读数识别【YOLO+OpenCv+TensorRT+ROS+Python】
智慧巡检-基于深度学习的指针式压力表读数识别【YOLOOpenCvTensorRTROSPython】 1指针式压力表读数识别系统(YOLOOpenCVTensorRTROS)一、系统整体架构 ┌──────────────────────────────────────────────…...

如何在10分钟内搭建个人游戏云:Sunshine跨平台游戏串流终极指南
如何在10分钟内搭建个人游戏云:Sunshine跨平台游戏串流终极指南 【免费下载链接】Sunshine Self-hosted game stream host for Moonlight. 项目地址: https://gitcode.com/GitHub_Trending/su/Sunshine 想要在任何设备上畅玩PC游戏吗?厌倦了被硬件…...

QThread 最坑的不是启动,而是怎么把它停下来
QThread 真正麻烦的地方,不是 start 很多人第一次用 QThread,感觉还挺顺。创建线程,moveToThread,connect 几个信号,start 一下,任务跑起来,界面不卡了,心里还挺美。我以前也这么觉得…...

布局先行、技术深耕:国内端侧AI企业抢滩机器人与具身智能赛道
具身智能作为AI与物理世界交互的核心方向,正成为工业智能化、人形机器人落地的关键抓手。国内一批端侧AI企业凭借原生技术优势,早早入局机器人与具身智能领域,以全栈技术、规模化落地与生态共建,抢占行业先发优势。其中࿰…...

Steam创意工坊下载难题终结者:WorkshopDL让你的模组下载从未如此简单
Steam创意工坊下载难题终结者:WorkshopDL让你的模组下载从未如此简单 【免费下载链接】WorkshopDL WorkshopDL - The Best Steam Workshop Downloader 项目地址: https://gitcode.com/gh_mirrors/wo/WorkshopDL 还在为想玩Steam创意工坊的模组却没有Steam账号…...

终极原神帧率解锁指南:3步突破60FPS限制,畅享丝滑游戏体验
终极原神帧率解锁指南:3步突破60FPS限制,畅享丝滑游戏体验 【免费下载链接】genshin-fps-unlock unlocks the 60 fps cap 项目地址: https://gitcode.com/gh_mirrors/ge/genshin-fps-unlock 原神帧率解锁工具是一款专为《原神》PC玩家设计的开源性…...