人工智能|网络爬虫——用Python爬取电影数据并可视化分析
一、获取数据
1.技术工具
IDE编辑器:vscode
发送请求:requests
解析工具:xpath
def Get_Detail(Details_Url):Detail_Url = Base_Url + Details_UrlOne_Detail = requests.get(url=Detail_Url, headers=Headers)One_Detail_Html = One_Detail.content.decode('gbk')Detail_Html = etree.HTML(One_Detail_Html)Detail_Content = Detail_Html.xpath("//div[@id='Zoom']//text()")Video_Name_CN,Video_Name,Video_Address,Video_Type,Video_language,Video_Date,Video_Number,Video_Time,Video_Daoyan,Video_Yanyuan_list = None,None,None,None,None,None,None,None,None,Nonefor index, info in enumerate(Detail_Content):if info.startswith('◎译 名'):Video_Name_CN = info.replace('◎译 名', '').strip()if info.startswith('◎片 名'):Video_Name = info.replace('◎片 名', '').strip()if info.startswith('◎产 地'):Video_Address = info.replace('◎产 地', '').strip()if info.startswith('◎类 别'):Video_Type = info.replace('◎类 别', '').strip()if info.startswith('◎语 言'):Video_language = info.replace('◎语 言', '').strip()if info.startswith('◎上映日期'):Video_Date = info.replace('◎上映日期', '').strip()if info.startswith('◎豆瓣评分'):Video_Number = info.replace('◎豆瓣评分', '').strip()if info.startswith('◎片 长'):Video_Time = info.replace('◎片 长', '').strip()if info.startswith('◎导 演'):Video_Daoyan = info.replace('◎导 演', '').strip()if info.startswith('◎主 演'):Video_Yanyuan_list = []Video_Yanyuan = info.replace('◎主 演', '').strip()Video_Yanyuan_list.append(Video_Yanyuan)for x in range(index + 1, len(Detail_Content)):actor = Detail_Content[x].strip()if actor.startswith("◎"):breakVideo_Yanyuan_list.append(actor)print(Video_Name_CN,Video_Date,Video_Time)f.flush()try:csvwriter.writerow((Video_Name_CN,Video_Name,Video_Address,Video_Type,Video_language,Video_Date,Video_Number,Video_Time,Video_Daoyan,Video_Yanyuan_list))except:pass保存数据:csv
if __name__ == '__main__':with open('movies.csv','a',encoding='utf-8',newline='')as f:csvwriter = csv.writer(f)csvwriter.writerow(('Video_Name_CN','Video_Name','Video_Address','Video_Type','Video_language','Video_Date','Video_Number','Video_Time','Video_Daoyan','Video_Yanyuan_list'))spider(117)2.爬取目标
本次爬取的目标网站是阳光电影网https://www.ygdy8.net,用到技术为requests+xpath。主要获取的目标是2016年-2023年之间的电影数据。
3.字段信息
获取的字段信息有电影译名、片名、产地、类别、语言、上映时间、豆瓣评分、片长、导演、主演等,具体说明如下:

 二、数据预处理
二、数据预处理
技术工具:jupyter notebook
1.加载数据
首先使用pandas读取刚用爬虫获取的电影数据

2.异常值处理
这里处理的异常值包括缺失值和重复值
首先查看原数据各字段的缺失情况

从结果中可以发现缺失数据还蛮多的,这里就为了方便统一删除处理,同时也对重复数据进行删除

可以发现经过处理后的数据还剩1711条。
3.字段处理
由于爬取的原始数据中各个字段信息都很乱,出现很多“/”“,”之类的,这里统一进行处理,主要使用到pandas中的apply()函数,同时由于我们分析的数2016-2023年的电影数据,除此之外的进行删除处理
# 数据预处理
data['Video_Name_CN'] = data['Video_Name_CN'].apply(lambda x:x.split('/')[0]) # 处理Video_Name_CN
data['Video_Name'] = data['Video_Name'].apply(lambda x:x.split('/')[0]) # 处理Video_Name
data['Video_Address'] = data['Video_Address'].apply(lambda x:x.split('/')[0]) # 处理Video_Address
data['Video_Address'] = data['Video_Address'].apply(lambda x:x.split(',')[0].strip())
data['Video_language'] = data['Video_language'].apply(lambda x:x.split('/')[0])
data['Video_language'] = data['Video_language'].apply(lambda x:x.split(',')[0])
data['Video_Date'] = data['Video_Date'].apply(lambda x:x.split('(')[0].strip())
data['year'] = data['Video_Date'].apply(lambda x:x.split('-')[0])
data['Video_Number'] = data['Video_Number'].apply(lambda x:x.split('/')[0].strip())
data['Video_Number'] = pd.to_numeric(data['Video_Number'],errors='coerce')
data['Video_Time'] = data['Video_Time'].apply(lambda x:x.split('分钟')[0])
data['Video_Time'] = pd.to_numeric(data['Video_Time'],errors='coerce')
data['Video_Daoyan'] = data['Video_Daoyan'].apply(lambda x:x.split()[0])
data.drop(index=data[data['year']=='2013'].index,inplace=True)
data.drop(index=data[data['year']=='2014'].index,inplace=True)
data.drop(index=data[data['year']=='2015'].index,inplace=True)
data.dropna(inplace=True)
data.head()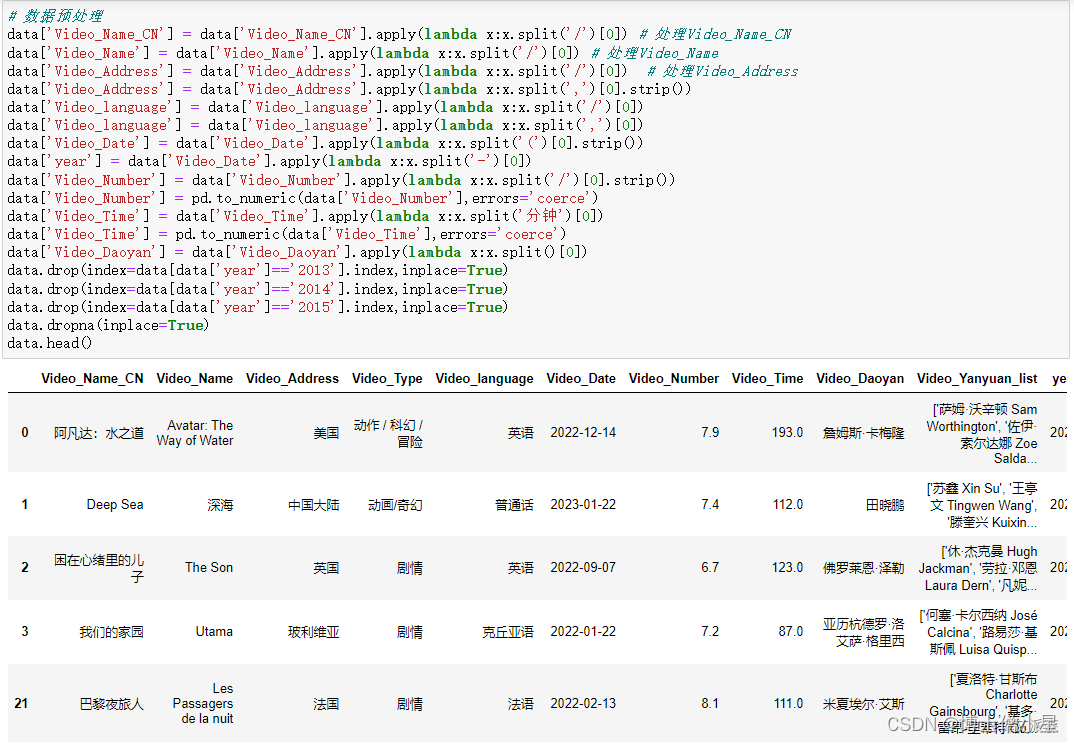
三、数据可视化
1.导入可视化库
本次可视化主要用到matplotlib、seaborn、pyecharts等第三方库
import matplotlib.pylab as plt
import seaborn as sns
from pyecharts.charts import *
from pyecharts.faker import Faker
from pyecharts import options as opts
from pyecharts.globals import ThemeType
plt.rcParams['font.sans-serif'] = ['SimHei'] #解决中文显示
plt.rcParams['axes.unicode_minus'] = False #解决符号无法显示2.分析各个国家发布的电影数量占比
# 分析各个国家发布的电影数量占比
df2 = data.groupby('Video_Address').size().sort_values(ascending=False).head(10)
a1 = Pie(init_opts=opts.InitOpts(theme = ThemeType.LIGHT))
a1.add(series_name='电影数量',data_pair=[list(z) for z in zip(df2.index.tolist(),df2.values.tolist())],radius='70%',)
a1.set_series_opts(tooltip_opts=opts.TooltipOpts(trigger='item'))
a1.render_notebook()3.发布电影数量最高Top5导演
# 发布电影数量最高Top5导演
a2 = Bar(init_opts=opts.InitOpts(theme = ThemeType.DARK))
a2.add_xaxis(data['Video_Daoyan'].value_counts().head().index.tolist())
a2.add_yaxis('电影数量',data['Video_Daoyan'].value_counts().head().values.tolist())
a2.set_series_opts(itemstyle_opts=opts.ItemStyleOpts(color='#B87333'))
a2.set_series_opts(label_opts=opts.LabelOpts(position="top"))
a2.render_notebook()4.分析电影平均评分最高的前十名国家
# 分析电影平均评分最高的前十名国家
data.groupby('Video_Address').mean()['Video_Number'].sort_values(ascending=False).head(10).plot(kind='barh')
plt.show()5.分析哪种语言最受欢迎
# 分析哪种语言最受欢迎
from pyecharts.charts import WordCloud
import collections
result_list = []
for i in data['Video_language'].values:word_list = str(i).split('/')for j in word_list:result_list.append(j)
result_list
word_counts = collections.Counter(result_list)
# 词频统计:获取前100最高频的词
word_counts_top = word_counts.most_common(100)
wc = WordCloud()
wc.add('',word_counts_top)
wc.render_notebook()6.分析哪种类型电影最受欢迎
# 分析哪种类型电影最受欢迎
from pyecharts.charts import WordCloud
import collections
result_list = []
for i in data['Video_Type'].values:word_list = str(i).split('/')for j in word_list:result_list.append(j)
result_list
word_counts = collections.Counter(result_list)
# 词频统计:获取前100最高频的词
word_counts_top = word_counts.most_common(100)
wc = WordCloud()
wc.add('',word_counts_top)
wc.render_notebook()7.分析各种类型电影的比例
# 分析各种类型电影的比例
word_counts_top = word_counts.most_common(10)
a3 = Pie(init_opts=opts.InitOpts(theme = ThemeType.MACARONS))
a3.add(series_name='类型',data_pair=word_counts_top,rosetype='radius',radius='60%',)
a3.set_global_opts(title_opts=opts.TitleOpts(title="各种类型电影的比例",pos_left='center',pos_top=50))
a3.set_series_opts(tooltip_opts=opts.TooltipOpts(trigger='item',formatter='{a} <br/>{b}:{c} ({d}%)'))
a3.render_notebook()8.分析电影片长的分布
# 分析电影片长的分布
sns.displot(data['Video_Time'],kde=True)
plt.show()9.分析片长和评分的关系
# 分析片长和评分的关系
plt.scatter(data['Video_Time'],data['Video_Number'])
plt.title('片长和评分的关系',fontsize=15)
plt.xlabel('片长',fontsize=15)
plt.ylabel('评分',fontsize=15)
plt.show()10.统计 2016 年到至今的产出的电影总数量
# 统计 2016 年到至今的产出的电影总数量
df1 = data.groupby('year').size()
line = Line()
line.add_xaxis(xaxis_data=df1.index.to_list())
line.add_yaxis('',y_axis=df1.values.tolist(),is_smooth = True)
line.set_global_opts(xaxis_opts=opts.AxisOpts(splitline_opts = opts.SplitLineOpts(is_show=True)))
line.render_notebook()四、总结
本次实验通过使用爬虫获取2016年-2023年的电影数据,并可视化分析的得出以下结论:
1.2016年-2019年电影数量逐渐增大,2019年达到最大值,从2020年开始迅速逐年下降。
2.发布电影数量最多的国家是中国和美国。
3.电影类型最多的剧情片。
4.电影片长呈正态分布,且片长和评分呈正相关关系。
相关文章:
人工智能|网络爬虫——用Python爬取电影数据并可视化分析
一、获取数据 1.技术工具 IDE编辑器:vscode 发送请求:requests 解析工具:xpath def Get_Detail(Details_Url):Detail_Url Base_Url Details_UrlOne_Detail requests.get(urlDetail_Url, headersHeaders)One_Detail_Html One_Detail.cont…...

mac苹果笔记本电脑如何强力删除卸载app软件?
苹果电脑怎样删除app?不是把app移到废纸篓就行了吗,十分简单呢! 其实不然,因为在Mac电脑上,删除应用程序只是删除了应用程序的主要组件。大多数时候,系统会有一个相当长的目录,包含所有与应用程…...

net6中使用MongoDB
目录 一、MongoDB是什么? 二、使用步骤 1.安装驱动 2.设置连接字符串、配置类 3.建立实体类 4.服务层 5.在Program添加服务 6.在Controller注入服务 总结 一、MongoDB是什么? MongoDB 是一个开源的、可扩展的、跨平台的、面向文档的非关系型数据库&…...

vue中yarn install超时问题
囚笼中的网络固然可以稳定局势,不让猴子们得以随时醒悟!给你吃的你就好好吃,不要有其他的翻然醒悟的时刻。无论如何,愚蠢的活着也是一种幸福,听着那些耐心寻味的统计幸福指数,我们不由的幸福的一批。。 最…...

vue3 引入 markdown编辑器
参考文档 安装依赖 pnpm install mavon-editor // "mavon-editor": "3.0.1",markdown 编辑器 <mavon-editor></mavon-editor>新增文本 <mavon-editor ref"editorRef" v-model"articleModel.text" codeStyle"…...

算法----K 和数对的最大数目
题目 给你一个整数数组 nums 和一个整数 k 。 每一步操作中,你需要从数组中选出和为 k 的两个整数,并将它们移出数组。 返回你可以对数组执行的最大操作数。 示例 1: 输入:nums [1,2,3,4], k 5 输出:2 解释&…...
RocketMQ-源码架构
源码环境搭建 1、主要功能模块 RocketMQ官方Git仓库地址:GitHub - apache/rocketmq: Apache RocketMQ is a cloud native messaging and streaming platform, making it simple to build event-driven applications. RocketMQ的官方网站下载:下载 | R…...
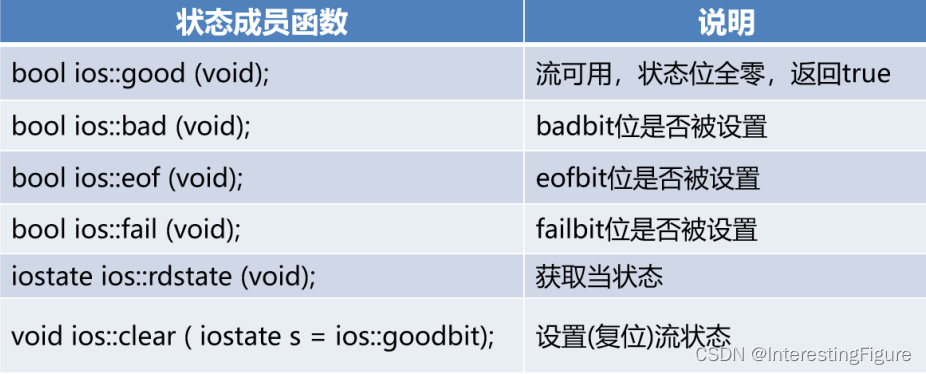
14-1、IO流
14-1、IO流 lO流打开和关闭lO流打开模式lO流对象的状态 非格式化IO二进制IO读取二进制数据获取读长度写入二进制数据 读写指针 和 随机访问设置读/写指针位置获取读/写指针位置 字符串流 lO流打开和关闭 通过构造函数打开I/O流 其中filename表示文件路径,mode表示打…...

每日一道算法题 1
借鉴文章:Java-敏感字段加密 - 哔哩哔哩 题目描述 给定一个由多个命令字组成的命令字符串; 1、字符串长度小于等于127字节,只包含大小写字母,数字,下划线和偶数个双引号 2、命令字之间以一个或多个下划线_进行分割…...

【网络奇缘】- 计算机网络|深入学习物理层|网络安全
🌈个人主页: Aileen_0v0🔥系列专栏: 一见倾心,再见倾城 --- 计算机网络~💫个人格言:"没有罗马,那就自己创造罗马~" 回顾链接:http://t.csdnimg.cn/ZvPOS 这篇文章是关于深入学习原理参考模型-物理层的相关知识点&…...

❀expect命令运用于bash❀
目录 ❀expect命令运用于bash❀ expect使用原理 expet使用场景 常用的expect命令选项 Expect脚本的结尾 常用的expect命令选参数 Expect执行方式 单一分支语法 多分支模式语法第一种 多分支模式语法第二种 在shell 中嵌套expect Shell Here Document(内…...

2023年团体程序设计天梯赛——总决赛题
F-L1-1 最好的文档 有一位软件工程师说过一句很有道理的话:“Good code is its own best documentation.”(好代码本身就是最好的文档)。本题就请你直接在屏幕上输出这句话。 输入格式: 本题没有输入。 输出格式: 在一…...

K8S 工具收集
杂货铺,我不用 K8S,把见过的常用工具放在这里,后面学的时候再来找 名称描述官网Pixie查看 k8s 的工具。集群性能、网络状态、pod 状态、热点图等HomeKubernetes Dashboard基于 Web 的 Kubernetes 集群用户界面。GithubGardenerSAP 开源的 K8…...
自动化测试之读取配置文件
前言: 在日常自动化测试开发工作中,经常要使用配置文件,进行环境配置,或进行数据驱动等。我们常常把这些文件放置在 resources 目录下,然后通过 getResource、ClassLoader.getResource 和 getResourceAsStream() 等方法…...
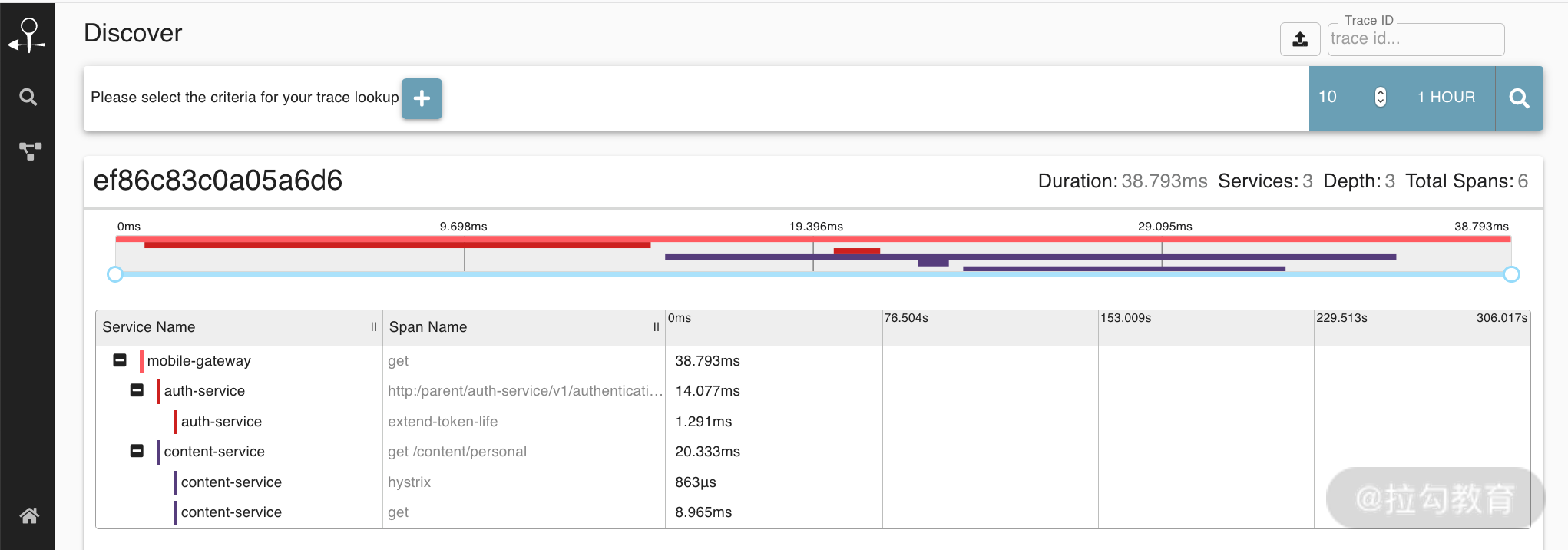
如何实现分布式调用跟踪?
分布式服务拆分以后,系统变得日趋复杂,业务的调用链也越来越长,如何快速定位线上故障,就需要依赖分布式调用跟踪技术。下面我们一起来看下分布式调用链相关的实现。 为什么需要分布式调用跟踪 随着分布式服务架构的流行…...
)
接口的性能优化(从前端、后端、数据库三个角度分析)
接口的性能优化(前端、后端、数据库) 主要通过三方面进行优化 前端后端数据库 前端优化 接口拆分 不要搞一个大而全的接口,要区分核心与非核心的接口,不然核心接口就会被非核心接口拖累 或者一个接口中大部分返回都很快&…...

区块链扩容问题研究【06】
1.Plasma:Plasma 是一种基于以太坊区块链的 Layer2 扩容方案,它通过建立一个分层结构的区块链网络,将大量的交易放到子链上进行处理,从而提高了以太坊的吞吐量。Plasma 还可以通过智能合约实现跨链交易,使得不同的区块…...

英语论文写作常用词汇积累
baseline:比较算法好坏中作为“参照物”而存在,在比较中作为基线;目的是比较提出算法的性能或者用以彰显所提出的算法的优势; benchmark:评价算法好坏的一种规则和标准。是目前的模型能做到的比较好的效果;…...

redis集群(cluster)笔记
1. 定义: 由于数据量过大,单个Master复制集难以承担,因此需要对多个复制集进行集群,形成水平扩展每个复制集只负责存储整个数据集的一部分,这就是Redis的集群,其作用是提供在多个Redis节点间共享数据的程序…...

css 元素前后添加图标(::before 和 ::after 的妙用)
<template><div class"container"><div class"label">猜你喜欢</div></div> </template><style lang"scss" scoped> .label {display: flex;&::before,&::after {content: "";widt…...

3大核心功能解锁QtScrcpy:实现跨平台Android设备高效控制
3大核心功能解锁QtScrcpy:实现跨平台Android设备高效控制 【免费下载链接】QtScrcpy Android real-time display control software 项目地址: https://gitcode.com/GitHub_Trending/qt/QtScrcpy QtScrcpy是一款开源的跨平台Android实时显示与控制工具&#x…...

千问3.5-2B图文对话入门:一张图+一句话提问,实现图像理解、颜色判断、主体定位
千问3.5-2B图文对话入门:一张图一句话提问,实现图像理解、颜色判断、主体定位 1. 认识千问3.5-2B视觉语言模型 千问3.5-2B是Qwen系列中的小型视觉语言模型,它能够同时理解图片内容和自然语言问题。想象一下,你给朋友看一张照片&…...

【CW32无线抄表项目】W25Q+CW32程序示例
资料下载: https://telesky.yuque.com/bdys8w/01/zr02y6vd0r7mnzcl?singleDoc# 参考仓库: https://gitee.com/Armink/SFUD 一、程序分析 硬件总线映射(引脚与时钟的“避坑点”) #define FLASH_SPIx CW_SPI2 // 注意&…...

MogFace-large模型版本管理实践:使用Docker镜像实现环境一致性
MogFace-large模型版本管理实践:使用Docker镜像实现环境一致性 你是不是也遇到过这样的场景?在本地电脑上跑得好好的MogFace-large人脸检测模型,一放到同事的机器或者服务器上,就各种报错:CUDA版本不对、Python包冲突…...

FK-Onmyoji:阴阳师终极自动化护肝助手完整使用指南
FK-Onmyoji:阴阳师终极自动化护肝助手完整使用指南 【免费下载链接】FK-Onmyoji 阴阳师抗检测多功能脚本 项目地址: https://gitcode.com/gh_mirrors/fk/FK-Onmyoji 阴阳师玩家们,是否厌倦了重复枯燥的日常任务?FK-Onmyoji为您带来革命…...

Spring Boot 远程调试终于来了!IntelliJ IDEA 新版支持「无 Agent」远程调试
推荐阅读 IDEA 官宣全新AI CLI:Gemini大模型免费用! IDEA 2026.1 EAP 4 发布:新特性太丝滑了! IDEA 官宣:终于可以爽用Cursor了! IDEA 这个骚操作,连 VS Code 都跟不上! IDEA 这个测试接口的好工具,效率 提升 10x 这些 IDEA 技巧没用上,你可能少了一大半摸…...

3个场景驱动策略:如何让Citra模拟器在你的硬件上火力全开
3个场景驱动策略:如何让Citra模拟器在你的硬件上火力全开 【免费下载链接】citra A Nintendo 3DS Emulator 项目地址: https://gitcode.com/gh_mirrors/cit/citra 作为一款开源的任天堂3DS模拟器,Citra让无数经典游戏在PC上重获新生。但要让这款高…...

从零搭建一个病虫害识别系统:我用Albumentations和SE注意力,把YOLOv8的mAP提升了3%
从零搭建病虫害识别系统:Albumentations与SE注意力如何让YOLOv8性能突破瓶颈 田间作物叶片上若隐若现的霉斑、果实表面微小的虫卵——这些农业病虫害的早期特征,往往只有经验丰富的农艺师才能敏锐捕捉。而现在,一套搭载改进版YOLOv8的智能识别…...

BEAST 2 终极指南:如何快速掌握贝叶斯分子进化分析工具
BEAST 2 终极指南:如何快速掌握贝叶斯分子进化分析工具 【免费下载链接】beast2 Bayesian Evolutionary Analysis by Sampling Trees 项目地址: https://gitcode.com/gh_mirrors/be/beast2 BEAST 2(Bayesian Evolutionary Analysis by Sampling T…...

快速SEO排名服务需要多长时间见效_快速SEO排名服务有哪些常见的手段
快速SEO排名服务需要多长时间见效 在当今数字化时代,网站的在线可见度对于企业的成功至关重要。快速SEO排名服务应运而生,旨在帮助企业尽快在搜索引擎上获得更好的排名,从而提高流量和业务。但是,很多人都会疑惑,快速…...