Qwen系列之Qwen3解读:最强开源模型的细节拆解
文章目录
- 1.1分钟快览
- 2.模型架构
- 2.1.Dense模型
- 2.2.MoE模型
- 3.预训练阶段
- 3.1.数据
- 3.2.训练
- 3.3.评估
- 4.后训练阶段
- S1: 长链思维冷启动
- S2: 推理强化学习
- S3: 思考模式融合
- S4: 通用强化学习
- 5.全家桶中的小模型训练
- 评估
- 评估数据集
- 评估细节
- 评估效果
- 弱智评估和民间Arena
- 分析
- 展望
如果有格式或者想查看更多内容,可以访问:Qwen系列之Qwen3解读:最强开源模型的细节拆解查看详情
1.1分钟快览
Qwen3发了什么?
- 发布了密集型和专家混合(Mixture-of-Experts, MoE)模型,参数数量从 0.6 亿到 235 亿不等,以满足不同下游应用的需求。
- 将两种不同的运行模式——思考模式和非思考模式——整合到单一模型中。这允许用户在这些模式之间切换。集成了思考预算机制,为用户提供了对模型在任务执行过程中推理长度的细粒度控制。
训练里面的核心亮点是什么?
训练过程:
- 三阶段预训练:36T的token训练:先30T的4096长度的通用训练,再5T的4096推理训练带衰减学习率,最后是千亿长文本32768训练。
- 后训练:前两个阶段主要增强推理能力,后两个阶段做拒绝采样和强化学习,增强通用能力
- S1: Long-Cot冷启动:qwq32b造数据,qwen72B + 人工洗数据。
- S2: 推理强化学习:选用无leak的多样性的难度适中的4k数据跑GRPO。
- S3: 思考模式融合SFT:通过一个specitoken,在prompt加/think和/no_think标志,然后训练。混合着也学会了自动的短cot模式,很神奇。
- S4: 通用强化学习:涵盖20多种不同任务,每个任务都有定制的评分标准,规则+模型(有无参考答案)。
- 蒸馏到小模型:logits蒸馏非数据蒸馏,效果更好。
2.模型架构
6个Dense模型:Qwen3-0.6B、Qwen3-1.7B、Qwen3-4B、Qwen3-8B、Qwen3-14B 和 Qwen3-32B
2个MoE 模型:Qwen3-30B-A3B 和 Qwen3-235B-A22B。
2.1.Dense模型
- Grouped Query Attention (GQA, Ainslie et al., 2023)
- SwiGLU (Dauphin et al., 2017)
- Rotary Positional Embeddings (RoPE, Su et al., 2024)
- RMSNorm (Jiang et al., 2023) with pre-normalization.
- 移除了Qwen2中使用的 QKV 偏置,并在注意力机制中引入了 QK-Norm,以确保 Qwen3 的稳定训练;
- 模型使用 Qwen的分词器(Bai 等人,2023),该分词器实现Byte-level byte-pair encoding(BBPE,Brown 等人,2020;Wang 等人,2020;Sennrich 等人,2016),词汇量为 151,669。

2.2.MoE模型
- 与Qwen3 Dense模型共享相同的基本架构,参考Qwen2.5-MoE并实现细粒度专家分割(fine-grained expert segmentation)(Dai 等人,2024)。Qwen3 MoE 模型共有 128 个专家,每个 token 激活 8 个专家。
- 与 Qwen2.5-MoE 不同,Qwen3-MoE设计没有使用共享专家。我们采用全局批处理负载均衡损失(lobal-batch load balancing loss)(Qiu 等人,2025)来鼓励专家专业化。这些架构和训练创新在下游任务中显著提升了模型性能。关于负载均衡损失可以参考两篇文章:关于 MoE 大模型负载均衡策略演进的回顾:坑点与经验教训 和 阿里云通义大模型新技术:MoE模型训练专家平衡的关键细节

3.预训练阶段
3.1.数据
Qwen3 模型都在一个包含 119 种语言和方言的大型多样化数据集上进行训练,总共有 36 万亿个 token。这个数据集包括包括编码、STEM(科学、技术、工程和数学)、推理任务、书籍、多语言文本和合成数据等各个领域的高质量内容。
值得注意的是用Qwen2.5-VL从大量 PDF 文档中提取文本,识别出的文本随后通过 Qwen2.5 模型(Yang 等人,2024b)进行优化,以提升其质量。我们还使用领域特定模型生成合成数据:Qwen2.5-Math用于数学内容,Qwen2.5-Coder用于代码相关数据。
3.2.训练
Qwen3模型通过三个阶段进行预训练:
(1) 一般阶段 (S1):在第一个预训练阶段,所有Qwen3模型在超过30万亿个标记上进行训练,序列长度为4,096个标记。在此阶段,模型已在语言能力和一般世界知识上完成全面预训练,训练数据覆盖119种语言和方言。
(2) 推理阶段 (S2):为了进一步提高推理能力,我们通过增加STEM、编码、推理和合成数据的比例来优化这一阶段的预训练语料库。模型在序列长度为4,096个标记的情况下,进一步预训练了约5T的高质量标记。我们还加快了这一阶段的学习率衰减。
(3) 长文本阶段(S3):在最终的预训练阶段,我们收集高质量的长文本语料库,以扩展Qwen3模型的上下文长度。所有模型在数千亿个标记上进行预训练,序列长度为32,768个标记。长文本语料库包括75%的文本长度在16,384到32,768 token,25%的文本长度在4,096到16,384 token。跟Qwen2.5相同,使用ABF技术(Xiong等,2023)将RoPE的基础频率从10,000提高到1,000,000。同时,引入YARN(Peng等,2023)和双块注意力(DCA,An等,2024),以推理过程中将序列长度能力提升四倍。
与Qwen2.5(Yang等,2024b)类似,我们基于上述三个预训练阶段开发了最佳超参数(例如,学习率调度和批量大小)预测的缩放法则。通过广泛的实验,我们系统地研究了模型架构、训练数据、训练阶段与最佳训练超参数之间的关系。最后,我们为每个密集模型或MoE模型设定了预测的最佳学习率和批量大小策略。
3.3.评估
- General Tasks:
- MMLU (Hendrycks et al., 2021a) (5-shot),
- MMLU-Pro (Wang et al., 2024) (5-shot, CoT),
- MMLU-redux (Gema et al., 2024) (5-shot),
- BBH (Suzgun et al., 2023) (3-shot, CoT),
- SuperGPQA (Du et al., 2025)(5-shot, CoT).
- Math & STEM Tasks:
- GPQA (Rein et al., 2023) (5-shot, CoT),
- GSM8K (Cobbe et al., 2021) (4-shot,CoT),
- MATH (Hendrycks et al., 2021b) (4-shot, CoT).
- Coding Tasks:
- EvalPlus (Liu et al., 2023a) (0-shot) (Average of HumanEval (Chen et al., 2021),
- MBPP (Austin et al., 2021),
- Humaneval+, MBPP+) (Liu et al., 2023a),
- MultiPL-E (Cassano et al.,2023) (0-shot) (Python, C++, JAVA, PHP, TypeScript, C#, Bash, JavaScript),
- MBPP-3shot (Austin et al., 2021), CRUX-O of CRUXEval (1-shot) (Gu et al., 2024).
- Multilingual Tasks:
- MGSM (Shi et al., 2023) (8-shot, CoT),
- MMMLU (OpenAI, 2024) (5-shot),
- INCLUDE (Romanou et al., 2024) (5-shot)
评估结论:
- 与先前开源的密集和 MoE 基础模型(如 DeepSeekV3 Base、Llama-4-Maverick Base 和 Qwen2.5-72B-Base)相比,Qwen3-235B-A22B-Base 在大多数任务中表现优于这些模型,且参数总数或激活参数显著更少。
- 对于 Qwen3 MoE 基础模型,我们的实验结果表明:
- 使用相同的预训练数据,Qwen3 MoE 基础模型仅需 1/5 的激活参数即可达到与 Qwen3 密集基础模型相似的性能。
- 由于 Qwen3 MoE 架构的改进、训练 token 规模的扩大以及更先进的训练策略,Qwen3 MoE 基础模型可以用不到 1/2 的激活参数和更少的总参数超越 Qwen2.5 MoE 基础模型。
- 即使只有 Qwen2.5 密集基础模型 1/10 的激活参数,Qwen3 MoE 基础模型也能达到相当的性能,这为我们的推理和训练成本带来了显著优势。
- Qwen3 Dense 基础模型的整体性能在更高参数规模下与 Qwen2.5 基础模型相当。例如,Qwen3-1.7B/4B/8B/14B/32B-Base 分别达到了与 Qwen2.5-3B/7B/14B/32B/72B-Base 相当的性能。特别是在 STEM、编程和推理基准测试中,Qwen3 密集基础模型在更高参数规模下的性能甚至超越了 Qwen2.5 基础模型。
详细评估结果见原文。
4.后训练阶段

S1: 长链思维冷启动
我们首先整理一个涵盖广泛类别的综合数据集,包括数学、代码、逻辑推理和一般STEM(STEM:即科学、技术、工程和数学)问题。数据集中的每个问题都配有经过验证的参考答案或基于代码的测试用例。
数据过滤:
- 数据集构建涉及严格的两阶段过滤过程:query过滤和answer过滤。
- query过滤:我们使用Qwen2.5-72B-Instruct识别并移除那些不易验证的query,这包含多个子问题的query或要求生成一般文本的query。
- answer过滤:我们过滤掉那些Qwen2.5-72B-Instruct能够在不使用链式推理的情况下正确回答的query。这有助于防止模型进行浅显的推演,确保仅包含需要更深入推理的复杂问题。
- 我们使用Qwen2.5-72B-Instruct对每个query的domain(领域)进行标注,以保持数据domain(领域)表示的平衡。
数据处理:
在保留验证query集后,我们使用QwQ-32B为每个query生成N个候选answer。如果QwQ-32B无法生成正确答案时,人工评估员会手动评估answer的准确性。对于N个候选存在正确结果的query,进一步严格的过滤标准被应用,以去除以下answer:
- 产生错误的最终答案;
- 包含明显重复;
- 存在明显猜测,但是缺乏足够的推理;
- 思考与最终的summary内容之间不一致;
- 存在不当的语言混合(language mixing )或风格转变(stylistic shifts);
- 跟验证集很像的数据;
随后,经过精心挑选的精炼数据集子集用于推理模式的初始冷启动训练。此阶段的目标是向模型灌输基础推理模式,而不过分强调即时推理性能。这种方法确保模型的潜力不受限制,从而在随后的强化学习(RL)阶段提供更大的灵活性和改进。为了有效实现这一目标,最好在这一准备阶段尽量减少训练样本和训练步骤。
这里的N是多少?训练数据是多少?文中没提~
S2: 推理强化学习
在推理强化学习阶段使用的 query-verifier对必须满足以下四个标准:
- 在冷启动阶段未被使用;
- 对于冷启动模型是可学习的;
- 尽可能具有挑战性;
- 涵盖广泛的子领域。
我们最终收集了总共3,995个 query-verifier对,并采用GRPO(Shao等,2024)来更新模型参数。我们观察到,使用较大的batch size,增加对每个query的rollouts次数,以及off-policy训练以提高样本效率,对训练过程是有益的。我们还解决了如何通过控制模型的熵来平衡探索与利用,以实现稳步增加或保持不变。
感觉这里面的细节挺多的: 如何定义对冷启模型是可学习的?如何定义是有挑战的?
S3: 思考模式融合
思维模式融合阶段的目标是将“非思维”能力整合到先前开发的“思维”模型中。这种方法使开发者能够管理和控制推理行为,同时降低了为思维和非思维任务部署单独模型的成本和复杂性。为此,我们对推理强化学习模型进行持续的监督微调,并设计一个chat模板以融合这两种模式。此外,我们发现能够熟练处理这两种模式的模型在不同的思维预算下表现始终良好。
SFT数据的构建:SFT数据集结合了“思考”和“非思考”数据。为了确保第二阶段模型的性能不受额外SFT的影响,“思考”数据是通过对第一阶段的query并使用第二阶段模型进行拒绝采样生成的。“非思考”数据则经过精心设计,涵盖包括编码、数学、遵循指令、多语言任务、创意写作、问答和角色扮演多样化的任务。此外,我们使用自动生成的checklist来评估“非思考”数据的answer质量。为了提高低资源语言任务的表现,我们特别增加了翻译任务的比例。
这里也有提到,使用了checklist的方案来评估"非思考"类数据的质量,这个是我们在问答场景做过比较详细实验的一种方案,确实很有效。
聊天模板设计:为了更好地整合这两种模式并使用户能够动态切换模型的思维过程,我们为Qwen3设计了聊天模板,如下图所示。具体而言,对于思维模式和非思维模式的样本,我们在用户query或系统消息中分别引入</think>和</no_think>标志。这使得模型能够根据用户的输入选择相应的思维模式。对于非思维模式样本,我们在助手的answer中保留一个空的思维块。该设计确保了模型内部格式的一致性,并允许开发者通过在聊天模板中连接一个空的思维块来防止模型进行思考行为。默认情况下,模型在思维模式下运行,另外,我们添加了一些用户query不包含</think>标志的思维模式训练样本。对于更复杂的多轮对话,我们随机在用户的query中插入多个</think>和</no_think>标志,模型的answer遵循最后遇到的标志。

思维预算:思维模式融合的一个额外优势是,一旦模型学会在非思维和思维模式下answer,它自然会发展出处理中间情况的能力——基于不完整思维生成answer。这一能力为实施对模型思维过程的预算控制奠定了基础。具体而言,当模型的思维长度达到用户定义的阈值时,我们手动停止思维过程并插入停止思维指令:“Considering the limited time by the user, I have to give the solution based on the thinking directly now.\n\</think>.\n\n” 插入此指令后,模型继续生成基于其到该时刻为止的累积推理的最终answer。值得注意的是,这一能力并不是通过明确训练获得的,而是作为应用思维模式融合的结果自然出现的。具体的,从产品形态(chat.qwen.ai)上如下图,达到字数后就插入上述指令后终止思考,开始summary部分生成。从最终结果上看,随着长度调大,效果是越来越好的,详见后文的分析章节。
S4: 通用强化学习
通用强化学习阶段旨在广泛增强模型在多种场景下的能力和稳定性。为此,我们建立了一个复杂的奖励系统,涵盖20多种不同任务,每个任务都有定制的评分标准。这些任务特别针对以下核心能力的提升:
-
指令遵循:该能力确保模型准确解读并遵循用户指令,包括与内容、格式、长度和结构化输出相关的要求,提供符合用户期望的answer。
-
格式遵循:除了明确的指令外,我们期望模型遵循特定的格式约定。例如,它应在思考和非思考模式中适当地使用
/think和/no_think标志,并始终使用指定的标记(例如,<think>和</think>)来分隔最终输出中的思考和answer部分。 -
偏好对齐:对于开放式query,偏好对齐侧重于提高模型的帮助性(helpfulness)、参与度(engagement)和风格(style),最终提供更自然和令人满意的用户体验。
-
Agent能力:这涉及训练模型通过指定接口正确调用工具。在强化学习rollout时,需要模型能够进行完整的多轮交互,并获得真实环境执行反馈,从而提高其在长期决策任务(long-horizon decision-making tasks)中的表现和稳定性。
-
特殊场景的能力:在更专业的场景中,我们设计了针对特定上下文的任务。例如,在检索增强生成(RAG)任务中,我们引入奖励信号,我们结合奖励信号引导模型生成准确且符合上下文的response,从而降低幻觉风险。
rag场景的特殊奖励防止幻觉,具体怎么做的?这里没展开说~
为了为上述任务提供反馈,我们利用了三种不同类型的奖励:
- 基于规则的奖励:基于规则的奖励在推理强化学习阶段被广泛使用,并且对一般任务如遵循指令(Lambert等,2024)和格式遵循也很有用。设计良好的基于规则的奖励可以高精度地评估模型输出的正确性,防止reward hacking等问题。
- 有参考答案情况下基于模型的奖励:在这种方法中,我们为每个query提供一个参考答案,并提示Qwen2.5-72B-Instruct根据该参考答案对模型的answer进行评分。这种方法允许更灵活地处理多样化的任务,而无需严格的格式,从而避免了纯规则奖励可能出现的假阴性。
- 无参考答案情况下基于模型的奖励:利用人类偏好数据,我们训练一个奖励模型,为模型answer分配标量分数。这种不依赖于参考答案的方法可以处理更广泛的query,同时有效提升模型的参与度和帮助性。
蜗牛说:
这里的实现细节还挺多的。
有参考答案情况下基于模型的奖励,其实说白了就是用Qwen2.5写个prompt进行评估,是经典的LLM-as-judger的方法。但是其实LLM-as-judger的维度可能是多样的,不同任务可能都有至少一个甚至多个评估维度,20个任务那评估的体系是一个很复杂的系统,构建这样的verifier系统是基于RL的后训练优化的关键。
无参考答案情况下,只用了reward model进行打分。
5.全家桶中的小模型训练
从强到弱的蒸馏流程专门设计用于优化轻量级模型,包括5个密集模型(Qwen3-0.6B、1.7B、4B、8B和14B)和一个MoE模型(Qwen3-30B-A3B)。这种方法在有效传授强大的模式切换能力的同时,提升了模型性能。蒸馏过程分为两个主要阶段:
(1) 离线蒸馏:在这个阶段,教师模型在 /think 和 /no_think 两种模式下进行answer生成,并进行蒸馏。这有助于轻量级学生模型发展基本的推理能力和在不同思维模式之间切换的能力,为下一阶段的在线训练奠定坚实基础。
(2) 在线蒸馏:在这个阶段,学生模型生成on policy序列进行微调。prompt随机情况下,学生模型选择在 /think 或 /no_think 模式下生成answer。然后,通过将其logits与教师模型(Qwen3-32B或Qwen3-235B-A22B)的logits对齐,微调学生模型以最小化KL散度。
通过蒸馏的方式,带来了更好的即时性能,如更高的 Pass@1 分数所示,同时也提升了模型的探索能力,体现在 Pass@64 结果的改善上。
对于较小的模型,我们利用大型模型的on-policy和off-policy方式,使用从强到弱的蒸馏方法来增强其能力。从比较强的teacher模型进行蒸馏,在性能和训练效率方面显著优于强化学习。这个结论在R1以及Qwen等多个大模型的技术报告中被多次证实了。
评估
评估数据集
通用任务:
- MMLU-Redux (Gema et al., 2024),
- GPQA-Diamond (Rein et al., 2023), sample 10 times for each query and report the averaged accuracy.
- C-Eval (Huang et al., 2023),
- LiveBench (2024-11-25) (White et al.,2024).
对齐任务:
- 指令遵循:IFEval (Zhou et al., 2023).
- 通用话题:Arena-Hard (Li et al., 2024) and AlignBench v1.1 (Liu et al., 2023b).
- 写作/创作任务:Creative Writing V3 (Paech, 2024) and WritingBench (Wu et al., 2025)
数学与文本推理:
- 数学:MATH-500 (Lightman et al., 2023), AIME’24 and AIME’25(AIME, 2025)。对于 AIME 问题,每年的问题包括第一部分和第二部分,共计 30 道题。对于每道题,我们采样 64 次,并取平均准确率作为最终得分。(没记错的话,AIME这里的方式跟R1里面的评估方法一致)
- 文本推理:ZebraLogic (Lin et al., 2025) and AutoLogi(Zhu et al., 2025).
- 智能体与编程:
- BFCLv3 (Yan et al., 2024), 对于 BFCL,所有 Qwen3 模型均使用 FC 格式进行评估,并使用 yarn 将模型部署到 64k 的上下文长度进行多轮评估。部分基线来自 BFCL 排行榜,取 FC 格式和 Prompt 格式的较高分数。对于排行榜上未报告的模型,则评估 Prompt 格式。
- LiveCodeBench (v5, 2024.10-2025.02) (Jain et al., 2024), 对于 LiveCodeBench,在非思考模式下,我们使用官方推荐的提示词,而在思考模式下,我们调整提示词模板以允许模型更自由地思考,通过移除“You will not return anything
except for the program.”的限制。 - Codeforces Ratings from CodeElo (Quan et al., 2025). 为评估模型与竞赛编程专家之间的性能差距,我们使用 CodeForces 计算 Elo 评分。在我们的基准测试中,每个问题通过生成最多8个推理尝试来解决。
多语言任务
- 指令遵循:Multi-IF (He et al., 2024), 该任务专注于 8 种关键语言。
- 知识评估:分为两种类型: regional knowledg通过INCLUDE (Romanou et al.,2024)进行评估,涵盖 44 种语言;通用知识使用 MMMLU(OpenAI,2024)进行评估,涵盖 14 种语言,不包括未优化的约鲁巴语。对于这两个基准,我们仅采样原始数据的 10%以提高评估效率。
- 数学任务: MT-AIME2024 (Son et al., 2025),涵盖 55 种语言。 PolyMath (Wang et al.,2025),包含 18 种语言。
- 逻辑推理: MlogiQA 进行评估,涵盖 10 种语言。
评估细节
- 思考模式:我们采用采样温度 0.6、top-p 值 0.95 和 top-k 值 20。此外,对于 Creative Writing v3 和 WritingBench,我们应用存在惩罚 1.5 以鼓励生成更多多样化的内容。
- 非思考模式:我们配置采样超参数为温度=0.7、top-p=0.8、top-k=20 和presence penalty=1.5。
- 对于思考模式和非思考模式,我们将最大输出长度设置为 32,768 个 token。但 AIME’24 和 AIME’25 除外,我们将此长度扩展至 38,912 个 token 以提供足够的思考空间。
评估效果
关键结论:
- 我们的旗舰模型 Qwen3-235B-A22B 在思考和非性思维模式下均表现出开源模型中的顶尖整体性能,超越了 DeepSeek-R1 和 DeepSeek-V3 等强基线模型。Qwen3-235B-A22B 在与 OpenAI-o1、Gemini2.5-Pro 和 GPT-4o 等闭源领先模型相比中也极具竞争力,展示了其深刻的推理能力和全面的通用能力。
- 我们的旗舰密集模型 Qwen3-32B 在大多数基准测试中超越了我们之前最强的推理模型 QwQ-32B,并且性能与闭源的 OpenAI-o3mini 相当,表明其具有令人信服的推理能力。Qwen3-32B 在非性思维模式下也表现出色,超越了我们之前旗舰的非推理密集模型 Qwen2.5-72B-Instruct。
- 我们的轻量级模型,包括 Qwen3-30B-A3B、Qwen3-14B 以及其他更小的密集模型,在参数数量相近或更大的开源模型中始终表现出更优越的性能,证明了我们强到弱蒸馏方法的成功。

Qwen3跟R1比起来,整体上是comparable,或者说是略强的。Gemini2.5-pro整体上还是比较强的,呈碾压态势。
弱智评估和民间Arena
挺有意思~
参考:阿里通义千问 Qwen3 系列模型正式发布,该模型有哪些技术点?
分析
思考预算的有效性
为验证 Qwen3 能否通过增加思考预算来提升其智能水平,我们在数学、编程和 STEM 领域的四个基准测试中调整了分配的思考预算。Qwen3 表现出与分配的思考预算相关的可扩展且平滑的性能提升。

蒸馏的有效性和效率
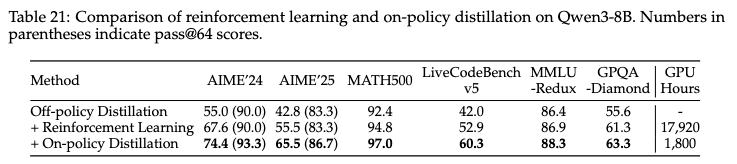
- 蒸馏比强化学习显著地实现了更好的性能,同时只需要大约 1/10 的 GPU 小时。
- 从教师 logits 进行蒸馏使学生模型能够扩展其探索空间并增强其推理潜力,这一点通过蒸馏后 AIME’24 和 AIME’25 基准测试中 pass@64 分数的提高与初始检查点相比得到证明。相比之下,强化学习并未导致 pass@64 分数的任何提高。这些观察结果突出了利用更强的教师模型指导学生模型学习的优势。
思考模式融合和通用强化学习的影响
为了评估在训练后使用思考模式融合和通用强化学习(RL)的有效性,我们对 Qwen-32B 模型的各个阶段进行评估。除了之前提到的数据集外,我们还引入了几个内部基准来监控其他能力。这些基准包括:
- CounterFactQA:包含反事实问题,模型需要识别这些问题并非事实,并避免生成幻觉性答案。
- LengthCtrl:包括有长度要求的创意写作任务;最终得分基于生成内容长度与目标长度的差异。
- ThinkFollow:涉及多轮对话,随机插入/think 和/no think 标志,以测试模型能否根据用户查询正确切换思考模式。
- ToolUse:评估模型在单轮、多轮和多步工具调用过程中的稳定性。分数包括工具调用过程中意图识别的准确性、格式准确性和参数准确性。
结论:
- 第三阶段将非思考模式整合进模型,该模型在前两个阶段的训练后已具备思考能力。ThinkFollow 基准测试分数为 88.7 表明,模型已初步发展了在不同模式间切换的能力,尽管偶尔仍会出错。第三阶段还增强了模型在思考模式下的泛化能力和指令跟随能力,CounterFactQA 提升了 10.9 分,LengthCtrl 提升了 8.0 分。
- 第四阶段进一步增强了模型在思考和非思考模式下的通用能力、指令跟随能力和代理能力。值得注意的是,ThinkFollow 分数提升至 98.9,确保了模式的准确切换。
- 对于知识、STEM、数学和编程任务,思维模式融合和通用强化学习并没有带来显著改进。相反,对于 AIME’24 和 LiveCodeBench 等具有挑战性的任务,思维模式下的性能在这些两个训练阶段后实际上会下降。我们推测这种退化是由于模型在更广泛的通用任务上进行了训练,这可能削弱了其处理复杂问题的专业能力。在 Qwen3 的开发过程中,我们选择接受这种性能权衡,以增强模型的整体通用性。

展望
在不久的将来,我们的研究将集中在几个关键领域。
- 我们将继续通过使用质量和内容多样性更高的数据来扩大预训练规模。同时,我们将致力于改进模型架构和训练方法,以实现有效压缩、扩展到极长上下文等目标。
- 我们计划增加强化学习的计算资源,特别关注从环境反馈中学习的基于智能体的 RL 系统。这将使我们能够构建能够处理需要推理时间扩展的复杂任务的智能体。

相关文章:
Qwen系列之Qwen3解读:最强开源模型的细节拆解
文章目录 1.1分钟快览2.模型架构2.1.Dense模型2.2.MoE模型 3.预训练阶段3.1.数据3.2.训练3.3.评估 4.后训练阶段S1: 长链思维冷启动S2: 推理强化学习S3: 思考模式融合S4: 通用强化学习 5.全家桶中的小模型训练评估评估数据集评估细节评估效果弱智评估和民间Arena 分析展望 如果…...

虚幻基础:角色旋转
能帮到你的话,就给个赞吧 😘 文章目录 移动组件使用控制器所需旋转:组件 使用 控制器旋转将旋转朝向运动:组件 使用 移动方向旋转 控制器旋转和移动旋转 缺点移动旋转:必须移动才能旋转,不移动不旋转控制器…...

RushDB开源程序 是现代应用程序和 AI 的即时数据库。建立在 Neo4j 之上
一、软件介绍 文末提供程序和源码下载 RushDB 改变了您处理图形数据的方式 — 不需要 Schema,不需要复杂的查询,只需推送数据即可。 二、Key Features ✨ 主要特点 Instant Setup: Be productive in seconds, not days 即时设置 :在几秒钟…...

StarRocks 全面向量化执行引擎深度解析
StarRocks 全面向量化执行引擎深度解析 StarRocks 的向量化执行引擎是其高性能的核心设计,相比传统行式处理引擎(如MySQL),性能可提升 5-10倍。以下是分层拆解: 1. 向量化 vs 传统行式处理 维度行式处理向量化处理数…...

SQL进阶之旅 Day 22:批处理与游标优化
【SQL进阶之旅 Day 22】批处理与游标优化 文章简述(300字左右) 在数据库开发中,面对大量数据的处理任务时,单条SQL语句往往无法满足性能需求。本篇文章聚焦“批处理与游标优化”,深入探讨如何通过批量操作和游标技术提…...

深度解析云存储:概念、架构与应用实践
在数据爆炸式增长的时代,传统本地存储因容量限制、管理复杂等问题,已难以满足企业和个人的需求。云存储凭借灵活扩展、便捷访问等特性,成为数据存储领域的主流解决方案。从个人照片备份到企业核心数据管理,云存储正重塑数据存储与…...
)
stm32进入Infinite_Loop原因(因为有系统中断函数未自定义实现)
这是系统中断服务程序的默认处理汇编函数,如果我们没有定义实现某个中断函数,那么当stm32产生了该中断时,就会默认跑这里来了,所以我们打开了什么中断,一定要记得实现对应的系统中断函数,否则会进来一直循环…...

C++ 类基础:封装、继承、多态与多线程模板实现
前言 C 是一门强大的面向对象编程语言,而类(Class)作为其核心特性之一,是理解和使用 C 的关键。本文将深入探讨 C 类的基本特性,包括封装、继承和多态,同时讨论类中的权限控制,并展示如何使用类…...
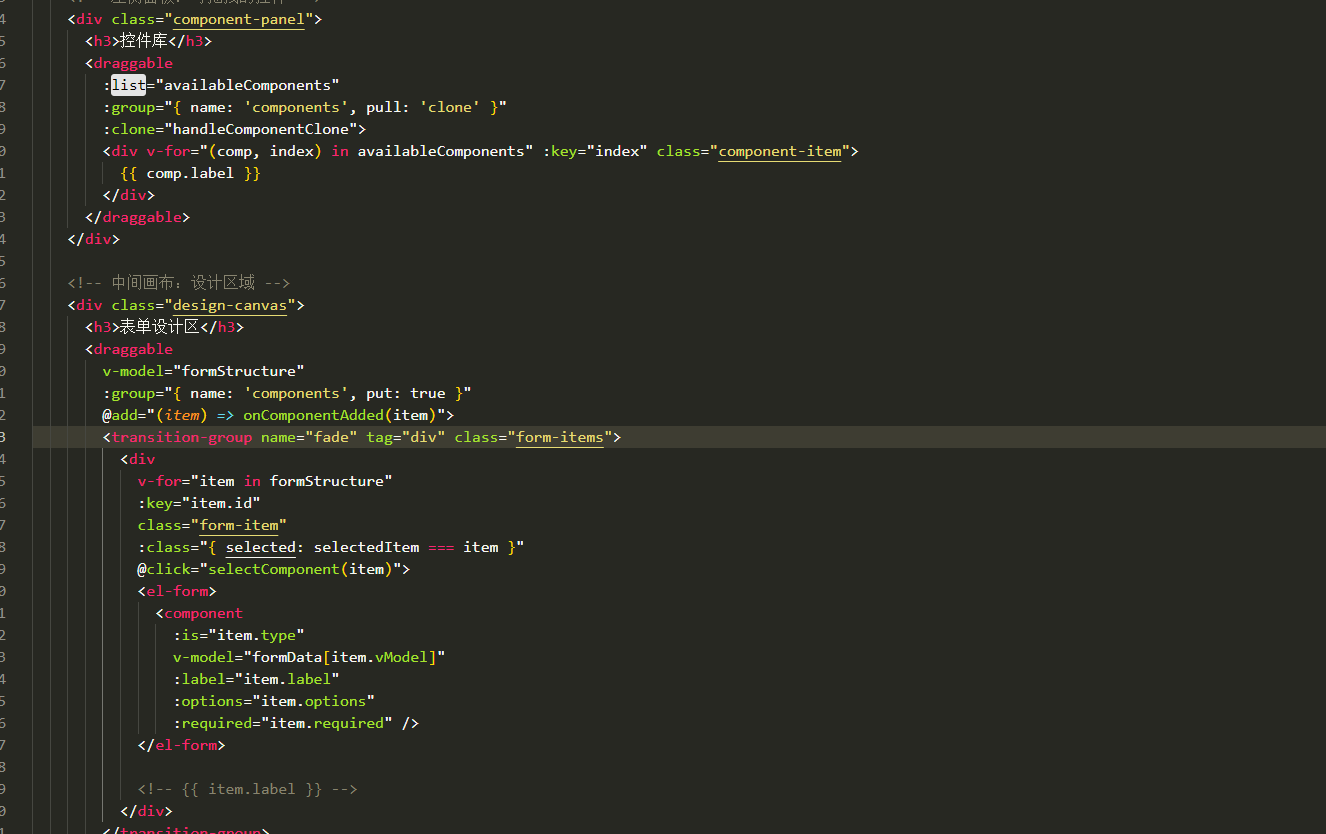
表单设计器拖拽对象时添加属性
背景:因为项目需要。自写设计器。遇到的坑在此记录 使用的拖拽组件时vuedraggable。下面放上局部示例截图。 坑1。draggable标签在拖拽时可以获取到被拖拽的对象属性定义 要使用 :clone, 而不是clone。我想应该是因为draggable标签比较特。另外在使用**:clone时要将…...

简单介绍C++中 string与wstring
在C中,string和wstring是两种用于处理不同字符编码的字符串类型,分别基于char和wchar_t字符类型。以下是它们的详细说明和对比: 1. 基础定义 string 类型:std::string 字符类型:char(通常为8位)…...

CSS 工具对比:UnoCSS vs Tailwind CSS,谁是你的菜?
在现代前端开发中,Utility-First (功能优先) CSS 框架已经成为主流。其中,Tailwind CSS 无疑是市场的领导者和标杆。然而,一个名为 UnoCSS 的新星正以其惊人的性能和极致的灵活性迅速崛起。 这篇文章将深入探讨这两款工具的核心理念、技术差…...

Yii2项目自动向GitLab上报Bug
Yii2 项目自动上报Bug 原理 yii2在程序报错时, 会执行指定action, 通过重写ErrorAction, 实现Bug自动提交至GitLab的issue 步骤 配置SiteController中的actions方法 public function actions(){return [error > [class > app\helpers\web\ErrorAction,],];}重写Error…...
)
背包问题双雄:01 背包与完全背包详解(Java 实现)
一、背包问题概述 背包问题是动态规划领域的经典问题,其核心在于如何在有限容量的背包中选择物品,使得总价值最大化。根据物品选择规则的不同,主要分为两类: 01 背包:每件物品最多选 1 次(选或不选&#…...

Python第七周作业
Python第七周作业 文章目录 Python第七周作业 1.使用open以只读模式打开文件data.txt,并逐行打印内容 2.使用pathlib模块获取当前脚本的绝对路径,并创建logs目录(若不存在) 3.递归遍历目录data,输出所有.csv文件的路径…...

Qt的学习(二)
1. 创建Hello Word 两种方式,实现helloworld: 1.通过图形化的方式,在界面上创建出一个控件,显示helloworld 2.通过纯代码的方式,通过编写代码,在界面上创建控件, 显示hello world; …...

算法刷题-回溯
今天给大家分享的还是一道关于dfs回溯的问题,对于这类问题大家还是要多刷和总结,总体难度还是偏大。 对于回溯问题有几个关键点: 1.首先对于这类回溯可以节点可以随机选择的问题,要做mian函数中循环调用dfs(i&#x…...
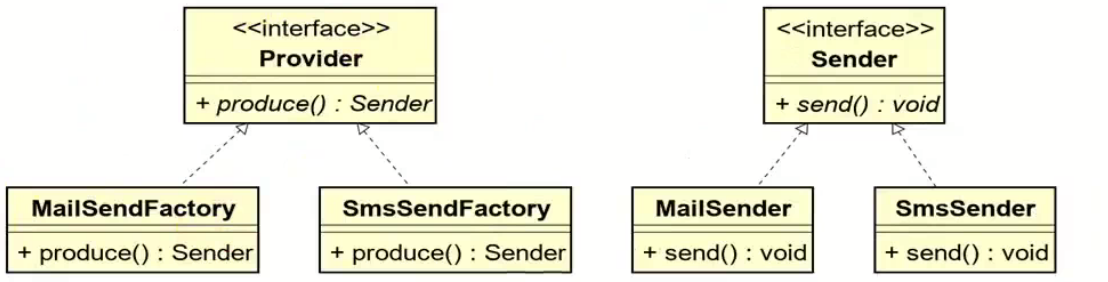
工厂方法模式和抽象工厂方法模式的battle
1.案例直接上手 在这个案例里面,我们会实现这个普通的工厂方法,并且对比这个普通工厂方法和我们直接创建对象的差别在哪里,为什么需要一个工厂: 下面的这个是我们的这个案例里面涉及到的接口和对应的实现类: 两个发…...

深入解析 ReentrantLock:原理、公平锁与非公平锁的较量
ReentrantLock 是 Java 中 java.util.concurrent.locks 包下的一个重要类,用于实现线程同步,支持可重入性,并且可以选择公平锁或非公平锁的实现方式。下面将详细介绍 ReentrantLock 的实现原理以及公平锁和非公平锁的区别。 ReentrantLock 实现原理 基本架构 ReentrantLo…...
鸿蒙Navigation路由导航-基本使用介绍
1. Navigation介绍 Navigation组件是路由导航的根视图容器,一般作为Page页面的根容器使用,其内部默认包含了标题栏、内容区和工具栏,其中内容区默认首页显示导航内容(Navigation的子组件)或非首页显示(Nav…...

JavaScript 标签加载
目录 JavaScript 标签加载script 标签的 async 和 defer 属性,分别代表什么,有什么区别1. 普通 script 标签2. async 属性3. defer 属性4. type"module"5. 各种加载方式的对比6. 使用建议 JavaScript 标签加载 script 标签的 async 和 defer …...

「Java基本语法」变量的使用
变量定义 变量是程序中存储数据的容器,用于保存可变的数据值。在Java中,变量必须先声明后使用,声明时需指定变量的数据类型和变量名。 语法 数据类型 变量名 [ 初始值]; 示例:声明与初始化 public class VariableDemo {publi…...
CMS内容管理系统的设计与实现:多站点模式的实现
在一套内容管理系统中,其实有很多站点,比如企业门户网站,产品手册,知识帮助手册等,因此会需要多个站点,甚至PC、mobile、ipad各有一个站点。 每个站点关联的有站点所在目录及所属的域名。 一、站点表设计…...

用鸿蒙HarmonyOS5实现国际象棋小游戏的过程
下面是一个基于鸿蒙OS (HarmonyOS) 的国际象棋小游戏的完整实现代码,使用Java语言和鸿蒙的Ability框架。 1. 项目结构 /src/main/java/com/example/chess/├── MainAbilitySlice.java // 主界面逻辑├── ChessView.java // 游戏视图和逻辑├── …...
ZYNQ学习记录FPGA(二)Verilog语言
一、Verilog简介 1.1 HDL(Hardware Description language) 在解释HDL之前,先来了解一下数字系统设计的流程:逻辑设计 -> 电路实现 -> 系统验证。 逻辑设计又称前端,在这个过程中就需要用到HDL,正文…...

k8s从入门到放弃之Pod的容器探针检测
k8s从入门到放弃之Pod的容器探针检测 在Kubernetes(简称K8s)中,容器探测是指kubelet对容器执行定期诊断的过程,以确保容器中的应用程序处于预期的状态。这些探测是保障应用健康和高可用性的重要机制。Kubernetes提供了两种种类型…...
:电商转化率优化与网站性能的底层逻辑)
精益数据分析(98/126):电商转化率优化与网站性能的底层逻辑
精益数据分析(98/126):电商转化率优化与网站性能的底层逻辑 在电子商务领域,转化率与网站性能是决定商业成败的核心指标。今天,我们将深入解析不同类型电商平台的转化率基准,探讨页面加载速度对用户行为的…...
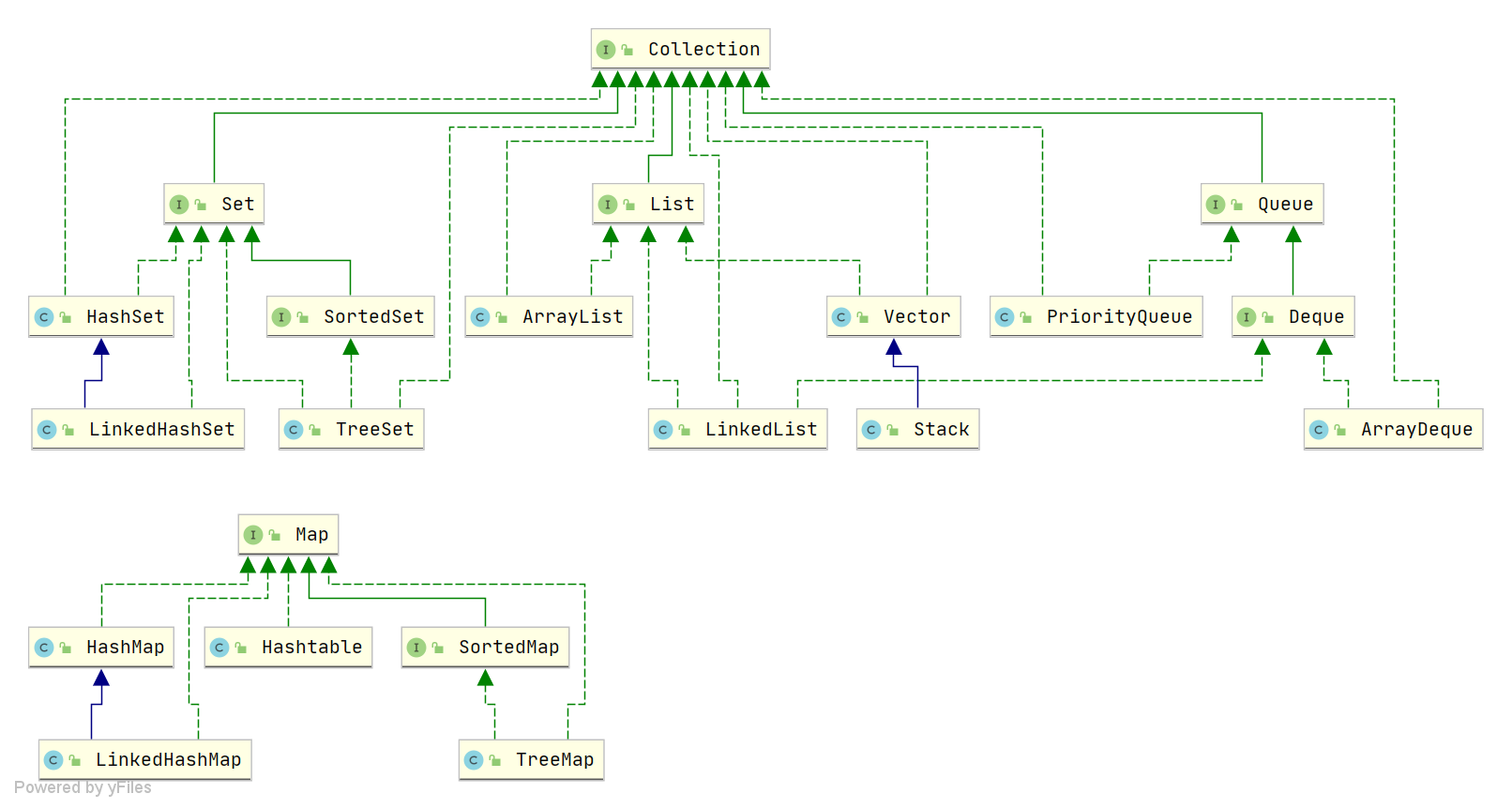
Java中HashMap底层原理深度解析:从数据结构到红黑树优化
一、HashMap概述与核心特性 HashMap作为Java集合框架中最常用的数据结构之一,是基于哈希表的Map接口非同步实现。它允许使用null键和null值(但只能有一个null键),并且不保证映射顺序的恒久不变。与Hashtable相比,Hash…...
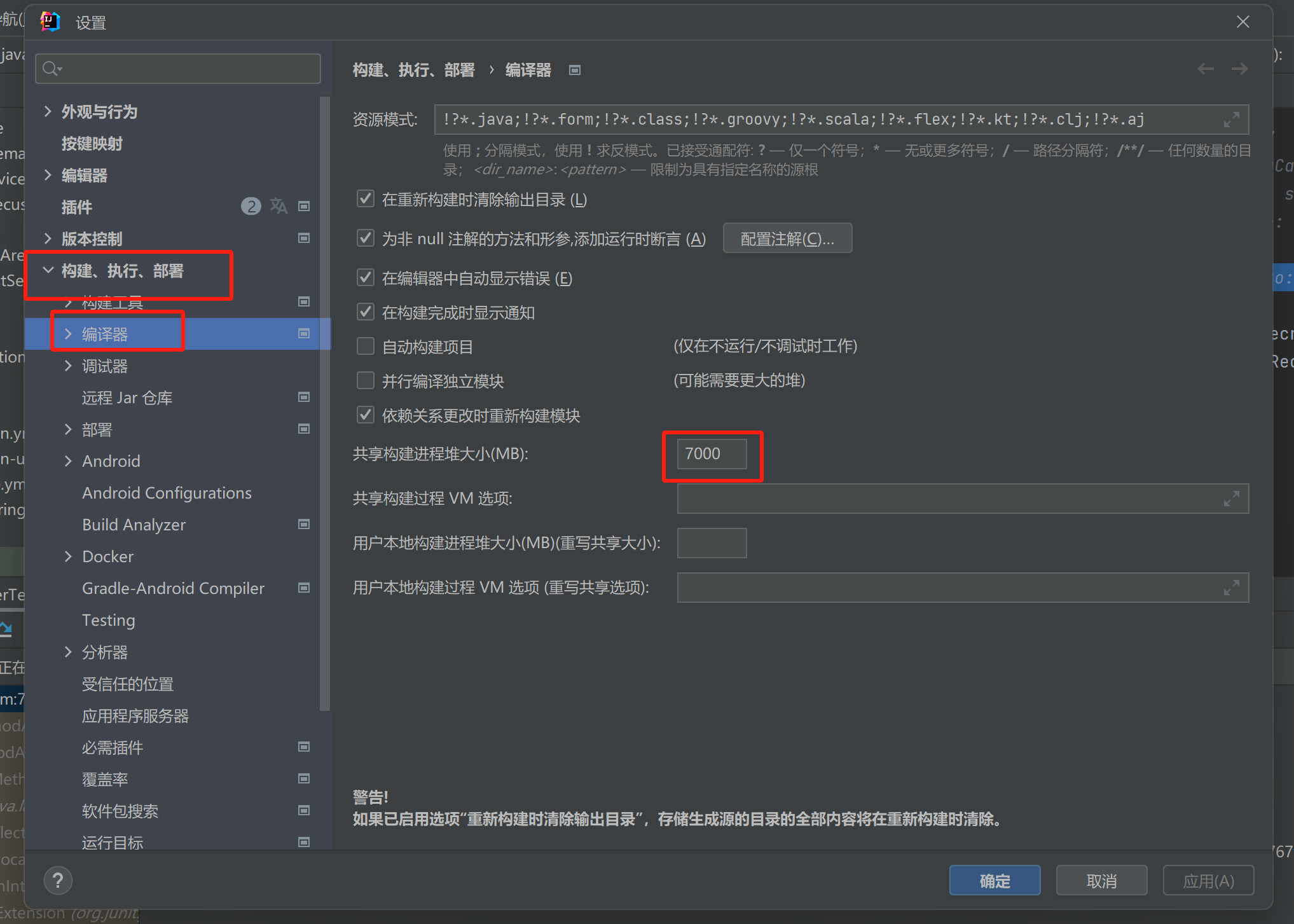
【记录坑点问题】IDEA运行:maven-resources-production:XX: OOM: Java heap space
问题:IDEA出现maven-resources-production:operation-service: java.lang.OutOfMemoryError: Java heap space 解决方案:将编译的堆内存增加一点 位置:设置setting-》构建菜单build-》编译器Complier...
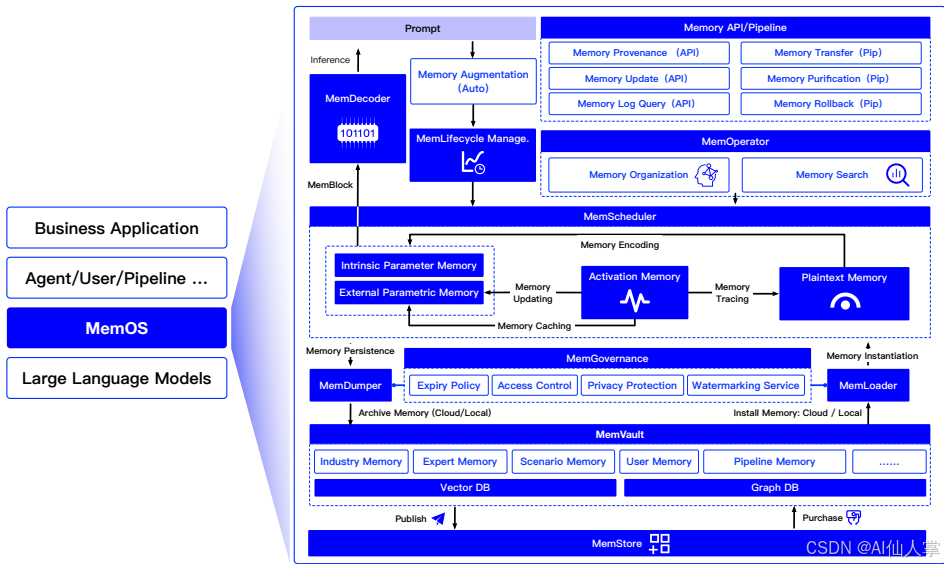
【阅读笔记】MemOS: 大语言模型内存增强生成操作系统
核心速览 研究背景 研究问题:这篇文章要解决的问题是当前大型语言模型(LLMs)在处理内存方面的局限性。LLMs虽然在语言感知和生成方面表现出色,但缺乏统一的、结构化的内存架构。现有的方法如检索增强生成(RA…...

Java中栈的多种实现类详解
Java中栈的多种实现类详解:Stack、LinkedList与ArrayDeque全方位对比 前言一、Stack类——Java最早的栈实现1.1 Stack类简介1.2 常用方法1.3 优缺点分析 二、LinkedList类——灵活的双端链表2.1 LinkedList类简介2.2 常用方法2.3 优缺点分析 三、ArrayDeque类——高…...