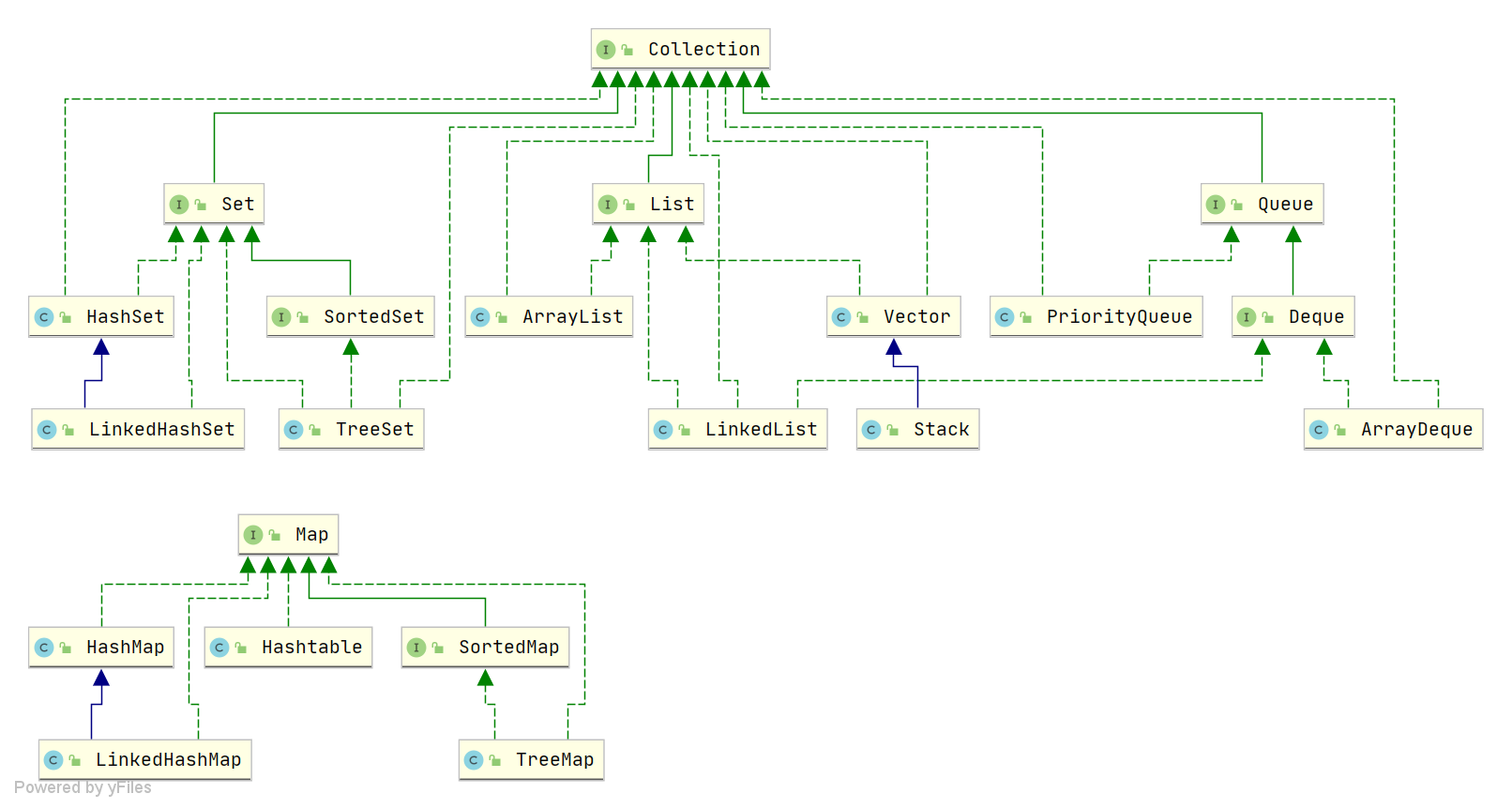
Java中HashMap底层原理深度解析:从数据结构到红黑树优化
一、HashMap概述与核心特性
HashMap作为Java集合框架中最常用的数据结构之一,是基于哈希表的Map接口非同步实现。它允许使用null键和null值(但只能有一个null键),并且不保证映射顺序的恒久不变。与Hashtable相比,HashMap是非线程安全的,这意味着在多线程环境下需要额外同步措施,但也因此获得了更高的性能。
核心特性总结:
- 键值对存储结构,实现快速存取(平均时间复杂度O(1))
- 允许null键/值(Hashtable不允许)
- 非同步(线程不安全)
- 不保证顺序(与LinkedHashMap对比)
- 初始容量16,负载因子0.75(经验值)
二、底层数据结构演进
JDK1.7及之前:数组+链表
在JDK1.7及之前版本中,HashMap采用经典的"数组+链表"结构,每个数组元素称为一个"桶"(bucket),桶内是Entry对象的链表。Entry包含四个关键字段:
static class Entry<K,V> implements Map.Entry<K,V> {final K key;V value;Entry<K,V> next; // 链表指针int hash; // 缓存hash值
}当发生哈希冲突时,新的Entry会以头插法插入链表(即新元素放在链表头部),这导致多线程扩容时可能产生循环链表问题。
JDK1.8及之后:数组+链表+红黑树
JDK1.8进行了重大优化,数据结构变为"数组+链表+红黑树"。主要改进包括:
- 链表转红黑树:当链表长度≥8且数组长度≥64时,链表转为红黑树,查找时间从O(n)优化到O(log n)
- 尾插法替代头插法:解决多线程扩容死循环问题
- TreeNode节点:红黑树专用节点,继承自Node类
static final class TreeNode<K,V> extends LinkedHashMap.Entry<K,V> {TreeNode<K,V> parent; // 红黑树父节点TreeNode<K,V> left; // 左子树TreeNode<K,V> right; // 右子树TreeNode<K,V> prev; // 前驱节点(仍保留链表特性)boolean red; // 颜色标记
}三、核心方法实现原理
1. hash()方法:扰动函数
HashMap通过扰动函数减少哈希碰撞:
static final int hash(Object key) {int h;return (key == null) ? 0 : (h = key.hashCode()) ^ (h >>> 16);
}设计精妙之处:
- 高16位与低16位异或:充分利用高低位信息
- 与(length-1)做与运算:保证索引在数组范围内
2. put()方法流程详解
put操作是HashMap最核心的方法,其执行流程如下:
- 计算哈希值:调用hash()方法获取key的哈希值
- 确定桶位置:通过
(n-1) & hash计算数组下标 - 处理碰撞:
- 无碰撞:直接创建新节点放入桶中
- 链表碰撞:遍历链表,存在相同key则更新value;否则尾插新节点
- 树节点碰撞:调用红黑树的插入方法
- 扩容检查:size超过阈值(容量×负载因子)时进行resize
JDK1.8 putVal()方法关键代码片段:
final V putVal(int hash, K key, V value, boolean onlyIfAbsent,boolean evict) {Node<K,V>[] tab; Node<K,V> p; int n, i;// 首次使用初始化tableif ((tab = table) == null || (n = tab.length) == 0)n = (tab = resize()).length;// 计算索引位置并处理空桶情况if ((p = tab[i = (n - 1) & hash]) == null)tab[i] = newNode(hash, key, value, null);else {// 处理哈希碰撞...}++modCount;// 检查扩容if (++size > threshold)resize();return null;
}3. get()方法工作原理
get操作相对简单,主要步骤为:
- 计算key的hash值
- 确定桶位置
(n-1) & hash - 检查第一个节点是否匹配
- 若不匹配:
- 链表:顺序遍历查找
- 红黑树:调用树查找方法
4. resize()扩容机制
HashMap扩容是性能关键点,默认扩容为原容量2倍:
- 新建2倍大小的数组
- 重新计算所有元素位置(高效处理:只需看新增的bit是0还是1)
- 链表拆分:保持原顺序或移动到"原索引+旧容量"位置
- 树拆分:可能退化为链表(节点数≤6时)
扩容触发条件:
- size > threshold (capacity * loadFactor)
- 链表长度≥8但数组长度<64(优先扩容而非树化)
四、线程安全问题与替代方案
虽然HashMap性能优异,但在多线程环境下存在以下问题:
- 数据丢失:多线程put时可能覆盖写入
- 死循环:JDK1.7扩容时头插法导致(1.8已修复)
- 不一致问题:迭代过程中结构被修改
解决方案:
- 使用
Collections.synchronizedMap包装 - 使用
ConcurrentHashMap(推荐)
- JDK1.7:分段锁
- JDK1.8:CAS+synchronized优化
五、性能优化实践建议
根据HashMap原理,给出以下优化建议:
-
合理设置初始容量:减少扩容次数
// 预估存储100个元素,负载因子0.75 Map<String, Object> map = new HashMap<>(128); -
优化hashCode()实现:
- 减少哈希碰撞
- 保证一致性(对象相等则hashCode必须相等)
- 避免频繁变化
3.考虑使用专用集合:
- 需要有序:LinkedHashMap
- 并发场景:ConcurrentHashMap
- 排序需求:TreeMap
六、经典面试题解析
1. 为什么链表长度超过8转为红黑树?
这是基于统计学和空间时间权衡的结果:
- 链表长度达到8的概率极低(哈希函数良好时)
- 红黑树占用更多内存
- 查询时间复杂度从O(n)降到O(log n)
2. HashMap为什么长度总是2的幂次方?
这样设计有两个好处:
- 高效取模运算:
(n-1) & hash替代hash % n - 扩容时元素位置计算优化:只需判断新增bit是0还是1
3. 为什么重写equals()必须重写hashCode()?
这是Java对象契约的要求:
- 两个对象equals相等,则hashCode必须相等
- 否则会导致HashMap等集合无法正确工作
4.hashmap的默认长度是多少?
HashMap的默认长度(初始容量)是16。这个值在Java的HashMap实现中被定义为常量DEFAULT_INITIAL_CAPACITY,具体值为1 << 4(即2的4次方)。
关键点说明:
- 默认容量16是经过精心设计的,采用2的幂次方形式,这样可以利用位运算
(n-1) & hash高效计算元素位置 - 与默认负载因子0.75配合使用,当元素数量超过12(16×0.75)时会触发扩容
- 即使指定了初始容量,HashMap也会自动调整为大于等于该值的最小2的幂次方(如指定50会调整为64)
七、总结
HashMap作为Java集合框架的经典实现,其设计思想体现了数据结构与算法的精妙结合。从JDK1.7到1.8的演进,展示了Java团队对性能优化的不懈追求。理解其底层原理不仅有助于正确使用,更能提升我们的程序设计能力。
关键点回顾:
- 数据结构:数组+链表+红黑树(JDK1.8+)
- 哈希计算:扰动函数减少碰撞
- 扩容机制:2倍扩容,重新分布元素
- 线程安全:需额外同步措施
- 性能优化:合理初始化,优化hashCode
相关文章:
Java中HashMap底层原理深度解析:从数据结构到红黑树优化
一、HashMap概述与核心特性 HashMap作为Java集合框架中最常用的数据结构之一,是基于哈希表的Map接口非同步实现。它允许使用null键和null值(但只能有一个null键),并且不保证映射顺序的恒久不变。与Hashtable相比,Hash…...
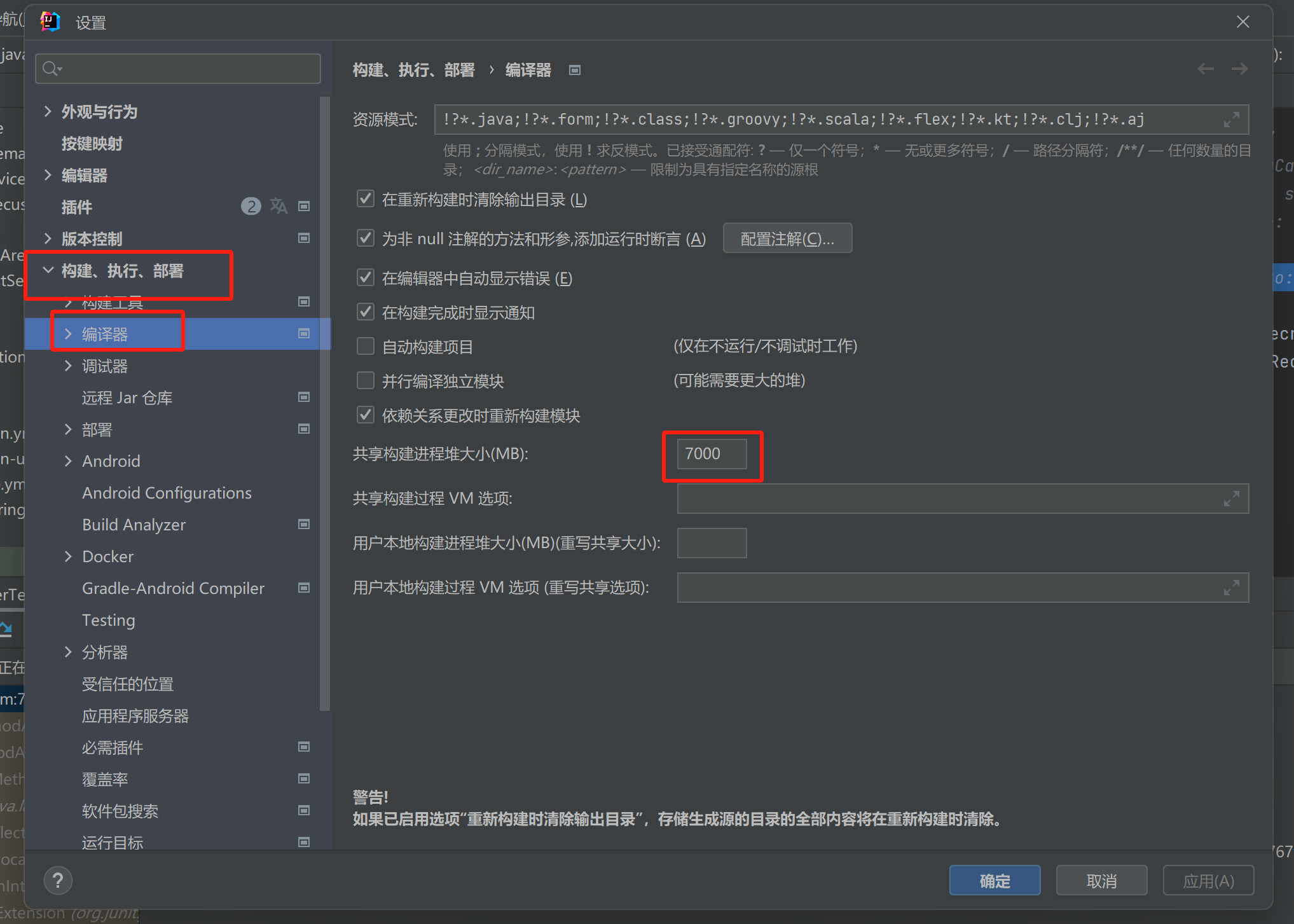
【记录坑点问题】IDEA运行:maven-resources-production:XX: OOM: Java heap space
问题:IDEA出现maven-resources-production:operation-service: java.lang.OutOfMemoryError: Java heap space 解决方案:将编译的堆内存增加一点 位置:设置setting-》构建菜单build-》编译器Complier...
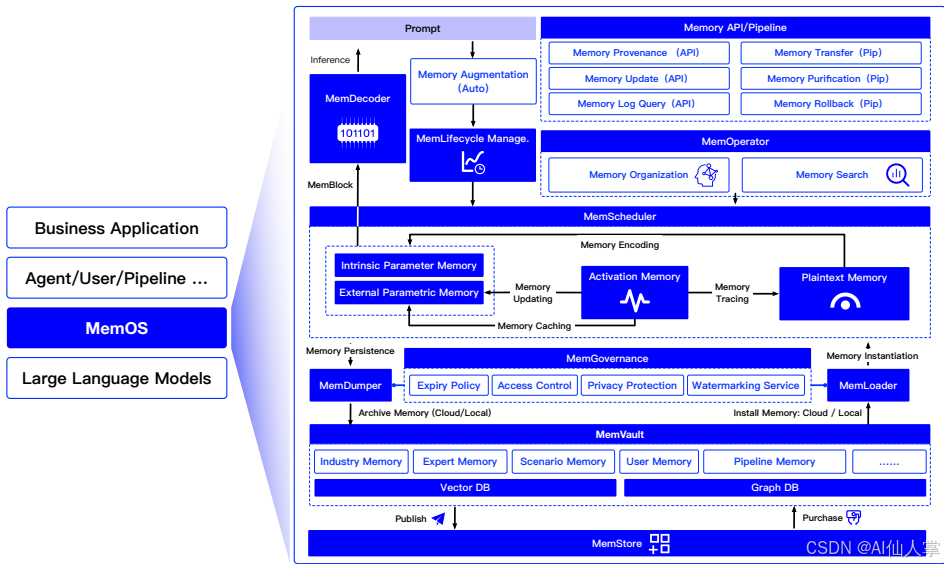
【阅读笔记】MemOS: 大语言模型内存增强生成操作系统
核心速览 研究背景 研究问题:这篇文章要解决的问题是当前大型语言模型(LLMs)在处理内存方面的局限性。LLMs虽然在语言感知和生成方面表现出色,但缺乏统一的、结构化的内存架构。现有的方法如检索增强生成(RA…...

Java中栈的多种实现类详解
Java中栈的多种实现类详解:Stack、LinkedList与ArrayDeque全方位对比 前言一、Stack类——Java最早的栈实现1.1 Stack类简介1.2 常用方法1.3 优缺点分析 二、LinkedList类——灵活的双端链表2.1 LinkedList类简介2.2 常用方法2.3 优缺点分析 三、ArrayDeque类——高…...

6.计算机网络核心知识点精要手册
计算机网络核心知识点精要手册 1.协议基础篇 网络协议三要素 语法:数据与控制信息的结构或格式,如同语言中的语法规则语义:控制信息的具体含义和响应方式,规定通信双方"说什么"同步:事件执行的顺序与时序…...

基于Uniapp的HarmonyOS 5.0体育应用开发攻略
一、技术架构设计 1.混合开发框架选型 (1)使用Uniapp 3.8版本支持ArkTS编译 (2)通过uni-harmony插件调用原生能力 (3)分层架构设计: graph TDA[UI层] -->|Vue语法| B(Uniapp框架)B --&g…...
【笔记】AI Agent 项目 SUNA 部署 之 Docker 构建记录
#工作记录 构建过程记录 Microsoft Windows [Version 10.0.27871.1000] (c) Microsoft Corporation. All rights reserved.(suna-py3.12) F:\PythonProjects\suna>python setup.py --admin███████╗██╗ ██╗███╗ ██╗ █████╗ ██╔════╝…...
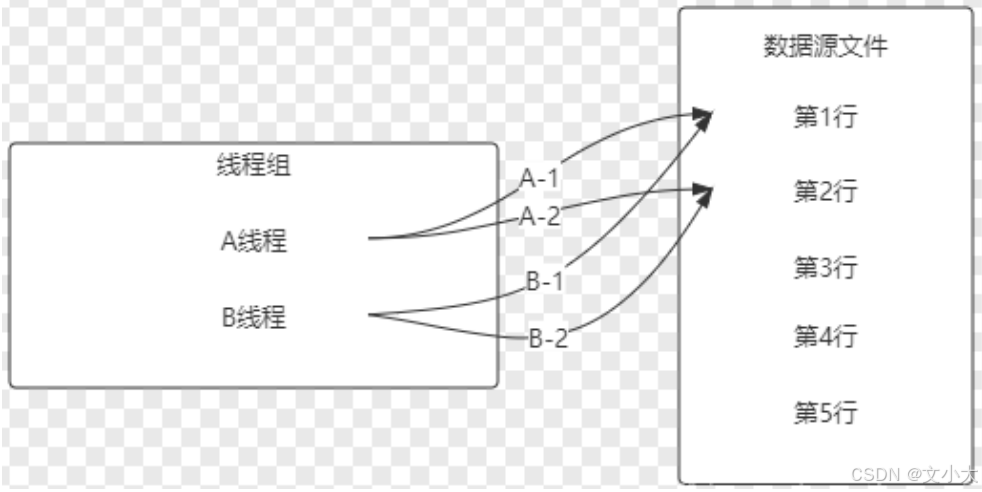
五、jmeter脚本参数化
目录 1、脚本参数化 1.1 用户定义的变量 1.1.1 添加及引用方式 1.1.2 测试得出用户定义变量的特点 1.2 用户参数 1.2.1 概念 1.2.2 位置不同效果不同 1.2.3、用户参数的勾选框 - 每次迭代更新一次 总结用户定义的变量、用户参数 1.3 csv数据文件参数化 1、脚本参数化 …...
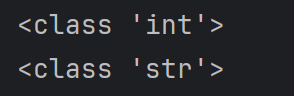
python基础语法Ⅰ
python基础语法Ⅰ 常量和表达式变量是什么变量的语法1.定义变量使用变量 变量的类型1.整数2.浮点数(小数)3.字符串4.布尔5.其他 动态类型特征注释注释是什么注释的语法1.行注释2.文档字符串 注释的规范 常量和表达式 我们可以把python当作一个计算器,来进行一些算术…...
C++11 constexpr和字面类型:从入门到精通
文章目录 引言一、constexpr的基本概念与使用1.1 constexpr的定义与作用1.2 constexpr变量1.3 constexpr函数1.4 constexpr在类构造函数中的应用1.5 constexpr的优势 二、字面类型的基本概念与使用2.1 字面类型的定义与作用2.2 字面类型的应用场景2.2.1 常量定义2.2.2 模板参数…...

EEG-fNIRS联合成像在跨频率耦合研究中的创新应用
摘要 神经影像技术对医学科学产生了深远的影响,推动了许多神经系统疾病研究的进展并改善了其诊断方法。在此背景下,基于神经血管耦合现象的多模态神经影像方法,通过融合各自优势来提供有关大脑皮层神经活动的互补信息。在这里,本研…...

python打卡day49@浙大疏锦行
知识点回顾: 通道注意力模块复习空间注意力模块CBAM的定义 作业:尝试对今天的模型检查参数数目,并用tensorboard查看训练过程 一、通道注意力模块复习 & CBAM实现 import torch import torch.nn as nnclass CBAM(nn.Module):def __init__…...

Qt Quick Controls模块功能及架构
Qt Quick Controls是Qt Quick的一个附加模块,提供了一套用于构建完整用户界面的UI控件。在Qt 6.0中,这个模块经历了重大重构和改进。 一、主要功能和特点 1. 架构重构 完全重写了底层架构,与Qt Quick更紧密集成 移除了对Qt Widgets的依赖&…...

手动给中文分词和 直接用神经网络RNN做有什么区别
手动分词和基于神经网络(如 RNN)的自动分词在原理、实现方式和效果上有显著差异,以下是核心对比: 1. 实现原理对比 对比维度手动分词(规则 / 词典驱动)神经网络 RNN 分词(数据驱动)…...
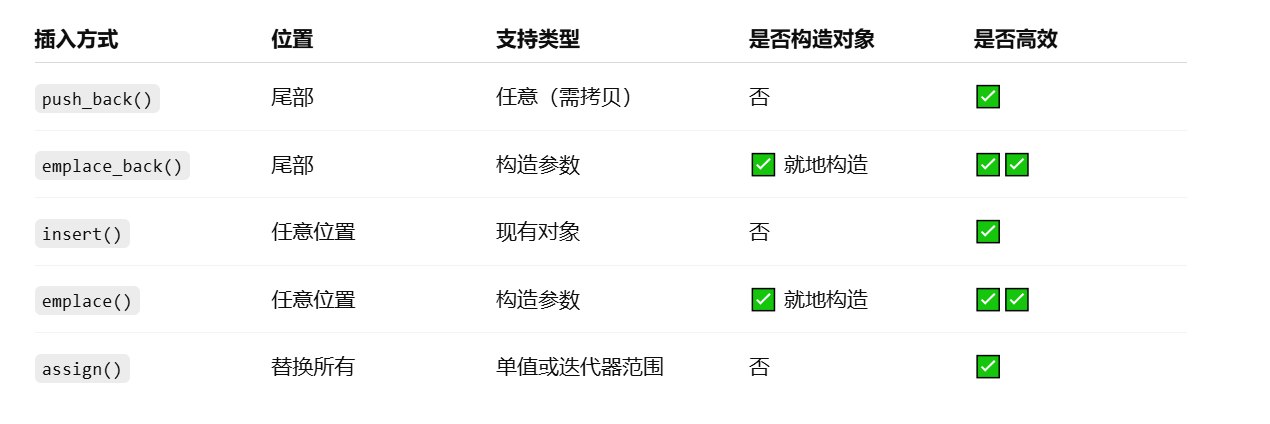
C++中vector类型的介绍和使用
文章目录 一、vector 类型的简介1.1 基本介绍1.2 常见用法示例1.3 常见成员函数简表 二、vector 数据的插入2.1 push_back() —— 在尾部插入一个元素2.2 emplace_back() —— 在尾部“就地”构造对象2.3 insert() —— 在任意位置插入一个或多个元素2.4 emplace() —— 在任意…...

计算机系统结构复习-名词解释2
1.定向:在某条指令产生计算结果之前,其他指令并不真正立即需要该计算结果,如果能够将该计算结果从其产生的地方直接送到其他指令中需要它的地方,那么就可以避免停顿。 2.多级存储层次:由若干个采用不同实现技术的存储…...

HTML中各种标签的作用
一、HTML文件主要标签结构及说明 1. <!DOCTYPE html> 作用:声明文档类型,告知浏览器这是 HTML5 文档。 必须:是。 2. <html lang“zh”>. </html> 作用:包裹整个网页内容,lang"z…...

CVE-2023-25194源码分析与漏洞复现(Kafka JNDI注入)
漏洞概述 漏洞名称:Apache Kafka Connect JNDI注入导致的远程代码执行漏洞 CVE编号:CVE-2023-25194 CVSS评分:8.8 影响版本:Apache Kafka 2.3.0 - 3.3.2 修复版本:≥ 3.4.0 漏洞类型:反序列化导致的远程代…...
——统计抽样学习笔记(考试用))
统计学(第8版)——统计抽样学习笔记(考试用)
一、统计抽样的核心内容与问题 研究内容 从总体中科学抽取样本的方法利用样本数据推断总体特征(均值、比率、总量)控制抽样误差与非抽样误差 解决的核心问题 在成本约束下,用少量样本准确推断总体特征量化估计结果的可靠性(置…...
Copilot for Xcode (iOS的 AI辅助编程)
Copilot for Xcode 简介Copilot下载与安装 体验环境要求下载最新的安装包安装登录系统权限设置 AI辅助编程生成注释代码补全简单需求代码生成辅助编程行间代码生成注释联想 代码生成 总结 简介 尝试使用了Copilot,它能根据上下文补全代码,快速生成常用…...
Axure零基础跟我学:展开与收回
亲爱的小伙伴,如有帮助请订阅专栏!跟着老师每课一练,系统学习Axure交互设计课程! Axure产品经理精品视频课https://edu.csdn.net/course/detail/40420 课程主题:Axure菜单展开与收回 课程视频:...

Docker、Wsl 打包迁移环境
电脑需要开启wsl2 可以使用wsl -v 查看当前的版本 wsl -v WSL 版本: 2.2.4.0 内核版本: 5.15.153.1-2 WSLg 版本: 1.0.61 MSRDC 版本: 1.2.5326 Direct3D 版本: 1.611.1-81528511 DXCore 版本: 10.0.2609…...
RabbitMQ 各类交换机
为什么要用交换机? 交换机用来路由消息。如果直发队列,这个消息就被处理消失了,那别的队列也需要这个消息怎么办?那就要用到交换机 交换机类型 1,fanout:广播 特点 广播所有消息:将消息…...
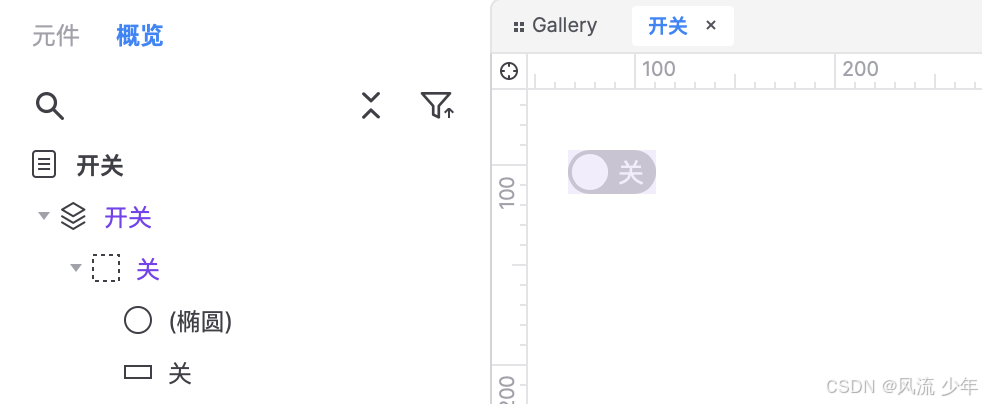
高保真组件库:开关
一:制作关状态 拖入一个矩形作为关闭的底色:44 x 22,填充灰色CCCCCC,圆角23,边框宽度0,文本为”关“,右对齐,边距2,2,6,2,文本颜色白色FFFFFF。 拖拽一个椭圆,尺寸18 x 18,边框为0。3. 全选转为动态面板状态1命名为”关“。 二:制作开状态 复制关状态并命名为”开…...
未授权访问事件频发,我们应当如何应对?
在当下,数据已成为企业和组织的核心资产,是推动业务发展、决策制定以及创新的关键驱动力。然而,未授权访问这一隐匿的安全威胁,正如同高悬的达摩克利斯之剑,时刻威胁着数据的安全,一旦触发,便可…...

Easy Excel
Easy Excel 一、依赖引入二、基本使用1. 定义实体类(导入/导出共用)2. 写 Excel3. 读 Excel 三、常用注解说明(完整列表)四、进阶:自定义转换器(Converter) 其它自定义转换器没生效 Easy Excel在…...

欢乐熊大话蓝牙知识17:多连接 BLE 怎么设计服务不会乱?分层思维来救场!
多连接 BLE 怎么设计服务不会乱?分层思维来救场! 作者按: 你是不是也遇到过 BLE 多连接时,调试现场像网吧“掉线风暴”? 温度传感器连上了,心率带丢了;一边 OTA 更新,一边通知卡壳。…...

AWS vs 阿里云:功能、服务与性能对比指南
在云计算领域,Amazon Web Services (AWS) 和阿里云 (Alibaba Cloud) 是全球领先的提供商,各自在功能范围、服务生态系统、性能表现和适用场景上具有独特优势。基于提供的引用[1]-[5],我将从功能、服务和性能三个方面进行结构化对比分析&#…...

用js实现常见排序算法
以下是几种常见排序算法的 JS实现,包括选择排序、冒泡排序、插入排序、快速排序和归并排序,以及每种算法的特点和复杂度分析 1. 选择排序(Selection Sort) 核心思想:每次从未排序部分选择最小元素,与未排…...

python读取SQLite表个并生成pdf文件
代码用于创建含50列的SQLite数据库并插入500行随机浮点数据,随后读取数据,通过ReportLab生成横向PDF表格,包含格式化(两位小数)及表头、网格线等美观样式。 # 导入所需库 import sqlite3 # 用于操作…...