【C++】讲的最通透最易懂的关于结构体内存对齐的问题
目录
- 1. 内存对齐规则
- 2. 简单易懂的内存对齐示例
- 2.1 简单结构体
- 2.2 含位域的结构体
- 2.3 空类的大小
- 2.4 嵌套结构体
- 3. 为什么需要内存对齐?
- 4. 类型在不同系统下所占字节数
1. 内存对齐规则
- 第一个成员在与结构体变量偏移量为0的位置处。
- 其他成员变量要对齐到某个数字(对其数)的整数倍的地址处。对其数=编译器默认的一个对齐数与该成员大小的较小者。
vs中默认的值是8 Linux中默认的值是4 - 结构体总大小为最大对其数(每一个成员变量都有一个对其数)的整数倍。
- 如果嵌套了结构体对齐到自己的最大对其数是整数倍处,结构体的整体大小就是最大对齐数(含嵌套结构体的对齐数)的整数倍。
- 如对内存对齐有明确要求,可用
#pragma pack(n)指定(n必须是2的N次方),以n和结构体中最长数据成员长度中较小者为有效值
可能只看上面的描述你还是有点搞不懂,那么我们可以看一下具体的例子和视图讲解:
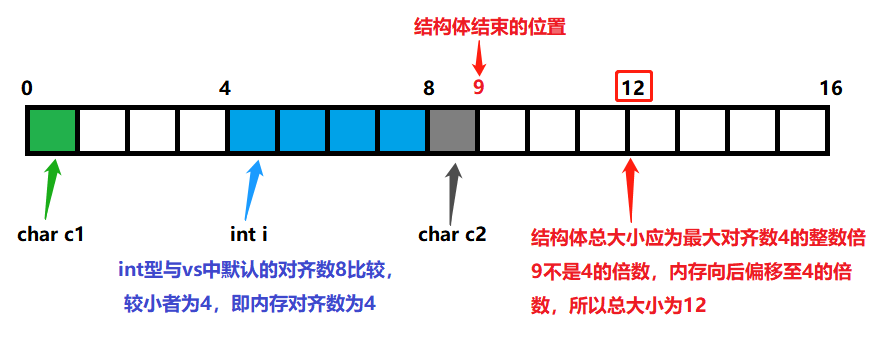
struct s1{char c1;int i;char c2;
};
//结构体总大小为:12
2. 简单易懂的内存对齐示例
2.1 简单结构体
struct s1
{char str; //1字节short x; //2字节int num; //4字节
};
// sizeof(s1) = 8 // (1+1) + 2 + 4 = 8 第2个加1处的内存是空的
2.2 含位域的结构体
一个位域必须存储在同一个字节中,不能跨两个字节。如一个字节所剩空间不够存放另一位域时,应从下一单元起存放该位域。
struct s2
{unsigned char a:7; //字段a占用了一个字节的7个bitunsigned char b:2; //字段b占用了2个bitunsigned char c:7; //字段c占用了7个bit
}s1;
// sizeof(s1) = 3 // 1 + 1 + 1 = 3
struct s3
{char t : 4; //4表示在一个字节中占4个比特位char k : 4;
};
// sizeof(s3) = 1 //0.5 + 0.5 = 1
struct s4
{char t : 4; //4表示在一个字节中占4个比特位char k : 4;unsigned short i : 8;char a;
};
// sizeof(s4) = 6 //(0.5 + 0.5 + 1) + 2 + (1+1) = 6
// 解释:0.5和0.5占一个字节,两个占4比特的刚好可以放在一个字节中,short为2字节,对齐数是2,所以0.5 + 0.5 + 1中加的1是空的
2.3 空类的大小
class A {};
// sizeof(A) = 1
空类,没有任何成员变量和成员函数,编译器是支持空类实例化对象的,对象必须要被分配内存空间才有意义,大小: 1Byte (字节)
2.4 嵌套结构体
class A {
private:double dd;int ii;int* pp;
};class Test {
private:int i;A a;double d;char* p;
};
int main()
{A a1;Test test;cout << sizeof(a1) << endl;cout << sizeof(test) << endl;
}
// x86(32位操作系统)平台运行结果:40
// x64(64位操作系统)平台运行结果:48
对其数 = 编译器默认的一个对齐数与该成员大小的较小者,vs中默认的值是8
-
x86:指针是4字节,类A的大小是16,8与16的较小者是8。内存大小为:8 + 16 + 8 + 4 = 36,又因为36不是最大对齐数8的倍数,所以内存向后偏移,大小为 40
-
x64:指针是8字节,类A大小为24,8与24的较小者是8。内存大小为:8 + 24 + 8 +8 = 48,48刚好是最大对齐数8的倍数,所以内存大小为48
3. 为什么需要内存对齐?
字节对齐主要是为了提高内存的访问效率
cpu一次能读取多少内存要看数据总线是多少位,如果是16位,则一次只能读取2个字节,如果是32位,则可以读取4个字节,并且cpu不能跨内存区间访问。
假设有这样一个结构体如下:
struct s
{char a;int b;
};
假设地址空间是类似下面这样的:

-
在没有字节对齐的情况下,变量a就是占用了
0x00000001这一个字节,而变量b则是占用了0x00000002~0x000000005这四个字节,那么cpu如果想从内存中读取变量b,首先要从变量b的开始地址0x00000002读到0x0000004,然后再读取一次0x00000005这个字节,相当于读一个int,cpu从内存读取了两次。 -
而如果进行字节对齐的话,变量a还是占用了
0x00000001这一个字节,而变量b则是占用了0x00000005~0x00000008这四个字节,那么cpu要读取变量b的话,就直接一次性从0x00000005读到0x00000008,就一次全部读取出来了。 -
所以说,字节对齐的根本原因其实在于cpu读取内存的效率问题,对齐以后,cpu读取内存的效率会更快。结构体的内存对齐是拿空间来换取时间的做法
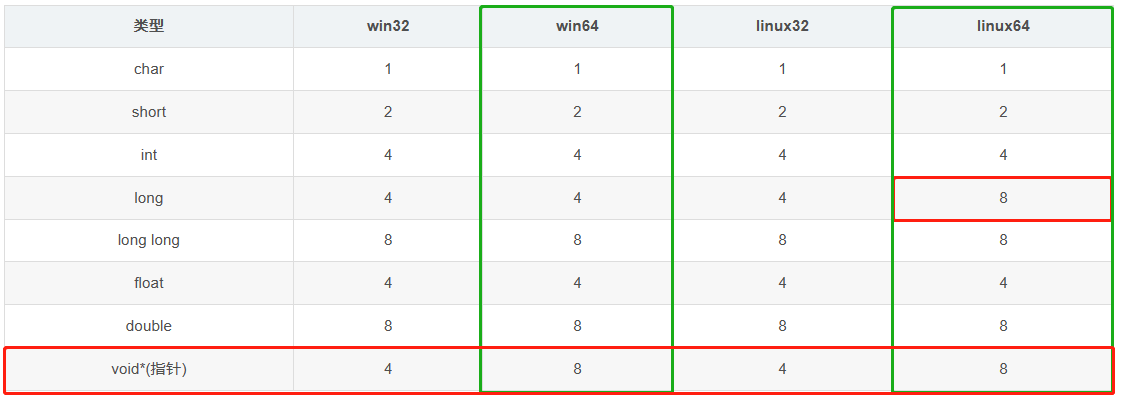
4. 类型在不同系统下所占字节数
| 类型 | win32 | win64 | linux32 | linux64 |
|---|---|---|---|---|
| char | 1 | 1 | 1 | 1 |
| short | 2 | 2 | 2 | 2 |
| int | 4 | 4 | 4 | 4 |
| long | 4 | 4 | 4 | 8 |
| long long | 8 | 8 | 8 | 8 |
| float | 4 | 4 | 4 | 4 |
| double | 8 | 8 | 8 | 8 |
| void*(指针) | 4 | 8 | 4 | 8 |
相关文章:
【C++】讲的最通透最易懂的关于结构体内存对齐的问题
目录1. 内存对齐规则2. 简单易懂的内存对齐示例2.1 简单结构体2.2 含位域的结构体2.3 空类的大小2.4 嵌套结构体3. 为什么需要内存对齐?4. 类型在不同系统下所占字节数1. 内存对齐规则 第一个成员在与结构体变量偏移量为0的位置处。其他成员变量要对齐到某个数字&a…...
Stochastic Approximation 随机近似方法的详解之(一)
随机近似的定义:它指的是一大类随机迭代算法,用于求根或者优化问题。 Stochastic approximation refers to a broad class of stochastic iterative algorithms solving root finding or optimization problems. temporal-difference algorithms是随机近…...

软件自动化测试工程师面试题集锦
以下是部分面试题目和我的个人回答,回答比较简略,仅供参考。不对之处请指出 1.自我介绍 答:姓名,学历专业,技能,近期工作经历等,可以引导到最擅长的点,比如说代码或者项目 参考&a…...

智合同丨教你做一个懂AI的法律人
作为一名法律人,合同审核工作是日常工作中最基本也是必不可少的一项事务。我们知道,一般在企业,合同审批会涉及到众多部门和职务角色,最关键的一环其实在法务或者律师建议,其他部门给出的审批意见基本上都是基于自己部…...

如何判断自己使用的IP是独享还是共享?
在互联网上,我们常常听到独享IP和共享IP这两个概念。独享IP指的是一个IP地址只被一个用户或一个网站所使用,而共享IP则是多个用户或多个网站共用一个IP地址。那么,如何分辨IP是不是独享呢?接下来,我们将从几个方面来看。在这之前…...

跳石头
题目描述 一年一度的"跳石头"比赛又要开始了! 这项比赛将在一条笔直的河道中进行,河道中分布着一些巨大岩石。组委会已经选择好了两块岩石作为比赛起点和终点。在起点和终点之间,有 N 块岩石(不含起点和终点的岩石)。在比赛过程中,选手们将从起点出发,每一步跳…...
上传gitee教程,Gitee怎么上传代码到仓库
目录 第一步:配置git的用户名和邮箱 第二步:上传到远程仓库 第三步:将仓库的master分支拉取过来和本地的当前分支进行合并 第四步:将修改的所有代码添加到暂存区 第五步:将缓存区内容添加到本地仓库(…...

netstat命令详解
1、下载netstat命令对应的软件包 yum install net-tools -y2、netsta命令介绍 [rootvm01 ~]# man netstatNETSTAT(8) Linux System Administrators Manual NETSTAT(8)NAMEnetstat - Print network connections, routing t…...

数据库三范式
文章目录数据库三范式1. 第一范式(1NF)2. 第二范式(2NF)3. 第三范式(3NF)数据库三范式 第一范式:有主键,具有原子性,字段不可分割第二范式:完全依赖…...

K8S 1.20 弃用 Docker 评估之 Docker 和 OCI 镜像格式的差别
背景 2020 年 12 月初,Kubernetes 在其最新的 Changelog 中宣布,自 Kubernetes 1.20 之后将弃用 Docker 作为容器运行时。 弃用 Docker 带来的,可能是一系列的改变,包括不限于: 容器镜像构建工具容器 CLI容器镜像仓…...

Vue2和Vue3响应式的区别
数据响应式是什么? 所谓 数据响应式 就是建立 响应式数据 与 依赖(调用了响应式数据的操作)之间的关系,当响应式数据发生变化时,可以通知那些使用了这些响应式数据的依赖操作进行相关更新操作,可以是DOM…...

模型实战(6)之Alex实现图像分类:模型原理+训练+预测(详细教程!)
Alex实现图像分类:模型原理+训练+预测 图像分类或者检索任务在浏览器中的搜索操作、爬虫搜图中应用较广,本文主要通过Alex模型实现猫狗分类,并且将可以复用的开源模型在文章中给出!!!数据集可以由此下载:Data本文将从以下内容做出讲述: 1.模型简介及环境搭建2.数据集准…...

【大数据】最全的大数据Hadoop|Yarn|Spark|Flink|Hive技术书籍分享/下载链接,持续更新中...
这里写目录标题Hadoop大数据处理Hadoop技术内幕:深入解析YARN架构设计与实现原理Hadoop 技术内幕:深入解析Hadoop Common 和HDFS 架构设计与实现原理Spark SQL内核剖析Hadoop 应用架构深度剖析Hadoop HDFSHadoop实战Hive编程指南Hadoop大数据处理 本书以…...

RIG Exploit Kit 仍然通过 IE 感染企业用户
RIG Exploit Kit 正处于最成功的时期,每天尝试大约 2000 次入侵并在大约 30% 的案例中成功,这是该服务长期运行历史中的最高比率。 通过利用相对较旧的 Internet Explorer 漏洞,RIG EK 已被发现分发各种恶意软件系列,包括 Dridex…...
GIS在地质灾害危险性评估与灾后重建中的实践技术应用及python机器学习灾害易发性评价模型建立与优化进阶
地质灾害是指全球地壳自然地质演化过程中,由于地球内动力、外动力或者人为地质动力作用下导致的自然地质和人类的自然灾害突发事件。由于降水、地震等自然作用下,地质灾害在世界范围内频繁发生。我国除滑坡灾害外,还包括崩塌、泥石流、地面沉…...

SQL SERVER中SCHEMA的詳解
SQL SERVER中SCHEMA的講解1. Introduction1.1 優勢1.2 內置schema2. Create Schema2.1 Parameters2.2 Sql3.Awakening1. Introduction 1.1 優勢 数据库模式为我们提供了在数据库中创建逻辑对象组的灵活性。如果多个团队使用同一个数据库,我们可以设计各种模式来分組…...
【LeetCode】剑指 Offer(13)
目录 题目:剑指 Offer 31. 栈的压入、弹出序列 - 力扣(Leetcode) 题目的接口: 解题思路: 代码: 过啦!!! 写在最后: 题目:剑指 Offer 31. 栈…...

帮助小型企业实现业务增长的7种数字营销策略
数字营销一直在不断地变化和发展,在过去的几年里我们已经见识到了其迅猛的发展速度。虽然我们在数字营销中看到了一些新的趋势,但对于小型企业来说很难利用并发挥其优势。相比较大型企业,小型企业的预算和资源通常有限,所以他们很…...

互联网行业的高级产品经理和普通产品经理有哪些区别?
普通产品经理的一天可能是这样的。 早上到公司想一想,这几天有哪些事情要处理。打开记事本,按照上面要求的任务一条一条开始做。 这里有个需求,是要给产品的聊天模块增加历史记录。嗯,看一下常见的几款社交工具 APP,他…...

aardio - 【库】简单信息框
昨晚得知aardio作者一鹤的妻子病情严重,深感悲痛。今日给一鹤捐赠少许,望其妻能挺过难关,早日康复。 aardio是一个很好的编程工具,我非常喜欢,这两年也一直在用。虽然未曾用其获利,但其灵活的语法ÿ…...

开关电源EMC设计:从原理到实践的关键技术
1. 开关电源EMC设计基础 开关电源因其高效率和小型化优势,在现代电子设备中广泛应用。然而,高频开关动作带来的电磁干扰(EMI)问题不容忽视。作为一名电源工程师,我经常需要面对各种EMC挑战。记得有一次,我们团队设计的工业电源模块…...

中国地址生成器:快速生成真实地址数据的开发者利器
中国地址生成器:快速生成真实地址数据的开发者利器 【免费下载链接】chinese-address-generator 中国地址生成器 - 三级地址 四级地址 随机生成完整地址 项目地址: https://gitcode.com/gh_mirrors/ch/chinese-address-generator 在开发测试、数据填充、表单…...

长期使用Taotoken的Token Plan套餐在项目开发成本控制上的实际感受
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 长期使用Taotoken的Token Plan套餐在项目开发成本控制上的实际感受 1. 从按需付费到计划用量的转变 在AI应用开发的早期阶段&…...
)
【仅开放72小时】:Gemini Workspace与Microsoft Entra ID双向同步的密钥轮换脚本(含自动审计日志生成器)
更多请点击: https://intelliparadigm.com 第一章:Gemini Workspace整合方案概述 Gemini Workspace 是 Google 推出的面向企业级 AI 协作的统一平台,其核心价值在于将 Gemini 模型能力深度嵌入办公套件(如 Gmail、Drive、Docs、M…...

Notero终极指南:打通Zotero与Notion的学术工作流桥梁
Notero终极指南:打通Zotero与Notion的学术工作流桥梁 【免费下载链接】notero A Zotero plugin for syncing items and notes into Notion 项目地址: https://gitcode.com/gh_mirrors/no/notero 当你在Zotero中积累了数百篇文献,却发现整理和引用它…...

量子噪声对机器学习模型的影响与缓解策略
1. 量子噪声与机器学习模型的复杂关系量子计算领域近年来最令人兴奋的进展之一,就是量子机器学习(QML)的兴起。作为一名长期跟踪量子计算发展的从业者,我亲眼见证了量子算法在机器学习任务中展现出的惊人潜力。然而,在…...
:Claude在长文档法律分析胜出32%,Gemini在实时多跳检索快4.8倍——你的业务该选谁?)
大模型选型生死局(企业CTO私藏对比清单):Claude在长文档法律分析胜出32%,Gemini在实时多跳检索快4.8倍——你的业务该选谁?
更多请点击: https://intelliparadigm.com 第一章:大模型选型生死局:Claude vs Gemini核心能力全景图 在企业级AI应用落地的关键阶段,模型选型已远非单纯比拼参数量或基准分数,而是对推理鲁棒性、上下文工程适配度、多…...

处理电商分类难题:我是如何用XGBoost为Otto数据集做多类别预测的
电商商品分类实战:XGBoost在Otto数据集上的高阶应用 当面对海量商品需要精准分类时,传统人工规则往往力不从心。Otto Group Product Classification Challenge正是这样一个典型场景——需要将数十万商品准确划分到93个类别中。本文将分享如何用XGBoost构…...

Jentic Mini:为AI智能体构建安全的API执行层与凭据管理方案
1. 项目概述:为AI智能体构建安全的API执行层 如果你正在开发AI智能体,并且希望它能帮你操作Notion、Slack、GitHub这些真实世界的服务,那你一定遇到过这个核心难题:怎么把API密钥安全地交给它?直接把密钥塞进提示词里&…...
)
arXiv论文智能检索革命(Perplexity深度集成实战白皮书)
更多请点击: https://intelliparadigm.com 第一章:arXiv论文智能检索革命(Perplexity深度集成实战白皮书) 传统 arXiv 检索依赖关键词匹配与手动筛选,面对日均超 2000 篇新增论文,科研人员常陷入信息过载困…...