大数据分析与应用实验任务十一
大数据分析与应用实验任务十一
实验目的
-
通过实验掌握spark Streaming相关对象的创建方法;
-
熟悉spark Streaming对文件流、套接字流和RDD队列流的数据接收处理方法;
-
熟悉spark Streaming的转换操作,包括无状态和有状态转换。
-
熟悉spark Streaming输出编程操作。
实验任务
一、DStream 操作概述
-
创建 StreamingContext 对象
登录 Linux 系统后,启动 pyspark。进入 pyspark 以后,就已经获得了一个默认的 SparkConext 对象,也就是 sc。因此,可以采用如下方式来创建 StreamingContext 对象:
from pyspark.streaming import StreamingContext sscluozhongye = StreamingContext(sc, 1)
如果是编写一个独立的 Spark Streaming 程序,而不是在 pyspark 中运行,则需要在代码文件中通过类似如下的方式创建 StreamingContext 对象:
from pyspark import SparkContext, SparkConf from pyspark.streaming import StreamingContext conf = SparkConf() conf.setAppName('TestDStream') conf.setMaster('local[2]') sc = SparkContext(conf = conf) ssc = StreamingContext(sc, 1) print("创建成功,lzy防伪")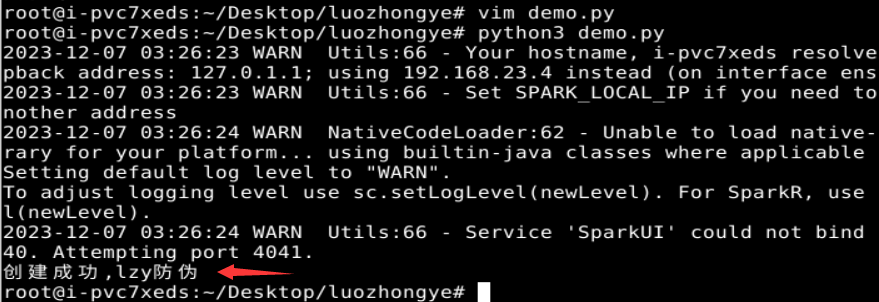
二、基本输入源
- 文件流
-
在 pyspark 中创建文件流
首先,在 Linux 系统中打开第 1 个终端(为了便于区分多个终端,这里记作“数据源终端”),创建一个 logfile 目录,命令如下:
cd /root/Desktop/luozhongye/ mkdir streaming cd streaming mkdir logfile
其次,在 Linux 系统中打开第二个终端(记作“流计算终端”),启动进入 pyspark,然后,依次输入如下语句:
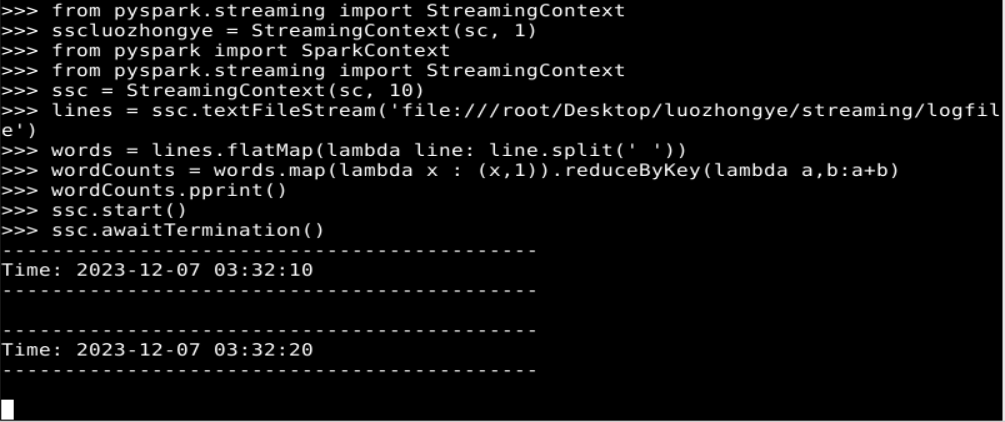
from pyspark import SparkContext from pyspark.streaming import StreamingContext ssc = StreamingContext(sc, 10) lines = ssc.textFileStream('file:///root/Desktop/luozhongye/streaming/logfile') words = lines.flatMap(lambda line: line.split(' ')) wordCounts = words.map(lambda x : (x,1)).reduceByKey(lambda a,b:a+b) wordCounts.pprint() ssc.start() ssc.awaitTermination()
-
采用独立应用程序方式创建文件流
#!/usr/bin/env python3 from pyspark import SparkContext, SparkConf from pyspark.streaming import StreamingContext conf = SparkConf() conf.setAppName('TestDStream') conf.setMaster('local[2]') sc = SparkContext(conf = conf) ssc = StreamingContext(sc, 10) lines = ssc.textFileStream('file:///root/Desktop/luozhongye/streaming/logfile') words = lines.flatMap(lambda line: line.split(' ')) wordCounts = words.map(lambda x : (x,1)).reduceByKey(lambda a,b:a+b) wordCounts.pprint() ssc.start() ssc.awaitTermination() print("2023年12月7日lzy")保存该文件,并执行以下命令:
cd /root/Desktop/luozhongye/streaming/logfile/ spark-submit FileStreaming.py
- 套接字流
-
使用套接字流作为数据源
新建一个代码文件“/root/Desktop/luozhongye/streaming/socket/NetworkWordCount.py”,在NetworkWordCount.py 中输入如下内容:
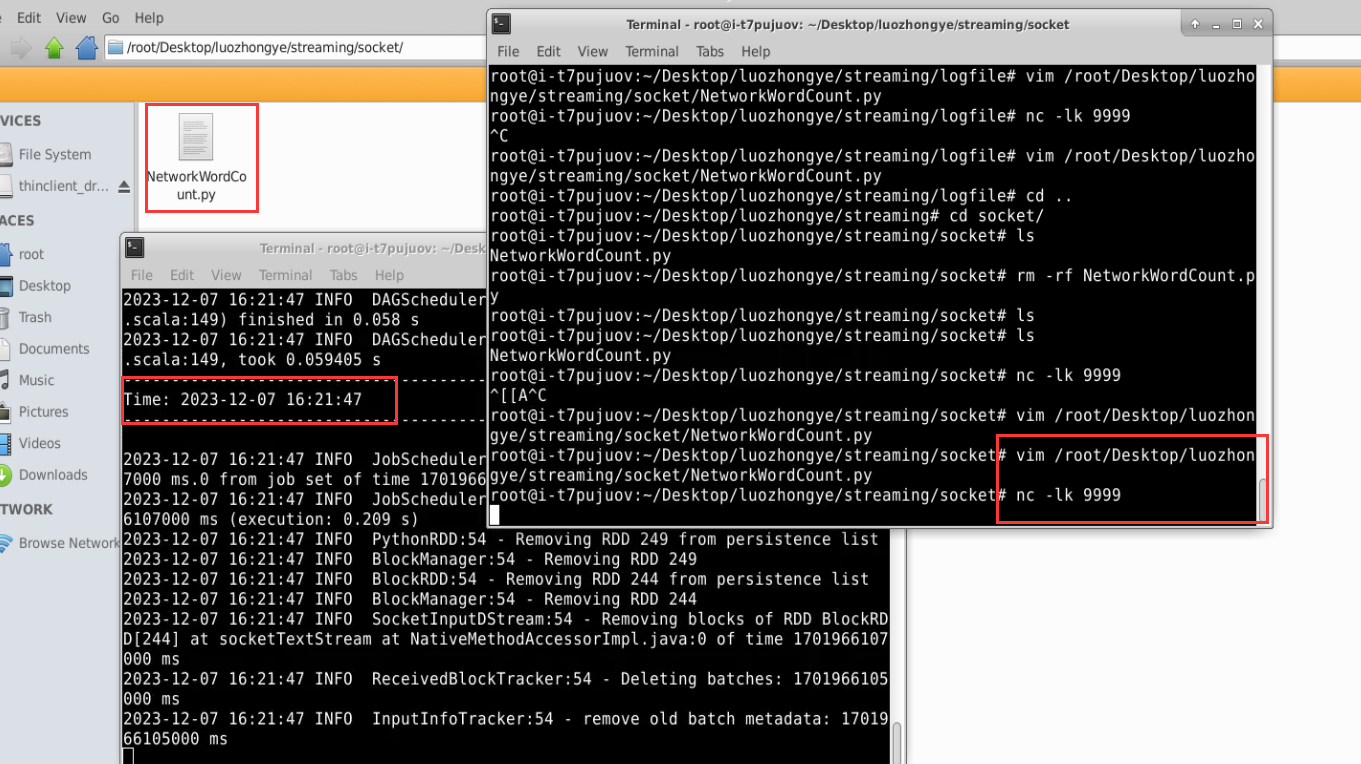
#!/usr/bin/env python3 from __future__ import print_function import sys from pyspark import SparkContext from pyspark.streaming import StreamingContextif __name__ == "__main__":if len(sys.argv) != 3:print("Usage: NetworkWordCount.py <hostname> <port>", file=sys.stderr)exit(-1)sc = SparkContext(appName="PythonStreamingNetworkWordCount")ssc = StreamingContext(sc, 1)lines = ssc.socketTextStream(sys.argv[1], int(sys.argv[2]))counts = lines.flatMap(lambda line: line.split(" ")).map(lambda word: (word, 1)).reduceByKey(lambda a, b: a + b)counts.pprint()ssc.start()ssc.awaitTermination()使用如下 nc 命令生成一个 Socket 服务器端:
nc -lk 9999新建一个终端(记作“流计算终端”),执行如下代码启动流计算:
cd /root/Desktop/luozhongye/streaming/socket /usr/local/spark/bin/spark-submit NetworkWordCount.py localhost 9999
-
使用 Socket 编程实现自定义数据源
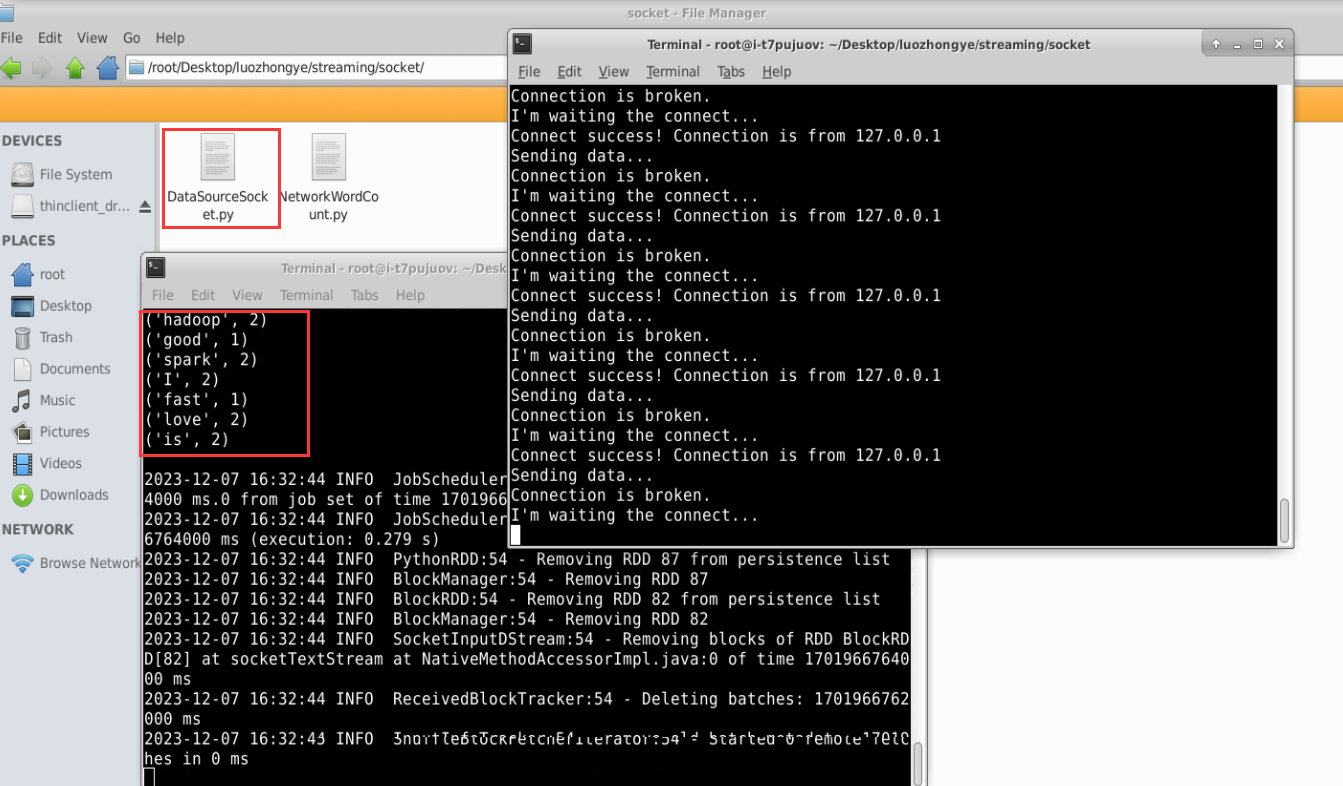
新建一个代码文件“/root/Desktop/luozhongye/streaming/socket/DataSourceSocket.py”,在 DataSourceSocket.py 中输入如下代码:
#!/usr/bin/env python3 import socket# 生成 socket 对象 server = socket.socket() # 绑定 ip 和端口 server.bind(('localhost', 9999)) # 监听绑定的端口 server.listen(1) while 1:# 为了方便识别,打印一个“I’m waiting the connect...”print("I'm waiting the connect...")# 这里用两个值接收,因为连接上之后使用的是客户端发来请求的这个实例# 所以下面的传输要使用 conn 实例操作conn, addr = server.accept()# 打印连接成功print("Connect success! Connection is from %s " % addr[0])# 打印正在发送数据print('Sending data...')conn.send('I love hadoop I love spark hadoop is good spark is fast'.encode())conn.close()print('Connection is broken.') print("2023年12月7日lzy")执行如下命令启动 Socket 服务器端:
cd /root/Desktop/luozhongye/streaming/socket /usr/local/spark/bin/spark-submit DataSourceSocket.py新建一个终端(记作“流计算终端”),输入以下命令启动 NetworkWordCount 程序:
cd /root/Desktop/luozhongye/streaming/socket /usr/local/spark/bin/spark-submit NetworkWordCount.py localhost 9999
-
RDD 队列流
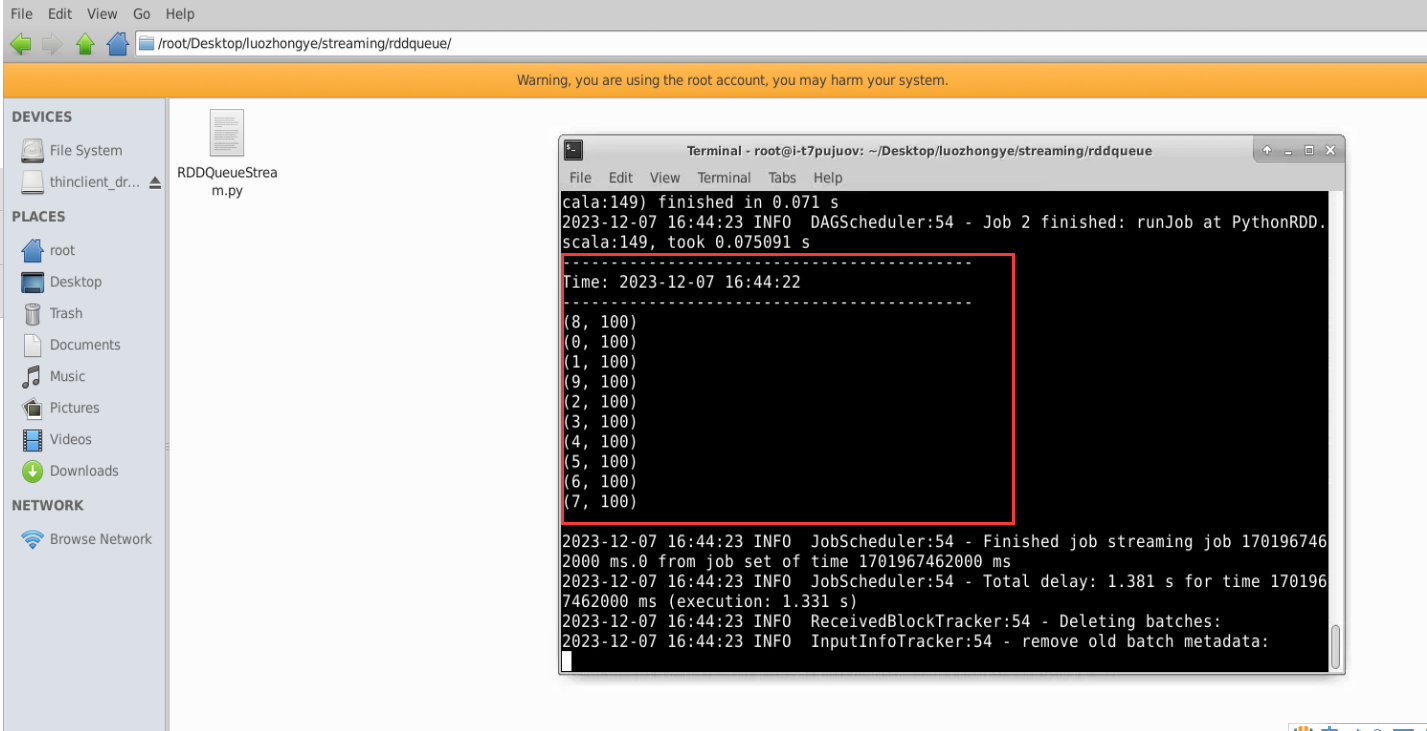
Linux 系统中打开一个终端,新建一个代码文件“/root/Desktop/luozhongye/ streaming/rddqueue/ RDDQueueStream.py”,输入以下代码:
#!/usr/bin/env python3 import time from pyspark import SparkContext from pyspark.streaming import StreamingContextif __name__ == "__main__":print("")sc = SparkContext(appName="PythonStreamingQueueStream")ssc = StreamingContext(sc, 2)# 创建一个队列,通过该队列可以把 RDD 推给一个 RDD 队列流rddQueue = []for i in range(5):rddQueue += [ssc.sparkContext.parallelize([j for j in range(1, 1001)], 10)]time.sleep(1)# 创建一个 RDD 队列流inputStream = ssc.queueStream(rddQueue)mappedStream = inputStream.map(lambda x: (x % 10, 1))reducedStream = mappedStream.reduceByKey(lambda a, b: a + b)reducedStream.pprint()ssc.start()ssc.stop(stopSparkContext=True, stopGraceFully=True)下面执行如下命令运行该程序:
cd /root/Desktop/luozhongye/streaming/rddqueue /usr/local/spark/bin/spark-submit RDDQueueStream.py
三、转换操作
-
滑动窗口转换操作
对“套接字流”中的代码 NetworkWordCount.py 进行一个小的修改,得到新的代码文件“/root/Desktop/luozhongye/streaming/socket/WindowedNetworkWordCount.py”,其内容如下:
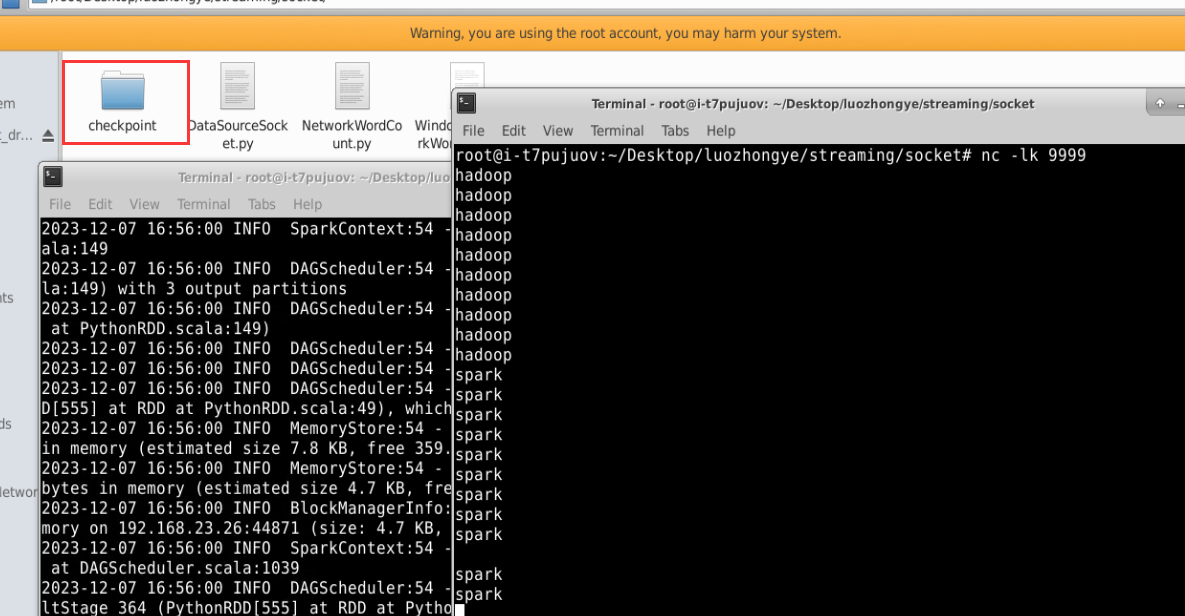
#!/usr/bin/env python3 from __future__ import print_function import sys from pyspark import SparkContext from pyspark.streaming import StreamingContextif __name__ == "__main__":if len(sys.argv) != 3:print("Usage: WindowedNetworkWordCount.py <hostname> <port>", file=sys.stderr)exit(-1)sc = SparkContext(appName="PythonStreamingWindowedNetworkWordCount")ssc = StreamingContext(sc, 10)ssc.checkpoint("file:///root/Desktop/luozhongye/streaming/socket/checkpoint")lines = ssc.socketTextStream(sys.argv[1], int(sys.argv[2]))counts = lines.flatMap(lambda line: line.split(" ")) \.map(lambda word: (word, 1)) \.reduceByKeyAndWindow(lambda x, y: x + y, lambda x, y: x - y, 30, 10)counts.pprint()ssc.start()ssc.awaitTermination()
为了测试程序的运行效果,首先新建一个终端(记作“数据源终端”),执行如下命令运行nc 程序:
cd /root/Desktop/luozhongye/streaming/socket/ nc -lk 9999
然后,再新建一个终端(记作“流计算终端”),运行客户端程序 WindowedNetworkWordCount.py,命令如下:
cd /root/Desktop/luozhongye/streaming/socket/ /usr/local/spark/bin/spark-submit WindowedNetworkWordCount.py localhost 9999
在数据源终端内,连续输入 10 个“hadoop”,每个 hadoop 单独占一行(即每输入一个 hadoop就按回车键),再连续输入 10 个“spark”,每个 spark 单独占一行。这时,可以查看流计算终端内显示的词频动态统计结果,可以看到,随着时间的流逝,词频统计结果会发生动态变化。
-
updateStateByKey 操作
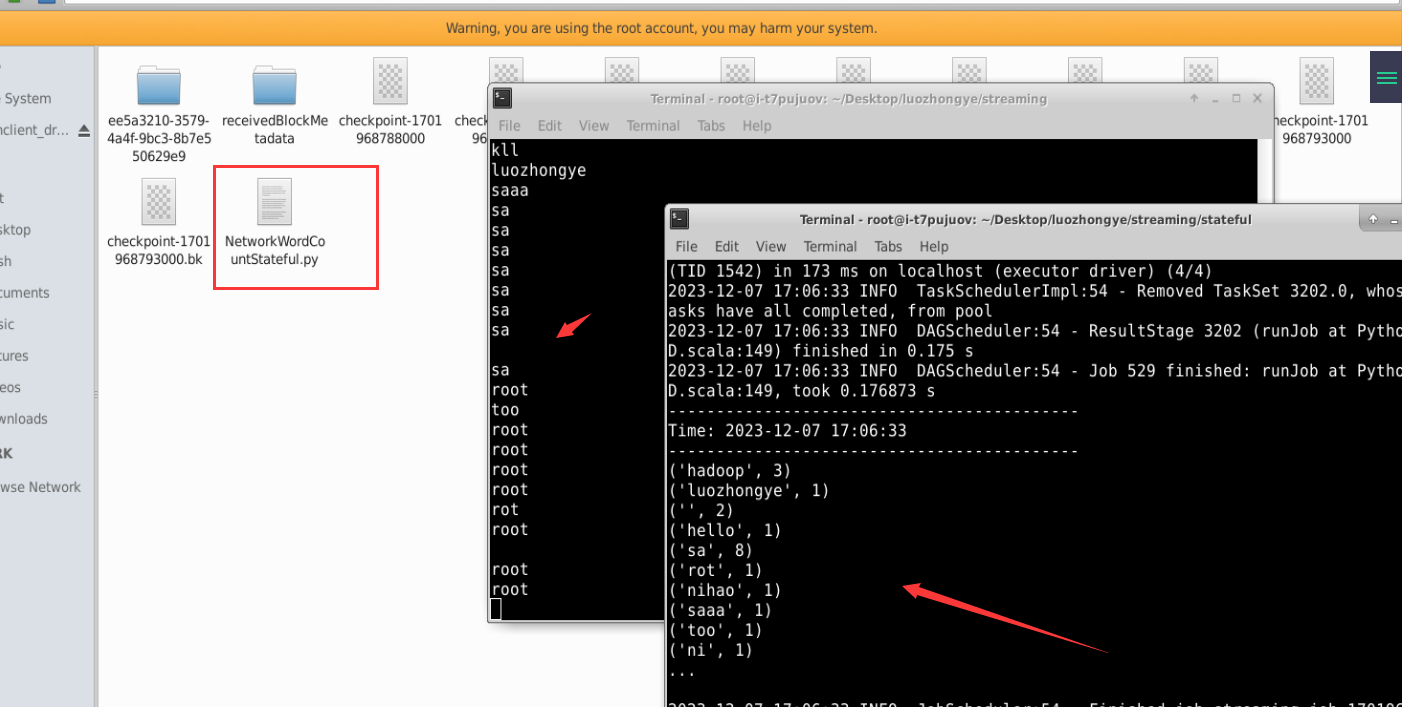
在“/root/Desktop/luozhongye/streaming/stateful/”目录下新建一个代码文件 NetworkWordCountStateful.py,输入以下代码:
#!/usr/bin/env python3 from __future__ import print_function import sys from pyspark import SparkContext from pyspark.streaming import StreamingContextif __name__ == "__main__":if len(sys.argv) != 3:print("Usage: NetworkWordCountStateful.py <hostname> <port>", file=sys.stderr)exit(-1)sc = SparkContext(appName="PythonStreamingStatefulNetworkWordCount")ssc = StreamingContext(sc, 1)ssc.checkpoint("file:///root/Desktop/luozhongye/streaming/stateful/")# RDD with initial state (key, value) pairsinitialStateRDD = sc.parallelize([(u'hello', 1), (u'world', 1)])def updateFunc(new_values, last_sum):return sum(new_values) + (last_sum or 0)lines = ssc.socketTextStream(sys.argv[1], int(sys.argv[2]))running_counts = lines.flatMap(lambda line: line.split(" ")) \.map(lambda word: (word, 1)) \.updateStateByKey(updateFunc, initialRDD=initialStateRDD)running_counts.pprint()ssc.start()ssc.awaitTermination()新建一个终端(记作“数据源终端”),执行如下命令启动 nc 程序:
nc -lk 9999新建一个 Linux 终端(记作“流计算终端”),执行如下命令提交运行程序:
cd /root/Desktop/luozhongye/streaming/stateful /usr/local/spark/bin/spark-submit NetworkWordCountStateful.py localhost 9999
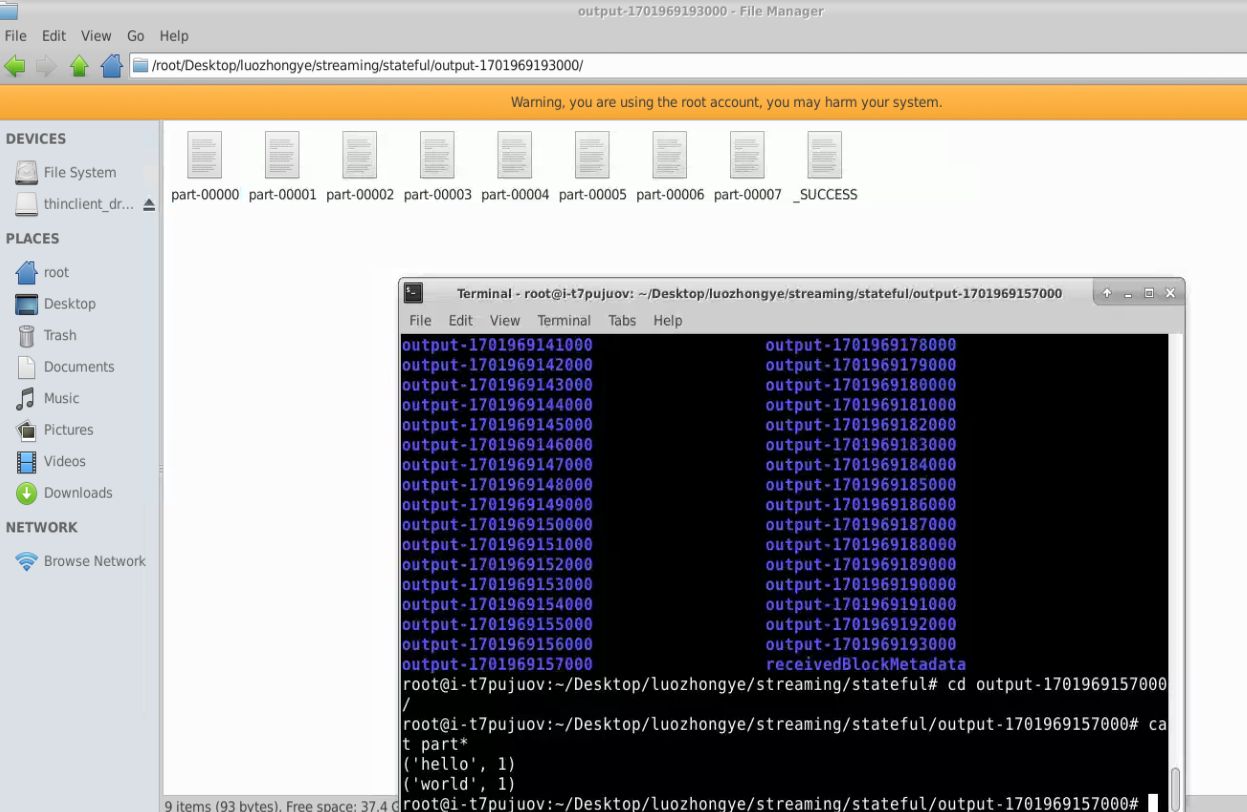
四、把 DStream 输出到文本文件中
下面对之前已经得到的“/root/Desktop/luozhongye/streaming/stateful/NetworkWordCountStateful.py”代码进行简单的修改,把生成的词频统计结果写入文本文件中。
修改后得到的新代码文件“/root/Desktop/luozhongye/streaming/stateful/NetworkWordCountStatefulText.py”的内容如下:
#!/usr/bin/env python3
from __future__ import print_function
import sys
from pyspark import SparkContext
from pyspark.streaming import StreamingContextif __name__ == "__main__":if len(sys.argv) != 3:print("Usage: NetworkWordCountStateful.py <hostname> <port>", file=sys.stderr)exit(-1)sc = SparkContext(appName="PythonStreamingStatefulNetworkWordCount")ssc = StreamingContext(sc, 1)ssc.checkpoint("file:///root/Desktop/luozhongye/streaming/stateful/")# RDD with initial state (key, value) pairs initialStateRDD = sc.parallelize([(u'hello', 1), (u'world', 1)])def updateFunc(new_values, last_sum):return sum(new_values) + (last_sum or 0)lines = ssc.socketTextStream(sys.argv[1], int(sys.argv[2]))running_counts = lines.flatMap(lambda line: line.split(" ")) \.map(lambda word: (word, 1)) \.updateStateByKey(updateFunc, initialRDD=initialStateRDD)running_counts.saveAsTextFiles("file:///root/Desktop/luozhongye/streaming/stateful/output")running_counts.pprint()ssc.start()ssc.awaitTermination()
新建一个终端(记作“数据源终端”),执行如下命令运行nc 程序:
cd /root/Desktop/luozhongye/streaming/socket/
nc -lk 9999
新建一个 Linux 终端(记作“流计算终端”),执行如下命令提交运行程序:
cd /root/Desktop/luozhongye/streaming/stateful
/usr/local/spark/bin/spark-submit NetworkWordCountStatefulText.py localhost 9999
实验心得
通过本次实验,我深入理解了Spark Streaming,包括创建StreamingContext、DStream等对象。同时,我了解了Spark Streaming对不同类型数据流的处理方式,如文件流、套接字流和RDD队列流。此外,我还熟悉了Spark Streaming的转换操作和输出编程操作,并掌握了map、flatMap、filter等方法。最后,我能够自定义输出方式和格式。总之,这次实验让我全面了解了Spark Streaming,对未来的学习和工作有很大的帮助。
相关文章:
大数据分析与应用实验任务十一
大数据分析与应用实验任务十一 实验目的 通过实验掌握spark Streaming相关对象的创建方法; 熟悉spark Streaming对文件流、套接字流和RDD队列流的数据接收处理方法; 熟悉spark Streaming的转换操作,包括无状态和有状态转换。 熟悉spark S…...
“78Win-Vận mệnh tốt”Trang web hỗ trợ kỹ thuật
Chng ti l một phần mềm cung cấp dịch vụ mua hộ xổ số cho người Việt Nam gốc Hoa. Bạn c thể gửi số v số lượng v số cần mua hộ, chng ti sẽ gửi đến tay bạn trước khi mở giải thưởng. Bạn chỉ cần trả tiền offline. Nếu bạ…...

React中使用react-json-view展示JSON数据
文章目录 一、前言1.1、在线demo1.2、Github仓库 二、实践2.1、安装react-json-view2.2、组件封装2.3、效果2.4、参数详解2.4.1、src(必须) :JSON Object2.4.2、name:string或false2.4.3、theme:string2.4.4、style:object2.4.5、…...

一文简述“低代码开发平台”到底是什么?
低代码开发平台到底是什么? 低代码开发平台(英文全称Low-Code Development Platform)是一种基于图形界面、可视化编程技术的开发平台,旨在提高软件开发的效率和质量。它可以帮助开发者快速构建应用程序,减少手动编写代…...
HNU计算机体系结构-实验3:多cache一致性算法
文章目录 实验3 多cache一致性算法一、实验目的二、实验说明三 实验内容1、cache一致性算法-监听法模拟2、cache一致性算法-目录法模拟 四、思考题五、实验总结 实验3 多cache一致性算法 一、实验目的 熟悉cache一致性模拟器(监听法和目录法)的使用&am…...

Go语言学习路线规划
🌷🍁 博主猫头虎(🐅🐾)带您 Go to New World✨🍁 🦄 博客首页——🐅🐾猫头虎的博客🎐 🐳 《面试题大全专栏》 🦕 文章图文…...
微软NativeApi-NtQuerySystemInformation
微软有一个比较实用的Native接口:NtQuerySystemInformation,具体可以参考微软msdn官方文档:NtQuerySystemInformation, 是一个系统函数,用于收集特定于所提供的指定种类的系统信息。ProcessHacker等工具使用NtQuerySys…...
灵活与高效的结合,CodeMeter Cloud Lite轻云锁解决方案
众多软件开发商日渐认识到,威步推出的一系列尖端软件产品在维护知识产权、精确控制及有效管理软件授权方面发挥着不可或缺的作用。这些产品的核心功能包括将许可证及其他关键敏感数据安全地存储于高端复杂的硬件设备、经过专业加密的文件,或者置于受严格…...

Flink 系列文章汇总索引
Flink 系列文章 一、Flink 专栏 本专栏系统介绍某一知识点,并辅以具体的示例进行说明。 本专栏的文章编号可能不是顺序的,主要是因为写的时候顺序没统一,但相关的文章又引入了,所以后面就没有调整了,按照写文章的顺…...
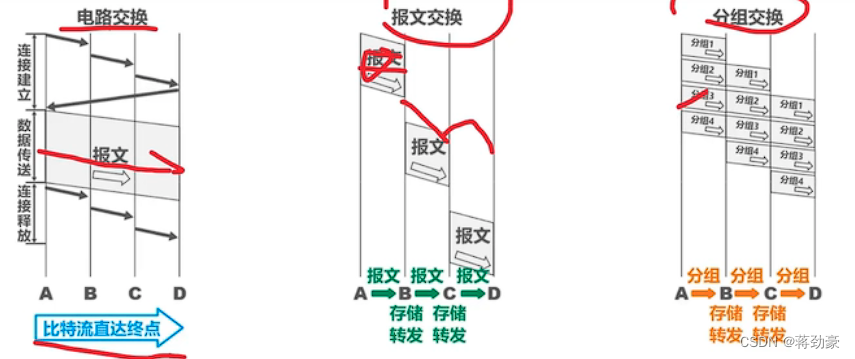
计算机网络——期末考试复习资料
什么是计算机网络 将地理位置不同的具有独立功能的多台计算机及其外部设备通过通信线路和通信设备连接起来;实现资源共享和数据传递的计算机的系统。 三种交换方式 报文交换:路由器转发报文; 电路交换:建立一对一电路 分组交换&a…...

【数据结构】面试OJ题——链表
目录 1.移除链表元素 思路: 2.反转链表 思路: 3.链表的中间结点 思路: 4.链表中的倒数第K个结点 思路: 5.合并两个有序链表 思路: 6.链表分割 思路: 7.链表的回文结构 思路: 8.随机链表…...
flask web开发学习之初识flask(三)
文章目录 一、flask扩展二、项目配置1. 直接配置2. 使用配置文件3. 使用环境变量4. 实例文件夹 三、flask命令四、模版和静态文件五、flask和mvc架构 一、flask扩展 flask扩展是指那些为Flask框架提供额外功能和特性的库。这些扩展通常遵循Flask的设计原则,易于集成…...

【设计模式-3.1】结构型——外观模式
说明:本文介绍设计模式中结构型设计模式中的,外观模式; 亲手下厨还是点外卖? 外观模式属于结构型的设计模式,关注类或对象的组合,所呈现出来的结构。以吃饭为例,在介绍外观模式之前࿰…...

flutter学习-day2-认识flutter
📚 目录 简介特点架构 框架层引擎层嵌入层 本文学习和引用自《Flutter实战第二版》:作者:杜文 1. 简介 Flutter 是 Google 推出并开源的移动应用开发框架,主打跨平台、高保真、高性能。开发者可以通过 Dart 语言开发 App&#…...
报错:unknown error: unsupported protocol)
解决selenium使用.get()报错:unknown error: unsupported protocol
解决方法 将原来的: url "https://www.baidu.com" browser.get(url)替换为: url "https://www.baidu.com" browser.execute_script(f"window.location.replace({url});") # 直接平替 .get()问题解析 之前运行都是正…...

关于加密解密,加签验签那些事
面对MD5、SHA、DES、AES、RSA等等这些名词你是否有很多问号?这些名词都是什么?还有什么公钥加密、私钥解密、私钥加签、公钥验签。这些都什么鬼?或许在你日常工作没有听说过这些名词,但是一旦你要设计一个对外访问的接口ÿ…...
容器重启后,Conda文件完整保存(虚拟环境、库包),如何重新安装conda并迁移之前的虚拟环境
Vim安装 容器重启后默认是vi,升级vim,执行命令 apt install -y vim安装 Anaconda 1. 下载Anaconda 其他版本请查看Anaconda官方库 wget https://mirrors.bfsu.edu.cn/anaconda/archive/Anaconda3-2023.03-1-Linux-x86_64.sh --no-check-certificate…...
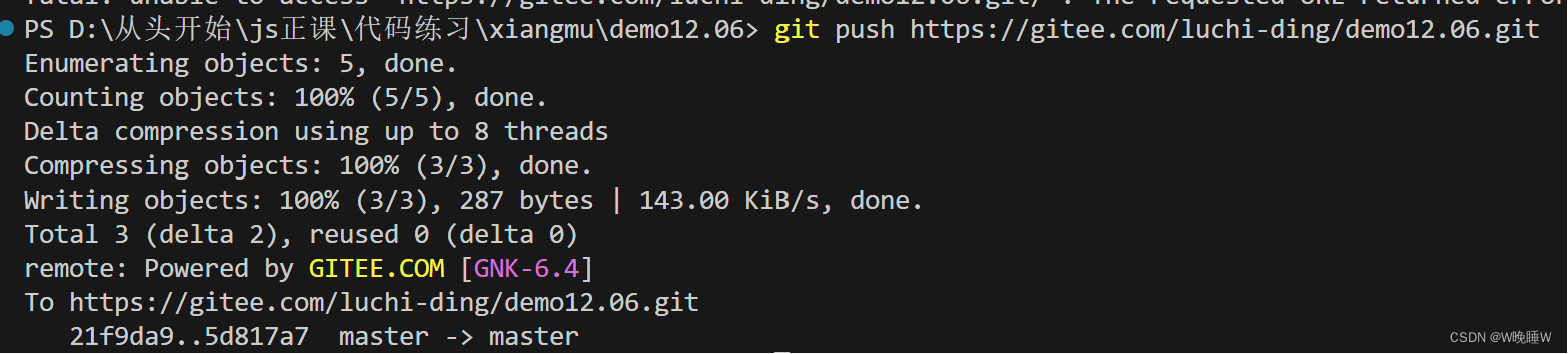
gitee对接使用
1.创建一个文件夹 2.进入Gitee接受对方项目编辑 3.打开终端初始化一开始创建的文件夹 git init 3.1打开终端 3.2输入git.init 4.克隆对方的项目 4.1进入Gitee复制对方项目的路径 4.2在编辑器终端内克隆对方项目 git clone 网址 如此你的编辑器就会出现对方的项目 …...

C语言中的一维数组与二维数组
目录 一维数组数组的创建初始化使用在内存中的存储 二维数组创建初始化使用在内存中的存储 数组越界 一维数组 数组的创建 数组是一组相同类型元素的集合。 int arr1[10]; char arr3[10]; float arr4[10]; double arr5[10];下面这个数组能否成功创建? int count…...

【Linux】地址空间
本片博客将重点回答三个问题 什么是地址空间? 地址空间是如何设计的? 为什么要有地址空间? 程序地址空间排布图 在32位下,一个进程的地址空间,取值范围是0x0000 0000~ 0xFFFF FFFF 回答三个问题之前我们先来证明地址空…...

SeqGPT-560M入门指南:Web界面操作+Jupyter调试+API调用三路径并行
SeqGPT-560M入门指南:Web界面操作Jupyter调试API调用三路径并行 1. 从零开始:认识SeqGPT-560M 如果你正在寻找一个开箱即用、能快速处理中文文本分类和信息抽取的AI工具,那么SeqGPT-560M绝对值得你花十分钟了解一下。 简单来说,…...

关于eclipse2019中导入克隆的web项目
分为导入项目和排查可能错误两个方面前言:本文主要总结个人在完成需要合作完成学习项目时,使用共享项目文件时“环境”问题导致的无法“跑通”,为此忙碌很久和豆包进行了“深入聊天”。决定对自己的问题进行总结,方便自己以后阅读…...

龙虾白嫖指南,请查收~
故障表现 发现请求集群 demo 入口时卡住,并且对应 Pod 没有新的日志输出 rootce-demo-1:~# kubectl get pods -n deepflow-otel-spring-demo -o wide NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NO…...

郭老师-永远要跟认知比你高的人在一起
永远要跟认知比你高的人在一起 ——从高人身上汲取智慧“你跟什么样的人在一起, 比你做什么样的事情重要得多。” ——巴菲特🌿 真正的成长, 不是埋头苦干, 而是—— 站在巨人的肩膀上看世界。🔭 一、认知高的人&#…...

Skywire蜂窝模组TCP客户端嵌入式框架解析
1. 项目概述klevebrand-skywire-framework-tcp-client是由 Klevebrand 公司开发的轻量级嵌入式 TCP 客户端框架,专为 Skywire(Airgain)系列蜂窝调制解调器设计。该框架并非通用 TCP 协议栈实现,而是面向特定硬件平台的AT 指令驱动…...

StreamIO:Arduino嵌入式统一I/O流与缓冲区抽象库
1. StreamIO 库概述StreamIO 是一个面向嵌入式 Arduino 生态的轻量级 I/O 抽象封装库,其核心设计目标是统一处理流式数据(Stream)与静态内存缓冲区(array buffer)的读写操作。在传统 Arduino 开发中,开发者…...

【已解决】conda环境报错:Error while loading conda entry point: conda-libmamba-solver
打算配环境装 Signac,跑基因活性矩阵来着,图省事让 Gemini 给我生成 conda 配环境的命令。它建议我用 mamba,我想也没想,直接复制它的命令在终端开始安装。 结果装好后,base 环境也出问题了,所有环境都出问…...
)
保姆级教程:在ROS Noetic下用DWA算法让无人机在已知地图里自动巡航(附完整配置文件)
无人机自主导航实战:ROS Noetic中DWA算法的深度配置与避坑指南 当你在Gazebo仿真环境中看着无人机缓缓升起,准备开始它的首次自主飞行时,那种期待与忐忑交织的感觉,想必每个ROS开发者都深有体会。本文将从实战角度出发,…...

别再让AI瞎猜了!5个实战案例教你写出让Vibe Coding一次成功的提示词
别再让AI瞎猜了!5个实战案例教你写出让Vibe Coding一次成功的提示词 当你在Vibe Coding平台上输入一串提示词,满心期待地按下生成按钮,结果却得到一个与你想象中完全不同的产物——这种经历相信很多开发者都不陌生。为什么AI总是"误解&q…...

2025届最火的十大降AI率方案实际效果
Ai论文网站排名(开题报告、文献综述、降aigc率、降重综合对比) TOP1. 千笔AI TOP2. aipasspaper TOP3. 清北论文 TOP4. 豆包 TOP5. kimi TOP6. deepseek 在当下,关于AI生成内容的检测变得越发严格起来,于是降AI工具就相应地…...