PySpark大数据处理详细教程

欢迎各位数据爱好者!今天,我很高兴与您分享我的最新博客,专注于探索 PySpark DataFrame 的强大功能。无论您是刚入门的数据分析师,还是寻求深入了解大数据技术的专业人士,这里都有丰富的知识和实用的技巧等着您。让我们一起潜入 PySpark 的世界,解锁数据处理和分析的无限可能!
基础操作
基础操作涵盖了数据的创建、加载、查看、选择、过滤、转换、聚合、排序、合并和导出等基本操作。
1.数据创建和加载
# 读取 CSV 文件
df = spark.read.csv("path/to/file.csv", header=True, inferSchema=True)# 读取 HIVE 表
hive_sql = f"select * from {DATABASE}.{TABLE_NAME} {CONDITION}"
df = spark.sql(hive_sql)# 读取 Parquet 文件
parquet_file = "path/to/parquet/file"
df = spark.read.parquet(parquet_file)
2.数据查看和检查
df.show(2,truncate=False)
df.printSchema()
3.查看分位数
quantiles = df.approxQuantile("salary", [0.25, 0.5, 0.75], 0)
# col:要计算分位数的列名,为字符串类型。
# probabilities:一个介于 0 和 1 之间的数字列表,表示要计算的分位数。例如,0.5 表示中位数。
# relativeError:相对误差。这是一个非负浮点数,用于控制计算精度。
# 值为 0 表示计算精确的分位数(可能非常耗时)。
# 随着该值的增加,计算速度会提高,但精度会降低。例如,如果 relativeError 为 0.01,则计算结果与真实分位数的差距在真实分位数的 1% 范围内。
4.数据选择和过滤
df.select("column1").show()
df.filter(df["column1"] > 100).show()# 或者
df.filter(F.col("column1") > 100).show()
5.数据转换和操作
df.withColumn("new_column", F.col("column1").cast("int"))).show()df.withColumn("new_column", df["column1"] + F.lit(100)).show()
df.withColumn("new_column", F.col("column1") + F.lit(100)).show()df.drop("column1").show()
6.数据聚合和分组
df.groupBy("column1").count().show()df.groupBy("column1")agg.(F.count(F.col("id"))).show()
7.排序和排名取TopN
df.orderBy(df["column1"].desc()).show()
df.orderBy(F.col("column1").desc()).show()
8.数据合并和连接
df1.join(df2, df1["column"] == df2["column"]).show()# 或者
from functools import reduce
from pyspark.sql import DataFrame
dataframes = [df1,df2,df3]
union_df = reduce(DataFrame.union, dataframes)
9.缺失值和异常值处理
df.na.fill({"column1": 0}).show()
10.数据转换和类型转换
df.withColumn("column_casted", df["column1"].cast("int")).show()
11.数据导出和写入
# 存储 DataFrame 为CSV
df.write.csv("path/to/output.csv")
# 存储 DataFrame 为HIVE
df.write.format("orc").mode("overwrite").saveAsTable(f"test.sample")
# 存储 DataFrame 为 Parquet 文件
output_path = "path/to/output/directory"
df.write.parquet(output_path)
高级操作
高级操作包括更复杂的数据处理技术、特征工程、文本处理和高级 SQL 查询。
1.数据分区和优化
df.repartition(10).write.parquet("path/to/output")
2.数据探索和分析
df.describe().show()
# 或者
df.summary().show())
3.复杂数据类型处理
from pyspark.sql.functions import explode
df.withColumn("exploded_col", explode(df["array_col"])).show()
4.特征工程
from pyspark.ml.feature import StringIndexer
indexer = StringIndexer(inputCol="category", outputCol="category_index")
df_indexed = indexer.fit(df).transform(df)
5.文本数据处理
from pyspark.ml.feature import Tokenizer
tokenizer = Tokenizer(inputCol="text", outputCol="words")
df_words = tokenizer.transform(df)
6.高级 SQL 查询
df.createOrReplaceTempView("table")
spark.sql("SELECT * FROM table WHERE column1 > 100").show()
进阶操作
进阶操作涵盖了性能调优、与其他数据源的集成和数据流处理,这些通常需要更深入的理解和经验。
1.性能调优和监控
df.explain()
2.与其他数据源集成
df_jdbc = spark.read \.format("jdbc") \.option("url", "jdbc:mysql://your-db-url") \.option("dbtable", "tablename") \.option("user", "username") \.option("password", "password") \.load()
3.数据流处理
df_stream = spark.readStream \.schema(df_schema) \.option("maxFilesPerTrigger", 1) \.json("/path/to/directory/")
4.使用 Structured Streaming
stream_query = df_stream.writeStream \.outputMode("append") \.format("console") \.start()
stream_query.awaitTermination()
这些示例提供了对 PySpark 操作的广泛了解,从基础到进阶,涵盖了数据处理和分析的多个方面。对于更复杂的场景和高级功能,强烈建议查阅 PySpark 的官方文档和相关教程。

相关文章:
PySpark大数据处理详细教程
欢迎各位数据爱好者!今天,我很高兴与您分享我的最新博客,专注于探索 PySpark DataFrame 的强大功能。无论您是刚入门的数据分析师,还是寻求深入了解大数据技术的专业人士,这里都有丰富的知识和实用的技巧等着您。让我们…...
ts非基础类型(对象))
三(五)ts非基础类型(对象)
在ts里面定义对象的方式也有很多。 普通定义 let obj1:{} {} // obj1.name fufu 报错,只能定义为空对象且不能修改 // 但是可以在赋初始值的时候直接添加属性,这是ts在类型推断时,它会宽容地匹配对象的结构。 let obj2:{} {name: fufu}…...
HeartBeat监控Redis状态
目录 一、概述 二、 安装部署 三、配置 四、启动服务 五、查看数据 一、概述 使用heartbeat可以实现在kibana界面对redis服务存活状态进行观察,如有必要,也可在服务宕机后立即向相关人员发送邮件通知 二、 安装部署 参照文章:HeartBeat监…...

FairGuard无缝兼容小米澎湃OS、ColorOS 14 、鸿蒙4!
随着移动互联网时代的发展,各大手机厂商为打造生态系统、构建自身的技术壁垒,纷纷投身自研操作系统。 而对于一款游戏安全产品,在不同操作系统下,是否能够无缝兼容并且提供稳定的、高强度的加密保护,成了行业的一大痛…...
【Copilot】Edge浏览器的copilot消失了怎么办
这种原因,可能是因为你的ip地址的不在这个服务的允许范围内。你需要重新使用之前出现copilot的ip地址,然后退出edge的账号,重新登录一遍,最后重启edge,就能够使得copilot侧边栏重新出现了。...

C++入门【6-C++ 修饰符类型】
C 修饰符类型 C 允许在 char、int 和 double 数据类型前放置修饰符。 修饰符是用于改变变量类型的行为的关键字,它更能满足各种情境的需求。 下面列出了数据类型修饰符: signed:表示变量可以存储负数。对于整型变量来说,signe…...

STP笔记总结
STP --- 生成树协议 STP(Spanning Tree Protocol,生成树协议)是根据 IEEE802.1D标准建立的,用于在局域网中消除数据链路层环路的协议。运行STP协议的设备通过彼此交互信息发现网络中的环路,并有选择地对某些端口进行阻…...
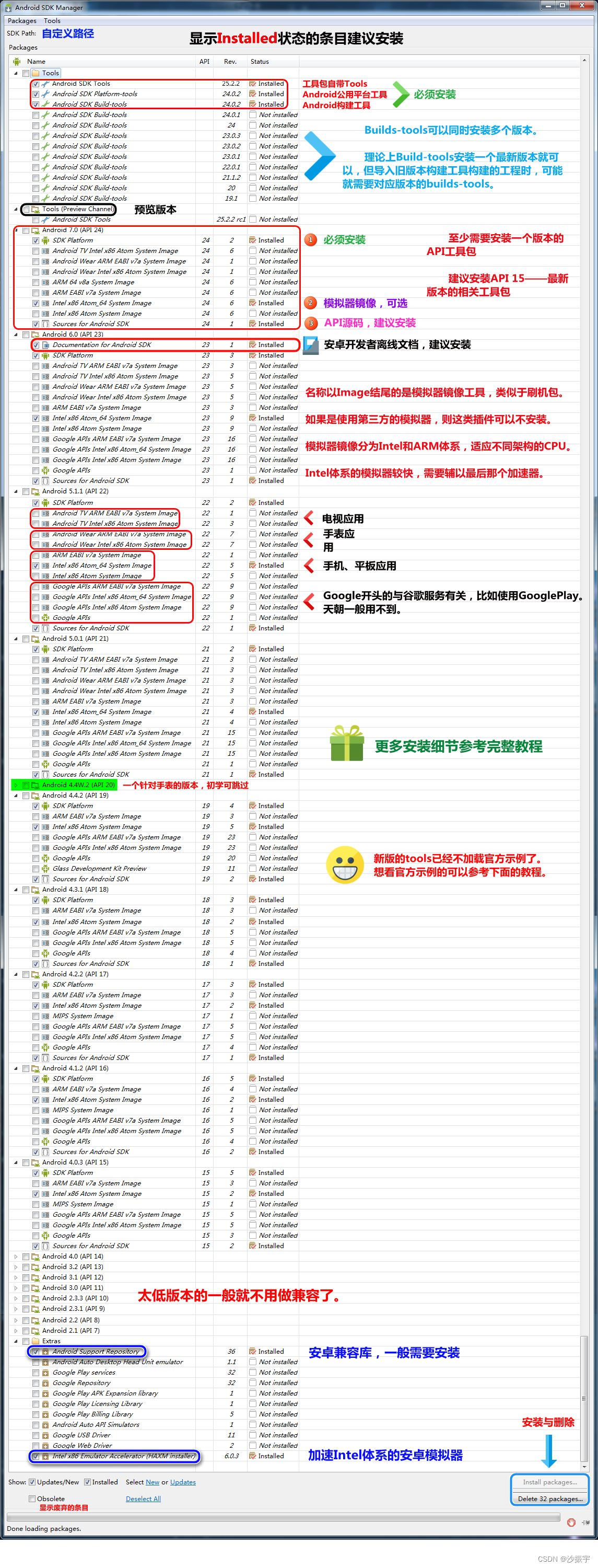
Qt开发 之 记一次安装 Qt5.12.12 安卓环境的失败案例
文章目录 1、安装Qt2、安卓开发的组合套件2.1、CSDN地址2.2、官网地址2.3、发现老方法不适用了 3、尝试用新方法解决3.1、先安装JDK,搞定JDK环境变量3.1.1、安装jdk3.1.2、确定jdk安装路径3.1.3、打开系统环境变量配置3.1.4、配置系统环境变量3.1.5、验证JDK环境变量…...
基于SpringBoot的就业信息管理系统设计与实现(源码+数据库+文档)
摘 要 在新冠肺炎疫情的影响下,大学生的就业问题已经变成了一个引起人们普遍重视的社会焦点问题。在这次疫情的冲击之下,大学生的就业市场的供求双方都受到了不同程度的影响,大学生的就业情况并不十分乐观。目前,各种招聘平台上…...
Java IO流)
Java面试整理(四)Java IO流
我记得自己刚开始学Java的时候,都听过师兄的分享,说IO流是很重要,而且很难。 自己正式接触之后,其实IO流这块知识并不是特别难,而且随着IT的发展,IO流这块反而用得不是很多。特别是在应用开发这个层面,用得更少。 当然,可能会有朋友跳出来说“这怎么可能?你不懂Java吧…...
《安富莱嵌入式周报》第328期:自主微型机器人,火星探测器发射前失误故障分析,微软推出12周24期免费AI课程,炫酷3D LED点阵设计,MDK5.39发布
周报汇总地址:嵌入式周报 - uCOS & uCGUI & emWin & embOS & TouchGFX & ThreadX - 硬汉嵌入式论坛 - Powered by Discuz! 更新一期视频教程: 【实战技能】 单步运行源码分析,一期视频整明白FreeRTOS内核源码框架和运行…...
产品经理在项目周期中扮演的角色Axure的安装与基本使用
目录 一.项目周期流程 二.Axure是什么 三.Axure安装 3.1 一键式安装 3.2 汉化 3.3 授权登录 四.Axure的界面介绍及基本使用 4.1 菜单栏的使用 4.2 工具栏的使用 4.3 页面概要的使用及组件的使用 4.4 组件的样式设计 一.项目周期流程 在一般的项目周期中包含的工作内容有&…...
Dockerfile创建镜像介绍
1.介绍 Docker 提供了一种更便捷的方式,叫作 Dockerfile,docker build命令用于根据给定的Dockerfile构建Docker镜像。 docker build语法: # docker build [OPTIONS] <PATH | URL | -> 常用选项说明 --build-arg,设置构建时的…...

Android 滥用 SharedPreference 导致 ANR 问题
SharedPreference 是 Android 平台提供的一种轻量级的数据存储方式,它用于存储应用的配置信息或者一些简单的数据。SharedPreference 基于键值对的存储,并且支持基本的数据类型,如整型、字符串、布尔值等。它的使用非常简单方便,适…...

虚幻商城 道具汇总
文章目录 载具Vehicle Variety Pack(车辆品种包)Vehicle Variety Pack Volume 2(车辆品种包第 2 卷)家具Free Furniture Pack(免费家具包)Old West - VOL 1 - Interior Furniture(旧西部 - 第1卷 - 家具包)Old West VOL.3 - Travel Supplies and Goods(旧西部 - 第3卷…...
docker: Error response from daemon: failed to create shim task: OCI runtime
1 概述 在解决"Docker: Error response from daemon: failed to create shim task: OCI runtime"问题之前,我们先来了解一下Docker和OCI runtime的基本概念。 Docker是一个开源的应用容器引擎,可以帮助开发者将应用程序和其依赖打包到一个可…...
SpringBoot+线程池实现高频调用http接口并多线程解析json数据
场景 SpringbootFastJson实现解析第三方http接口json数据为实体类(时间格式化转换、字段包含中文): SpringbootFastJson实现解析第三方http接口json数据为实体类(时间格式化转换、字段包含中文)-CSDN博客 Java中ExecutorService线程池的使用(Runnable和Callable多…...
背景/需求)
java实现局域网内视频投屏播放(一)背景/需求
一 背景 我们在用电视上投屏电影或者电视剧时,如果没有vip,用盗版电影网站投屏的话会有两个问题,1:他们网站没有投屏功能。2:卡!!!。还有就是不能随心所欲的设置自己先要自动播放的视频列表(如…...

【Spring】手写一个简易starter
需求: 自定义一个starter,里面包含一个TimeLog注解和一个TimeLogAspect切面类,用于统计接口耗时。要求在其它项目引入starter依赖后,启动springboot项目时能进行自动装配。 步骤: (1)引入pom依赖…...
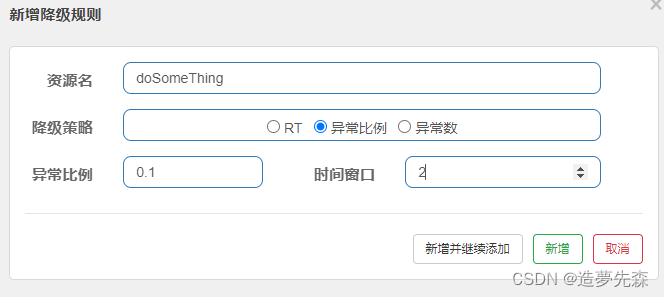
Spring Cloud Alibaba实践 --Sentinel
sentinel介绍 Sentinel的官方标题是:分布式系统的流量防卫兵。从名字上来看,很容易就能猜到它是用来作服务稳定性保障的。对于服务稳定性保障组件,如果熟悉Spring Cloud的用户,第一反应应该就是Hystrix。但是比较可惜的是Netflix…...

传感器与变送器:工业自动化的感知与信号处理核心
1. 传感器与变送器的核心差异解析在工业自动化领域,传感器和变送器就像人的感官神经与语言翻译系统。传感器如同触觉、视觉等感官末梢,直接感知外界物理量变化;而变送器则像专业的同声传译,将原始感知信息转化为标准化的表达方式。…...

手把手教你用objdump和readelf破解ELF文件:从代码节修改到目标输出
深入解析ELF文件:从代码节定位到二进制修改实战 在Linux系统开发与逆向工程领域,理解ELF(Executable and Linkable Format)文件结构是每位开发者必备的核心技能。ELF作为Unix-like系统标准的可执行文件格式,承载着程序运行的完整信息架构。本…...

ModTheSpire终极指南:5个技巧让杀戮尖塔模组加载零烦恼
ModTheSpire终极指南:5个技巧让杀戮尖塔模组加载零烦恼 【免费下载链接】ModTheSpire External mod loader for Slay The Spire 项目地址: https://gitcode.com/gh_mirrors/mo/ModTheSpire 厌倦了每次想体验新模组都要手动修改游戏文件的繁琐操作吗ÿ…...

三步掌握Alienware终极控制权:AlienFX Tools新手完全指南
三步掌握Alienware终极控制权:AlienFX Tools新手完全指南 【免费下载链接】alienfx-tools Alienware systems lights, fans, and power control tools and apps 项目地址: https://gitcode.com/gh_mirrors/al/alienfx-tools 你是否厌倦了Alienware官方软件的…...

LuatOS固件玩转多摄像头:Air8101开发板的USB端口切换技巧大全
LuatOS固件玩转多摄像头:Air8101开发板的USB端口切换技巧大全 在工业检测和安防监控领域,多摄像头系统的动态切换能力往往决定着整个方案的灵活性与可靠性。Air8101开发板搭载LuatOS固件后,其USB端口管理功能为开发者提供了前所未有的摄像头控…...

Qwen3-4B-Instruct镜像免配置:一键拉起暗黑WebUI实操指南
Qwen3-4B-Instruct镜像免配置:一键拉起暗黑WebUI实操指南 无需复杂配置,无需GPU设备,5分钟拥有自己的AI写作大师 1. 为什么选择这个镜像? 如果你正在寻找一个既强大又容易上手的AI写作助手,这个Qwen3-4B-Instruct镜像…...

【Matter】Ubuntu 22.04下chip-tool编译实战:避坑指南与代理配置详解
1. Ubuntu 22.04环境准备与基础配置 在开始编译Matter的chip-tool之前,我们需要先准备好Ubuntu 22.04的开发环境。这个环节虽然基础,但往往决定了后续编译过程的顺利程度。我曾在多个项目中验证过,一个干净的Ubuntu 22.04系统是最稳定的编译环…...

ArcMap10.4.1中文版地图数字化技巧:如何高效捕捉和数字化等高线
ArcMap 10.4.1中文版等高线数字化实战:从基础操作到效率倍增技巧 在GIS数据处理中,等高线数字化是地形分析的基础环节,也是许多项目中最耗时的步骤之一。我曾参与过一个山区防洪规划项目,团队需要处理超过200平方公里的1:10000地形…...

新手友好:告别visio下载烦恼,用快马AI代码学画架构图
作为一个刚接触编程的新手,想要画个简单的系统架构图却卡在了Visio下载和操作上,这种经历我太熟悉了。最近发现用代码直接画图其实没那么难,特别是在InsCode(快马)平台上尝试后,发现整个过程意外地顺畅。这里分享下我的学习过程&a…...

ARM Cortex-M开发避坑指南:DMB、DSB、ISB这三个内存屏障指令到底该怎么用?
ARM Cortex-M内存屏障实战手册:DMB/DSB/ISB的精准选择与避坑策略 当你在调试一个间歇性出现的DMA传输错误时,是否曾怀疑过是内存访问顺序的问题?在RTOS任务切换后寄存器值莫名其妙改变的场景中,是否考虑过指令流水线的影响&#x…...