【NLP】RAG 应用中的调优策略

检索增强生成应用程序的调优策略
没有一种放之四海而皆准的算法能够最好地解决所有问题。
本文通过数据科学家的视角审视检索增强生成(RAG)管道。它讨论了您可以尝试提高 RAG 管道性能的潜在“超参数”。与深度学习中的实验类似,例如,数据增强技术不是超参数,而是可以调整和实验的旋钮,本文还将介绍您可以应用的不同策略,这些策略本身不是超参数。
本文涵盖以下按相关阶段排序的“超参数”。在RAG 管道的
摄取阶段,您可以通过以下方式实现性能改进:
- 数据清洗
- 分块
- 嵌入模型
- 元数据
- 多重索引
- 索引算法
在推理阶段(检索和生成),您可以调整:
- 查询转换
- 检索参数
- 高级检索策略
- 重新排序模型
- LLM
- 及时工程
请注意,本文涵盖了 RAG 的文本用例。对于多模式 RAG 应用,可能需要考虑不同的因素。
摄取阶段
摄取阶段是构建 RAG 管道的准备步骤,类似于 ML 管道中的数据清理和预处理步骤。通常,摄取阶段包括以下步骤:
- 收集数据
- 块数据
- 生成块的向量嵌入
- 将向量嵌入和块存储在向量数据库中
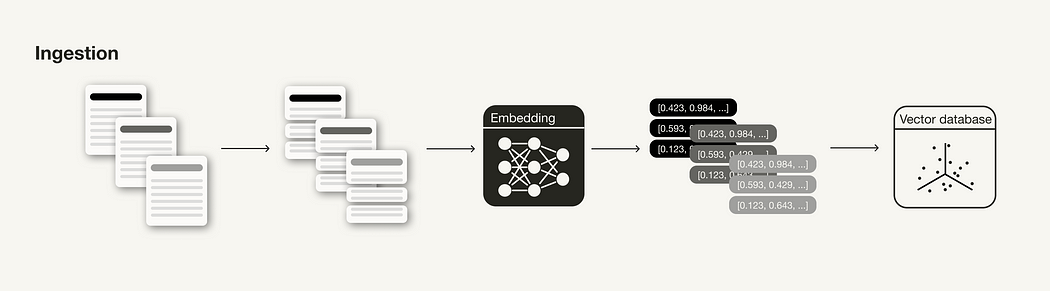
RAG 管道的摄取阶段
本节讨论有影响力的技术和超参数,您可以应用和调整这些技术和超参数,以提高推理阶段检索到的上下文的相关性。
数据清洗
与任何数据科学管道一样,数据质量会严重影响 RAG 管道中的结果 。在继续执行以下任何步骤之前,请确保您的数据满足以下条件:
- 清洗:至少应用自然语言处理中常用的一些基本数据清理技术,例如确保所有特殊字符都正确编码。
- 准确:确保您的信息一致且事实准确,以避免信息冲突使您的LLM感到困惑。
分块
对文档进行分块是 RAG 管道中外部知识源的重要准备步骤,这可能会影响性能 。它是一种生成逻辑上连贯的信息片段的技术,通常是将长文档分解成较小的部分(但它也可以将较小的片段组合成连贯的段落)。
您需要考虑的一项是分块技术的选择。例如,在LangChain中,不同的文本拆分器通过不同的逻辑来拆分文档,例如按字符、令牌等。这取决于您拥有的数据类型。例如,如果您的输入数据是代码,则您将需要使用不同的分块技术,如果它是 Markdown 文件,您将需要使用不同的分块技术。
块 ( chunk_size)的理想长度取决于您的用例:如果您的用例是问答,您可能需要较短的特定块,但如果您的用例是摘要,您可能需要更长的块。此外,如果块太短,它可能无法包含足够的上下文。另一方面,如果块太长,它可能包含太多不相关的信息。
此外,您需要考虑块之间的“滚动窗口”( overlap)以引入一些额外的上下文。
嵌入模型
嵌入模型是检索的核心。嵌入的质量会严重影响您的检索结果。通常,生成的嵌入的维数越高,嵌入的精度就越高。
要了解可用的替代嵌入模型,您可以查看大规模文本嵌入基准 (MTEB) 排行榜,其中涵盖 164 个文本嵌入模型(在撰写本文时)。
虽然您可以开箱即用地使用通用嵌入模型,但在某些情况下,根据您的特定用例微调嵌入模型可能是有意义的,以避免稍后出现域外问题 。根据 LlamaIndex 进行的实验,微调嵌入模型可以使检索评估指标的性能提高 5-10% 。
请注意,您无法微调所有嵌入模型(例如,OpenAItext-ebmedding-ada-002目前无法微调)。
元数据
当您将矢量嵌入存储在矢量数据库中时,某些矢量数据库允许您将它们与元数据(或未矢量化的数据)存储在一起。使用元数据注释向量嵌入有助于对搜索结果进行额外的后处理,例如元数据过滤[1,3,8,9]。例如,您可以添加元数据,例如日期、章节或子章节参考。
多重索引
如果元数据不足以提供附加信息来逻辑地分隔不同类型的上下文,您可能需要尝试使用多个索引。例如,您可以对不同类型的文档使用不同的索引。请注意,您必须在检索时合并一些索引路由。
索引算法
为了实现大规模快速相似性搜索,矢量数据库和矢量索引库使用近似最近邻 (ANN) 搜索而不是 k 最近邻 (kNN) 搜索。顾名思义,ANN 算法近似最近邻,因此可能不如 kNN 算法精确。。
您可以尝试不同的 ANN 算法,例如Facebook Faiss(聚类)、Spotify Annoy(树)、Google ScaNN(矢量压缩)和HNSWLIB(邻近图)。此外,许多 ANN 算法都有一些您可以调整的参数,例如HNSW的ef、efConstruction和maxConnections。
此外,您可以为这些索引算法启用矢量压缩。与 ANN 算法类似,矢量压缩会损失一些精度。但是,根据矢量压缩算法的选择及其调整,您也可以对此进行优化。
然而,在实践中,这些参数已经由向量数据库和向量索引库的研究团队在基准测试过程中调整,而不是由 RAG 系统的开发人员调整。但是,如果您想尝试使用这些参数来发挥最后的性能,我建议您从这篇文章开始:
推理阶段(检索和生成)
RAG 管道的主要组件是检索组件和生成组件。本节主要讨论改进检索的策略(查询转换、检索参数、高级检索策略和重新排序模型),因为这是两者中影响更大的部分。但它也简要介绍了一些提高生成的策略(LLM和即时工程)
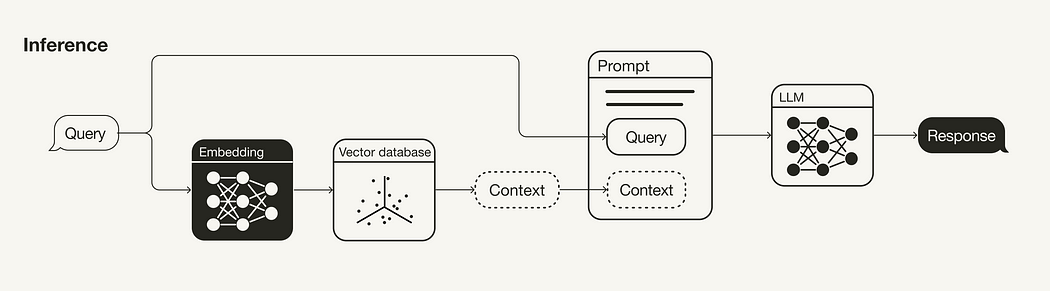
RAG 管道的推理阶段
查询转换
由于在 RAG 管道中检索附加上下文的搜索查询也嵌入到向量空间中,因此其措辞也会影响搜索结果。因此,如果您的搜索查询没有产生令人满意的搜索结果,您可以尝试各种查询转换技术,例如:
- 重新措辞:使用LLM重新措辞查询并重试。
- 假设文档嵌入 (HyDE):使用 LLM 生成对搜索查询的假设响应,并将两者用于检索。
- 子查询:将较长的查询分解为多个较短的查询。
检索参数
检索是 RAG 管道的重要组成部分。首先要考虑的是语义搜索是否足以满足您的用例,或者您是否想尝试混合搜索。
在后一种情况下,您需要在混合搜索中尝试对稀疏和密集检索方法的聚合进行加权。因此,调整参数alpha来控制语义 (alpha = 1 ) 和基于关键字的搜索 (alpha = 0 )之间的权重将变得必要。
此外,要检索的搜索结果的数量也将发挥重要作用。检索到的上下文数量将影响所使用的上下文窗口的长度。此外,如果您使用重新排名模型,则需要考虑向模型输入多少上下文。
请注意,虽然语义搜索使用的相似性度量是一个可以更改的参数,但您不应该对其进行实验,而是根据使用的嵌入模型进行设置(例如,text-embedding-ada-002支持余弦相似性或multi-qa-MiniLM-l6-cos-v1支持余弦相似性、点积和欧几里得距离) )。
高级检索策略
从技术上讲,本节可以单独成一篇文章。对于本概述,我们将尽可能保持简洁。
本节的基本思想是用于检索的块不一定与用于生成的块相同。理想情况下,您可以嵌入较小的块进行检索,但检索更大的上下文。
- 句子窗口检索:不只是检索相关句子,而是检索检索到的句子之前和之后的适当句子的窗口。
- 自动合并检索:文档以树状结构组织。在查询时,独立但相关的较小块可以合并到更大的上下文中。
重新排列模型
虽然语义搜索根据与搜索查询的语义相似性来检索上下文,但“最相似”并不一定意味着“最相关”。重新排序模型(例如Cohere的重新排序模型)可以通过计算每个检索到的上下文的查询相关性的分数来帮助消除不相关的搜索结果 。
“最相似”并不一定意味着“最相关”
如果您使用重新排序模型,您可能需要重新调整重新排序输入的搜索结果数量以及您想要输入 LLM 的重新排序结果数量。
与嵌入模型一样,您可能需要尝试根据您的特定用例微调重新排序器。
LLM
LLM是生成回复的核心组件。与嵌入模型类似,您可以根据自己的要求选择多种 LLM,例如开放模型与专有模型、推理成本、上下文长度等。
与嵌入模型或重新排序模型一样,您可能需要尝试根据您的特定用例对LLM 进行微调,以纳入特定的措辞或语气。
及时工程
你如何表达或设计你的提示将显着影响LLM完成。
请仅根据搜索结果给出您的答案,不要考虑其他任何内容!很重要!您的答案必须基于所提供的搜索结果。
请解释为什么您的答案基于搜索结果!此外,在提示中使用少量示例可以提高完成的质量。
正如检索参数中提到的,输入到提示中的上下文数量是您应该尝试的一个参数 。虽然 RAG 管道的性能可以随着相关上下文的增加而提高,但您也可能会遇到“迷失在中间”的效果,即如果将相关上下文放置在许多上下文的中间,LLM 就无法识别相关上下文。上下文。
概括
随着越来越多的开发人员获得 RAG 管道原型设计的经验,讨论将 RAG 管道引入生产就绪性能的策略变得更加重要。本文讨论了不同的“超参数”以及您可以根据相关阶段在 RAG 管道中调整的其他旋钮:
本文涵盖了摄取截断的以下策略:
- 数据清理:确保数据干净且正确。
- 分块:选择分块技术、块大小 (
chunk_size) 和块重叠 (overlap)。 - 嵌入模型:嵌入模型的选择,包括。维度,以及是否对其进行微调。
- 元数据:是否使用元数据以及元数据的选择。
- 多重索引:决定是否针对不同的数据集合使用多个索引。
- 索引算法:可以调整 ANN 和矢量压缩算法的选择和调整,但通常不由从业者进行调整。
以及推理截断(检索和生成)的以下策略:
- 查询转换:尝试改写、HyDE 或子查询。
- 检索参数:搜索技术的选择(
alpha如果启用了混合搜索)和检索的搜索结果的数量。 - 高级检索策略:是否使用高级检索策略,例如句子窗口或自动合并检索。
- 重新排序模型:是否使用重排序模型、重排序模型的选择、输入重排序模型的搜索结果数量以及是否微调重排序模型。
- LLM:LLM 的选择以及是否对其进行微调。
- 及时工程:尝试不同的措辞和少量示例。
相关文章:
【NLP】RAG 应用中的调优策略
检索增强生成应用程序的调优策略 没有一种放之四海而皆准的算法能够最好地解决所有问题。 本文通过数据科学家的视角审视检索增强生成(RAG)管道。它讨论了您可以尝试提高 RAG 管道性能的潜在“超参数”。与深度学习中的实验类似,例如&am…...

Android-Framework 默认隐藏导航栏,添加控制显示属性
一、环境 高通865 Android 10 二、源码修改 device/qcom/qssi/system.prop -217,3 217,5 persist.ruichi.gpu2persist.ruichi.gpu_max587persist.ruichi.gpu_min305# Show navigation bar, 0 for display, 1 for hidden persist.navbar.status1 frameworks/base/services/…...

【AIGC】Midjourney高级进阶版
Midjourney 真是越玩越上头,真是给它的想象力跪了~ 研究了官方API,出一个进阶版教程 命令 旨在介绍Midjourney在Discord频道中的文本框中支持的指令。 1)shorten 简化Prompt 该指令可以将输入的Prompt为模型可以理解的语言。模型理解语言…...

C语言学习----指针和数组
🌈这篇blog记录一下指针学习~ 主要是关于指针和数组之间的关系,还有指针的使用等~ 🍎指针变量是一个变量 其本身也有一个地址 也需要存放,就和int char等类型一样的,也需要有一个地址来存放它 🍌而指针变量…...

学习Node.js与Webpack总结
今天学习了模块化的简介,其实一个项目是由很多个模块文件组成的,它们有它们各自的功能和用途来协助这个项目的完成,这样的模块组成有很多的好处比如提高代码的复用性、还可以按需加载、还有独立的作用域,还需要搞清楚的一点就是No…...

JAVA基础知识:泛型
一、什么是泛型? 泛型是Java中的一种参数化类型机制,它允许在类或方法的声明中使用类型参数,以实现代码的通用性和类型安全性。通过使用泛型,我们可以编写更加灵活和可复用的代码,同时减少类型转换错误的可能性。 二、…...
【WinRAR】为什么右键没有压缩选项?
我们安装了WinRAR之后想要压缩文件,但是右键点击文件之后发现并没有WinRAR压缩选项,这应该如何设置才能出现右键带有压缩选项呢?方法如下: 首先打开WinRAR,在上面功能中点击选项 – 设置 然后我们在设置界面中切换到集…...

数据云:数据基础设施的一小步,数字经济的一大步
随着数字经济的崛起,数据正成为推动社会发展和经济增长的核心要素。在这个数字化时代,数据已经被誉为新的生产要素,是数字经济发展的基础性资源和战略性资源。为了更好地支持数据的汇聚、流通和应用,数据基础设施迎来了一次重要的…...
极兔速递查询,极兔速递单号查询,筛选出指定派件员的单号
批量查询极兔速递单号的物流信息,并将指定派件员的单号筛选出来。 所需工具: 一个【快递批量查询高手】软件 极兔速递单号若干 操作步骤: 步骤1:运行【快递批量查询高手】软件,第一次使用的朋友记得先注册ÿ…...

条款25:考虑写出一个不抛出异常的swap函数
1.前言 swap是个有趣的函数,原本它只是STL的一部分,而后成为异常安全编程的基石,以及用来处理自我赋值可能性的一个常见机制。由于swap功能如此强大,适当的实现很重要。然而在非凡的重要性之外它也带来了非凡的复杂度。 所谓swa…...

linux 中crontab 定时任务计划创建时间文件夹示例
1.创建一个sh脚本 /usr/bin/mkdir 是mkdir命令的路径 /usr/bin/chmod 是chmod命令的路径 2.编辑定时任务 crontab -e...

欣赏动态之美,不如欣赏C语言实现动态内存管理之美 ! ! !
本篇会加入个人的所谓‘鱼式疯言’ ❤️❤️❤️鱼式疯言:❤️❤️❤️此疯言非彼疯言 而是理解过并总结出来通俗易懂的大白话, 我会尽可能的在每个概念后插入鱼式疯言,帮助大家理解的. 可能说的不是那么严谨.但小编初心是能让更多人能接受我们这个概念 !࿰…...

from pycocotools.coco import COCO报错
需要注意的是,自己的系统是windows还是linux的系统: windows系统的安装: pip install pycocotools-windows linux的系统安装: pip install pycocotools 别用错了命令哦!...
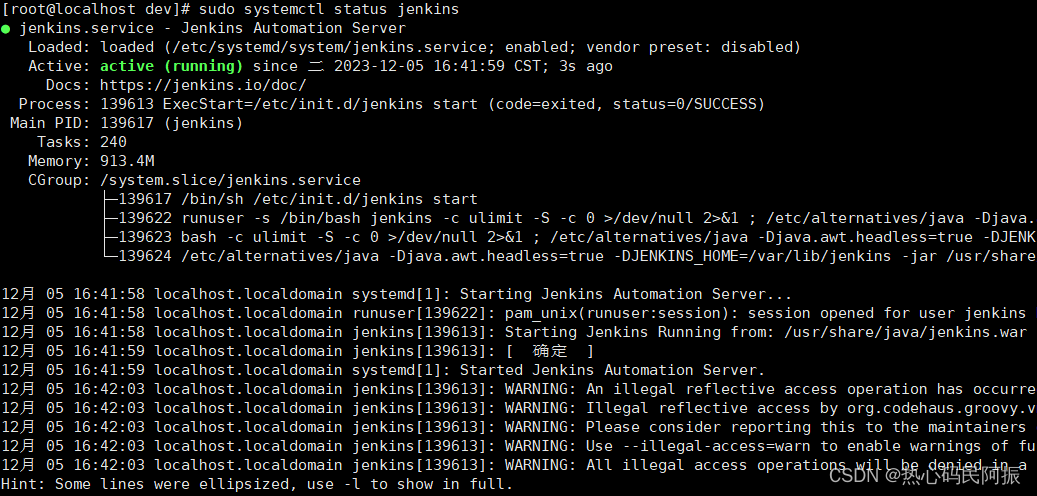
CentOS服务自启权威指南:手动启动变为开机自启动(以Jenkins服务为例)
前言 CentOS系统提供了多种配置服务开机自启动的方式。本文将介绍其中两种常见的方式, 一种是使用Systemd服务管理器配置,不过,在实际中,如果你已经通过包管理工具安装的,那么服务通常已经被配置为Systemd服务&#…...

第二百零一回 介绍一个三方包open_settings
文章目录 1. 概念介绍2 使用方法3 代码与效果3.1 示例代码3.2 运行效果 4. 经验分享 我们在上一章回中介绍了Form Widget相关的内容,本章回中将介绍Form系列组件的验证与提交功能.闲话休提,让我们一起Talk Flutter吧。 1. 概念介绍 我们在这里说的的验…...
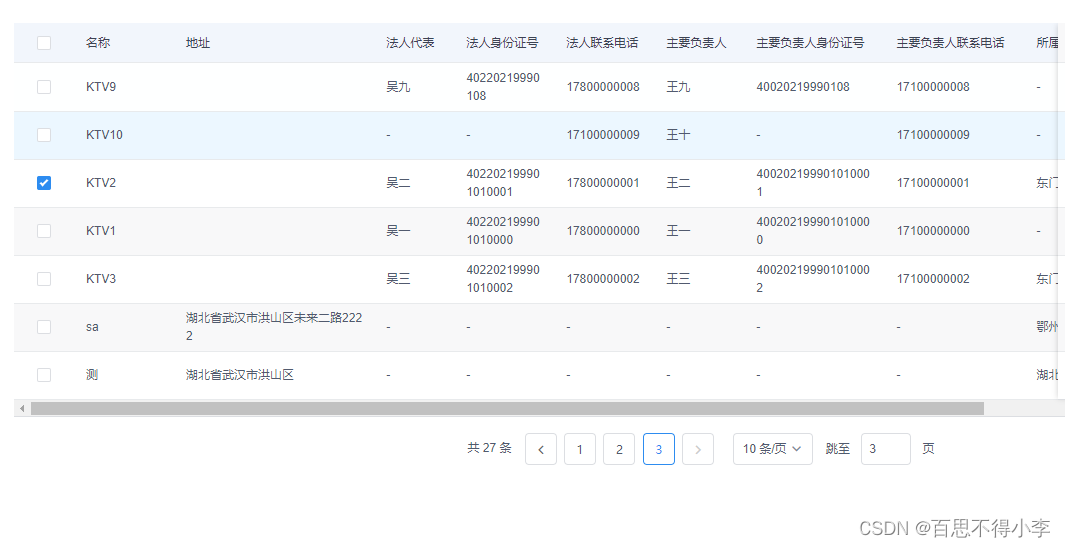
iview Table实现跨页勾选记忆功能以及利用ES6的Map数据结构实现根据id进行对象数组的去重
因为iview Table组件的勾选是选中当前页的所有数据,当我们切到别的页面时,会发送请求给后端,这个时候就会刷新我们之前页码已经选中的数据。现在有个需求就是,在我们选择不同页码的数据勾选中之后,实现跨页勾选记忆功能,就是说已经打钩了的数据,不管切到哪一页它都是打钩…...
【Spring 源码】 贯穿 Bean 生命周期的核心类之 AbstractAutowireCapableBeanFactory
🚀 作者主页: 有来技术 🔥 开源项目: youlai-mall 🍃 vue3-element-admin 🍃 youlai-boot 🌺 仓库主页: Gitee 💫 Github 💫 GitCode 💖 欢迎点赞…...
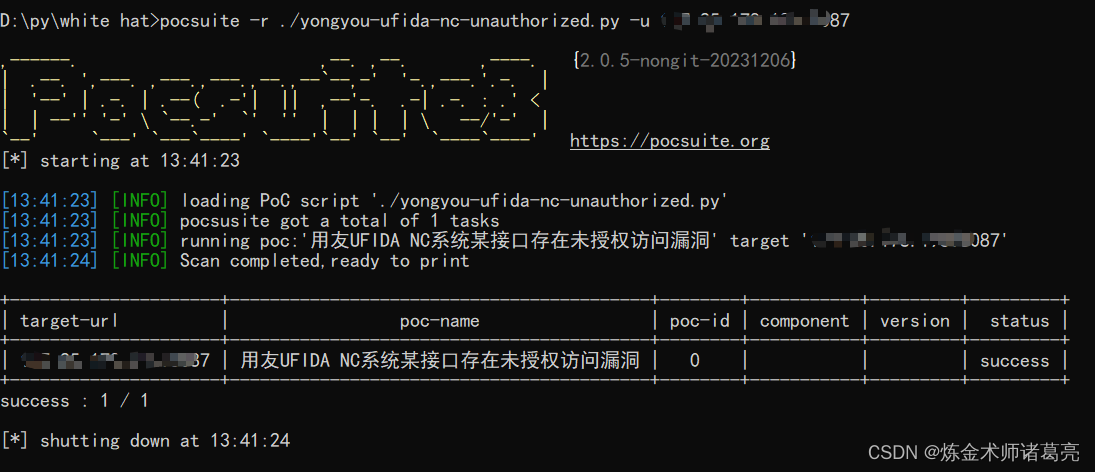
漏洞复现-某友UFIDA NC系统某接口未授权访问漏洞(附漏洞检测脚本)
免责声明 文章中涉及的漏洞均已修复,敏感信息均已做打码处理,文章仅做经验分享用途,切勿当真,未授权的攻击属于非法行为!文章中敏感信息均已做多层打马处理。传播、利用本文章所提供的信息而造成的任何直接或者间接的…...

树莓派5安装opencv
1 建立虚拟环境 参考网站 https://www.piwheels.org/faq.html#venv 虚拟环境建立过程: To create a virtual environment: $ sudo apt install virtualenv python3-virtualenv -y $ virtualenv -p /usr/bin/python3 testpip sudo apt install virtualenv pytho…...

【测试开发】Python+Django实现接口测试工具
PythonDjango接口自动化 引言: 最近被几个公司实习生整自闭了,没有基础,想学自动化又不知道怎么去学,没有方向没有头绪,说白了其实就是学习过程中没有成就感,所以学不下去。出于各种花里胡哨的原因…...

百度网盘macOS客户端下载速度技术优化方案:基于开源工具的本地部署实践
百度网盘macOS客户端下载速度技术优化方案:基于开源工具的本地部署实践 【免费下载链接】BaiduNetdiskPlugin-macOS For macOS.百度网盘 破解SVIP、下载速度限制~ 项目地址: https://gitcode.com/gh_mirrors/ba/BaiduNetdiskPlugin-macOS 问题诊断࿱…...

3种方案高效解决res-downloader配置难题:从故障诊断到场景落地
3种方案高效解决res-downloader配置难题:从故障诊断到场景落地 【免费下载链接】res-downloader 视频号、小程序、抖音、快手、小红书、直播流、m3u8、酷狗、QQ音乐等常见网络资源下载! 项目地址: https://gitcode.com/GitHub_Trending/re/res-downloader 当…...

谷歌开源Gemma 4:256K原生多模态,免费商用
谷歌刚刚发布了新一代开源大模型Gemma 4,直接把Gemini 3的核心技术下放了。2026年4月2日,谷歌如约献上复活节惊喜:Gemma 4 正式开源。从手机到服务器全覆盖四种规格,首次加入MoE架构,原生支持文本图像音频三模态&#…...
)
手把手教你用GPT-4搭建电商智能客服(附避坑指南)
电商智能客服实战:从GPT-4选型到高并发优化的全链路指南 当一位顾客深夜询问"刚买的羽绒服钻绒怎么办"时,传统客服机器人可能只会回复"请联系售后邮箱"。而搭载GPT-4的智能客服不仅能识别商品问题,还能同步提供退换货指引…...
)
Readest(电子书阅读器)
链接:https://pan.quark.cn/s/34ee49565f01Readest是一款开源电子书阅读器,专为深度阅读体验而设计。它支持多种格式,如EPUB、MOBI、KF8AZW3、FB2、CBZ以及实验性的PDF格式。这款阅读器拥有沉浸式的阅读环境,可以在滚动和页面查看…...

如何快速配置Obsidian个性化首页:从零开始的完整指南
如何快速配置Obsidian个性化首页:从零开始的完整指南 【免费下载链接】obsidian-homepage Obsidian homepage - Minimal and aesthetic template (with my unique features) 项目地址: https://gitcode.com/gh_mirrors/obs/obsidian-homepage 你是否每天打开…...

Palworld存档工具完全指南:高效管理与转换游戏数据
Palworld存档工具完全指南:高效管理与转换游戏数据 【免费下载链接】palworld-save-tools Tools for converting Palworld .sav files to JSON and back 项目地址: https://gitcode.com/gh_mirrors/pa/palworld-save-tools Palworld存档工具是一款专为Palwor…...

跨平台创意工坊下载工具:突破游戏平台限制的开源解决方案
跨平台创意工坊下载工具:突破游戏平台限制的开源解决方案 【免费下载链接】WorkshopDL WorkshopDL - The Best Steam Workshop Downloader 项目地址: https://gitcode.com/gh_mirrors/wo/WorkshopDL 当你在Epic Games平台免费领取了《求生之路2》,…...

甩掉作图焦虑,我把商业级出图压缩到10分钟,设计团队必备AI工具推荐
作为一个在设计行业熬了快十年的工作室主理人,我无数次在甲方的要求下气的想撞墙——不是因为脑子里没有创意,而是因为团队的视觉交付效率根本跟不上客户“朝令夕改”的节奏。你如果是设计师一定懂这种窒息感:早会刚定下的视觉方向࿰…...

多层循环神经网络|Multi-layer RNNs
----------------------------------------------------------------------------------------------- 这是我在我的网站中截取的文章,有更多的文章欢迎来访问我自己的博客网站rn.berlinlian.cn,这里还有很多有关计算机的知识,欢迎进行留言或…...