NLP项目实战01--电影评论分类
介绍:
欢迎来到本篇文章!在这里,我们将探讨一个常见而重要的自然语言处理任务——文本分类。具体而言,我们将关注情感分析任务,即通过分析电影评论的情感来判断评论是正面的、负面的。
展示:
训练展示如下:
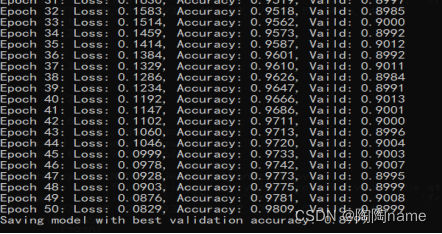
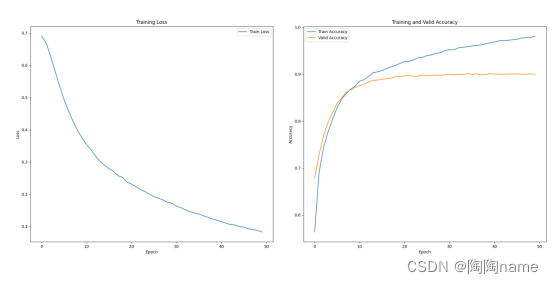
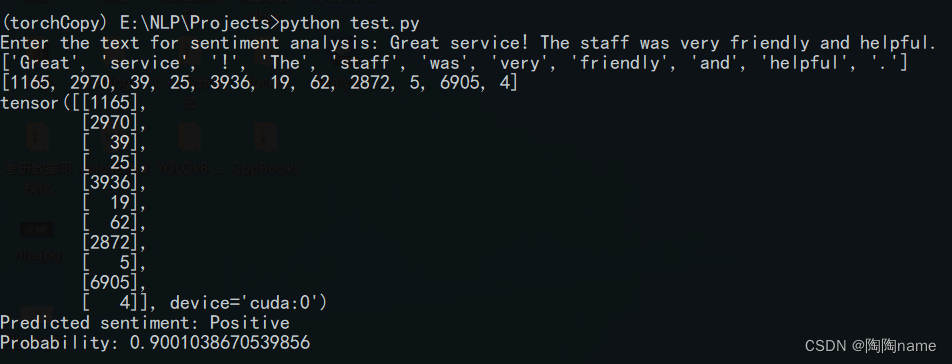
实际使用如下:
实现方式:
选择PyTorch作为深度学习框架,使用电影评论IMDB数据集,并结合torchtext对数据进行预处理。
环境:
Windows+Anaconda
重要库版本信息
torch==1.8.2+cu102
torchaudio==0.8.2
torchdata==0.7.1
torchtext==0.9.2
torchvision==0.9.2+cu102
实现思路:
1、数据集
本次使用的是IMDB数据集,IMDB是一个含有50000条关于电影评论的数据集
数据如下:
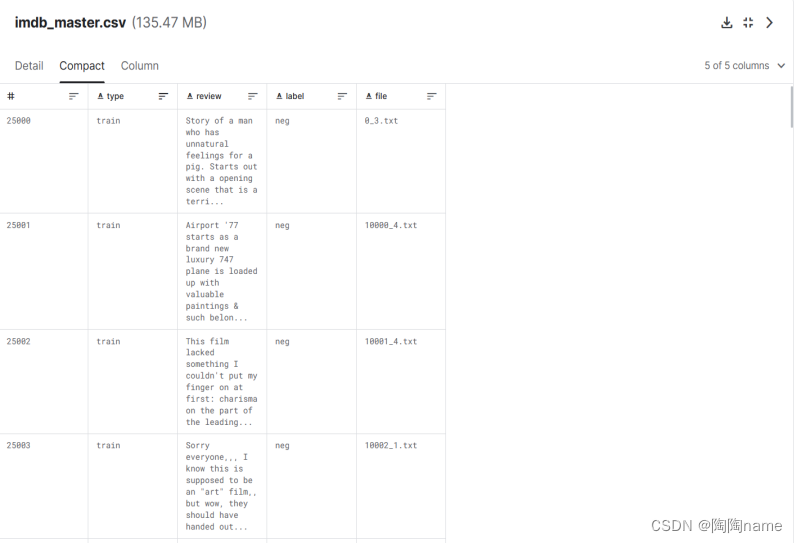
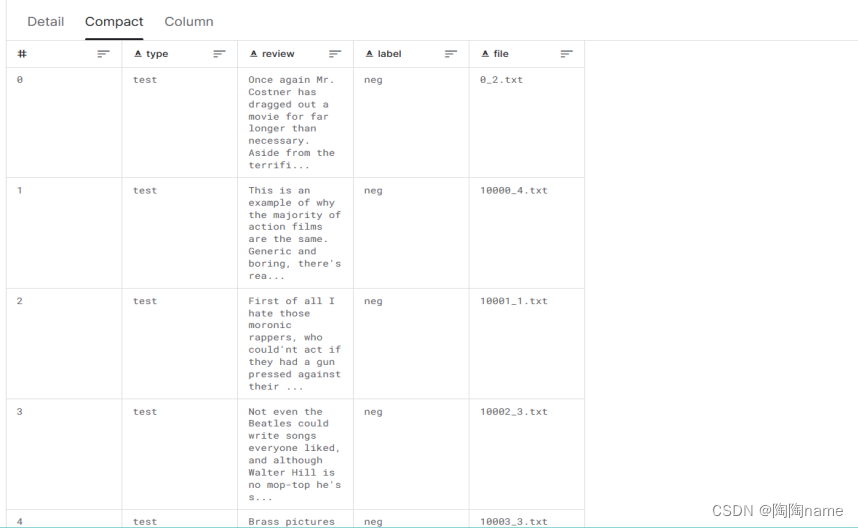
2、数据加载与预处理
使用torchtext加载IMDB数据集,并对数据集进行划分
具体划分如下:
TEXT = data.Field(tokenize='spacy', tokenizer_language='en_core_web_sm')
LABEL = data.LabelField(dtype=torch.float)
# Load the IMDB dataset
train_data, test_data = datasets.IMDB.splits(TEXT, LABEL)
创建一个 Field 对象,用于处理文本数据。同时使用spacy分词器对文本进行分词,由于IMDB是英文的,所以使用en_core_web_sm语言模型。
创建一个 LabelField 对象,用于处理标签数据。设置dtype 参数为 torch.float,表示标签的数据类型为浮点型。
使用 datasets.IMDB.splits 方法加载 IMDB 数据集,并将文本字段 TEXT 和标签字段 LABEL 传递给该方法。返回的 train_data 和 test_data 包含了 IMDB 数据集的训练和测试部分。
下面是train_data的输出

3、构建词汇表与加载预训练词向量
TEXT.build_vocab(train_data,max_size=25000,vectors="glove.6B.100d",unk_init=torch.Tensor.normal_)
LABEL.build_vocab(train_data)
train_data:表示使用train_data中数据构建词汇表
max_size:限制词汇表的大小为 25000
vectors=“glove.6B.100d”:表示使用预训练的 GloVe 词向量,其中 “glove.6B.100d” 指的是包含 100 维向量的 6B 版 GloVe。
unk_init=torch.Tensor.normal_ :表示指定未知单词(UNK)的初始化方式,这里使用正态分布进行初始化。
LABEL.build_vocab(train_data):表示对标签进行类似的操作,构建标签的词汇表
train_iterator, valid_iterator, test_iterator = data.BucketIterator.splits( (train_data, valid_data, test_data), batch_size=BATCH_SIZE, device=device)
使用data.BucketIterator.splits 来创建数据加载器,包括训练、验证和测试集的迭代器。这将确保你能够方便地以批量的形式获取数据进行训练和评估。
4、定义神经网络
这里的网络定义比较简单,主要采用在词嵌入层(embedding)后接一个全连接层的方式完成对文本数据的分类。
具体如下:
class NetWork(nn.Module):def __init__(self,vocab_size,embedding_dim,output_dim,pad_idx):super(NetWork,self).__init__()self.embedding = nn.Embedding(vocab_size,embedding_dim,padding_idx=pad_idx)self.fc = nn.Linear(embedding_dim,output_dim)self.dropout = nn.Dropout(0.5)self.relu = nn.ReLU()def forward(self,x):embedded = self.embedding(x)embedded = embedded.permute(1,0,2) pooled = F.avg_pool2d(embedded, (embedded.shape[1], 1)).squeeze(1)pooled = self.relu(pooled)pooled = self.dropout(pooled)output = self.fc(pooled)return output
5、模型初始化
vocab_size = len(TEXT.vocab)
embedding_dim = 100
output = 1
pad_idx = TEXT.vocab.stoi[TEXT.pad_token]
model = NetWork(vocab_size,embedding_dim,output,pad_idx)
pretrained_embeddings = TEXT.vocab.vectors
model.embedding.weight.data.copy_(pretrained_embeddings)
定义模型的超参数,包括词汇表大小(vocab_size)、词向量维度(embedding_dim)、输出维度(output,在这个任务中是1,因为是二元分类,所以使用1),以及 PAD 标记的索引(pad_idx)
之后需要将预训练的词向量加载到嵌入层的权重中。TEXT.vocab.vectors 包含了词汇表中每个单词的预训练词向量,然后通过 copy_ 方法将这些词向量复制到模型的嵌入层权重中对网络进行初始化。这样做确保了模型的初始化状态良好。
6、训练模型
total_loss = 0train_acc = 0
model.train()
for batch in train_iterator:optimizer.zero_grad()preds = model(batch.text).squeeze(1)loss = criterion(preds,batch.label)total_loss += loss.item()batch_acc = (torch.round(torch.sigmoid(preds)) == batch.label).sum().item()train_acc += batch_accloss.backward()optimizer.step()average_loss = total_loss / len(train_iterator)train_acc /= len(train_iterator.dataset)
optimizer.zero_grad():表示将模型参数的梯度清零,以准备接收新的梯度。
preds = model(batch.text).squeeze(1):表示一次前向传播的过程,由于model输出的是torch.tensor(batch_size,1)所以使用squeeze(1)给其中的1维度数据去除,以匹配标签张量的形状
criterion(preds,batch.label):定义的损失函数 criterion 计算预测值 preds 与真实标签 batch.label 之间的损失
(torch.round(torch.sigmoid(preds)) == batch.label).sum().item():
通过比较模型的预测值与真实标签,计算当前批次的准确率,并将其累加到 train_acc 中
后面的就是进行反向传播更新参数,还有就是计算loss和train_acc的值了
7、模型评估:
model.eval()valid_loss = 0valid_acc = 0best_valid_acc = 0with torch.no_grad():for batch in valid_iterator:preds = model(batch.text).squeeze(1)loss = criterion(preds,batch.label)valid_loss += loss.item()batch_acc = ((torch.round(torch.sigmoid(preds)) == batch.label).sum().item())valid_acc += batch_acc
和训练模型的类似,这里就不解释了
8、保存模型
这里一共使用了两种保存模型的方式:
torch.save(model, "model.pth")
torch.save(model.state_dict(),"model.pth")
第一种方式叫做模型的全量保存
第二种方式叫做模型的参数保存
全量保存是保存了整个模型,包括模型的结构、参数、优化器状态等信息
参数量保存是保存了模型的参数(state_dict),不包括模型的结构
9、测试模型
测试模型的基本思路:
加载训练保存的模型、对待推理的文本进行预处理、将文本数据加载给模型进行推理
加载模型:
saved_model_path = "model.pth"
saved_model = torch.load(saved_model_path)
输入文本:
input_text = “Great service! The staff was very friendly and helpful.”
文本进行处理:
tokenizer = get_tokenizer("spacy", language="en_core_web_sm")
tokenized_text = tokenizer(input_text)
indexed_text = [TEXT.vocab.stoi[token] for token in tokenized_text]
tensor_text = torch.LongTensor(indexed_text).unsqueeze(1).to(device)
模型推理:
saved_model.eval()
with torch.no_grad():output = saved_model(tensor_text).squeeze(1)prediction = torch.round(torch.sigmoid(output)).item()probability = torch.sigmoid(output).item()
由于笔者能力有限,所以在描述的过程中难免会有不准确的地方,还请多多包含!
更多NLP和CV文章以及完整代码请到"陶陶name"获取。
相关文章:
NLP项目实战01--电影评论分类
介绍: 欢迎来到本篇文章!在这里,我们将探讨一个常见而重要的自然语言处理任务——文本分类。具体而言,我们将关注情感分析任务,即通过分析电影评论的情感来判断评论是正面的、负面的。 展示: 训练展示如下…...

Linux vmstat命令:监控系统资源
vmstat命令,是 Virtual Meomory Statistics(虚拟内存统计)的缩写,可用来监控 CPU 使用、进程状态、内存使用、虚拟内存使用、硬盘输入/输出状态等信息。此命令的基本格式有如下 2 种: [rootlocalhost ~]# vmstat [-a…...

php爬虫规则与robots.txt讲解
在进行网页爬虫时,有一些规则需要遵守,以避免违反法律,侵犯网站隐私和版权,以及造成不必要的麻烦。以下是一些常见的PHP爬虫规则: 1. 尊重网站的使用条款:在开始爬取之前,请确保你阅读并理解了…...

Ray使用备注
Ray使用备注 框架介绍 Ray是一种python分布式任务调度框架其支持 无状态的任务并发执行,也支持 有状态的任务按照一定顺序执行其支持 分布式调度器,在一个节点上创建的任务先给本节点的局部调度器,并让本节点自己处理,当资源不够时,再将任务发给全局调度器供其他节点处理其支…...

个人介绍以及毕业去向
CSDN陪伴我从大一到大四,后面也会接着用 写一点大学四年的总结 #总结#理工科#留学 211大学 弃保出国 智能科学与技术 均分88.9 EI论文一篇 数学竞赛和数学建模均为省二 大创评为国家级 全国大学生计算机设计大赛国家三等奖 百度Paddle、大疆RoboMaster、Phytium Te…...
原创度检测,在线文章原创度检测
原创度检测,作为数字时代中内容创作者和学术界广泛关注的话题,正逐渐成为保障知识产权、促进创新发展的不可或缺的工具。今天,我们将深入介绍原创度检测的定义、意义、技术原理、应用领域以及未来趋势。 一、什么是原创度检测? 原…...
windows下安装git中文版客户端
下载git Windows客户端 git客户端下载地址:Git - Downloads 我这里下载的是Git-2.14.0-64-bit.exe版本 下载TortoiseGit TortoiseGit客户端下载地址:Download – TortoiseGit – Windows Shell Interface to Git TortoiseGit客户端要下载两个&#…...

短视频怎么批量添加水印logo
在现代数字化时代,视频内容已经成为我们日常生活中不可或缺的一部分。然而,当我们辛辛苦苦制作的视频在网络上分享时,常常会遇到被他人盗用或未经授权使用的情况。为了保护我们的创作成果,给视频添加水印logo成为了一种常见的手段…...

一文入门 UUID
UUID简介 UUID代表Universally Unique Identifier,译为全局一标识符。它是一种由软件构建的标准化身份验证方案,用于确保跨多个上下文中的对象都具有唯一性。UUID在各种系统之间确保了严格的唯一性,因此即使在大型分布式环境中,也…...
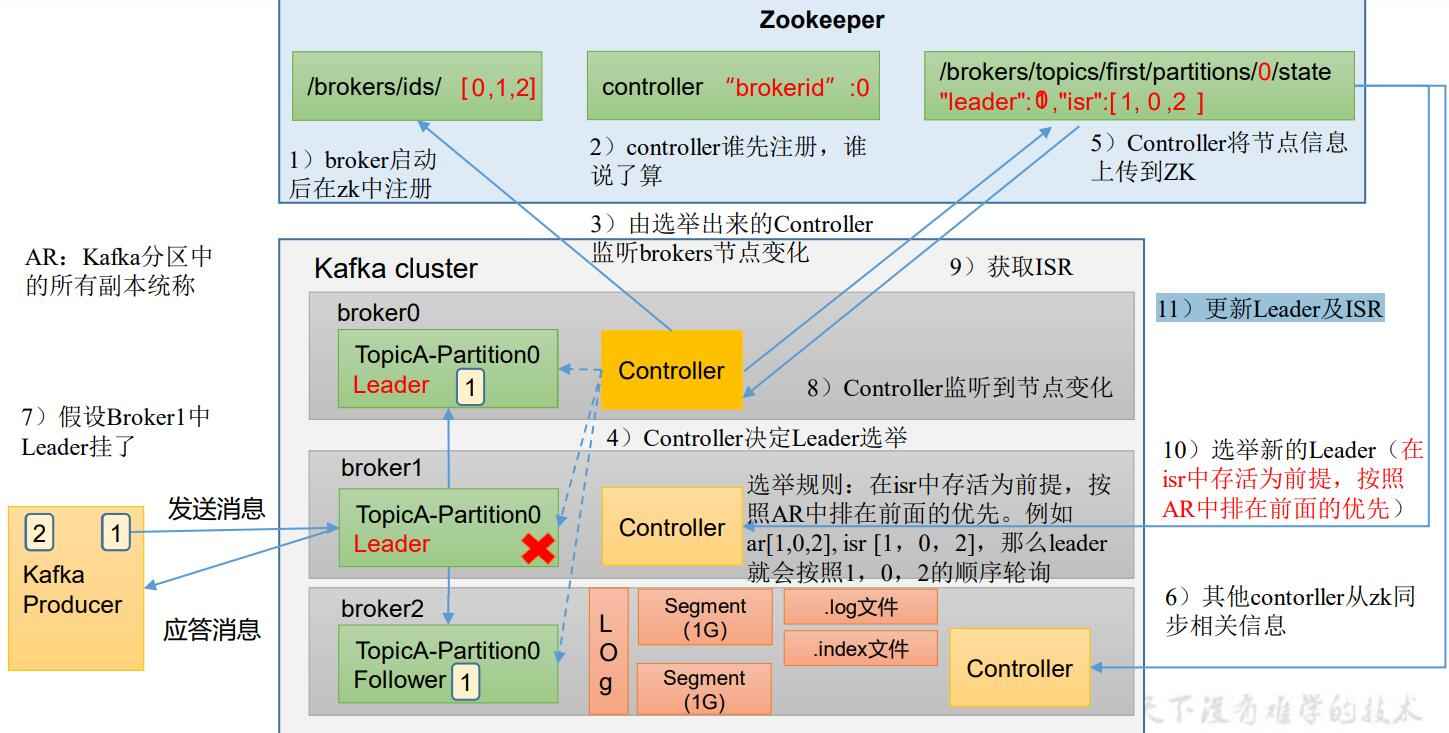
kafka学习笔记--broker工作流程、重要参数
本文内容来自尚硅谷B站公开教学视频,仅做个人总结、学习、复习使用,任何对此文章的引用,应当说明源出处为尚硅谷,不得用于商业用途。 如有侵权、联系速删 视频教程链接:【尚硅谷】Kafka3.x教程(从入门到调优…...
多合一iPhone 解锁工具:iMyFone LockWiper iOS
多合一iPhone 解锁工具 无需密码解锁 iPhone/iPad/iPod touch 上所有类型的屏幕锁定 在几分钟内解锁 iPhone Apple ID、Touch ID 和 Face ID 立即绕过 MDM 并删除 iPhone/iPad/iPod touch 上的 MDM 配置文件 支持所有 iOS 版本和设备,包括最新的 iOS 17 和 iPhone 1…...

在设计和考虑建造室外雨水收集池时需要注意的因素
在设计和建造室外雨水收集池时,需要考虑以下因素: 地质条件:建造雨水收集池需要考虑到地质条件,例如土壤类型、地基承载能力等。这些因素可能对水池的建造和结构产生影响。 气候条件:不同地区的降雨量、湿度、气温等…...

C_5练习题答案
一、单项选择题(本大题共20小题,每小题2分,共40分。在每小题给出的四个备选项中,选出一个正确的答案,并将所选项前的字母填写在答题纸的相应位置上。) 下列叙述中错误的是(D)。A.计算机不能直接执行用C语言编写的源程序 B.C程序经C编译程序编译后,生成扩展名为obj的文件是一个二…...

使用 Axios 进行网络请求的全面指南
使用 Axios 进行网络请求的全面指南 本文将向您介绍如何使用 Axios 进行网络请求。通过分步指南和示例代码,您将学习如何使用 Axios 库在前端应用程序中发送 GET、POST、PUT 和 DELETE 请求,并处理响应数据和错误。 准备工作 在开始之前,请…...

已解决java.lang.exceptionininitializererror异常的正确解决方法,亲测有效!!!
已解决java.lang.exceptionininitializererror异常的正确解决方法,亲测有效!!! 文章目录 报错问题解决思路解决方法交流 报错问题 java.lang.exceptionininitializererror 解决思路 java.lang.ExceptionInInitializerError 是一…...
深度学习 Day10——T10数据增强
🍨 本文为🔗365天深度学习训练营 中的学习记录博客🍖 原作者:K同学啊 | 接辅导、项目定制 文章目录 前言一、我的环境二、代码实现与执行结果1.引入库2.设置GPU(如果使用的是CPU可以忽略这步)3.导入数据4.查…...

ky10 x86 一键安装wvp gb28181 pro平台
下载代码 git clone https://gitcode.net/zengliguang/ky10_x86_wvp_record_offline_install.gitfinalshell mobaxterm 修改服务器ip 查看服务器ip ip a 在脚本文件中修改服务器ip 执行安装脚本 切换到root用户 sudo su cd ky10_x86_wvp_record_of...
FPGA时序分析与约束(0)——目录与传送门
一、简介 关于时序分析和约束的学习似乎是学习FPGA的一道分水岭,似乎只有理解了时序约束才能算是真正入门了FPGA,对于FPGA从业者或者未来想要从事FPGA开发的工程师来说,时序约束可以说是一道躲不过去的坎,所以这个系列我们会详细介…...

Linux 驱动开发需要掌握哪些编程语言和技术?
Linux 驱动开发需要掌握哪些编程语言和技术? 在开始前我有一些资料,是我根据自己从业十年经验,熬夜搞了几个通宵,精心整理了一份「Linux的资料从专业入门到高级教程工具包」,点个关注,全部无偿共享给大家&a…...

Android studio生成二维码
1.遇到的问题 需要生成一个二维码,可以使用zxing第三方组件,增加依赖。 //生成二维码 implementation com.google.zxing:core:3.4.1 2.代码 展示页面 <ImageViewandroid:id"id/qrCodeImageView"android:layout_width"150dp"an…...
)
从DRC到PAE:VLSI天线效应全解析(含最新工艺避坑指南)
从DRC到PAE:VLSI天线效应全解析(含最新工艺避坑指南) 在28nm以下先进工艺节点中,工程师们常会遇到一个看似简单却暗藏杀机的问题——某条金属线在DRC检查时完全合规,但流片后却出现大规模栅氧击穿。这种被称为"工…...

告别90%无效操作:3个让文档获取效率倍增的反直觉方案
告别90%无效操作:3个让文档获取效率倍增的反直觉方案 【免费下载链接】kill-doc 看到经常有小伙伴们需要下载一些免费文档,但是相关网站浏览体验不好各种广告,各种登录验证,需要很多步骤才能下载文档,该脚本就是为了解…...

Palworld存档工具终极指南:掌握游戏数据编辑的专业方法
Palworld存档工具终极指南:掌握游戏数据编辑的专业方法 【免费下载链接】palworld-save-tools Tools for converting Palworld .sav files to JSON and back 项目地址: https://gitcode.com/gh_mirrors/pa/palworld-save-tools 你是否曾想过深入Palworld游戏…...

零基础5分钟上手:Wan2.2-T2V-A5B文本生成视频保姆级教程
零基础5分钟上手:Wan2.2-T2V-A5B文本生成视频保姆级教程 1. 为什么选择Wan2.2-T2V-A5B 如果你正在寻找一个快速、轻量级的文本生成视频工具,Wan2.2-T2V-A5B绝对值得考虑。这个50亿参数的模型专为快速内容创作优化,能在普通显卡上实现秒级出…...
)
STM32CubeMX实战:如何用通用定时器精准实现微秒级延时(附DHT11读取示例)
STM32CubeMX实战:通用定时器实现微秒级延时的工程化解决方案 在嵌入式开发中,精确的时序控制往往是项目成功的关键。许多传感器如DHT11温湿度模块、超声波测距模块HC-SR04等,都需要微秒级精度的延时操作。然而,STM32CubeMX默认提…...

全原子设计驱动的蛋白质工程:RFDiffusionAA技术原理与实战指南
全原子设计驱动的蛋白质工程:RFDiffusionAA技术原理与实战指南 【免费下载链接】rf_diffusion_all_atom Public RFDiffusionAA repo 项目地址: https://gitcode.com/gh_mirrors/rf/rf_diffusion_all_atom 在药物研发与蛋白质工程领域,如何高效设计…...

告别杂乱原理图!手把手教你用PDFCreator+Ghostscript为OrCAD 16.6原理图生成带导航书签的PDF
告别杂乱原理图!手把手教你用PDFCreatorGhostscript为OrCAD 16.6原理图生成带导航书签的PDF 硬件工程师的日常工作中,原理图评审是绕不开的环节。但你是否遇到过这样的场景:当你将精心设计的OrCAD原理图导出为PDF分享给团队时,软件…...

LaTeX公式一键转换Word:学术写作的效率革命
LaTeX公式一键转换Word:学术写作的效率革命 【免费下载链接】LaTeX2Word-Equation Copy LaTeX Equations as Word Equations, a Chrome Extension 项目地址: https://gitcode.com/gh_mirrors/la/LaTeX2Word-Equation 作为一名研究生,你是否曾经为…...

NLP-StructBERT赋能内容去重:展示海量文本相似度排查惊艳效果
NLP-StructBERT赋能内容去重:展示海量文本相似度排查惊艳效果 每次打开内容平台,你是不是也经常看到一堆“换汤不换药”的文章?标题不一样,内容却大同小异。对于平台运营者来说,这更是个头疼的问题:怎么从…...

学术公式迁移困境:从3小时到45秒的转换革命——LaTeX2Word-Equation技术解析
学术公式迁移困境:从3小时到45秒的转换革命——LaTeX2Word-Equation技术解析 【免费下载链接】LaTeX2Word-Equation Copy LaTeX Equations as Word Equations, a Chrome Extension 项目地址: https://gitcode.com/gh_mirrors/la/LaTeX2Word-Equation 问题溯源…...