深度学习 Day10——T10数据增强
- 🍨 本文为🔗365天深度学习训练营 中的学习记录博客
- 🍖 原作者:K同学啊 | 接辅导、项目定制
文章目录
- 前言
- 一、我的环境
- 二、代码实现与执行结果
- 1.引入库
- 2.设置GPU(如果使用的是CPU可以忽略这步)
- 3.导入数据
- 4.查看数据
- 5.加载数据
- 6.再次检查数据
- 7.配置数据集
- 8.可视化数据
- 9.构建CNN网络模型
- 10.编译模型
- 11.训练模型
- 12.模型评估
- 三、知识点详解
- 1.图像增强
- 1.1TensorFlow 之中进行图像数据增强
- 1.1.1使用 tf.keras 的预处理层进行图像数据增强
- 1.1.2 使用 tf.image 进行数据增强
- 1.2自定义增强函数
- 1.3 图像增强数据与原始数据合并作为新样本
- 总结
前言
本文将采用CNN实现猫狗识别。简单讲述实现代码与执行结果,并浅谈涉及知识点。
关键字:图像增强
一、我的环境
- 电脑系统:Windows 11
- 语言环境:python 3.8.6
- 编译器:pycharm2020.2.3
- 深度学习环境:TensorFlow 2.10.1
- 显卡:NVIDIA GeForce RTX 4070
二、代码实现与执行结果
1.引入库
from PIL import Image
import numpy as np
from pathlib import Path
import tensorflow as tf
from tensorflow.keras import datasets, layers, models, regularizers
from tensorflow.keras.callbacks import ModelCheckpoint, EarlyStopping
from tensorflow.keras.applications.vgg16 import VGG16
from tensorflow.keras import layers, models, Input
from tensorflow.keras.models import Model
from tensorflow.keras.layers import Conv2D, MaxPooling2D, Dense, Flatten, Dropout, BatchNormalization
from tqdm import tqdm
import tensorflow.keras.backend as K
import matplotlib.pyplot as plt
import warningswarnings.filterwarnings('ignore') # 忽略一些warning内容,无需打印
2.设置GPU(如果使用的是CPU可以忽略这步)
'''前期工作-设置GPU(如果使用的是CPU可以忽略这步)'''
# 检查GPU是否可用
print(tf.test.is_built_with_cuda())
gpus = tf.config.list_physical_devices("GPU")
print(gpus)
if gpus:gpu0 = gpus[0] # 如果有多个GPU,仅使用第0个GPUtf.config.experimental.set_memory_growth(gpu0, True) # 设置GPU显存用量按需使用tf.config.set_visible_devices([gpu0], "GPU")
执行结果
True
[PhysicalDevice(name='/physical_device:GPU:0', device_type='GPU')]
3.导入数据
数据链接: 猫狗数据
'''前期工作-导入数据'''
data_dir = r"D:\DeepLearning\data\CatDog"
data_dir = Path(data_dir)
4.查看数据
'''前期工作-查看数据'''
image_count = len(list(data_dir.glob('*/*.png')))
print("图片总数为:", image_count)
image_list = list(data_dir.glob('cat/*.png'))
image = Image.open(str(image_list[1]))
# 查看图像实例的属性
print(image.format, image.size, image.mode)
plt.imshow(image)
plt.show()执行结果:
图片总数为: 3400
JPEG (512, 512) RGB
5.加载数据
'''数据预处理-加载数据'''
batch_size = 64
img_height = 224
img_width = 224
"""
关于image_dataset_from_directory()的详细介绍可以参考文章:https://mtyjkh.blog.csdn.net/article/details/117018789
"""
train_ds = tf.keras.preprocessing.image_dataset_from_directory(data_dir,validation_split=0.2,subset="training",seed=12,image_size=(img_height, img_width),batch_size=batch_size)
val_ds = tf.keras.preprocessing.image_dataset_from_directory(data_dir,validation_split=0.2,subset="validation",seed=12,image_size=(img_height, img_width),batch_size=batch_size)
# 我们可以通过class_names输出数据集的标签。标签将按字母顺序对应于目录名称。
class_names = train_ds.class_names
print(class_names)
运行结果:
Found 3400 files belonging to 2 classes.
Using 2720 files for training.
Found 3400 files belonging to 2 classes.
Using 680 files for validation.
['cat', 'dog']
6.再次检查数据
'''数据预处理-再次检查数据'''
# Image_batch是形状的张量(32,180,180,3)。这是一批形状180x180x3的32张图片(最后一维指的是彩色通道RGB)。
# Label_batch是形状(32,)的张量,这些标签对应32张图片
for image_batch, labels_batch in train_ds:print(image_batch.shape)print(labels_batch.shape)break
运行结果
(64, 224, 224, 3)
(64,)
7.配置数据集
AUTOTUNE = tf.data.AUTOTUNEdef preprocess_image(image, label):return (image / 255.0, label)# 归一化处理
train_ds = train_ds.map(preprocess_image, num_parallel_calls=AUTOTUNE)
val_ds = val_ds.map(preprocess_image, num_parallel_calls=AUTOTUNE)
test_ds = test_ds.map(preprocess_image, num_parallel_calls=AUTOTUNE)train_ds = train_ds.cache().shuffle(1000).prefetch(buffer_size=AUTOTUNE)
val_ds = val_ds.cache().prefetch(buffer_size=AUTOTUNE)
8.可视化数据
'''数据预处理-可视化数据'''
plt.figure(figsize=(18, 3))
for images, labels in train_ds.take(2):for i in range(8):ax = plt.subplot(1, 8, i + 1)plt.imshow(images[i].numpy().astype("uint8"))plt.title(class_names[labels[i]], fontsize=40)plt.axis("off")
# 显示图片
plt.show()

9.构建CNN网络模型
#VGG16
def VGG16(class_names, img_height, img_width):model = models.Sequential([# 1layers.Conv2D(filters=64, kernel_size=(3, 3), activation='relu', padding='same',input_shape=(img_height, img_width, 3)),layers.Conv2D(filters=64, kernel_size=(3, 3), activation='relu', padding='same'),layers.MaxPool2D(pool_size=(2, 2), strides=2),# 2layers.Conv2D(filters=128, kernel_size=(3, 3), activation='relu', padding='same'),layers.Conv2D(filters=128, kernel_size=(3, 3), activation='relu', padding='same'),layers.MaxPool2D(pool_size=(2, 2), strides=2),# 3layers.Conv2D(filters=256, kernel_size=(3, 3), activation='relu', padding='same'),layers.Conv2D(filters=256, kernel_size=(3, 3), activation='relu', padding='same'),layers.Conv2D(filters=256, kernel_size=(3, 3), activation='relu', padding='same'),layers.MaxPool2D(pool_size=(2, 2), strides=2),# 4layers.Conv2D(filters=512, kernel_size=(3, 3), activation='relu', padding='same'),layers.Conv2D(filters=512, kernel_size=(3, 3), activation='relu', padding='same'),layers.Conv2D(filters=512, kernel_size=(3, 3), activation='relu', padding='same'),layers.MaxPool2D(pool_size=(2, 2), strides=2),# 5layers.Conv2D(filters=512, kernel_size=(3, 3), activation='relu', padding='same'),layers.Conv2D(filters=512, kernel_size=(3, 3), activation='relu', padding='same'),layers.Conv2D(filters=512, kernel_size=(3, 3), activation='relu', padding='same'),layers.MaxPool2D(pool_size=(2, 2), strides=2),# FClayers.Flatten(),layers.Dense(4096, activation='relu'),layers.Dense(4096, activation='relu'),layers.Dense(len(class_names), activation='softmax')])return model
model = VGG16(class_names, img_height, img_width)
model.summary()
网络结构结果如下:
Model: "sequential_1"
_________________________________________________________________Layer (type) Output Shape Param #
=================================================================conv2d (Conv2D) (None, 224, 224, 64) 1792 conv2d_1 (Conv2D) (None, 224, 224, 64) 36928 max_pooling2d (MaxPooling2D (None, 112, 112, 64) 0 ) conv2d_2 (Conv2D) (None, 112, 112, 128) 73856 conv2d_3 (Conv2D) (None, 112, 112, 128) 147584 max_pooling2d_1 (MaxPooling (None, 56, 56, 128) 0 2D) conv2d_4 (Conv2D) (None, 56, 56, 256) 295168 conv2d_5 (Conv2D) (None, 56, 56, 256) 590080 conv2d_6 (Conv2D) (None, 56, 56, 256) 590080 max_pooling2d_2 (MaxPooling (None, 28, 28, 256) 0 2D) conv2d_7 (Conv2D) (None, 28, 28, 512) 1180160 conv2d_8 (Conv2D) (None, 28, 28, 512) 2359808 conv2d_9 (Conv2D) (None, 28, 28, 512) 2359808 max_pooling2d_3 (MaxPooling (None, 14, 14, 512) 0 2D) conv2d_10 (Conv2D) (None, 14, 14, 512) 2359808 conv2d_11 (Conv2D) (None, 14, 14, 512) 2359808 conv2d_12 (Conv2D) (None, 14, 14, 512) 2359808 max_pooling2d_4 (MaxPooling (None, 7, 7, 512) 0 2D) flatten (Flatten) (None, 25088) 0 dense (Dense) (None, 4096) 102764544 dense_1 (Dense) (None, 4096) 16781312 dense_2 (Dense) (None, 2) 8194 =================================================================
Total params: 134,268,738
Trainable params: 134,268,738
Non-trainable params: 0
_________________________________________________________________
10.编译模型
'''编译模型'''
#设置初始学习率
initial_learning_rate = 1e-4
opt = tf.keras.optimizers.Adam(learning_rate=initial_learning_rate)
model.compile(optimizer=opt,loss='sparse_categorical_crossentropy',metrics=['accuracy'])
11.训练模型
'''训练模型'''
epochs = 10
history = model.fit(train_ds,validation_data=val_ds,epochs=epochs,shuffle=False
)训练记录如下:
Epoch 1/1043/43 [==============================] - 42s 606ms/step - loss: 0.6830 - accuracy: 0.5511 - val_loss: 0.7328 - val_accuracy: 0.6630
Epoch 2/10
43/43 [==============================] - 17s 384ms/step - loss: 0.4927 - accuracy: 0.7614 - val_loss: 0.3283 - val_accuracy: 0.8714
Epoch 3/10
43/43 [==============================] - 17s 385ms/step - loss: 0.2113 - accuracy: 0.9165 - val_loss: 0.1986 - val_accuracy: 0.9221
Epoch 4/10
43/43 [==============================] - 17s 385ms/step - loss: 0.1173 - accuracy: 0.9555 - val_loss: 0.0977 - val_accuracy: 0.9620
Epoch 5/10
43/43 [==============================] - 17s 385ms/step - loss: 0.0561 - accuracy: 0.9798 - val_loss: 0.0789 - val_accuracy: 0.9728
Epoch 6/10
43/43 [==============================] - 17s 385ms/step - loss: 0.0483 - accuracy: 0.9816 - val_loss: 0.0578 - val_accuracy: 0.9783
Epoch 7/10
43/43 [==============================] - 17s 385ms/step - loss: 0.0457 - accuracy: 0.9838 - val_loss: 0.0551 - val_accuracy: 0.9783
Epoch 8/10
43/43 [==============================] - 17s 385ms/step - loss: 0.0372 - accuracy: 0.9875 - val_loss: 0.0985 - val_accuracy: 0.9692
Epoch 9/10
43/43 [==============================] - 17s 385ms/step - loss: 0.0324 - accuracy: 0.9915 - val_loss: 0.0264 - val_accuracy: 0.9873
Epoch 10/10
43/43 [==============================] - 17s 385ms/step - loss: 0.0109 - accuracy: 0.9967 - val_loss: 0.0408 - val_accuracy: 0.9891
2/2 [==============================] - 0s 116ms/step - loss: 0.0615 - accuracy: 0.9922
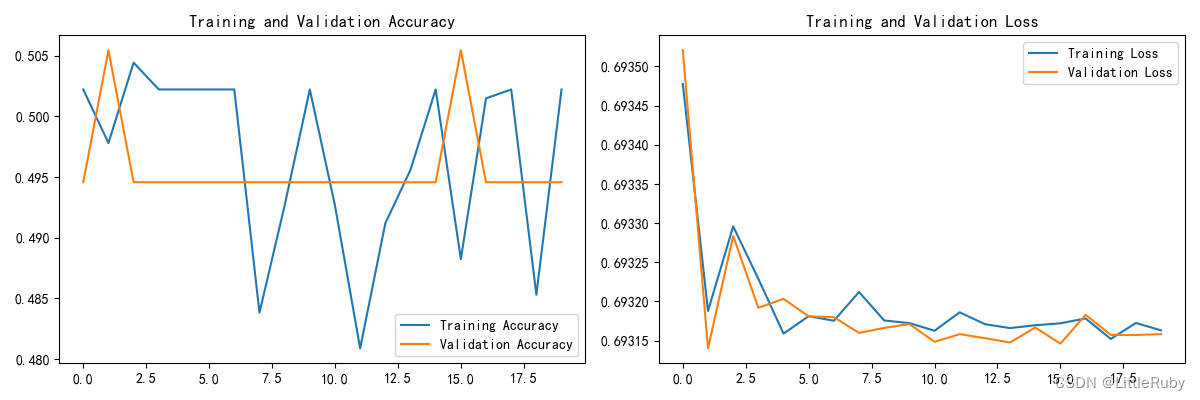
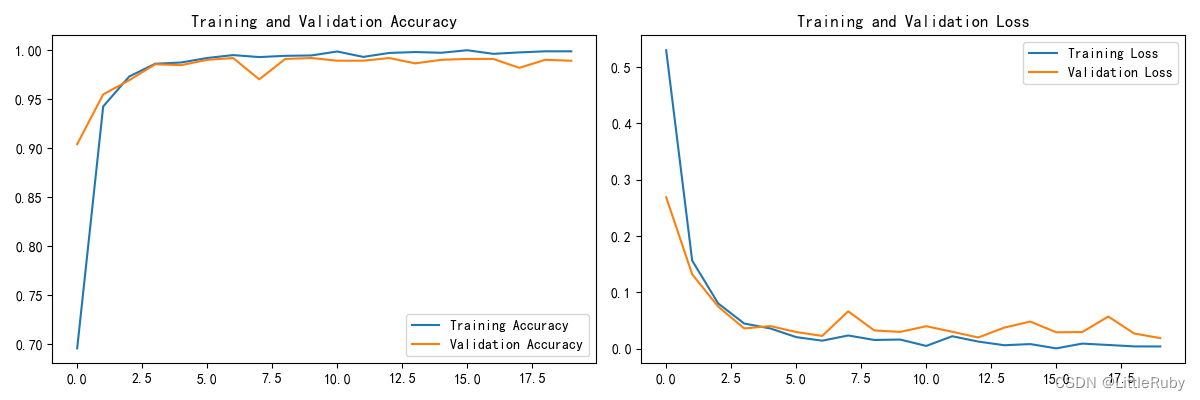
Accuracy 0.992187512.模型评估
'''模型评估'''
acc = history.history['accuracy']
val_acc = history.history['val_accuracy']
loss = history.history['loss']
val_loss = history.history['val_loss']
epochs_range = range(len(loss))
plt.figure(figsize=(12, 4))
plt.subplot(1, 2, 1)
plt.plot(epochs_range, acc, label='Training Accuracy')
plt.plot(epochs_range, val_acc, label='Validation Accuracy')
plt.legend(loc='lower right')
plt.title('Training and Validation Accuracy')
plt.subplot(1, 2, 2)
plt.plot(epochs_range, loss, label='Training Loss')
plt.plot(epochs_range, val_loss, label='Validation Loss')
plt.legend(loc='upper right')
plt.title('Training and Validation Loss')
plt.show()loss, acc = model.evaluate(test_ds)
print("Accuracy", acc)
执行结果
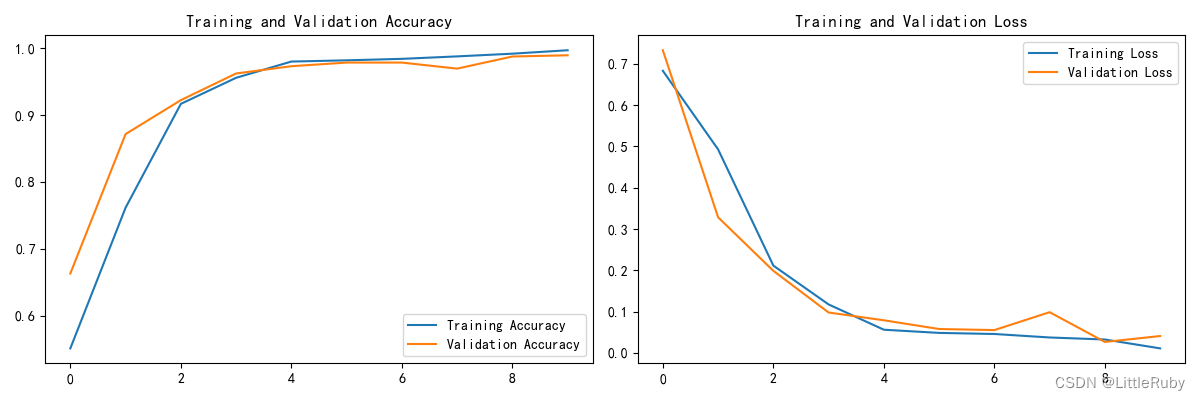
2/2 [==============================] - 0s 116ms/step - loss: 0.0615 - accuracy: 0.9922
Accuracy 0.9921875
三、知识点详解
1.图像增强
在深度学习中,有的时候训练集不够多,或者某一类数据较少,或者为了防止过拟合,让模型更加鲁棒性,data augmentation是一个不错的选择。
通过数据增强,我们可以将一些已经存在的数据进行相应的变换(可以选择将这些变换之后的数据增加到新的原来的数据集之中,也可以直接在原来的数据集上进行变换),从而实现数据种类多样性的增加。
对于图片数据,常见的数据增强方式包括:
- 随机水平翻转:
- 随机的裁剪;
- 随机调整明亮程度;
- 其他方式等
1.1TensorFlow 之中进行图像数据增强
在 TensorFlow 之中进行图像数据增强的方式主要有两种:
- 使用 tf.keras 的预处理层进行图像数据增强;
- 使用 tf.image 进行数据增强。
1.1.1使用 tf.keras 的预处理层进行图像数据增强
使用 tf.keras 的预处理层进行图像数据增强要使用的最主要的 API 包括在一下包之中:
tf.keras.layers.experimental.preprocessing
在这个包之中,我们最常用的数据增强 API 包括:
tf.keras.layers.experimental.preprocessing.RandomFlip(mode): 将输入的图片进行随机翻转,一般我们会取 mode=“horizontal” ,因为这代表水平旋转;而 mode=“vertical” 则代表随机进行上下翻转;
tf.keras.layers.experimental.preprocessing.RandomRotation§: 按照旋转角度(单位为弧度) p 将输入的图片进行随机的旋转;
tf.keras.layers.experimental.preprocessing.RandomContrast§:按照 P 的概率将输入的图片进行随机的图像色相翻转;
tf.keras.layers.experimental.preprocessing.CenterCrop(height, width):使用 height * width 的大小的裁剪框,在数据的中心进行裁剪。
该API有两种使用方式:一个是将其嵌入model中,一个是在Dataset数据集中进行数据增强
方式一:嵌入model中
调用方式如下
# tf.keras.layers.experimental.preprocessing图像增强 第一个层表示进行随机的水平和垂直翻转,而第二个层表示按照 0.2 的弧度值进行随机旋转。
data_augmentation = tf.keras.Sequential([tf.keras.layers.experimental.preprocessing.RandomFlip("horizontal_and_vertical",input_shape=(img_height, img_width, 3)),tf.keras.layers.experimental.preprocessing.RandomRotation(0.2),
])
model = tf.keras.Sequential([data_augmentation,layers.Conv2D(16, 3, padding='same', activation='relu'),layers.MaxPooling2D(),
])
# 图像增强 可视化效果图
for images, labels in train_ds.take(1):# Add the image to a batch.image = tf.expand_dims(images[0], 0)plt.figure(figsize=(8, 8))for i in range(9):augmented_image = data_augmentation(image)ax = plt.subplot(3, 3, i + 1)plt.imshow(augmented_image[0])plt.axis("off")plt.show()break
本文案例使用如下
data_augmentation = tf.keras.Sequential([tf.keras.layers.experimental.preprocessing.RandomFlip("horizontal_and_vertical",input_shape=(img_height, img_width, 3)),tf.keras.layers.experimental.preprocessing.RandomRotation(0.2),
])
#方式一图像增强:tf.keras.layers.experimental.preprocessing方式实现的图像增强,嵌入模型中
#只有在模型训练时(Model.fit)才会进行增强,在模型评估(Model.evaluate)以及预测(Model.predict)时并不会进行增强操作
def VGG16_aug0(class_names, img_height, img_width):model = models.Sequential([data_augmentation,# 1layers.Conv2D(filters=64, kernel_size=(3, 3), activation='relu', padding='same',input_shape=(img_height, img_width, 3)),layers.Conv2D(filters=64, kernel_size=(3, 3), activation='relu', padding='same'),layers.MaxPool2D(pool_size=(2, 2), strides=2),# 2layers.Conv2D(filters=128, kernel_size=(3, 3), activation='relu', padding='same'),layers.Conv2D(filters=128, kernel_size=(3, 3), activation='relu', padding='same'),layers.MaxPool2D(pool_size=(2, 2), strides=2),# 3layers.Conv2D(filters=256, kernel_size=(3, 3), activation='relu', padding='same'),layers.Conv2D(filters=256, kernel_size=(3, 3), activation='relu', padding='same'),layers.Conv2D(filters=256, kernel_size=(3, 3), activation='relu', padding='same'),layers.MaxPool2D(pool_size=(2, 2), strides=2),# 4layers.Conv2D(filters=512, kernel_size=(3, 3), activation='relu', padding='same'),layers.Conv2D(filters=512, kernel_size=(3, 3), activation='relu', padding='same'),layers.Conv2D(filters=512, kernel_size=(3, 3), activation='relu', padding='same'),layers.MaxPool2D(pool_size=(2, 2), strides=2),# 5layers.Conv2D(filters=512, kernel_size=(3, 3), activation='relu', padding='same'),layers.Conv2D(filters=512, kernel_size=(3, 3), activation='relu', padding='same'),layers.Conv2D(filters=512, kernel_size=(3, 3), activation='relu', padding='same'),layers.MaxPool2D(pool_size=(2, 2), strides=2),# FClayers.Flatten(),layers.Dense(4096, activation='relu'),layers.Dense(4096, activation='relu'),layers.Dense(len(class_names), activation='softmax')])return model
model = VGG16_aug0(class_names, img_height, img_width) # 方式一图像增强
model.summary()# 图像增强 可视化效果图
for images, labels in train_ds.take(1):# Add the image to a batch.image = tf.expand_dims(images[0], 0)plt.figure(figsize=(8, 8))for i in range(9):augmented_image = data_augmentation(image)ax = plt.subplot(3, 3, i + 1)plt.imshow(augmented_image[0])plt.axis("off")plt.show()break
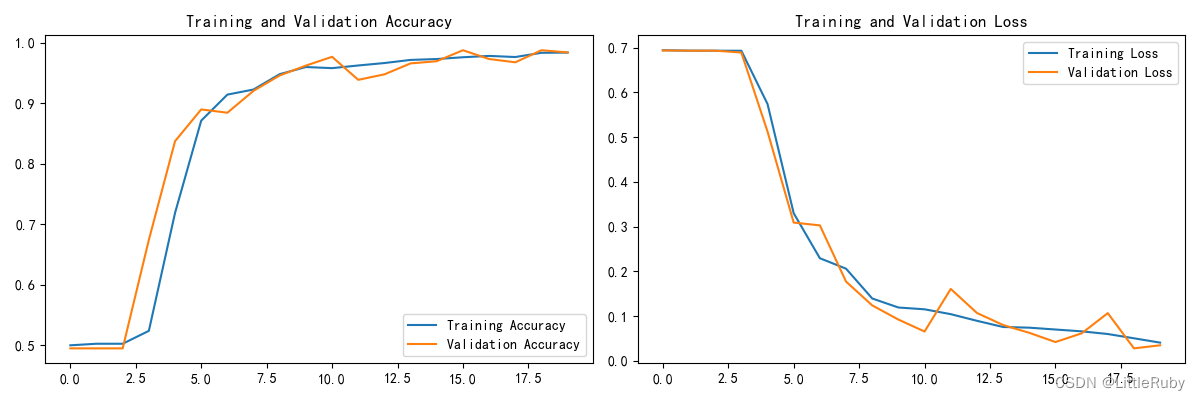

方式二:在Dataset数据集中进行数据增强
本文案例使用如下
#方式二图像增强:tf.keras.layers.experimental.preprocessing方式实现的图像增强.在Dataset数据集中进行数据增强
AUTOTUNE = tf.data.AUTOTUNEdef prepare(ds):ds = ds.map(lambda x, y: (data_augmentation(x, training=True), y), num_parallel_calls=AUTOTUNE)return ds
train_ds1 = prepare(train_ds)'''训练模型'''
epochs = 20
history = model.fit(train_ds1,validation_data=val_ds,epochs=epochs
)
本文试验效果并不理想
1.1.2 使用 tf.image 进行数据增强
使用 tf.image 是 TensorFlow 最原生的一种增强方式,使用这种方式可以实现更多、更加个性化的数据增强。
其中包含的数据增强方式主要包括:
tf.image.flip_left_right (img):将图片进行水平翻转;
tf.image.rgb_to_grayscale (img):将 RGB 图像转化为灰度图像;
tf.image.adjust_saturation (image, f):将 image 图像按照 f 参数进行饱和度的调节;
tf.image.adjust_brightness (image, f):将 image 图像按照 f 参数进行亮度的调节;
tf.image.central_crop (image, central_fraction):按照 p 的比例进行图片的中心裁剪,比如如果 p 是 0.5 ,那么裁剪后的长、宽就是原来图像的一半;
tf.image.rot90 (image):将 image 图像逆时针旋转 90 度。
可以看到,很多的 tf.image 数据增强方式并不提供随机化选项,因此我们需要手动进行随机化。
也正是因为上述特性,tf.image 数据增强主要用在一些自定义的模型之中,从而可以实现数据增强的自定义化。
参考链接在 TensorFlow 之中进行数据增强
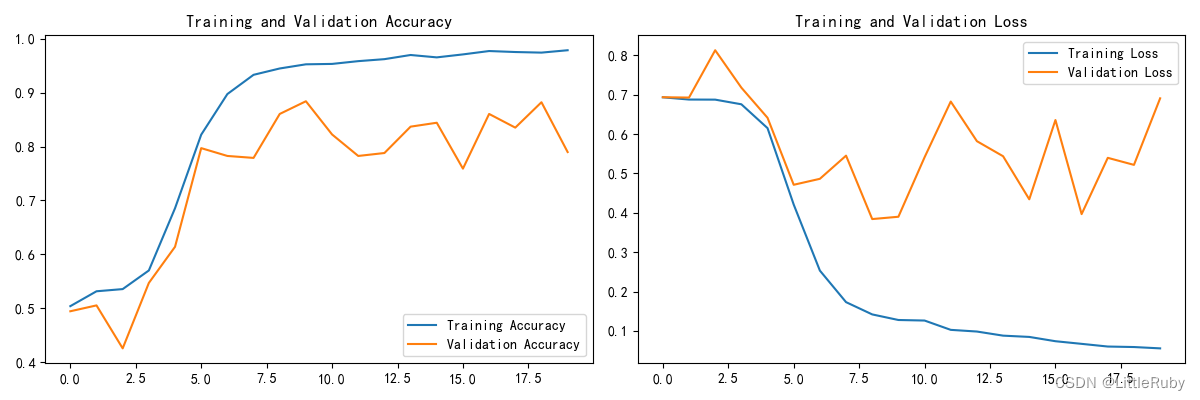
1.2自定义增强函数
import random
# 这是大家可以自由发挥的一个地方
def aug_img(image,label):seed = (random.randint(0, 9), 0)# 随机改变图像对比度stateless_random_brightness = tf.image.stateless_random_contrast(image, lower=0.1, upper=1.0, seed=seed)return stateless_random_brightness,label
train_ds2 = train_ds.map(aug_img, num_parallel_calls=AUTOTUNE)# 图像增强 可视化效果图
for images, labels in train_ds.take(1):# Add the image to a batch.image = tf.expand_dims(images[0], 0)plt.figure(figsize=(8, 8))for i in range(9):augmented_image = aug_img(image)ax = plt.subplot(3, 3, i + 1)# plt.imshow(augmented_image[0].numpy().astype("uint8"))plt.imshow(augmented_image[0][0])plt.axis("off")plt.show()break
效果也不是很理想,知道调用方法就行,针对不同案例实现图像增强
1.3 图像增强数据与原始数据合并作为新样本
操作步骤如下:
- 读取原始数据并图像增强
- 保存增强效果图
- 将原始数据与新生成的增强数据一起符号链接到新目录
读取原始数据并图像增强,保存增强效果图
from pathlib import Path
import cv2
import matplotlib.pyplot as plt
import warningswarnings.filterwarnings('ignore') # 忽略一些warning内容,无需打印
def saveaugimg(imgfile,newdir,prefix="aug_"):# cv2保存中文路径的图像imgFile = imgfile # 读取文件的路径img = cv2.imread(imgFile, flags=1) # flags=1 读取彩色图像(BGR)img1 = cv2.flip(img, 2) # 水平翻转img2 = cv2.cvtColor(img1, cv2.COLOR_BGR2RGB)# plt.imshow(img2)# plt.show()saveFile = imgfile.replace(r"D:\DeepLearning\data\CatDog", newdir) # 带有中文的保存文件路径newname=prefix+str(Path(imgfile).name)saveFile = Path(saveFile).parent / newnamePath(saveFile).parent.mkdir(parents=True, exist_ok=True) # 创建新文件夹# cv2.imwrite(saveFile, img) # imwrite 不支持中文路径和文件名,读取失败,但不会报错!img_write = cv2.imencode(".jpg", img1)[1].tofile(saveFile)dirs=r"D:\DeepLearning\data\CatDog"
newdir = r"D:\DeepLearning\data\CatDog_aug"
for p in Path(dirs).rglob("*"):if p.is_file(): # 如果是文件imgfile=str(p)saveaugimg(imgfile, newdir)
将原始数据与新生成的增强数据一起符号链接到新目录
from pathlib import Path# 对目录dirs做符号链接
def createslinkbatfile(dirs, slinkdirs, batfile="slink.bat"):print(f"为{dirs}创建符号链接目录{slinkdirs}\n")# 创建符号链接目录Path(slinkdirs).mkdir(parents=True, exist_ok=True)# 创建bat文件,为了解决bat脚本中文输出乱码问题,# 我们需要在bat脚本开头添加chcp 65001来设置控制台编码格式为UTF-8。# 同时,我们还需要使用setlocal enabledelayedexpansion启用延迟变量扩展with open(batfile, 'a', encoding='utf-8') as file:file.write("@echo off\nchcp 65001\nsetlocal enabledelayedexpansion " + '\n')# 遍历目标目录下的文件夹及文件,创建符号链接cmd命令for p in Path(dirs).rglob("*"):slink = Path(str(p).replace(str(dirs), str(slinkdirs))) # 替换符号链接文件夹目录if p.is_dir(): # 目录符号链接command = f"mklink /d \"{slink}\" \"{str(p)}\""else: # 文件符号链接command = f"mklink \"{slink}\" \"{str(p)}\""# 将符号链接cmd命令写入bat文件with open(batfile, 'a', encoding='utf-8') as file:# 增加编码encoding='utf-8',解决中文乱码问题解决方法file.write(command + '\n')print(command)# 对目录dirs做符号链接,生成后右击bat文件,选用管理员身份运行Path("slink.bat").unlink(missing_ok=False)# 删除bat文件
dirs=r"D:\DeepLearning\data\CatDog"
newdirs = r"D:\DeepLearning\data\CatDog_aug"
slinkdirs = r"D:\DeepLearning\data\CatDog_all"
createslinkbatfile(dirs, slinkdirs)
createslinkbatfile(newdirs, slinkdirs)部分bat内容同如下
@echo off
chcp 65001
setlocal enabledelayedexpansion
mklink /d "D:\DeepLearning\data\CatDog_all\cat" "D:\DeepLearning\data\CatDog\cat"
mklink /d "D:\DeepLearning\data\CatDog_all\dog" "D:\DeepLearning\data\CatDog\dog"
mklink "D:\DeepLearning\data\CatDog_all\cat\flickr_cat_000002.jpg" "D:\DeepLearning\data\CatDog\cat\flickr_cat_000002.jpg"
mklink "D:\DeepLearning\data\CatDog_all\cat\flickr_cat_000003.jpg" "D:\DeepLearning\data\CatDog\cat\flickr_cat_000003.jpg"
mklink "D:\DeepLearning\data\CatDog_all\cat\flickr_cat_000004.jpg" "D:\DeepLearning\data\CatDog\cat\flickr_cat_000004.jpg"
mklink "D:\DeepLearning\data\CatDog_all\cat\flickr_cat_000005.jpg" "D:\DeepLearning\data\CatDog\cat\flickr_cat_000005.jpg"
tf.keras.preprocessing.image_dataset_from_directory()传入新的文件夹目录
data_dir1 = r"D:\DeepLearning\data\CatDog_all" # 将自定义数据增强后的数据保存后,与原始数据一起合并加入样本中
data_dir = Path(data_dir1)
总结
通过本次的学习,学习到了几种图像增强调用方式,原文中增强方式均为增强数据替代原始数据加入训练集,本文加入将增强数据与原始数据一起合并作为样本的方法,本文中的增强方式加入案例,效果并没有很理想,跟数据集实际情况有关,可将本文提到的图像增强方式运用到其他案例中。
相关文章:
深度学习 Day10——T10数据增强
🍨 本文为🔗365天深度学习训练营 中的学习记录博客🍖 原作者:K同学啊 | 接辅导、项目定制 文章目录 前言一、我的环境二、代码实现与执行结果1.引入库2.设置GPU(如果使用的是CPU可以忽略这步)3.导入数据4.查…...

ky10 x86 一键安装wvp gb28181 pro平台
下载代码 git clone https://gitcode.net/zengliguang/ky10_x86_wvp_record_offline_install.gitfinalshell mobaxterm 修改服务器ip 查看服务器ip ip a 在脚本文件中修改服务器ip 执行安装脚本 切换到root用户 sudo su cd ky10_x86_wvp_record_of...
FPGA时序分析与约束(0)——目录与传送门
一、简介 关于时序分析和约束的学习似乎是学习FPGA的一道分水岭,似乎只有理解了时序约束才能算是真正入门了FPGA,对于FPGA从业者或者未来想要从事FPGA开发的工程师来说,时序约束可以说是一道躲不过去的坎,所以这个系列我们会详细介…...

Linux 驱动开发需要掌握哪些编程语言和技术?
Linux 驱动开发需要掌握哪些编程语言和技术? 在开始前我有一些资料,是我根据自己从业十年经验,熬夜搞了几个通宵,精心整理了一份「Linux的资料从专业入门到高级教程工具包」,点个关注,全部无偿共享给大家&a…...

Android studio生成二维码
1.遇到的问题 需要生成一个二维码,可以使用zxing第三方组件,增加依赖。 //生成二维码 implementation com.google.zxing:core:3.4.1 2.代码 展示页面 <ImageViewandroid:id"id/qrCodeImageView"android:layout_width"150dp"an…...

python——第十六天
面向对象——继承 class RichMan(object): def __init__(self): self.money 1000000000 self.company "阿里巴巴" self.__secretary "小蜜" def speak(self): print(f"我对钱不感兴趣,我最后悔的事,就是创建了{self.company…...
JWT介绍及演示
JWT 介绍 cookie(放在浏览器) cookie 是一个非常具体的东西,指的就是浏览器里面能永久存储的一种数据,仅仅是浏览器实现的一种数据存储功能。 cookie由服务器生成,发送给浏览器,浏览器把cookie以kv形式保存到某个目录下的文本…...
Android Studio新版UI介绍
顶部菜单栏 左侧主要菜单入口项目名称分支名称 展开之后,主要功能与原来菜单栏功能一样,最大的变化就是把setting独立出去了。 而项目名称这里,展开就可以看到打开的历史工程列表,可以直接新建工程,原来需要在项目名称…...
基于ssm应急资源管理系统论文
摘 要 现代经济快节奏发展以及不断完善升级的信息化技术,让传统数据信息的管理升级为软件存储,归纳,集中处理数据信息的管理方式。本应急资源管理系统就是在这样的大环境下诞生,其可以帮助管理者在短时间内处理完毕庞大的数据信息…...
-k8s核心对象init pod)
K8S学习指南(9)-k8s核心对象init pod
文章目录 引言什么是Init容器?Init容器的使用场景1. 数据初始化2. 网络设置3. 等待依赖服务 Init容器的生命周期1. **Pending**2. **Running**3. **Terminated** Init容器的示例Init容器的高级用法结论 引言 Kubernetes(简称K8s)是一个强大的…...
以太坊:前世今生与未来
一、引言 以太坊,这个在区块链领域大放异彩的名字,似乎已经成为了去中心化应用(DApps)的代名词。从初期的萌芽到如今的繁荣发展,以太坊经历了一段曲折而精彩的旅程。让我们一起回顾一下以太坊的前世今生,以…...
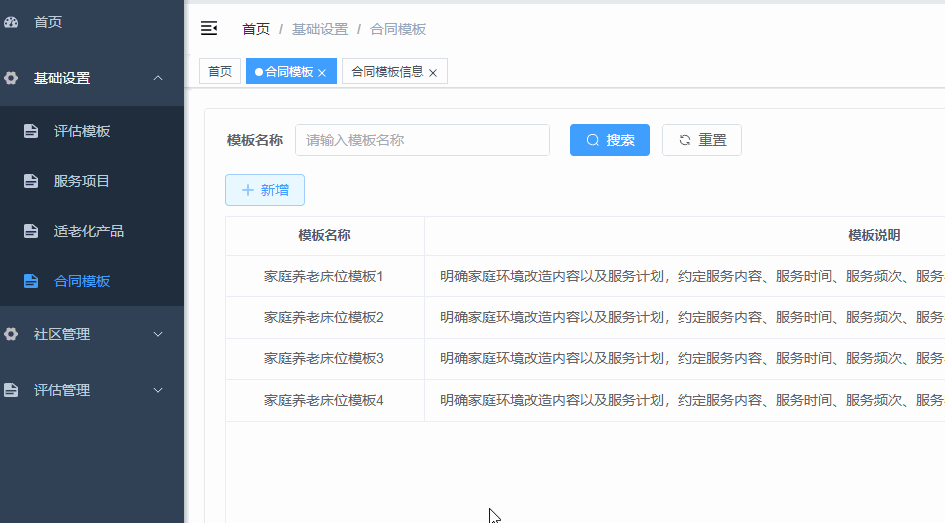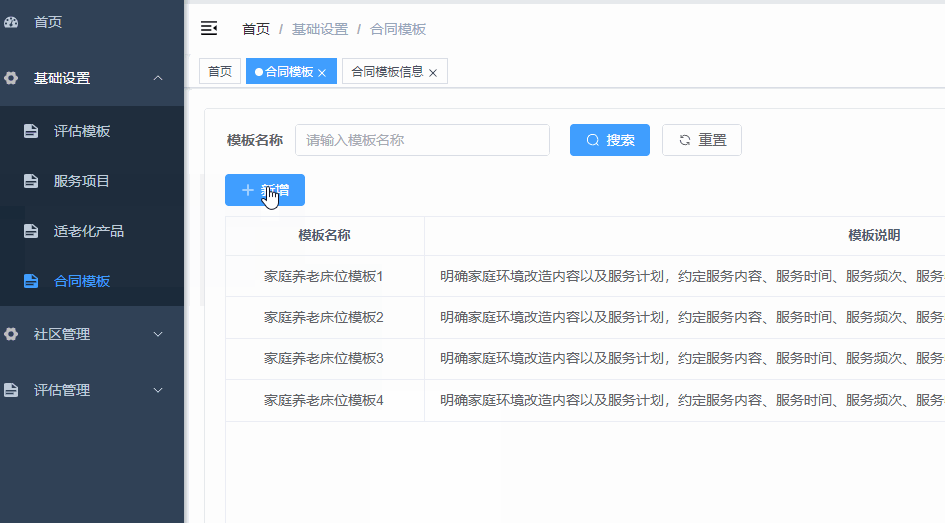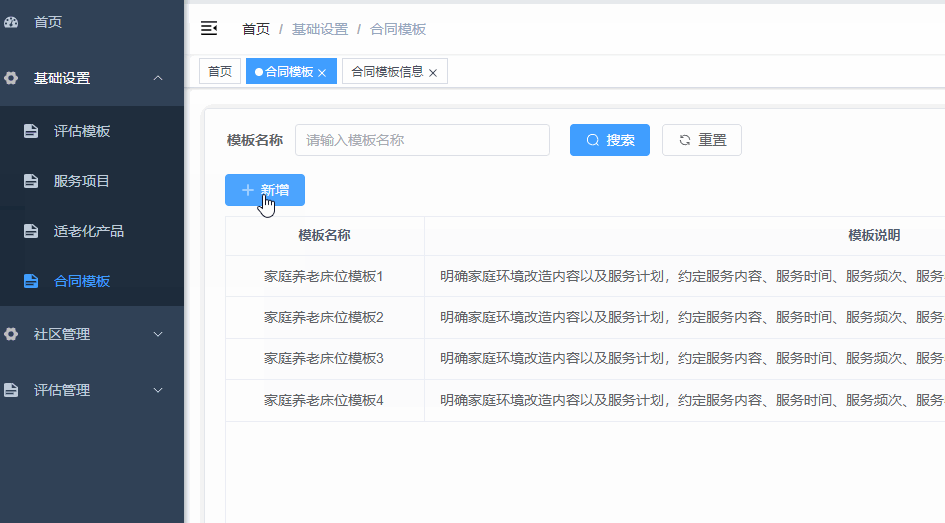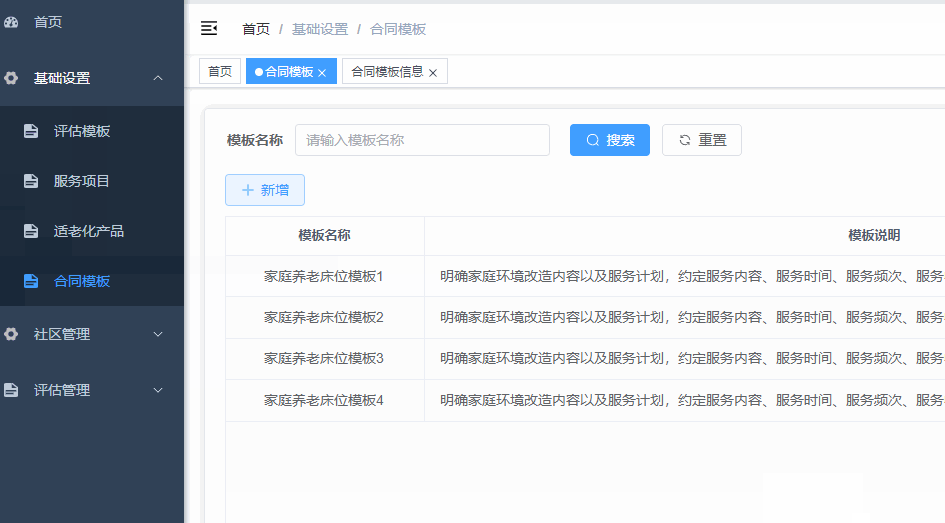
vue3若依框架,在页面中点击新增按钮跳转到新的页面,不是弹框,如何实现
在router文件中的动态路由数组中新增一个路由配置,这个配置的就是新的页面。 注意path不要和菜单配置中的路径一样,会不显示内容。 在菜单配置中要写权限标识就是permissions:[]里的内容 在children里的path要写占位符info/:data 点击新增按钮&#x…...

【大模型】800万纯AI战士年末大集结,硬核干货与音乐美食12月28日准时开炫
文章目录 WAVE SUMMIT五载十届,AI开发者热血正当时酷炫前沿、星河共聚!大模型技术生态发展正当时 回望2023年,大语言模型或许将是科技史上最浓墨重彩的一笔。从技术、产业到生态,大语言模型在突飞猛进中加速重构万物。随着理解、生…...

linux配置python环境
目录 安装screen安装解压工具安装python环境安装程序所需要的依赖包镜像附录 安装screen screen用于后台运行程序 先升级包管理工具 sudo apt-get update 安装screen sudo apt-get install screen创建screen screen -S erl安装解压工具 对上传到服务器的文件进行解压 …...
【教程】app备案流程简单三部曲即可完成
APP备案流程包括以下步骤: 1. 开发者实名认证:在提交备案申请之前,开发者需要通过移动应用开发平台进行实名认证。这个步骤需要提供身份证号码、姓名、联系方式等信息,并上传相关证件照片或扫描件。 2. 应用信息登记:…...

C++使用vector创建二维数组并指定大小
一、一维容器的初始化: vector<int> v(n)表示声明一个容器v,并给他预定存储空间。每一个单元初始化为0,因此,vector<int> v(n)vector<int> v(n, 0)。 如果想要初始化为其他值,可改为vector<int…...

Spring支持哪几种事务管理类型,Spring 的事务实现方式和实现原理是?
1.Spring事务简介 事务作用:在数据层保障一系列的数据库操作同成功同失败 Spring事务作用:在数据层或业务层保障一系列的数据库操作同成功同失败 为何需要在业务层处理事务?:有些操作在数据层无法保证同成功同失败,…...
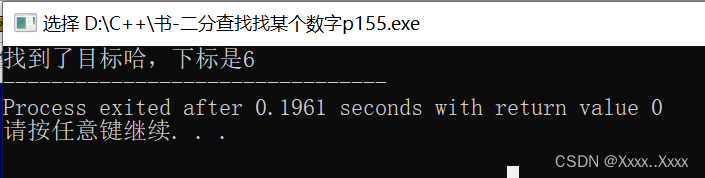
书-二分查找找某个数字p155
#include<stdio.h> int main(){int a[10]{1,4,5,6,7,8,23,34,90,14567};int mid;int low0;int high9;while(low<high){mid(lowhigh)/2;//数组分成两段,前一段low-mid,后一段mid-highif (a[mid]<23)//因为已经是排序好的了,所以如…...
【NLP】RAG 应用中的调优策略
检索增强生成应用程序的调优策略 没有一种放之四海而皆准的算法能够最好地解决所有问题。 本文通过数据科学家的视角审视检索增强生成(RAG)管道。它讨论了您可以尝试提高 RAG 管道性能的潜在“超参数”。与深度学习中的实验类似,例如&am…...

Android-Framework 默认隐藏导航栏,添加控制显示属性
一、环境 高通865 Android 10 二、源码修改 device/qcom/qssi/system.prop -217,3 217,5 persist.ruichi.gpu2persist.ruichi.gpu_max587persist.ruichi.gpu_min305# Show navigation bar, 0 for display, 1 for hidden persist.navbar.status1 frameworks/base/services/…...

智慧医疗能源事业线深度画像分析(上)
引言 医疗行业作为现代社会的关键基础设施,其能源消耗与环境影响正日益受到关注。随着全球"双碳"目标的推进和可持续发展理念的深入,智慧医疗能源事业线应运而生,致力于通过创新技术与管理方案,重构医疗领域的能源使用模式。这一事业线融合了能源管理、可持续发…...

DeepSeek 赋能智慧能源:微电网优化调度的智能革新路径
目录 一、智慧能源微电网优化调度概述1.1 智慧能源微电网概念1.2 优化调度的重要性1.3 目前面临的挑战 二、DeepSeek 技术探秘2.1 DeepSeek 技术原理2.2 DeepSeek 独特优势2.3 DeepSeek 在 AI 领域地位 三、DeepSeek 在微电网优化调度中的应用剖析3.1 数据处理与分析3.2 预测与…...

React第五十七节 Router中RouterProvider使用详解及注意事项
前言 在 React Router v6.4 中,RouterProvider 是一个核心组件,用于提供基于数据路由(data routers)的新型路由方案。 它替代了传统的 <BrowserRouter>,支持更强大的数据加载和操作功能(如 loader 和…...

高频面试之3Zookeeper
高频面试之3Zookeeper 文章目录 高频面试之3Zookeeper3.1 常用命令3.2 选举机制3.3 Zookeeper符合法则中哪两个?3.4 Zookeeper脑裂3.5 Zookeeper用来干嘛了 3.1 常用命令 ls、get、create、delete、deleteall3.2 选举机制 半数机制(过半机制࿰…...

TRS收益互换:跨境资本流动的金融创新工具与系统化解决方案
一、TRS收益互换的本质与业务逻辑 (一)概念解析 TRS(Total Return Swap)收益互换是一种金融衍生工具,指交易双方约定在未来一定期限内,基于特定资产或指数的表现进行现金流交换的协议。其核心特征包括&am…...

华为云Flexus+DeepSeek征文|DeepSeek-V3/R1 商用服务开通全流程与本地部署搭建
华为云FlexusDeepSeek征文|DeepSeek-V3/R1 商用服务开通全流程与本地部署搭建 前言 如今大模型其性能出色,华为云 ModelArts Studio_MaaS大模型即服务平台华为云内置了大模型,能助力我们轻松驾驭 DeepSeek-V3/R1,本文中将分享如何…...

tree 树组件大数据卡顿问题优化
问题背景 项目中有用到树组件用来做文件目录,但是由于这个树组件的节点越来越多,导致页面在滚动这个树组件的时候浏览器就很容易卡死。这种问题基本上都是因为dom节点太多,导致的浏览器卡顿,这里很明显就需要用到虚拟列表的技术&…...

重启Eureka集群中的节点,对已经注册的服务有什么影响
先看答案,如果正确地操作,重启Eureka集群中的节点,对已经注册的服务影响非常小,甚至可以做到无感知。 但如果操作不当,可能会引发短暂的服务发现问题。 下面我们从Eureka的核心工作原理来详细分析这个问题。 Eureka的…...

基于Java Swing的电子通讯录设计与实现:附系统托盘功能代码详解
JAVASQL电子通讯录带系统托盘 一、系统概述 本电子通讯录系统采用Java Swing开发桌面应用,结合SQLite数据库实现联系人管理功能,并集成系统托盘功能提升用户体验。系统支持联系人的增删改查、分组管理、搜索过滤等功能,同时可以最小化到系统…...

【SSH疑难排查】轻松解决新版OpenSSH连接旧服务器的“no matching...“系列算法协商失败问题
【SSH疑难排查】轻松解决新版OpenSSH连接旧服务器的"no matching..."系列算法协商失败问题 摘要: 近期,在使用较新版本的OpenSSH客户端连接老旧SSH服务器时,会遇到 "no matching key exchange method found", "n…...